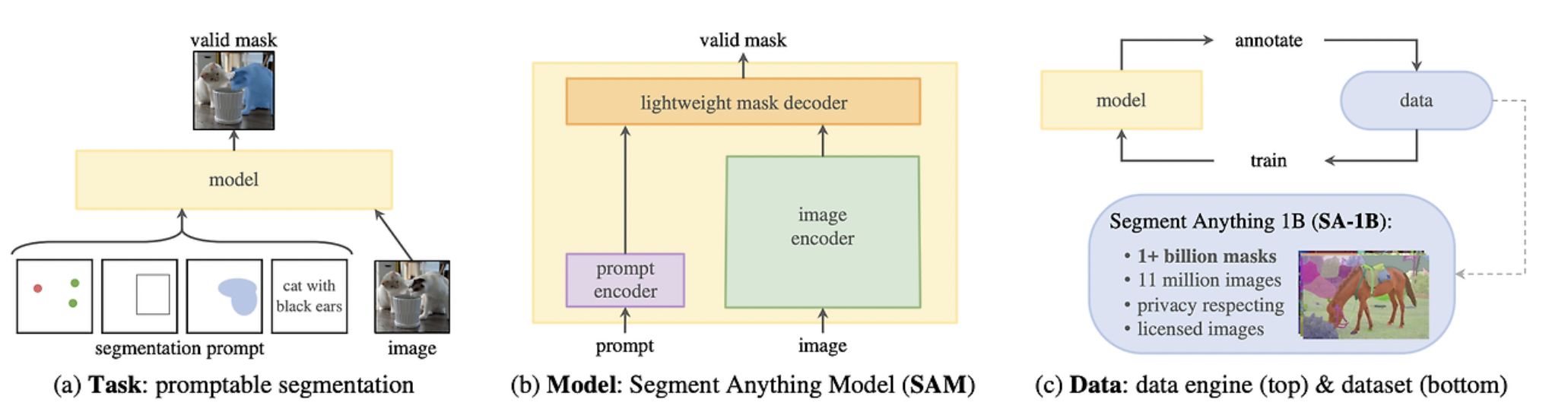
-1. 논문 개요
- NLP의 GPT 같은, CV의 foundation model을 만들자! (zero-shot transfer)
- NLP의 거대한 capability는, prompt engineering으로 구현되는 편이다.
- CV의 foundation model을 위해, 아래 3가지 제안
- 충분히 보편적인 CV task 정의
- flexible prompting을 지원하는 model
- 거대한 dataset 생성
-1.1. task

- 이 중에서 1개는 반드시 실제 유저의 의도와 일치해야 한다.
- LLM이 다중의미의 prompt에도 일관성 있는 대답을 하는 것처럼,
- SAM 모델도 일관된 답을 해야하기 때문에 이러한 task 정의가 필요하다.
- 이런 task가 자연스러운 pre-training 알고리즘으로 이끌고,
- downstream에 대하여 보편적으로 작용하게 한다.
