p726

1. (C.1)

이 명령어들에 붙은 **'D'**는 **Doubleword(64비트, 8바이트)**를 의미합니다.
우리가 흔히 배우는 기본 MIPS32 아키텍처(32비트)가 아니라,
MIPS64 아키텍처를 다루고 있기 때문에 이름이 살짝 다를 뿐 원리는 완전히 똑같습니다.
LD (Load Doubleword):
메모리에서 64비트 데이터를 레지스터로 읽어옵니다. (32비트의 LW와 동일)
**Forwading 할때 X가 아니라 M에서 데이터 값 저장
DADDI (Doubleword Add Immediate):
상수(Immediate)를 더하는 명령어입니다. (32비트의 ADDI와 동일)
SD (Store Doubleword):
레지스터의 64비트 데이터를 메모리에 씁니다. (32비트의 SW와 동일)
**store X에서 주소계산, M에서 데이터 저장
DSUB (Doubleword Subtract):
두 레지스터의 값을 뺍니다. (32비트의 SUB와 동일)
BNEZ (Branch if Not Equal to Zero):
레지스터 값이 0이 아니면 지정된 라벨(Loop)로 점프합니다. BNE R4, R0, Loop를 짧게 쓴 형태입니다.달리기 경주 비유
- R3 (도착선): 초기값이 R2 + 396입니다. 즉, 출발선보다 396만큼 앞에 그어진 '도착선'이며, 루프를 도는 동안 값이 절대 변하지 않습니다.
- R2 (달리기 선수): 코드를 돌 때마다 DADDI R2, R2, 4 명령어를 만나서 한 걸음에 4씩 앞으로 전진합니다.
- R4 (남은 거리): DSUB R4, R3, R2 명령어를 통해 도착선(R3)에서 선수의 현재 위치(R2)를 뺍니다.
- BNEZ (심판): BNEZ R4, Loop는 "남은 거리(R4)가 0이 아니면 다시 뛰어라(Loop로 돌아가라)!"라고 지시합니다.
// C equivalent loop
for (int R2 = start; R2 < start + 396; R2 += 4) {
// Execute loop instructions
}b.
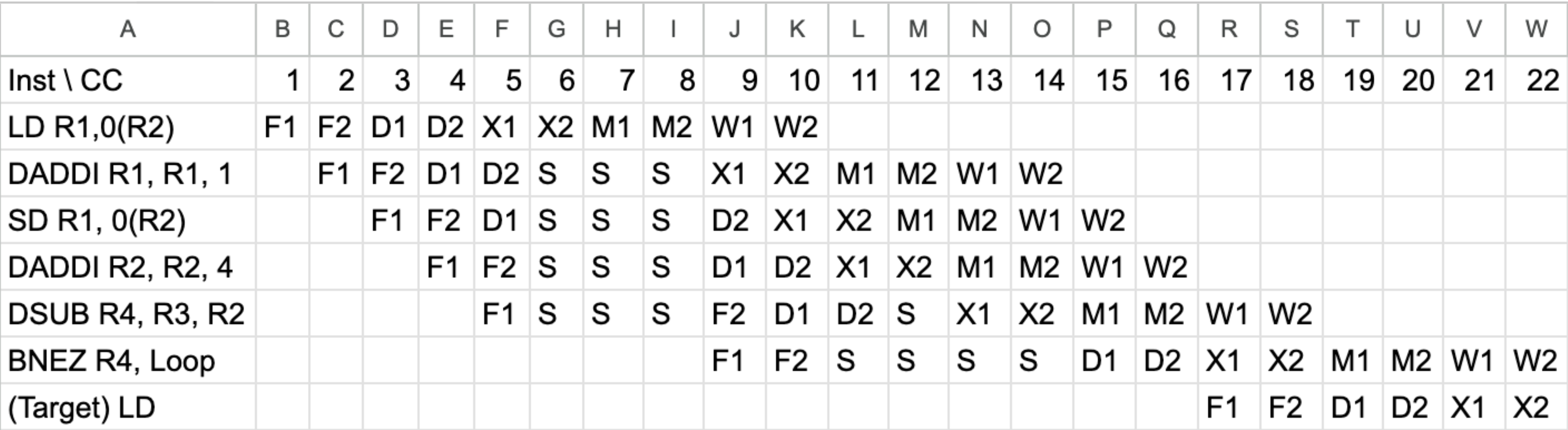
[15] <C.2> Show the timing of this instruction sequence for the 5-stage RISC pipeline without any forwarding or bypassing hardware but assuming that a register read and a write in the same clock cycle "forwards" through the register file, as shown i n Figure C.6. Use a pipeline timing chart like that in Figure C.5. Assume that the branch is handled by flushing the pipeline. If all memory references take 1 cycle, how many cycles does this loop take to execute?
-
No forwarding or bypassing: 포워딩(지름길) 회로가 없습니다. 앞 명령어의 결과가 필요하면, 무조건 레지스터에 기록될 때(WB 단계)까지 기다려야(Stall) 합니다.
-
Half-clock register read/write: 같은 클럭 안에서 전반부에는 쓰고(WB), 후반부에는 읽을 수(ID) 있습니다. 즉, 앞 명령어가 WB를 하는 클럭에 뒤 명령어는 ID에서 그 값을 읽어올 수 있습니다.
-
Branch is handled by flushing: 분기(Branch) 명령어는 ID 단계에서 판단이 끝납니다. 점프해야 한다면 파이프라인을 비우고(Flush), 다음 클럭에 목적지 주소부터 새로 가져옵니다(IF).

Q.왜 cc16에 다음 사이클 시작이야?
R4랑은 충돌될거도 없잖아? CC15에 할수 있는거 아냐?
-> 정말 예리한 질문입니다! 데이터 의존성(Data Hazard) 관점에서는 회원님 말씀이 100% 맞습니다. R4와 다음 루프의 LD 명령어 사이에는 데이터 충돌이 전혀 없죠.
그런데도 다음 사이클의 LD가 CC15가 아니라 CC16에 시작해야 하는 이유는, 바로 제어 해저드(Control Hazard) 즉, "점프(Branch) 명령어 자체의 동작 원리" 때문입니다.
