[2022 ICML] (Simple Review) BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
[Paper Review] VLM to LMM
Paper Info


Abstract
(Background)
- Vision-Language Pre-training (VLP)는 많은 vision-language tasks에서 성능을 향상시켜 왔다.
(문제 1)
- 하지만, 대부분의 pre-trained models은 understanding-based tasks 또는 generation-based tasks 중 하나에만 특화되어 뛰어난 성능을 내는 경우가 많다.
(문제 2)
- 또한, 성능 향상은 주로 web에서 수집된 noisy image-text pairs를 scaling up해서 대규모로 사용하는 방시에 의존해 왔는데,
이는 suboptimal source of supervision이다.
(제안)
- 이 논문에서는 BLIP이라는 a new VLP framework를 제안하는데,
이는 vision-language understanding and generation tasks 모두에 flexibly하게 transfer될 수 있다.
BLIP은 captioner가 synthetic captions을 생성하고, filter가 noisy caption을 제거하는 방식으로
nosiy web data를 효과적으로 활용한다.
(실험)
- BLIP은 다양한 vision-language task에서 SOTA를 달성했다.
예를 들어, image-text retrieval에서 average recall@1을 +2.7%,
image captioning에서 CIDEr을 +2.8%,
VQA에서 VQA score를 +1.6%
향상을 이루었다.
또한 BLIP은 video-language tasks에서 곧바로 zero-shot으로 적용했을 때도 강한 generalization ability를 보였다.
https://github.com/salesforce/BLIP
1. Introduction
(VLP에서 related work의 두 가지 문제)
- vision-language pre-training (VLP)는 다양한 multimodal downstream tasks에서 성공을 거두고 있다.
하지만, 기존 방법들은 two major limitations을 갖는다:- Model perspective:
대부분의 방법은 encoder-based model 또는 encoder-decoder model 중 하나를 적용한다.
하지만 encoder-based model은 image captioning과 같은 text generation tasks로 directly transfer하기 어렵다.
반면, encoder-decoder model은 image-text retrieval task에서 성공적으로 사용된 사례가 없다. - Data perspective:
대부분의 SOTA 방법들(CLIP, ALBEF, SimVLM 등)은 web에서 수집된 image-text pairs를 활용해 pre-train한다.
dataset을 scaling up하면 성능이 향상되긴 하지만,
본 논문은 noisy web text가 vision-language learning에 suboptimal하다는 것을 보여준다.
- Model perspective:
(제안과 기여점)
- 이를 해결하기 위해, 우리는 BLIP: Bootstrapping Language-Image Pre-training을 제안한다.
BLIP은 기존 방법들보다 wider range of downstream tasks를 수행할 수 있는 a new VLP framework이다.
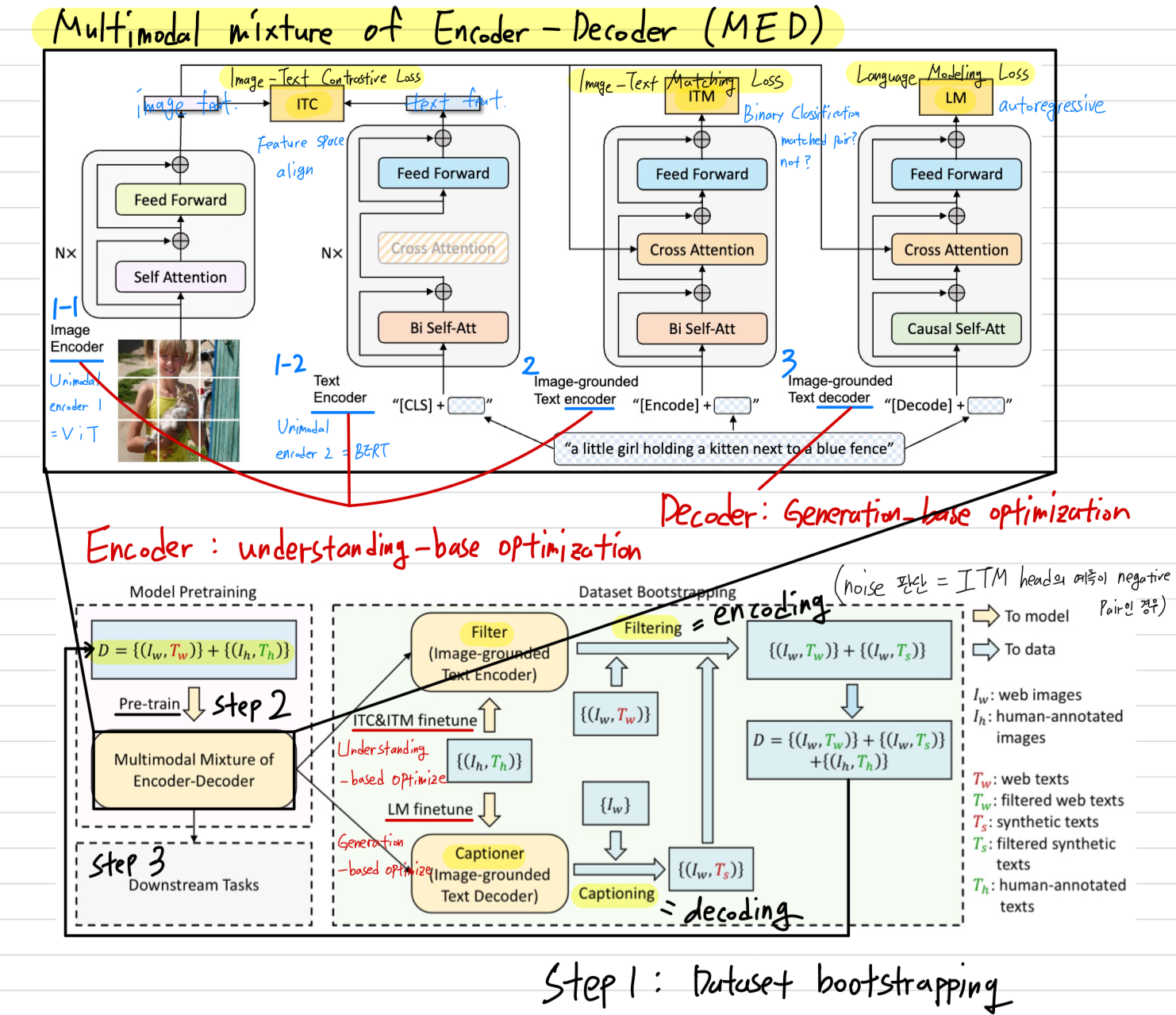
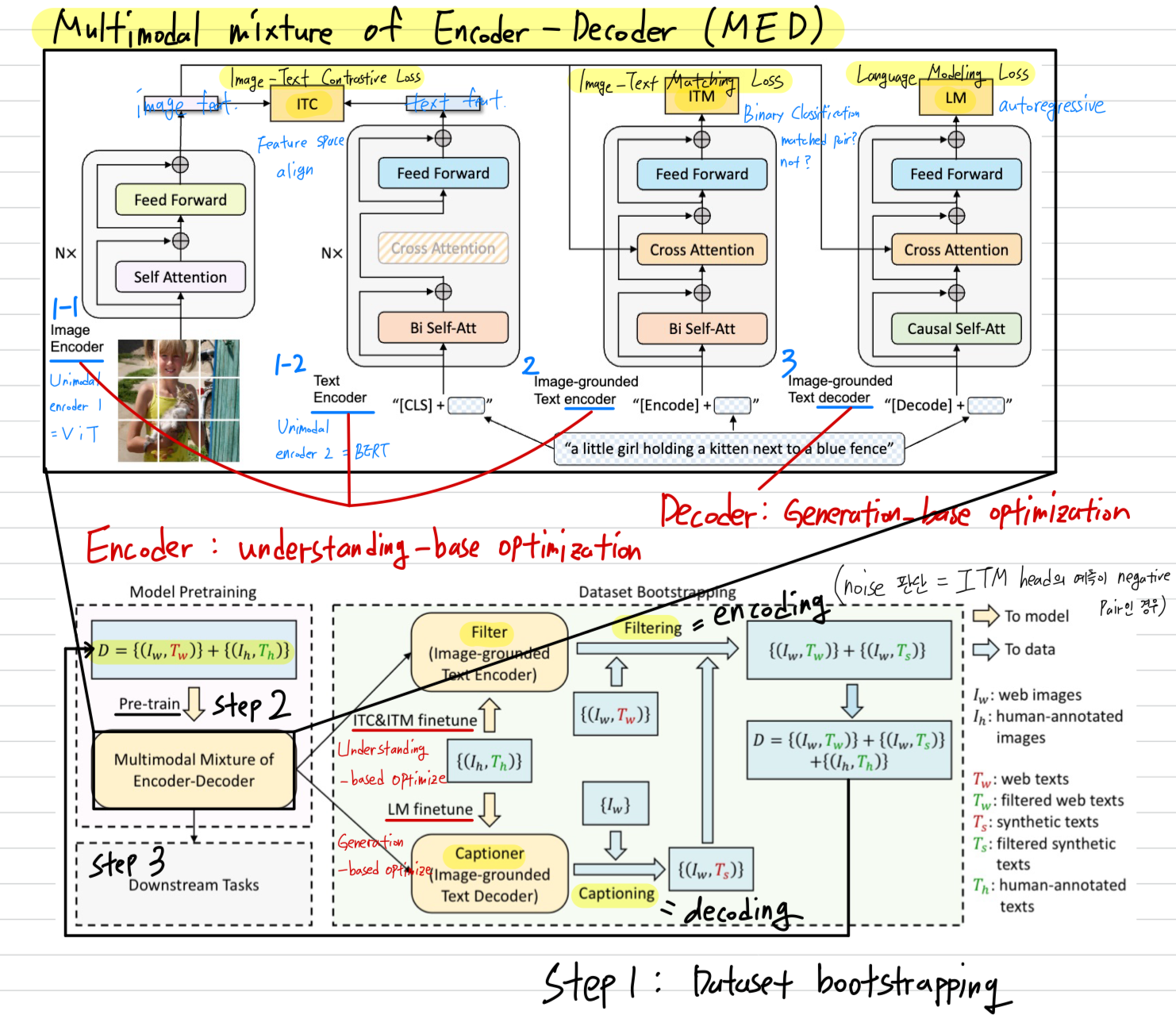
BLIP은 model perspective와 data perspective에서 각각 다음과 같은 two contributions을 포함한다.- Multimodal mixture of Encoder-Decoder (MED):
effective multi-task pre-training and flexible transfer learning을 위한 a new model architecture.