-1.2. pre-training
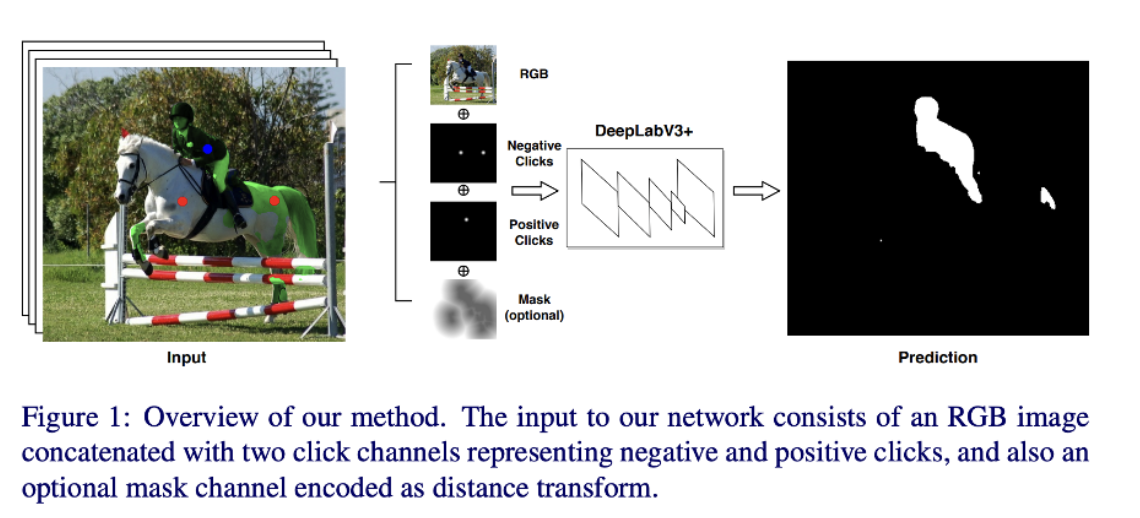
- interactive segmentation: 사용자 클릭을 사용하여 CNN을 트레이닝 시키는 방법
- 즉 사람이 'green point'와 'red point'를 사용해서 특정 부분을 마스크가 맞다 아니다를 알려준다.
0. 중요 포인트
text를 입력으로 주고, 거기에 맞는 segment mask를 주는 code는 찾지 못했는데, 추가된게 있나 확인해봐야함.- box나 Point를 input prompt로 주면, 거기에 맞는 segment mask를 어떤 기준으로 출력하나?
- 데이터셋에 표시된 대로..!
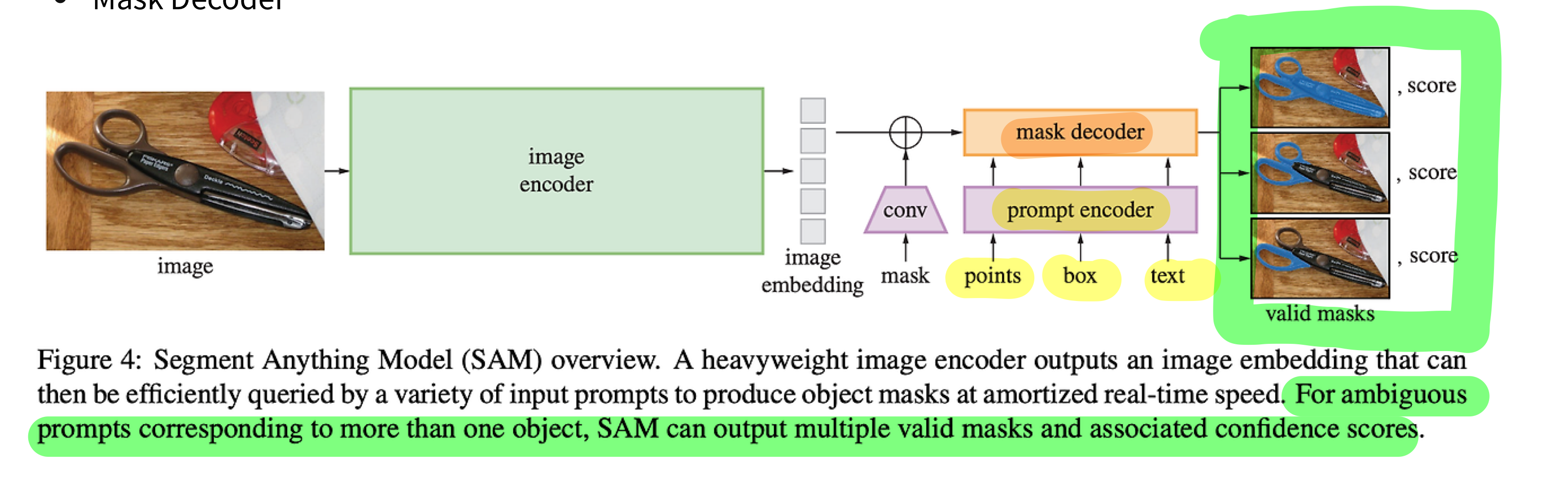
1. Image Encoder
- 연산량 많음
Masked Autoencoder(MAE) pre-trained ViT를 사용Masked Autoencoder(MAE)Vision Transformer
2. Prompt Encoder
- 연산량 매우 적음
- prompt 종류
- sparse point
- 점 points
- 점 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding
(batch, 1, embed_dim) - 해당 Pixel (r,g,b)를 임베딩한 learned embeddings
(batch, 1, embed_dim)
- 점 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding
- 박스 boxes
- 박스의 꼭지점 2개 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding
(batch, 2, embed_dim) - 해당 Pixel (r,g,b) 2개를 임베딩한 learned embeddings
(batch, 2, embed_dim)
- 박스의 꼭지점 2개 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding
- 텍스트 text: CLIP network의 output
- 점 points
- sparse point
어떤 prompt를 주던, mask만 생성하지, label은 생성하지 않음!!- 데이터셋이 어떻게 라벨링 되어있는지에 따라, 어떤 label을 알아서 mask할지가 결정됩니다.
