- image level task와 object level task 이 2개를 동시에 학습을 해서 -> 성능을 높여보자!
- contribution
- object detection task를 Pharse grounding task 로 봄으로써, 전체 네트워크를 reformulating해서 통합하는 모델을 제시
- Phrase Grounding: 이미지와 그에 대한 설명이 주어졌을 때, 설명에 나와있는 단어와 그에 해당하는 부분을 localize하는 Task
image-text 데이터셋에서 ->image-object level label을 도출해내는 scaling up 방법을 제안- 하나의 모델로, 많은 task에 공동적으로 적용할 수 있게 만듦
- object detection task를 Pharse grounding task 로 봄으로써, 전체 네트워크를 reformulating해서 통합하는 모델을 제시
- 입력 text:
- 전체 이미지를 묘사하는 문장이 아님!!
각 객체를 설명하는 명사구의 조합이 input으로 들어감
- Visual encoder:
Swin-Tiny 백본을 사용하는 SoTA DyHead 감지기- swin transformer: https://velog.io/@hsbc/swin-transformer
- Dyhead: https://velog.io/@hsbc/Dyhead-module
- Text encoder: BERT
image-text 데이터셋에서 ->image-object level을 도출 하는법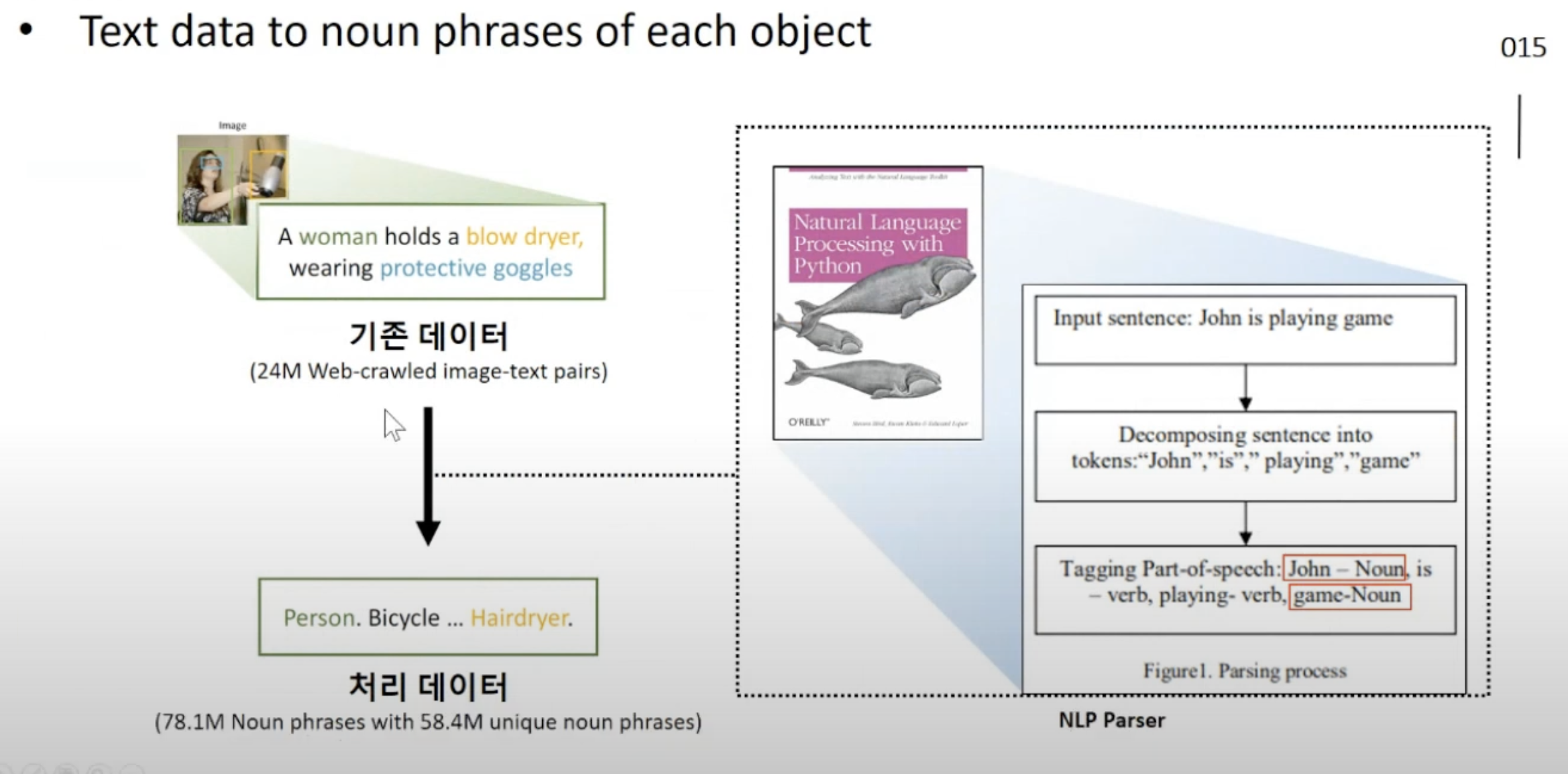
