[2022 ICLR] DAB-DETR: DYNAMIC ANCHOR BOXES ARE BETTER QUERIES FOR DETR
[Paper Review] 2D Object Detection
Paper Info.

Abstract
-
이 paper에서 a novel query formulation using dynamic anchor boxes for DETR을 소개하고
a deepr understanding of the role in queries in DETR을 제공한다. -
This new formulation은 decoder에서 queries를 직접적으로 box coordinates로 사용하여, 그들을 layer-by-layer로 dynamically update한다.
box coordinates는 query-to-feature similarity를 향상시키고 DETR의 slow training convergence issue를 제거하기 위해
explicity positional priors로 사용되면 도움이 될 뿐만 아니라,
box width and height information을 사용하여 the positional attention map을 modulate하도록 허용할 수 있다. -
이러한 design은 DETR의 queries가 layer-by-layer in cascade manner로 진행되는 soft ROI pooling으로 구현될 수 있음을 명확히 보여준다.
(기존 query는 였다면, DAB-DETR에서는 로 formulation했다는 의미인가?
여기서, 은 #queries, 는 box coordinates)
1. Introduction
(background)
- DETR (DEtection TRansformer)는 anchors와 같은 the need for hand-designed components를 줄여서 end-to-end detector로 제안되었다.
anchor-based detectors들과 달리, DETR models은 object ddetection을 a set prediction problem으로 취하고,
images로부터 probe and pool features를 하기 위한 100개의 learnable queries를 사용하여 non-maximum suppression의 필요 없이 predictions을 만들어낸다.
(motivation & related works)
- 하지만 이 ineffective design and use of queries로 인해, DETR은 significantly slow training convergence로부터 고통을 겪는다.
이를 해결하기 위해 많은 연구들이 있었지만, 여전히 the role of the learned queries in DETR은 is not fully understood or utilized이다.
기존 연구들은 대부분 DETR의 각 query를 multiple positions이 아닌 oen specific spatial position에 명시적으로 연결하려는 시도를 했지만, 그 기술적 접근법은 완전히 다르다.
예를 들어, Conditional DETR은 query의 content feature를 적응적으로 학습하여 image feature와 더 잘 matching되도록 하였다.
Efficient DETR은 dense prediction module을 도입하여 top-K object queries를 선택하였고,
Anchor DETR은 query를 2D anchor points로 formulates하였다.
이들 모두 각 query를 specific spatial position과 연관시킨다.
유사하게, Deformable DETR은 2D reference point를 직접 query로 사용하고 각 reference points에서 deformable cross-attention을 수행한다.
그러나 위의 모든 연구들은 object의 scales을 고려하지 않고 2D positions만을 anchor points로 활용한다.
(method)
-
이러한 studies에 motivated되어, 본 논문에서는 transformer decoder의 cross-attention module을 면밀히 분석하고,
DETR의 queries를 4D box coordinates 를 가지는 anchor box로 사용하며 이를 layer-by-layer update하는 방법을 제안한다.
This new query formulation은 각 anchor box의 position and size를 고려하여 cross-attention module에 better spatial priors를 제공한다.
이는 implementation을 더 simpler할 뿐만 아니라 DETR에서 queries의 역할을 deepr understanding할 수 있게 해준다. -
The key insight behind this formulation은,
DETR의 각 query는 content part (decoder self-attention output)와 a positional part (learnable queries in DETR)라는 두 parts로 구성된다는 점이다.
cross-attention weights는 a query가 a set of keys which consists of two parts as a content part (encoder image feature) and a positional part (positional embedding) 와의 유사도를 comparing함으로써 계산된다.
따라서 Transformer의 decoder queries는 query-to-feature similarity를 기반으로 feature map으로부터 feature를 pooling하는 과정으로 해석할 수 있다.
이때, content similarity는 semantically related features를 pooling하기 위함이며, positional information은 query 주변 position에서 feature를 모으는 데 positional constraint를 제공한다.
- 이러한 attention computing mechanism은 queries를 anchor boxes로 formulate하도록 motivates를 한다.
