1. Global Prediction: Correlated Prediction
Code fragment from eqntott:
if (aa==2) aa=0; (b1)
if (bb==2) bb=0; (b2)
if (aa!=bb) { … (b3)
MIPS code (aa=R1, bb=R2):
SUBUI R3,R1,#2 ;(aa-2)
BNEZ R3,L1 ; branch b1 (aa!=2)
ADD R1,R0,R0 ; aa=0
L1: SUBUI R3,R2,#2 ;(bb-2)
BNEZ R3,L2 ; branch b2 (bb!=2)
ADD R2,R0,R0 ; bb=0
L2: SUBU R3,R1,R2 ;(aa-bb)
BEQZ R3,L3 … ; branch b3 (aa==bb)
b3 is taken if both b1 and b2 are not taken핵심은 "서로 관련이 없어 보이는 앞선 두 개의 if문이, 세 번째 if문의 결과를 100% 결정지어 버린다"는 것을 증명하는 것입니다. 이것이 바로 주변 문맥을 파악하는 상관 예측(Correlated Prediction)의 존재 이유입니다.
BNEZ (Branch if Not Equal to Zero)
뜻: 검사하는 레지스터의 값이 0이 아니면(Not Equal to 0) 지정된 라벨로 점프해라.
BEQZ (Branch if Equal to Zero)
뜻: 검사하는 레지스터의 값이 정확히 0과 같으면(Equal to 0) 지정된 라벨로 점프해라.
1. C 코드의 숨겨진 함정 (상관관계)

먼저 C 코드를 논리적으로 따라가 보겠습니다.
b1: 만약 aa == 2라면, aa를 0으로 만듭니다.
b2: 만약 bb == 2라면, bb를 0으로 만듭니다.
b3: 만약 aa != bb라면, 괄호 안으로 들어갑니다.
여기서 아주 특정한 상황을 가정해 봅시다. 만약 애초에 aa도 2였고, bb도 2였다면 어떻게 될까요?
b1을 거치면서 aa는 0이 됩니다.
b2를 거치면서 bb도 0이 됩니다.
이제 b3 조건문에 도달했습니다. aa는 0이고 bb도 0입니다. 둘은 무조건 같습니다.
따라서 aa != bb라는 조건은 무조건 거짓(False)이 됩니다.
2. MIPS 어셈블리로 보는 하드웨어의 동작
이제 이 상황을 슬라이드에 있는 하드웨어 분기(Branch) 명령어의 시선으로 다시 보겠습니다. (참고로 분기 조건이 참이어서 다른 곳으로 뛰면 Taken, 조건이 거짓이어서 바로 다음 줄을 실행하면 Not Taken입니다.)
-
b1 (BNEZ R3, L1): aa != 2일 때 L1으로 점프(Taken)합니다. 즉, aa == 2여서 값을 0으로 바꾸는 작업을 하려면 점프를 하지 말아야 합니다 (Not Taken).
-
b2 (BNEZ R3, L2): bb != 2일 때 L2로 점프(Taken)합니다. 마찬가지로 bb == 2여서 값을 0으로 바꾸려면 점프를 하지 말아야 합니다 (Not Taken).
-
b3 (BEQZ R3, L3): aa == bb일 때 L3로 점프(Taken)하여 if 블록을 건너뜁니다.
3. 결론: "b3 is taken if both b1 and b2 are not taken"
위의 1번과 2번 분석을 합치면 슬라이드 맨 마지막의 마법 같은 문장이 완성됩니다.
앞선 b1과 b2가 둘 다 점프하지 않았다면(Not Taken), 그것은 aa와 bb가 모두 2였다는 뜻이고, 둘 다 0으로 바뀌었으므로 무조건 aa == bb가 성립합니다. 따라서 b3에서는 계산해 볼 것도 없이 무조건 L3로 건너뛰어야(Taken) 합니다.
-
기존 Local Predictor의 멍청함: 오직 b3 자신의 과거 기록만 봅니다. b1, b2에서 무슨 일이 있었는지 모르기 때문에, b3에서 점프를 할지 말지 찍다가 계속 틀립니다.
-
Global (Correlated) Predictor의 영리함: 하드웨어가 직전에 실행된 b1과 b2의 결과를 기억해 둡니다. "어? 방금 b1 안 뛰었고(0), b2도 안 뛰었네(0)? 그럼 b3는 100% 무조건 뛰는(1) 자리구나!" 하고 완벽하게 정답을 예측해 냅니다.
