[230630] BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
Object detection
목록 보기
5/23
Abstract
dubbed(더빙된) BEVDepth, for camera-based Bird’s-Eye-View (BEV) 3D object detection.- leveraging explicit depth supervision.
- 또한, (아래와 같은) 카메라를 고려한 깊이 추정 모듈을 도입하여 깊이 예측 능력을 향상
camera-awareness depth estimation module-> facilitate the depth predicting capability.a novel Depth Refinement Module-> counter the side effects carried by imprecise feature unprojection.- customized Efficient Voxel Pooling + multi-frame mechanism
- 코드는 https://github.com/Megvii-BaseDetection/BEVDepth
Introduction

-
LSS (https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123590188.pdf, ECCV, 300회 인용)
- They “lift” (estimating depth).
- multi-view features -> 3D frustums.
- then “splat” frustums onto a reference plane,
- usually being a plane in Bird’s-Eye-View (BEV).
- They “lift” (estimating depth).
-
그러나 LSS 기반 인식 알고리즘의 성공에도 불구하고, 이 파이프라인 내에서 학습된 depth는 거의 연구되지 않았습니다.(Fig. 1 참조).
-
감지기는 nuScenes (Caesar et al. 2020) 벤치마크에서 30 mAP를 달성하였지만, 깊이는 놀랍도록 부족합니다.
-
이 관찰을 기반으로, 기존 Lift-splat에서의 깊이 학습 메커니즘이 다음과 같은 세 가지 결함을 가져온다고 지적합니다:
부정확한 깊이- Since the depth prediction module is indirectly supervised by the final detection loss, the absolute depth quality is far from satisfying;
Depth Module Over-fitting- 대부분의 픽셀은 합리적인 깊이를 예측할 수 없으므로, 학습 단계에서 제대로 훈련되지 않습니다. 이는 깊이 모듈의 일반화 능력에 대한 의문을 품게 합니다. 즉, camera paramter을 고려한 depth 추정이 부정확하다는 뜻은, camera parameter 변화에 훨씬 취약하다는 뜻입니다.
Imprecise BEV Semantics- The learned depth in Lift-splat unprojects image features into 3D frustum features,
- which will be further pooled into BEV features.
- The learned depth in Lift-splat unprojects image features into 3D frustum features,
-
we introduce BEVDepth, a new multi-view 3D detector that leverages depth supervision derives from point clouds to guide depth learning.
-
우리는 깊이 품질이 전체 시스템에 미치는 영향을 철저히 분석한 최초의 팀.
-
동시에 we innovatively propose to
encode camera intrinsics and extrinsicsinto a depth learning module- so that the detector is robust to various camera settings.
-
In the end,
a Depth Refinement Moduleis introduced to refine the learned depth. -
Efficient Voxel Pooling+Multi-frame Fusion technique
Related Work
Vision-based 3D object detection
- 연구 중 하나는 2D 이미지 특징에서 바로 3D 바운딩 박스를 예측하는 방법입니다.
- CenterNet (Zhou, Wang, and Kra ̈henbu ̈hl 2019)와 같은 2D 검출기를 사용하여 감지 헤드에 작은 변경을 가하여 3D 감지에 사용할 수 있습니다.
- M3D-RPN (Brazil and Liu 2019)은 공간 인식을 향상시키기 위해 깊이 인식 컨볼루션 레이어를 제안합니다.
- D4LCN (Huo et al. 2020)은 깊이 맵을 사용하여 동적 커널 학습을 안내합니다.
- FCOS3D (Wang et al. 2021b)는 3D 대상을 이미지 도메인으로 변환하여 객체의 2D 및 3D 속성을 예측합니다.
- 또한, PGD (Wang et al. 2022a)는 깊이 추정을 용이하게 하기 위해 기하학적 관계 그래프를 제안합니다.
- DD3D (Park et al. 2021a)는 깊이 사전 훈련이 최종적으로 3D 감지를 크게 개선할 수 있다는 것을 보여줍니다.
- 다른 연구 방향은 3D 공간에서 객체를 예측하는 것입니다.
- 2D 이미지 특징을 3D 공간으로 변환하는 다양한 방법이 있습니다.
- 대표적인 접근 방법은 이미지 기반의 깊이 맵을 가짜 LiDAR로 변환하여 LiDAR 신호를 모방하는 것입니다 (Wang et al. 2019; You et al. 2019; Qian et al. 2020).