MED는 다음과 같이, 여러 방식 중 하나로 동작할 수 있다.
(1. unimodal encoder, 2. image-grouned text encoder, 3. image-grounded text decoder)
이 model은 세 가지 vision-language objectives를 통해 jointly pre-trained된다.
(1. image-text contrastive learning, 2. image-text matching, 3. image-conditioned language modeling) - Captioning and Filtering (CapFilt): noisy image-text pairs로부터 학습하기 위한 a new dataset bootstrapping method이다.
우리는 pre-trained MED를 fine-tuning하여 두 개의 module로 구성한다.
(1. web image가 주어졌을 때 synthetic caption을 생성하는 captioner)
(2. original web texts와 the synthetic texts 모두에서 noisy captions을 제거하는 filter)
- bootstrapping method란?
사전적 의미: bootstrap은 외부 지원 없이 스스로 시작하여 진행되는 과정을 의미함. 컴퓨터 전원을 켜서 booting되는 듯한.
GPT 답변: 기존 데이터에서 스스로 더 좋은 데이터를 만들어내며 학습을 향상시키는 방법.
(여기까지 내가 이해한 내용: noisy raw data captioner를 통해 더 좋은 caption 생성 filter를 통해 noisy caption 제거 더 좋은 data로 학습)
- bootstrapping method란?
- Multimodal mixture of Encoder-Decoder (MED):
(실험과 관찰)
- 우리는 extensive experiments and analysis를 했고,
다음의 key observations을 만들어냈다.- captionre와 filter를 같이 활용하여, captions을 bootstrapping함으로써 다양한 downstream tasks에 큰 성능 향상을 달성할 수 있다.
또한 more diverse captions을 사용할수록 larger gain을 얻을 수 있음을 발견했다. - BLIP은 image-text retrieval, image captioning, visual question answering, vision reasoning, and visual dialog와 같은
a wide range of vision-language tasks에서 SOTA를 달성했다.
또한, two video-language tasks: text-to-video retrieval and videoQA에 대해
model을 바로 zero-shot으로 transfer했을텍스트 때도 SOTA를 달성한다.
- captionre와 filter를 같이 활용하여, captions을 bootstrapping함으로써 다양한 downstream tasks에 큰 성능 향상을 달성할 수 있다.
2. Related Work
2.1. Vision-language Pre-training
(요약: web에서 수집한 noisy image–text pairs로 학습하는 기존 VLP의 한계를 지적, CapFilt 기법을 통해 noisy data를 더 효과적으로 활용하는 방법을 제안)
- VLP는 large-scale image-text pairs로 model을 pre-training하여 이후의 downtream vision and language tasks의 성능을 향상시키는 것을 목표로 한다.
하지만 human-annotated texts를 확보하는 데 비용이 매우 크기 때문에,
대부분의 기존 방법들은 image and alt-text pairs crawled from the web을 사용한다.
simple rule-based filters에도 불구하고, web texts는 여전히 많은 noise가 존재한다.
하지만 the negative impact of the noise는 dataset을 scaling up함으로써 얻는 performance gain에 가려져, 그동안 크게 주목되지 않았다.
우리 논문은 noisy web texts are suboptimal for vision-language learning임을 보이고,
이를 더 효과적으로 활용하기 위한 CapFilt 기법을 제안한다.
(요약: understanding-based tasks와 generation-based tasks를 모두 처리할 수 있는
새로운 Multimodal mixture of Encoder-Decoder architecture로 기존 모델들의 구조적 한계를 해결)
- 여러 vision and language tasks를 a single framework로 unify하려는 시도가 많았다.
The biggest challenge는 understanding-based tasks (즉, image-text retrieval)과 generation-based tasks (즉, image captioning)를
모두 수행할 수 있는 model architecture를 설계하는 것이다.
그러나 encoder-based models도, encoder-decoder models도 두 tasks 모두에서 뛰어난 성능을 내지 못하며,
a single unified encoder-decoder (Zhou et al., 2020) 또한 model's capability를 제한한다.
우리가 제안하는 multimodal mixture of encoder-decoder(MED) model은
more flexibility and better performance on a wide range of downstream tasks를 제공하며,
동시에 pre-training을 simple and efficient하게 유지할 수 있다.
2.2. Knowledge Distillation
(요약: captioner와 filter는 각각 synthetic caption 생성과 noise 제거를 통해 knowledge를 전달하는 새로운 형태의 self-distillation 방식이다)
-
Knowledge distillation (KD)는 teacher model로부터 student model로 knowledge를 distilling하여 student model의 성능을 향상시키는 것을 목표로 한다.
Self-distillation은 teacher and student가 equal sizes인 특수한 KD의 형태이다.
이는 image classification(Xie et al., 2020)뿐 아니라 최근에는 VLP(Li et al., 2021a)에서도 효과가 있음이 보여졌다. -
대부분의 기존 KD 방법은 teacher model이 student model과 same class prediction을 하도록 강제하는 방식을 사용한다.
그러나 우리가 제안하는 CapFilt는 VLP의 맥락에서, 더 효과적인 KD 방식으로 해석될 수 있다.
이 방법에서는 captioner가 semantically-rich synthetic captions을 생성하여 그 knowledge를 distill하고,
filter는 noisy captions을 제거함으로써 자신의 knowledge를 distill한다.
2.3. Data Augmentation
(요약: BLIP은 synthetic captions를 이용해 large-scale VLP에서 성능을 향상시킬 수 있음을 보여준다.)
- data augmentation (DA)는 CV에서 널리 사용되고 있지만, language tasks에서는 less straightforward하다.
최근에는, generative language model을 활용해 다양한 NLP tasks를 위한 examples을 synthesize하는 방법들이 등장했다.
이러한 기존 방법들이 low-resource language-only tasks에 초점을 맞추는 것과 달리,
우리 방법은 large-scale vision-language pre-training에서 synthetic captions의 장점을 보여준다.
3. Method
- 우리는 noisy image-text pairs로부터 학습할 수 있는 a unified VLP framework, BLIP을 제안한다.
이 section에서는 먼저 our new model architecture MED와 its pre-training objectives를 소개하고,
이어서 CapFilt를 통한 dataset bootstrapping을 설명한다.
3.1. Model Architecture
-
우리는 image encoder로 Vision Transformer (ViT)를 사용한다.
ViT는 input image를 patch로 나누고 이를 a sequence of embeddings로 encoding하며,
global image feature를 나타내기 위해 an additional token을 포함한다.
