아마 작년부터 논문 리뷰를 쓰기 시작하면서 가장 먼저 읽었던 논문이 트랜스포머에 관한 Attention is All You Need(2017) 논문이였다.
자연어 처리 분야에서 RNN 기반 모델 대신 어텐션(attention)을 적극 활용한 트랜스포머 모델을 연구한 논문인데, 얼마 전 비전 모델 관련 리서치를 하다가 최근 컴퓨터 비전 분야에서도 트랜스포머 기반 모델이 많이 연구됐다는 걸 알고 비전 트랜스포머(vision transformer)에 대한 논문 리뷰를 하게 되었다.
그러면 구글 브레인에서 발표한 AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 논문을 리뷰하고 ViT에 대해 알아보도록 하자!
(실험 Experiments 파트는 생략한다)
Abstract
트랜스포머(Transformer) 구조(Vaswani et al., 2017)는 등장 이래로 사실상 자연어 처리 분야의 표준으로 자리잡았는데, 컴퓨터 비전 분야에서 트랜스포머 아키텍쳐의 적용은 한정적이였다.
비전 분야에서, 어텐션(attention)은 컨볼루션 네트워크(CNNs)와 함께 적용되거나, 컨볼루션 네트워크의 전체적 구조는 유지하면서 특정 컴포넌츠만을 대체하는 데 사용되었다.
본 논문에서는 이러한 컨볼루션 네트워크 의존이 필수가 아니며, pure transformer를 image patches의 시퀀스에 다이렉트하게 적용하는 것이 이미지 분류 태스크에서 상당히 좋은 성능을 낸다는 것을 입증한다. Vision Transformer(ViT)가 많은 양의 데이터로 사전학습하고 multiple mid-sized 또는 small image recognition benchmarks(ImageNet, CIFAR-100, VTAB 등과 같은) 전이되었을 때, SOTA 컨볼루션 네트워크보다 훈련에 필요한 연산량이 크게 감소하면서도, 성능이 매우 훌륭하다.
Introduction
셀프 어텐션(self-attention) 기반 구조는 특히 트랜스포머(Transformer)에서 자연어 처리(NLP)의 모델 중 하나로 자리잡았다. 자연어 처리에서 dominant approach는 (Devlin et al., 2019) 대형 텍스트 코퍼스(corpus)에서 사전학습하여 smaller task-specific dataset에 파인튜닝하는 것이다. Transformer의 연산 효율성과 확장성(scalability) 덕분에, 100B 파라미터 이상의 전례없는(unprecedented) 크기의 모델을 훈련하는 것이 가능해졌다. 모델과 데이터셋이 계속 성장하면서, 현재까지 퍼포먼스 포화(saturation)의 징조는 보이지 않는다.
하지만, computer vision에서는 컨볼루션 구조가 여전히 우세했다(LeCun et al., 1989; Krizhevsky et al., 2012; He et al., 2016). NLP의 성공에 자극받아, CNN-like 구조를 셀프 어텐션과 결합하는 연구가 많이 수행되었고, 일부 연구에서는 컨볼루션을 완전히 대체하기도 했다.
그러나, 컨볼루션을 완전히 대체하는 모델은 이론상(theoretically)으로 효율적이었음에도, 특수한 어텐션 패턴의 사용 때문에 현대 하드웨어 가속기에서는 아직까지 효율적으로 작용하지 못했다. 따라서, 대규모의 image recognition에서 클래식한 ResNet-like 구조가 여전히 SOTA 구조이다 (Mahajan et al., 2018; Xie et al., 2020; Kolesnikov et al., 2020).
자연어 처리에서 트랜스포머의 성공적인 scaling에 영감을 받아, 본 연구에서는 가능한 극소량의 변형만을 거친 표준 트랜스포머 모델을 이미지에 다이렉트하게 적용하는 실험을 진행한다. 본 실험 진행을 위하여, 이미지를 패치(patches) 단위로 분리하고 이러한 패치의 선형 임베딩 시퀀스를 입력으로 하여 트랜스포머 모델에 전달한다. 이미지 패치는 자연어 처리에서 워드 토큰(word token)과 같은 방식으로 취급된다. 그리고 이미지 분류 모델을 지도학습 방식으로 학습시킨다.
