[2021 ICML] [simple review] (ALIGN) Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
[Paper Review] VLM to LMM
Paper Info.
Jia, Chao, et al. "Scaling up visual and vision-language representation learning with noisy text supervision." International conference on machine learning. PMLR, 2021.


Abstract
(background)
- Pre-trained representations은 많은 NLP and perception tasks에서 중요해지고 있다.
NLP에서 representation learning은 human annotations 없이 raw text로 training하는 쪽으로 변하고 있고,
visual and vision-language representations은 여전히 expensive하거나 expert knowledge가 필요한
curated(정제된) dataset에 의존하고 있다.
(background & 문제 제기)
- vision applications에서는, ImageNet이나 OpenImages와 같이 explicit class labels이 포함된 dataset을 사용해 representations을 학습하는 경우가 대부분이다.
vision-language 분야에서도 Conceptual Captions, MSCOCO, CLIP과 같은 popular datasets은 모두 data collection과 cleaning에 많은 비용이 드는 과정이 필요하다.
이러한 costly curation process(비용이 많이 드는 정제 과정)는 dataset의 규모를 제한하게 만들고, 결국 trained model의 scaling을 방해한다.
(제안)
- 본 논문에서는 Conceptual Captions dataset에서 사용된 expensive filtering or post-processing 단계 없이,
one billion image(10억 개) 이상의 image alt-text pairs로 구성된 a noisy dataset을 활용한다.
단순한 dual-encoder architecture를 사용하여 image와 text pairs의 visual and language representations을 contrastive loss로 align할 수 있도록 학습한다.
우리는 이 대규모 corpus가 dataset의 noise를 충분히 상쇄할 수 있으며, simple learning scheme임에도 불구하고 SOTA representations를 만들어낼 수 있음을 보여준다.- corpus란?
GPUT 답변: 대규모 text data 모음.
예를 들어, Wikipedia 전체 text, SNS 게시글 1억개, 뉴스 기사 100만 개 모음은 각각 한 개의 corpus를 의미한다.) - image alt-text란?
GPU 답변: HTML에서 image를 넣을 때 아래와 같이 씀.
<img src="cat.png" alt="a small brown cat sitting on a sofa" />
즉, alt-text(Alternative text)는 web page에서 image에 붙는 짧은 text 설명임.
web의 모든 image에 alt-text가 붙어있으니까 별도의 annotation 없이 수집하기 쉽고, 데이터가 엄청 많음.
단, 실제로는 image와 상관없는 text도 많고, 너무 짧거나 모호한 경우도 많기 때문에 noise도 있음.
- corpus란?
(실험)
- Our (pretrained된) visual representation은 ImageNet and VTAB과 같은 classification tasks에 transferred 시 strong performance를 보인다.
The aligned visual and language representations은 또한 zero-shot image classification를 가능하게 하고,
복잡한 cross-attention models와 비교하더라도 Flickr30K 및 MSCOCO image-text retrieval benchmarks에서 SOTA를 달성한다.
더 나아가, 이 representations들은 complex text 그리고 text+image를 이용한 cross-modality search를 가능하게 한다.- (image-text retrieval benchmark란?
GPT 답변: image와 text를 서로 정확히 매칭되는지를 평가하는 benchmark.
예를 들어, 하나의 image에 대해 5개 정도의 caption을 제공.
이 image와 가장 잘 맞는 caption을 prediction해라.
또는 이 caption과 가장 잘 맞는 image를 prediction해라.) - (text+image를 이용한 cross-modality search란?
GPT 답변: text와 image를 함께 입력하여, 다른 modality를 검색하거나 filtering하는 기술.
예를 들어, text로 "이런 스타일의 방에서 쓰일만한 의자", image로 "사용자가 참고용으로 올린 방 사진"을 각각 query 했을 때,
두 modality의 정보를 융합하여 그 방 분위기와 text 설명에 어울리는 의자 이미지를 찾아줌.)
- (image-text retrieval benchmark란?
1. Introduction
(background: vision, vision-language model에 대한 pre-training datasets을 만드는 것은 heavy work이기 때문에 datasets 규모가 여전히 작다.)
-
기존 문헌에서, vision과 vision-language representation learning은 보통 서로 다른 training data sources를 사용하며 별도로 연구되어 왔다.
-
vision domain에서는
ImageNet, OpenImages, JFT-300M과 같은 large-scale supervised data로 pretraining하는 것이
transfer learning을 통한 downstream tasks의 성능 향상에 매우 중요한 것으로 입증되었다.
하지만 이러한 pre-training datasets을 구성하기 위해서는 data gathering, sampling and human annotation 등과 같은 heavy work가 필요하며, 이는 dataset이 scale되기 어렵게 만든다. -
vision-language modeling에서도 pre-training은 de-facto(사실상 표준) approach가 되었다.
그러나 Conceptual Captions, Visual Genome Dense Captions, ImageBERT와 같은 vision-language pre-training datasets은
human annotaion, semantic parsing, cleaning and balancing의 과정이 훨씬 더 heavier work이다.