이는 object detector를 사용해 visual feature extraction하던 기존 방식에 비해 computation-friendly하고,
최근 연구에서도 채택되는 추세이다. -
unified model이 understanding and generation 능력을 모두 갖추도록 하기 위해,
우리는 multimodal mixture of encoder-decoder (MED)라는 multi-task model을 제안한다.
MED는 다음 3가지 functionalities(기능들) 중 하나로 동작할 수 있다.
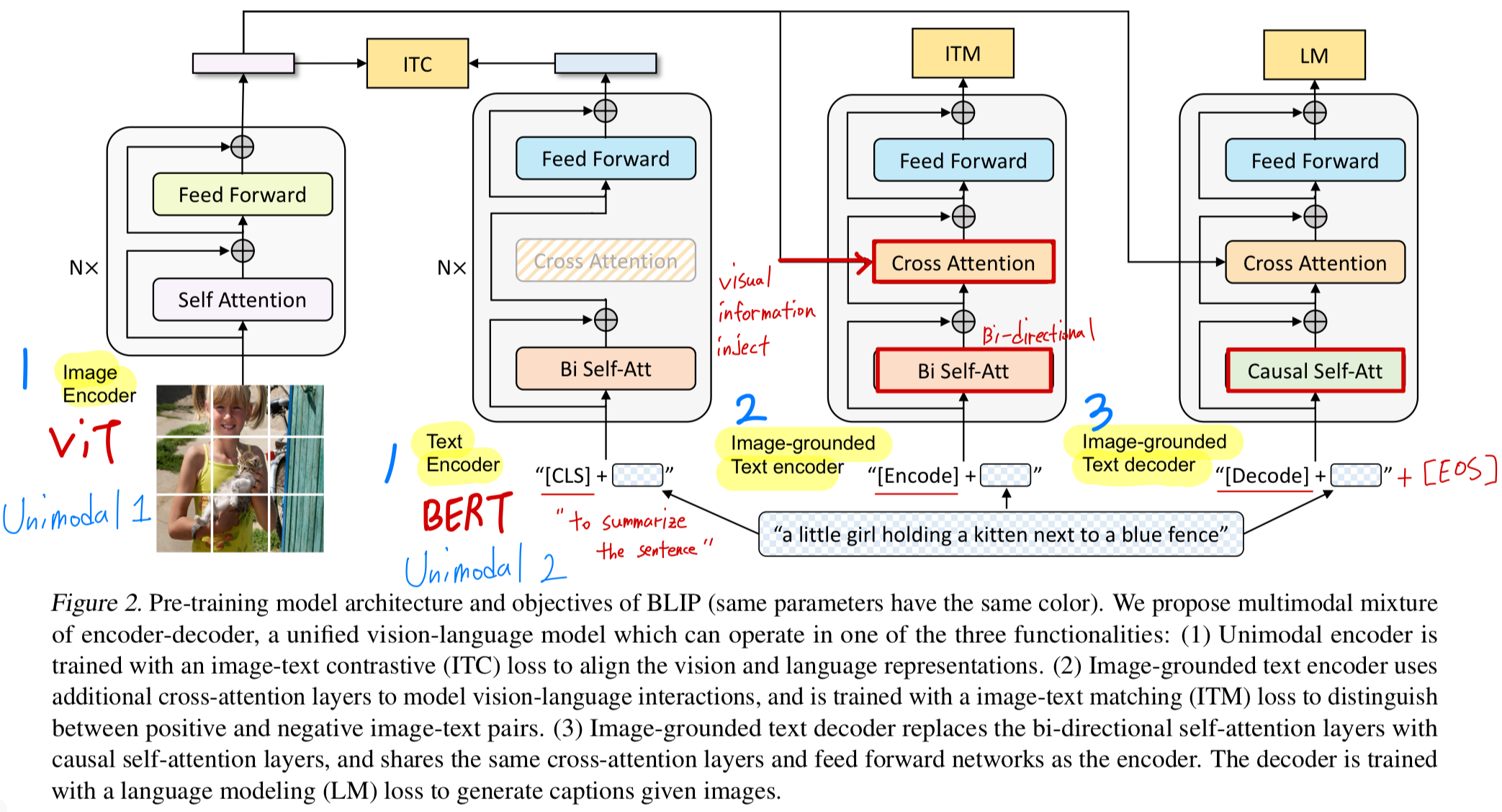
Unimodal encoder:
image와 text를 각각 독립적으로 encoding한다.
text encoder는 BERT이며, sentence를 요약하기 위해 text input의 맨 앞에 token을 붙인다.Image-grounded text encoder:
text encoder의 각 transformer block에 대해 self-attention (SA) layer와 FFN 사이에
cross-attention (CA)를 넣어 visual information을 inject한다.
text에는 task-specific token이 추가되고,
최종적으로 이 token의 output embedding이 image-text pair의 multimodal representation으로 사용된다.Image-grounded text decoder:
image-grounded text encoder와 구조는 비슷하지만,
여기서는 bi-directional self-attention을 causal(uni-directional) self-attention으로 교체하였다.
text 생성을 위해 token이 the beginning of a sequence를 나타내며,
문장의 끝을 표시하기 위해 end-of-sequence token( 말하는 듯)을 사용한다.
3.2. Pre-training Objectives
- 우리는 pre-training 동안에 3가지 objectives(2개의 understanding-based objectives와 1개의 generation-based objective)를 optimize했다.
각 image-text pair는
computational-heavier ViT를 한 번만 forward pass하며,
text transformer는 3가지 functionalities 각각 activate하여 3번의 forward pass를 수행하며,
아래에서 설명하는 3가지 losses를 계산한다.
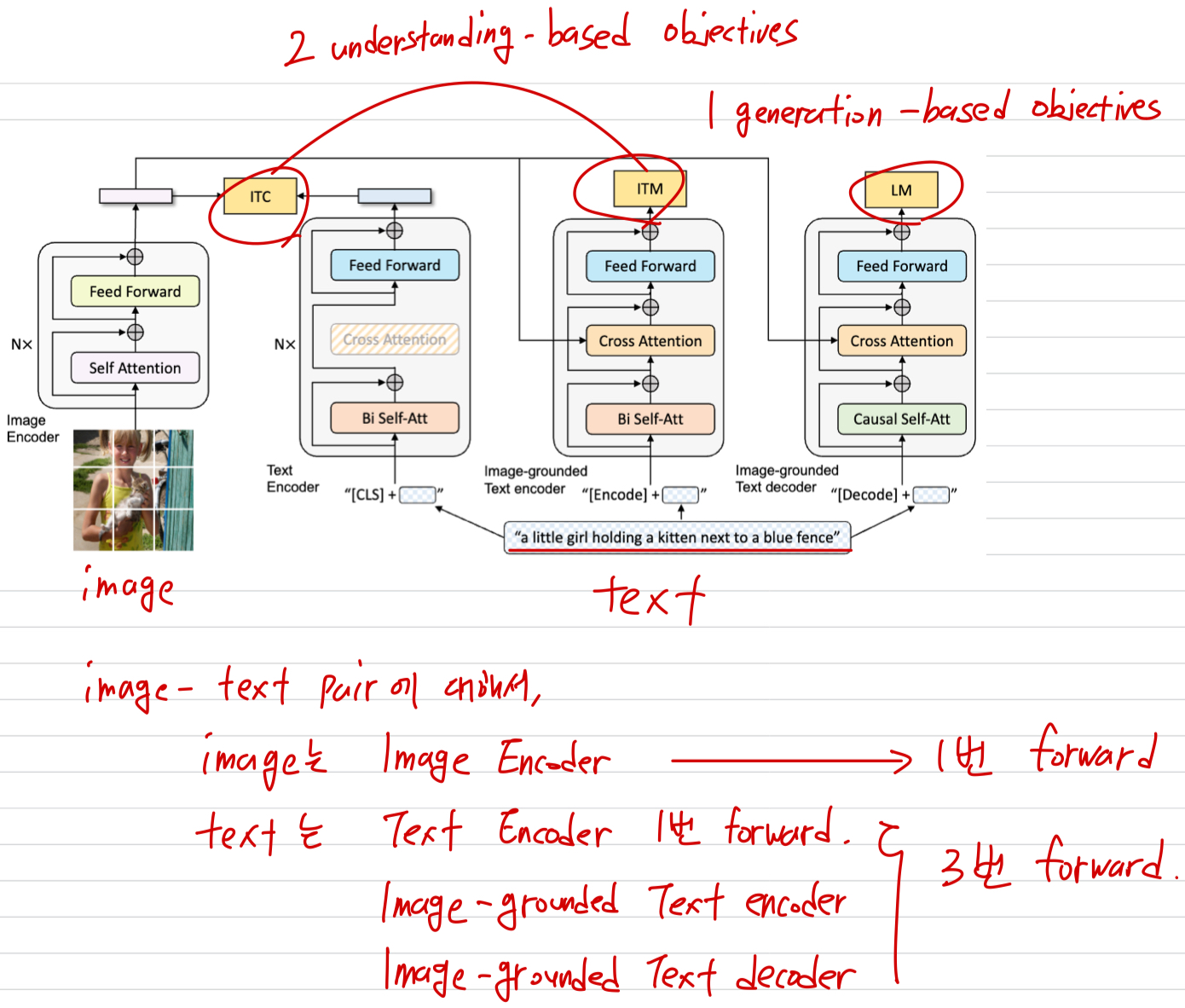
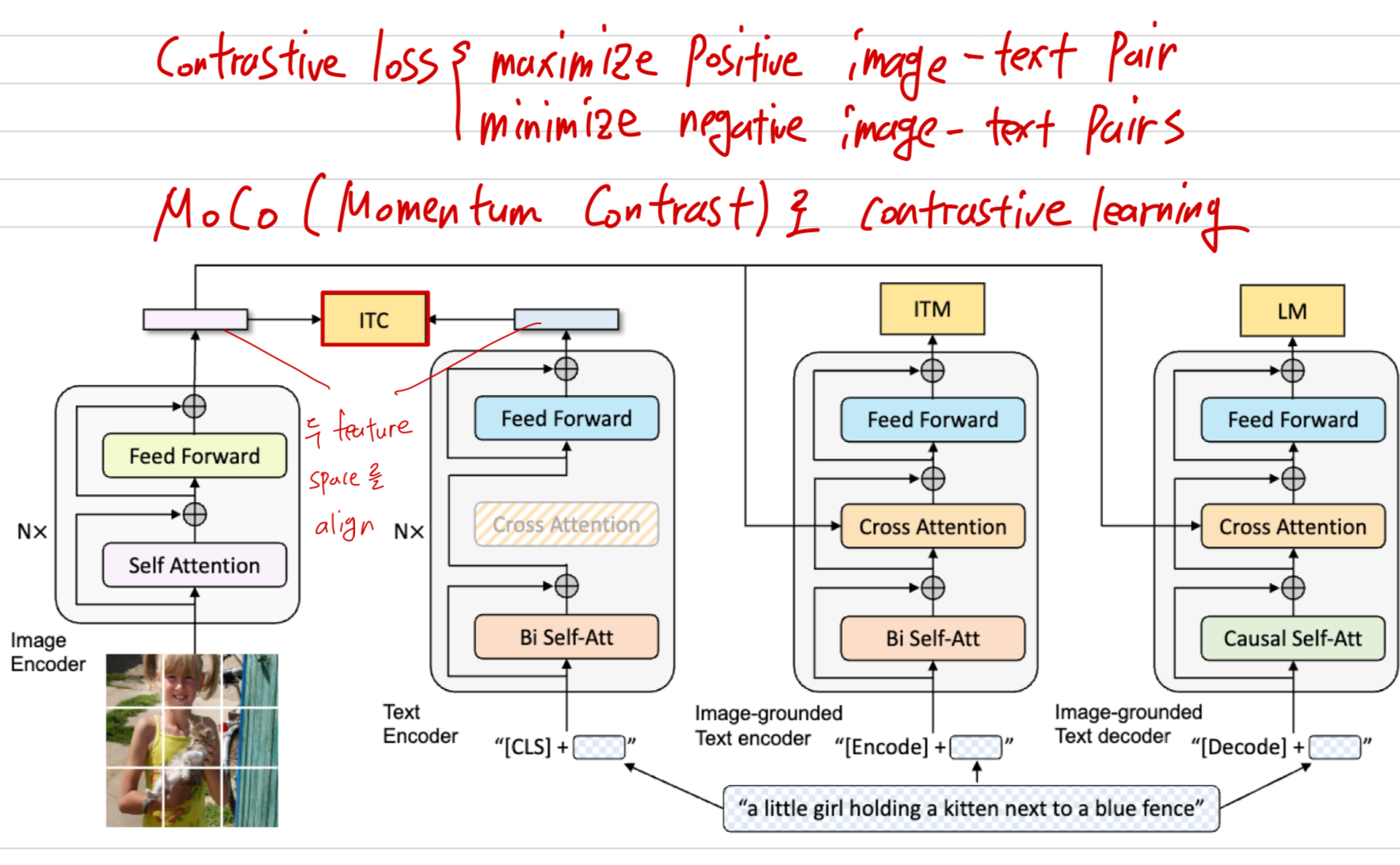
Image-Text Contrastive Loss (ITC)
-
Image-Text Contrastive Loss (ITC)는 unimodal encoder를 activates한다.
ITC Loss의 목표는 positive image-text pairs는 서로 similar representations에서 가깝게,
반대로 negative pairs는 멀어지게 하여
visual transformer와 text transformer의 feature space를 align하는 것이다.
