References
- ConVIRT: Zhang, Yuhao, et al. "Contrastive learning of medical visual representations from paired images and text." Machine learning for healthcare conference. PMLR, 2022.
- CLIP: Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PmLR, 2021.
CLIP은 ConVIRT에 비해 구체적으로 어떤게 단순화되었는가?
1. encoder initialization (pretrained weight? from scratch?)
-
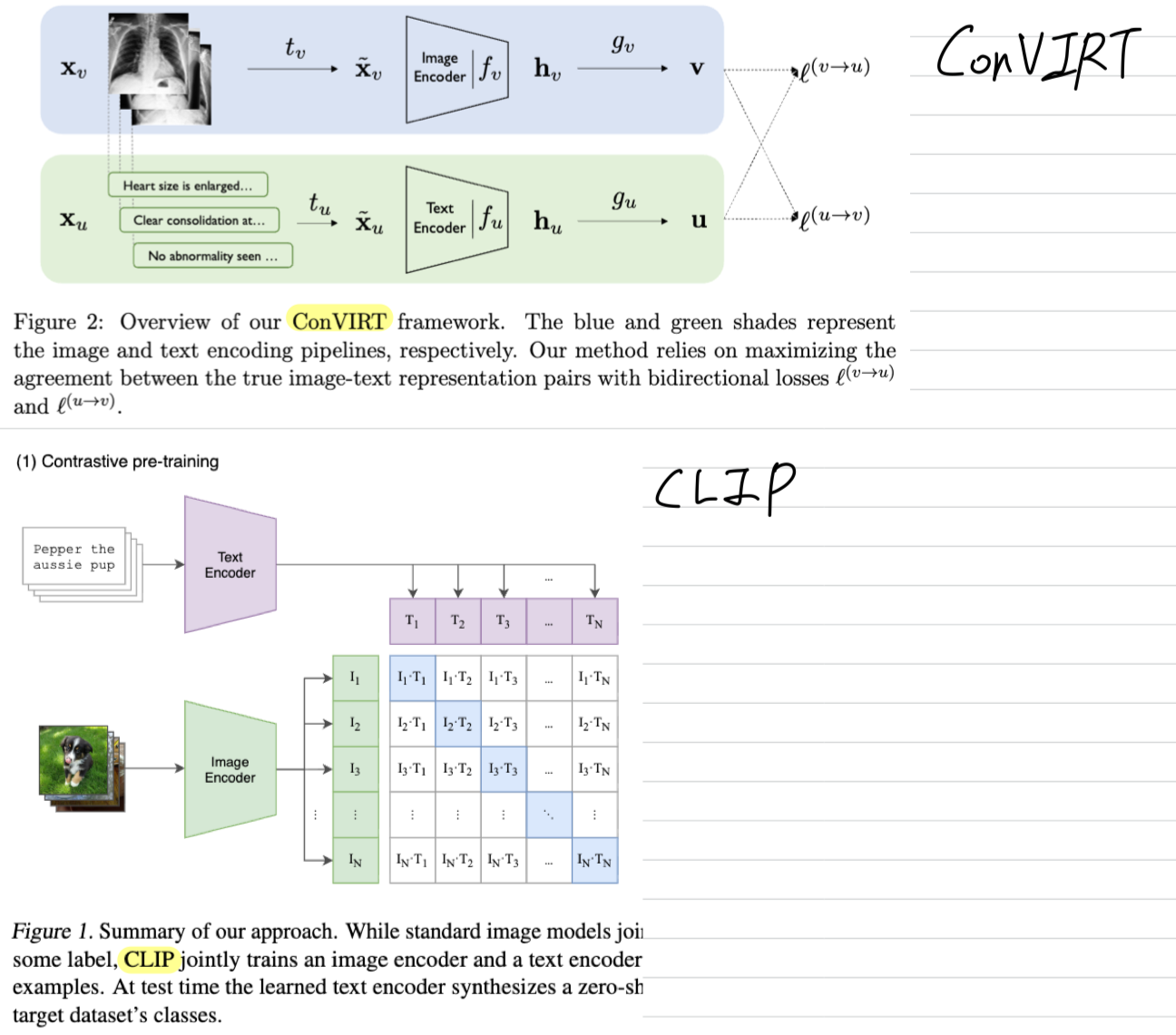
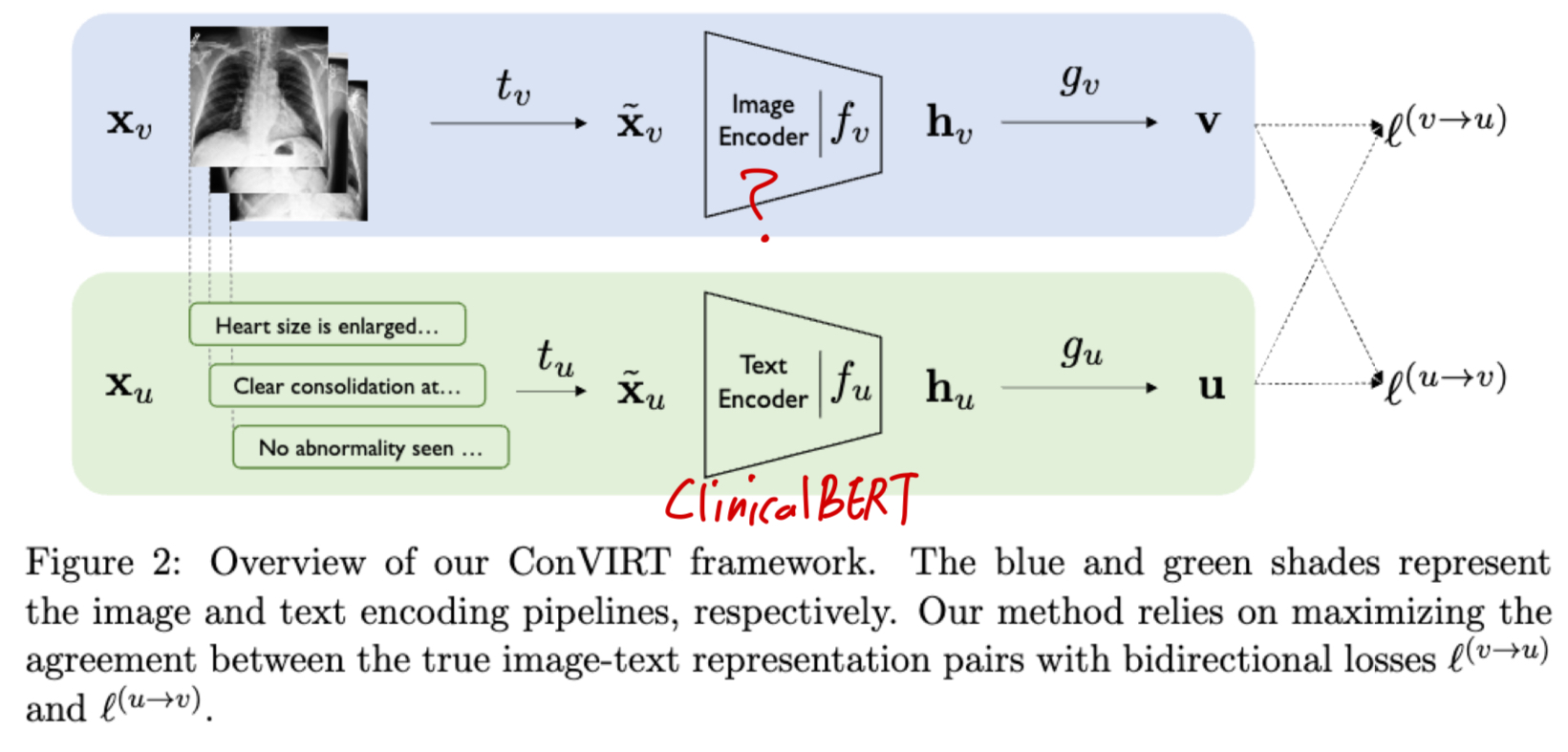
ConVIRT에서는 pretrained weight로 image(언급 없음), text encoder(ClinicalBERT의 weight로 초기화) 둘 다 initializing함.