그 결과, 이러한 dataset의 규모는 최대 10M개 examples 수준에 머무르며,
이는 순수 vision domain의 pre-training datasets에 비해 적어도 한 자릿수 이상 작고,
또한 NLP pre-training을 위해 수집된 large corpora of text에 비해 훨씬 작은 규모이다.
-
(제안: noisy dataset을 대규모로 구성하여, vision and vision-language representaion learning을 대규모로 확장)
-
이 연구에서는 ,
1B(10억) 개 이상의 noisy image alt-text pairs로 구성된 dataset을 활용하여
vision and vision-language representation learning을 scale(확장)한다.
우리는 Conceptual Captions(Sharma et al., 2018)의 procedures(절차)를 따라 a large noisy dataset을 만들되,
원 논문에서 제안한 complex filtering and post-processing steps을 적용하지 않고,
simple frequency-based filtering만 적용했다.
결과적으로 dataset은 noisy하지만, Conceptual Captions보다 two orders of magnitude(두 자릿수=100배) 더 크다.
우리는 이 exacale dataset으로 pre-trained한 vision and vision-language representations이
a wide range of tasks에서 strong performance를 달성했음을 보인다. -
우리 model을 train하기 위해,
a simple dual-encoder architecture를 이용하여
visual and language representation을 a shared latent embedding space (공유되 잠재 임베딩 공간)으로 align해주는 objective를 사용한다.
이러한 비슷한 objectives는 visual-semantic embedding(VSE)(Frome et al., 2013; Faghri et al., 2018) 학습에서도 사용된 바 있다.
우리는 이 model을 ALIGN: A Large-scale ImaGe and Noisy-text embedding이라고 부른다.- image encoder와 text encoder는 contrastive loss (normalized softmax 형태)로 학습된다.
이 loss는 matched image-text pair의 embedding은 가까워지도록,
non-matched image-text pair는 멀어지도록 학습시킨다.
이는 self-supervised와 supervised representation learning 모두에서 most effective loss functions 중 하나로 알려져 있다. - paring된 texts를 images의 fine-grained labels라고 간주하면,
image-to-text contrastive loss는 conventinoal label-based classification objective와 유사하다.
단, key difference는 text encoder가 "label" weights를 생성한다는 점이다.
(내가 이해한 내용: CLIP에서 활용한 contrastive learning과 똑같네.
그리고 반대로 생각해도 같은 직관이겠네.
paring된 images를 texts들의 label candidates라고 간주하면,
text-to-image contrastive loss는 text가 설명하는 올바른 image를 찾는 N-way classification objective와 유사한데,
여기서 주요 차이점은 image encoder가 "class generator"로 작동한다는 점.)
- image encoder와 text encoder는 contrastive loss (normalized softmax 형태)로 학습된다.
-
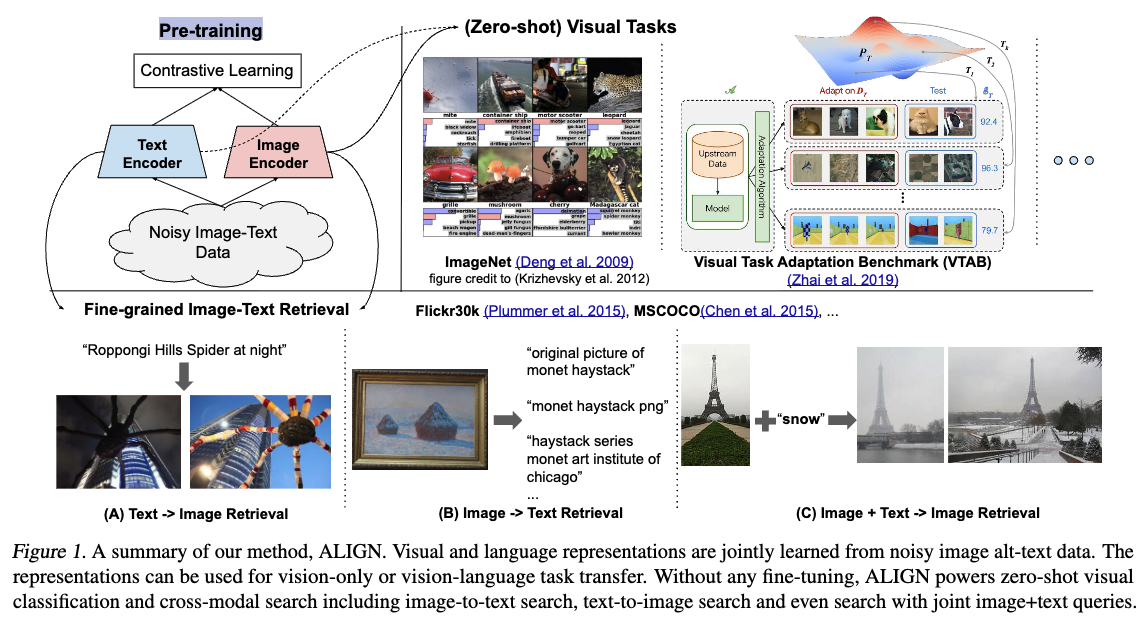
Figure 1의 top-left(내가 1이라고 표시해놓은 부분)는 ALIGN에서 사용한 방법을 요약한다.