이러한 contrastive learning은 vision and language understanding을 향상시키는 데 매우 효과적인 것으로 알려지고 있다.
우리는 Li et al. (2021a)의 ITC loss를 따른다.
여기서는 momentum encoder를 추가해 feature를 생성하고,
potentional positives일 수 있는 negative pairs를 고려하기 위해 momentum encoder로부터 soft label을 만들어 training targets으로 사용한다.
- momentum encoder란?
GPT 답변:
Contrastive Learning framework 중 하나인 MoCo (Momentum Contrast)에서 핵심적으로 사용되는 기술.
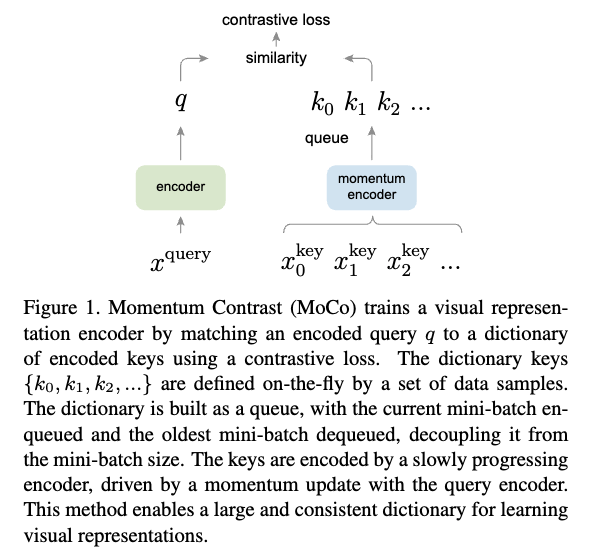
contrastive learning의 성능은 (1) negative pairs의 개수, (2) negative feature의 일관성에 크게 좌우된다.
이 두 문제를 동시에 해결하는 핵심이 바로 momentum encoder이다.- CLIP에서 했던 것처럼 batch 내 negative sample을 사용하는 방식은 batch size가 커질수록 negative sample 수가 으로 늘어나 성능이 좋아질 수 있지만,
batch size는 GPU memory에 의해 제한되기 때문에, batch size가 작아질수록 contrastive learning에 효과가 떨어진다.
이를 해결 하기 위해, MoCo는 Queue(FIFO)라는 큰 저장 공간을 만들어, 과거 batch에서 생성된 key feature를 저장.
현재 batch에서는 Queue의 모든 feature를 negative sample로 활용.
이때, Queue에 넣을 feature를 생성하는 network가 momentum encoder. - MoCo는 negative key features를 생성하는 momentum encoder의 weight를
query encoder의 weight로 직접 update하지 않고, momentum update 방식을 사용함.
- CLIP에서 했던 것처럼 batch 내 negative sample을 사용하는 방식은 batch size가 커질수록 negative sample 수가 으로 늘어나 성능이 좋아질 수 있지만,
- momentum encoder란?
Image-Text Matching Loss (ITM)
- Image-Text Matching Loss (ITM)는 image-grounded text encoder를 activates한다.
이 loss는 vision and language 사이의 fine-grained alignment를 capture하는 image-text multi-modal representation을 학습하는 것이다.
ITM은 binary classification task로 구성되며,
model은 ITM head (a linear layer)를 사용해 주어진 multimodal feature가
positive(matched) image-text pair인지, negative (unmatched) image-text pair인지를 predict한다.
