[2021 ICML] (CLIP) Learning Transferable Visual Models From Natural Language Supervision
[Paper Review] VLM to LMM


Abstract
(문제 제기)
- SOTA computer vision systems은 a fixed set of predetermined object categories를 predict하도록 학습된다.
이렇게 제한된 형태의 supervision은 또 다른 visual concept(시각적 개념)을 인식하게 하려면 추가의 labeled data가 필요하기 때문에,
model의 generality and usability(활용성)을 떨어뜨린다.
(내가 이해한 내용: 즉, down-stream task에 zero-shot transfer하기 힘들다.)
(제안)
-
image에 대한 raw text로부터 직접 learning하는 방법은 much broader source of supervision을 활용할 수 있는 a promising alternative이다.
우리는 "어떤 caption이 어떤 image에 할당되어야 하는지 예측하는 simple pre-training task"가
internet에서 수집한 400M개의 (image, text) pairs로부터 SOTA image representation을 학습하는 an efficient and scalable 방법임을 보인다. -
Pre-training 이후에는 natural language를 사용하여 learned visual concepts을 참조하거나, 새로운 visual concepts을 설명할 수 있으며,
이를 통해 downstream tasks에 zero-shot transfer가 가능해진다.
(실험)
- 우리는 OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification 등 30개 이상의 CV datasets에서 성능을 평가했다.
model은 대부분의 task에 대해 dataset specific training 없이도 a fully supervised bsaeline과 competitive한 결과를 얻었다.
예를 들어, ImageNet에서 1.28M개의 training examples 중 단 한 장의 train data도 사용하지 않고, 원래 ResNet-50이 달성한 accuracy에 zero-shot으로 도달했다.
https://github.com/OpenAI/CLIP
1. Introduction and Motivating Work
(background: NLP에서 raw text로부터 pre-training하는 방식이 zero-shot transfer를 가능하게 함.)
- 지난 몇 년간 NLP에서는 raw text로부터 directly 학습하는 pre-training methods가 진화되어왔다.
standardized input-output interface로써, the development of "text-to-text"는
task-agnostic architecture들이 별도의 학습 없이도 다양한 downstream datasets에 zero-shot transfer를 가능하게 했다.
GPT-3 같은 Flagship system은 이제 거의 모든 task에서 bespoke(맞춤형) model들과 경쟁할 수준의 성능을 보이며, specific training data이 필요없다.
(background: CV에서도 web text로부터 pre-training하는게 breaktrough가 될 수 있을까?)
- 이러한 결과들은,
pre-training methods가 활용할 수 있는 supervision이
기존의 high-quality crowd-labeled NLP datasets에서 얻을 수 있는 것보다
web-scale의 collections of text에서 얻을 수 있는게 더 크다는 것을 시사한다.
그러나, CV에서는 여전히 ImageNet 같은 crowd-labeled datasets을 사용해 pre-training하는 것이 standard practice(표준적인 관행)이다.
그렇다면 "web text로부터 직접 학습하는 scalable pre-training methods가 CV에서도 a similar breakthrough로 가져올 수 있을까?"
(related works: CV에서도 text로부터 image representation을 학습할 수 있음을 꾸준히 보여왔다)
- Joulin et al. (2016)은 image caption 속 단어를 예측하도록 CNN을 학습시키는 것만으로도 ImageNet training과 경쟁 가능하다는 것을 보였다.
Li et al. (2017)은 이를 확장해 단어뿐 아니라 구(phrase) n-gram(n개의 연속 단위로 묶어 표현한 것)까지 예측하도록 만들었고, 이를 통해 다른 image classification datasets에 zero-shot transfer가 가능함을 보여줬다.
최근에는 VirTex (Desai & Johnson, 2020), ICMLM (Sariyildiz et al., 2020), ConVIRT (Zhang et al., 2020)가
text로부터 image representations을 학습하기 위해
각각 Transformer-based language modeling, masked language modeling, and contrastive objectives 등의 potential을 입증했다.
(limitation of related works: CV에서도 text로부터 image representation을 학습할 수 있음을 꾸준히 보여왔지만, scale이라는 중요한 차이가 있다.)
- 그러나 이러한 model들은 여전히 SOTA CV model들, 예를 들어 Big Transfer (Kolesnikov et al., 2019)나 weakly supervised ResNeXt (Mahajan et al., 2018)보다는 성능이 낮았다.
여기에는 규모(scale)라는 중요한 차이가 있다.
Mahajan et al. (2018)과 Kolesnikov et al. (2019)은 millions~billions개의 image로 수 년 단위의 TPU/GPU 학습을 진행한 반면,
VirTex, ICMLM, ConVIRT는 10만 ~ 20만 장의 image로 며칠 간의 학습만 진행했다.
(내가 이해한 scale 차이: 기존 SOTA vision model은 수억~수십억 장으로 매우 긴 시간 학습했지만, natural language supervision-based 연구들은 적은 data로 매우 짧은 시간 학습. 즉, 훨씬 작은 scale
이전의 natural language 기반 image model들은 데이터량/학습량이 너무 적어서 SOTA vision model에 못 미쳤다.)
(method: ConVIRT=natural language supervision 기반 image model의 scale을 높혀 scratch부터 training해서 다양한 task로 zero-shot transfer가 가능한 model을 만들겠다.)
- 본 연구에서는 이 scale gap을 해소하고,
natural language supervision at large scale로 image models을 학습할 때 나타나는 behaviors를 조사한다.
우리는 a simplified version of ConVIRT를 scratch부터 다시 학습한 model을 제안하는데,
이를 CLIP(Contrastive Language-Image Pre-training)이라고 부른다.
CLIP은 natural language supervision으로부터 learning하는 an efficient and sclable method이다.
(experiments)
- CLIP은 pre-training 과정에서 이미 OCR, geo-localization, action recognition 등 a wide set of tasks를 자연스럽게 습득하며,
the best publicly available ImageNet model보다 outperform하면서도 computationally efficient하다.
또한 zero-shot CLIP model은 동일한 accuracy를 갖는 supervised ImageNet models보다 훨씬 robust함을 확인했다.
2. Approach
2.1. Creating a Sufficiently Large Dataset
-
기존 연구들은 주로 three datasets, MS-COCO, Visual Genome, and YFCC100M을 사용했다.
MS-COCO and Visual Genome은 high quality crwod-labeled dataset이지만,
각각 약 10만 장의 train image밖에 되지 않아 modern standards(현대 기준)에 비하면 너무 적다.
비교하자면, 다른 CV systems들은 3.5 billion Instagram photos를 사용해 학습되기도 한다.
YFCC100M은 100M photos로 a possible alternative이지만, image마다 붙어있는 metadata가 sparse하고 quality도 일정하지 않다.
많은 이미지들이 "20160716_113957.JPG" 처럼 자동으로 생성된 filenames을 "title"로 사용하거나 camera exposure setting과 같은 정보가 "description"에 포함되어 있는 경우도 있다.
그래서 natural language(English)로 쓰인 titles and/or descriptions이 있는 image들만 남기도록 filtering을 적용한 결과,
dataset size가 6배 줄어 15M 장의 photo만 남게되었다.
이는 ImageNet과 거의 동일한 size이다. -
natural language supervision을 하는 주요 motivation은
internet에 공개적으로 존재하는 large quantities of data of this form(image, text) 덕분이다.
이를 test하기 위해 우리는 Internet에서 공개된 다양한 sources로부터 400M(4억)개의 (image, text) pairs로 이루어진 a new dataset을 구축했다.
가능한 한 폭넓은 a set of visual concepts를 포함하기 위해, data 구성 과정에서 text가 500,000개의 queries 중 하나 이상을 포함하는 (image, text) pairs로 검색했다.
그리고 query마다 최대 20,000개의 (image, text) pairs를 포함하도록 하여, 대략적으로 class를 balance하게 만들었다.
최종적으로 생성된 dataset은 GPT-2 학습에 사용된 WebText dataset과 유사한 총 단어 수를 갖는다.
우리는 이 dataset을 WIT(WebImageText)라고 부른다.
2.2. Selecting an Efficient Pre-Training Method
(text transformer의 학습이 비효율적인 문제가 있다.)
- 우리의 초기 접근방식도 VirTex와 유사하게,
image CNN과 text transformer를 scratch부터 jointly training시켜
the caption of an image를 predict하는 방식이었다.
그러나 우리는 이 방법을 효율적으로 scaling하는 데 어려움을 겪었다.
(초기 방식이 BoW Prediction 방식에 비해 3배 느렸다.)
- Figure 2에서 보여주듯,
(image encoder인 ResNet50보다 2배 많은 연산량을 사용하는) 63M개의 parameter를 갖는 transformer language model은
동일한 text에 대해 bag-of-words encoding을 예측하는 Joulin et al. (2016)의 방식과 비교했을 때,
ImageNet class 인식하는 것을 3배 더 느리게 학습했다..
- (참고) bag-of-words prediction, BoW prediction?:
caption에 들어갈 정확한 한 단어를 예측하는게 아니라, 등장할 단어들의 집합을 예측하는 방식.
예를 들어, "고양이가 잔디 위에 앉아 있다."와 "잔디 위에 고양이 한 마리가 있다."라는 두 문장은
서로 단어 순서만 다르지, 단어 집합을 동일하므로 이 둘을 같은 의미의 데이터로 간주함.- 기존에는 왜 BoW prediction을 썼는가?
- 문장 전체를 prediction(captioning)하는 것보다 쉽고 빠름.
- text 순서 modeling이 필요 없어 효율적
- 단어 출현 여부 ("cat", "grass", "sitting")만 맞추면 되어 large-scale 학습 가능
- image와 text 간 semantic alignment 유효
- 기존에는 왜 BoW prediction을 썼는가?
여기까지 내가 이해한 내용:
처음에는 caption의 정확한 한 단어를 예측하는 방식 (VirTex)이었는데,
이 방식은 단어 집합 예측하는 방식 (bag-of-words prediction)보다
ImageNet class 인식에 걸리는 학습 시간이 3x 더 걸림.
그래서 BoW prediction(주황)을 baseline으로 설정.
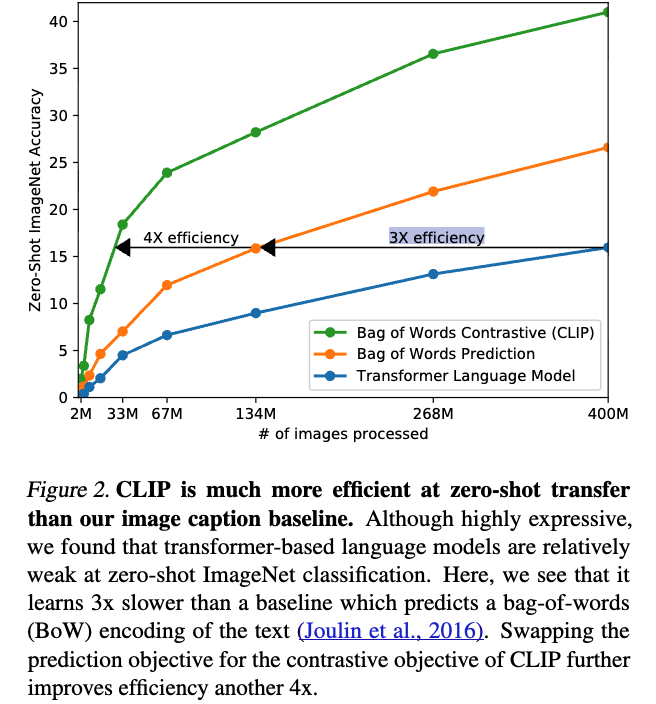
(prediction objective를 contrastive objective로 교체하자, BoW Prediction 방식에서 4x 빨라졌다.)