- NLP with python이라는 책에서 소개된 NLP parser을 이용해서,
- 원본 sentence 에서 명사구에 해당하는 부분만 자동 추출
- NLP with python이라는 책에서 소개된 NLP parser을 이용해서,
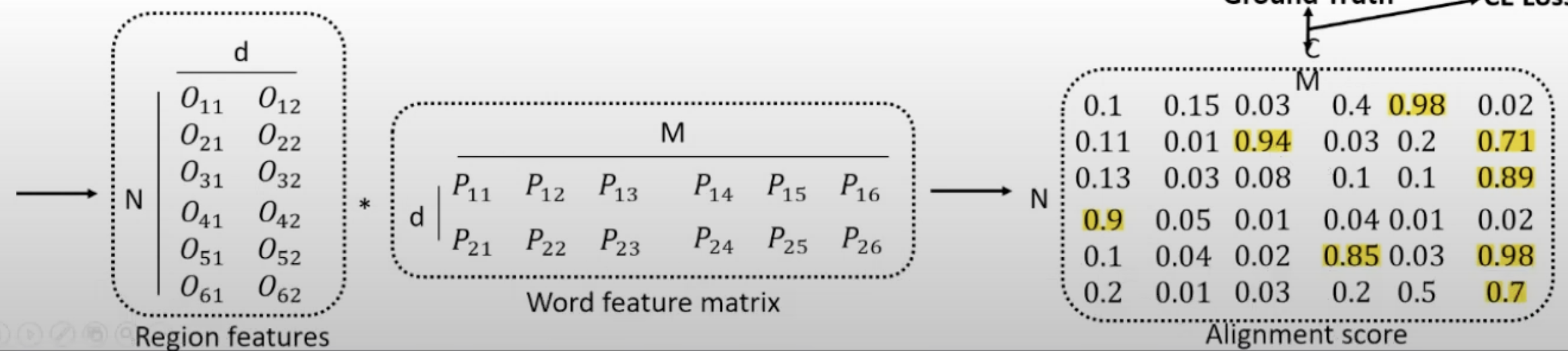
- 아래 그림은 학습 과정을 나타냄
- N: 사진 내 region 후보군의 갯수
- M: input text로 주어진 명사의 개수
- 각 명사마다, 여러개의 region이 할당될 수 있다. 이를 고려해서 cross entropy loss를 구한다.
- Grounding data(이미지, 문장 -> 문장 내의 단어들과 이미지 내 box의 조합 도출)를 이용해서 (semantic rich한 데이터라고 함) pre-train을 하면 어떤 장점이 있을까?
- 본 논문에서는 feature network를 이용해서 pseudo labelling을 진행함.
- https://velog.io/@hsbc/pseudo-labelling
- grounding data로 학습하니, (기존 object detection dataset은 최대 2000개 정도의 Class) VG caption이라는 데이터셋에서는 11만개 정도의 class가 있다.
GLIP에서 pseudo label 을 만들어 내는 법
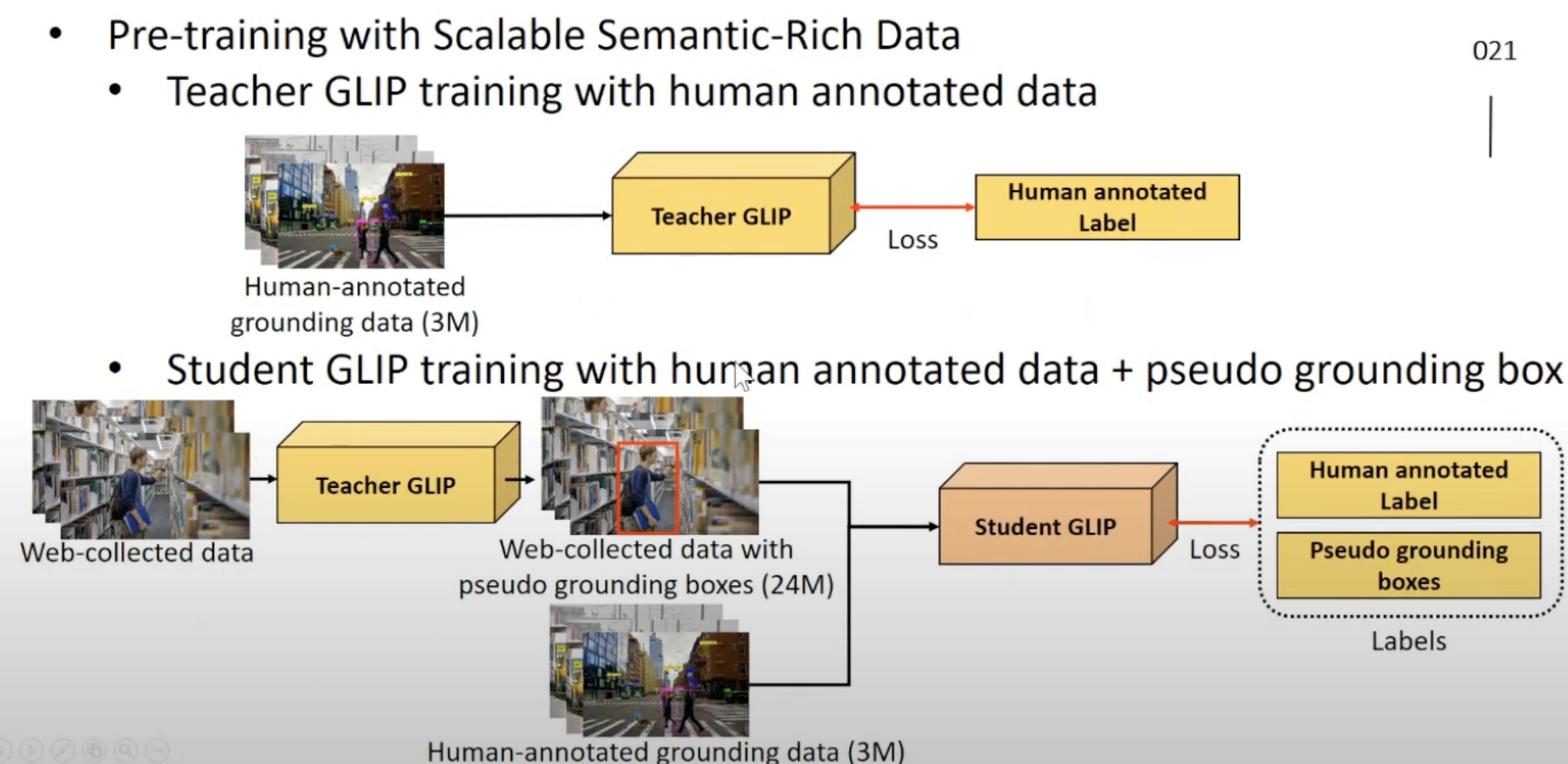
- 이렇게 하니, student GLIP이 teacher 보다 훨씬 더 잘 동작한다고 한다!