- 이미지 특징을 사용하여 3D 복셀(Rukhovich, Vorontsova, and Konushin 2022)이나 orthographic feature maps(Roddick, Kendall, and Cipolla 2018)을 생성할 수도 있습니다.
LSS(2020)는 proposes aview transform methodthat explicitly predicts depth distribution and projects image features onto a bird’s-eye view (BEV), which has been proved practical for 3D object detection.BEV-Former (Li et al. 2022b)는 지역적인 어텐션과 그리드 형태의 BEV 쿼리를 사용하여 2D에서 3D로 변환합니다.- DETR (Carion et al. 2020)를 따라 DETR3D (Wang et al. 2022b)는 트랜스포머와 객체 쿼리를 사용하여 3D 객체를 감지하며, PETR (Liu et al. 2022a)는 3D 위치-인식 표현을 도입하여 성능을 더욱 개선합니다.
- 2D 이미지 특징을 3D 공간으로 변환하는 다양한 방법이 있습니다.
깊이 추정
- 깊이 예측은 mono 이미지 해석에 있어서 중요합니다.
- Fu et al. (Fu et al. 2018)은 확장 컨볼루션과 장면 이해 모듈을 사용하여 이미지의 깊이를 예측하는 회귀 방법을 채용합니다.
- Monodepth (Godard, Mac Aodha, and Brostow 2017)는 감독 없이 거리와 재구성을 사용하여 깊이를 예측합니다.
- Monodepth2 (Godard et al. 2019)는 깊이 추정과 자세 추정 네트워크를 결합하여 단일 프레임에서 깊이를 예측합니다.
- 일부 접근 방식은 predict depth by constructing cost volume.
- MVSNet (Yao et al. 2018) first introduces cost- volume to the field of depth estimation.
- MVSNet을 기반으로 RMVSNet (Yao et al. 2019)은 메모리 비용을 줄이기 위해 GRU를 사용하고,
- MVSCRF (Xue et al. 2019)는 CRF 모듈을 추가하고,
- Cascade MVSNet (Gu et al. 2020)은 MVSNet을 계층 구조로 변경합니다.
- Wang et al. (Wang et al. 2021a)는 다중 스케일 퓨전을 사용하여 깊이 예측을 생성하고 성능을 개선하면서 메모리 사용량을 줄이는 적응형 모듈을 도입합니다.
- Bae et al. (Bae, Budvytis, and Cipolla 2022)은 단일 뷰 이미지를 다중 뷰 이미지와 융합하고, 계산 비용을 줄이기 위해 깊이 샘플링을 도입합니다.
Lift-splat의 depth prediction 분석!
