Dynamic Branch Prediction
-
Local Branch prediction:
use own history -
Global Branch prediction:
determined by other instruction
use someone else history
(동적 분기 예측의 필요성)
파이프라인이 왜 과거의 기록을 '학습'해야만 하는지 그 배경을 설명합니다.
-
ILP와 Control Stall의 역설: 명령어 수준 병렬성(ILP)을 높게 설계할수록 파이프라인은 한 번에 더 많은 명령어를 처리합니다(CPI 감소). 하지만 이럴수록 분기문에서 멈칫하는 시간(Control stall)의 타격이 기하급수적으로 커집니다. 예측이 틀리면 파이프라인에 미리 가득 채워둔 수많은 명령어(n-cycle 딜레이 분량)를 한꺼번에 다 버려야(Flush) 하기 때문입니다.
-
동적 하드웨어 예측: 프로그래머나 컴파일러가 미리 정해두는 것이 아니라, 칩 내부의 하드웨어가 실시간으로 프로그램이 실행되는 패턴을 "학습"합니다.
-
목표: 대부분의 경우 올바른 예측(Taken으로 뛸지, Not Taken으로 안 뛸지)을 해내어 지연 시간을 없애는 것입니다. 프로세서의 성능 하락은 이 예측이 얼마나 자주 틀리느냐(Misprediction rate)에 전적으로 달려 있습니다.
Local Prediction: Branch-Prediction Buffers (BPB)
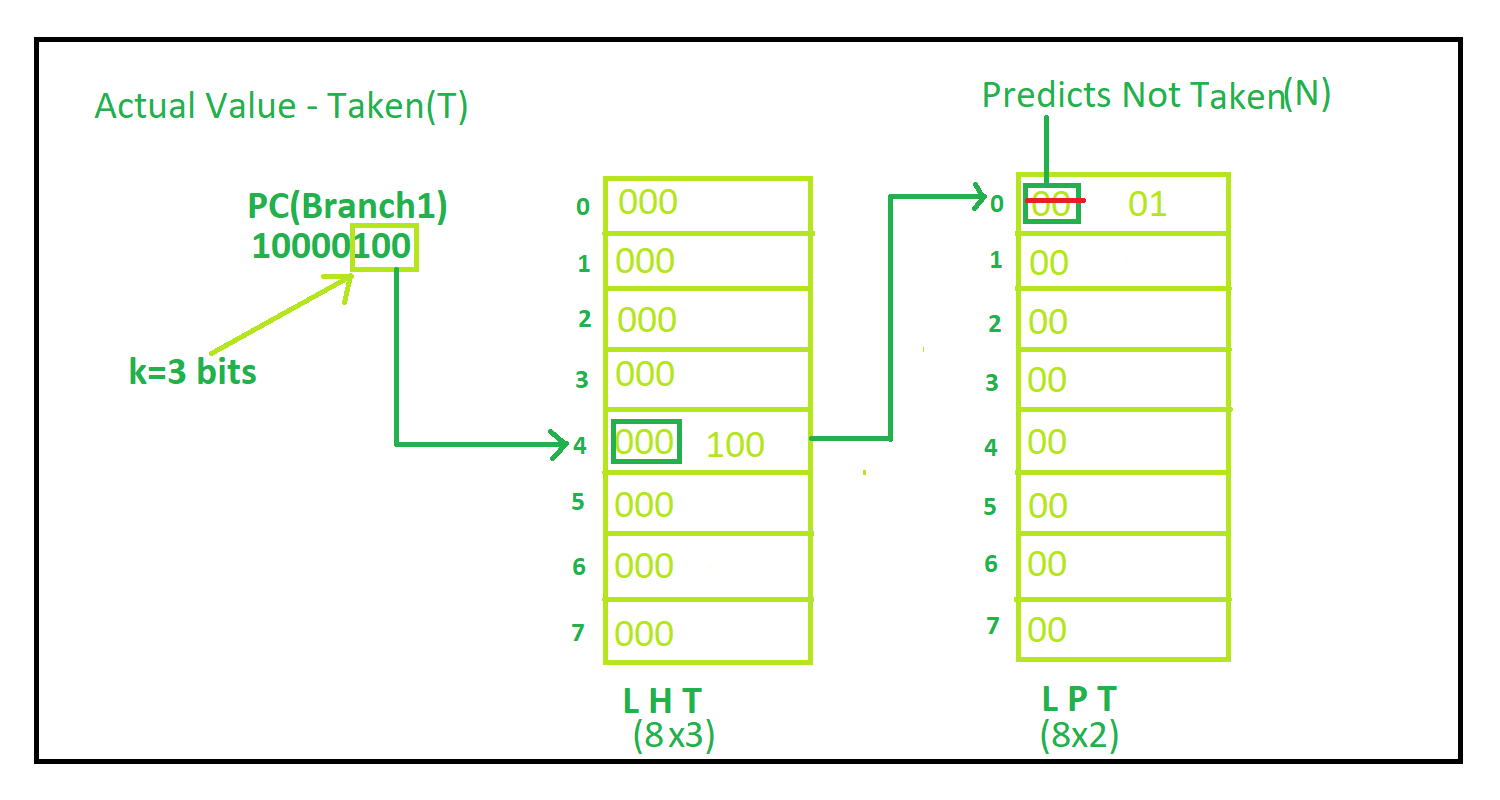
Local Prediction: Branch-Prediction Buffers (BPB)
하드웨어가 이 "과거 기록"을 물리적으로 어디에, 어떻게 저장하는지에 대한 구조입니다. 현업에서는 BHT (Branch History Table)라고 더 자주 부릅니다.
하위 n비트 인덱싱 (Low-order n bits): 수만 개의 분기문 주소(PC, Program Counter)를 모두 하드웨어 표에 담을 수는 없습니다. 캐시 메모리와 비슷한 원리로, 분기문 주소의 하위 n비트만 잘라내어 이 표(Table)의 주소(Index)로 사용합니다.