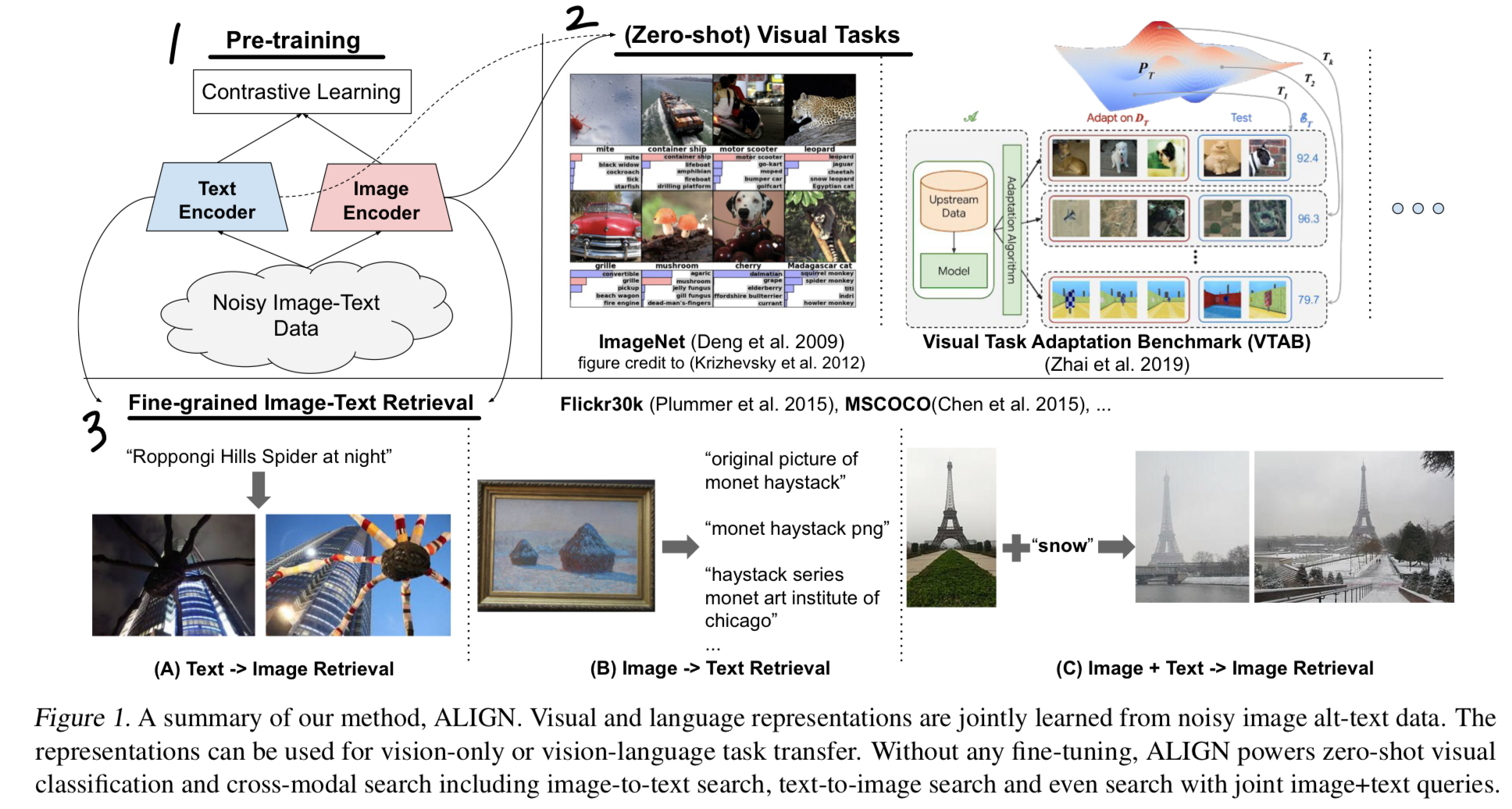
-
aligned image and text representations는 본질적으로
cross-modality matching/retrieval tasks에 매우 적합하며, 해당 bechmarks에서 SOTA를 달성.