보다 informative negatives를 선택하기 위해, Li et al. (2021a)의 hard negative mining strategy를 사용한다.
이 strategy에서는 한 batch 내에서 contrastive similarity가 높은 negative pair일수록 ITM loss 계산에 선택될 가능성이 커진다.- hard negative mining이란?
GPT답변: contrastive learning이나 image-text matching과 같은 학습 상황에서,
더 헷갈리는 negative sample을 우선적으로 사용해 model을 더 강하게 학습시키는 기법.
즉, contrastive similarity가 높은 negative pair = negative이지만 긴가민가하는 애매한 pair를 선택해 loss를 계산
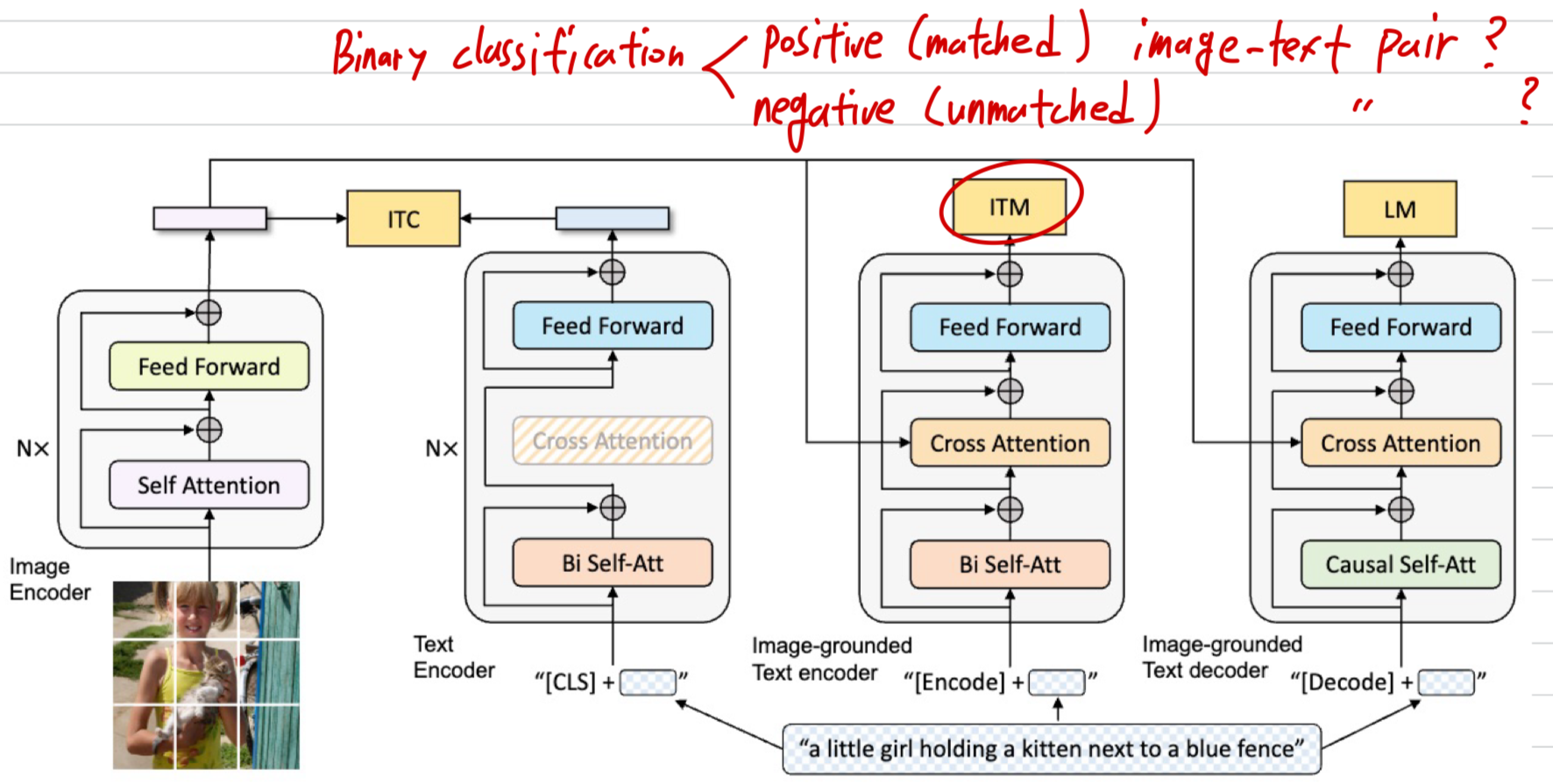
- hard negative mining이란?
Language Modeling Loss (LM)
- Language Modeling Loss (LM) 는 image-grounded text decoder를 activates하며,
image를 입력받아 textual descriptions을 생성하는 것을 목표로 한다.
이 Loss는 cross entropy loss를 optimize하며, model이 autoregressive 방식으로 (앞 단어부터 차례대로)
text의 likelihood를 maximize하도록 학습된다.
또한 우리는 loss 계산 시 label smoothing 0.1을 적용한다.
기존 VLP 연구에서 널리 사용된 MLM(masked language modeling) loss와 비교했을 때,
LM은 model이 visual information을 자연스럽고 일관된 caption으로 변환하는 generalization capability를 갖추도록 해준다.
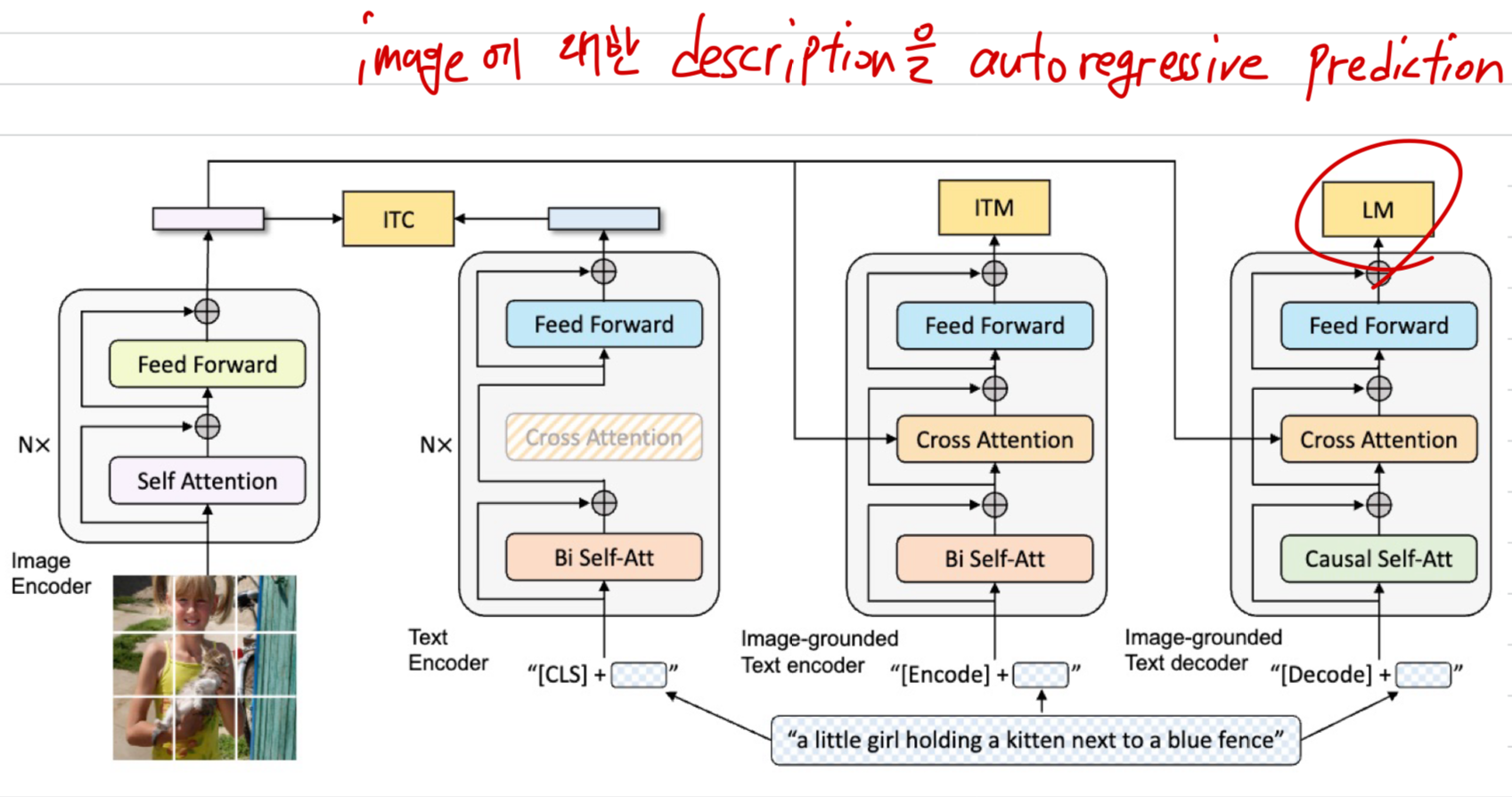
- 효율적인 pre-training과 multi-task learning을 동시에 수행하기 위해,
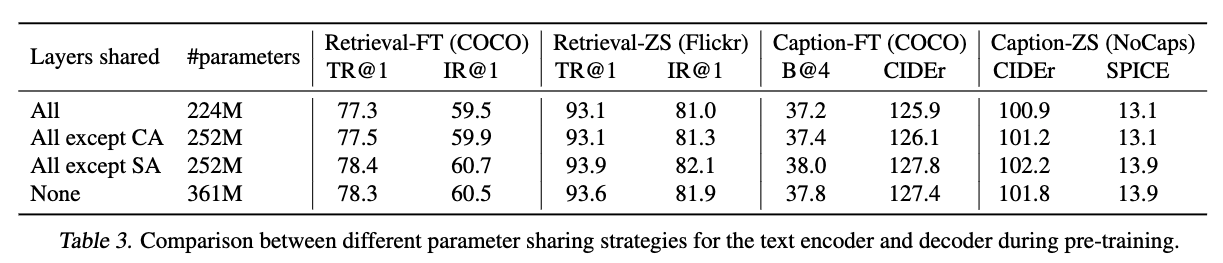
text encoder와 text decoder는 self-attention(SA) 레이어를 제외한 모든 parameter를 공유한다.