즉, 이 슬라이드는 단일 분기문 하나만 쳐다보는 시야에서 벗어나, "프로그램 전체의 실행 맥락(Global History)을 읽어야만 예측 실패율의 한계를 돌파할 수 있다"는 것을 완벽하게 증명하는 예시입니다.
2. Even Simpler Example

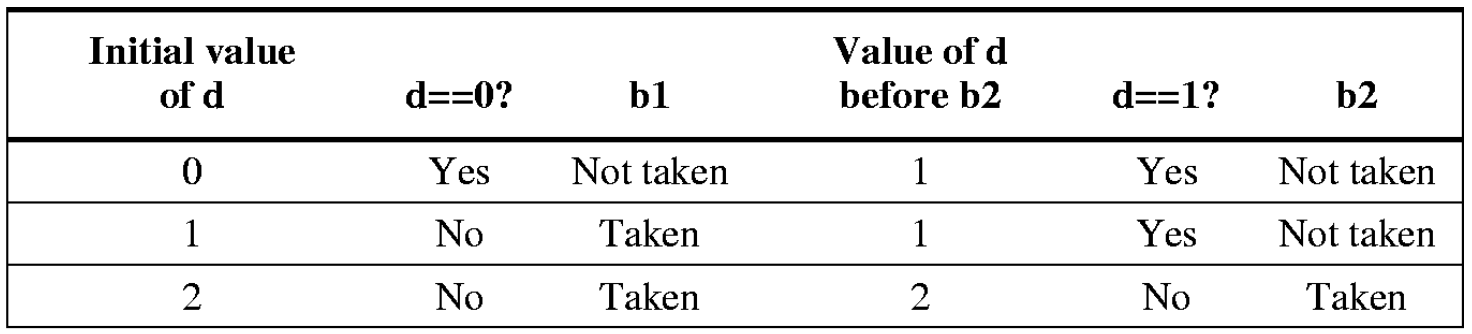
b2 will not be taken if b1 is not taken
- Correlated Predictor의 해결책: 하드웨어가 직전 분기문 b1이 어땠는지를 기억합니다. 만약 방금 전 b1이 Not Taken(0)이었다면, 하드웨어는 과거의 기록이나 패턴을 복잡하게 계산할 필요도 없이 "방금 b1이 0이었어? 그럼 이번 b2도 100% 0(Not Taken)이겠네!"라고 완벽하게 적중시켜 버립니다.
3. Using 1-bit Predictor
- Suppose initial value of ‘d’ alternates between 2 and 0. The initial value of b1 and b2 predictor is “NT”
- All branches are mispredicted!!
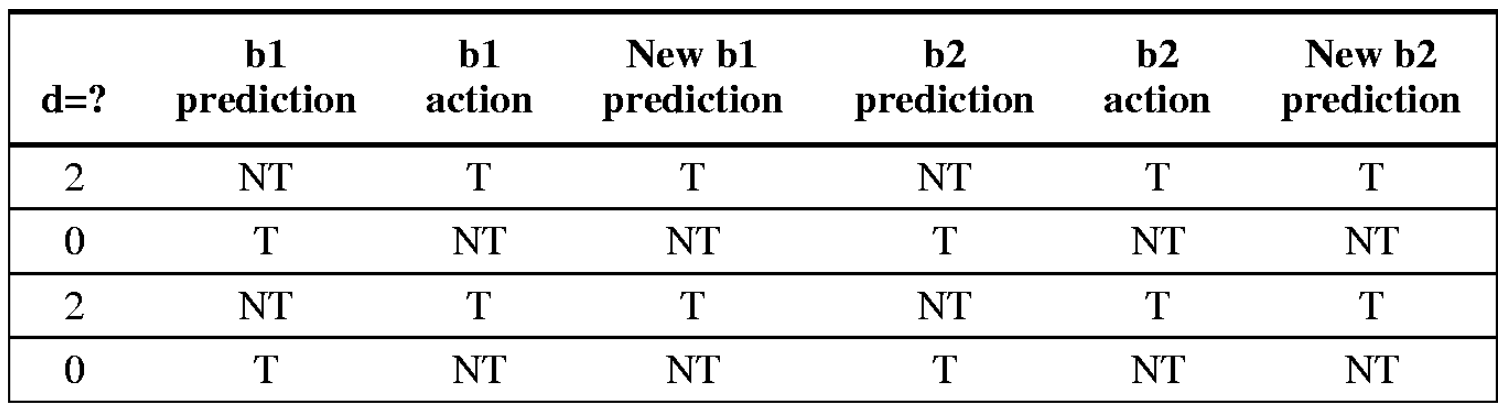
C code:
if (d==0) d=1; if (d==1)
이 슬라이드는 방금 전 보셨던 코드를 기존의 1비트 로컬 예측기(1-bit Local Predictor)로 돌렸을 때 발생하는 대참사(0% 적중률)를 증명하는 표입니다.