- 최근 contrastive representation learning 연구에서는
contrastive objectives가 그에 대응하는 prediction objective보다 outperform할 수 있다는 결과가 보고되었다.
이 발견에 주목하여, 우리는 text의 정확한 단어를 prediction하는 것 대신, 어떤 text 전체가 어떤 image와 paired되는지만 예측하는,
잠재적으로 더 쉬운 proxy task를 해결하도록 system을 train하는 방식을 연구했다.
(내가 이해한 내용: image와 text가 서로 pair인지 아닌지만 맞추도록 contrastive learning을 이용해 학습했다는 의미인듯.)
처음에는 동일한 bag-of-words encoding baseline을 사용했지만,
Figure 2에서 보이듯, predictive objective를 contrastive objective로 교체하자
ImageNet에 대한 zero-shot transfer 속도에서 추가적으로 4x efficiency improvement를 관찰했다.
여기까지 내가 이해한 내용:
BoW prediction에서 predictive objective를 constrastive objective로 바꿨더니 ImageNet zero-shot transfer 속도가 4배 빨라짐. (초록색)
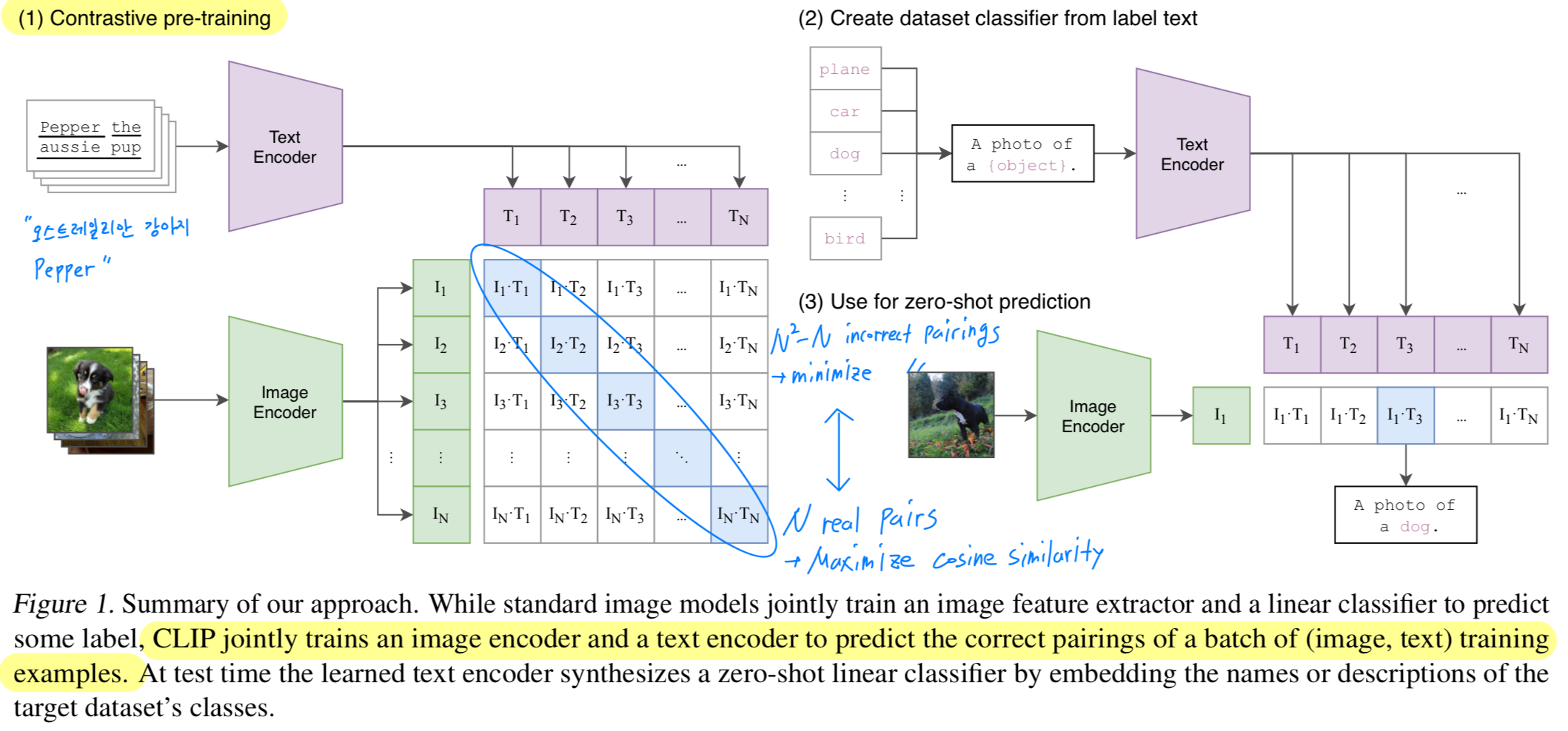
(실제로 어떻게 구현했는가?)
- 개의 (image, text) pairs로 구성된 batch가 주어졌을 때,
CLIP은 해당 batch에서 가능한 개의 (image, text) pairings 중에서
실제로 pairing될 pair가 무엇인지 예측하도록 train된다.
이를 위해, CLIP은 image encoder와 text encoder를 jointly training시켜 multi-modal embedding space를 학습한다.
이 과정에서 batch 내 개의 real pairs에 대한 image embedding과 text embedding의 cosine similarity를 maximize하는 동시에,
개의 incorrect pairings에 대한 cosine similarity를 minimize하도록 학습한다.
우리는 이 similarity scores에 대해 a symmetric cross entropy loss를 optimize한다.
(symmetric cross entropy loss는 Figure 3에 나옴)
- Figure 3에는 pseudocode for the code of an implementation of CLIP을 포함한다.
이 batch construction techniques and objective는 Sohn (2016)에 의해
multi-class -pair loss로 처음 소개되었으며,
최근 Zhang et al. (2020) (본 논문 초반에 말한 ConVIRT)에 의해 the domain of medical imaging의 contrastive (text, image) representation learning에 적용되었다.

정리하자면, 아래와 같은데...
(내 생각) pseudo code에서
axis=0 기준으로 cross_entropy_loss 구하는게 loss_t (text-to-image contrastive loss)로 바뀌고,
axis=1 기준으로 cross_entropy_loss 구하는게 loss_i (image-to-text contrastive loss)로 바껴야
figure에 맞는 설명인 것 같음...
추가로,
CLIP에서 loss_i = ConVIRT에서 image-to-text contrastive loss
CLIP에서 loss_t = ConVIRT에서 text-to-image contrastive loss

- over-fitting은 큰 우려사항이 아니기 때문에, CLIP 학습 과정의 details은 Zhang et al. (2020)(ConVIRT)보다 단순화되었다.
(ConVIRT 학습에서 단순화된 것)- CLIP은 pretrained weights로 initializing하지 않고 scratch로 training한다.
- 또한, representation embedding space와 contrastive embedding space 사이의 non-linear projection을 제거하고,
각 encoder's representation을 multi-modal embedding space로 mapping하는 only a linear projection만 사용. - text에서 a single sentence를 uniform하게 sampling하는 the text transformation function 도 제거했는데,
이는 CLIP의 pre-training dataset(WIT)에서 많은 (image, text) pairs가 only a single sentence로 이루어져 있기 때문이다. - image transformation function 도 simplify했다.
resized images로부터 random crop을 수행하는 data augmentation만 학습에 사용했다. - 마지막으로, softmax logit의 range를 조절하는 temperature parameter 는 학습 동안에
log-parameterized된 multiplicative scalar(곱셈을 수행하는 scalar?)로 직접 optimized되어 hyper-parameter로 설정할 필요가 없다.
2.3. Choosing and Scaling a Model
(어떤 image encoder를 골랐고, 어떻게 변형했는가?)
- 우리는 image encoder를 위해 두 가지 다른 architecture를 고려한다.
- 첫 번째로, widespread adoption and proven performance 때문에 ResNet50을 base architecture로 사용한다.
우리는 ResNetD improvements와 Zhang (2019)의 anti-aliased rect-2 blur pooling을 적용하여
original version에 several modifications을 추가한다.
또한 global average pooling layer를 attention pooling mechanism으로 대체한다.
이 attention pooling은 image의 global average-pooled representation에 기반하여 query를 조건부로 생성하는 "transformer-style" QKV attention layer로 구현된다. - 두 번째 arcthiecture로는, 최근 도입된 Vision Transformer (ViT)을 실험한다.
우리는 그들의 구현을 거의 그대로 따르는데, 단 한 가지 작은 수정으로 patch embedding과 position embedding을 결합한 후 transformer에 입력하기 전에 additional layer normalization을 추가하고, 약간(slightly) 다른 initialization scheme을 사용한다.
- 첫 번째로, widespread adoption and proven performance 때문에 ResNet50을 base architecture로 사용한다.
(어떤 text encoder를 골랐고, 어떻게 변형했는가?)
- text encoder는 Radford et al. (2019)에서 설명된 architecture modifications이 적용된 Transformer(Vaswani et al., 2017)이다.
기본 size로 12-layer 512-wide model with 8 attention heads를 사용한다.
이 transformer는 lower-cased (소문자) byte pair encoding (BPE) 기반의 text 표현을 입력으로 사용한다.
text sequence는 [SOS](Start of Sequence인 듯)와 [EOS](End of Sequence인 듯) token으로 감싸며,
transformer의 the highest layer에서 [EOS] token의 activation값을 text의 feature representation으로 사용한다.
이 feature representation은 layer normalization된 후 multi-modal embedding space로 linearly projected된다.
text encoder에서는 Masked self-attention을 사용했는데, 이는 language modeling을 auxiliary objective로 추가할 수 있는 능력을 유지하기 위함이지만, 이에 대한 탐구는 future work로 남겨뒀다.
(image encoder, text encoder 각각에 대해 scaling을 어떻게 했는가?)
- 이전 CV 연구에서는 종종 width or depth를 isolation하여 model을 scaling해 왔다.
반면 우리는 Resnet image encoders에 Tan & Le (2019)의 approach를 채택했으며,
이들은 계산량을 width, depth, and resolution 에 모두 분배하는 것이 한 가지 dimension만 확장하는 것보다 더 우수하다는 것을 발견했다.
우리는 additional compute를 model의 width, depth, and resolution을 동일한 비율로 증가시키는 a simple variant를 사용했다.
text encoder에 대해서는 ResNet에서 계산된 width의 증가 비율에 비례하도록 width만 확장하고 depth는 전혀 확장하지 않았는데,
이는 CLIP 성능이 text encoder의 depth에 크게 민감하지 않았음을 확인했기 때문이다.
2.4. Pre-training
-
우리는 5개 series의 ResNets과 3개 series의 ViT를 학습시킴.
- ResNet에 대해서 ResNet50, ResNet101,
그리고 EfficientNet-style model scaling을 적용해 ResNet50 대비 4x, 16x 그리고 64x 연산량을 가지는 세 모델을 추가로 학습했다.
이들은 각각 RN50x4, RN50x16, RN50x64로 표기한다.
가장 큰 ResNetx64는 592개 V100 GPU에서 18일 걸렸다. - ViT의 경우 ViT-B/32, ViT-B/16, ViT-L/14 세 가지 모델을 학습했다.
가장 큰 ViT는 256개 V100에서 12일이 걸렸다.