SA layer에서 parameter를 제외한 이유는 encoding과 decoding의 핵심 차이는 SA layer에서 발생하기 때문이다.
(encoder는 현재 input token들 간의 관계를 학습하기 위해 bi-directional self-attention을 사용하고,
decoder는 다음 token을 생성해야 하므로 causal(단방향) self-attention을 사용)
반면, embedding layer, cross-attention(CA) layer, FFN layer는 encoding과 decoding 모두에서 동일한 방식으로 작동하므로 공유가 가능하다.
이 구조는 training efficiency를 높이면서 multi-task learning의 이점을 제공한다.
3.3. CapFilt
-
annotation cost가 매우 높기 때문에, COCO와 같은 high-quality human-annotated image-text pairs 만 존재한다.
최근 연구는 web에서 자동적으로 수집된 훨씬 더 많은 image and alt-text pairs 을 활용한다.
그러나 alt-texts는 종종 image의 visual content를 정확히 설명하지 못해, vision-language alignment를 학습하기에는 suboptimal한 noisy signal이 된다. -
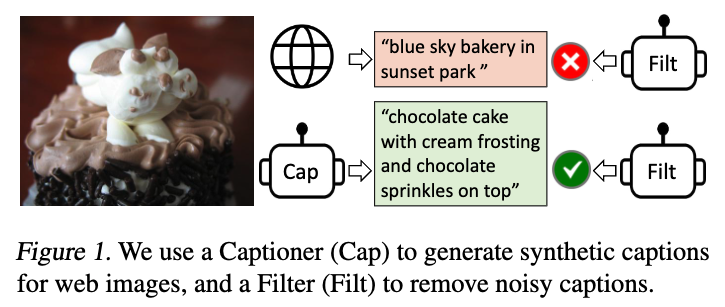
우리는 text corpus의 quality를 향상시키기 위한 새로운 방법인 Captioning and Filtering (CapFilt)을 제안한다.
Figure 3은 CapFilt의 개요를 보여준다.
CapFilt는 두 가지 module을 도입한다: (1) web image를 입력받아 caption을 생성하는 captioner, 그리고 (2) noisy image-text pairs를 제거하기 위한 filter
captioner와 filter는 동일한 pre-trained MED model에서 initialized되며, COCO dataset으로 각각 lightweight finetuning된다.
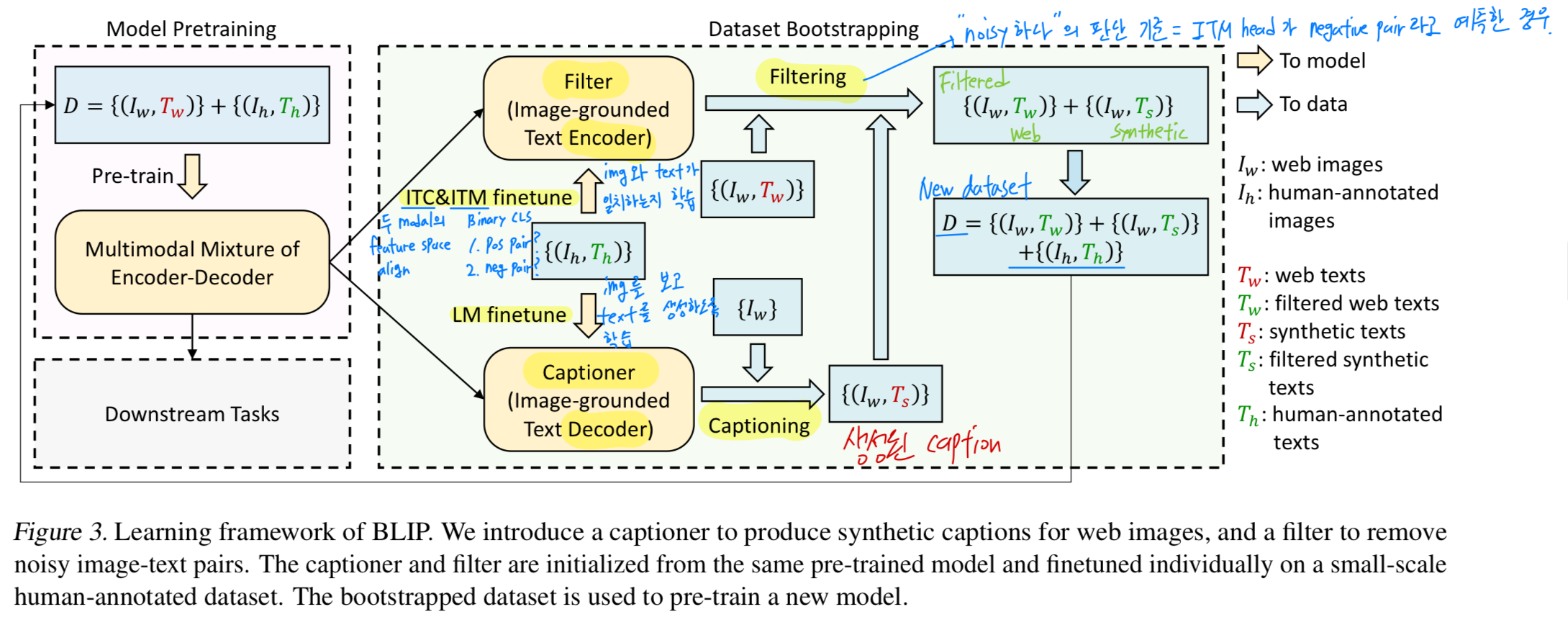
- 구체적으로, captioner는 image-grounded text decoder이다.
image를 입력받아 text를 decode하도록 LM objective로 finetuning된다.
web images 가 주어지면, captioner는 image당 한 synthetic caption 를 생성한다. - 반면, filter는 image-grounded text encoder이다.
text가 image와 일치하는지를 학습하기 위해 ITC and ITM objective로 finetuning된다.
filter는 original web texts 와 synthetic texts 모두에서 noisy text를 제거한다.
여기서 text가 noisy하다고 판단되는 기준은 ITM head가 해당 text가 image와 matching되지 않는다고 예측하는 경우이다. - 마지막으로, 우리는 filtering된 image-text pairs와 human-annotated pairs를 결합하여 새로운 dataset을 구성하고,
이를 사용해 new model을 pre-train하는 데 사용한다.
- 구체적으로, captioner는 image-grounded text decoder이다.
4. Experiments and Discussions
문제 제기, 제안 방법만 간략히 살펴보기 위한 간단한 paper review이기 때문에 아래는 쭉 생략...