ImageNet과 같은 mid-sized dataset에 강한 규제(regularization) 없이 훈련시킬 때, 이러한 모델은 비슷한 크기의 ResNet보다 몇 %정도 낮은 정확도를 보인다. 이러한 현상이 겉보기에 실망스러운 결과를 예상되게 한다 : 트랜스포머는 CNN에 내재되어 있는 translation equivariance, locality와 같은 inductive bias(귀납 편향)가 일부 부족하고, 따라서 충분한 양의 데이터로 학습되지 않으면 일반화가 어렵다.
그러나, 모델이 더 큰 데이터셋(14M-300M images)으로 훈련된 경우 상황은 바뀐다. 본 논문은 대규모 학습이 inductive bias를 이겨내는 것을 발견한다. 비전 트랜스포머(ViT)는 충분한 규모로 사전학습된 다음 더 적은 양의 데이터포인트를 갖는 태스크에 전이시키면 훌륭한 결과를 얻을 수 있다.
ImageNet-21k 또는 JFT-300M 데이터셋으로 사전학습했을 때, ViT 접근법이 다수의 이미지 인식 벤치마크의 SOTA 성능을 능가하였다. 특히, 최적 모델은 ImageNet에서 88.55%, ImageNet-ReaL에서 90.72%, CIFAR-100에서 94.55%, VTAP의 19개 태스크에서 77.63%의 정확도를 달성했다.
Method
Model Overview
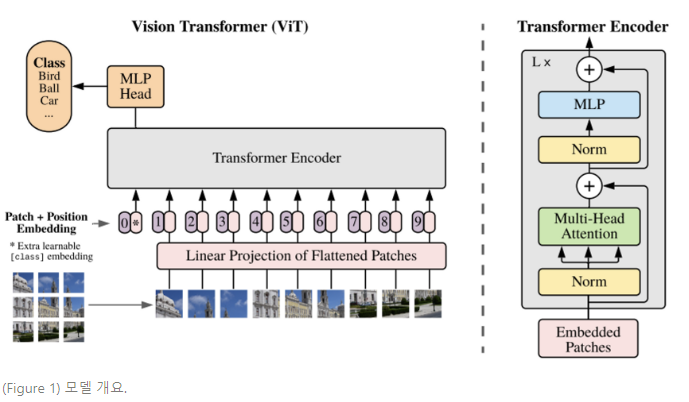
(Model Overview) 이미지를 고정된 크기(fixed-sized)의 패치(patches)로 나누고, 각 패치들을 선형적으로 임베딩하고 position embedding을 더한 다음, 표준 트랜스포머 인코더(encoder)에 벡터의 최종적인 출력 시퀀스를 피딩한다. 분류를 수행하기 위해 추가적으로 훈련이 가능한 “분류 토큰”을 시퀀스에 더하는 방식의 표준 접근법을 사용한다. 트랜스포머 인코더의 설명은 Vaswani et al. (2017).을 참고한다.
Vision Transformer(ViT)
표준 트랜스포머는 1D 토큰 임베딩(token embeddings) 시퀀스를 입력으로 받는다. 2D 이미지를 다루기 위해, 이미지를 flattened 2D 패치 시퀀스로 reshape한다.
→ (origin image to sequence of flattened 2D patches)
여기서 는 원본 이미지의 해상도(resolution), 는 채널의 수, 는 각 이미지 패치의 해상도, 는 최종 패치의 수로, 트랜스포머의 효과적인 입력 시퀀스 길이가 된다.
트랜스포머는 모든 레이어에서 constant latent vector size 를 사용하고, 따라서 패치를 flatten하고 trainable linear projection (Eq. 1)로 차원에 사상한다. 이러한 projection의 출력을 패치 임베딩(patch embedding)이라 한다.
BERT의 토큰과 유사하게, 학습가능한 임베딩은 임베딩 패치 시퀀스 ( ) 의 앞에 붙게 되는데, 이러한 상태는 트랜스포머 인코더()의 출력에서 image representation (Eq. 4)와 같이 작용한다. classification head는 사전학습 시에는 한개의 은닉층과 MLP(Multi-layer Perceptron)로 시행되고, 미세 조정(fine-tuning)시에는 단일 선형 레이어(single linear layer)로 시행된다.