해시 충돌 (Collisions): 하위 비트만 잘라서 쓰다 보니, 메모리상에서 완전히 멀리 떨어져 있는(distant) 두 개의 다른 분기문이 우연히 뒷자리 하위 비트가 같아서 표의 같은 칸을 공유하게 되는 현상이 발생합니다. 이로 인해 남의 기록을 보고 잘못된 예측을 하는 충돌(Aliasing)이 필연적으로 일어납니다.
k비트의 역사 (k bits of history): 표의 각 칸(Entry)에는 k비트 크기의 과거 실행 결과가 저장됩니다. 설계 비용 문제로 보통 k=1 (1비트) 또는 k=2 (2비트)를 사용합니다.
예측과 업데이트: 명령어가 Fetch 될 때 이 칸을 읽어 다음 행동을 예측(Predict)하고, 나중에 해당 분기문의 실제 실행 결과가 확정되면 그 결과를 다시 표에 덮어써서 업데이트(Update)합니다.
1-bit Branch Prediction
이 예측기의 상태는 단 2개뿐입니다. 과거의 복잡한 패턴은 무시하고 오직 "바로 직전에 했던 행동"만 맹신합니다.
- Bit 1: "방금 점프(Taken)했으니, 다음번에도 무조건 점프할 것이다."
- Bit 0: "방금 안 뛰었으니(Not Taken), 다음번에도 무조건 안 뛸 것이다."
1-bit Branch Prediction
Will make 2 mistakes each time a loop is encountered.
– At the end of the first & last iterations
LD R1, #5
Loop: LD R2, 0(R5)
ADD R2, R2, R4
STORE R2, 0(R5)
ADD R5, R5, #4
SUB R1, R1, #1
BNEZ R1, Loop어셈블리 코드와 루프 분석
제공된 MIPS 어셈블리 코드는 배열의 요소를 더하는 전형적인 for 루프입니다.
- LD R1, #5: 루프 카운터 R1을 5로 초기화합니다. 즉, 이 루프는 총 5번 돕니다.
- SUB R1, R1, #1: 루프를 한 번 돌 때마다 R1을 1씩 뺍니다.