ViT-L/14의 경우 FixRes(Touvron et al., 2019)처럼 성능을 향상시키기 336 pixel resolution으로 한 epoch 동안 추가 pre-train을 수행.
이 model은 ViT-L/14@336px로 표기한다.
- ResNet에 대해서 ResNet50, ResNet101,
-
별도로 명시되지 않은 한, 본 논문에서 “CLIP”이라고 지칭하는 결과는 모두 이 model(ViT-L/14@336px 말하는 듯)을 사용하며, 이 model이 best performance를 보였다.
Full model hyperparameters and details는 supplementary material에 있다.
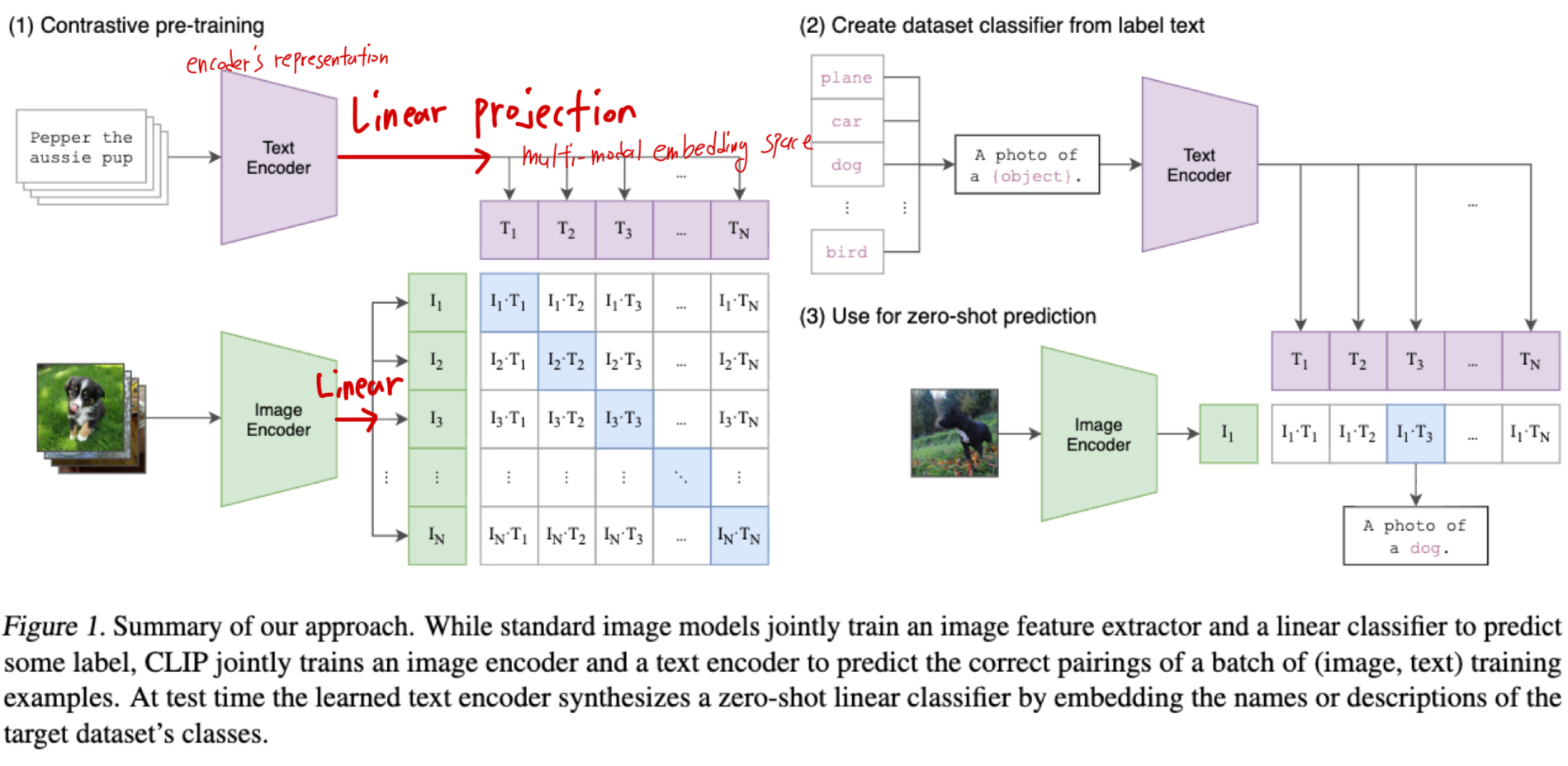
2.5. Using CLIP
-
zero-shot transfer performance = task learning capability 평가
CLIP은 WiT dataset에서 image와 text snippet(조각)이 서로 pair인지 predict하도록 pre-trained되었다.
CLIP을 downstream tasks에 적용하기 위해서, 우리는 이 능력을 reuse하고 CV datasets에서 CLIP의 the zero-shot transfer performance를 평가한다.
Radford et al. (2019)와 비슷하게, 우리는 이를 representation learning capability와는 구별되는 task learning capability를 측정하는 방법으로 본다.
각 dataset마다, 우리는 dataset의 모든 class 이름을 the set of potential text pairings으로 사용하고,
CLIP이 most probable (가장 높은 확률의) (image, text) pair를 예측한다.
(내가 이해한 내용: 아래 그림)

-
또한 CLIP에서 task를 더 명확히 알려주기 위해 text prompots를 제공하는 실험도 수행하며,
-
performance 향상을 위해 multiple of these templates의 ensembling하는 방법도 실험한다.
-
하지만 대부분의 unsupervised and self-supervised computer vision research는 representation learning에 초점을 두고 있기에,
이를 위해서, 우리는 CLIP에 대해서도 일반적으로 사용되는 linear probe protocol을 이용해 representation learning capability 측면을 추가로 조사한다. (?)- (이게 무슨 의미인가? linear probe protocol이 무엇인가?)
기존 unsupervised and self-supervised CV 연구들의 주된 목표는 대규모의 label 없는 데이터로부터 재사용 가능한 고품질의 feature representation을 학습하는 것이다.
그래서 classification 또는 detection 같은 downstream task를 위해 재사용될 때, fine-tuning 없이도 강력한 성능을 내는 것이 중요하다.
그래서 CLIP에서도 feature representation의 quality를 측정하기 위해 Linear probe protocol을 사용했다.
Linear probe protocol은 feature representation의 quality를 측정하기 위한 CV 분야의 표준 benchmark인데,
CLIP의 image encoder를 freeze시키고, 이 freeze된 model에 단순한 linear classifier만 추가하여 ImageNet 같은 dataset에서 supervised learning 방식으로 학습시킴.
여기서 linear classifier의 성능이 높을수록, CLIP이 pretraining 단계에서 image로부터 추출한 feature representation이 이미 얼마나 많은 정보를 갖고 있는지를 의미함.
즉, feature space가 선형적으로 분리 가능할 정도로 잘 구성되어 있는가를 평가하는 것임.
- (이게 무슨 의미인가? linear probe protocol이 무엇인가?)
3.Analysis
3.1. Initial Comparison to Visual N-Grams
-
우리의 지식으로, Visual N-Grams는 위에서 설명한 방식으로 existing image classification dataset에 대한 zero-shot transfer를 처음으로 연구한 작업이다.
또한 우리가 알고 있는 바로, task-agnostic (특정 down-stream task에 맞춰져 있지 않은) pre-trained model을 사용해 standard image classification datasets에서 zero-shot transfer를 연구한 유일한 연구이기도 하다. -
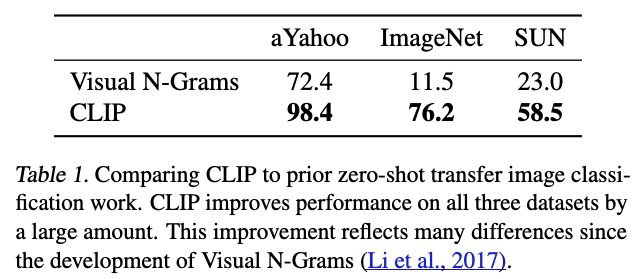
Table 1에서 우리는 Visual N-Grams와 CLIP을 비교한다.
가장 성능이 좋은 CLIP 모델은 ImageNet의 accuracy를 기존의 proof-of-concept 수준인 11.5%에서 76.2%로 향상시켰으며,
1.28M개의 crowd-labeled training examples를 전혀 사용하지 않았음에도 원래의 ResNet50와 비슷한 성능을 달성했다.
이처럼 fully supervised baselien과 zero-shot setting에서 performance가 유사하다는 점은 CLIP이 flexible and practical zero-shot computer vision classifiers로 나아가는 첫 단계임을 시사한다.
다만 이 비교는 완전히 공정한 비교는 아니다.
CLIP과 Visual N-Grams 사이에는 통제되지 않은 여러 차이가 있다.
보다 직접적인 비교를 위해, 우리는 Visual N-Grams가 학습에 사용한 것과 동일한 YFCC100M dataset으로 CLIP ResNet50을 학습시켜봤고,
V100 GPU 하루 분량의 학습으로 그들의 보고된 ImageNet 성능을 재현할 수 있었다.
또한 이 baseline은 Visual N-Grams처럼 pre-trained ImageNet weights를 initialized하는 대신,
scratch에서부터 학습했다.
(직접적인 비교를 어디에 했다는 거지? Table 1은 아니라고 말했는데...)
3.2. Zero-Shot Performance
(우리는 zero-shot learning을 unseen datasets에 대한 generalization 연구로 사용한다.)
- CV에서, zero-shot learning은 보통 image classification에서 unseen object categories에 대한 generalizing 연구를 뜻한다.
하지만 우리는 이 용어를 더 넓은 의미로 사용하며, unseen datasets에 대한 generalization을 연구한다.
우리는 이를 Larochelle et al. (2008)의 zero-data learning paper에서 제안된 것처럼,
보지 못한 태스크(unseen tasks)를 수행하는 능력을 평가하기 위한 proxy(대리 지표)로 motivate한다.
unsupervised learning의 많은 연구는 machine learning systems의 representation learning capability에 초점을 맞추지만,
우리는 zero-shot transfer 성능을 machine learning systems의 task-learning capability를 측정하는 방법으로 본다.
(zero-shot performance를 위한 실험 구성)
- more comprehensive analysis를 위해,
우리는 supplementary material에 자세히 설명되어 있는 a much larger evaluation suite(한 벌)를 구성했다.
총 3개 datasets만 사용했던 Visual N-Grams과 달리, 우리는 30개 이상의 dataset으로 확장하고,
결과를 contextualize하기 위해 50개 이상의 exisiting CV systems과 비교를 수행한다.
(zero-shot performance 실험 결과 분석)
- 우선, 우리는 CLIP's zero-shot classifiers가 얼마나 잘 작동하는지를, a simple off-the-shelf baseline과 비교한다.
baseline model은 canonical ResNet50의 features에 logistic regression classifier를 학습시킨 것이다.