3. 결론: 로컬 예측기(Local Predictor)의 치명적 한계
이 표가 말하고자 하는 핵심은 명확합니다. 1비트 로컬 예측기는 널뛰기(Alternating) 패턴에 완벽하게 무방비라는 것입니다.
예측기가 자신의 '과거'만 보고 미래를 찍기 때문에, 정답이 T -> NT -> T -> NT로 바뀌는 상황에서는 항상 정답의 정확히 반대만 찍으면서 영원히 한 박자 늦은 뒷북을 치게 됩니다. 그 결과 예측 실패율 100%라는 재앙이 발생합니다.
4. Correlating Predictors
- Have different predictions for the current branch depending on the previously executed branch instruction was taken or not.
앞서 로컬 예측기가 2 -> 0 -> 2 -> 0 패턴에서 100% 오답을 내며 처참하게 박살 나는 것을 보셨습니다.
이 슬라이드는 바로 그 동일한 악조건에서, 상관 예측기(Correlated Predictors)가 어떻게 단 한 번의 초기 학습만으로 나머지 모든 예측을 100% 적중시켜 버리는지 그 마법 같은 원리를 증명합니다.
1. 표기법의 비밀: "기억의 방을 2개로 쪼개다"
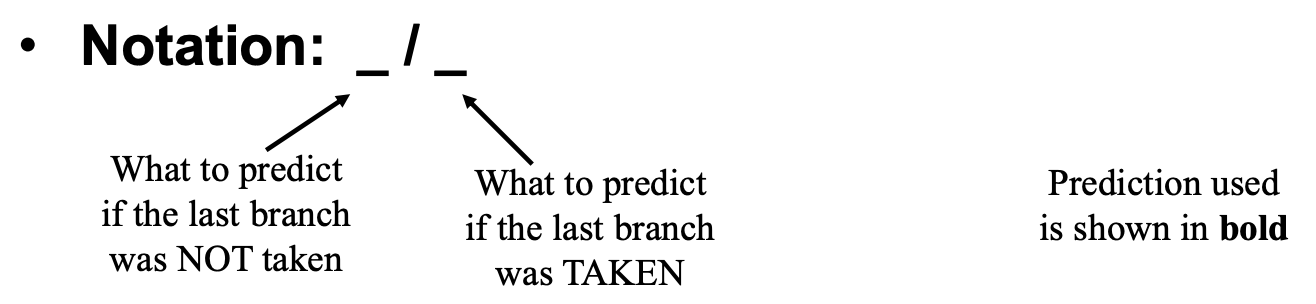
이 예측기는 앞선 로컬 예측기처럼 무식하게 과거 하나만 기억하지 않습니다. "내 직전 분기문이 뛰었는가, 안 뛰었는가"에 따라 참조하는 기억의 방이 다릅니다.
왼쪽 / 오른쪽 표기법의 의미:
- 왼쪽 자리: "내 직전 분기문이 안 뛰었을 때(NT)" 꺼내 볼 예측값.
- 오른쪽 자리: "내 직전 분기문이 뛰었을 때(T)" 꺼내 볼 예측값.
굵은 글씨 (Bold): 하드웨어가 직전 상황을 보고 실제로 선택한 예측값입니다.
2. 타임라인 분석: 패턴을 분리해 내는 과정
b1과 b2는 코드상에서 서로 다른 줄에 위치한, 메모리 주소(PC)가 완전히 다른 명령어입니다.