- 예: box를 prompt로 줬는데, 그 box 안에 어떤 물체를 mask할 것인가?
- 데이터셋에 라벨링 된 대로. (box-mask pair)
- 예: box를 prompt로 줬는데, 그 box 안에 어떤 물체를 mask할 것인가?
- 데이터셋이 어떻게 라벨링 되어있는지에 따라, 어떤 label을 알아서 mask할지가 결정됩니다.
3. Mask Decoder
- 연산량 매우 적음
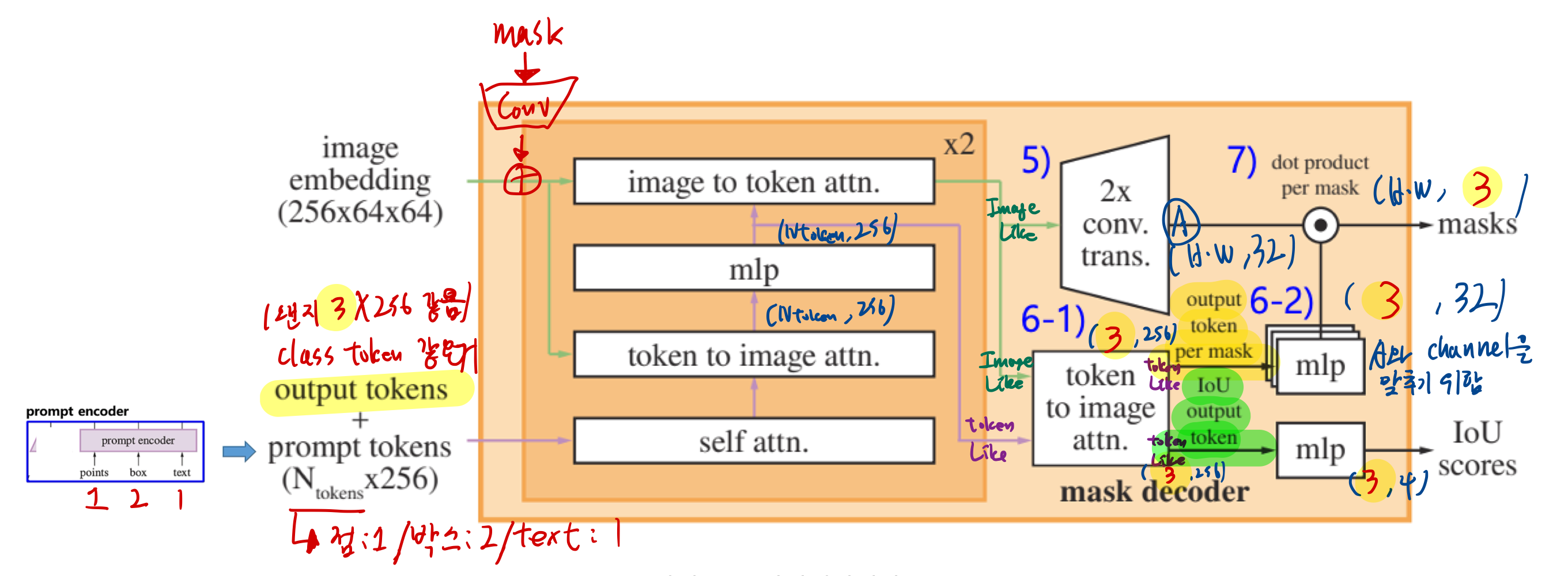
3.1. Resolving Ambiguity
- 사람 손톱이 있는 픽셀에 점을 찍었을 떄, 어떤 mask를 얻고 싶은지는 알기 어려움
- 손톱을 얻고 싶은건지
- 손을 얻고 싶은건지
- 사람을 얻고싶은건지
- 논문에서는, 위 네트워크 구조의 output인 mask가 3개의 후보에 대한 mask를 추출하도록 합니다.