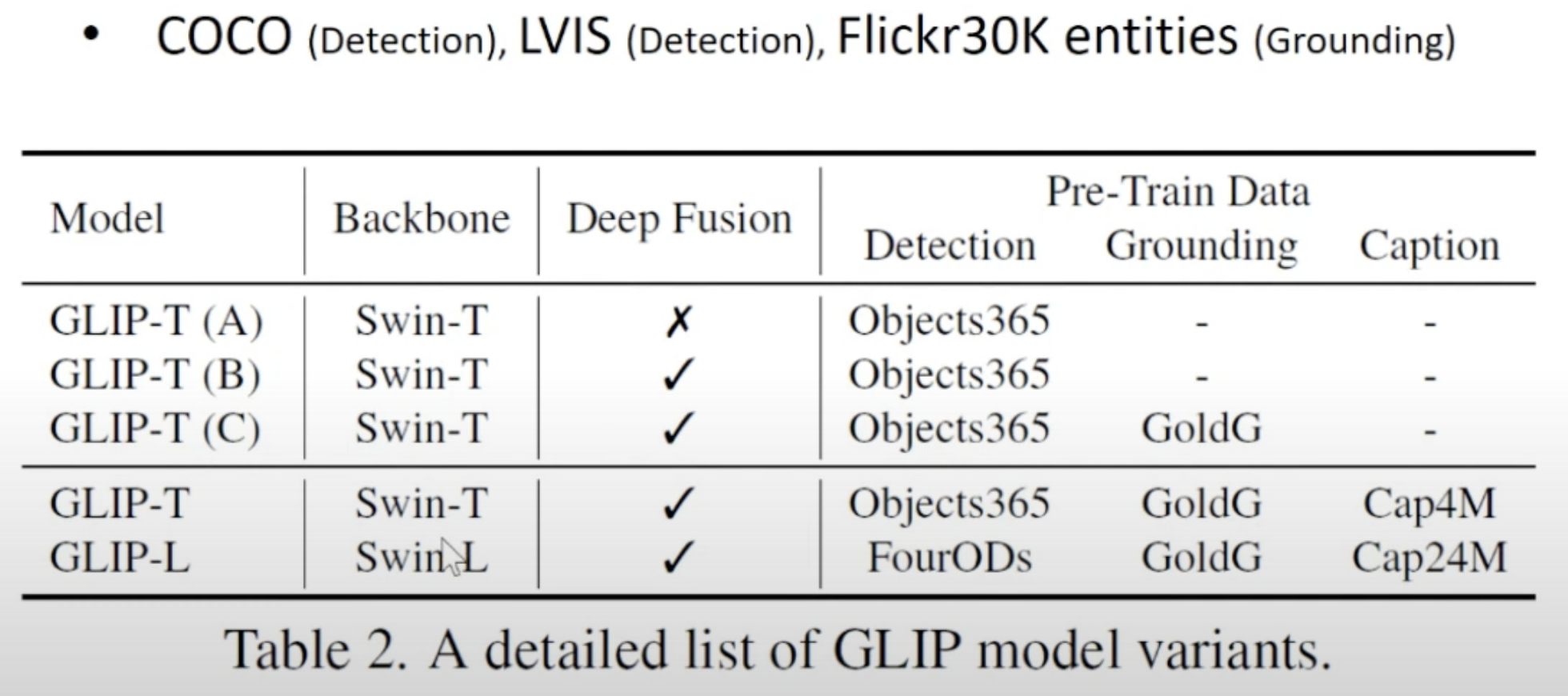
사용한 dataset들 정리
GoldG (학습에 이용)
- grounding dataset
- Flickr30K, VG Caption, GQA을 합쳐서 만든 것으로 보임
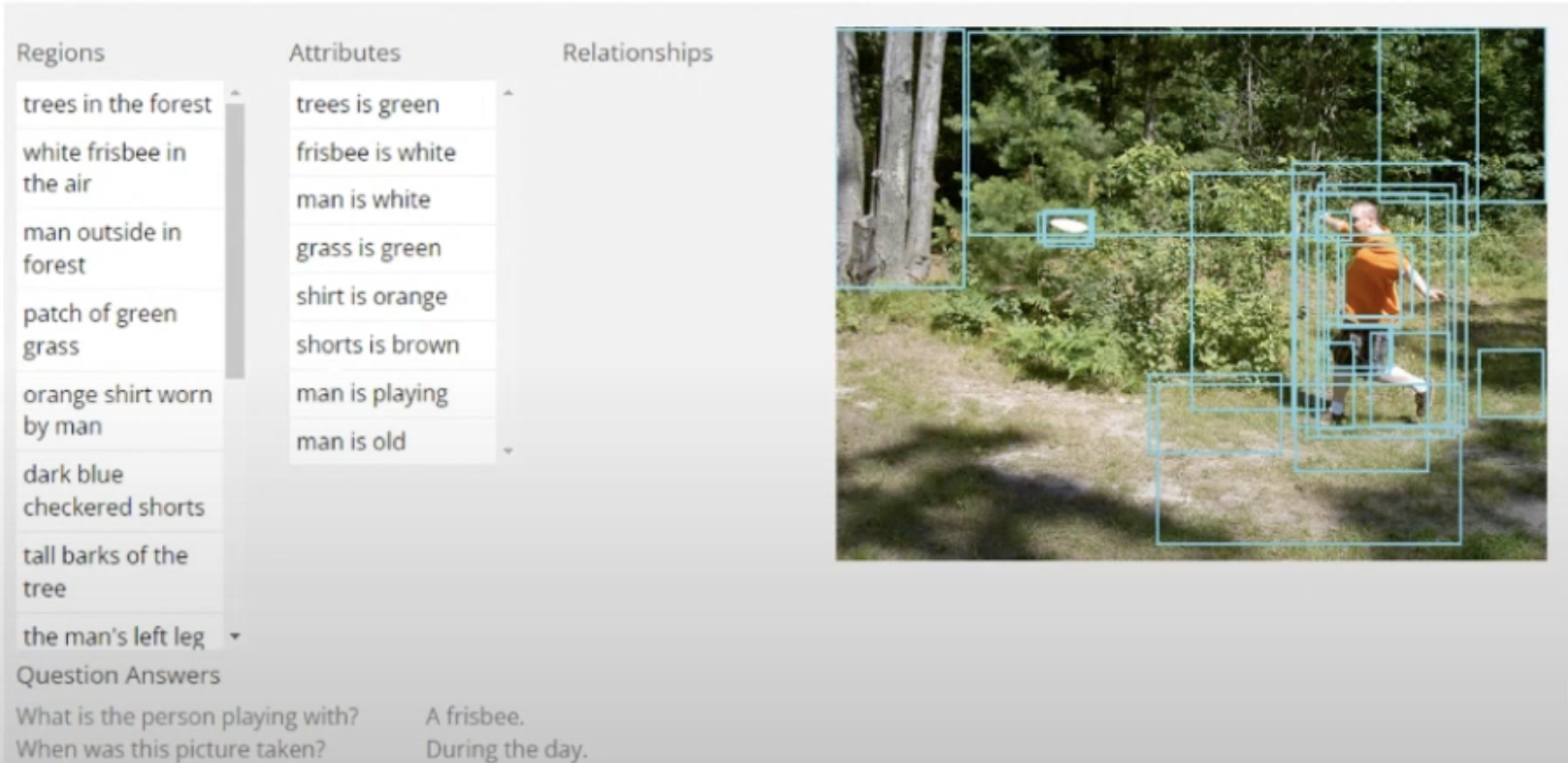
Flickr30K entities (밴치마크)
- grounding dataset
- 총 3만장
- 각 이미지를 설명하는 5개 문장들과
- 각 문장들 내의 명사구에 해당하는 bounding box
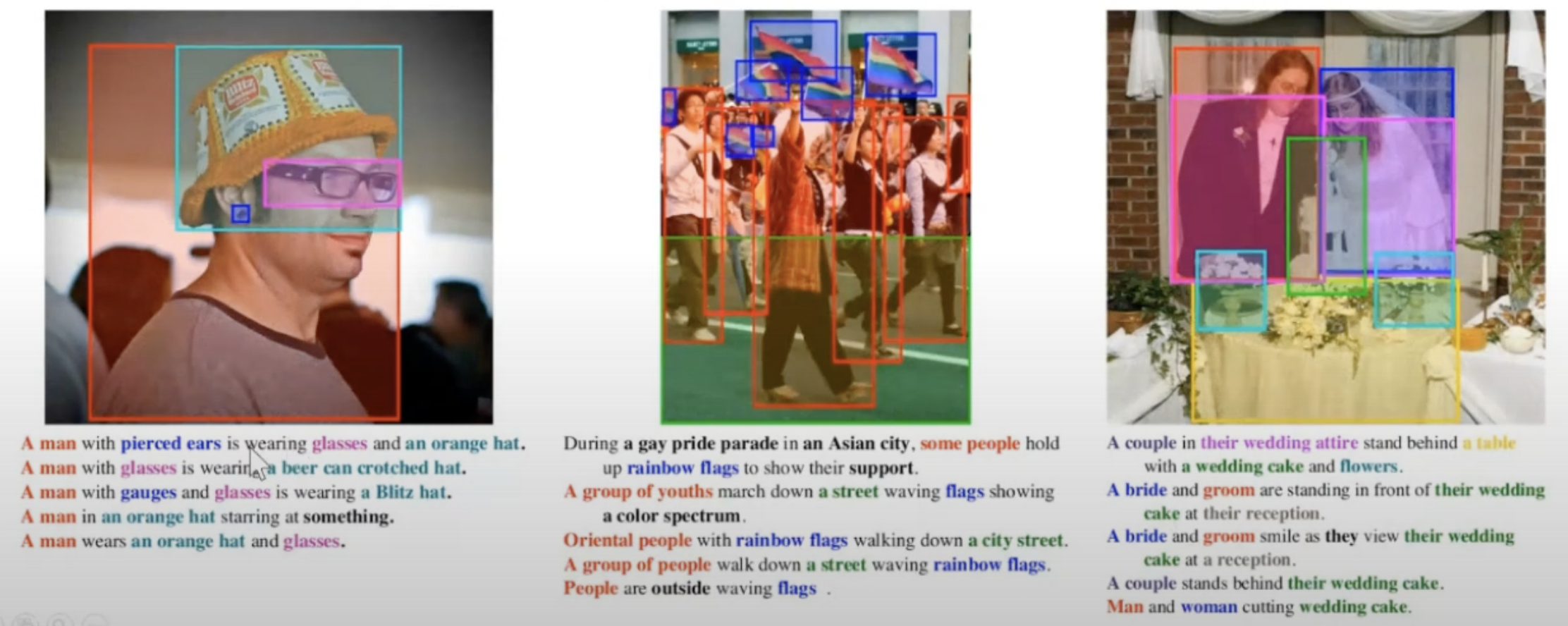
Object 365 (학습에 이용)
- object detection dataset
- 365개 클래스 200만장
COCO dataset (밴치마크)
- object detection dataset
- 총 80개의 클래스, 총 33만장
- 이미지 당 5개의 caption
LVIS (밴치마크)
- object segmentation dataset
- 1200개 클래스, 총 16만장
image caption data
- image caption dataset
- 웹에서 크롤링한 데이터 or public dataset
- 이미지 caption 데이터는, 주어진 데이터셋에 negative caption 레이블을 만들어서 썼다.