하드웨어 예측기 내부에는 수천 개의 방(Entry)이 있고, PC 주소를 인덱스로 삼아 찾아갑니다. 따라서 b1 전용 장부와 b2 전용 장부는 아예 다른 칸에 따로 존재합니다.
초기 상태에서 b1의 장부도 NT/NT, b2의 장부도 NT/NT로 각각 세팅되어 시작합니다.
표를 위에서부터 한 줄씩 따라가며, 하드웨어가 어떻게 패턴을 파악하는지 보겠습니다. (최초 시작 전 과거 기록은 NT였다고 가정합니다.)
첫 번째 줄 (d=2): 예열 및 학습 (유일하게 틀리는 구간)
-
b1: 직전이 NT였으므로 왼쪽 방을 엽니다. NT/NT에서 왼쪽인 NT를 예측합니다. 하지만 실제는 T입니다. (예측 실패). 방금 열어본 왼쪽 방을 T로 고쳐 씁니다. ➔ New: T/NT
-
b2: 자, 방금 전 b1이 T였습니다! 그래서 b2는 오른쪽 방을 엽니다. NT/NT에서 오른쪽인 NT를 예측합니다. 하지만 실제는 T입니다. (예측 실패). 방금 열어본 오른쪽 방을 T로 고쳐 씁니다. ➔ New: NT/T
두 번째 줄 (d=0): 마법의 시작
-
b1: 방금 전(첫 번째 줄의 b2)이 T였습니다. 그래서 b1은 오른쪽 방을 엽니다. 아까 고쳐진 T/NT에서 오른쪽인 NT를 예측합니다. 실제 값도 NT입니다. (예측 적중!) 방 크기(값)는 변함없이 T/NT 유지.
-
b2: 방금 전 b1이 NT였습니다. b2는 왼쪽 방을 엽니다. NT/T에서 왼쪽인 NT를 예측합니다. 실제 값도 NT입니다. (예측 적중!)
세 번째 줄 (d=2): 완벽한 적응
-
b1: 방금 전(두 번째 줄의 b2)이 NT였습니다. b1은 왼쪽 방을 엽니다. T/NT에서 왼쪽인 T를 예측합니다. 실제 값도 T입니다. (예측 적중!)
-
b2: 방금 전 b1이 T였습니다. b2는 오른쪽 방을 엽니다. NT/T에서 오른쪽인 T를 예측합니다. 실제 값도 T입니다. (예측 적중!)
Only misprediction on the first iteration when d=2
헷갈리는 부분
완전히 별개인 부품: 예측 카운터 테이블 (SRAM)
-
제가 앞서 "별개"라고 말씀드린 부분은 예측값(00, 01, 10, 11)이 적혀 있는 물리적인 메모리 공간입니다.
-
b1 전용 방 2개와 b2 전용 방 2개는 칩 내부에서 아예 번지수가 다른 별개의 공간입니다.
-
b1이 100번 틀려서 자기 방의 값을 00에서 11로 바꾼다고 한들, b2의 방 안의 값은 털끝만큼도 변하지 않습니다. 이 '데이터 저장 공간'은 철저하게 독립적입니다.
영향을 미치는 부품: 글로벌 히스토리 레지스터 (GHR)
반면, b1의 결과가 b2에 영향을 미치는 매개체는 딱 하나뿐인 공용 레지스터(GHR, Global History Register)입니다.
-
이 레지스터는 파이프라인 전체가 공유하는 '1비트짜리 공용 게시판'입니다.
-
b1이 실행을 마치면, 자기 전용 방(카운터)의 값을 업데이트하는 것과는 별개로, 공용 게시판에 "나 방금 진짜로 뛰었다(T)" 또는 "안 뛰었다(NT)"라는 1비트짜리 발자취를 남기고 떠납니다.
-
그 직후 b2가 실행될 때, b2는 자기 전용 방을 열기 전에 이 공용 게시판을 먼저 쳐다봅니다. 그리고 "아, 방금 앞 명령어(b1)가 T였네? 그럼 나는 내 독립적인 2개의 방 중에서 오른쪽 방을 열어야겠다"라고 결정하게 됩니다.
b2 prediction
3단계: 방을 열고 값 읽기 (최종 예측)
- 직전 행동이 NT였으므로, 하드웨어는 b2의 장부 00/00 중에서 왼쪽 방을 엽니다.
- 왼쪽 방 안에 적혀있는 값이 00입니다.