- we first review the overall structure of our baseline 3D detector built on Lift-splat.
- Then we conduct a simple experiment on our base detector to reveal why we observe the previous phenomenon.
- Finally, we discuss three deficiencies(결함) carried by this detector and point out a potential solution to it.
Model Architecture for Base Detector
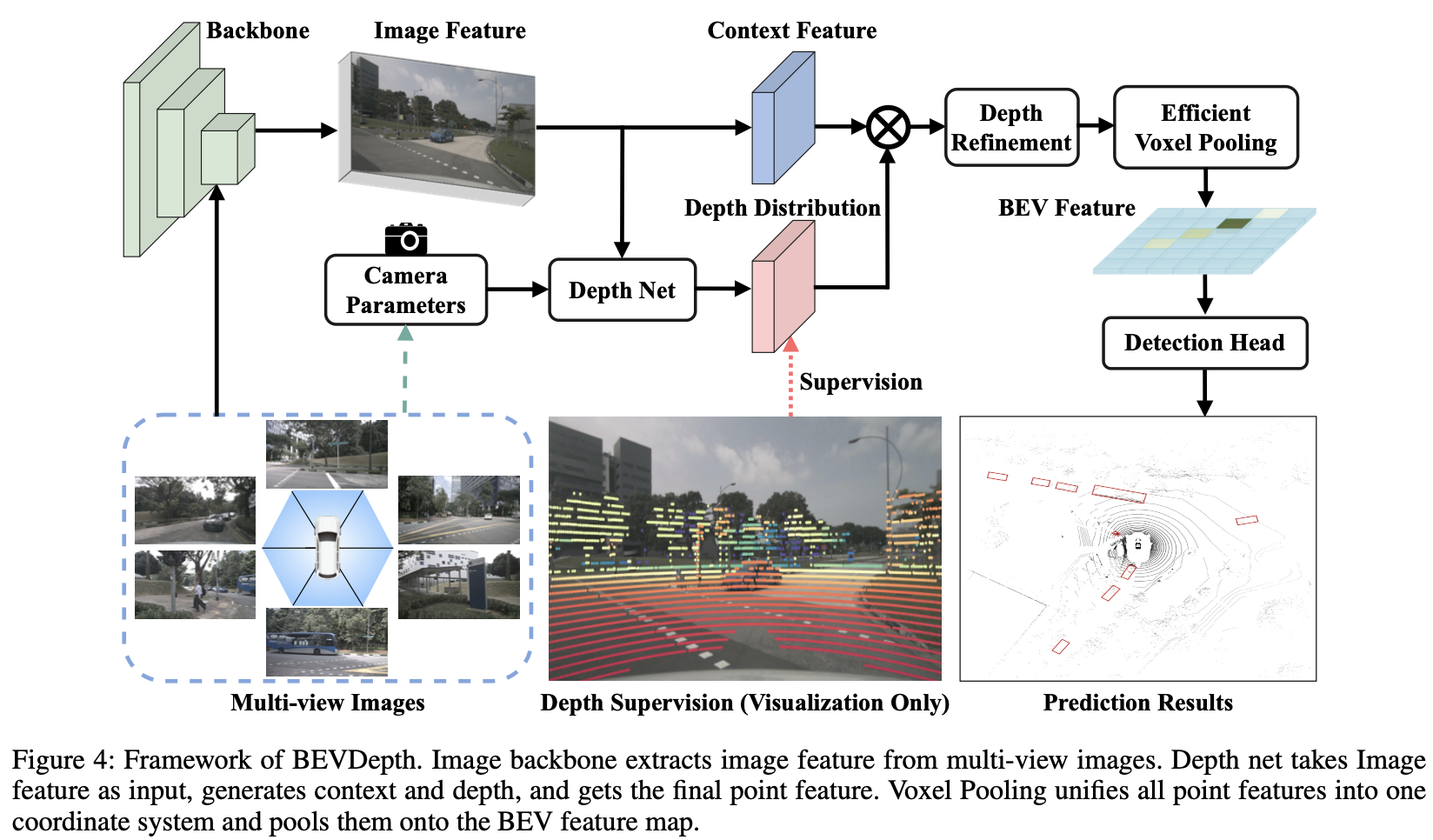
- Our vanilla Lift-splat based detector simply replaces the
segmentation head in LSS (2020)withCenterPoint head(2021) for 3D detection.
Making Lift-splat work is easy
- Now, we take a step further to study the essence of this pipeline
- by replacing
Dpredwith a random initialized tensor- and freezing it during both the training and testing phases.
- We are surprised to find that mAP only drops 3.7% (from 28.2% to 24.5%) after replacing Dpred with randomized soft values.
- 우리는
the depth used for unprojecting features가 심각하게 손상되었더라도,- 깊이 분포의 소프트한 특성이 -> 어느 정도로든
unproject to the right depth position하는데 도움이 되어 -> 합리적인 mAP를 얻을 수 있다고 가정합니다.
- 깊이 분포의 소프트한 특성이 -> 어느 정도로든
- 그러나 동시에 많은 수의 노이즈를 투영하게 됩니다.
- by replacing
- 우리는 더 나아가 소프트한 랜덤화된 깊이를 하드한 랜덤화된 깊이로 대체하고 (one-hot activation at each position), 6.9%의 큰 저하가 관찰되었음을 확인하여 이 가정을 검증합니다.
- 이는 올바른 위치의 깊이에 어느정도 활성화가 있다면 -> 감지 헤드가 작동할 수 있다는 것을 보여줍니다.
Making Lift-splat work well is hard
- 기존의 성능은 합리적인 결과를 얻기는 하지만 만족스럽지는 않습니다.
- 이 부분에서 우리는 Lift-splat의 기존 작동 메커니즘에서 발생하는 부정확한 깊이, 깊이 모듈의 과적합 및 부정확한 BEV 의미 세 가지 결함을 밝힙니다.