BNEZ의 ID 단계 (CC15)에서 벌어지는 일
MIPS 파이프라인에서 분기 명령어(BNEZ)는 ID (해독) 단계에서 다음 두 가지 일을 완수해야 합니다.
- 조건 확인: 레지스터 R4의 값을 읽어와서 0인지 아닌지 비교합니다. (점프할까, 말까?)
- 주소 계산: 점프해야 한다면, 돌아갈 Loop의 진짜 메모리 주소가 몇 번지인지 계산합니다. (어디로 점프할까?)
왜 CC15에 다음 LD를 시작할 수 없을까?
시간적 순서의 한계: BNEZ가 CC15 동안 열심히 "점프할지 말지", "어디로 갈지"를 계산하고 있습니다. 이 계산 결과는 CC15 클럭이 끝나는 그 찰나의 순간(클럭 엣지)에 비로소 완료되어 PC(프로그램 카운터)에 저장됩니다.
IF 단계의 입장: CPU가 메모리에서 LD 명령어를 가져오려면(IF 단계), 무조건 PC에 적힌 주소를 보고 찾아가야 합니다. 하지만 CC15 진행 중에는 아직 PC에 Loop의 주소가 업데이트되지 않았습니다.
결론: 따라서, CC15가 완전히 끝나고 PC가 업데이트된 직후인 CC16이 되어야만, 비로소 새롭게 알아낸 주소(Loop)로 달려가서 LD 명령어를 가져올 수(IF) 있는 것입니다.
Data Hazard (충돌) 위치 찾기
- LD DADDI R1: LD가 R1에 데이터를 쓸 때까지 대기 (2 Stall)
- DADDI R1 SD: DADDI가 계산한 R1 값을 SD가 저장해야 하므로 대기 (2 Stall)
- DADDI R2 DSUB: DADDI가 계산한 R2 값을 DSUB가 연산에 써야 하므로 대기 (2 Stall)
- DSUB BNEZ: DSUB가 계산한 R4 값을 BNEZ가 비교해야 하므로 대기 (2 Stall)
1루프 사이클 = (명령어 개수) + (데이터 스톨 횟수) + (분기 페널티)
- 명령어 개수: 코드 줄 수가 총 6개입니다.
- 데이터 스톨(Stall) 횟수 세기:
LD DADDI (R1 충돌): 2번 멈춤
DADDI SD (R1 충돌): 2번 멈춤
SD DADDI (충돌 없음): 0번
DADDI DSUB (R2 충돌): 2번 멈춤
DSUB BNEZ (R4 충돌): 2번 멈춤
총 스톨 = 8번
1단계: 이 루프는 총 몇 바퀴를 돌까?
문제 맨 밑에 보면 초기값 R3 = R2 + 396이라고 되어 있죠?
그리고 코드를 보면 DADDI R2, R2, #4 (R2를 4씩 증가시킴)를 하고, 마지막에 DSUB R4, R3, R2 (R3에서 R2를 뺌)를 합니다.
결과가 0이 될 때까지 도는 거니까, 396이라는 차이를 4씩 줄여나가는 겁니다.
계산: 396 ÷ 4 = 99바퀴
2단계: 98바퀴까지 걸린 시간 구하기 (바통 터치)
우리가 방금 앞서 배운 진짜 중요한 사실이 있죠? "이 루프는 다음 바퀴로 넘어갈 때까지 15사이클이 걸린다!" -> 다음 바퀴 넘어가기 직전 사이클 숫자
즉, 첫 번째 바퀴가 출발하고 나서 15사이클 뒤에 두 번째 바퀴가 출발합니다. 이렇게 98번의 바통 터치를 합니다.
계산: 15사이클 × 98번 = 1,470 사이클
(즉, 마지막 99번째 바퀴의 첫 명령어 LD는 1,471번째 클럭에서 딱 출발합니다.)
3단계: 대망의 마지막 99번째 바퀴 달리기
마지막 99번째 바퀴는 점프를 하지 않고 그냥 끝납니다.
우리가 그렸던 표를 잘 떠올려보세요! 첫 명령어 LD가 IF(1번 칸)에서 시작해서, 마지막 명령어 BNEZ가 WB(18번 칸)에서 완전히 끝날 때까지 한 바퀴를 완주하는 데 총 18칸(사이클)이 필요했습니다.
계산: 1,471번째 클럭에서 시작해서 18칸을 진행합니다. (1471을 포함해서 18개를 세어야 하므로, 을 합니다.)최종 종료 시간: 1471 + 17 = 1,488 사이클
c.
Show the timing of this instruction sequence for the 5-stage RISC pipeline with full forwarding and bypassing hardware. Use a pipeline timing chart like that shown in Figure C.5. Assume that the branch is handled by predicting it as not taken. If all memory references take 1 cycle, how many cycles does this loop take to execute?

포워딩이 있는데도 왜 S가 2번 생겼을까요?
1. CC4의 Stall (Load-Use Hazard): LD가 메모리에서 데이터를 가져오는 건 M 단계(CC4)가 끝나야 합니다. 그런데 DADDI는 X 단계 시작부터 그 값이 필요하죠. 시간을 거스를 순 없으니 1사이클 대기 후 포워딩을 받습니다. (앞차 DADDI가 멈추니 뒤차 SD의 F 단계도 CC4에서 강제로 멈춥니다.)
- CC6 ~ CC8의 예술적인 포워딩 (No Stall):
- SD는 DADDI가 만든 R1 값을 M 단계(CC7)에 씁니다. 이때 앞선 DADDI는 W 단계이므로 충돌 없이 넘깁니다.
- DSUB는 앞선 DADDI가 갓 계산해 낸 R2 값을 X 단계(CC8)에 씁니다. 포워딩 유닛이 EX/MEM 레지스터에서 값을 낚아채 오기 때문에 스톨 없이 통과합니다!