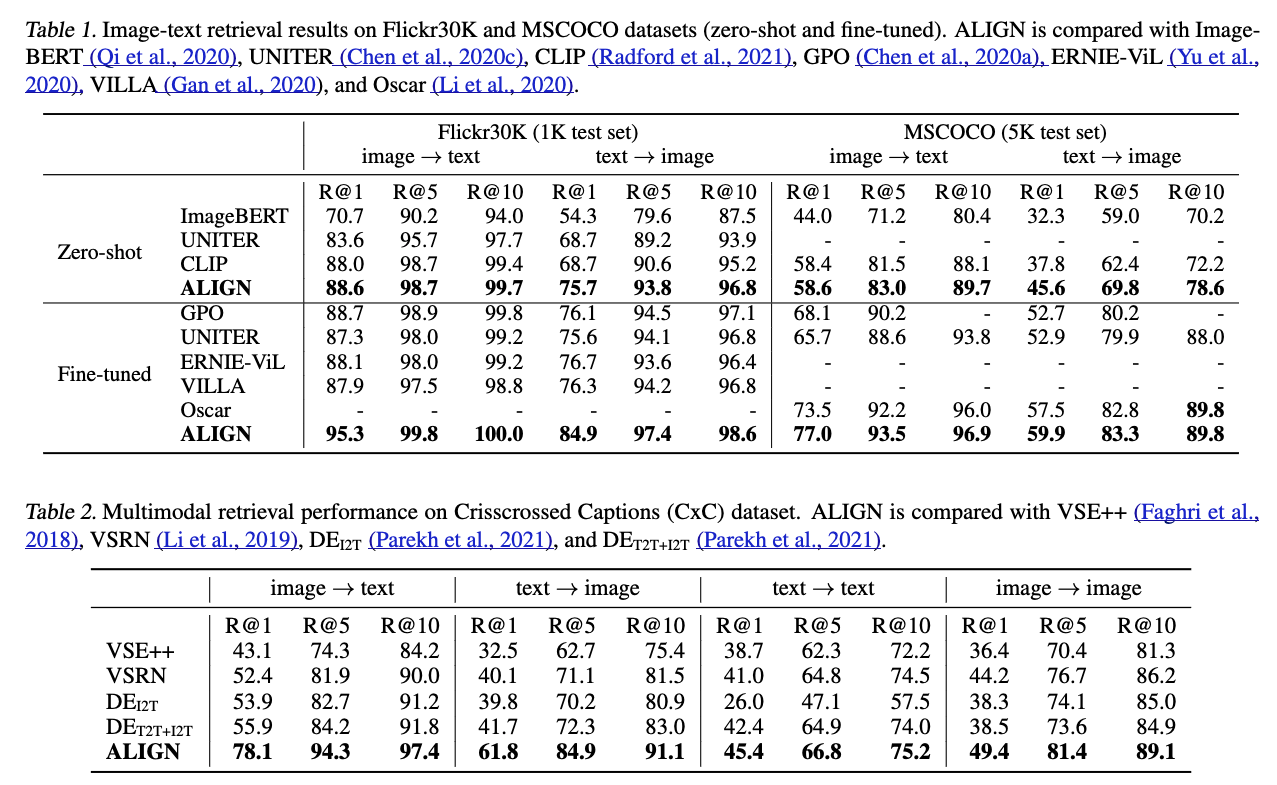
예를 들어, ALIGN은 Flickr30K와 MSCOCO에서 대부분의 zero-shot 및 fine-tuned R@1 metric에서 이전 SOTA method 보다 7% 이상 outperform한다.
또한 이러한 cross-modality matching은 classnames을 text encoder에 입력하기만 하면 zero-shot image classification이 가능하도록 한다.
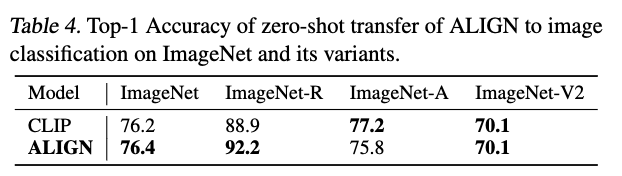
ImageNet training samples를 하나도 사용하지 않고도 76.4% top-1 accuracy를 달성한다.
image representation 자체도 다양한 downstream visual tasks에서 superior performance를 보인다.
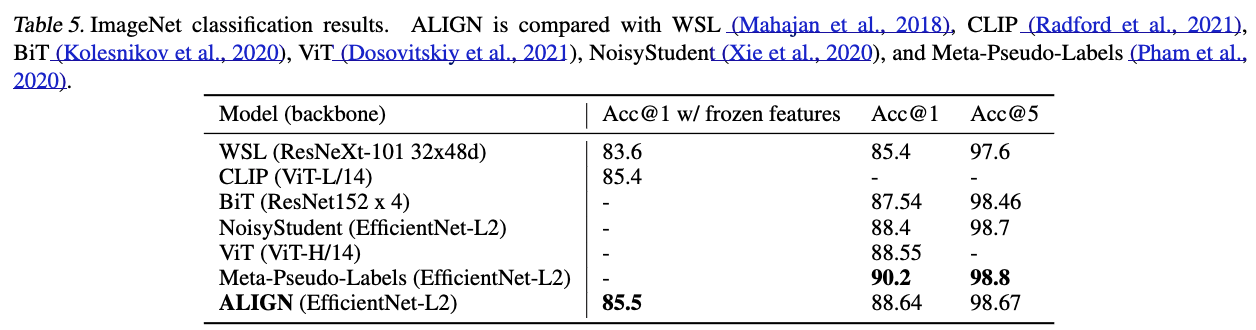
예를 들어, ALIGN은 ImageNet에서 88.64% top-1 accuracy를 달성한다.
Figure 1-bottom(내가 3이라고 표시해놓은 부분)은 ALIGN으로 구축된 실제 retrieval system에서 나온 cross-modal retrieval examples를 보여준다.
2. Related Work
-
High-quality visual representations은 일반적으로 large-scale labeled datasets에서 pre-trained되어 image classification or retrieval에 사용된다.
최근에는 self-supervised learning과 semi-supervised learning도 alternative paradigms로 연구되고 있다.
