[230811] Deformable DETR : Deformable Transformers for End-to-End Object Detection 논문 리뷰
Object detection
목록 보기
13/23
reference
- https://velog.io/@hsbc/Deformable-DETR-Deformable-Transformers-for-End-to-End-Object-Detection-논문-리뷰
Introduction
- DETR의 문제점 극복
- 느린 수렴 극복
- DETR
- Attention weight가 uniform하게 초기화되고 나서, 의미있는 위치에 focus 시키기 위해 학습하는 시간이 매우 길다. (uniform이란, 평균이 0이고 분산이 1인 분포)
- ex) key가 160개라면, 1/160으로 시작해서 gradient도 매우 작은 상태, query가 주어졌을 때 key는 이미지의 다른 모든 pixel이 되기 때문에 학습이 오래 걸림
- DETR
- 작은 물체에 대한 낮은 성능 극복
- DETR
- 작은 객체를 detection은 주로 high resolution feature map에서 이뤄지는데,
- Encoder는 feature size의 제곱에 비례한 시간복잡도를 가지기 때문에, high resolution image를 감당할 수 없음-> 작은 물체 탐지 성능 저하
- DETR
Method
backbone + 후처리
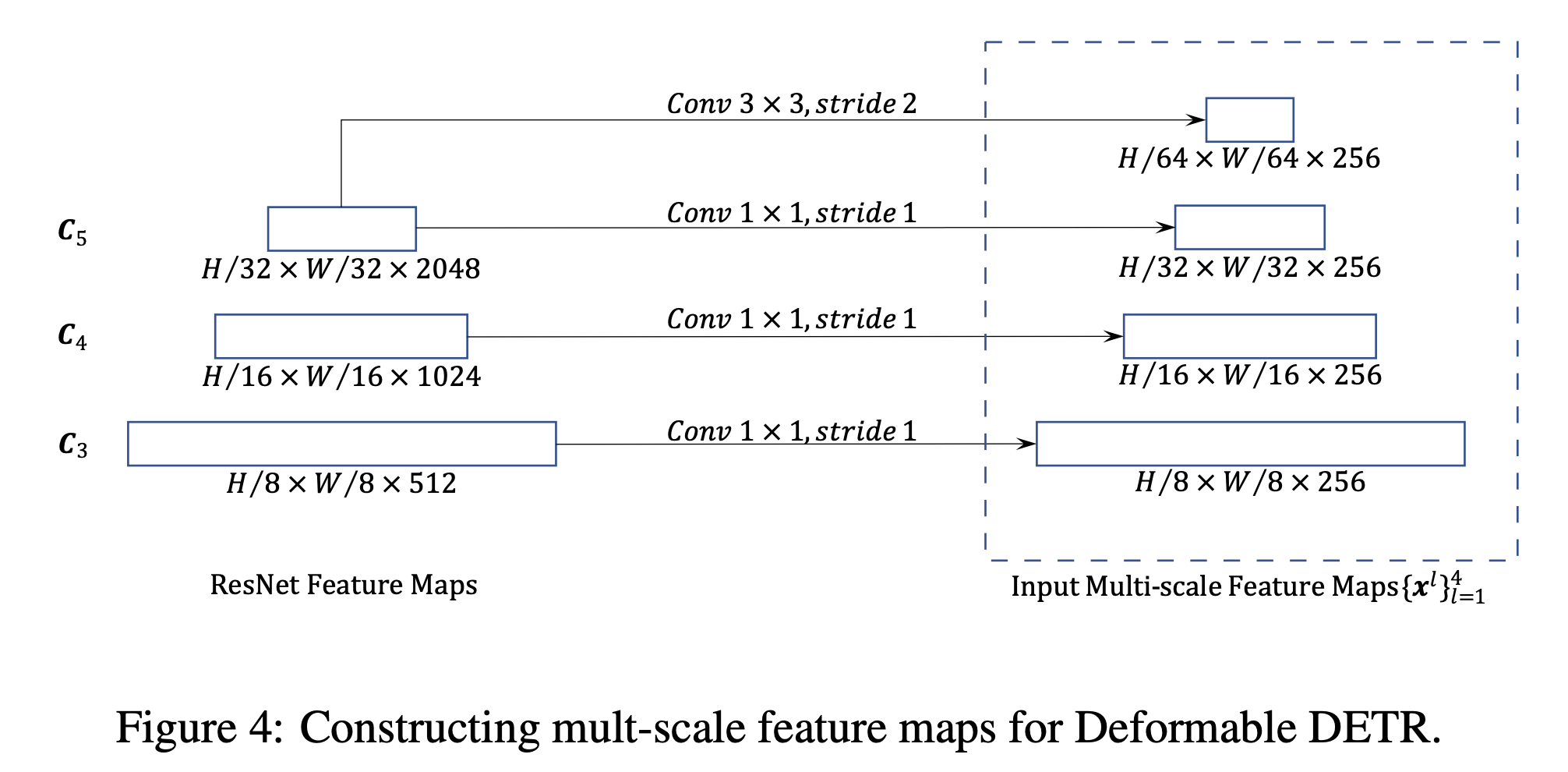
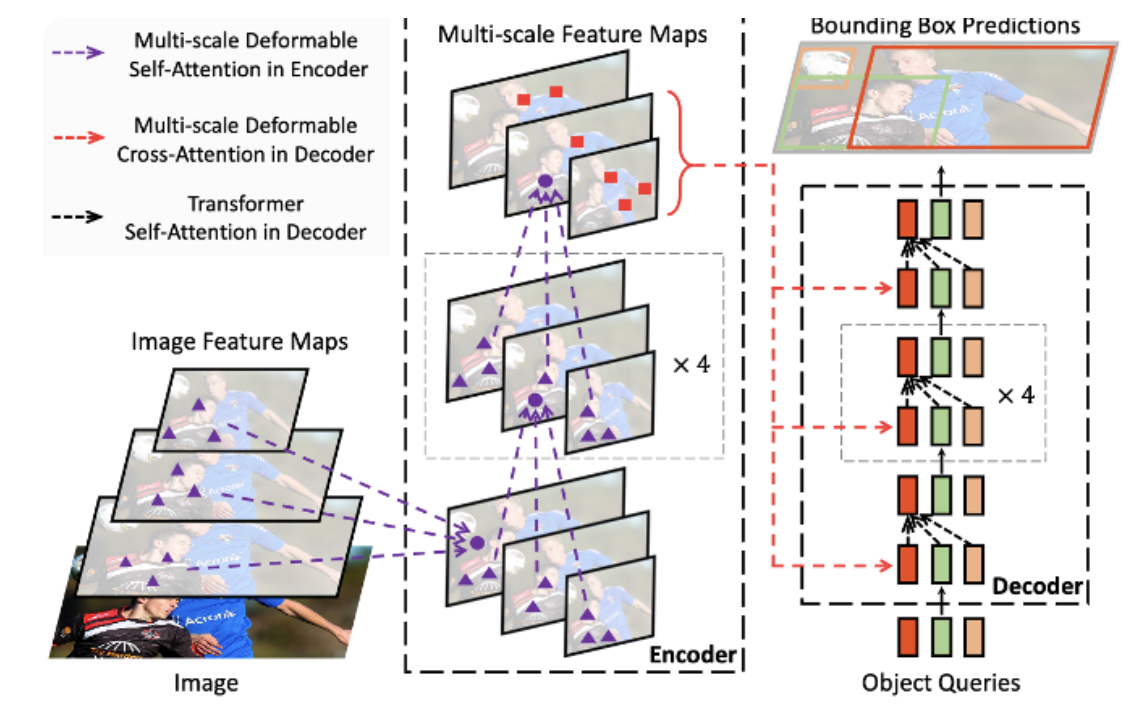
- 각 scale의 feature 의 dimension을 256으로 같게 만들어줌.