-
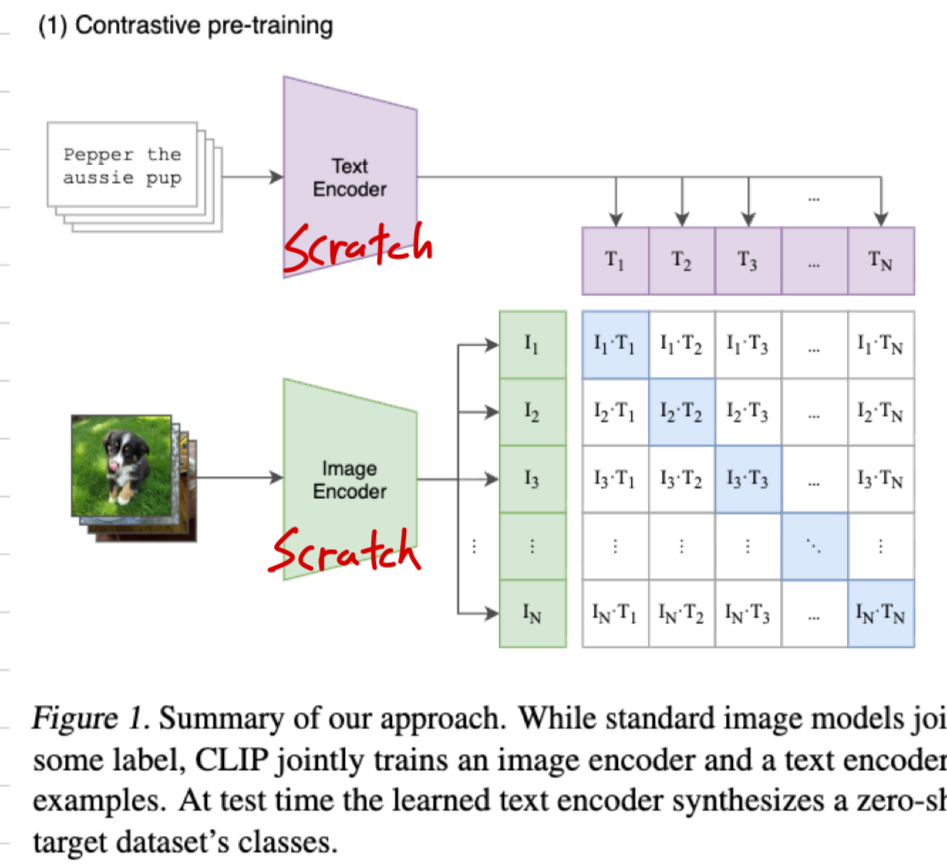
CLIP에서는 둘 다 scratch로 training함.
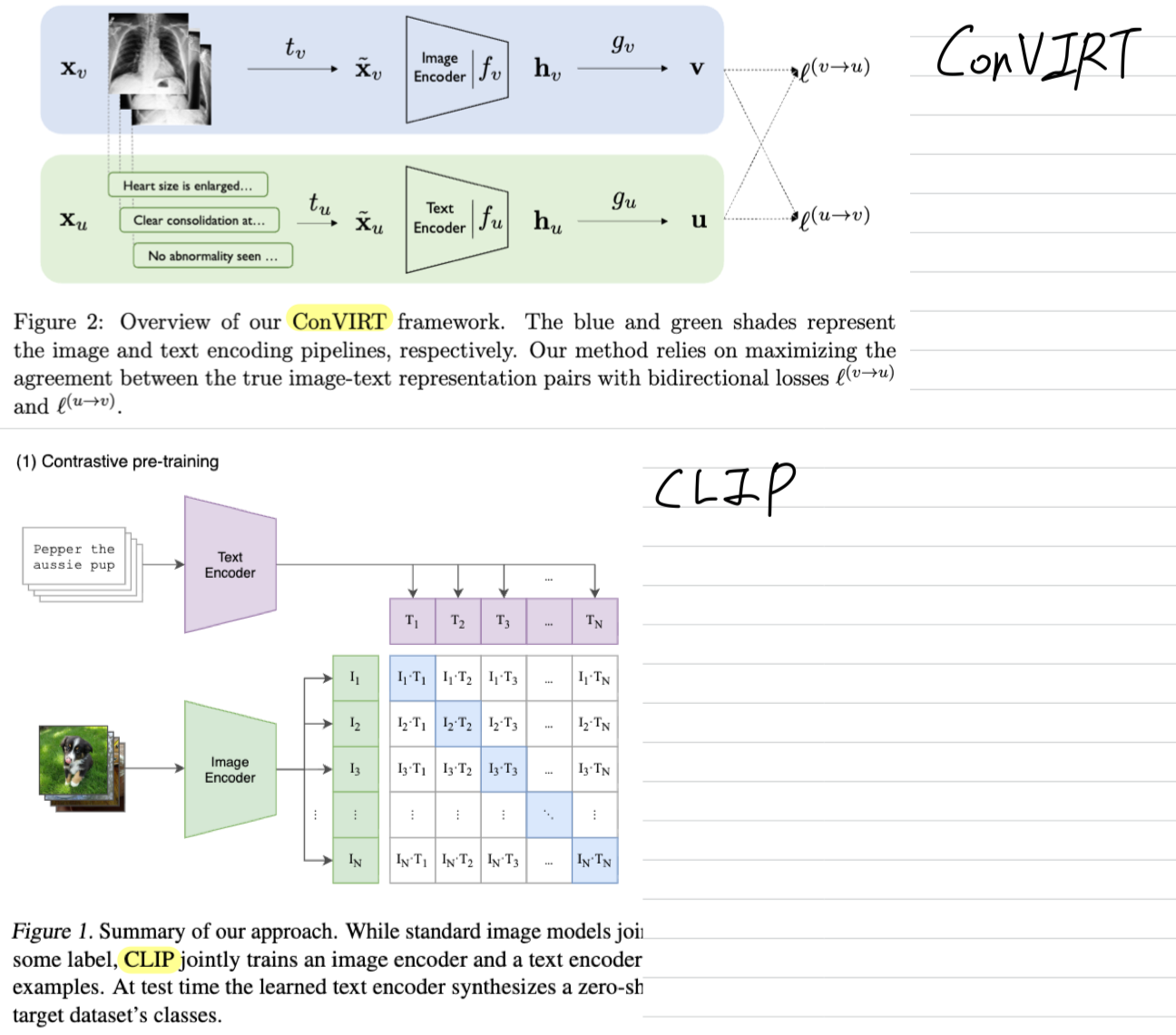
2. contrastive loss에서 InfoNCE 방식의 loss를 가중합하는가?
- ConVIRT에서는 InfoNCE 방식의 assymetric loss를 로 weight 주어 결합