- 카운터 규칙상 00은 '강한 NT(Strongly Not Taken)'를 의미합니다.
따라서 하드웨어는 파이프라인에 "이번 b2는 NT일 것이다!"라고 최종 예측 결과를 던져줍니다.
결론적으로 하드웨어는 복잡한 계산을 하는 것이 아니라, "이전 사이클에서 내 방 안에 적어둔 2비트 숫자"를 찾아 읽어오는 것뿐입니다. 그 숫자가 00이나 01이면 NT로 예측하고, 10이나 11이면 T로 예측하는 아주 기계적이고 단순한 방식입니다.
3. 결론: 왜 100% 맞출 수 있는가?
로컬 예측기가 실패했던 이유는 d=2 상황(무조건 뜀)과 d=0 상황(무조건 안 뜀)이 하나의 기억 공간을 서로 덮어쓰며 싸웠기 때문입니다.
하지만 상관 예측기는 "직전 결과"라는 문맥을 이용해 기억의 방을 아예 2개로 분리해 버렸습니다.
- 직전에 NT였다면? ➔ "아하, 방금 d=0 패턴이 끝났구나. 그럼 이번엔 d=2 차례니까 무조건 뛰어야지!" (왼쪽 방에 T 저장)
- 직전에 T였다면? ➔ "방금 d=2 패턴이 끝났네. 그럼 이번엔 d=0 차례니까 무조건 안 뛰어야지!" (오른쪽 방에 NT 저장)
결과적으로 "Only misprediction on the first iteration when d=2"라는 슬라이드 하단의 말처럼, 하드웨어가 이 두 개의 방을 처음 세팅할 때(첫 번째 줄)만 틀리고, 그 이후로는 널뛰기 패턴에 완벽하게 동기화되어 예측 실패율을 0%로 만들어 냅니다.
왼쪽것만 업데이트, 사용하는 것만 업데이트
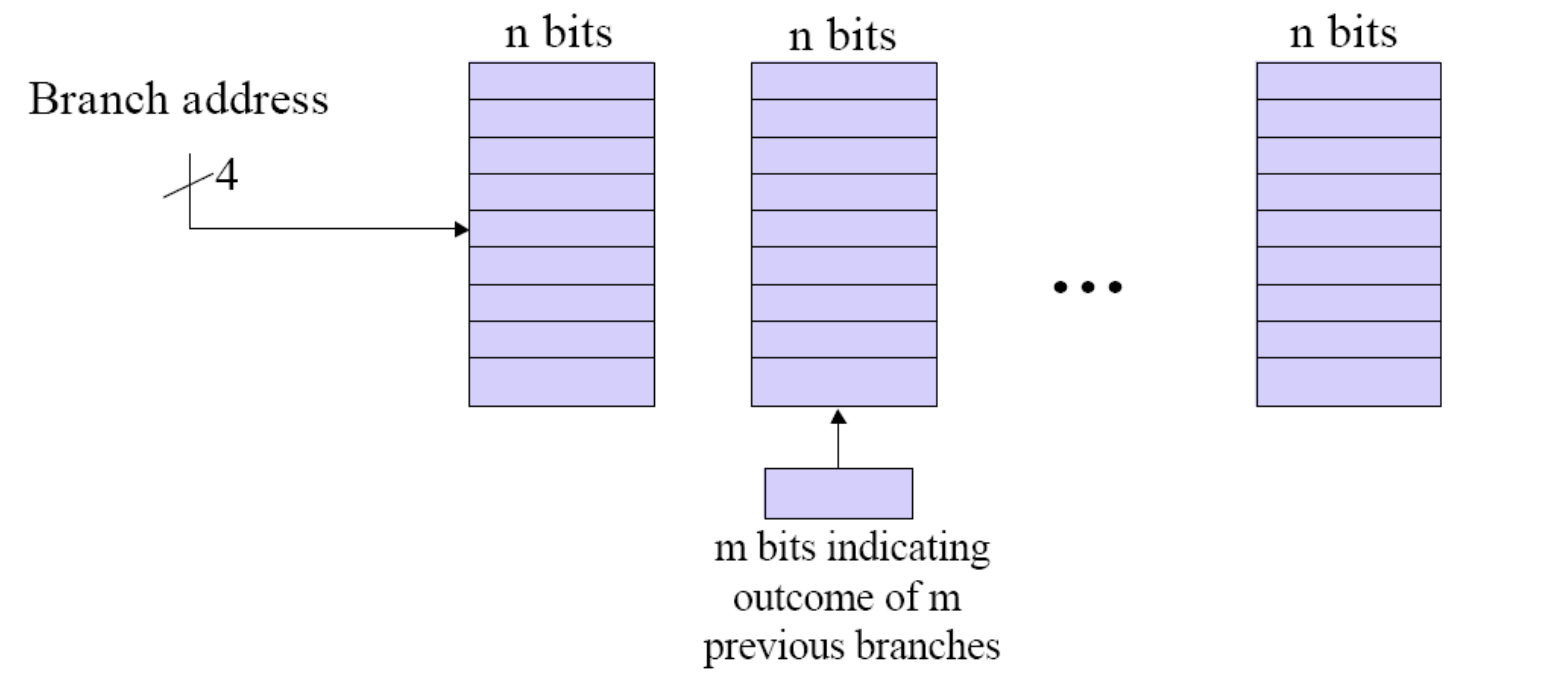
(m,n) correlated predictors
-
Uses the behavior of the most recent m branches encountered to select one of 2m different branch predictors for the next branch.