- 이를 더 명확하게 보여주기 위해 두 가지 기준선을 비교합니다.
- 기본적인 LSS 기반 감지기인 Base Detector
- 다른 하나는 Dpred로부터 파생된 포인트 클라우드 데이터에서 extra depth supervision을 활용하는 Enhanced Detector
Inaccurate depth
- when a detector is trained without depth loss (just like Lift-splat), it detects objects by only learning partial depth.
Depth Module Overfitting
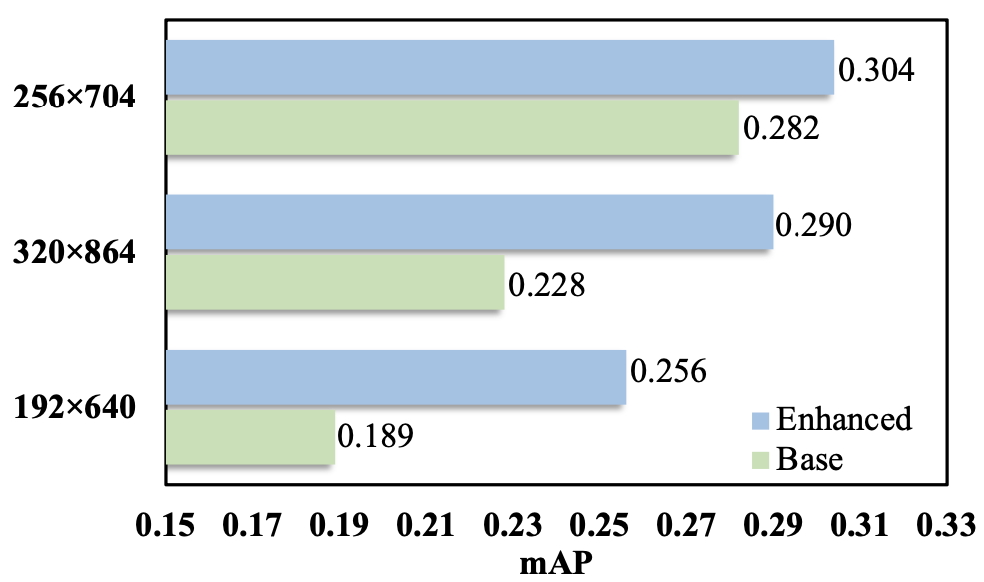
- 이전 콘텐츠에서 언급한 대로, Base Detector은 일부 영역에서만 깊이를 예측하도록 학습합니다.
- 구체적으로, the detector learning depth in that way could be very sensitive to hyperparameters such as
image sizes,camera parameters, etc. - Such a phenomenon implies that the model without depth loss has a higher risk of over-fitting, and thus it may also be sensitive to the noise in camera intrinsics, extrinsics, or other hyper-parameters.
Imprecise BEV Semantics
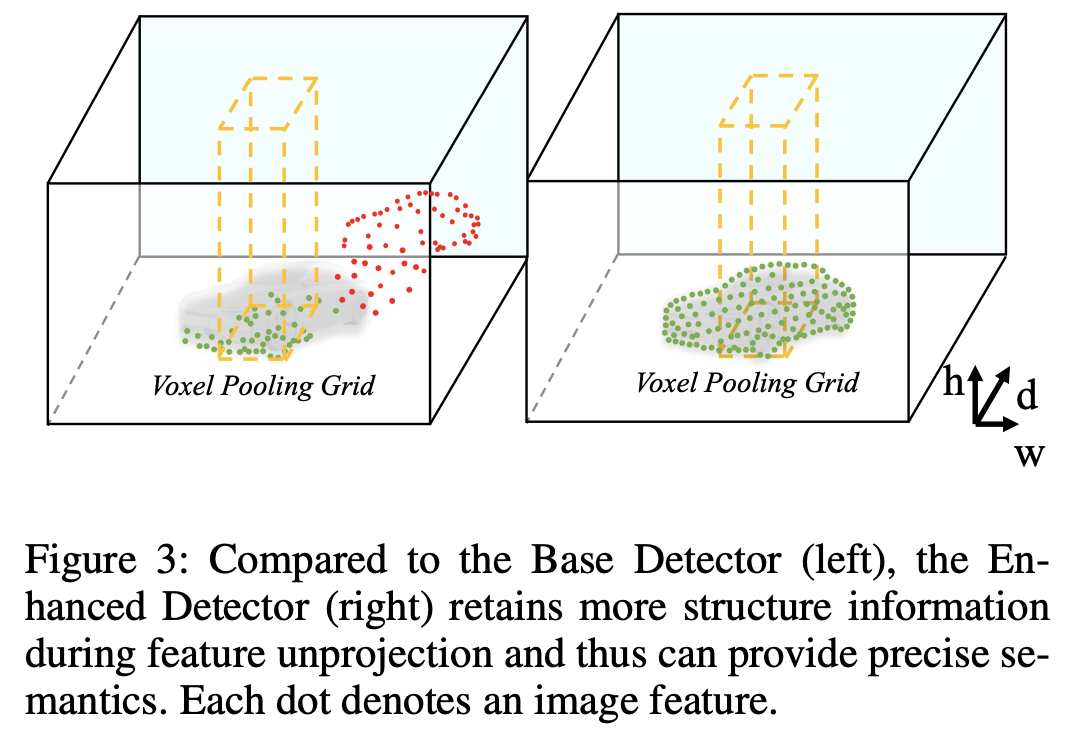
- Once image features are unprojected to frustum features using learned depth, a Voxel/Pillar Pooling operation is adopted to aggregate them to BEV.