학습 과정
- https://openaccess.thecvf.com/content/CVPR2022/papers/Li_Grounded_Language-Image_Pre-Training_CVPR_2022_paper.pdf
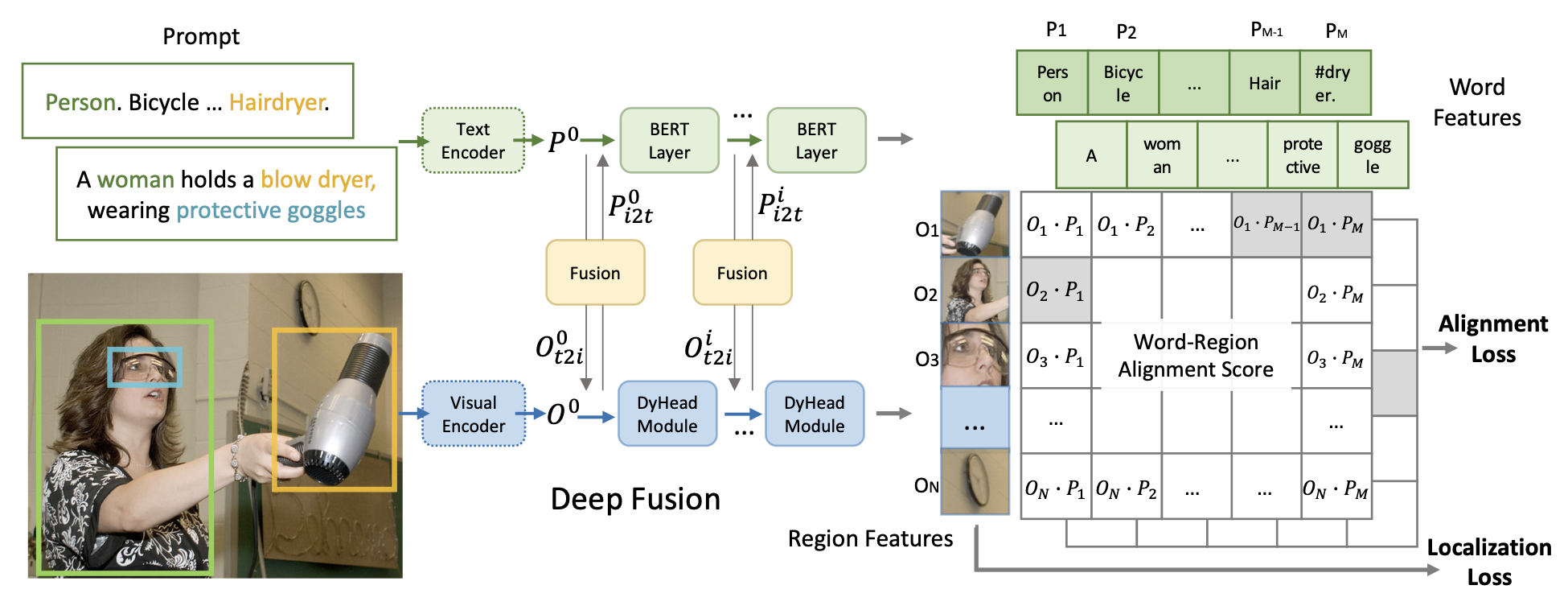
- object detection 및 grounding을 위한 통합 프레임워크.