- 그 중 minimum loss를 갖는 mask에 대해 backprop한다고 합니다.
3.2. Loss and Training
- 선형 조합 of
focal lossanddice lossfocal loss: 더 어려운 객체에 대해 가중치를 주어 학습한다.dice loss: IOU보다 더 recall에 집중한 개념 (예측 mask가 GT mask를 최대한 많이 포함할수록 무조건 좋은 metric)
4. Dataset? (중요하지 않음)
- Segmentation mask가 인터넷에 풍부하지 않기 때문에 저자들은 11억 개의 마스크 데이터셋인 SA-1B를 수집할 수 있는 데이터 엔진을 구축했다. - 데이터 엔진은 세 단계로 구성된다.
Model-assisted 주석을 사용하는 수동 단계자동으로 예측된 마스크와 model-assisted 주석이 혼합된 반자동 단계완전 자동 단계
- 모델은
주석 입력 없이마스크를 생성한다.
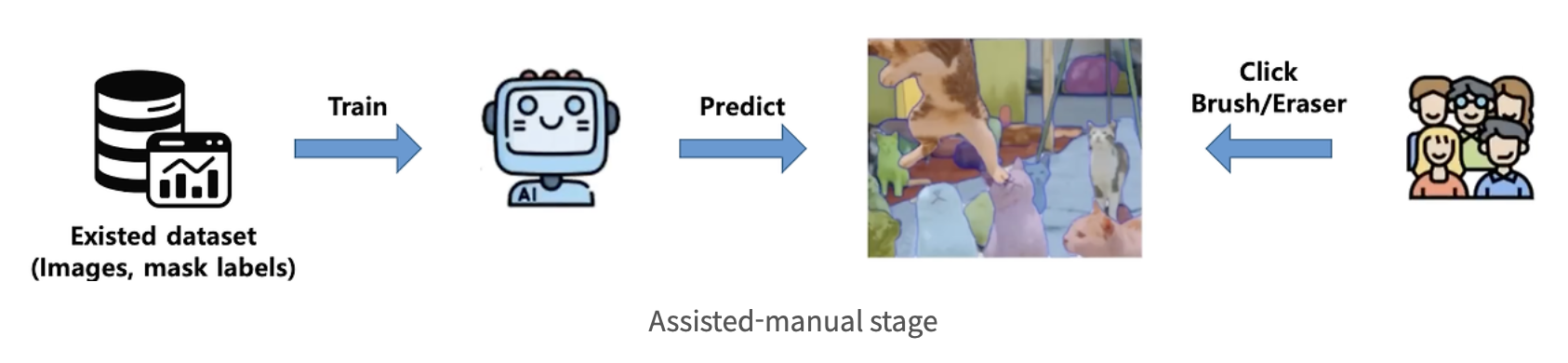
4.1. Assisted-manual stage
-
-
이 단계의 시작에서 SAM은 공개된 segmentation 데이터셋을 사용하여 학습을 받았다.
-
첫 번째 단계에서는 고전적인 interactive segmentation과 유사하며,
- 전문 주석 팀이 SAM에서 제공하는 브라우저 기반 interactive segmentation 도구를 사용하여
- 전경/배경 개체 지점을 클릭하여 마스크에 레이블을 지정
- 픽셀 정밀 “브러시”와 “지우개” 도구를 사용하여 마스크를 다듬을 수 있다.