즉, image()-to-text() loss와 text()-to-image() loss를 가중합
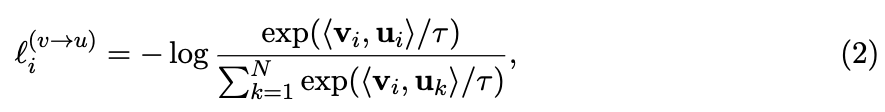
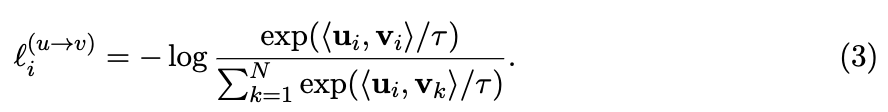
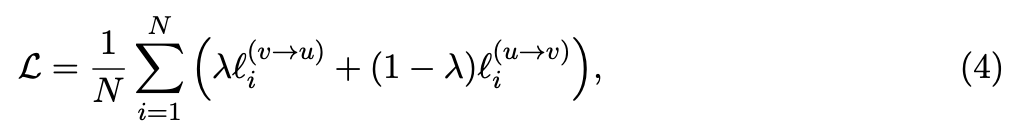
- CLIP에서도 image-to-text loss (loss_i)와 text-to-image loss (loss_t)를 구하는데,
가중합하지 않고 그냥 더함(가중합 X).