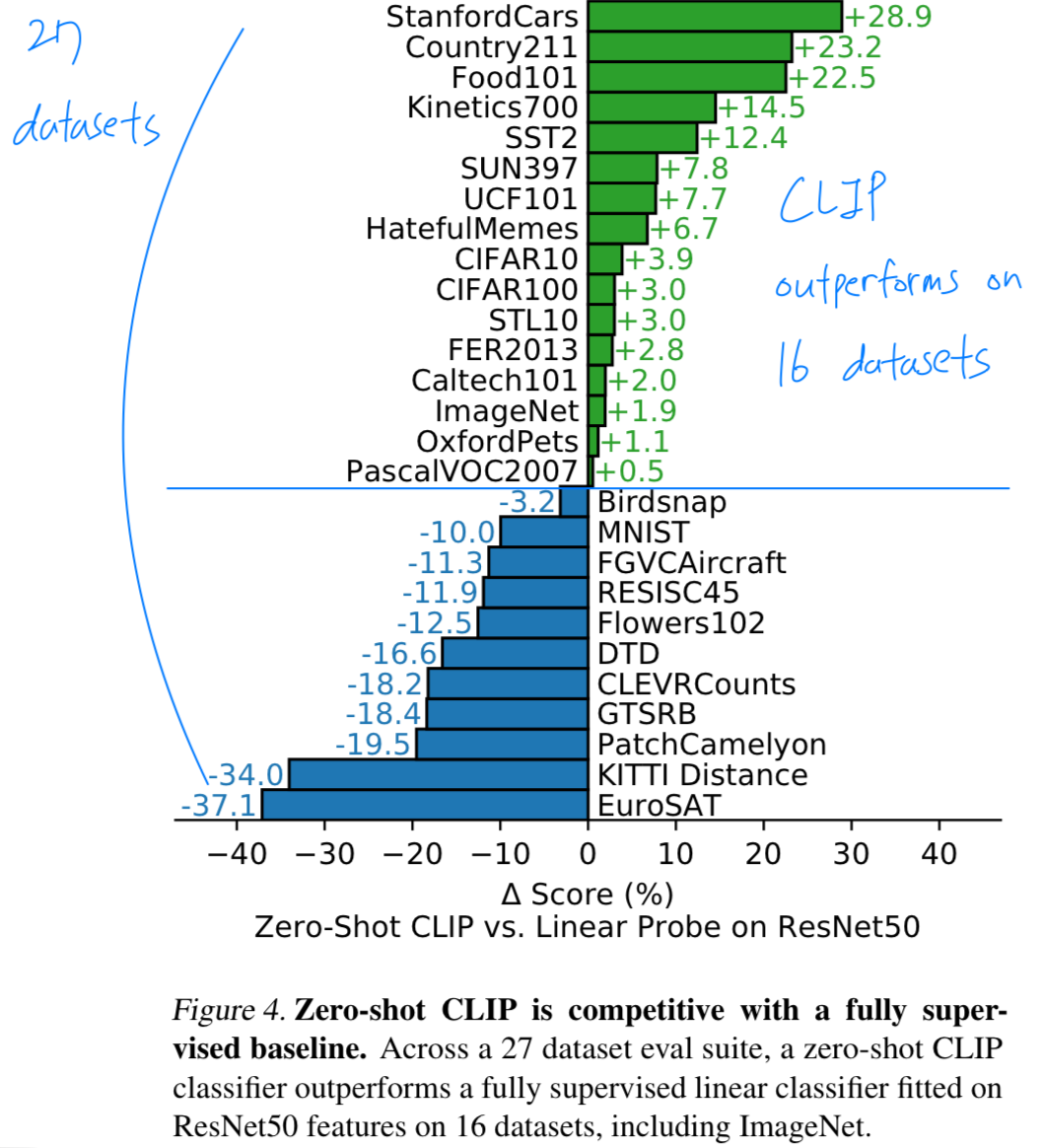
그 비교 결과는 Figure 4에 나타낸 바와 같이, 27개 데이터셋에 대해 수행되었다.
(CLIP이 outperform한 경우 분석)
Zero-shot CLIP은 baseline보다 약간 더 우수한 성능을 보였으며, 27개 데이터셋 중 16개에서 더 좋은 결과를 냈다.- fine-grained classification task에서는 성능 편차가 크게" 나타났다.
우리는 이러한 차이가 주로 WIT(CLIP을 pre-train할 때 사용한 dataset)와 ImageNet(baseline을 pre-train할 때 사용한 dataset) 사이의 Per-task supervision의 차이에서 비롯된 것이라고 추측**한다. - "general" object classification datasets (ImageNet, CIFAR10, PascalVOC2007)에서는 두 모델의 성능이 대체로 비슷하며, zero-shot CLIP이 약간 우위에 있다.
- Zero-shot CLIP은 action recognition을 평가하는 두 dataset에서 ResNet50 (baseline)을 크게 능가한다.
우리는 이러한 차이가, ImageNet이 noun-centric(명사에 초점을 맞춘) object supervision을 제공하는 반면,
natural language는 verbs(동사)를 포함한 더 wider supervision을 제공하는 덕분이라고 추측한다.
- fine-grained classification task에서는 성능 편차가 크게" 나타났다.
(CLIP이 underform한 경우 분석)
Zero-shot CLIP이 특히 underperform하는 영역을 보면,
위성 이미지 분류, 림프절 종양 탐지, 합성 장면에서 objects 개수를 세는 작업,
자율주행 관련 작업 등 특수하고 복잡하거나 추상적인 작업에서 zero-shot CLIP이 상당히 약하다는 것을 확인할 수 있다.
반면, non-expert humans는 counting, 위성 이미지 분류, 교통 표지판 인식 같은 여러 작업을 안정적으로 수행할 수 있기 때문에,
이 분야에는 개선의 여지가 상당히 크다고 할 수 있다.
그러나 주의해야 하는 것은 림프절 종양 분류처럼 humans 대부분 (CLIP도 마찬가지) piror experience가 전혀 없는 어려운 task에 대해,
zero-shot transfer만을 가지고 model을 평가하는 것이 의미 있는지 unclear하다는 것이다.
이런 경우에는 few-shot transfer가 더 적절할 수 있다.
(Zero-shot CLIP vs. 다른 model few-shot)
-
Zero-shot performance를 fully supervised model과 비교하는 것은 CLIP의 task-learning capability를 이해하는 데 도움이 되지만,
zero-shot은 few-shot의 limit이므로, few-shot 방법과 비교하는 것이 더 직접적인 비교 방식이다.
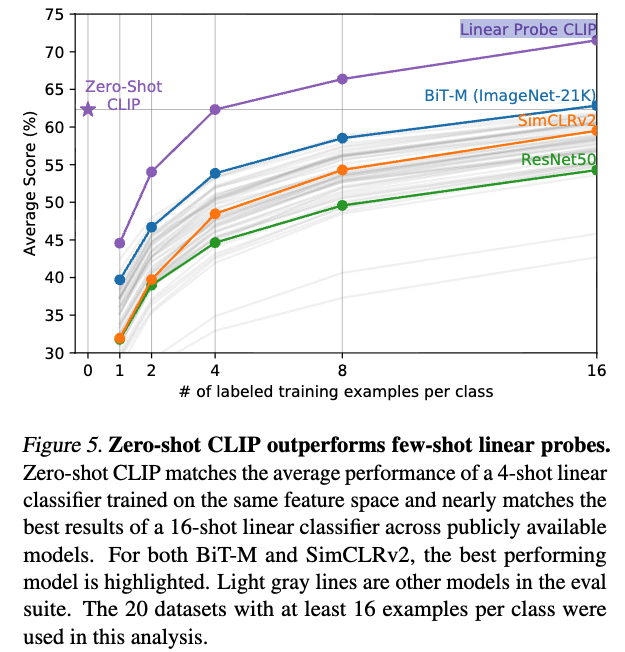
Figure 5에서, 우리는 zero-shot CLIP이 the best publicly available ImageNet models, self-supervised learning methods, 그리고 CLIP itself를 포함한 다양한 image model의 feature에서 few-shot logistic regression과 어떻게 비교되는지를 시각화한다.
일반적으로는 zero-shot이 one-shot보다 성능이 떨어질 것이라고 예상할 수 있지만,
실제로는 zero-shot CLIP이 동일한 feature space에서 4-shot logistic regression 성능과 비슷하게 나타난다.
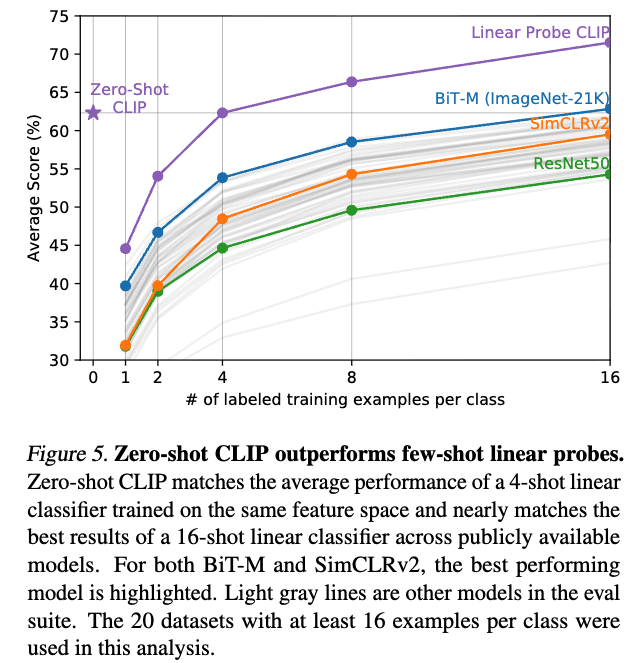
- 이는 zero-shot 방식과 few-shot 방식 사이의 중요한 차이 때문으로 보인다.
- 우선적으로, CLIP's zero-shot classifier는 natural language를 이용해 생성되므로,
visual concetps들이 직접적으로 specified("communicated")될 수 있다.
반면 "normal" supervised learning에서는 training examples로부터 training examples로부터 concepts을 indirectly infer해야 한다. - context-less example-based learning은 특히 one-shot case에서 data와 일치할 수 있는 hypotheses가 너무 많다는 문제가 있다.
A simgle image에는 여러 개의 visual concepts이 존재할 수 있기 때문이다.
capable learner(능력있는 학습자?)는 image 내에서 primary object에 대해서 visual cues and heuristics을 활용할 수는 있지만, 이는 guarantee되지 않는다.
- 우선적으로, CLIP's zero-shot classifier는 natural language를 이용해 생성되므로,
- zero-shot CLIP을 few-shot logistic regression on the features of other models과 비교해보면,
zero-shot CLIP은 ImageNet-21K로 학습된 BiT-M ResNet152x2의 feature를 사용한 16-shot classifier의 성능과 거의 비슷한 수준을 보인다.
흥미로운 점은, 16-shot setting에서 BiT-M ResNet152x2가 가장 잘 작동한다는 점이다.
이는 약간 놀라운 결과인데, Section 3.3에서 분석된 바에 따르면
Noisy Student EfficientNet-L2가 fully supervised 환경에서는 평균적으로 27개의 데이터셋에서 BiT-M을 약 5% 정도 앞서기 때문이다. (?)
이게 무슨 말이지? 일반적인 기대는 fully supervised 성능이 더 높은 model이면 few-shot transfer에서도 더 좋을 것이다.
하지만 실제 관찰에서는 Noisy Student Efficient-L2가 fully supervised에서는 최고였지만, 16-shot에서는 BiT-M이 더 좋았다라는 것임.
Figure 5에 Noisy Student Efficient-L2가 없지 않나?
- 이는 zero-shot 방식과 few-shot 방식 사이의 중요한 차이 때문으로 보인다.
-
(궁금한 점): 왜 Zero-shot CLIP보다 one-shot, two-shot CLIP의 성능이 더 낮을까?
- Gemini 답: \text{zero-shot 성능은 text prompt ensembling이라는 강력한 trick과 task learning capability 덕분에 매우 높습니다.
One/Two-shot이 이를 능가하지 못하는 것은 훈련 데이터의 양이 질적으로 zero-shot prompt의 풍부함을 넘어서지 못했기 때문일 가능성이 높습니다.