- BNEZ R1, Loop: R1이 0이 아니면(Not Equal to Zero) Loop 라벨로 점프(Taken)합니다.
분기문의 실제 행동: 총 5번의 평가 중, 처음 4번은 점프(Taken)하고, 마지막 5번째는 R1=0이 되므로 탈출(Not Taken)합니다.
왜 항상 2번 틀리는가? (The 2 Mistakes)
이전에 이 루프 코드를 한 번 다 돌고 빠져나갔던 상태라고 가정해 봅시다. 루프를 빠져나갈 때 "안 뛰었으므로(Not Taken)", 예측기는 현재 0으로 세팅되어 있습니다. 다시 이 코드를 만났을 때의 타임라인입니다.
Time 1 (첫 번째 진입 - 실수 1):
- 하드웨어 예측: 0 (아까 이 루프 끝날 때 안 뛰었으니까 이번에도 안 뛸 거야)
실제 결과: 1 (R1이 4이므로 루프를 돌아야 함, Taken)
판정: 예측 실패 (Miss). 하드웨어는 파이프라인을 플러시(Flush)하고 예측기를 1로 업데이트합니다.
Time 2, 3, 4 (중간 반복 - 적중):
하드웨어 예측: 1 (방금 뛰었으니까 계속 뛸 거야)
실제 결과: 1 (계속 루프를 돎, Taken)
판정: 적중 (Hit). 파이프라인이 지연 없이 매끄럽게 돌아갑니다.
Time 5 (마지막 탈출 - 실수 2):
하드웨어 예측: 1 (방금까지 계속 뛰었으니까 이번에도 뛸 거야)
실제 결과: 0 (R1이 0이 되어 루프를 탈출해야 함, Not Taken)
판정: 예측 실패 (Miss). 파이프라인을 플러시하고 예측기를 다시 0으로 업데이트합니다
misprediction Rate
$
2-bit Branch Prediction
이 Finite machine 그리는거 매우 중요
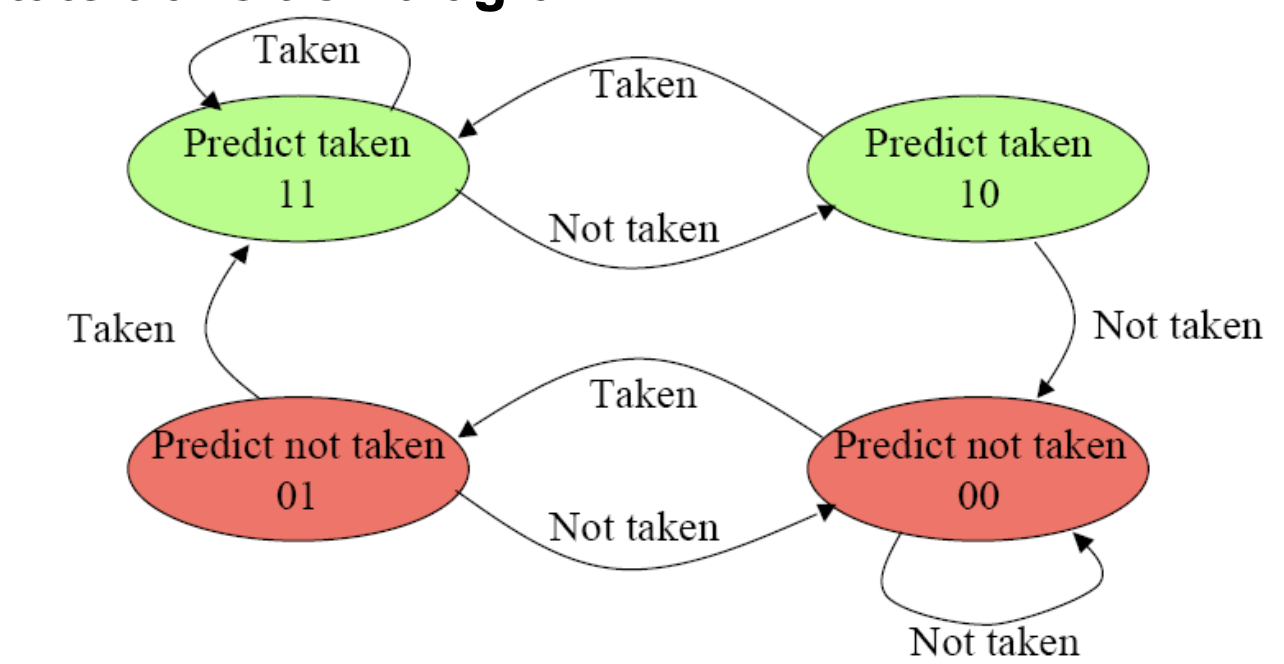
이 슬라이드는 앞서 살펴본 1비트 예측기의 치명적 단점인 "한 번 틀렸다고 바로 태세를 전환해버리는 가벼움"을 해결하기 위해 하드웨어에 '확신(Confidence)'이라는 개념을 부여한 2비트 분기 예측기(2-bit Branch Predictor)의 상태 머신(State Machine) 구조를 보여줍니다.