- Fig. 3은 깊이 감독이 없을 때 이미지 특징이 적절하게 투영되지 않음을 보여줍니다.
- Therefore, the pooling operation only aggregates part of semantic information.
- Enhanced Detector은 이 시나리오에서 더 나은 성능을 발휘합니다.
BEVDepth
Explicit Depth Supervision
- we simply adopt Binary Cross Entropy.
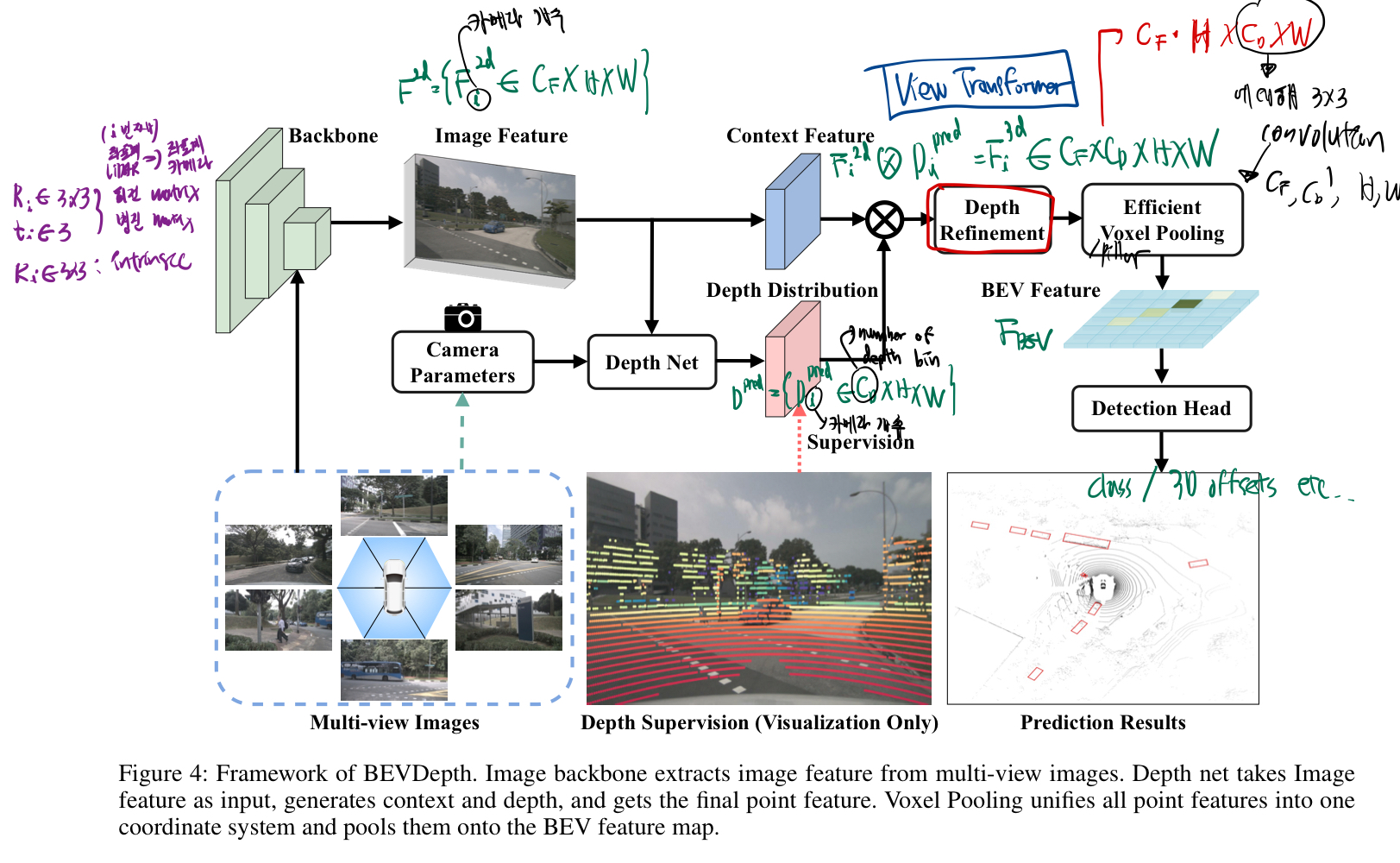
Camera-aware Depth Prediction
- it is non-trivial
to model the camera intrinsicsinto DepthNet. - This is especially important in multi-view 3D datasets when cameras may have different FOVs (e.g., nuScenes Dataset).
- Therefore, we propose to utilize the camera intrinsics as one of the inputs for Depth-Net.
- the dimension for camera intrinsics is first scaled up to the features using an MLP layer.
- Then, they are used to re-weight the image feature F_i^2d with an
Squeeze-and-Excitation(Hu, Shen, and Sun 2018) module. - Finally, we concatenate the camera extrinsics to its intrinsics to help DepthNet aware of F_2d ’s spatial location in the ego coordinate system.