- 고전적인 object detection 모델이 각 감지된 객체에 대해 범주형 클래스를 예측하는 것과 달리,
- 우리는
object detection을 그라운딩 작업으로 재구성하여,각 영역/박스를 텍스트 프롬프트의 phrase구절과 정렬 - GLIP은 이미지 인코더와 언어 인코더를 공동으로 학습시켜 영역과 단어의 올바른 쌍을 예측
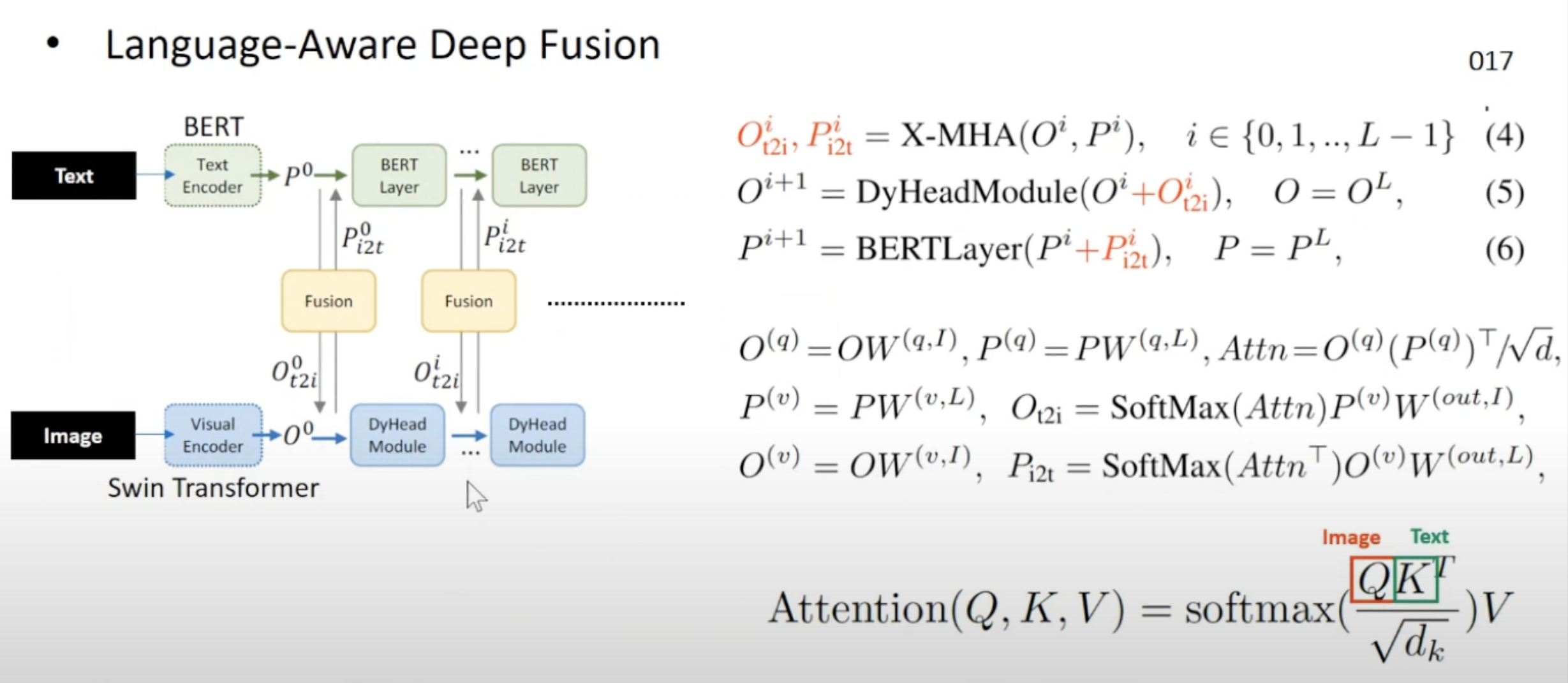
- 우리는 또한 두 모달리티의 정보를 조기에 결합하고, 언어 인식 시각 표현을 학습하기 위해 크로스 모달리티 딥 퓨전을 추가

- dynamic head
- 논문 내용 발췌:
Swin-Tiny 백본을 사용하는 SoTA DyHead 감지기 - https://velog.io/@hsbc/Dyhead-module
- 논문 내용 발췌:
- bert
- swin transformer
- 논문 내용 발췌:
Swin-Tiny 백본을 사용하는 SoTA DyHead 감지기 - https://velog.io/@hsbc/swin-transformer
- 논문 내용 발췌:
왜 함?
- 목적 1: Object Detection Task 를 할 때, 학습 데이터에 없었던 class도 inference시 잘 맞추기 위함. (다른 말로, 매우 많은 class들을 잘 맞추는 모델을 만들어보자.)
- 이를 위해 Mutli-Modal(Image + Text) Concept을 Object Detection Task에 적용
- 기존
Image-Text Pair 데이터 대량 학습한 CLIP은 Image Classification, Text-image retrieval Task에만 적용 가능했다.
- 목적 2: multi modality(text + 이미지)를 object detection에 적용하여, 더 풍부한 representation understanding을 통해 객체 인식 성능을 높이자!
Abstract
- GLIP은 객체 감지와 Phrase Grounding 작업을 하나로 통합합니다.
- Phrase Grounding: 이미지와 그에 대한 설명이 주어졌을 때, 설명에 나와있는 단어와 그에 해당하는 부분을 localize하는 Task
- 이렇게 통합하는 것에는 두 가지 장점이 있습니다.
- 1) GLIP은 객체 감지와 문장 그라운딩 데이터에서 동시에 학습하여 두 작업을 함께 개선하고 더 좋은 그라운딩 모델
- 2)GLIP은 Self-training을 통해서 grounding boxes를 만듦으로써 image-text 쌍을 대량 사용 가능
- 실험에서 우리는 GLIP을 2천 7백만개의 그라운딩 데이터로 사전 훈련시켰습니다.
- 이 데이터에는 3백만개의 사람이 주석을 단 이미지와 2천 4백만개의 웹에서 가져온 이미지-텍스트 쌍이 포함됩니다.
Introduction
- 이 연구에서는 다음과 같은 주요 기여를 소개합니다:
- 기여 1: 대량의 이미지-텍스트 데이터를 이용하여 시각적 개념을 확장합니다.