4가지 상태 (4 States)
1비트가 0과 1 두 가지 상태만 가졌다면, 2비트 예측기는 총 4가지 상태를 가집니다. 예측 방향(Taken/Not taken)은 같더라도, 그 예측에 대한 확신의 강도가 다릅니다.
-
11 (Strongly Taken): "강한 점프 예측". 최근에 계속 점프했으므로, 다음에도 확실히 점프할 것이다. (초록색)
-
10 (Weakly Taken): "약한 점프 예측". 방금 한 번 안 뛰긴 했지만, 그래도 예전 기록을 믿고 점프한다고 예측해 보겠다. (초록색)
-
01 (Weakly Not Taken): "약한 미점프 예측". 방금 한 번 뛰긴 했지만, 그래도 예전 기록을 믿고 안 뛴다고 예측해 보겠다. (빨간색)
-
00 (Strongly Not Taken): "강한 미점프 예측". 최근에 계속 안 뛰었으므로, 다음에도 확실히 안 뛸 것이다. (빨간색)
핵심 원리: Must miss twice before changing the prediction
이 예측기의 존재 이유이자 가장 중요한 문장입니다. "연속으로 두 번 틀려야만 예측 방향(초록색 ↔ 빨간색)을 바꾼다"는 뜻입니다.
- 예를 들어, 현재 상태가 11(강한 점프 예측)이라고 가정해 보겠습니다.
- 이번에 분기문에서 점프를 하지 않았습니다(Not taken). 예측 실패(Miss)입니다.
- 1비트 예측기였다면 곧바로 상태를 0으로 뒤집었겠지만, 2비트 예측기는 다이어그램의 화살표를 따라 10(약한 점프 예측)으로 이동합니다.
- 결과: 예측은 한 번 틀렸지만, 하드웨어는 여전히 다음번 예측을 Taken(초록색)으로 유지합니다. 이것을 한 번의 '실수'나 '예외'로 눈감아 주는 것입니다.
현실 적용: 1비트 예측기의 루프 문제 해결
앞서 질문하셨던 for 루프 예시에서, 1비트 예측기는 루프를 들어갈 때와 나갈 때 무조건 2번 틀렸습니다. 2비트 예측기가 이 문제를 어떻게 1번으로 줄이는지 타임라인을 따라가 보겠습니다. (현재 루프를 한참 돌고 있어서 상태가 11이라고 가정합니다.)
루프 탈출 (마지막 반복):
예측: Taken (11)
실제: Not Taken (루프 종료)
결과: 예측 실패 (Miss). 상태는 11 10으로 하락합니다.
시간이 흘러 다시 해당 루프에 첫 진입할 때:
예측: Taken (10이므로 여전히 초록색)
실제: Taken (루프 시작이므로 뜀)
결과: 예측 적중 (Hit!). 상태는 다시 10 11로 회복됩니다.
결론적으로, 2비트 분기 예측기는 루프를 탈출할 때 발생하는 단 한 번의 예측 실패를 '일시적인 현상'으로 취급하여 흡수(Hysteresis)합니다. 그 결과, 다음번 루프 진입 시 발생하는 억울한 예측 실패를 막아내어 루프당 패널티를 2회에서 1회로 극적으로 줄여줍니다.