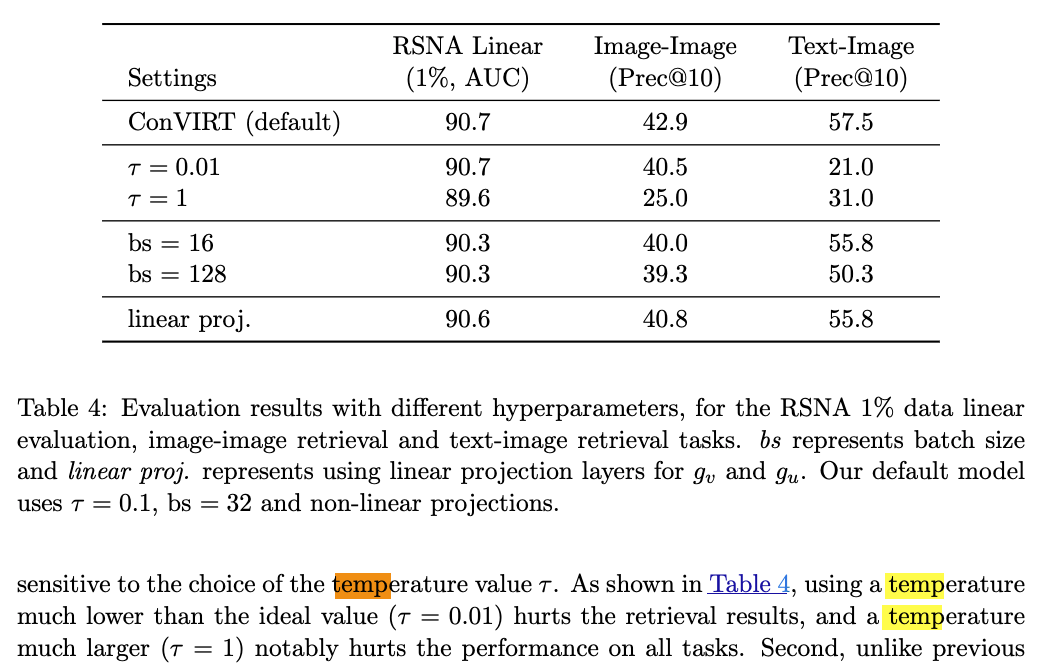
3. softmax의 temperature parameter (hyper? learnable?)
-
softmax에서 temperature 는 확률 분포의 sharpness 또는 smoothness를 조절하는 parameter.
contrastive learning에서 유사도 차이를 얼마나 강조할지 조절하는 역할을 함.- T < 1, 분포를 sharper
- T > 1, 분포를 smoother
-
ConVIRT에서는 temperature parameter를 hyper-parameter로 tuning함.
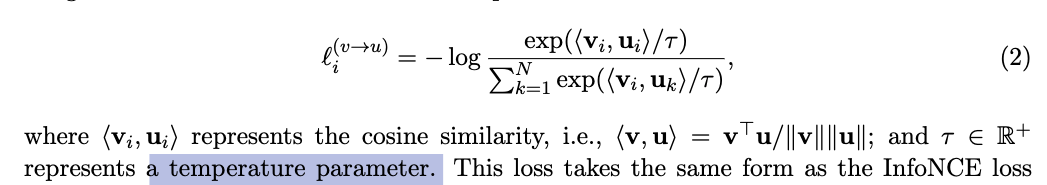
-
CLIP에서는 temperature parameter를 learnable parameter로 training함.