- 그들은 회귀 대상을 카메라의 내부 파라미터에 따라 스케일을 조정하여 복잡한 카메라 설정을 갖는 자동화된 시스템에 적응하기 어렵게 만듭니다.
- 반면에 우리의 방법은 카메라의 매개변수를 DepthNet 내부에 모델링하여 중간 깊이의 품질을 개선하는 것을 목표로 합니다.
- LSS (Philion and Fidler 2020)의 분리된 특성을 활용하면, the camera-aware depth prediction module is isolated from the detection head and thus the regression target, in this case, does not need to be changed, resulting in greater extensibility.
Depth Refinement Module
- Depth Refinement Module은 depth axis로 feature을 모을 수 있다. (depth prediction confidence가 낮을 때)
- 다른 한편으로, depth prediction이 부정확할 때, Depth Refinement Module은 (receptive field is large enough 이면) position을 정확히 보정해 줄 수 있다.
- 요약하면, Depth Refinement Module은 View Transformer 단계에 교정 메커니즘을 부여하여 잘못 배치된 특징들을 교정할 수 있게 합니다.
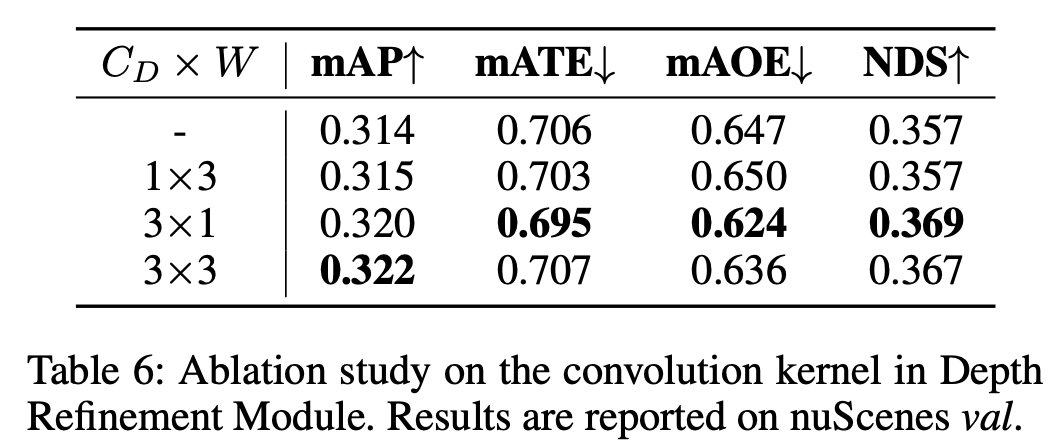
- Depth Refinement Module is designed to refine unsatisfactory depth by aggregating/refining the unprojected features along the depth axis.