-
Each of these predictors records n bits of history
information for any given branch → n-bit predictor -
On previous slide we saw a (1,1) predictor.
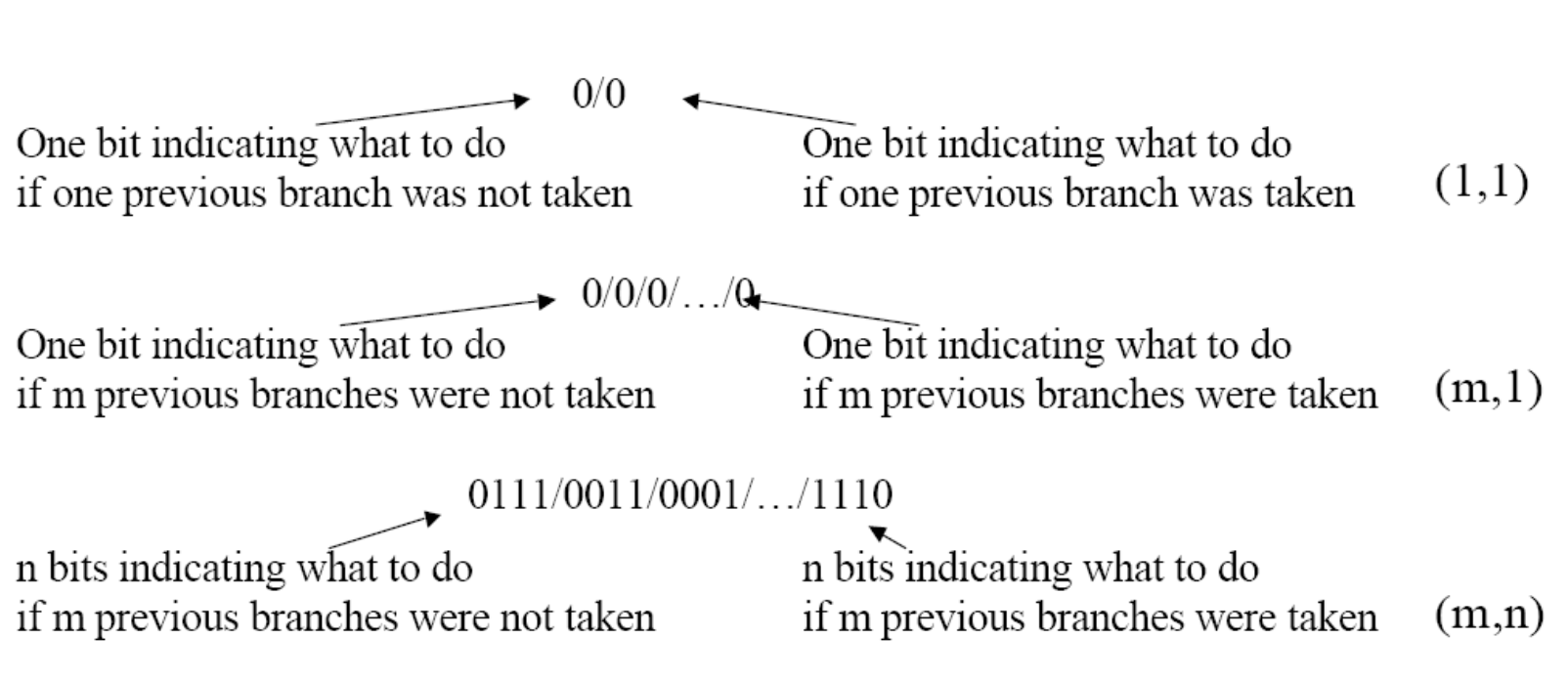
seungyun, 이 슬라이드는 방금 전까지 우리가 분석했던 '상관 예측기'의 구조를 하드웨어 설계자들의 공식적인 수학적 표기법인 (m, n) 형태로 일반화하여 정리해 주는 내용입니다.