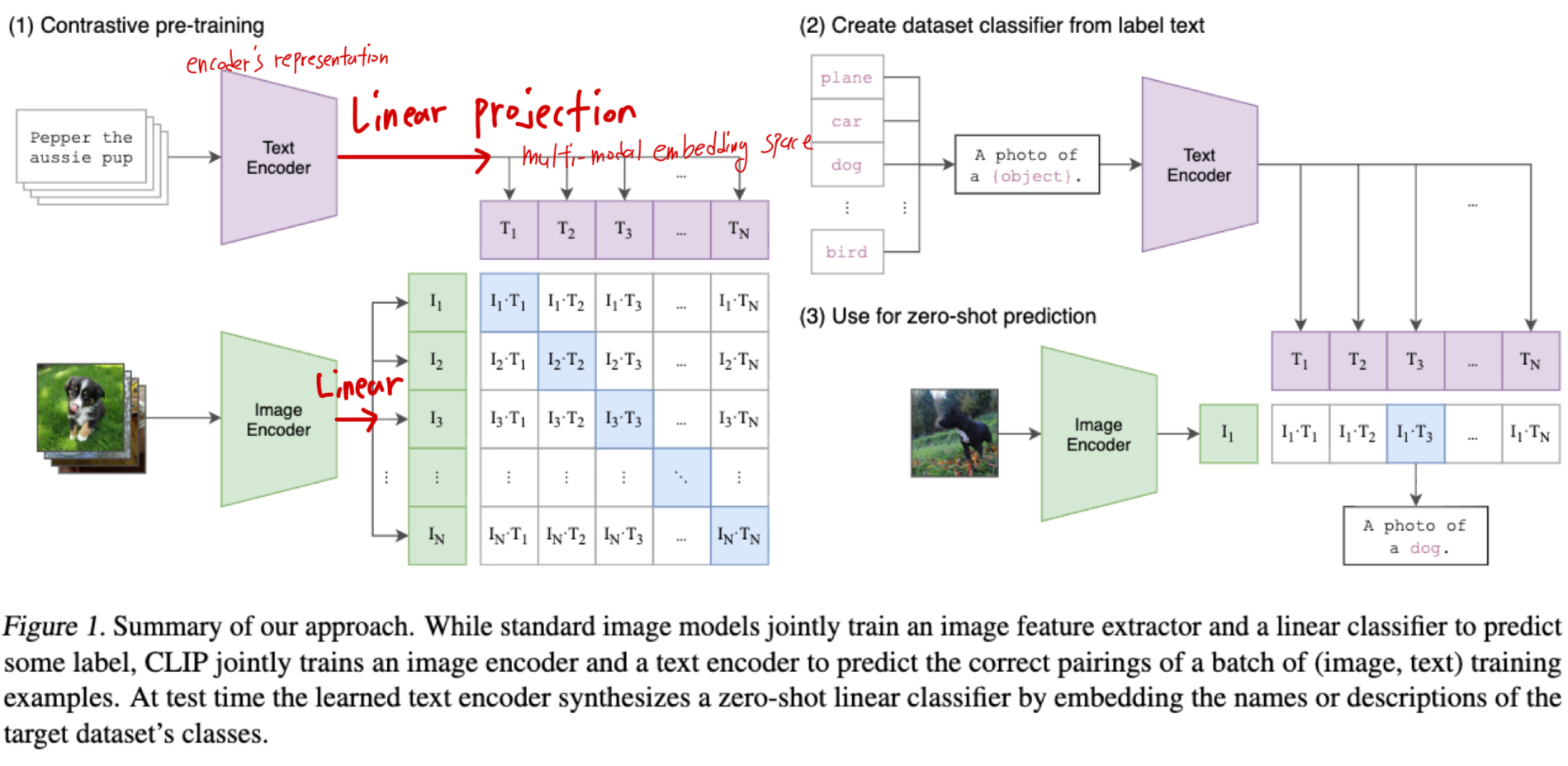
4. projection head (nonlinear? linear?)
- ConVIRT에서는 representation embedding space와 contrastive embedding space 사이의 non-linear projection head가 있었음.

- CLIP에서는 이 non-linear projection head를 제거하고, linear projection으로 바꿈.
