[23, 3][367] VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
action recognition in videos
목록 보기
11/24
-1. Info
- 2023, 367회 인용
- https://openaccess.thecvf.com/content/CVPR2023/papers/Wang_VideoMAE_V2_Scaling_Video_Masked_Autoencoders_With_Dual_Masking_CVPR_2023_paper.pdf
- https://openaccess.thecvf.com/content/CVPR2023/supplemental/Wang_VideoMAE_V2_Scaling_CVPR_2023_supplemental.pdf
- https://github.com/OpenGVLab/VideoMAEv2
- 520 stars
참고 공부 자료
- MAE? : https://velog.io/@hsbc/MAE-Masked-Auto-Encoding-are-scalable-Vision-Learner
- VideoMAE ?: https://velog.io/@hsbc/VideoMAE-Masked-Autoencoders-are-Data-Efficient-Learners-for-Self-Supervised-Video-Pre-Training
- Kinetics/SSV2 dataset?: https://velog.io/@hsbc/video-action-recognition-테스크-정리
0. 바쁘신 분들을 위한 3줄 요약
- 본 논문은 Video Foundatation Model 로써, data size나 model capacity를 scaling 하는데에 성공함.
- 1.35M개 비디오 데이터셋으로 Self-supervised MAE training 진행 후, Kinetics-710 데이터셋으로 supervised action classification으로 Post pre-training 진행
- pre-training 시, 6 ~ 7.25 fps 간격으로 비디오 frame input을 받아 딥러닝 네트워크의 input으로 사용하여 학습했음. 그리고 한번에 넣는 비디오가 커버하는 시간 길이도 2.2~2.66초로 거의 비슷함.
2. Introduction
- LLM 연구들은 이미, data size나 model capacity를 잘 scaling 하는데에 성공하였다.
- 즉, data size와 model capacity를 선형적으로 증가시킴에 따라, 성능도 선형적으로 증가함.
- 더불어서, computational cost와 memory consumption도 감당 가능한 수준에서, 성능 확보에 성공했다.