-
CC8의 Stall (Branch Data Hazard):
BNEZ는 점프할지 말지를 D 단계(CC8)에서 결정해야 합니다. 그런데 재료인 R4는 바로 앞 DSUB가 X 단계(CC8)에서 한창 계산 중입니다. 값이 없으니 1사이클 대기합니다. CC9에 DSUB가 M으로 넘어가면 그 값을 포워딩받아 평가를 완료(Taken!)합니다. -
CC10 시작 (Branch Penalty):
"점프 안 해!"라고 예측(Predict not taken)했지만, CC9에 평가해 보니 점프해야 했습니다. 그래서 헛짓거리를 취소하고, 진짜 목적지인 Loop의 첫 명령어(LD)를 CC10부터 새롭게 가져옵니다.결론: 1루프를 도는 간격은 딱 9사이클입니다. (CC1 CC10)
결론: 1루프를 도는 간격은 딱 9사이클입니다. (CC1 CC10)
루프 횟수는 이전 문제와 동일하게 99번입니다. (396 / 4 = 99)
98바퀴까지의 시간
루프 1바퀴마다 다음 루프로 바통 터치하는 데 9사이클이 걸립니다.
98바퀴 × 9사이클 = 882 사이클 * (즉, 마지막 99번째 바퀴의 LD는 883번째 클럭에 시작합니다.)
마지막 99번째 바퀴 완주:
위 표를 보시면 1번째 LD의 F부터 1번째 BNEZ의 W까지 루프 하나가 완전히 끝나는 길이는 12칸입니다.
883번째 클럭부터 시작해서 12칸을 진행합니다.
883 + 12 - 1 = 894 사이클
정답: 이 루프를 모두 실행하는 데 총 894 사이클이 소요됩니다.
d.
Show the timing of this instruction sequence for the 5-stage RISC pipeline with full forwarding and bypassing hardware. Use a pipeline timing chart like that shown in Figure C.5. Assume that the branch is handled by predicting it as taken. I f all memory references take 1 cycle, how many cycles does this loop take to execute?
- "Predict Taken" 하드웨어의 핵심 원리
이번 문제의 가장 중요한 차이점은 분기 명령어(BNEZ)의 ID(Decode) 단계가 두 가지 일을 병렬로 처리한다는 사실입니다.
- 타겟 주소 계산: PC + Offset을 계산하여 점프할 목적지(Loop) 주소를 알아냅니다. (이건 R4 값이 없어도 계산할 수 있습니다!)
- 조건 평가 (비교기): R4가 0인지 아닌지 확인합니다. (DSUB의 결과가 필요합니다.)
[예측 마법 발동]
BNEZ가 CC8에 ID 단계에 들어오면, 조건 평가(2번)는 R4가 없어서 스톨(S)에 걸립니다. 하지만 타겟 주소 계산(1번)은 CC8에 정상적으로 완료됩니다.
하드웨어는 "어차피 점프할 거라고 예측(Predict Taken)했으니까, 조건 평가가 끝날 때까지 기다리지 말고 방금 계산한 주소로 무조건 달려가!"라고 지시합니다. 그래서 CC9에 곧바로 타겟 주소(Loop)의 LD 명령어를 가져옵니다(Fetch).

[스톨 및 포워딩 분석]
- CC4 (Load-Use Stall): 앞선 LD 데이터를 기다리느라 1사이클 대기.
- CC8 (Branch Data Stall): BNEZ가 R4를 기다리며 ID 단계에서 대기. 하지만 여기서 목적지 주소(Loop) 계산은 끝납니다.
- CC9 (예측 성공 및 실행): * DSUB가 M 단계에 진입하며 포워딩으로 R4 값을 넘겨줍니다.
- BNEZ는 이 값을 받아 D 단계에서 "점프 맞네!" 하고 평가를 완료합니다.
- 동시에 IF 단계에서는 CC8에서 계산해 둔 Loop 주소로 뛰어가 새로운 LD를 가져옵니다. (페널티 0 사이클!)
taken 은 이전 cycle D에서 F 가능
결론적으로, 루프 1바퀴를 도는 간격은 이전 9사이클에서 8사이클로 더 짧아졌습니다.
이제 공식을 사용해 전체 사이클을 도출해 보겠습니다. 루프 횟수는 동일하게 99번 () 입니다.
-
98바퀴까지의 시간
1루프당 다음 루프로 넘어가는 간격은 8사이클입니다.
98번의 바통 터치가 일어나므로, 99번째 루프의 시작점은:
-
마지막 99번째 바퀴 완주
- 99번째 루프의 첫 명령어 LD는 CC785에 시작(F)합니다.
- 위 표를 보면, 1번째 LD의 F (CC1)부터 마지막 BNEZ의 W (CC12)까지 루프 1개가 완전히 종료되는 데는 12칸이 필요합니다.
- 따라서 785번째 클럭부터 12칸을 진행하면 됩니다.
(참고: 99번째 루프에서는 예측(Taken)이 틀려서(실제로는 Not Taken) CC793에 가져왔던 타겟 LD를 플러시(Flush)하고 올바른 다음 명령어를 다시 가져와야 하지만, 이는 루프 외부의 명령어에 영향을 줄 뿐, 루프의 마지막 명령어인 BNEZ가 W 단계를 마치는 시간(796) 자체를 연장시키지는 않습니다.)
정답: 이 루프를 모두 실행하는 데 총 796 사이클이 소요됩니다.
e.
High-performance processors have very deep pipelines—more than 15 stages. Imagine that you have a 10-stage pipeline in which every stage of the 5-stage pipeline has been split in two. The only catch is that, for data forwarding, data are forwarded from the end of a pair of stages to the beginning of the two stages where they are needed. For example, data are forwarded from the output of the second execute stage to the input of the first execute stage, still causing a I-cycle delay. Show the timing of this instruction sequence for the 10-stage RISC pipeline with full forwarding and bypassing hardware. Use a pipeline timing chart like that shown in Figure C.5. Assume that the branch is handled by predicting it as taken . If all memory references take 1 cycle, how many cycles does this loop take to execute?
"슈퍼파이프라이닝(Superpipelining) 10-stage"
이 문제는 기존 5단계를 무식하게 반으로 쪼개서 10단계(F1, F2, D1, D2, X1, X2, M1, M2, W1, W2)로 늘려버린 고성능 프로세서의 상황을 가정합니다.