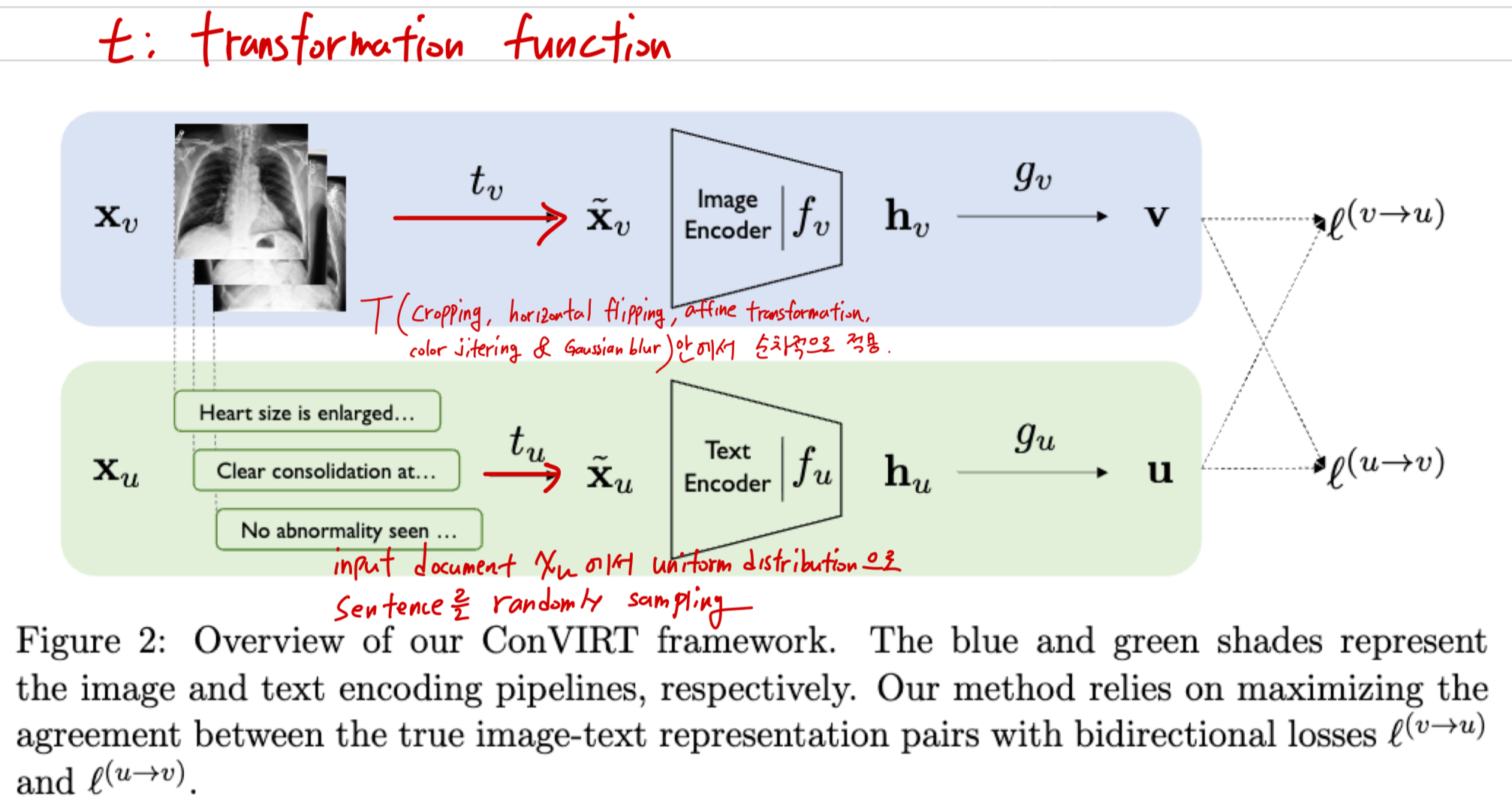
5. input datas(image, text) augmentation 복잡? 단순?
-
ConVIRT
- image: medical image 특성 때문에 보수적인 augmentation을 했지만, 다양한 augmentation technique을 적용함.