- Gemini 답: \text{zero-shot 성능은 text prompt ensembling이라는 강력한 trick과 task learning capability 덕분에 매우 높습니다.
3.3. Representation Learning
-
우리는 지금까지 zero-shot transfer를 통해 주로 the task-learning capabilities of CLIP에 집중했지만,
일반적으로는 the representation learning capabilities of a model을 평가하는 것이 더 흔하다.
우리는 linear probe evaluation protocol을 사용하는데, 이는 필요한 hyepr-parameter tuning이 minimal하며 standardized evaluation procedure이 표준화되어 있기 때문이다. -
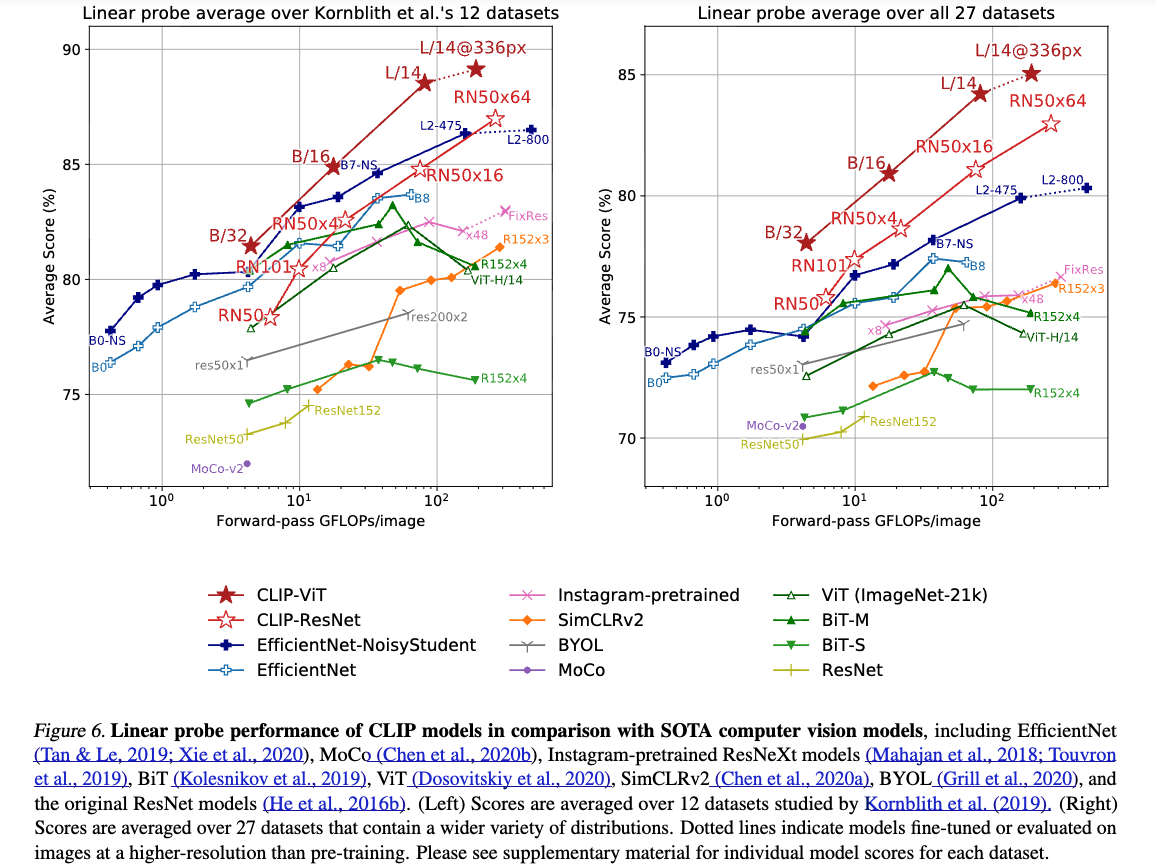
Figure 6는 our findings를 요약한다.
- selection bias를 줄이기 위해, 먼저 Kornblith et al. (2019)에서 제안한 12개 dataset evaluation suite에서 성능을 비교했다.
CLIP으로 학습된 model들은 연산량이 증가할수록 성능이 매우 잘 scaling되었고, 가장 큰 model은 the best existing model (Noisy Student EfficientNet-L2)을 both overall score and compute efficiency에서 slightly outperform했다.
또한, CLIP Vision Transformer는 CLIP ResNet보다 약 3배 더 compute efficient해서, 동일한 compute budget에서 higher overall performance를 달성할 수 있었다.
이는 large datasets으로 학습할 때 Vision Transformer가 Convolutional Network보다 더 효율적이라고 보고한 Dosovitskiy et al. (2020)의 결과를 재현한 것이다.
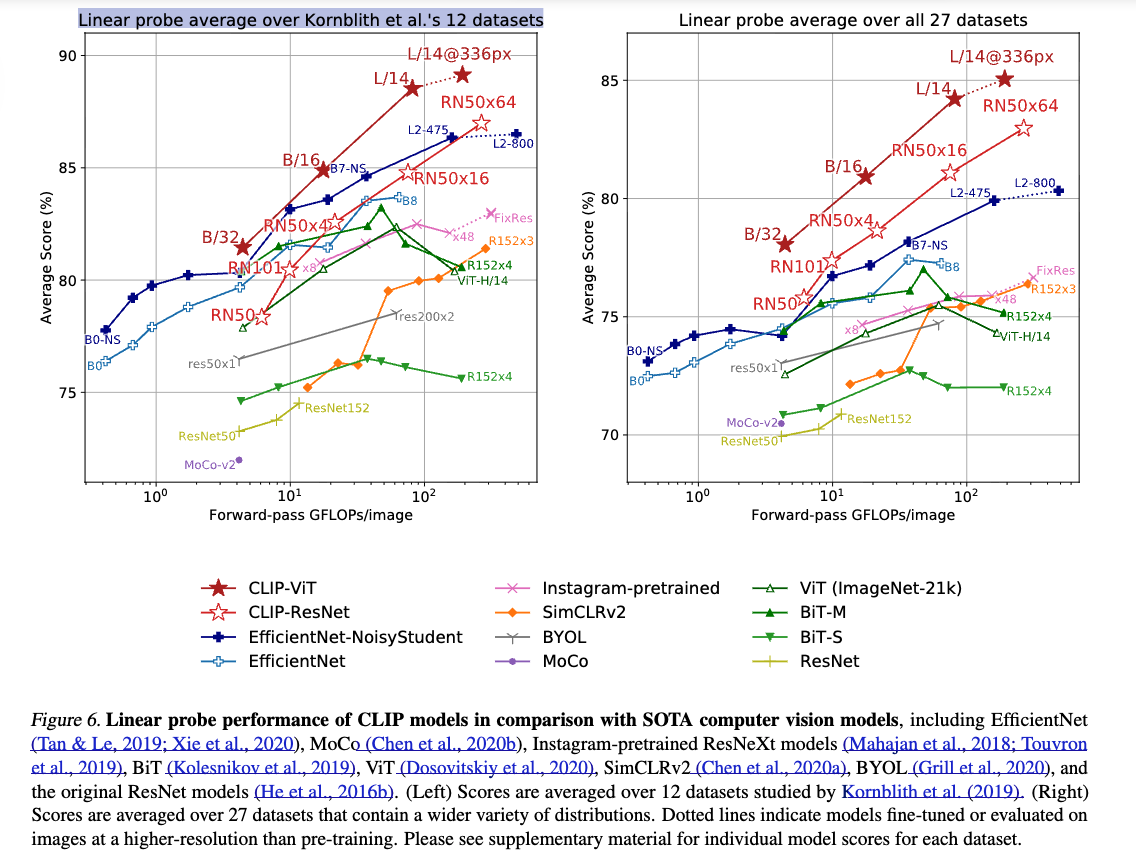
- CLIP model은 a single CV model을 Random initialization해서 end-to-end로 학습한 경우 이전에 보고된 것보다 더 넓은 범위의 tasks를 학습한다.
이러한 tasks에는 geo-localization, optical character recognition, facial emotion recognition 등이 포함된다.
이 task들은 Kornblith et al. (2019)의 evaluation suite에는 measured되지 않는다.
이 때문에 해당 evaluation suite가 ImageNet과 유사한 작업에 편향되었다는 selection bias 우려가 있다.
이를 보완하기 위해, 우리는 총 a broader 27 dataset evaluation suite에 성능을 측정했다.
this broader evaluation suite에서, CLIP의 장점은 더욱 명확하게 드러난다.
scale과 무관하게 모든 CLIP model은 모든 기존 system을 compute efficiency에서 능가한다.
또한 best model의 average score 개선 폭도 previous systems 대비 2.6%에서 5%로 증가한다.
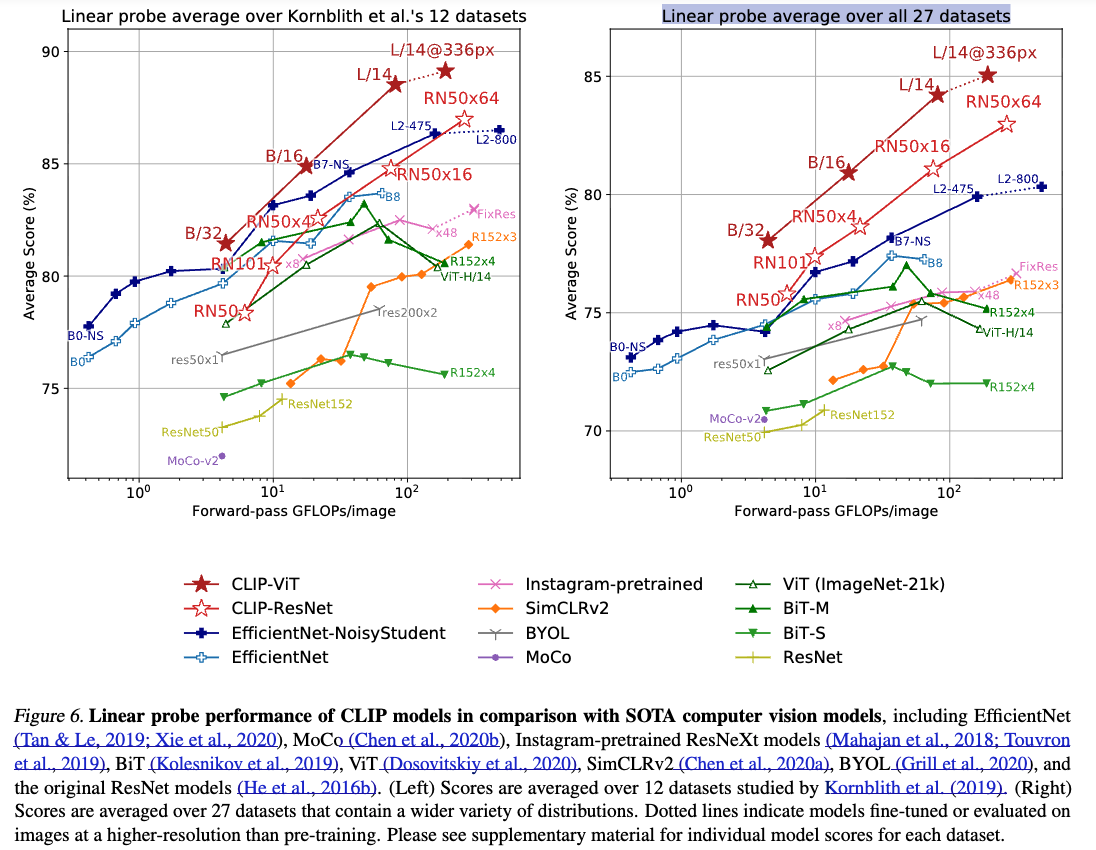
- selection bias를 줄이기 위해, 먼저 Kornblith et al. (2019)에서 제안한 12개 dataset evaluation suite에서 성능을 비교했다.