규칙: 데이터를 주는 쪽은 두 번째 단계(예: X2, M2)가 끝나야 줄 수 있고, 받는 쪽은 첫 번째 단계(예: X1, D1)가 시작할 때 받아야 합니다.
- ALU to ALU (1 사이클 스톨):
- 앞 연산은 X2가 끝나야 값이 나옵니다.
- 뒤 연산은 X1 시작부터 값이 필요합니다.
- 즉, 바로 뒤따라오는 명령어는 X1에 들어가려다 앞의 X2가 아직 안 끝난 걸 보고 1사이클을 대기(Stall)해야 합니다.
- Load to ALU (Load-Use: 3 사이클 스톨):
- LD는 M2가 끝나야 메모리에서 값이 나옵니다.
- 뒤 연산은 X1에서 값이 필요합니다. 거리가 너무 멀기 때문에 무려 3사이클을 대기(Stall)해야 합니다.
- 분기문 평가 (Branch Resolution):
- 분기문 BNEZ의 조건 평가와 목적지 주소 계산은 해독 단계의 끝인 D2에서 완료된다고 가정합니다.
d번 문제에선 taken일때 s에서 주소를 계산하니 D에서 바로 Fetch가 됬는데, e번 문제에선 덧셈기가 쪼개져있어 D1+D2를 다써야 타겟 주소가 나온다.
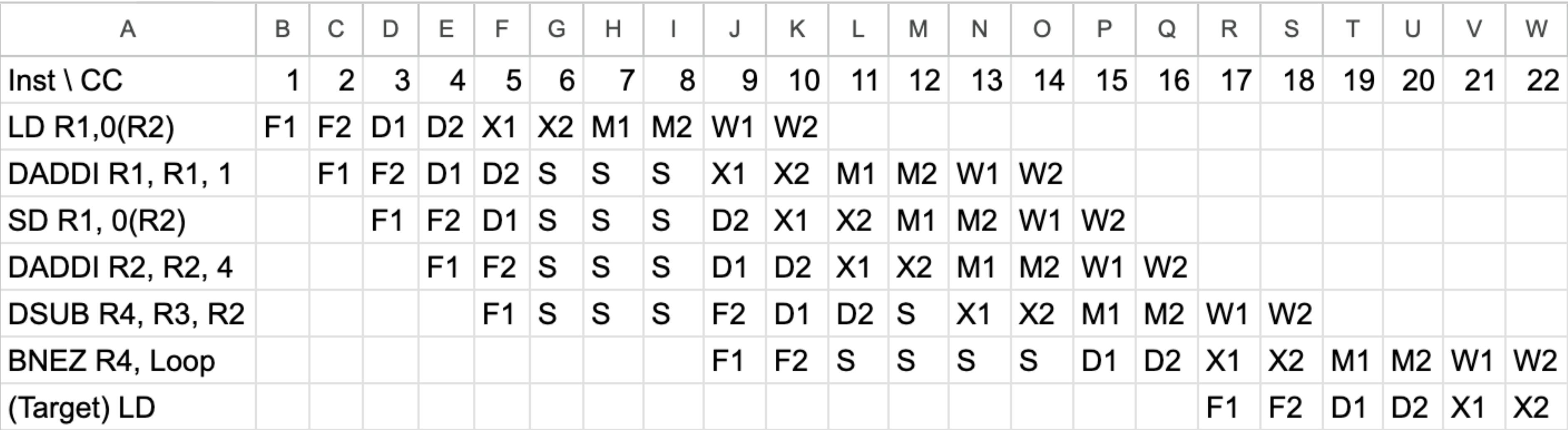
- CC6 ~ CC8 (Load-Use Stall): LD가 M2(CC8)를 끝낼 때까지, DADDI R1은 X1에 진입하지 못하고 3사이클(S)을 대기합니다. (뒤따라오던 SD, DADDI R2, DSUB도 줄줄이 밀려서 멈춥니다.)
- CC12 (ALU-ALU Stall): DSUB가 X1에 들어가려는데, 재료인 R2를 만드는 DADDI R2가 아직 X2(CC12)를 진행 중입니다. 따라서 1사이클을 대기하고 CC13에 X1을 시작합니다.
- CC11 ~ CC14 (Branch Data Stall): BNEZ는 D1 시작부터 R4 값이 필요합니다. 하지만 DSUB는 무려 CC14(X2)가 끝나야 R4를 뱉어냅니다. 따라서 BNEZ는 F2를 마치고 4사이클을 꼼짝없이 대기하다가 CC15에 D1을 시작합니다.
- CC17 (Target Fetch): 예측은 "Taken"으로 했지만, BNEZ가 실제로 어디로 갈지 주소를 알아내는 시점은 D2가 끝나는 CC16입니다. 따라서 다음 루프의 첫 명령어(LD)는 CC17에 F1을 새롭게 가져오기 시작합니다.
결론: 루프 1바퀴를 돌고 다음 루프로 넘어가는 간격은 16 사이클입니다! (CC1 CC17)
루프 횟수는 이전 문제들과 똑같이 99번입니다. 계산 공식도 완전히 똑같습니다!
1. 98바퀴까지의 바통 터치 시간:
1루프당 다음 루프 시작까지 16사이클이 걸립니다.
99번째 루프의 첫 명령어 LD가 F1을 시작하는 클럭(CC) = 1569 번째 클럭
- 마지막 99번째 바퀴 완주:
다이어그램을 보시면, 1번째 LD의 F1(CC1)부터 마지막 BNEZ의 W2(CC22)까지, 1개의 루프가 파이프라인을 완전히 빠져나가는 데 총 22칸(사이클)이 필요합니다.
1569번째 클럭부터 22칸을 진행합니다.
1590 사이클
최종 인사이트파이프라인을 잘게 쪼개서(10-stage) 클럭 스피드(Hz)를 극단적으로 높이면 컴퓨터가 빨라질 것 같지만, 보시다시피 해저드로 인한 스톨(거품) 페널티가 엄청나게 커집니다! (5-stage 796 사이클 10-stage 1,590 사이클)이것이 바로 과거 인텔 펜티엄 4 (극단적으로 긴 파이프라인)가 발열만 심하고 효율이 떨어져서 실패했던 역사적인 이유이기도 합니다.
f.