4.1. Pre-training Details

4.2. Effect of CapFilt
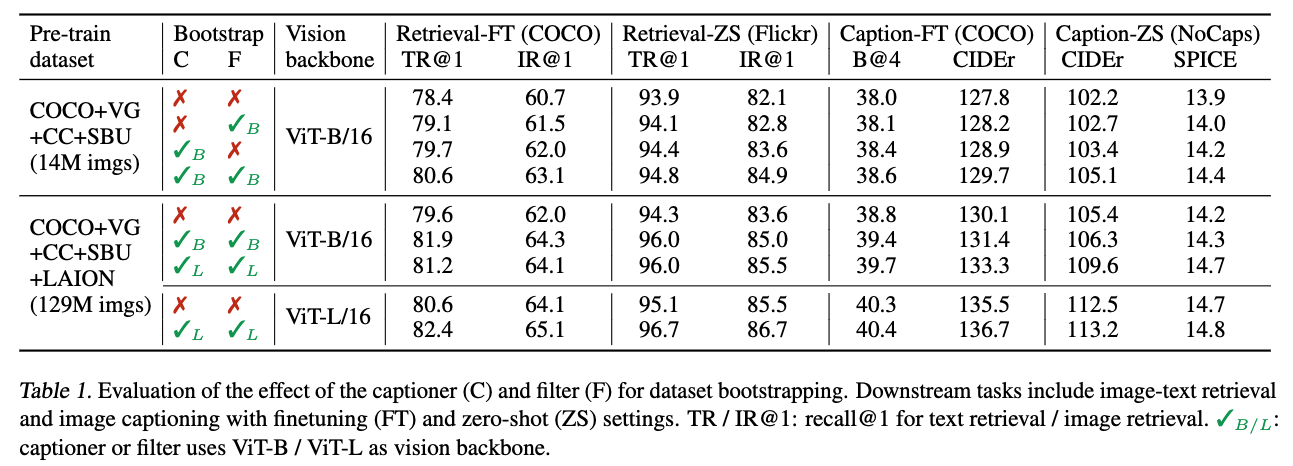

4.3. Diversity is Key for Synthetic Captions

4.4. Parameter Sharing and Decoupling

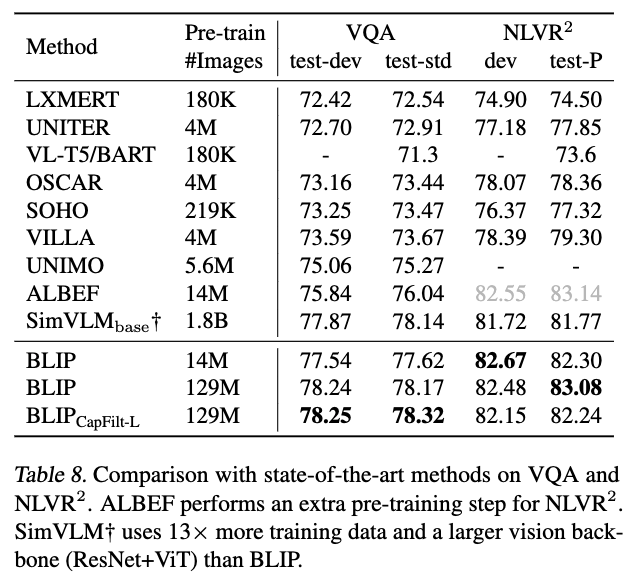
5. Comparison with State-of-the-arts
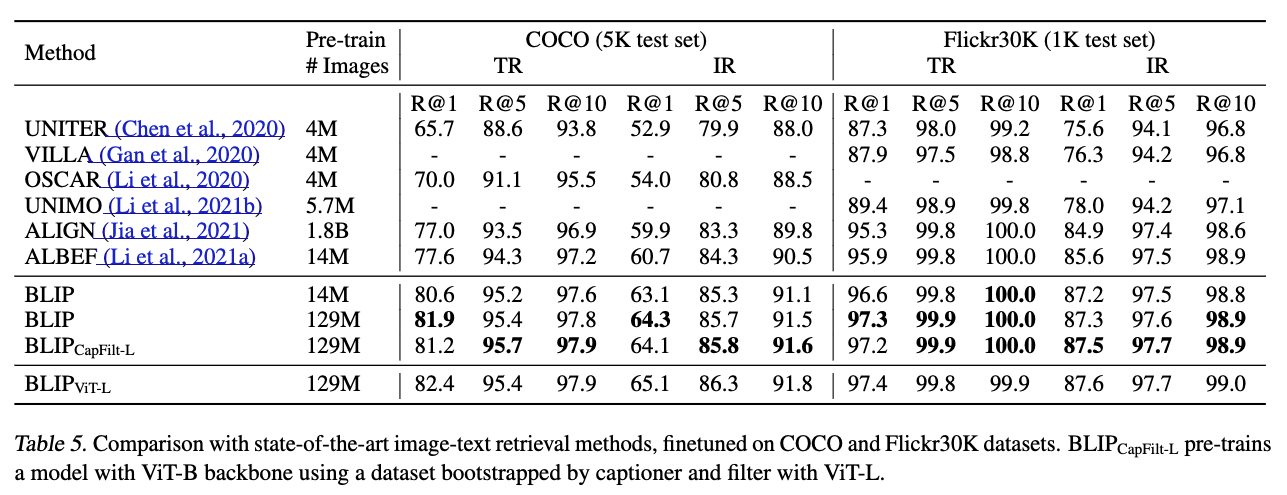
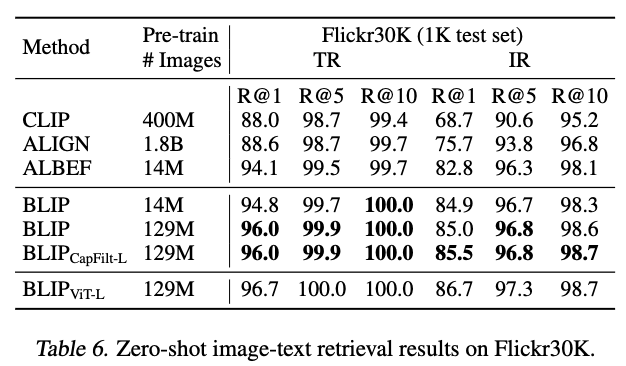
5.1. Image-Text Retrieval
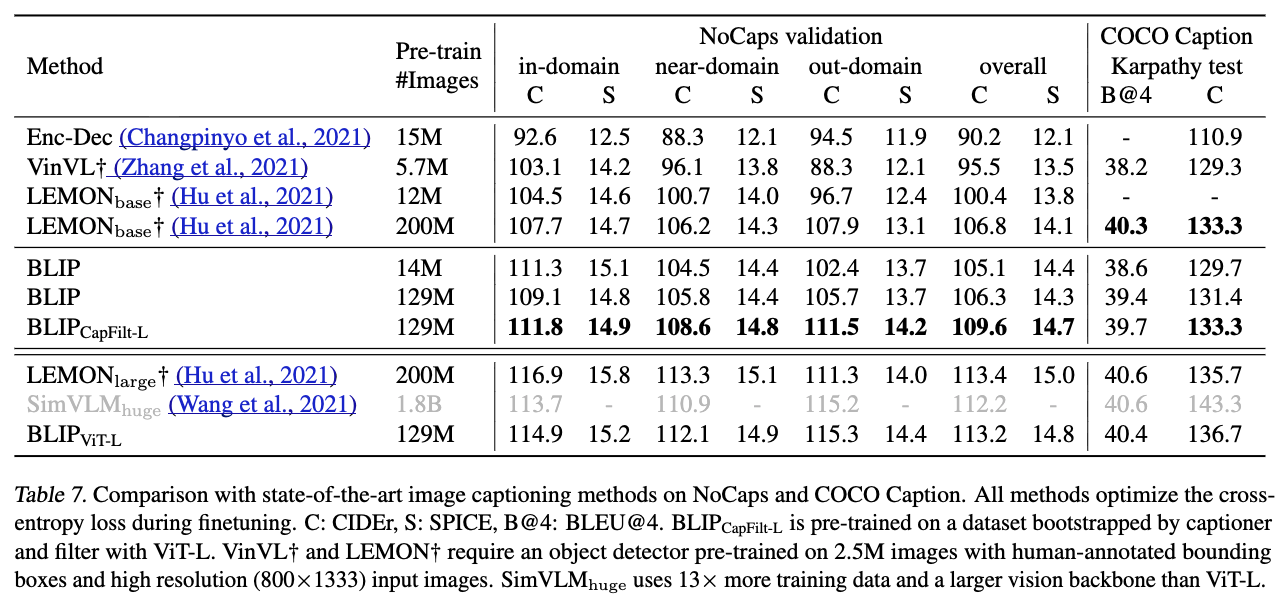
5.2. Image Captioning
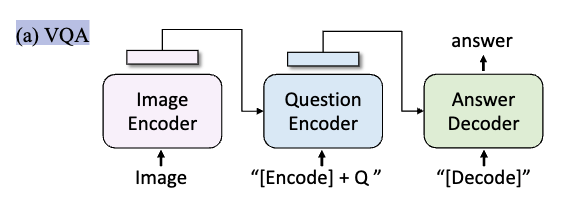
5.3. Visual Question Answering (VQA)
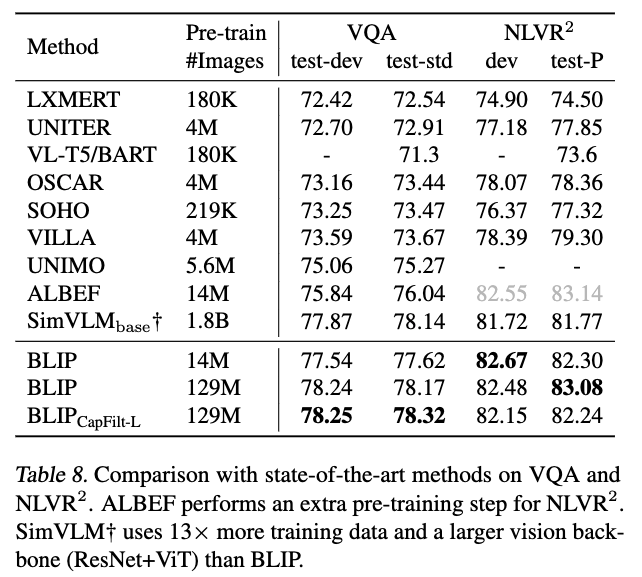
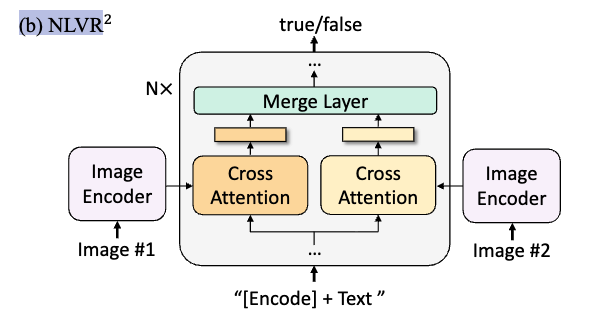
5.4. Natural Language Visual Reasoning (NLVR)
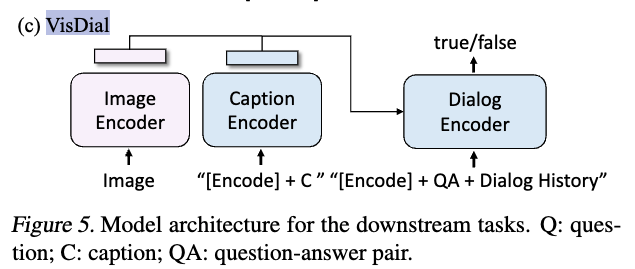
5.5. Visual Dialog (VisDial)
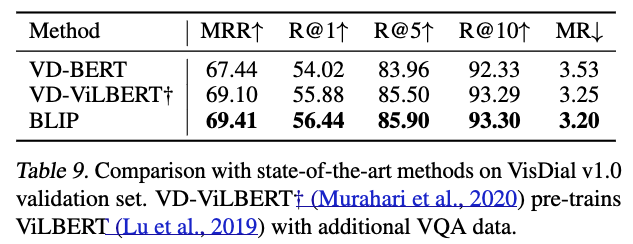
5.6. Zero-shot Transfer to Video-Language Tasks
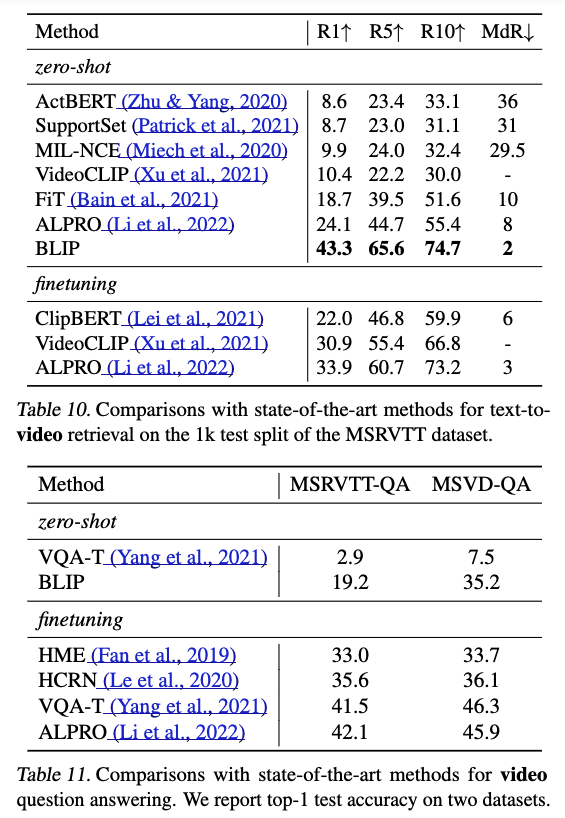
6. Conclusion
-
우리는 understanding-based and generation-based tasks 모두를 포함한 다양한 downstream vision-language tasks에서
SOTA를 달성하는 a new VLP framework, BLIP을 제안한다.
BLIP은 다양한 synthetic captions을 주입하고, noisy captions을 제거하여 large-scale noisy image-text pairs로부터 bootstrapped된 dataset을 활용해, a multimodal mixture of encoder-decoder model을 pre-train한다. -
BLIP의 성능을 더욱 향상시킬 수 있는 몇 가지 잠재적 방향이 존재하지만, 이러한 접근들은 computation cost 증가로 인해 본 논문에서는 다루지 않는다:
- 수차례의 dataset bootstrapping;
- pre-training corpurs를 더욱 확장시키기 위한 multiple synthetic captions
- 서로 다른 captioners와 filters를 여러 개 학습 시켜 CapFilt에서 이들을 ensemble하는 방식