- text: 한 medical report input에서 문장(span)을 random sampling
-
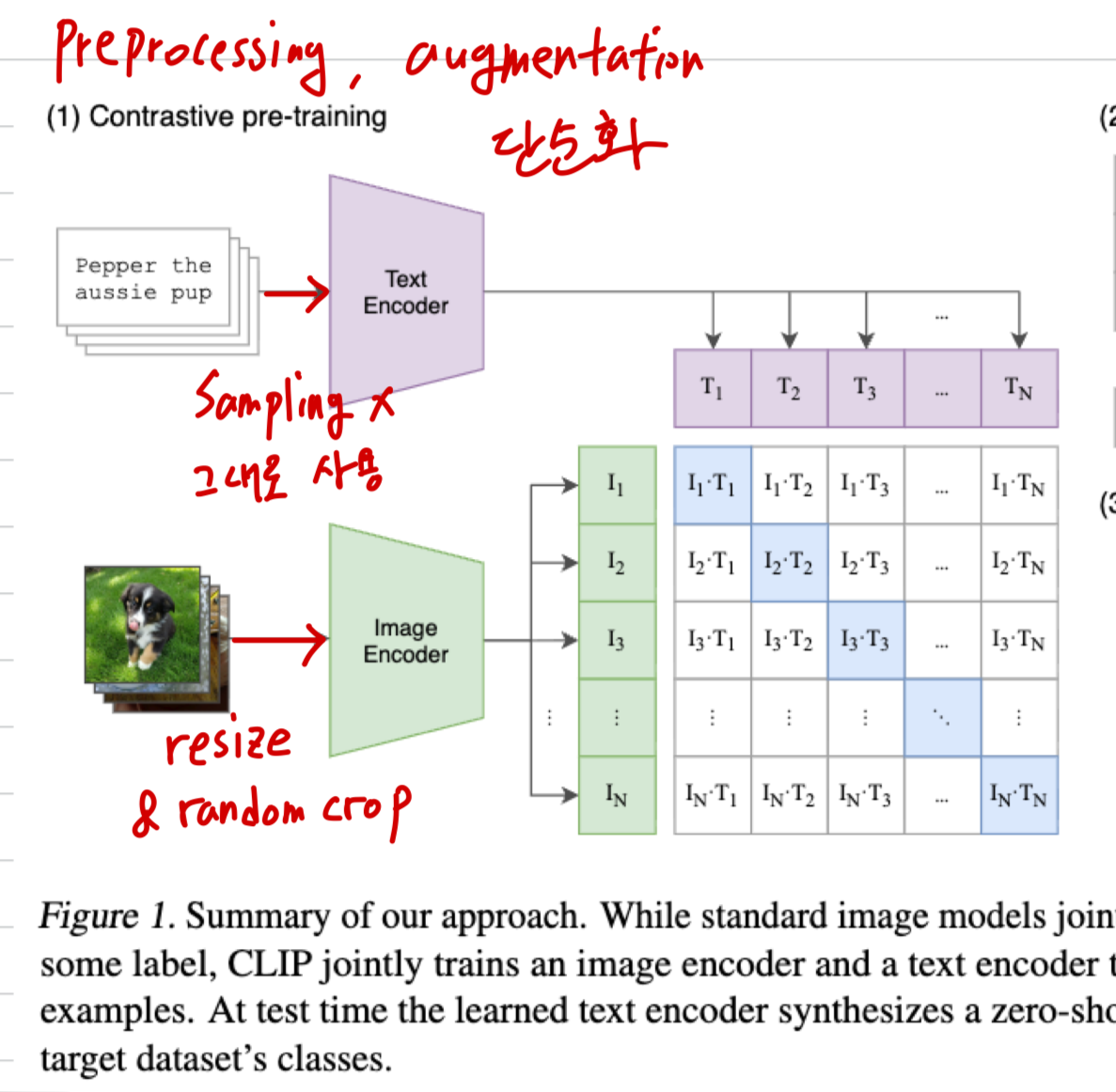
CLIP
- image: natural image 특성과 많은 데이터가 있기 때문에 ImageNet-style + random crop 정도로 단순화함.
- text: internet caption은 대부분 짧기 때문에 sampling 없이 text 그대로 사용

Efficient Deep Learning