- Model-assisted 주석은 사전 계산된 이미지 임베딩을 사용하여 브라우저 내에서 직접 실시간으로 실행되어 진정한 상호 작용하는 경험을 가능하게 한다.
- 전문 주석 팀이 SAM에서 제공하는 브라우저 기반 interactive segmentation 도구를 사용하여
-
저자들은 개체에 레이블을 지정하는 데 의미론적 제약을 부과하지 않았으며, 주석자는 “물건”과 “사물” 모두에 자유롭게 레이블을 지정했다.
-
충분한 데이터 주석 후 SAM은 새로 주석이 달린 마스크만 사용하여 재학습되었다.
-
더 많은 마스크가 수집됨에 따라 이미지 인코더가 ViT-B에서 ViT-H로 확장되었으며 기타 아키텍처 세부 사항이 발전했다.
-
총 6번 모델을 재학습했다.
-
모델이 개선됨에 따라 마스크당 평균 주석 시간이 34초에서 14초로 감소했으며, 이미지당 평균 마스크 수가 20개에서 44개 마스크로 증가했다.
-
전반적으로 이 단계에서 12만 개의 이미지에서 430만 개의 마스크를 수집했다.
Semi-automatic stage
- 이 단계에서 저자들은 모델이 무엇이든 분할하는 능력을 향상시키기 위해 마스크의 다양성을 높이는 것을 목표로 했다.
- 눈에 잘 띄지 않는 물체에 주석 작성자의 초점을 맞추기 위해 먼저 신뢰할 수 있는 마스크를 자동으로 감지한다.
- 그런 다음 이러한 마스크로 미리 채워진 이미지를 주석 작성자에게 제공하고 추가로 주석이 지정되지 않은 개체에 주석을 달도록 요청했다.
- 신뢰할 수 있는 마스크를 감지하기 위해 일반적인 “객체” 범주를 사용하여 모든 첫 번째 단계 마스크에서 boundary box detector를 학습했다.
- 이 단계에서 18만 개의 이미지에서 590만 개의 마스크를 추가로 수집했으며 (총 1020만 개의 마스크), 새로 수집된 데이터에 대해 주기적으로 모델을 재학습했다 (5회).
- 마스크당 평균 주석 시간이 최대 34초로 되돌아갔으며 (자동 마스크 제외), 이러한 개체는 레이블을 지정하기가 더 어려웠기 때문이다.
- 이미지당 평균 마스크 수는 자동 마스크를 포함하여 44개에서 72개로 증가했다.
Fully automatic stagePermalink
- 마지막 단계에서 주석은 완전히 자동으로 이루어진다. 이는 모델의 두 가지 주요 개선 사항으로 인해 가능했다.
- 첫째, 이 단계를 시작할 때 이전 단계의 다양한 마스크를 포함하여 모델을 크게 개선할 수 있는 충분한 마스크를 수집했다.
- 이 단계에서 모호한 경우에도 유효한 마스크를 예측할 수 있는 모호성 인식 모델을 개발했다.
- 구체적으로, 32×32 regular grid의 점으로 모델을 유도했고 각 점에 대해 유효한 객체에 해당할 수 있는 마스크 세트를 예측했다.
- 모호성 인식 모델을 사용하면 점이 부분 또는 하위 부분에 있으면 모델이 하위 부분, 부분 및 전체 개체를 반환한다.
- 모델의 IoU 예측 모듈은 신뢰할 수 있는 마스크를 선택하는 데 사용된다.
- 또한 안정적인 마스크만 식별하고 선택한다. 마지막으로 자신 있고 안정적인 마스크를 선택한 후 Non-Maximal Suppression (NMS)를 적용하여 중복을 필터링한다.
- 더 작은 마스크의 품질을 더욱 향상시키기 위해 여러 개의 겹치는 확대 이미지 crop도 처리하였다.
- 데이터셋의 모든 1,100만 개 이미지에 완전 자동 마스크 생성을 적용하여 총 11억 개의 고품질 마스크를 생성했다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것