LD R1, #5
Loop: LD R2, 0(R5)
ADD R2, R2, R4
STORE R2, 0(R5)
ADD R5, R5, #4
SUB R1, R1, #1
BNEZ R1, Loop첫 번째 루프 실행: 학습 과정 (Warm-up Phase)
하드웨어가 이 코드를 태어나서 처음 보았고, 예측기가 00 (Strongly Not Taken, 강한 미점프) 상태로 초기화되어 있다고 가정합니다. 실제 분기 결과는 5번의 반복 동안 Taken, Taken, Taken, Taken, Not Taken 순서로 발생합니다.
Time 1 (1회 차):
예측: 00 (Not Taken)
실제: Taken
결과: Miss (예측 실패). 하드웨어는 상태를 00 01 (Weakly Not Taken)로 올립니다. 아직은 뛸 것이라는 확신이 부족합니다.
Time 2 (2회 차):
예측: 01 (Not Taken)
실제: Taken
결과: Miss (예측 실패). 두 번 연속으로 틀렸으므로, 하드웨어는 드디어 임계점을 넘어 상태를 01 11 (Strongly Taken)로 확 바꿉니다. 이제 패턴을 파악했습니다.
Time 3, 4 (3, 4회 차):
예측: 11 (Taken)
실제: Taken
결과: Hit (예측 적중). 상태는 계속 11을 유지하며 파이프라인이 매끄럽게 돌아갑니다.
Time 5 (5회 차 - 루프 종료):
예측: 11 (Taken)
실제: Not Taken (루프 탈출)
결과: Miss (예측 실패). 예측이 틀렸지만, 상태는 11 10 (Weakly Taken)으로 단 한 계단만 떨어집니다.
중간 결론: 루프를 "처음" 실행할 때는 하드웨어가 예열(Warm-up)하느라 Time 1, Time 2, Time 5에서 총 3번이나 틀렸습니다.
핵심: 두 번째 루프 실행부터 (After the first time)
슬라이드의 가장 위쪽 제목인 "Only 1 mis-prediction per loop execution, after the first time"이 의미하는 바가 여기서 드러납니다.
프로그램이 계속 실행되다가 나중에 이 for 루프 코드를 다시 호출했다고 가정해 보겠습니다.
-
초기 상태의 변화: 방금 전 Time 5에서 루프를 탈출할 때 예측기 상태가 00으로 돌아가지 않고 10 (Weakly Taken)에 머물러 있었습니다. 하드웨어는 "방금 한 번 안 뛰긴 했지만, 원래 여기는 반복문이라 뛰는 자리였어"라는 과거의 기억(History)을 유지하고 있는 것입니다.
-
두 번째 루프의 Time 1 (첫 진입):
예측: 10 (Taken - 여전히 초록색 상태)
실제: Taken
결과: Hit (예측 적중!). 상태는 10 11로 다시 강력해집니다.