그러나 이러한 방법들로 학습된 모델은 downstream tasks로의 transferability가 제한적이다. -
image와 natural language captions을 확용하는 접근도 visual representations의 또 다른 방향이다.
Joulin et al. (2015); Li et al. (2017); Desai & Johnson (2020); Sariyildiz et al. (2020); Zhang et al. (2020)은
image로부터 caption을 prediction하는 방식으로 good visual representation을 학습할 수 있음을 보였으며,
이는 our work에도 영감을 주었다.
그러나 이러한 연구들은 Flickr나 COCO Captions처럼 small datasets에 한정되며,
그 결과 model은 cross-modal retrieval과 같은 tasks에 필요한 vision-language representation을 제공하지 못한다. -
vision-language learning domain에서는 Visual-Semantic Embedding (VSE)와, improved versions(즉, object detectors, dense feature maps, or multi-attention layers 등)이 제안되어 왔다.
최근에는 cross-modal attention layer를 활용하는 advanced model들이 등장했고, image-text matching tasks에서 뛰어난 성능을 보인다.
하지만 이러한 모델들은 속도가 매우 느리고, real world에서 image-text retrieval systems에는 impractical하다.
이에 반해, 우리의 ALIGN model은 the simplest VSE form을 유지하면서도, 기존의 모든 cross-attention model을 image-text matching benchmarks에서 outperform한다.- VSE(Visual-Semantic Embedding)?
GPT 답변: image와 text를 같은 semantic space에 mapping하여 서로 연관성을 비교할 수 있게 만드는 학습 방법
- VSE(Visual-Semantic Embedding)?
- 우리 연구와 가장 밀접한 관련이 있는 것은 CLIP인데,
CLIP 또한 similar contrastive learning setting에서
natural language supervision을 통한 visual representation learning을 제안한다.
두 model의 차이점은 vision과 language encoder 각각의 차이 외에도 training data 구성 방식에 있다.
ALIGN은 raw alt-text data로부터 얻은 natural distribution of image-text pairs를 그대로 사용한다.
CLIP은 먼저 English Wikipedia에서 high-frequency visual concepts의 allowlist를 만들고, 이를 기반으로 dataset을 구축한다.
ALIGN은 expert knowledge가 필요 없는 dataset으로도 strong visual and vision-language representations을 학습할 수 있음을 보여준다.
(ALIGN은 그냥 web에서 alt-text 긁어모은 있는 그대로의 natural data 사용.
CLIP은 allowlist 즉, 허용 목록을 만들고, 그 개념이 있는 data만 사용.
그래서 ALIGN은 CLIP보다 noise는 더 많지만, 훨씬 더 큰 scale의 dataset을 구축.)
3. A Large-Scale Noisy Image-Text Dataset
-
우리 연구의 focus는 visual and vision-language representation learning을 scale up 하는 것이다.
이를 위해, 우리는 기존 dataset보다 much larger dataset을 사용한다.
구체적으로, 우리는 Conceptual Captions(Sharma et al., 2018)을 구축한 methodology를 따라
raw English alt-text data(image and alt-text pairs)를 수집한다. -
Conceptual Captions dataset은 heavy filtering and post-processing을 거쳤다.
그러나 우리는 scale을 최우선으로 하기 때문에,
original work의 대부분의 cleaning steps을 생략하여
quality를 희생하는 대신 scale을 크게 늘린다. -
대신, 아래에 설명한 minimal frequency-based filtering만 적용한다.
그 결과, 1.8B(18억) 개의 image-text pair로 구성된 a much larger but noiser dataset을 얻는다.
Figure 2는 해당 dataset의 sample이다.

Image-based filtering
-
Sharma et al. (2018)을 따라 다음 규칙으로 image를 걸러낸다:
- pronographic images 제거
- shorter side가 200 pixels 이상
- aspect ratio가 3보다 작은
- 1000개 이상 alt-text가 달린 image 제거
- downstream evaluation datasets(ILSVRC-2012, Flickr30K, MSCOCO)의 test images와 중복/유사한 image 제거
-
자세한 내용은 Appendix A
Text-based filtering
- 다음 조건으로 alt-text를 걸러낸다:
- 10개 이상의 image에 공유되는 alt-text 제거
- image의 내용과 상관 없는 text 제거 (“1920x1080”, “alt img”, “cristina”)
- alt-text 내 token 중 rare token 포함 시 제거
(전체 raw 데이터에서 가장 자주 등장하는 unigram+bigrams 1억 개 밖에 없도록 제한)- (이게 무슨 뜻이지?)
GPT 답변:
rare token이란, 전체 data alt-text corpus에서 가장 자주 등장한 1억 개의 unigram(단어 1개짜리 token 단위. 예: New) + bigram(연속된 단어 2개를 묶어서 보는 token 단위. 예: New York) 목록에 포함되지 않은 단어/구를 뜻함.
즉, 전체 데이터에서 자주 등장하는 단어/구 (1억 개)를 allowlist로 만들고,
alt-text 안에 allowlist에 없는 rare 단어가 나오면, 그 alt-text는 너무 noise가 많다고 판단하여 제거.
왜 이렇게 하는가?