3.4. Robustness to Natural Distribution Shift
- 2015년, DL model이 ImageNet test set에서 human performance를 exceed했다는 발표가 있었다.
그러나 그 후 몇 년 동안의 연구들은 이러한 model들이 여전히 매우 단순한 실수를 많이 한다는 사실을 반복적으로 발견했다.
또한 이러한 system을 새로운 benchmark로 평가하면, 그 performance가 human accuracy 뿐 아니라 ImageNet performance보다 훨씬 낮다는 결과가 자주 나왔다.
Taori et al. (2020)은 ImageNet model에 대해 이를 quantifying하고 이해하려 한 recent comprehensive study이다.
Taori et al. (2020)은 ImageNet model들을 natural distribution shifts 상황에서 평가했을 때 성능이 어떻게 달라지는지를 분석했다.
그들은 a set of 7 distribution shifts에 대해서 performance를 측정했다.
Taori et al. (2020)은 distribution shift 상황에서의 accuracy는 ImageNet accuracy와 함께 예측 가능하게 증가하며,
a linear function of logit-transformed accuracy로 잘 modeling된다는 것을 발견했다. (?)
이 발견을 바탕으로, Taori et al. (2020)은 robustness 분석은 effective robustness와 relative robustness를 구분해야 한다고 제안한다.
Taori et al. (2020)은 robustness techniques는 both effective robustness and relative robustness를 모두 향상시켜야 한다고 주장한다.- Effective robustness는 distribution shift 환경에서의 accruacy가, "기존에 관찰된 in-distribution accuracy와 out-of-distribution accuracy의 관계로부터 예측된 값"보다 얼마나 더 개선되었는지를 측정하는 지표이다.
- Relative robustness는 any improvement in out-of-distribution accuracy를 측정하는 지표이다.
이해한 내용:
distribution shift는 model이 학습한 data distribution과, 실제로 test할 때 만나는 data distribution이 달라지는 상황.
robustness는 model이 이러한 distirbution shift에 성능이 덜 떨어지는지를 평가하는 것.
여기서, Relative Robustness는 그냥 OOD(Out-of Distribution, 분포가 다른 dataset)에서 accuracy를 측정하는 것.
예를 들어, model A는 ImageNet에서 80%이었던 것이 ImageNetV2에서 60% 나옴. model B는 ImageNet에서 80%였던 것이 ImageNetV2에서 65%나옴. model B가 relative robustness가 더 좋다.
즉, Relative Robustness는 OOD 성능 자체가 얼마나 좋은가? 를 측정
Effective Robustness는 OOD accuracy는 logit-transformed ImageNet accuracy의 "linear function"으로 예측 가능하다.
즉, ImageNet accuracy를 알면 OOD accuracy가 어느 정도일지 예측이 가능하다는 것임.
예를 들어, model A는 ImageNet에서 80%이고 modelB는 90%임. OOD(ImageNetV2)에서 model A와 model B는 각각 실제로 60%, 70%가 나왔는데,
실제 측정해보지 않고도 OOD를 예측할 수 있음. 예측 OOD를 model A와 model B에서 각각 58%, 72%라고 가정하면
model A는 예측 OOD(58%)보다 +2%p 높아서 effective robustness가 좋다고 말할 수 있음.
model B는 예측 OOD(72%)보다 -2%p 낮아서 effective robustness가 못하다고 말할 수 있음.
즉, Effective robustness는 예측한 OOD 성능보다 얼마나 더 좋은가? 를 측정.
- 그러나 Taori et al. (2020)의 연구에서 다룬 거의 모든 model들은 ImageNet dataset으로 trained되거나 fine-tuned된 model들이었다.
그렇다면 ImagNet dataset distribution에 model을 training or adapting시키는 것이 robustness gap의 원인일까?
직관적으로, zero-shot model은 specific distribution에만 존재하는 spurious(우연적) correlations에 의존할 수 없다, 왜냐하면 그 distribution으로 학습되지 않았기 때문이다.
따라서 zero-shot model은 higher effective robustness를 보일 가능성이 있다.
Figure 7에서, 우리는 zero-shot CLIP의 성능을 기존 ImageNet model들과 비교한다.
모든 zero-shot CLIP model들은 effective robustness를 매우 크게 향상시키고, ImageNet accuracy와 distribution shift 상황에서의 accuracy and accuracy 간극을 최대 75%까지 줄인다.
Zero-shot CLIP은 Taori et al. (2020)이 분석한 기존 204개의 prior model들과는 완전히 다른 robustness frontier를 형성한다.
이 결과는 최근의 large-scale task and dataset-agnostic pre-training combine with a , 그리고 zero-shot transfer evaluation이
더 robust systems 개발을 촉진하며, a more accurate assessment of true model performance를 제공해한다는 것을 시사한다.
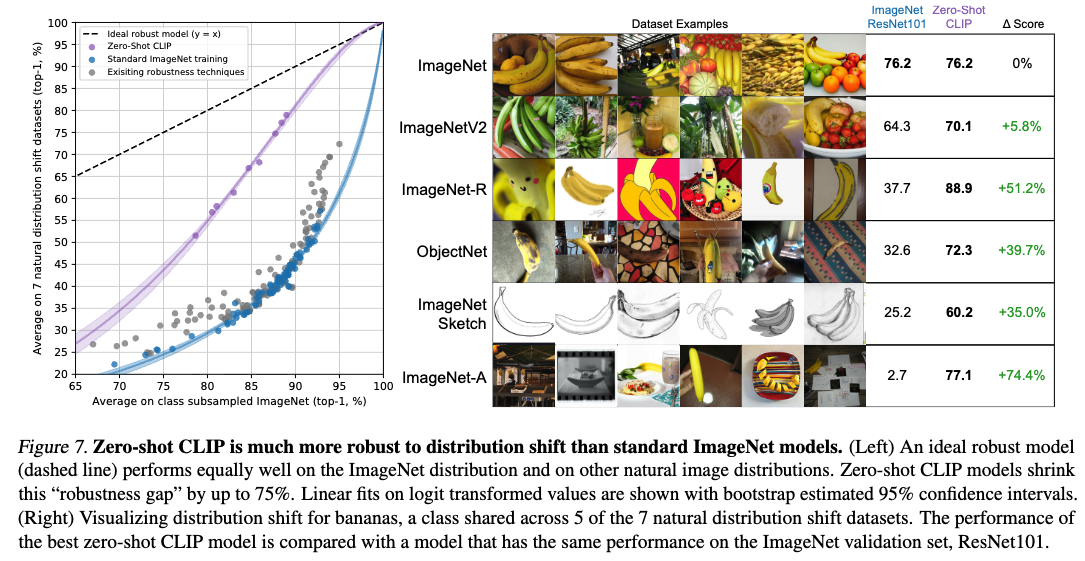
4. Data Overlap Analysis
- a very large internet dataset으로 pre-training하는 것에 대한 우려는 의도치 않게 downstream evals와 dataset이 overlap될 수도 있다는 것이다.
우리는 이러한 가능성을 조사하기 위해 de-duplication analysis를 수행했으며, full deatils는 supplementary material에 포함
5. Broader Impacts
- CLIP은 사용자가 their own classifiers를 design할 수 있게 해주며,
the need for task-specific training data를 필요 없게 한다.
그러나 classes를 어떻게 설계하느냐가 model performance and model biases에 큰 영향을 미친다.
추가적으로, CLIP은 task-specific training data 없이도 새로운 분야에 쉽게 적용될 수 있기 때문에,
일부 응용 분야는 privacy surveillance 관련 위험을 야기할 수도 있다.
우리는 CLIP이 가지는 잠재적 위험과 과제를 보완자료(supplemental materials)에 추가했으며,
이 연구가 CLIP과 같은 model의 capabilities, shortcomings, and biases를 더 정확히 파악하기 위한 future research가 촉진되기를 바란다.
6. Limitations
-
Zero-shot CLIP의 성능은 보통 ResNet-50 feature 위에 linear classifier를 얹어 학습한 supervised baseline과 비슷한 수준에 머문다.
그러나 이 baseline은 현재 전체적인 SOTA 성능이 비해 훨씬 낮다.
CLIP의 task learning and transfer capabilities를 개선하기 위해서는 여전히 많은 연구가 필요하다.
우리의 추정에 따르면, Zero-shot CLIP이 전체 evaluation suite에서 SOTA 수준에 도달하려면 대략 1000배 더 많은 compute가 필요하다.
이는 현재 HW로는 현실적으로 train이 불가능하다.
따라서 CLIP의 computational and data efficiency를 높이는 연구가 앞으로 필수적이다. -
Zero-shot transfer에 초점을 두었음에도, 우리는 development 과정에서 performance를 확인하기 위해 반복적으로 validation set을 queried했다.
이는 true zero-shot 상황에서는 현실적이지 않다.
이러한 문제는 semi-supervised learning 분야에서도 이전에 제기된 바 있다. -
또 다른 potential issue는 우리가 사용하는 evaluation datasets의 선택 방식이다.
우리는 Kornblith et al. (2019)의 12 dataset evaluation sutie를 standardized collection으로 보고 겨로가를 하지만,
주요 분석은 CLIP의 능력에 맞춰 어느 정도 co-adapted된 27 datasets을 다소 임의적으로 선정하여 사용한다.
broad zero-shot transfer capabilities를 평가하도록 설계된 new benchmark가 이러한 문제를 해결하는 데 도움이 될 것이다. -
우리는 natural language로 image classifer를 지정하는 방식이 flexible interface임을 강조하지만, 이 방식에도 분명한 한계가 있다.
많은 complex tasks는 text만으로 명확하게 정의하기 어렵다.
실제 ㅅraining examples는 분명 유용하지만, CLIP은 few-shot performance를 직접 optimize하지 않는다.
그래서 우리는 결국 CLIP's features 위에 linear classifier를 맞추는 방식으로 돌아가게 한다.
그러나 이것은 zero-shot에서 few-shot으로 전환할 때 오히려 성능이 떨어지는 counter-intuitive (역설적인) 현상을 초래한다.
7. Related Work
8. Conclusion
CLIP은 ConVIRT에 비해 구체적으로 어떻게 단순화되었는가?