- 이미 좋은 성능을 보이는 모델을 기반으로 문장 그라운딩 박스를 생성하여, 학습 데이터를 늘릴 수 있습니다.
- 이를 통해 모델은 더 많은 상황에서 정확한 결과를 얻을 수 있습니다.
- 기여 2: 객체 감지 작업을 문장 그라운딩으로 재정의하여 두 작업을 통합합니다.
- 기여 3: 학습된 모델은 다양한 작업에 적용할 수 있습니다. 이미지와 문장을 함께 이해하는 능력은 다양한 작업에 적용할 수 있습니다.
- 기여 1: 대량의 이미지-텍스트 데이터를 이용하여 시각적 개념을 확장합니다.
객체 감지를 문장 그라운딩으로 재정의하여 감지와 그라운딩을 통합
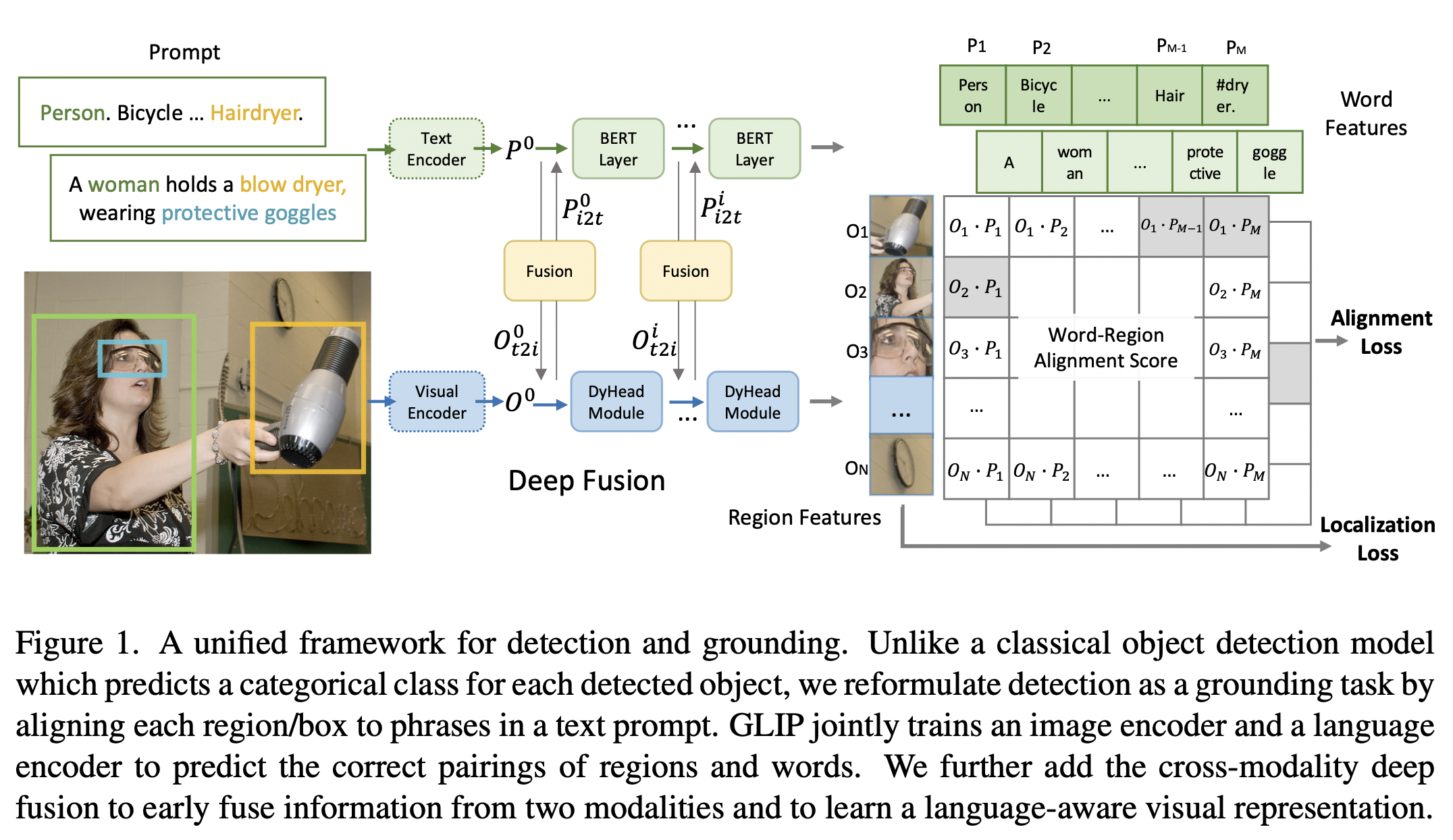
- 예를 들어, COCO 객체 감지의 경우 텍스트 프롬프트는 "80 COCO 객체 클래스 이름"을 " . "으로 연결한 텍스트 문자열입니다(그림 1 좌측 참조).
- 어떤 객체 감지 모델이든 감지 모델의 상자 분류기 내에서 객체 분류 로짓을 -> 단어-영역 정렬 점수로 대체하여 그라운딩 모델로 변환할 수 있습니다.
- 단어-영역 정렬 점수는
영역(또는 상자) 시각적 특징과토큰(또는 구) 언어 특징의 내적으로 계산됩니다(그림 1 우측 참조).
- 단어-영역 정렬 점수는
- CLIP는 최후의 내적 레이어에서만 비전과 언어를 융합하는 반면,(last fusion)
- GLIP은 early-stage deep fusion
- 높은 품질의 언어-인식 시각적 표현을 학습하고 우수한 전이 학습 성능을 달성하는 데 중요하다.