“image tid 25&id mggqpuweqdpd&cache 0&lan code 0” 또는 “x9a0c03dh29” 처럼 쓰레기 문자열(cache string, URL 조각, 등)이 많기 때문.
- (이게 무슨 뜻이지?)
- alt-text 길이가 너무 짧은 경우 (3개 미만 unigram) 또는 너무 긴 경우 (20개 초과 unigram) 제거
4. Pre-training and Task Transfer
4.1. Pre-training on Noisy Image-Text Pairs
-
우리는 dual-encoder architecture를 이용하여 ALIGN을 pre-train했다.
model은 한 쌍의 image encoder와 text encoder로 구성되어 있으며,
상위에는 cosine-similarity combination을 사용한다. -
image encoder로는 EfficientNet을 global pooling과 함께 사용한다.
(classification head의 1x1 conv layer는 학습하지 않는다)
text encoder는 BERT의 token embedding을 text embedding encoder로 사용한다.
(우리의 training dataset으로부터 100k=10만 개의 wordpiece vocabulary를 생성했다.)
image tower와 dimension을 맞추기 위해, BERT encoder 위에 FC layer with linear activation을 추가했다.
image encoder와 text encoder는 둘 다 scratch부터 train된다. -
image encoder와 text encoder는 normalized softmax loss(Zhai & Wu, 2019)를 사용해 optimized된다.
training 시에는,
matched image-text pairs를 positive로 보고,
training batch 안에서 만들 수 있는 all other random image-text pairs는 negative로 취급한다.
우리는 the sum of two losses를 minimize한다.- one for image-to-text classification:
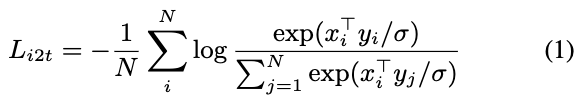
- and the other for text-to-image classification:
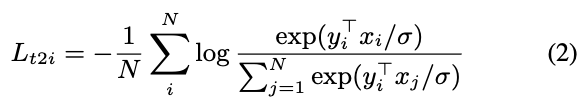
여기서,
는 -th pair의 normalized embedding of image,
는 -th pair에서 normalized embedding of text 이다.
은 batch size,
는 logit을 scale해주는 temperature이다.
in-batch negative의 효과를 더 크게 하기 위해, 우리는 모든 computing cores에서 나온 embeddings을 concatenate해 훨씬 더 큰 batch를 만든다.
temperature variable은 image embedding과 text embedding이 모두 L2-normalized되어 있기 때문에 매우 중요하다.
수동으로 optimal temperature value를 탐색하는 대신,
우리는 이 값 또한 다른 모든 parameter와 함께 학습하도록 하는 것이 효과적임을 발견했다.- (in-batch negative 효과를 크게 하기 위해, 모든 computing cores에서 나온 Embeddings을 concatenate해서 더 큰 batch를 만들었다고? 이게 무슨 의미야?
GPT 답변: multi GPU 환경에서 모든 device의 batch를 합쳐서 초대형 batch로 만든다는 뜻.
이렇게 하면 in-batch negative 수가 배로 늘어나서 constrastive learning이 더 강력해짐.
예를 들어, 8개의 각 GPU에서 256 batch를 계산하여 계산된 embedding을 모두 concatenate하면 8x256=2048. 즉 전체 batch 2048개가 됨.
이 2048 전체를 하나의 커다란 batch처럼 사용. 그러면 in-batch negative 수가 기존 대비 8배 증가.
contrastive learning에서는 negative sample이 많을수록 성능이 크게 증가한다고 함.
직관적으로 더 다양한 negative pair를 보게 되어 training signal이 잘 전파될 것이고, positive pair와 negative pair를 더 잘 구분하도록 할 수 있음. - (그럼 구현은 어떻게 해?)
GPT 답변: 각 device에서 local inference로 x_local, y_local을 얻음.
torch.distributed.all_gather로 모든 device의 x_local과 y_local을 모을 수 있음.
all_gather는 분산환경에서 모든 device가 가지고 있는 data를 수집하여, 모든 device가 전체 data를 복제하여 가지도록 만드는 통신.
메모리가 크다면 chunk 처리.
GPT가 짜준 예제 코드
- (in-batch negative 효과를 크게 하기 위해, 모든 computing cores에서 나온 Embeddings을 concatenate해서 더 큰 batch를 만들었다고? 이게 무슨 의미야?
- one for image-to-text classification:
# 전제: torch.distributed.init_process_group(...) 이미 호출되어 있음
# rank, world_size 구함
rank = dist.get_rank()
world_size = dist.get_world_size()
# x_local : [B, D], y_local : [B, D] (torch.Tensor, device='cuda')
# L2 normalize
x_local = F.normalize(x_local, dim=1)
y_local = F.normalize(y_local, dim=1)
# 1) all_gather to get x_all, y_all (no grad for gathered tensors)
# create buffers
B, D = x_local.shape
x_gather_list = [torch.zeros_like(x_local) for _ in range(world_size)]
y_gather_list = [torch.zeros_like(y_local) for _ in range(world_size)]
# gather
dist.all_gather(x_gather_list, x_local) # each tensor is [B, D]
dist.all_gather(y_gather_list, y_local)
# concatenate to form [N, D]
x_all = torch.cat(x_gather_list, dim=0) # N = world_size * B
y_all = torch.cat(y_gather_list, dim=0)