- 하지만, Vision 도메인, 특히 Video data에서의 Foundation model의 scaling 연구는 아직 활발하게 진행되고 있지 않음.
- 비디오 데이터의 볼륨이 너무 크기 때문.
- 본 논문은, scaling을 효과적으로 하기위해,
computational cost와 memory consumption을 비교적 적게 사용하는, 효과적인 VideoMAE scaling 방법을 제안- scaling up을 진행할 때에도, 계산량을 위해, decoder은 항상 4 layers with 512 channels를 유지하고, encoder만 scaling up 하도록 설계하였습니다.
3. Approach
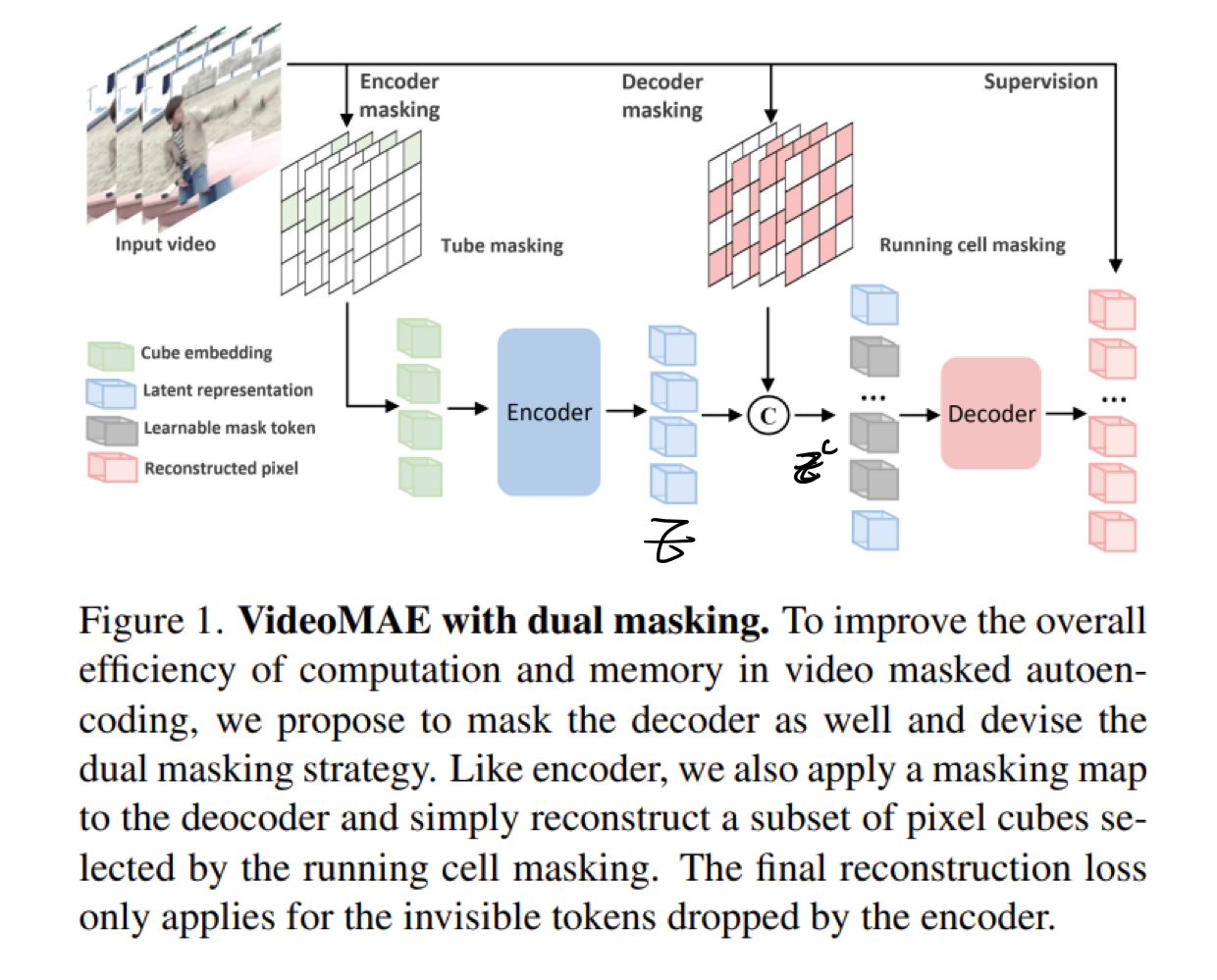
3.1. Dual Masking for VideoMAE
- 기존 VideoMAE의 한계점 1 극복
학습 단계에서 GPU/memory 의 과한소모를 줄이기 위해,dual masking 기법을 제안- 기존 VideoMAE의 과한 계산량의 원인
- 디코더가 visible / invisible token을 모두 입력으로 받기 때문에, Encoder에 비해서는 들어오는 데이터의 양이 10배 더 많음.
- 해결책

- 위 구조로 학습한 결과, model scaling up 과정에서, 한번도 다뤄본 적 없는 ViT-g에 대해서도 scaling을 성공했다고 함.
3.2. Scaling VideoMAE
3.2.1. Data scaling
- VideoMAE의 한계점 2 극복
- MAE 기반의 사전학습(self-supervised pre-training)은 정말 많은 데이터를 필요로 하는데, Video MAE는 데이터의 수가 비교적 적어서,
- fine-tuning 단계에 접어들었을 때, 비교적 작은 크기의 데이터에 대해서도 overfitting 됩니다.
- 즉, videoMAE는 Foundation model로써의 generality가 떨어집니다.
- 이를 극복하기 위해, UnlabeledHybrid 데이터 셋 제안
- 쉽게 얘기해서, pre-train 데이터 양을 6배(0.24M -> 1.35M개 비디오) 늘렸습니다!
Kinetics + General Webs + Youtube + Instagram + Movies 등의 소스 활용
- MAE 기반의 사전학습(self-supervised pre-training)은 정말 많은 데이터를 필요로 하는데, Video MAE는 데이터의 수가 비교적 적어서,
3.2.2. Progressive pre-Training
- VideoMAE의 한계점 3 극복
- 사전학습된 VideoMAE Foundation Model을, 어떻게 fine-tuning 해야하는지에 대한 연구가 부족했음.