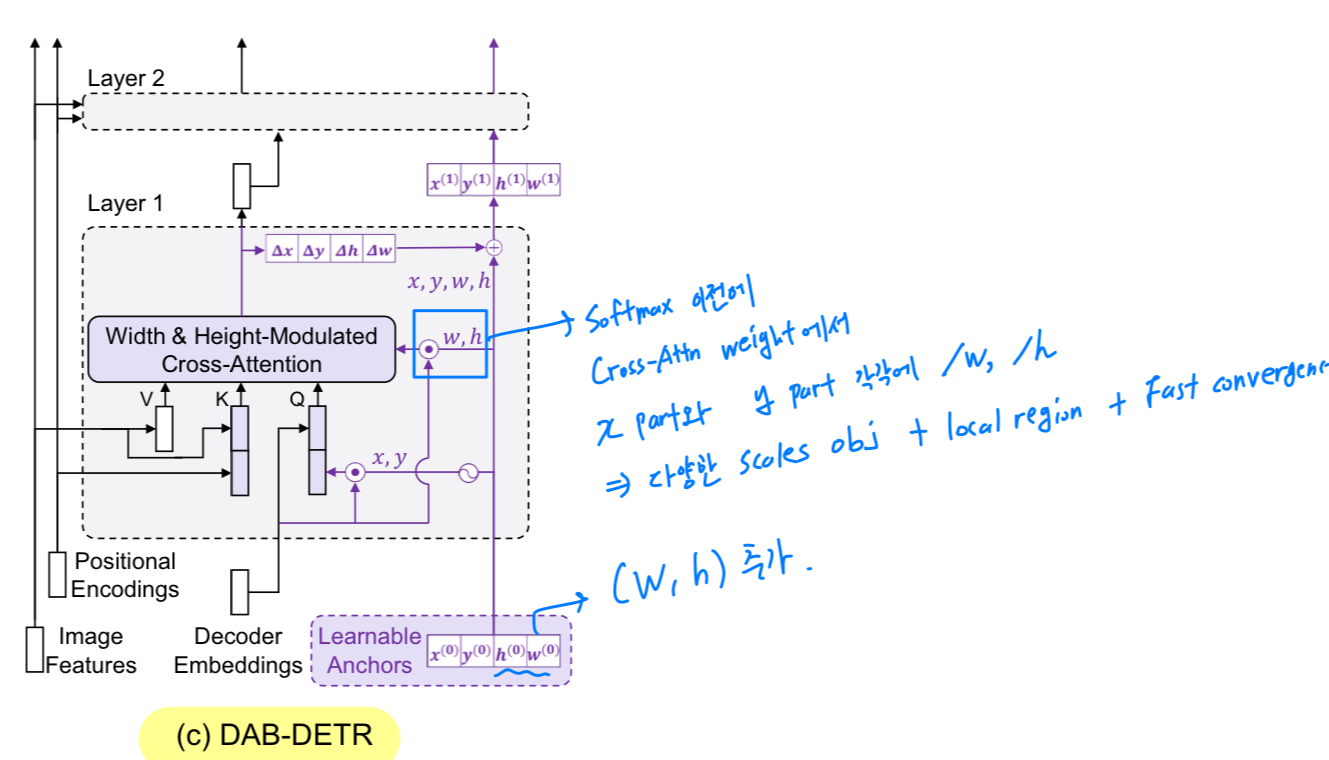
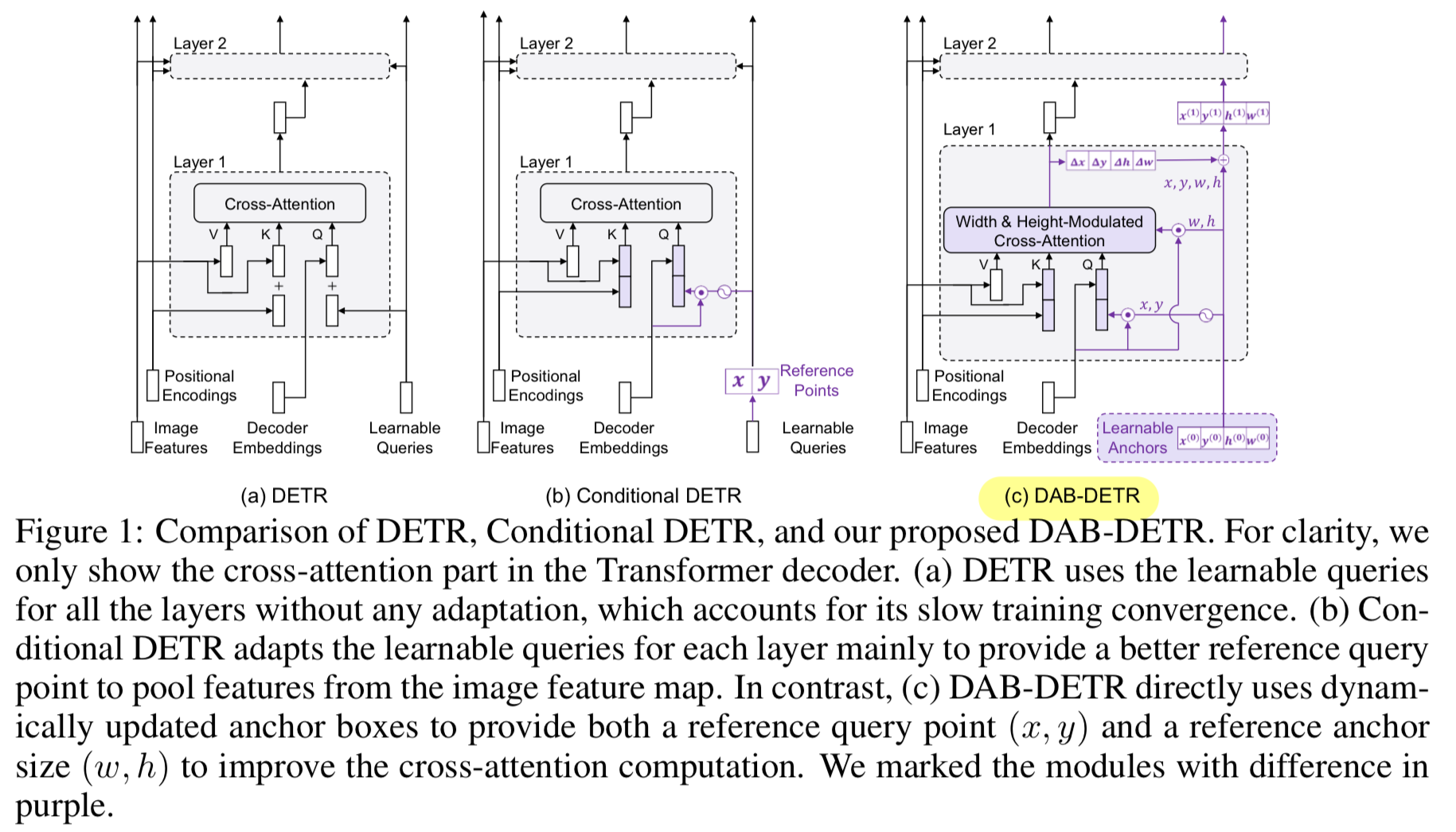 즉, Fig. 1(c)에 보이듯이, anchor boxes의 center position 를 사용해 center 주변의 features를 pooling하고,
즉, Fig. 1(c)에 보이듯이, anchor boxes의 center position 를 사용해 center 주변의 features를 pooling하고,
anchor box size 를 활용해 cross-attention map을 modulate함으로써 anchor box size를 adapting할 수 있다.
또한, queries를 coordinates로 사용하기 때문에, anchor boxes는 dynamically layer-by-layer로 update될 수 있다.
이러한 방식으로 DETR의 queries는 layer-by-layer in a cascade way로 soft ROI pooling 과정으로 구현될 수 있다.
(아래는 로 object size에 맞게 anchor box를 조절할 수 있는 방법에 대한 상세 설명인듯)
- 본 논문에서는 cross-attention을 modulate하기 위해 anchor box size를 활용함으로써 feature pooling에 a better positional prior를 제공한다.
cross-attention은 전체 feature map으로부터 feature를 pool할 수 있기 때문에, module이 target object에 해당하는 local region에 집중할 수 있도록 a proper positional prior를 제공하는 것이 중요하다.
이는 또한 DETR의 training convergence를 가속화하는 데 도움이 된다.
대부분의 prior works는 각 query를 specific location과 연관시킴으로써 DETR을 개선했으나, 대부분 fixed size의 an isotropic Gaussian positional prior를 가정하였고, 이는 다양한 scales의 objects를 처리하기에 부적절하다.
반면, 각 query anchor box에 size information 를 포함시킴으로써, Gaussian positional prior를 oval shape (타원형)으로 조절할 수 있다.