방금 전 슬라이드에서 제가 "기억의 방을 쪼갠다"고 표현했던 것 기억하십니까? m과 n이 바로 그 방의 개수와 방 안의 내용물을 결정하는 설계 파라미터입니다.
1. m의 의미: 과거를 얼마나 멀리 볼 것인가? (Global History)
- m은 "내 앞에 실행된 분기문을 몇 개까지 기억할 것인가"를 나타냅니다.
- 만약 m=2라면, 내 직전에 실행된 2개의 분기 결과(예: 뛰었고, 안 뛰었다 ➔ 10)를 봅니다.
- 경우의 수가 2의 m제곱 개가 나오므로, 하드웨어는 총 2^m 개의 서로 다른 예측기(기억의 방)를 준비해야 합니다. 앞서 m=1일 때는 방이 2개(왼쪽/오른쪽)였지만, m=2가 되면 방이 4개로 늘어납니다.
2. n의 의미: 각 방 안에는 어떤 예측기를 둘 것인가? (Predictor Type)
- n은 그 쪼개진 방 하나하나에 들어가는 예측기 카운터의 비트 수를 의미합니다.
- n=1이면 방금 전 보셨던 것처럼 그냥 0(NT) 아니면 1(T)만 저장하는 극단적인 1비트 예측기가 들어갑니다.
- n=2라면 우리가 이전에 배웠던 'Strong/Weak' 4가지 상태를 가지는 2비트 포화 카운터(2-bit Saturating Counter)가 각 방마다 하나씩 들어갑니다.
3. 이미지의 3가지 케이스 해독
이미지에 그려진 수식과 텍스트가 의미하는 바는 다음과 같습니다.
- 맨 윗줄 (1, 1): 직전 분기문 1개를 보고(방 2개), 각 방에는 1비트 예측기를 둔다. (우리가 방금 전 슬라이드에서 널뛰기 패턴을 100% 적중시켰던 바로 그 예측기입니다.)
- 중간 줄 (m, 1): 직전 분기문을 m개 보고 (방이 2^m 개로 늘어남), 각 방에는 여전히 단순한 1비트 예측기를 둔다.
- 맨 아랫줄 (m, n): 직전 분기문을 m개 보고, 각 방에는 n비트(주로 2비트) 예측기를 둔다.
- 그림의 0111/0011/... 부분이 바로 n비트 카운터의 값들이 여러 방에 나열되어 있는 모습을 그린 것입니다.
4. 하드웨어 구현의 용이성 (Easy to implement)
상관 예측기가 논리적으로는 복잡해 보여도, 실제 회로로 만들기는 아주 쉽고 우아합니다.
m-bit shift register (글로벌 히스토리 레지스터, GHR):
- 직전 개 분기문의 결과를 기억하는 장치는 그저 단순한 시프트 레지스터(Shift Register) 하나면 끝납니다.
- 점프하면 1, 안 뛰면 0을 레지스터 한쪽 끝으로 밀어 넣고(Shift), 가장 오래된 값은 버립니다.
Concatenated Indexing (주소 결합 매핑):
- 수많은 분기문 중에서 "지금 실행할 분기문"의 고유한 예측기 방(Entry)을 찾아가야 합니다.
- 이때, 현재 분기문의 메모리 주소(PC) 하위 비트와 방금 전 만든 비트 시프트 레지스터 값을 그냥 직렬로 이어 붙여서(Concatenate) 하나의 긴 메모리 인덱스(주소)를 만듭니다.