Branch-Prediction Performance
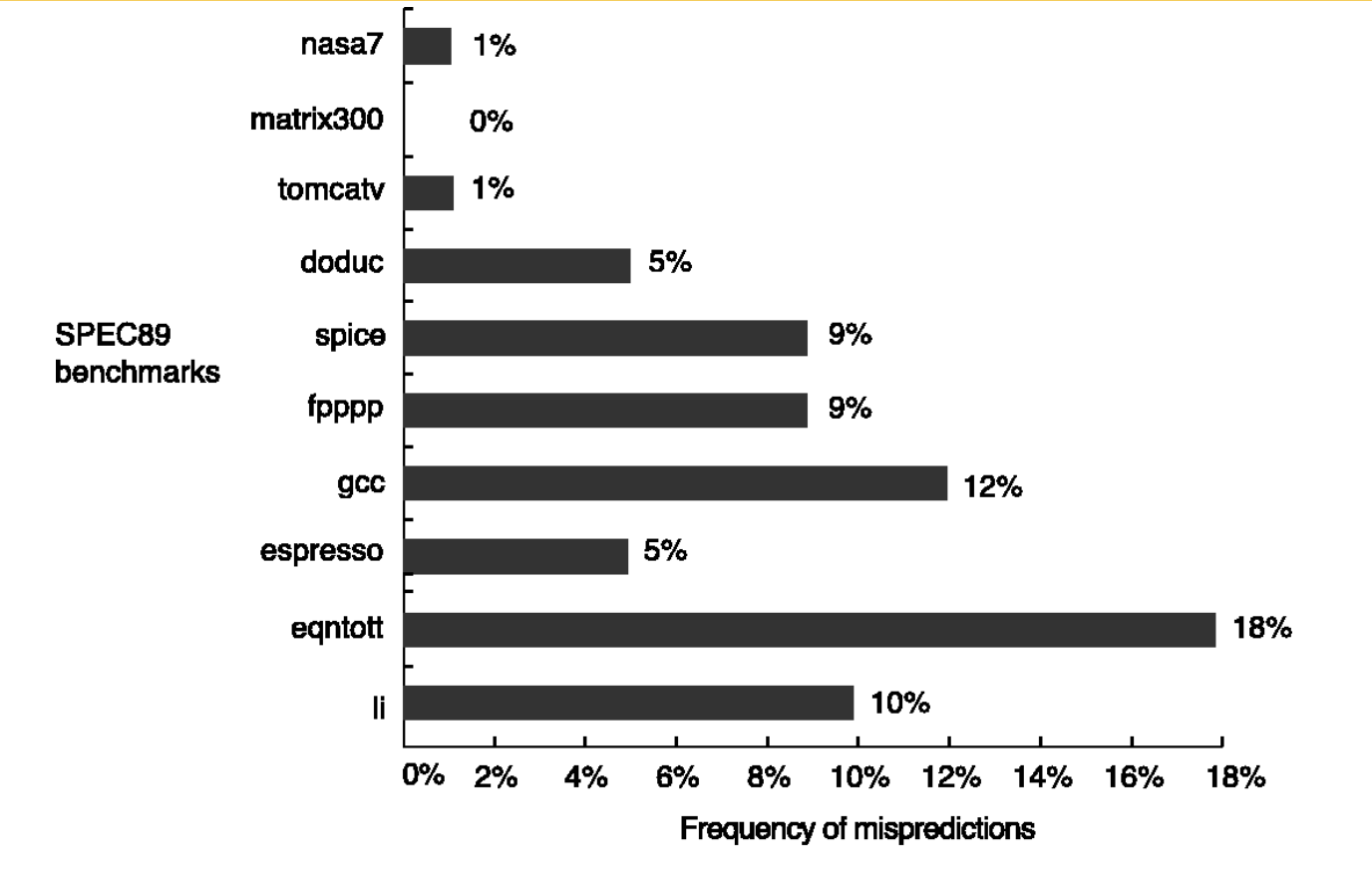
분기 예측 정확도의 중요성 (Branch-Prediction Performance)
"BPB Misprediction rate from 1% ~ 18% for SPEC89"
SPEC89라는 표준 벤치마크 프로그램을 돌려본 결과, 분기 예측 실패율이 1%에서 최대 18%까지 나왔다는 뜻입니다.
현실적인 관점에서 보면 "성공률이 82~99%면 꽤 높은 것 아닌가?"라고 생각할 수 있습니다. 하지만 현대의 깊은 파이프라인(Deep Pipeline) 구조에서는 단 5%의 예측 실패율만으로도 전체 프로세서 성능의 20~30%가 증발할 수 있습니다. 따라서 이 실패율을 1%라도 더 깎아내는 것이 아키텍처 설계의 핵심 과제입니다.
예측 실패율을 줄이기 위한 2가지 물리적/논리적 접근
예측을 잘하려면 하드웨어를 어떻게 늘려야 할지에 대한 두 가지 방향성입니다. 결론부터 말씀드리면, 단순히 크기만 키우는 무식한 방법은 한계에 부딪힌다는 것을 증명하고 있습니다.