- 효율성 측면에서, 우리는 처음에는 이 모듈에 3×3 컨볼루션을 사용했습니다.
- 여기서 우리는 1×3, 3×1 및 3×3을 포함한 다양한 커널을 실험하여 이 모듈의 작동 메커니즘을 연구했습니다.
- Table 6을 참조하면, CD × W 차원에 1×3 컨볼루션을 사용하면 정보가 깊이 축을 따라 교환되지 않으며 감지 성능에 거의 영향을 미치지 않습니다.
- 3×1 컨볼루션을 사용하면 특징이 깊이 축을 따라 상호작용할 수 있으며, 이에 따라 mAP와 NDS가 개선됩니다.
- 이는 단순한 3×3 컨볼루션을 사용하는 것과 유사하며, 이 모듈의 본질을 보여줍니다.
Experiment
실험 설정
데이터셋과 메트릭
- 데이터셋에는 1000개의 시나리오가 있으며, 이 중 700개, 150개, 150개의 시나리오가 각각 학습, 검증, 테스트용으로 분할되어 있습니다.
- 3D 검출 작업에서는 nuScenes 검출 점수(NDS), 평균 정밀도(mAP) 및 평균 이동 오차(mATE), 평균 스케일 오차(mASE), 평균 방향 오차(mAOE), 평균 속도 오차(mAVE), 평균 속성 오차(mAAE)와 같은 다섯 가지 TP(TP) 메트릭을 보고합니다.
Implementation Details
- 특별히 명시되지 않은 경우, 이미지 백본으로 ResNet-50(He et al. 2016)을 사용하고 이미지 크기는 256×704로 처리됩니다.
- (Huang et al. 2021)을 따라서, 랜덤 크롭, 랜덤 스케일링, 랜덤 뒤집기 및 랜덤 회전을 포함한 이미지 데이터 증강을 채택하고, 랜덤 스케일링, 랜덤 뒤집기, 랜덤 회전을 포함한 BEV 데이터 증강도 채택합니다.
- AdamW (Loshchilov and Hutter 2017)를 최적화기로 사용하며, 학습률은 2e-4로 설정하고 배치 크기는 64로 설정합니다.
- Ablation study에서는 CBGS 전략(Zhu et al. 2019)을 사용하지 않고 모든 실험을 24 에포크 동안 학습합니다.
- 다른 방법과 비교할 때, BEVDepth는 CBGS를 사용하여 20 에포크 동안 학습됩니다.
- Camera-aware DepthNet은 feature level에서 16의 stride로 배치됩니다.
Ablation study
Component Analysis
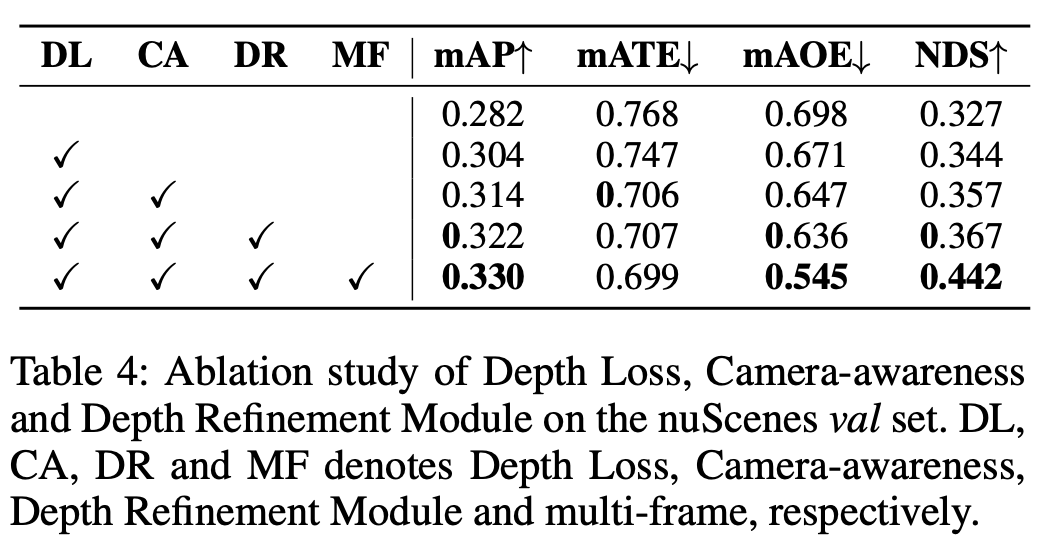
- Depth Loss를 추가하면 mAP가 2.2% 향상되는데, 이는 우리의 분석과 일치합니다.