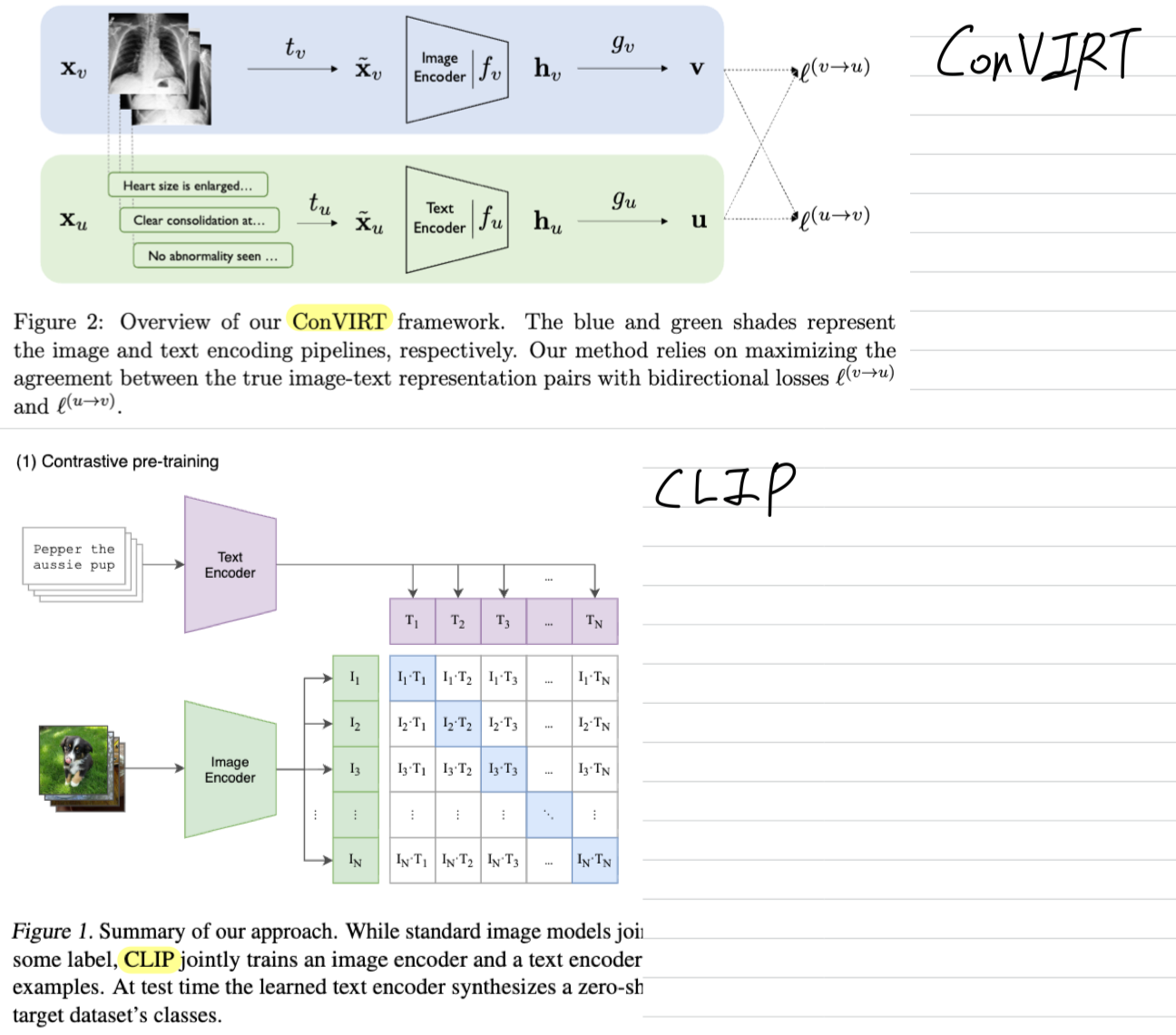
1. pretrained weight로 encoder를 initializing?
-
ConVIRT에서는 pretrained weight로 image(언급 없음), text encoder(ClinicalBERT의 weight로 초기화) 둘 다 initializing함.
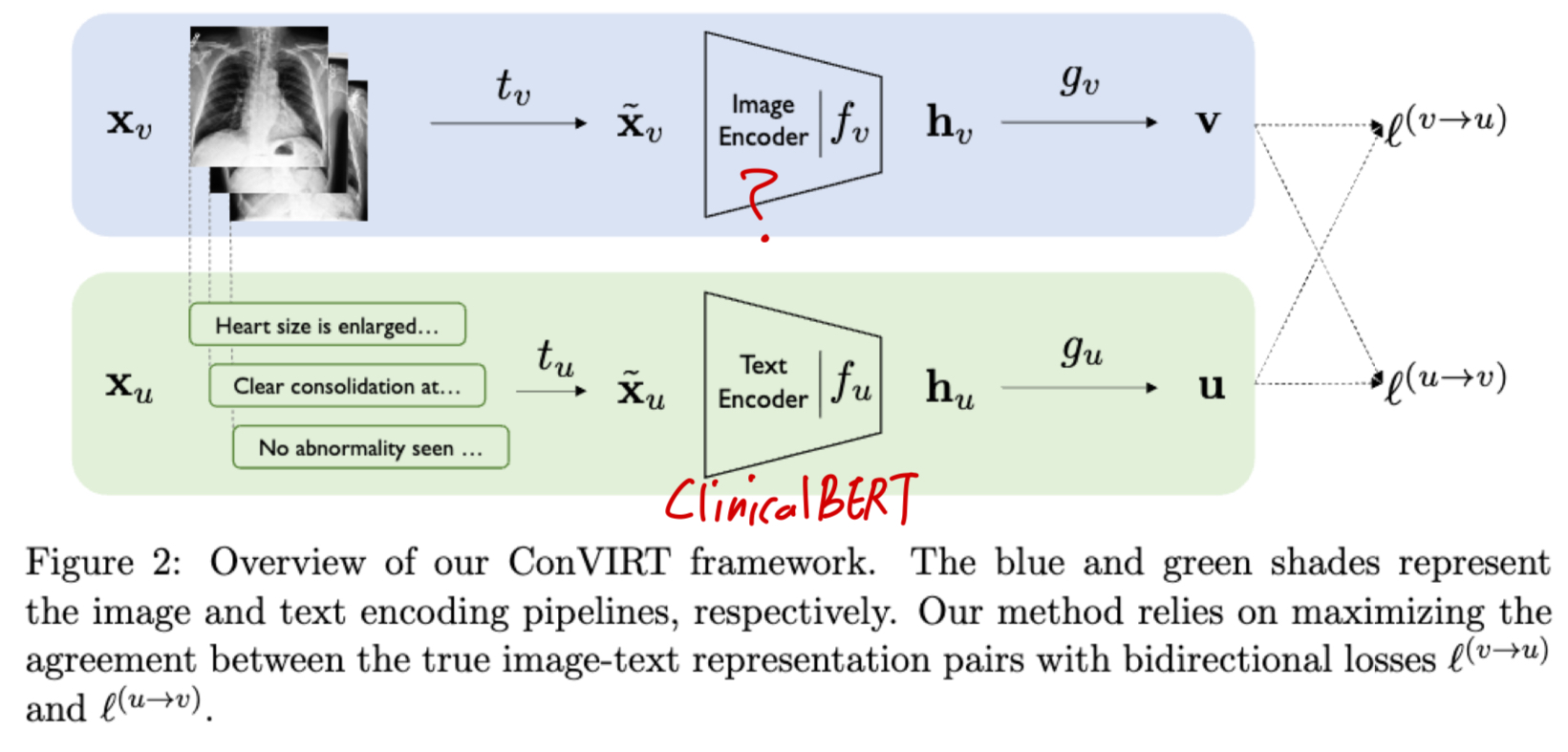
-
CLIP에서는 둘 다 scratch로 training함.
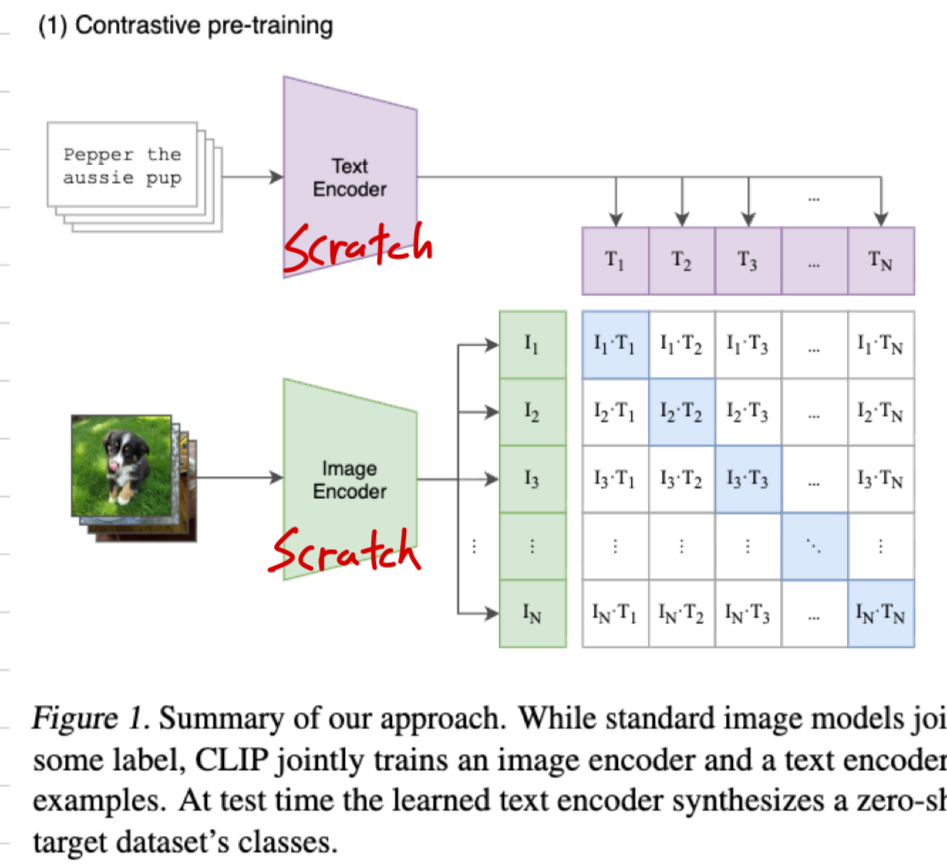
2. contrastive loss에서 InfoNCE 방식의 loss를 가중합하는가?
- ConVIRT에서는 InfoNCE 방식의 assymetric loss를 로 weight 주어 결합
즉, image()-to-text() loss와 text()-to-image() loss를 가중합
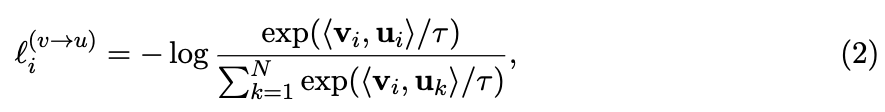
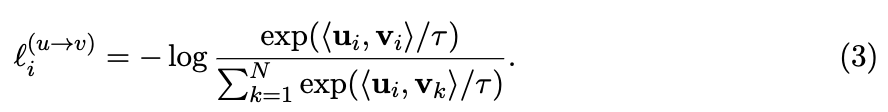
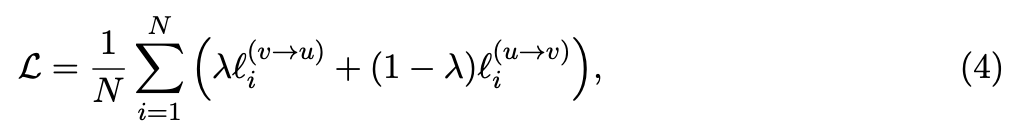
- CLIP에서도 image-to-text loss (loss_i)와 text-to-image loss (loss_t)를 구하는데,
가중합하지 않고 그냥 더함(가중합 X).

3. softmax에서의 temperature parameter
-
softmax에서 temperature 는 확률 분포의 sharpness 또는 smoothness를 조절하는 parameter.
contrastive learning에서 유사도 차이를 얼마나 강조할지 조절하는 역할을 함.- T < 1, 분포를 sharper
- T > 1, 분포를 smoother
-
ConVIRT에서는 temperature parameter를 hyper-parameter로 tuning함.