# -> x_all and y_all do NOT require grad (gathered), that's fine.
# 2) compute logits in chunks to save memory
temp = learned_temperature # scalar
labels = torch.arange(rank * B, rank * B + B, device=x_local.device, dtype=torch.long)
# compute image->text logits: [B, N]
def compute_logits_chunked(query, keys, chunk_size=1024):
# query: [B, D], keys: [N, D]
N = keys.size(0)
out_list = []
for start in range(0, N, chunk_size):
end = min(N, start + chunk_size)
# matmul chunk: [B, chunk]
chunk = torch.matmul(query, keys[start:end].T) / temp
out_list.append(chunk)
return torch.cat(out_list, dim=1) # [B, N]
logits_i2t = compute_logits_chunked(x_local, y_all, chunk_size=4096) # tune chunk_size
logits_t2i = compute_logits_chunked(y_local, x_all, chunk_size=4096)
# 3) cross entropy
loss_i2t = F.cross_entropy(logits_i2t, labels)
loss_t2i = F.cross_entropy(logits_t2i, labels)
loss = 0.5 * (loss_i2t + loss_t2i)
loss.backward()
optimizer.step()
4.2. Transferring to Image-Text Matching & Retrieval
-
우리는 image-text 및 text-image retrieval tasks에서, finetuning 여부에 따라 ALIGN model을 평가한다.
평가에는 두 가지 benchmark dataset인 Flickr30K(Plummer et al., 2015) 와 MSCOCO(Chen et al., 2015) 를 사용한다.
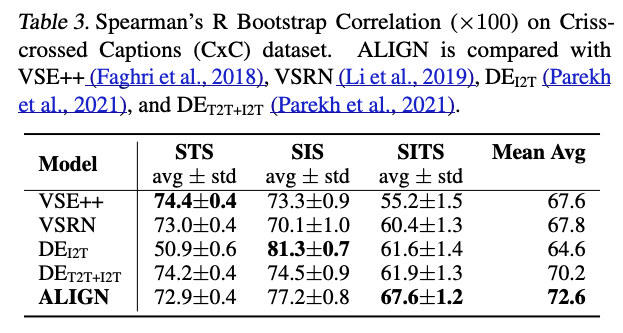
또한 MSCOCO를 확장한 Crisscrossed Captions(CxC) (Parekh et al., 2021) 에서도 ALIGN을 평가한다.
CxC는 caption-caption, image-image, image-caption pairs에 대해 human semantic similarity judgement (사람이 직접 제공한 의미적 유사도 label)를 추가로 포함한다.
(CxC는 MSCOCO에서 image-caption 쌍에 대해, c-c, i-i, i-c 간의 의미적 유사도를 사람이 직접 평가해 추가로 붙인 확장 데이터셋.
기존 MSCOCO의 한계를 보완하기 위해,
기존에는 강아지 이미지와 "cat" 은 둘 다 완전히 무관하지는 않지만 그냥 "wrong caption"이었음.
CxC는 이러한 경우에 의미적 유사성 점수를 제공함.)- CxC의 확장된 annotation을 통해, 다음과 같이 4개의 intra- and inter-modal retrieval tasks를 수행할 수 있다:
- image-to-text
- text-to-image
- text-to-text
- image-to-image
- CxC의 확장된 annotation을 통해, 다음과 같이 3개의 semantic similarity tasks를 수행할 수 있다:
- STS: semantic textual similarity
- SIS: semantic image similarity
- SITS: semantic image-text similarity
- CxC의 확장된 annotation을 통해, 다음과 같이 4개의 intra- and inter-modal retrieval tasks를 수행할 수 있다:
-
CxC의 training set은 original MSCOCO와 완전히 동일하므로,
MSCOCO로 fine-tuned한 ALIGN model을 그대로 CxC annotations을 통해 평가할 수 있다.
4.3. Transferring to Visual Classification
-
우리는 먼저 ALIGN을 ImageNet ILSVRC-2012 benchmark와
ImageNet-R(endition), ImageNet-A(dversarial), and ImageNet-V2를 포함한 variants들에 대해
zero-shot transfer 방식으로 평가한다.
이 모든 variants들은 the same set(or a subset) of ImageNet classes를 따르지만,
ImageNet-R과 ImageNet-A의 image는 ImageNet과 distributions이 매우 다르다. -
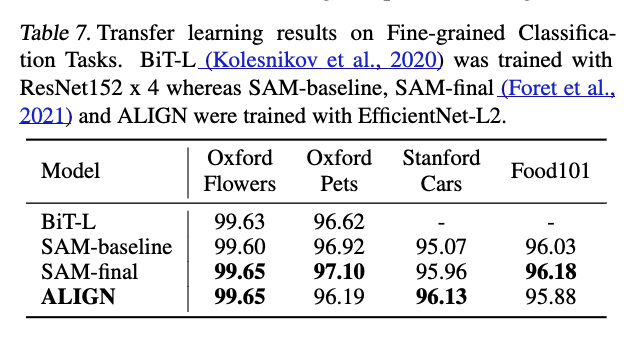
우리는 또한 ALIGN의 image encoder를 다양한 downstream visual classification tasks에 transfer하여 평가한다.