encoder
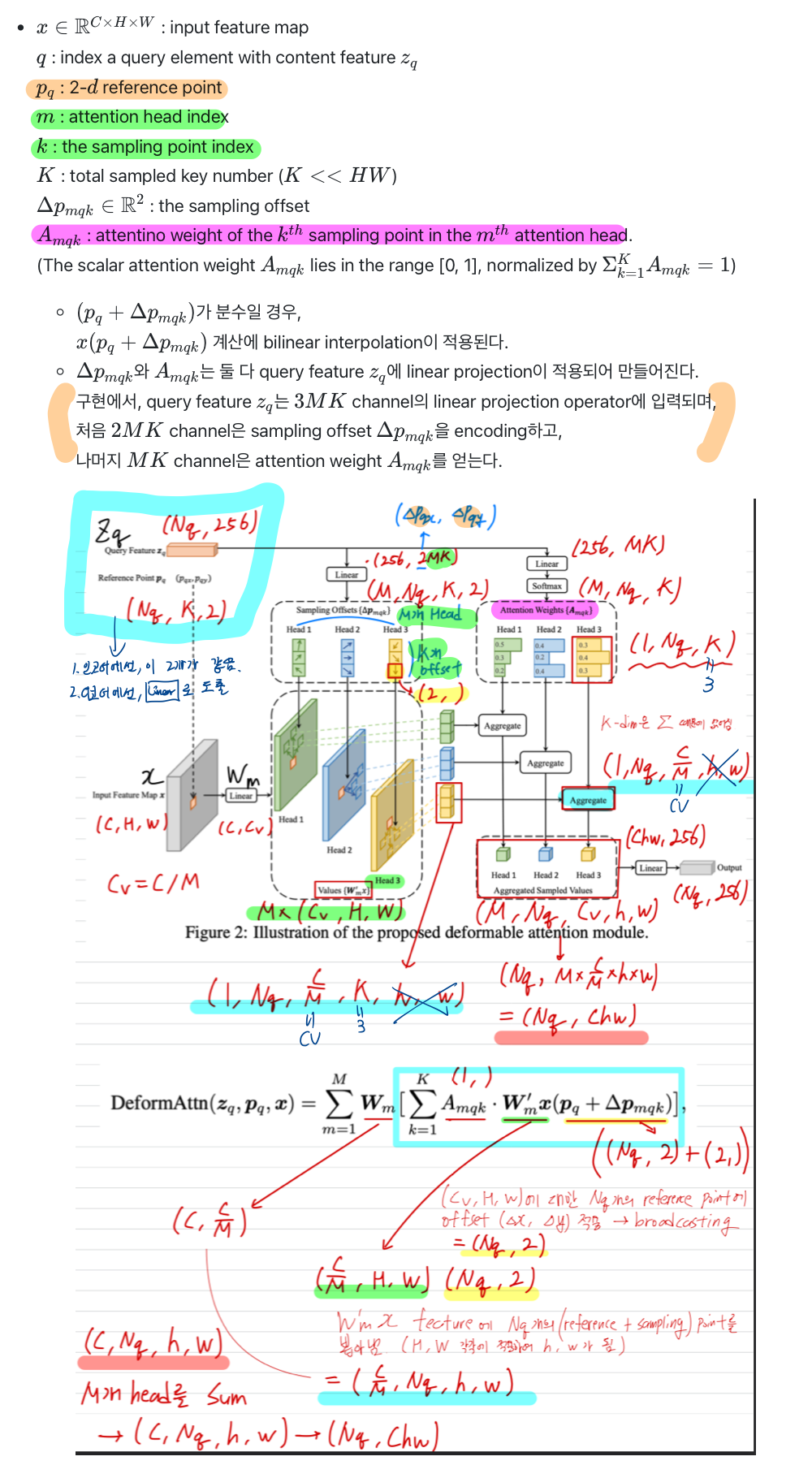
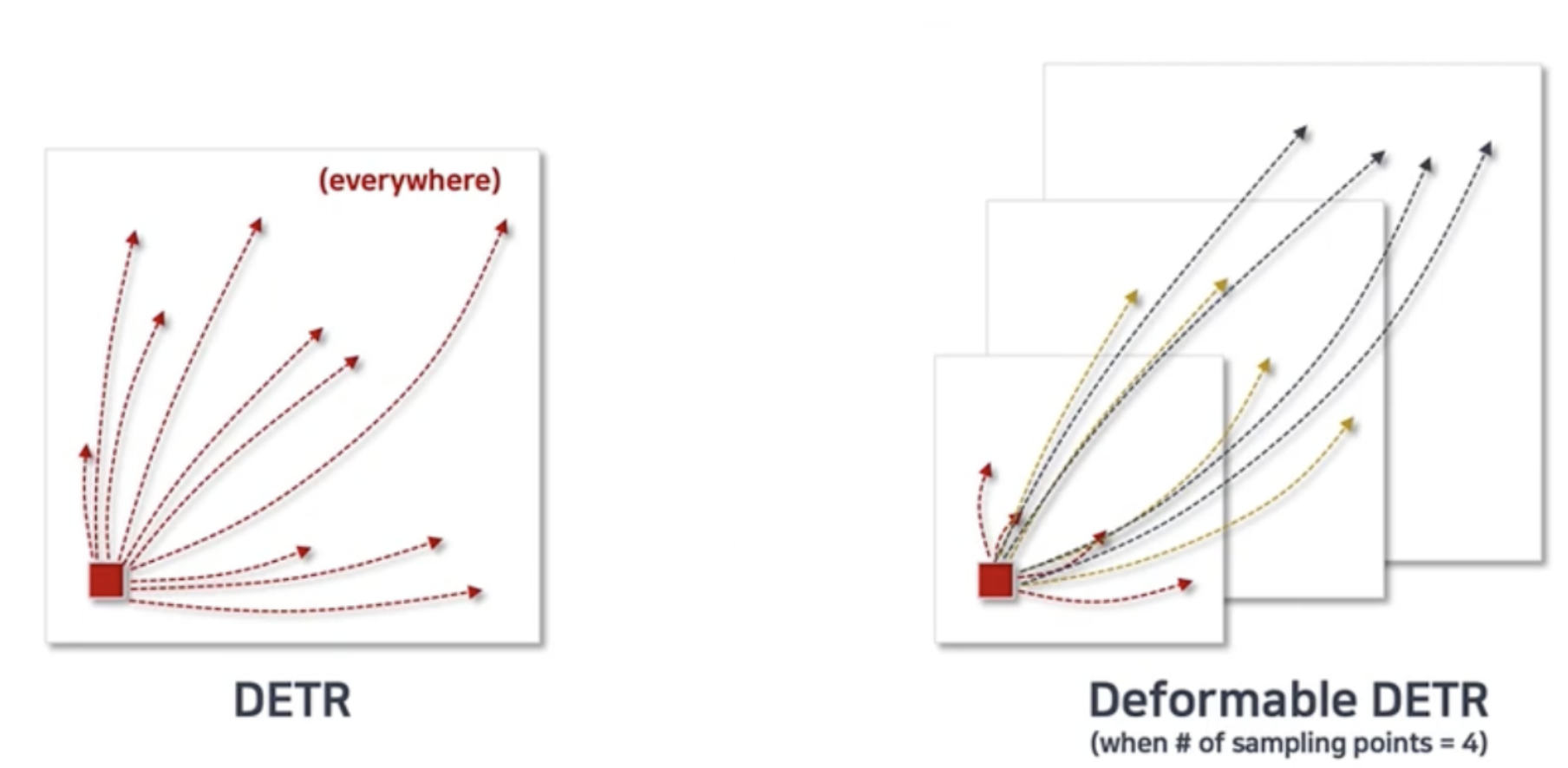
- 하나의 scale이 아닌, 다른 모든 scale에서의 pixel에 대해서도 attention 연산 수행하므로 속도와 여러 크기의 물체에 대해 이득!(이 때 좌표를 0-1 사이 값으로 normalize)
decoder (cross attention 부분이 개선됨)
- cross attention은 object queries들을 linear layer에 통과시켜 reference points들을 추출하고, 각 reference point에서 sampling points를 뽑아 인코더와 동일한 방식으로 value를 계산하는 부분이다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것