A. 버퍼 크기 증가 (Increase buffer size)
-
목적: 테이블의 칸(Entry) 수를 늘려서, 서로 다른 분기문이 같은 칸을 공유하게 되는 해시 충돌(Collision / Aliasing)을 막기 위함입니다.
-
현실적 한계 ("Has little effect beyond ~4,096 entries"):
- 테이블 크기를 4K(4,096) 칸 이상으로 무작정 늘려봤자 예측 정확도는 더 이상 올라가지 않습니다.
- 이유는 충돌이 없더라도, 분기문 자체의 패턴이 너무 불규칙해서 2비트 상태 머신 따위로는 애초에 예측할 수 없는 알고리즘 본연의 한계(Capacity Miss가 아닌 Compulsory/Conflict 본연의 한계)에 도달했기 때문입니다.
B. 예측 정확도 자체의 향상 (Increase prediction accuracy)
1) 칸당 비트 수 증가 ("Increase # of bits/entry"):
-
2비트 예측기 대신 3비트, 4비트를 써서 상태를 8개, 16개로 잘게 쪼개어 '확신'의 단계를 세밀하게 만들어보려는 시도입니다.
-
현실적 한계 ("little effect beyond 2"): 2비트에서 3비트로 넘어가도 성능 향상은 거의 없습니다. 쓸데없이 칩 면적(Area)과 전력만 낭비하게 되므로, 하드웨어 설계에서 기본 예측기는 2-bit Counter가 가성비의 정답(Sweet spot)으로 굳어졌습니다.
2) 완전히 다른 예측 기법 도입 ("Use a different prediction scheme"):
-
크기를 키우는 것으로는 한계가 명확하므로, 과거를 기억하는 방식(Scheme) 자체를 뜯어고쳐야 한다는 결론입니다.
-
Correlated Predictors (상관 예측기): 해당 분기문 하나만의 과거만 보는 것이 아니라, "내 앞에 실행되었던 다른 분기문들이 점프를 했는가?"라는 주변 문맥(Global History)을 함께 고려하는 방식입니다. (예: if (a==2)와 if (a!=2)는 서로 연관되어 있음을 하드웨어가 파악함)
-