- Depth Loss is beneficial to classification.
- 카메라 파라미터를 DepthNet에 모델링함으로써 mATE가 0.41 감소합니다.
- 이는 Camera-awareness의 중요성을 보여줍니다.
Depth Loss
- 깊이 추정 분야에서는 BCE와 L1Loss가 두 가지 일반적인 손실 함수입니다. 뭘 써도 성능 비슷합니다.
Benchmark Results
- 이번에는 nuScenes 벤치마크에서 우리의 성능을 얻기 위해 중요한 두 가지 구현 방법을 간략히 소개하겠습니다.
- Efficient Voxel Pooling과 Multi-frame Fusion입니다.
Efficient Voxel Pooling
Existing Voxel Pooling in Lift-splat leverages a “cumsum trick” that involves a “sorting” and a “cumulative sum” operations.- 이 방법은 각 pillar를 패딩하는 대신 (패딩을 피하고), pillar를 패킹(packing)을 사용하여 sum pooling을 수행합니다.
- 이 연산은 분석적으로 기울기를 계산할 수 있으므로, 자동 기울기 계산(autograd)를 더 빠르게 수행할 수 있습니다.
- 이는 큰 포인트 클라우드를 처리하는 데 있어 효율성이 중요하기 때문에, 이러한 방법을 사용하여 모델 훈련을 가속화합니다.
- 논문 주장: Both operations are computationally inefficient.
- We propose to utilize great parallelism of GPU
by assigning each frustum feature a CUDA thread that is used to add the feature to its corresponding BEV grid.
- 우리는 각 frustum 특징에 CUDA 스레드를 할당하여 해당 BEV 그리드에 기능을 추가하는 방식으로 GPU의 큰 병렬성을 활용합니다.
- As a result, the training time of our state-of-the- art model is reduced from 5 days to 1.5 days.
- The sole pooling operation is 80× faster than its baseline in Lift-splat.
Multi-frame Fusion
- Multi-frame Fusion은 더 나은 객체 감지와 속도 추정 능력을 갖도록 돕습니다.
우리는 다른 프레임의 frustum 특징의 좌표를 현재 ego 좌표 시스템으로 정렬하여 ego-motion 의 영향을 제거한 후 Voxel Pooling을 수행합니다.- 다른 프레임의 풀링된 BEV 특징을 직접 연결하여 다음 작업에 사용합니다.
nuScenes val set
- 우리는 FCOS3D, DETR3D, BEVDet, PETR, BEVDet4D 및 BEVFormer와 같은 최첨단 방법과 BEVDepth를 nuScenes 검증 세트에서 비교합니다.
- We don’t adopt test time augmentation.
nuScenes test set
- For the submitted results on the test set, we use the train set and val set for training.
Conclusion
- 이 논문에서는 정확한 깊이 예측을 위한 새로운 네트워크 아키텍처인 BEVDepth를 제안했습니다.
- 우리는 먼저 기존의 3D 객체 감지기의 작동 메커니즘을 연구하고 신뢰할 수 없는 깊이를 밝혀냈습니다.
- 이를 해결하기 위해 BEVDepth에는 Camera-aware Depth Prediction 및 Depth Refinement 모듈과 Explicit Depth Supervision이 도입되어 견고한 깊이 예측을 생성할 수 있게 됩니다.
- BEVDepth obtains the capability to predict the trustworthy depth and obtains remarkable improvement compared to existing multi-view 3D detectors.
- 또한, Multi-frame Fusion 스키마와 Efficient Voxel Pooling의 도움으로 BEVDepth는 nuScenes 리더보드에서 최고 성능을 달성합니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것