Assume that in the 5-stage pipeline the longest stage requires 0.8 ns, and the pipeline register delay is 0.1 ns. What is the clock cycle time ofthe 5-stage pipeline? If the 10-stage pipeline splits all stages in half, what is the cycle time of the 10-stage machine?
파이프라인의 클럭 속도는 "가장 오래 걸리는 단계(병목 현상)"에 맞춰서 설정해야 합니다. 거기에 데이터를 다음 단계로 넘기기 위해 파이프라인 레지스터가 닫히고 열리는 물리적인 지연 시간(Overhead)을 더해줘야 합니다.
1️⃣ 5-stage 파이프라인의 사이클 타임
가장 긴 단계(Longest stage)가 0.8 ns이고, 레지스터 지연(Register delay)이 0.1 ns입니다.
계산: 0.8 ns + 0.1 ns = 0.9 ns
정답: 5단계 파이프라인의 클럭 사이클 타임은 0.9 ns 입니다.
2️⃣ 10-stage 파이프라인의 사이클 타임 (모든 단계를 반으로 쪼갰을 때)
단계를 반으로 쪼개면 논리 회로가 처리해야 할 일도 반으로 줄어듭니다. 하지만 여기서 가장 중요한 함정은 "레지스터 지연 시간(0.1 ns)은 쪼개지지 않고 고정값으로 남는다"는 것입니다!
새로운 가장 긴 단계: 0.8 ns / 2 = 0.4 ns
레지스터 지연: 0.1 ns (그대로 유지)
계산: 0.4 ns + 0.1 ns = 0.5 ns
정답: 10단계 파이프라인의 클럭 사이클 타임은 0.5 ns 입니다.
이 간단한 산수 문제 안에 엄청난 하드웨어적 딜레마가 숨어있습니다.파이프라인을 2배로 잘게 쪼갰으니(5단계 -> 10단계), 이상적으로는 클럭 속도도 2배 빨라져서 사이클 타임이 0.45 ns가 되어야 할 것 같죠?
하지만 실제로는 0.45 ns가 아니라 0.5 ns에 머물렀습니다.
쪼개면 쪼갤수록 실제 연산 시간(0.4 ns) 대비 레지스터가 까먹는 낭비 시간(0.1 ns)의 비율이 점점 커지기 때문입니다. 즉, 단계를 무한히 쪼갠다고 무한히 빨라지는 것이 아니라, 레지스터 지연 시간이라는 물리적 장벽(Overhead) 때문에 성능 향상에 한계가 온다는 것을 보여주는 완벽한 예시입니다.
g.
Using your answers from parts (d) and (e), determine the cycles per instruction (CPI) for the loop on a 5-stage pipeline and a 10-stage pipeline. Make sure you count only from when the first instruction reaches the write-back stage to the end. Do not count the start-up of the first instruction. Using the clock cycle time calculated in part (f), calculate the average instruction execute time for each machine.
드디어 기나긴 파이프라인 여정의 마침표를 찍는 '최종 성능 평가(Performance Evaluation)' 문제입니다
이 문제의 가장 중요한 조건은 "첫 번째 명령어가 파이프라인을 채우는 데 걸리는 초기 시간(Start-up)을 제외하고 계산하라"는 것입니다. 즉, 파이프라인이 꽉 차서 톱니바퀴처럼 돌아가는 '루프 1바퀴당 평균적인 성능(Steady-state)'만 깔끔하게 보자는 뜻입니다.
사전 준비 (우리가 구했던 데이터)
- 루프 1바퀴당 명령어 개수 (Instruction Count): 6개 (LD, DADDI, SD, DADDI, DSUB, BNEZ)
- 5-stage 파이프라인 (Predict Taken): 루프 1바퀴 도는 데 8 사이클 소요 / 클럭 타임 0.9 ns
- 10-stage 파이프라인 (Predict Taken): 루프 1바퀴 도는 데 16 사이클 소요 / 클럭 타임 0.5 ns
1️⃣ 5-stage 파이프라인의 CPI 및 평균 실행 시간
1) CPI (Cycles Per Instruction)
초기 예열 시간을 제외하면, 6개의 명령어를 처리하는 데 꾸준히 8사이클이 걸리는 셈입니다.
계산: 8 사이클 / 6 명령어
CPI = 1.33 (명령어 1개당 평균 1.33클럭이 필요함)
2) 평균 명령어 실행 시간 (Average Instruction Execute Time)명령어 하나를 끝내는 데 실제 물리적인 시간(ns)이 얼마나 걸리는지 계산합니다.공식: CPI 클럭 사이클 타임계산: 1.33 0.9 ns평균 실행 시간 = 1.20 ns
2️⃣ 10-stage 파이프라인의 CPI 및 평균 실행 시간
1) CPI (Cycles Per Instruction)
마찬가지로 6개의 명령어를 처리하는 데 16사이클이 꾸준히 소모됩니다. (스톨이 너무 많아서 낭비가 심하죠!)
계산: 16 사이클 / 6 명령어
CPI = 2.67 (명령어 1개당 평균 2.67클럭이나 필요함)
2) 평균 명령어 실행 시간 (Average Instruction Execute Time)공식: CPI 클럭 사이클 타임계산: 2.67 0.5 ns평균 실행 시간 = 1.33 ns (반올림 기준, 정확히는 ns)
최종 결론 및 교수님의 출제 의도 (소름 돋는 반전)
두 결과를 나란히 비교해 볼까요?
5-stage 기계: 명령어당 1.20 ns
10-stage 기계: 명령어당 1.33 ns
클럭 속도(Hz)만 보면 10-stage 기계가 0.5 ns로 훨씬 빠릅니다. 마케팅 부서에서는 "우리 CPU가 클럭이 2배나 더 높아요!"라고 광고하겠죠.
하지만 실제 프로그램(이 루프 코드)을 돌려보니, 오히려 구형인 5-stage 기계가 더 빨리 계산을 끝냅니다! (1.20 ns < 1.33 ns)
이유: 파이프라인 단계를 잘게 쪼개서 클럭 속도를 높이더라도(0.9 ns 0.5 ns), 그로 인해 발생하는 해저드 스톨(Stall)의 개수가 기하급수적으로 늘어나버려 CPI가 망가졌기 때문(1.33 2.67)입니다. 게다가 레지스터 지연 시간(0.1 ns)이라는 물리적 낭비까지 겹쳤죠.