이 논문의 핵심
문제 제기 1:
과거 multi-modal model은 understanding(encoding) 또는 generation(decoding) 중 하나만 가능했는데,
이 논문에서는 understanding(encoding) & generation(decoding)을 동시에 수행할 수 있는 Multi-modal mixture of Encoder-Decoder(MED)를 제안함.(for understanding) Unimodal encoder + ITC(Image-Text Contrastive Loss):
image encoder와 text encoder에서 각각의 feature를 독립적으로 추출
ITC Loss를 통해 두 unimodal encoder에서 뽑은 두 modal의 feature를 align해주는 역할.
즉, CLIP에서 처럼 contrastive learning. (사실 디테일은 MoCo에서처럼 momentum encoder를 통해 loss를 생성)(for understanding) Multi-modal encoder + ITM(Image-Text Matching Loss):
image-grounded text encoder에서 text와 image encoder를 통해 얻은 image feature를 cross-attention하여 image와 text 간의 관계를 모델링.
ITM은 multi-modal encoder의 결과에 대해서 binary classification 학습. (matched pair인가? 아닌가?)(for generation) Multi-modal decoder + LM(Language Modeling Loss):
image-grounded text decoder에서 image encoder를 통해 얻은 image feature를 참고하여 새로운 caption을 generation.
문제 제기 2:
ALIGN에서처럼, web에서 자연적으로 얻은 아주 단순한 preprocessing만 거친 image alt-text pairs dataset을 사용하는 것은
dataset 자체에 noisy text가 많기 때문에 pre-training에 문제가 된다고 지적.
이 논문에서는 더 나은 dataset으로 pre-training하기 위해, caption noise 문제를 해결하기 위한 CapFilt module을 제안함.
CapFilt를 통해 pre-training 과정 중에, dataset을 bootstrapping(내부적으로 caption 생성과 정제)을 해줌.
(1) caption을 생성하는 Captioner (LM을 fine-tuning하여 image에 대한 caption을 생성)과
(2) 생성된 caption을 포함한 기존의 caption의 정제를 위한 Filter (ITC & ITM을 fine-tuning하여 noisy caption을 제거)
을 제안함.