VideoMAE : Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
0
action recognition in videos
목록 보기
13/19
1. info
- 2022, 1010회 인용
- https://taek-guen.tistory.com/51 을 참고하여 작성하였습니다.
- 논문: https://proceedings.neurips.cc/paper_files/paper/2022/file/416f9cb3276121c42eebb86352a4354a-Paper-Conference.pdf
- 보충자료: https://proceedings.neurips.cc/paper_files/paper/2022/file/416f9cb3276121c42eebb86352a4354a-Supplemental-Conference.pdf
- https://github.com/MCG-NJU/VideoMAE
- 1400 star
참고 자료
- MAE: https://velog.io/@hsbc/MAE-Masked-Auto-Encoding-are-scalable-Vision-Learner
- VideoMAE2: https://velog.io/@hsbc/VideoMAE-V2-Scaling-Video-Masked-Autoencoders-with-Dual-Masking
2. Introduction
2.1. 연구의 Motivation
- ViT는 학습을 잘 시키기 위해서, 데이터도 많이 필요하고, 학습 시간이 오래 걸림.
- Video ViT는 이미지로 사전 학습된 ViT를 기반으로 학습해야, 성능이 어느정도 나온다는 문제점이 있었음
- 비디오 데이터를 가지고도,
Video VisionTransformer을 scratch 방식으로 학습할 수 있는 연구가 필요했음!
- 비디오 데이터를 가지고도,
- 하지만, 비디오 데이터의 양은 일반적으로 이미지 데이터에 비해 적은 경우가 많아,
- Video VisionTransformer을 scratch 부터 학습 시키는 것이 어려운 상황이었음.
MAE를 Video ViT에 적용함으로써, 비디오 데이터로부터 scratch 부터 학습시키는 것을 가능하게 했음self supervised learning이 가능해졌으므로!!
2.2. 비디오 데이터와 이미지 데이터의 차이
- 비디오 데이터가 30fps면, 인접한 프레임끼리는 별 차이가 없음.
2.3. 그 외
데이터의 quantity보다, quality가 더 중요하다.
3. Method
3.1. 비디오 데이터의 특성을 활용한, masking
Temporal redundancy- semantics은 시간 축에서, 매우 느리게 변화합니다.
- 프레임을 많이 보는 것은, 모델이 학습하는 입장에서 난이도가 낮으므로, 프레임을 적게 보는 것이 효과적
- masking ratio 90-95% 정도로 적용.
- image MAE는 75% 정도의 masking을 사용했었다.
- 높게 가져간 이유? Temporal redundancy 로 인해, 단일 이미지 내에서 masking을 유추하는 것보다, 참고할 수 있는 힌트 정보가 더 많으므로
Temporal correlation- 이를 극복하기 위해, tube masking을 진행해야 합니다.

3.2. 네트워크 구조
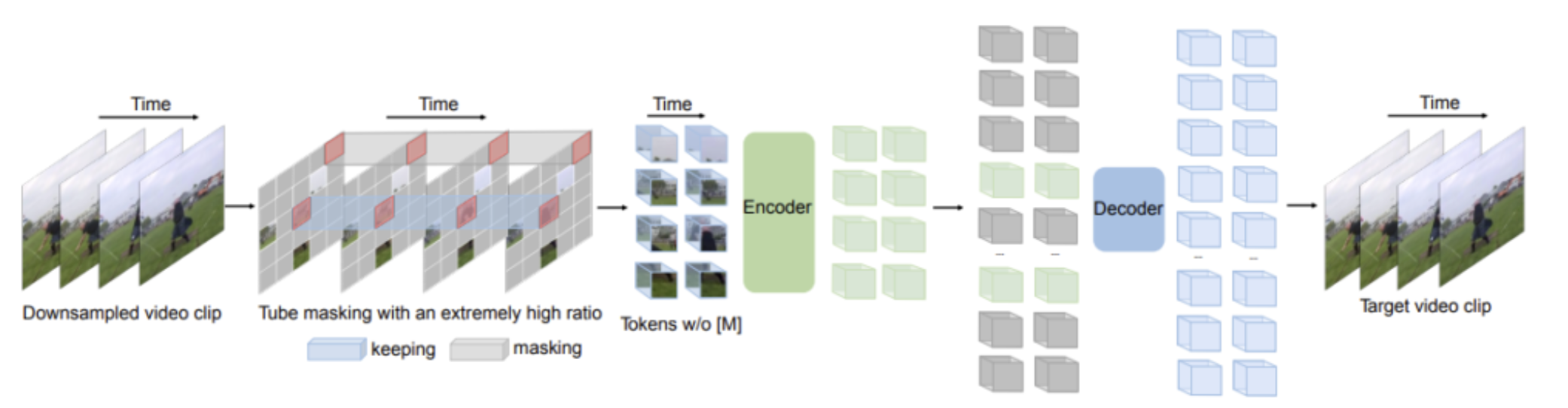
- Attention mechanism으로는, joint space-time attention을 적용
- space-time attention은 제곱의 연산량을 가져가지만, masking을 90% 정도 진행하기 때문에, attention으로부터 발생하는 cost를 줄일 수 있음

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것