이것이 바로 컴퓨터 구조학에서 가장 중요한 교훈인 "클럭 속도(Clock Rate)가 높다고 무조건 좋은 CPU가 아니다. 진정한 성능은 CPI와 클럭 속도의 조화에서 나온다."를 증명하는 완벽한 과정입니다.
2.
Use the same code fragment in Exercise C.1, and assume 5-stage RISC pipeline with a single-cycle delayed branch slot and normal forwarding and bypassing hardware. Schedule the instructions in the loop including the branch delay slot. You may reorder instructions and modify the individual instruction operations, but do not undertake other loop transformations that change the number or opcode of the instructions in the loop. Show a pipeline timing diagram and compute the number of cycles need to execute the entire loop.
명령어 스케줄링(Code Scheduling)과 지연 분기(Delayed Branch)를 결합하는 문제
이 문제는 하드웨어가 어쩔 수 없이 만들어내는 거품(Stall)들을, 프로그래머(혹은 컴파일러)가 코드의 순서를 영리하게 바꿔서(Reordering) 완벽하게 0개로 없애버리는 것이 목표입니다. 어떻게 테트리스 빈칸을 채우는지 단계별로 쪼개서 보여드릴게요.
-
지연 분기 슬롯 (Delayed Branch Slot)이란?
보통 분기 명령어(BNEZ)는 점프할 곳을 계산하느라 1사이클의 페널티(거품)를 만듭니다.
하지만 지연 분기(Delayed Branch)를 지원하는 하드웨어는 이 페널티를 없애기 위해 특별한 규칙을 씁니다.
"분기 명령어 바로 밑에 있는 1줄(Delay Slot)은, 점프를 하든 안 하든 무.조.건 실행해 줄게!"
즉, 이 빈칸(슬롯)에 유용한 명령어를 끼워 넣으면 분기 페널티를 완벽하게 공짜로 없앨 수 있습니다. -
마법의 코드 스케줄링 (재배치)
원래 코드는 LD 직후에 R1을 쓰고, DSUB 직후에 R4를 써서 스톨이 펑펑 터지는 구조였습니다. 이제 규칙을 어기지 않는 선에서 순서를 섞어보겠습니다.
[최적화 전략]
- Load-Use Stall 피하기: LD R1과 DADDI R1 사이에 연관 없는 명령어를 끼워 넣습니다. DADDI R2를 위로 끌어올립니다.
- 주소 보정 (핵심!): R2가 원래 순서보다 일찍 +4가 되어버렸죠? 그렇다면 뒤에 나오는 SD 명령어는 원래 주소에 제대로 저장하기 위해 오프셋을 4만큼 빼줘야 합니다. 즉, 0(R2)가 아니라 -4(R2)로 조작합니다. (문제에서 명령어 연산 수정은 허용했습니다.)
- Branch Data Stall 피하기: BNEZ는 DSUB의 결과를 당장 원합니다. 이 둘 사이를 벌려놓기 위해 DSUB도 위로 끌어올립니다.
- 지연 슬롯 채우기: 마지막에 남은 SD R1, -4(R2)를 BNEZ 바로 밑(Delay Slot)에 배치합니다.
Forwarding 했을때 원래 파이프라인
Loop: LD R1, 0(R2) // 1. R1 가져오기
DADDI R2, R2, #4 // 2. R2 미리 증가! (LD의 Load-Use 스톨 방어막)
DSUB R4, R3, R2 // 3. R4 계산 (변경된 R2 사용)
DADDI R1, R1, #1 // 4. R1 증가 (LD 데이터는 이미 도착함!)
BNEZ R4, Loop // 5. 분기 판단 (DSUB와 떨어져 있어서 스톨 없음)
SD R1, -4(R2) // 6. [지연 슬롯] 분기 직후 무조건 실행. (변경된 R2 반영)
[다이어그램 해설]
- CC6에서 BNEZ가 ID 단계를 수행하며 Loop로 점프할 주소를 알아냅니다.
- 지연 슬롯의 마법: 점프하기로 결정이 났음에도 불구하고, 하드웨어 규칙에 따라 CC6에 바로 밑의 명령어인 SD를 정상적으로 Fetch(F) 합니다.
- CC7이 되어서야 비로소 타겟 주소인 Loop의 첫 명령어(LD)를 새롭게 Fetch(F) 합니다. 빈칸(거품)이 단 하나도 생기지 않았습니다!
- 1루프를 도는 간격은 단 6 사이클입니다. (CC1 -> CC7)
총 실행 사이클 (Total Cycles) 계산
루프 횟수는 기존 문제들과 동일하게 99번입니다. (R2가 396만큼 증가, 한 번에 4씩 증가)
- 98바퀴까지의 바통 터치 시간:
- 1루프당 시작 간격은 6 사이클입니다.
- 98바퀴 × 6 사이클 = 588 사이클
- 99번째 루프의 첫 명령어 LD는 589번째 클럭(CC589)에 시작합니다.
- 마지막 99번째 바퀴 완주:
- 다이어그램을 보면, 1번째 LD의 F (CC1)부터 마지막 지연 슬롯 SD의 W (CC10)까지 1루프가 완전히 끝나는 길이는 10칸입니다.
- 589번째 클럭부터 10칸을 진행합니다. (지연 분기에서는 점프를 안 하더라도 지연 슬롯에 있는 SD는 끝까지 실행됩니다!)
- 589 + 10 - 1 = 598 사이클
정답: 최적화된 코드로 이 루프를 모두 실행하는 데 총 598 사이클이 소요됩니다.
스톨이 가득해서 1,488 사이클이나 걸리던 최초의 코드가, 포워딩 하드웨어와 똑똑한 컴파일러(코드 스케줄링)를 만나 598 사이클(거의 2.5배 속도 향상!)로 극적으로 최적화되었습니다.