이를 위해 ImageNet 뿐만 아니라 Oxford Flowers-102, Oxford-IIIT Pets, Stanford Cars, Food101 등
여러 a handler of smaller fine-graiend classification (소규모의 미세 분류) dataset을 사용한다.
ImageNet의 경우 두 가지 setting에서 결과를 보고한다:- ALIGN image encoder를 frozen시킨 채, top classification layer만 training하는 경우
- 전체 model을 fully fine-tuned하는 경우.
fine-graind classification benchmarks에는 2. 설정만 report했다.
-
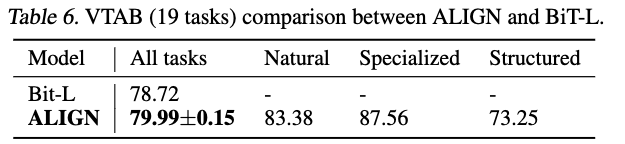
또한, Kolesnikov et al. (2020)을 따라 ALIGN model의 robustness를 Visual Task Adaptation Benchmark(VTAB) (Zhai et al., 2019)에서 평가한다.
VTAB는 natural, specialized and structured image classification tasks를 포함한 19개의 visual classification tasks로 구성되어 있으며,
각 task마다 1000개의 training samples만 제공한다.
5. Experiments and Results
5.1. Image-Text Matching & Retrieval
5.2. Zero-shot Visual Classification
5.3. Visual Classification w/ Image Encoder Only
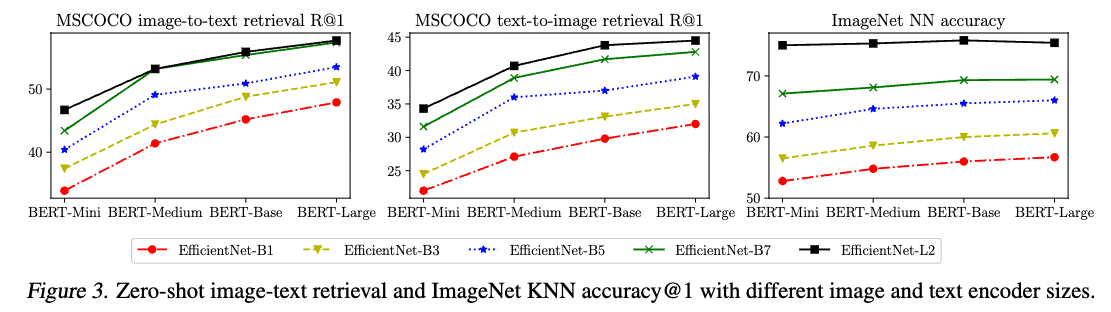
6. Ablation study
6.1. Model Architectures
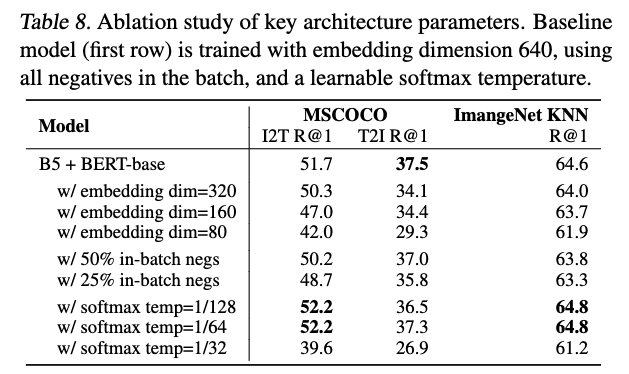
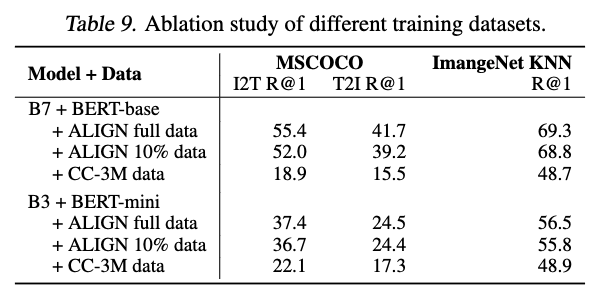
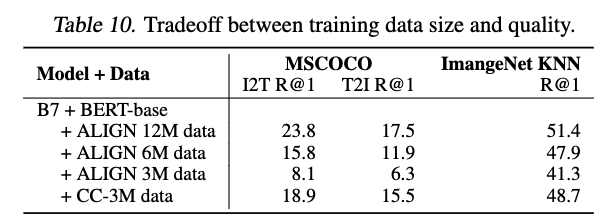
6.2. Pre-training Datasets
7. Analysis of Learned Embeddings


이 논문의 핵심
- CLIP과 같은 contrastive learning으로 model의 pre-training을 하는데,
CLIP의 정제된 dataset과 달리, web상의 noise가 많고 정제되지 않은 image alt-text pair로 더 큰 규모의 dataset으로 확장해,
CLIP을 능가하는 zero-shot transfer 가능.
즉, scale을 극대화.