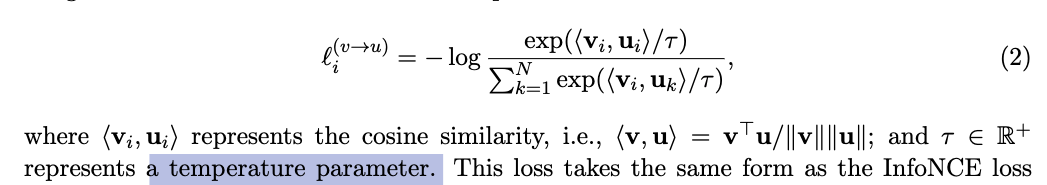
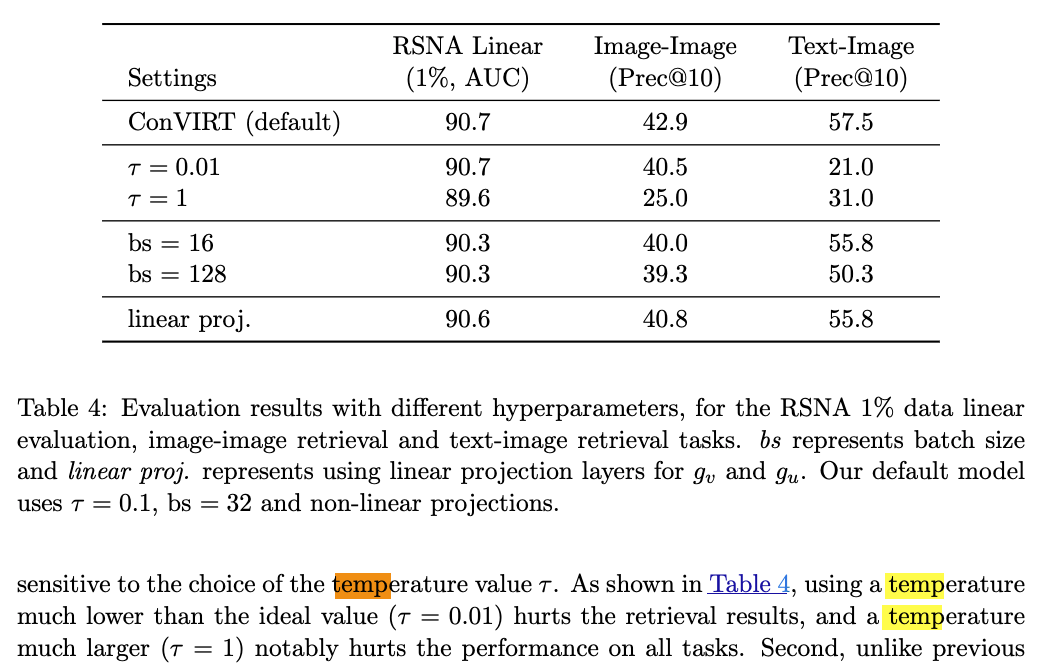
-
CLIP에서는 temperature parameter를 learnable parameter로 training함.

4. projection head (nonlinear? linear?)
- ConVIRT에서는 representation embedding space와 contrastive embedding space 사이의 non-linear projection head가 있었음.

- CLIP에서는 이 non-linear projection head를 제거하고, linear projection으로 바꿈.
5. input data(image, text) augmentation 복잡, 단순
-
ConVIRT
- image: medical image 특성 때문에 보수적인 augmentation을 했지만, 다양한 augmentation technique을 적용함.
- text: 한 medical report input에서 문장(span)을 random sampling
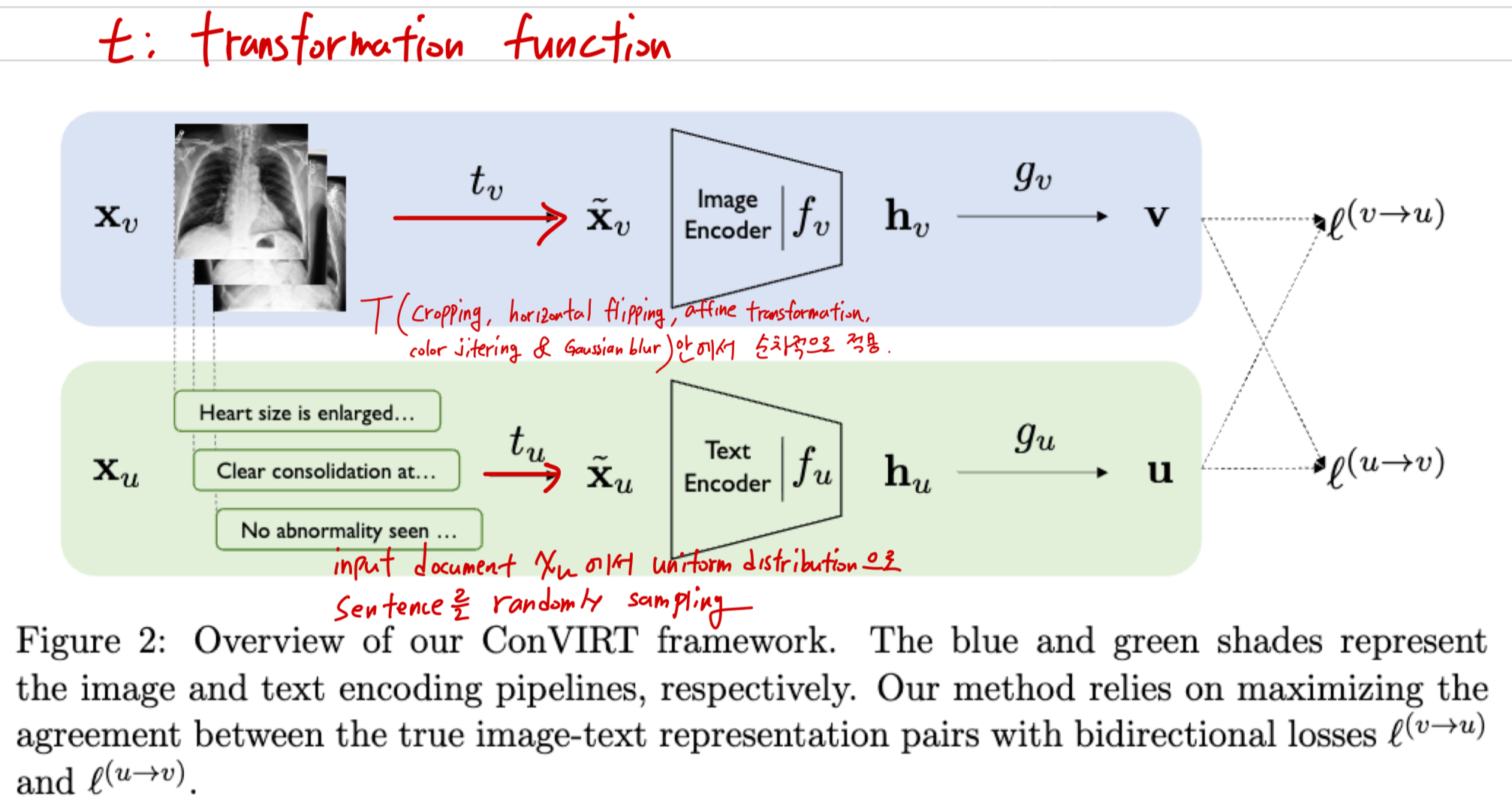
-
CLIP
- image: natural image 특성과 많은 데이터가 있기 때문에 ImageNet-style + random crop 정도로 단순화함.
- text: internet caption은 대부분 짧기 때문에 sampling 없이 text 그대로 사용
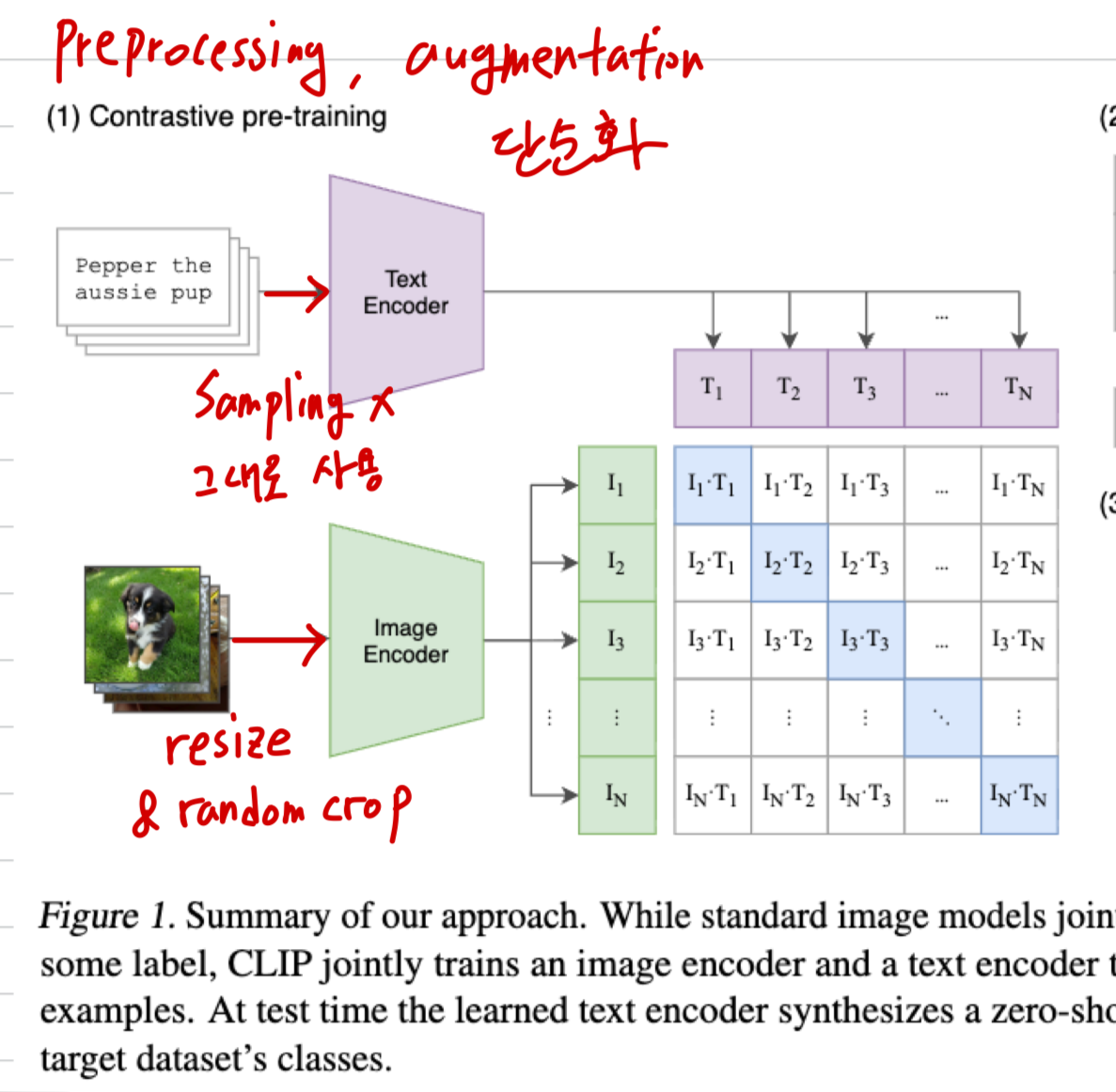
이 논문의 핵심
- 이 논문은 인터넷에서 수집한 4억 개의 image-text pairs를 contrastive learning을 통해,
natural language supervision만으로 visual concept을 pretraining하는 CLIP을 제안.
CLIP은 down-stream task에 뛰어난 zero-shot 성능을 보여주며, 기존 supervised learning model과 대등하거나 더 높은 성능을 달성한다.