3. (C.2)
제어 해저드(Control Hazard / Branch Hazard)가 실제 CPU 성능(CPI)을 얼마나 깎아먹는지 수학적으로 계산하는 문제입니다.

a.
We are examining a four-deep pipeline where the branch is resolved at the end of the second cycle for unconditional branches and at the end of the third cycle for conditional branches. Assuming that only the first pipe stage can always be done independent of whether the branch goes and ignoring other pipeline stalls, how much faster would the machine be without any branch hazards?
Assuming that only the first pipe stage can always be done independent of whether the branch goes
이 문장의 진짜 의미는 다음과 같습니다:
"분기 명령어를 만나면, 일단 바로 다음 줄에 있는 명령어(PC+4)를 가져오기(IF, 1단계)까지는 무조건 진행한다. 하지만 분기 결과가 확실해질 때까지 그다음 단계(ID, 해독)로는 절대 넘어가지 못하고 그 자리에 멈춰서(Stall) 기다려야 한다."
각 분기 상황별 페널티(Penalty) 분석
1. Unconditional Branches (무조건 점프 / Jumps and calls) - 빈도: 1%
- 조건: 2번째 사이클(CC2) 끝에 타겟 주소가 나옵니다.
동작 흐름: - CC1: Jump 명령어 가져옴(IF).
- CC2: Jump 해독 중(ID). 하드웨어 규칙에 따라 다음 명령어(PC+4)를 일단 가져옴(IF). CC2 끝에서 "점프해!" 확정.
- CC3: 확정된 타겟 주소에서 새 명령어를 가져옴. CC2에서 가져왔던 PC+4는 쓰레기통에 버림(Flush).
결과: 1클럭 낭비 페널티 1 사이클
2. Conditional Branches - Taken (조건부 분기, 점프함) - 빈도: 15% 60% = 9%
- 조건: 3번째 사이클(CC3) 끝에 조건 평가가 끝납니다.
동작 흐름: - CC1: Branch 명령어 가져옴(IF).
- CC2: Branch 해독 중(ID). 하드웨어 규칙에 따라 다음 명령어(PC+4)를 일단 가져옴(IF).
- CC3: Branch 실행 중(EX). PC+4 명령어는 ID 단계로 못 들어가고 대기(Stall). CC3 끝에서 "점프해!" 확정.
- CC4: 타겟 주소에서 새 명령어를 가져옴. 대기하던 PC+4는 버림(Flush).
결과: 2클럭 낭비 페널티 2 사이클
3. Conditional Branches - Not Taken (조건부 분기, 점프 안 함) - 빈도: 15% 40% = 6%
- 조건: 3번째 사이클(CC3) 끝에 조건 평가가 끝납니다
동작 흐름: - CC1: Branch 명령어 가져옴(IF).
- CC2: Branch 해독 중(ID). 다음 명령어(PC+4)를 일단 가져옴(IF).
- CC3: Branch 실행 중(EX). PC+4 명령어는 ID 단계로 못 들어가고 대기(Stall). CC3 끝에서 "점프 안 해!" 확정.
- CC4: 점프 안 하니까 PC+4가 맞았음! 대기하고 있던 PC+4가 드디어 ID 단계로 진입.
결과: 명령어는 맞았지만, CC3에서 1칸을 억지로 쉬었음 페널티 1 사이클
4. 총 CPI (Cycles Per Instruction) 계산
해저드가 하나도 없는 이상적인(Ideal) 파이프라인의 기본 CPI는 1.0입니다. 여기에 위에서 구한 페널티들을 더해주면 실제 이 컴퓨터의 성능이 나옵니다.
무조건 점프 페널티:
조건부 분기(Taken) 페널티:
조건부 분기(Not Taken) 페널티:
5. 최종 정답 도출 (얼마나 더 빠른가?)
문제에서 요구한 "분기 해저드가 전혀 없을 때(Ideal 상황) 기계가 얼마나 더 빠른가?"를 구하는 공식은 다음과 같습니다. 성능(속도)은 CPI에 반비례합니다.
정답: 이 기계는 분기 해저드가 없을 때 1.25배 (또는 25%) 더 빠릅니다.
b.
파이프라인의 깊이가 15단계로 깊어졌을 때(슈퍼파이프라이닝) 제어 해저드의 페널티가 얼마나 끔찍하게 커지는지 확인하는 문제입니다!
Now assume a high-performance processor in which we have a
15-deep pipeline where the branch is resolved at the end of the fifth cycle for unconditional branches and a t the end of the tenth cycle for conditional branches. Assuming that only the first pipe stage can always be done independent of whether the branch goes and ignoring other pipeline stalls, how much faster would the machine be without any branch hazards?
1️⃣ 각 분기 상황별 페널티(Penalty) 분석
파이프라인 규칙은 동일합니다: "다음 명령어(PC+4)를 첫 단계(IF)로는 무조건 가져오지만, 분기가 확정될 때까지 다음 단계(ID)로는 넘어가지 못하고 스톨(Stall)된다."
1. Unconditional Branches (무조건 점프) - 빈도: 1%
- 조건: 5번째 사이클(CC5) 끝에 목적지 주소가 확정됩니다.
- 페널티 계산: 이상적인 경우 다음 명령어는 CC2에 가져와야 합니다. 하지만 실제 타겟 명령어는 CC5가 끝난 후인 CC6에 가져옵니다.
- 결과: 페널티 4 사이클
2. Conditional Branches - Taken (조건부 분기, 점프함) - 빈도: 9% (15%의 60%)
- 조건: 10번째 사이클(CC10) 끝에 점프 여부와 주소가 확정됩니다.
- 페널티 계산: 점프를 해야 하므로, 처음에 가져왔던 PC+4는 버리고 진짜 타겟 명령어를 CC11에 새롭게 가져옵니다.
- 결과: 페널티 9 사이클
3. Conditional Branches - Not Taken (조건부 분기, 점프 안 함) - 빈도: 6% (15%의 40%)
- 조건: 10번째 사이클(CC10) 끝에 점프 안 하는 것으로 확정됩니다.
- 페널티 계산: CC2에 가져다 놓은 PC+4 명령어가 무려 CC10이 끝날 때까지 꼼짝 못 하고 IF/ID 단계에서 스톨됩니다. 이상적인 경우 CC3에 다음 단계(ID)로 넘어가야 하지만, 실제로는 CC11에 넘어갑니다.