- 효과: 이렇게 하면 "특정 분기문 주소"이면서 동시에 "특정 과거 문맥"일 때만 찾아가는 완벽하게 독립적인 고유 방 번호가 생성됩니다.
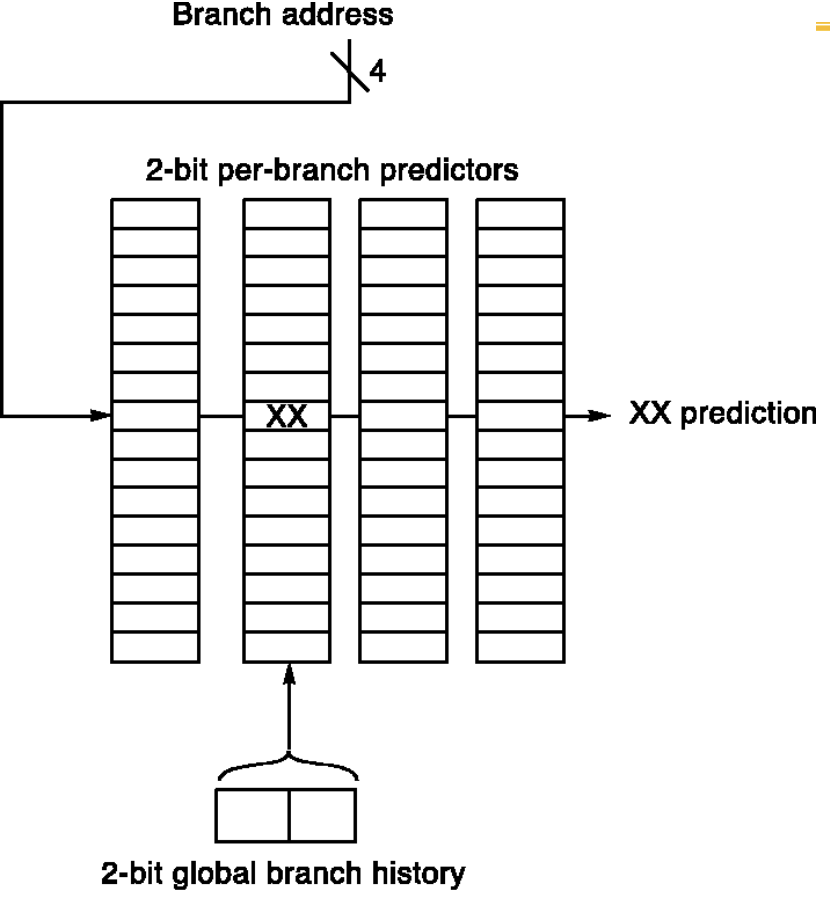
결론적으로 현대 하드웨어 아키텍처에서 (2, 2) 상관 예측기라고 하면, "직전 2개의 글로벌 문맥(Global History)을 읽어 4개의 방 중 하나를 고르고, 그 방 안에는 2비트 상태 머신이 들어있는 구조"를 뜻합니다. 이렇게 하면 로컬 예측의 패턴 한계와 1비트 예측의 가벼움을 동시에 극복할 수 있습니다.
5. 메모리 용량 계산 공식 (How many bits do we need?)
하드웨어 설계자에게 가장 중요한 것은 "그래서 이 예측기를 넣으려면 칩 면적을 얼마나 차지하는가?"입니다. 슬라이드의 공식 는 전체 비트 수를 구하는 식입니다.
각 항의 의미를 쪼개어 보겠습니다.
- : PC 주소의 하위 비트를 사용하여 구별할 수 있는 분기문의 개수 (행의 개수).
- : 각각의 분기문마다 존재하는 글로벌 히스토리(비트)의 경우의 수 (열의 개수, 즉 '방'의 개수).
- : 그 방 하나하나에 들어가는 예측기 카운터의 크기 (예: 2-bit 카운터면 ).
결론 (수식의 통합):
행의 수()와 열의 수()를 곱하면 전체 방의 개수가 나옵니다. 즉, 인덱스의 총길이는 비트가 되므로 전체 엔트리 수는 개가 됩니다. 여기에 방 하나당 용량인 을 곱한 것이 최종 공식인 (또는 ) 비트가 되는 것입니다.