- 감지 측면에서는 그라운딩 데이터 덕분에 pool of visual concepts이 크게 보강됩니다.
- On the grounding side,
detection data introduce more bounding box annotationsand help train a new SoTA phrase grounding model.
- GLIP은 early-stage deep fusion
참고: Pre-training with Scalable Semantic-Rich Data
- Prior work
- 대부분 self-training 방식으로 scale up을 한다.
- Teacher model을 학습시키고 knowledge distilation을 통해 student 모델을 학습시키는 대표적인 준지도학습 방식인데,
- 한계점은 student model은 teacher가 아는것 이상을 배울 수 없다는 점이다.
- GLIP
- student mode이 선생님을 능가 가능. (prior와 data의 특성에서 차이를 보임.)


Scaling up visual concepts with massive image-text data.
- Given a good grounding model (teacher), we can augment GLIP pre-training data by automatically generating grounding boxes for massive image-text-paired data, in which noun phrases are detected by an NLP parser [2].
- 대규모 이미지-텍스트 쌍에서 NLP 파서를 사용하여 텍스트 설명에서 명사 구를 추출
- 예를 들어, "A dog is playing in the park"라는 문장에서 "dog"와 "park"와 같은 명사 구를 추출
- Grounding Box 생성:
- 추출된 명사 구를 기반으로, 그라운딩 모델은 이미지 내에서 해당 명사 구에 대응하는 객체의 위치를 바운딩 박스로 나타냄
- 예를 들어, "dog"라는 명사 구에 대해 이미지를 분석하여 개의 위치를 바운딩 박스로 표시
- 데이터 증강:
- 이 과정을 통해 대규모 이미지-텍스트 쌍에 대해 자동으로 그라운딩 박스를 생성하여 GLIP 모델의 학습 데이터를 증강
- 이렇게 생성된 데이터는 GLIP 모델의 사전 학습에 사용되어 모델의 성능을 향상시킴
- 따라서 우리는 27M 그라운딩 데이터에서 GLIP-Large 모델(GLIP-L)을 사전 훈련할 수 있습니다.
- 이 데이터에는 3M 인간 주석이 달린 미세 조정 데이터와 24M 웹 크롤링된 이미지-텍스트 쌍이 포함됩니다.
- For the 24M image-text pairs, there are 78.1M high-confidence (> 0.5) phrase-box pseudo annotations, with 58.4M unique noun phrases.
- 2400만 개의 이미지-텍스트 쌍을 이용해서, 자동화된 방법(teacher 모델)을 통해 구-박스 주석을 생성
- 생성된 주석 중 신뢰도가 0.5 이상인 고신뢰도 주석이 총 7810만 개 존재
- 이 주석들 중 5840만 개의 명사구는 (중복되지 않는) 고유한 명사구
- For the 24M image-text pairs, there are 78.1M high-confidence (> 0.5) phrase-box pseudo annotations, with 58.4M unique noun phrases.
GLIP을 사용한 전이 학습 성능 좋다.
- 그라운딩 재구성(
객체 탐지를 그라운딩(텍스트와 이미지의 특정 객체를 매칭하는 작업)으로 재구성)과 의미적으로 풍부한 사전 학습은- GLIP 모델이 한 도메인에서 다른 도메인으로 전이하는 것을 촉진합니다.
- 이는 모델이 특정 작업에만 국한되지 않고 다양한 작업에 잘 적용될 수 있음을 의미합니다.
- Moreover, when
task-specific annotationsare available, instead of tuning the whole model,- one could tune only the task-specific prompt embedding,
- while keeping the model parameters unchanged.
- 설명
- 특정 작업을 위한 주석 데이터가 주어졌을 때, 예를 들어, "강아지"와 "고양이"를 구분하는 주석 데이터가 있다고 가정합니다.
- 이러한 주석 데이터는 모델이 특정 작업을 더 잘 수행하도록 도와줍니다.
- 전통적으로, 주석 데이터를 사용하여 전체 모델의 모든 파라미터를 조정(튜닝)합니다.
- 이는 모델이 특정 작업에 더 잘 맞추도록 하지만, 계산 비용이 크고 시간이 많이 걸리며, 새로운 주석 데이터마다 모델을 다시 튜닝해야 합니다.
- GLIP 모델에서는 전체 모델을 조정할 필요 없이, 특정 작업에 맞춘 프롬프트 임베딩만 조정할 수 있습니다.
- 예를 들어, "강아지"와 "고양이"를 구분하기 위해 "강아지"와 "고양이"라는 프롬프트를 사용하고, 이 프롬프트의 임베딩 벡터만 조정합니다.
- 프롬프트 임베딩을 조정하면, 모델이 특정 작업에 더 잘 맞추도록 하는데 필요한 정보만 업데이트합니다.
- 모델의 나머지 파라미터는 변경되지 않으므로, 계산 비용이 적고 시간이 덜 걸립니다.
- Under such a prompt tuning setting (Section 5.2), one GLIP model can simultaneously perform well on all downstream tasks , reducing the fine-tuning and deployment cost.(CLIP은 잘 못함)
- 이러한 프롬프트 튜닝 설정 하에서, 하나의 GLIP 모델은 모든 다운스트림 작업에서 동시에 우수한 성능을 발휘할 수 있습니다.
- 이로 인해 미세 조정 및 배포 비용이 줄어듭니다. 반면, CLIP 모델은 이 부분에서 잘 수행하지 못합니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것