- 결과: 페널티 8 사이클
2️⃣ 총 CPI (Cycles Per Instruction) 계산
해저드가 없는 이상적인 파이프라인의 CPI는 1.0입니다. 여기에 위에서 구한 거대한 페널티들을 더해줍니다.
- 무조건 점프 페널티:
- 조건부 분기(Taken) 페널티:
- 조건부 분기(Not Taken) 페널티:
3️⃣ 최종 정답 도출 (얼마나 더 빠른가?)
분기 해저드가 전혀 없을 때(Ideal CPI = 1.0) 기계가 실제 상황(Actual CPI = 2.33)보다 얼마나 더 빠른지 비율을 계산합니다.
정답: 이 기계는 분기 해저드가 없을 때 2.33배 더 빠릅니다.
4-stage 파이프라인: 페널티로 인해 성능이 1.25배 깎였습니다.
15-stage 파이프라인: 페널티로 인해 성능이 무려 2.33배 깎였습니다. 즉, 기계가 가진 원래 성능의 절반 이하(1/2.33)로 뚝 떨어져 버렸습니다!
파이프라인을 깊게(15-deep) 만들면 클럭 속도(Hz)는 엄청나게 올릴 수 있습니다. 하지만, 분기 명령어 하나를 만날 때마다 버려야 하는 사이클(페널티)이 8~9개로 폭증하기 때문에, 똑똑한 분기 예측기(Branch Predictor)가 없다면 깊은 파이프라인은 오히려 최악의 설계가 되어버립니다.
4.(C.7)
In this problem, we will explore how deepening the pipeline affects performance in two ways: faster clock cycle and increased stalls due to data and control hazards. Assume that the original machine is a 5-stage pipeline with a 1 ns clock cycle. The second machine is a 12-stage pipeline with a 0.6 ns clock cycle. The 5-stage pipeline experiences a stall due to a data hazard every 5 instructions, whereas the 12-stage pipeline experiences 3 stalls every 8 instructions. In addition, branches constitute 20% of the instructions, and the misprediction rate for both machines is 5%.
a.
What is the speedup o f the 12-stage pipeline over the 5-stage pipeline, taking into account only data hazards?
이번에는 파이프라인의 단계를 깊게 파면서(Deepening) 얻는 이점(빠른 클럭)과 잃는 단점(데이터 해저드로 인한 스톨 증가)을 동시에 비교하여 진짜 성능(Speedup)을 구하는 아주 훌륭한 문제입니다.
문제 a번에서는 "데이터 해저드(Data hazards)만 고려했을 때" 12단계 파이프라인이 5단계 파이프라인보다 얼마나 빠른지(Speedup)를 묻고 있습니다. (즉, 분기문 관련 조건인 20%와 5% 오예측률은 a번 문제에서는 무시합니다!)
1️⃣ 5-stage 파이프라인 (기존 기계) 분석
- 기본 조건: 이상적인 CPI (Ideal CPI) = 1.0
- 클럭 사이클 타임 (): 1 ns
- 데이터 해저드 발생률: 5개의 명령어당 1번의 스톨 (1 stall every 5 instructions)
[CPI 및 실행 시간 계산]
1. 데이터 해저드 페널티: 1번 스톨 / 5명령어 = 명령어당 0.2 사이클
2. 실제 : 1.2
3. 명령어당 평균 실행 시간 ():
2️⃣ 12-stage 파이프라인 (새로운 기계) 분석
- 기본 조건: 이상적인 CPI (Ideal CPI) = 1.0
- 클럭 사이클 타임 (): 0.6 ns (클럭이 훨씬 빨라졌습니다!)
- 데이터 해저드 발생률: 8개의 명령어당 3번의 스톨 (3 stalls every 8 instructions)(파이프라인이 깊어지면 연산 결과를 기다려야 하는 칸 수가 많아지므로 스톨이 폭증합니다.)
[CPI 및 실행 시간 계산]
데이터 해저드 페널티: 3번 스톨 / 8명령어 = 명령어당 0.375 사이클
실제 : 1.375
명령어당 평균 실행 시간 ():
3️⃣ 최종 정답 도출: Speedup (성능 향상 비율)
성능(Speedup)은 "구형 기계가 걸린 시간"을 "신형 기계가 걸린 시간"으로 나누면 나옵니다.
정답: 12-stage 파이프라인은 데이터 해저드만 고려했을 때 5-stage 파이프라인보다 약 1.45배 (또는 145%) 더 빠릅니다.
b.
If the branch mispredict penalty for the first machine is 2 cycles but the second machine is 5 cycles, what are the CPIs of each, taking into account the stalls due to branch mispredictions?
분기 예측 실패(Branch Misprediction)로 인한 제어 해저드(Control Hazard) 스톨까지 모두 합산하여 최종 CPI를 구하는 문제입니다.
- 전체 명령어 중 분기문(Branch) 비율: 20% (0.20)
- 분기 오예측률 (Misprediction rate): 5% (0.05)(즉, 예측기가 95%는 맞히고, 5% 확률로 틀려서 페널티를 받는다는 뜻입니다.)
- 제어 해저드 스톨 계산 공식:
1️⃣ 5-stage 파이프라인 (기존 기계)의 최종 CPI
- 오예측 페널티 (Mispredict Penalty): 2 cycles
- 데이터 해저드 스톨 (a번에서 계산): 0.2 cycles
[계산]
제어 해저드 스톨:
최종 CPI:
2️⃣ 12-stage 파이프라인 (새로운 기계)의 최종 CPI
- 오예측 페널티 (Mispredict Penalty): 5 cycles
(파이프라인이 깊어지면 분기 결과를 알아내는 단계도 뒤로 밀리기 때문에 페널티가 커집니다!) - 데이터 해저드 스톨 (a번에서 계산): 0.375 cycles
[계산]
1. 제어 해저드 스톨:
2. 최종 CPI:
정답:
5-stage 파이프라인의 최종 CPI = 1.22
12-stage 파이프라인의 최종 CPI = 1.425