위치 임베딩(Position Embedding)은 위치 정보를 유지하기 위해 패치 임베딩에 추가된다. 본 논문에서는 learnable한 표준 1D 위치 임베딩을 사용하는데, 이는 advanced 2D-aware 위치 임베딩을 사용하는 것과 중대한 퍼포먼스 차이가 관측되지 않았기 때문이다. 임베딩 벡터의 최종 시퀀스는 인코더의 입력이 된다.
트랜스포머 인코더(Transformer encoder)는 멀티헤드 셀프 어텐션(multiheaded self-attention)과 MLP blocks의 alternation layers로 구성된다 (Eq. 2,3). Layernorm(LN)은 모든 블록 앞에서 적용되고, 모든 블록 후에 잔차 연결(residual connection)이 적용된다.
MLP는 GELU non-linearity 2 layers를 갖는다.
(1)
(2)
(3)
(4)
- Inductive bias
비전 트랜스포머가 CNNs보다 image-specific한 귀납 편향이 훨씬 적다는 것에 주목한다. CNNs에서, 지역성(localtiy), 2차원 인접 구조(2-dimensional neighborhood structure)와 번역 등변(translation equivariance)는 전체 모델에 걸쳐 각 레이어에 포함된다. ViT에서는 MLP 레이어만 지역적(local)이고 translationally equivariant하며, 셀프 어텐션 레이어는 전역적(global)이다. 2차원 인접 구조는 매우 드물게(sparingly) 사용된다.
모델의 시작점에서는 이미지를 패치로 분리하면서 2차원 인접 구조가 사용되고, 미세조정 시에는 다양한 해상도의 이미지에 대한 위치 임베딩을 조정하기 위해 사용된다. 그 외에도, 초기화 시에 위치 임베딩이 패치의 2D 위치에 대한 정보를 갖고있지 않고 패치 간의 공간적 관계가 처음부터 학습되어야 할 때 사용된다.
- Hybrid Architecture
raw image patch에 대한 대안으로, 입력 시퀀스는 CNN의 특성 맵에서 형성될 수 있다. 하이브리드 모델에서, 패치 임베딩 projection (Eq. 1)는 CNN 특성 맵에서 추출된 패치에 적용된다. 특정한 경우에, 패치는 공간 크기 1x1을 가질 수 있는데, 이는 단순히 특성 맵의 공간적 차원을 flattening하고 트랜스포머 차원으로 projecting함으로써 입력 시퀀스를 얻을 수 있다는 것이다.
Conclusion
본 연구는 트랜스포머를 이미지 인식 태스크에 직접적으로 적용하는 과정을 탐구하였다. 컴퓨터 비전 분야에 셀프 어텐션을 사용한 선행 연구들과는 달리, 본 논문에서는 initial patch와 extraction step을 제외하면 image-specific한 귀납 편향을 네트워크 구조에 반영하지 않는다. 대신, 이미지를 패치 시퀀스로 해석하여, NLP에서처럼 표준 트랜스포머 인코더를 통해 처리한다. 이러한 단순하면서도 확장성 있는 방법은 대규모의 데이터셋에서 사전학습과 더불어 사용되었을 때 상당히 잘 작용한다. 그러므로, 비전 트랜스포머가 많은 이미지 분류 데이터셋의 SOTA 모델들과 필적하거나 그들을 뛰어넘으면서도, 사전학습 비용을 상대적으로 절감할 수 있다.
이러한 초기 결과가 희망적임에도, 많은 어려움들이 여전히 남아 있다. 한 가지는 ViT를 detection이나 segmentation과 같은 다른 컴퓨터 비전 태스크에 적용하는 것이다. 본 논문의 결과는 Carion et al. (2020)의 연구와 더불어 이러한 접근법이 유망하다는 것을 보여준다. 또 다른 어려움은 자가지도 사전학습(self-supervised pretraining) 방법을 계속 탐구해야 한다는 것이다. 본 연구의 초기 실험은 자기지도 사전학습의 향상점을 보여주었으나, 자가지도학습과 대규모 지도 사전학습 간에는 여전히 큰 갭이 존재한다. 마지막에는, ViT의 확장성이 더 향상된 성능을 가져올 지도 모른다.

"패치 간의 공간적 관계가 스크래치에서 학습되어야 할 때 사용된다." 라고 하셨는데 from scratch 는 처음부터 라는 의미입니다. 저도 스크래치가 뭐지? 싶어서 찾아보고 알았네요 ㅎㅎ