구체적으로, softmax 이전에 cross-attention weight에서 part와 part를 각각 width와 height로 나누어, Gaussian prior가 다양한 scales의 objects와 더 잘 일치하도록 한다.
나아가, positional prior을 더욱 개선하기 위해, 기존 연구에서 간과된 temperature paramter를 도입하여 positional attention의 flatness를 조절한다
2. Related Work
-
DETR은 a set of learnable vectors as queries로 사용하는 a fully anchor-free detector이다.
Many follow-up works들은 다양한 관점으로 DETR의 the slow convergence를 해결하기 위해 시도했다.
~
"Despite their improved performance, they did
not give a proper explanation of the slow training and the roles of queries in DETR." -
우리 연구와 가장 유사한, DETR 향상에 대한 방향은 DETR의 the role of queries에 대한 a deeper understanding에 대한 것이다.
대부분의 related works는 query를 more explictly related to a specific spatial position rather than multiple position modes in the vanilla DETR을 시도했다.
예를 들어,- Deformable DETR은 queries를 directly 2D reference points로 취하고,
deformable cross-attention operation을 수행하기 위한 each reference point에 대해 deformable sampling points를 예측한다. - Conditional DETR은 attention formulation을 decouple하고 reference coordinates에 기반한 positional queries를 생성한다.
- Efficient DETR은 object queries로 사용할 top-K positions을 선택하기 위한 dense prediction module을 도입한다.
- Deformable DETR은 queries를 directly 2D reference points로 취하고,