Tournament Predictors (토너먼트 예측기): Local 방식과 Global 방식의 예측기를 둘 다 만들어두고, "현재 분기문은 어떤 예측기의 말을 듣는 게 더 정확한가?"를 판단하는 또 다른 예측기(Meta-predictor)를 두어 최적의 결과를 선택하는 방식입니다.
n-bit Branch Prediction
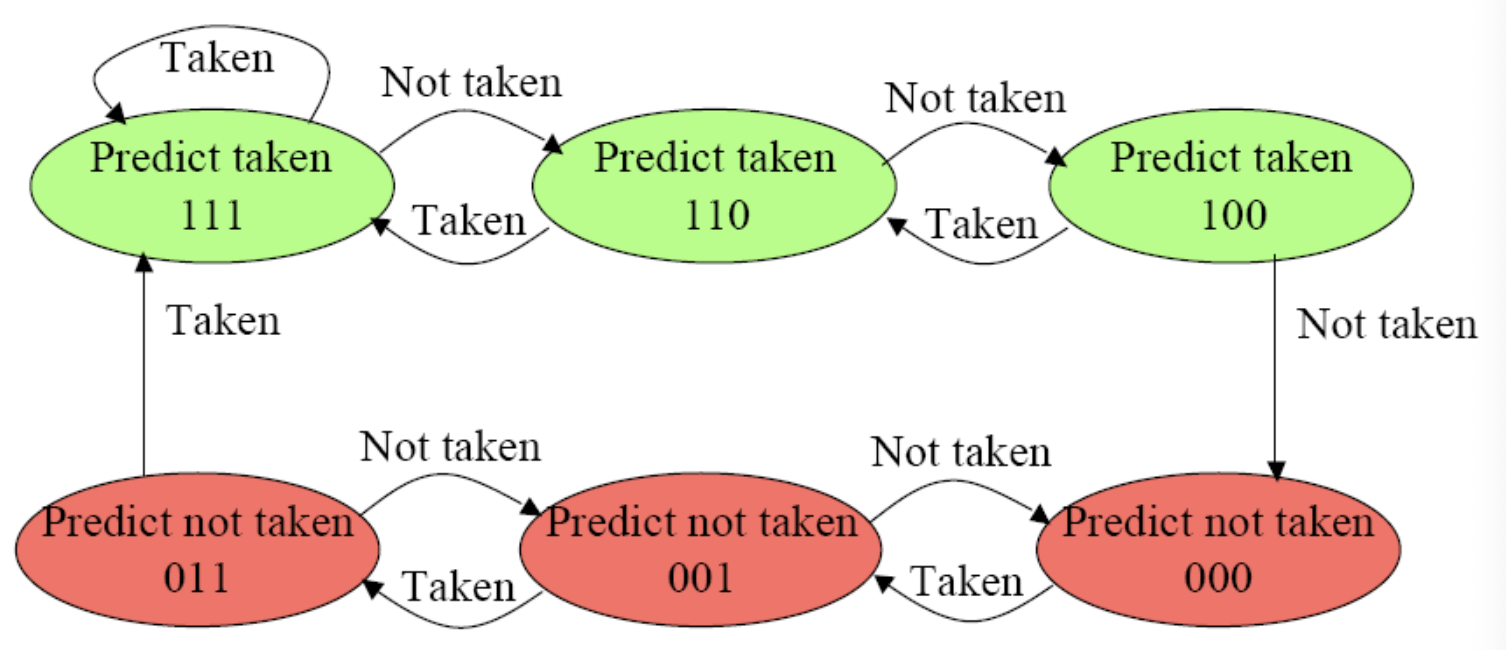
n비트 확장과 예측 기준 ()
하드웨어가 n비트 카운터를 사용할 때, '점프할 것인가(Taken)'를 결정하는 기준선을 수학적으로 정의한 것입니다.
- n비트 카운터가 표현할 수 있는 값의 범위는 0부터 까지입니다.
- 하드웨어는 이 범위의 정확히 절반인 중간값, 즉 을 임계점(Threshold)으로 설정합니다.
- 예시 (3-bit 예측기의 경우):
카운터는 0부터 7까지 총 8개의 상태를 가집니다.
기준값은 가 됩니다.
카운터 값이 4, 5, 6, 7이면 Taken (점프) 예측
카운터 값이 0, 1, 2, 3이면 Not Taken (미점프) 예측
결국 숫자가 높을수록 뛰겠다는 '확신의 강도'가 높다는 뜻이며, 1을 더하고 빼는 포화 카운터(Saturating Counter) 방식으로 작동합니다.
가혹한 현실: 별로 안 정확하다 (Not much more accurate)
이전 슬라이드의 결론과 이어지는 핵심입니다. 이론상으로는 비트가 많을수록 과거의 기억을 길게 간직하니까 더 똑똑해질 것 같지만, 실제 성능 평가를 돌려보면 2비트 예측기와 비교해서 정확도 상승이 거의 없습니다. 그 현실적인 이유는 두 가지입니다.
느려터진 웜업(Warm-up) 시간: 만약 4비트 카운터가 0 (가장 강력한 Not Taken) 상태에 있다고 가정해 보겠습니다. 프로그램의 패턴이 바뀌어서 이제부터 계속 점프(Taken)를 해야 하는 상황이 와도, 하드웨어가 예측을 Taken(8 이상)으로 뒤집으려면 무려 8번이나 연속으로 예측 실패(Miss) 패널티를 두들겨 맞아야 합니다. 상황 변화에 대처하는 반응 속도가 너무 둔해집니다.
알고리즘 패턴의 한계: 대부분의 일반적인 프로그램 분기문은 연속으로 3~4번씩 불규칙한 예외가 발생할 만큼 복잡하지 않습니다. 앞서 루프문에서 보셨듯, '단 한 번의 실수'만 눈감아주는 2비트 카운터만으로도 웬만한 기계적 패턴은 100% 방어가 가능합니다.