- 나이브하게 billion-level로 사전학습된 VideoMAE를,
굉장히 작은 small dataset을 가지고 finetuning 하는 것은 sub-optimal할 것이라고 주장.
- 이런 부분을 고민하여 개선했다고 함.
- 이미지 도메인에서는 이러한 고민의 해결책으로 , intermediate fine tuning 등을 내놓고 있음
학습 단계 1: Pre-training (self-supervised)
- UnlabeledHybrid Dataset
- Kinetics, Something-Someting, AVA, WdbVid2M과 저자들이 모은 Instargram dataset
- Something-Something 만 2 stride로 sampling하고, 나머지 데이터들은 4 stride로 sampling
- 이유: Something-Something 12 fps, Kinetics 25fps, AVA 30fps
- 즉, 비디오 당, 6fps, 6.25fps, 7.25 fps 로 추출하여 학습함!!
여기서 얻을 수 있는 교훈- 6 ~ 7.25 fps 간격으로 비디오 frame input을 받아 딥러닝 네트워크의 input으로 사용함
- 그리고, 각 비디오마다 객체의 이동 속도 등이 다를 것이므로, 얼추 다양한 motion movement를 embedding 한다고 볼 수 있음
학습 단계 2: Post pre-training (supervised)
- intermediate fine tuning 기법임
- 단계 1: 좀 더 큰 규모의 라벨 데이터셋으로 supervised Fine tuning 먼저 수행
- 이 때 사용되는 데이터셋(labledhybrid) 제안
- Kinetics 710: kinetics 400 + 600 + 700 합친 것
- 이 때 사용되는 데이터셋(labledhybrid) 제안
- 이렇게 학습 후, Encoder만 떼서 사용함.
학습 단계 3: Specific fine-tuning (supervised)
- Target으로 하는 작은 데이터 셋으로 최종 finetune
- pre-training 때 진행한 해상도(224 by 244) 보다, 높은 해상도 (266 by 266)으로 fine-tuning하여 실험하기도 했음.
- SSV2에 대해서는 uniform(sparse) sampling 을 수행했다고 함.
uniform(sparse) sampling
-
비디오 분할 (Segmentation):
긴 비디오를 총 K개의 동일한 길이의 구간(segments)으로 나눕니다. 예를 들어, 비디오가 L개의 프레임으로 구성되어 있다면, 각 구간의 길이는 약 L/K 프레임이 됩니다. -
스니펫 추출 (Snippet Extraction):
각 구간에서 하나의 스니펫(snippet)을 선택합니다. 스니펫은 단일 프레임일 수도 있고, 짧은 연속 프레임(예: 5프레임)일 수도 있습니다.
학습 단계에서는 보통 각 구간 내에서 랜덤하게 (randomly) 선택하여 다양한 temporal 변화를 학습하도록 하고,
테스트 단계에서는 보통 구간의 중앙값을 선택하는 방식(중심 샘플링)을 사용할 수 있습니다. -
Uniform Sampling의 장점:
- 전체 커버리지: 비디오 전체에서 고르게 샘플을 선택함으로써, 중요한 액션 단서가 어느 구간에 존재하더라도 포착할 수 있습니다.
- 고정된 계산 비용: 모든 비디오에서 샘플의 개수 K가 동일하므로, 비디오 길이에 상관없이 모델의 입력 크기와 계산 비용이 일정합니다.
4. Experiments
4.1. Results on dual masking
- 디코더를 50% masking 했을 때, VideoMAE와 거의 근접한 성능을 달성.
- 성능은 그대로인데, FLOPs가 크게 줄어들었음 (35.48G -> 25.87G)
- FLOPs란?: https://velog.io/@hsbc/FLOPsFloating-Point-Operations-Per-Second-hbcldtk7
- 학습 속도도 1.5~1.7배 더 빨라짐
4.2. Performance on Downstream Tasks
- Action Detection 부분에서 Optical FLow를 쓰지 않고도 SOTA를 달성함.
- Action Detection 분야?: https://velog.io/@hsbc/Video-Task-전부-정리
- Optical FLow: https://velog.io/@hsbc/Optical-Flow

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것