[2022 TMLR] (simple review) CoCa: Contrastive Captioners are Image-Text Foundation Models
[Paper Review] VLM to LMM
Paper Info.
https://openreview.net/forum?id=Ee277P3AYC

Abstract
(제안: encoding=understanding과 decoding=generating을 동시에 수행할 수 있게 contrasitve loss와 captioning loss로 jointly pretrain)
- large-scale pretrained foundation model을 탐구하는 것은, 이러한 model들이 다양한 downstream tasks로 빠르게 transferred될 수 있기 때문에 CV에서 큰 관심을 받고 있다.
본 논문에서는 Contrastive Captioner (CoCa)를 제안하는데, 이는 contrastive loss and captioning loss을 함께 사용하여
image-text encoder-decoder foundation model을 jointly pretrain하는 minimalist design이다.
이를 통해 CLIP과 같은 contrastive approaches와 SimBLM과 같은 generative methods를 하나의 framework로 포괄한다.
(방법: decoder layer를 반으로 나눠서,
초기 layer는 unimodal text representation 학습, 후기 layer는 multimodal image-text representation 학습)
-
일반적인 encoder-decoder transformers에서는 decoder의 모든 layer가 encoder outputs에 대해 cross-attention을 수행하지만,
CoCa는 decoder layer의 첫 절반의 layer에서는 cross-attention을 생략하여 unimodal text representations을 encoding하고,
이후 나머지 decoder layer에서 image encoder에 대해 cross-attention을 수행함으로써
multimodal image-text representations을 형성한다. -
본 model은
unimodal image and text embeddings 간의 contrastive loss와,
multimodal decoder outputs에 대해 text token을 autoregressively하게 predict하는 captioning loss를 함께 적용한다.
두 training objectives는 same computational graph를 공유하기 때문에, minimal overhead로 효율적으로 계산된다.
- CoCa는 web-scale의 alt-text data와 annotated image를 모두 사용하여 end-to-end 방식으로, 그리고 from scratch로 pre-train되며,
모든 Label을 단순히 text로 사용함으로써 natural language supervision을 representation learning에 통합한다.
(실험)
- CoCa는 zero-shot transfer 또는 minimal task-specific adaptation만으로도 광범위한 downstream tasks에서 SOTA를 달성한다.
특히 ImageNet classification task에서 CoCa는 zero-shot top-1 accuracy에서 86.3%,
frozen encoder and learned classification head에서 90.6%,
fintuned encoder에서 91.0%의 정확도를 달성하였다.
1. Introduction
(B.g: Language에서 foundation model)
- DL에서 최근 BERT, T5, GPT-3와 같은 foundation language models이 부상하고 있다.
이러한 model들은 web-scale data로 pretrained되며 zer-shot, few-shot or transfer learning을 통해 generic multi-tasking capabilities를 보여준다.
specialized individual models과 비교하여, pretraining models은 training costs를 분산할 수 있으며, human-level intelligence를 향해 model scale의 한계를 확장할 수 있는 기회를 제공한다.
(B.G.: Vision and Vision-Language에서 foundation model)
- vision and visoin-language problems에서도 여러 foundation model candidates가 탐구되어 왔다
-
Pioneering works(Girshick et al., 2014; Long et al., 2015; Simonyan & Zisserman, 2014)은
image classification에서 cross-entropy loss로 pretraind된 single-encoder models의 효과를 보여줬다.
하지만 이러한 single-encoder model들은 annotations을 label vectors 형태로 강하게 의존하며,
free-form human antural language에 대한 지식을 내재하지 못하므로,
vision and language modalities를 동시에 다루는 downstream tasks에는 적용이 제한된다. -
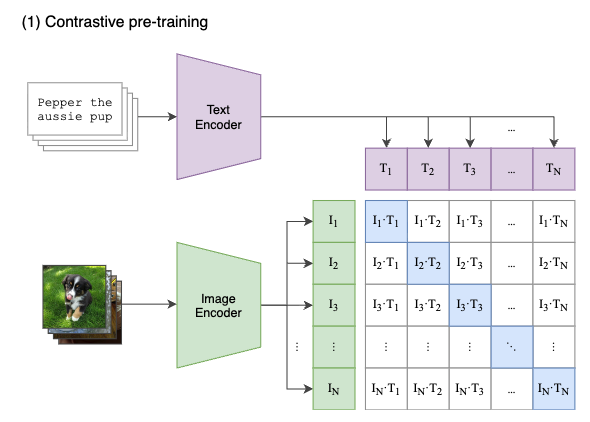
최근에는, web-scale noisy image-text pairs를 이용하여,
두 개의 parallel encoders를 contrasitve loss로 pretraining하는 image-text foundation model의 가능성이 제시되었다.
이러한 dual-encoder model은 vision-only tasks를 위한 visual embedding뿐만 아니라, text embedding도 동일한 latent space로 encoding할 수 있어,
zero-shot image classification이나 image-text retrieval과 같은 새로운 crossmodal alignment capabilities를 가능하게 한다.
그러나 이러한 model들은 fused image and text representations을 학습하기 위한 joint vision-language understanding이 없기 때문에,
VQA(Visual Question Answering)와 같은 복잡한 vision-language understanding tasks에는 직접적으로 적용하기 어렵다.그러나 이러한 모델들은 이미지와 텍스트의 융합된 표현을 학습하기 위한 공동(joint) 구성 요소가 없기 때문에, 시각적 질의응답(VQA)과 같은 복합적인 비전-언어 이해 작업에는 직접적으로 적용하기 어렵다.
-
또 다른 연구 흐름(Vinyals et al., 2015; Wang et al., 2021b; 2022)은 encoder-decoder model을 활용한 generative pretraining을 통해
generic vision and multimodal representation을 학습하는 방법을 탐구했다.
pretraining 과정에서, model은 encoder side에 image를 입력 받고, decoder 출력에 대해 language modeling loss를 적용한다.
downstream task에서는 decoder 출력이 multimodal understanding tasks를 joint representations으로 사용될 수 있다.
이러한 pretrained encoder-decoder model은 우수한 vision-language results를 달성하였으나,
image embedding과 aligned된 text-only representation을 생성하지 못하므로,
crossmodal alignment tasks에서는 효율성과 활용성이 상대적으로 낮다.
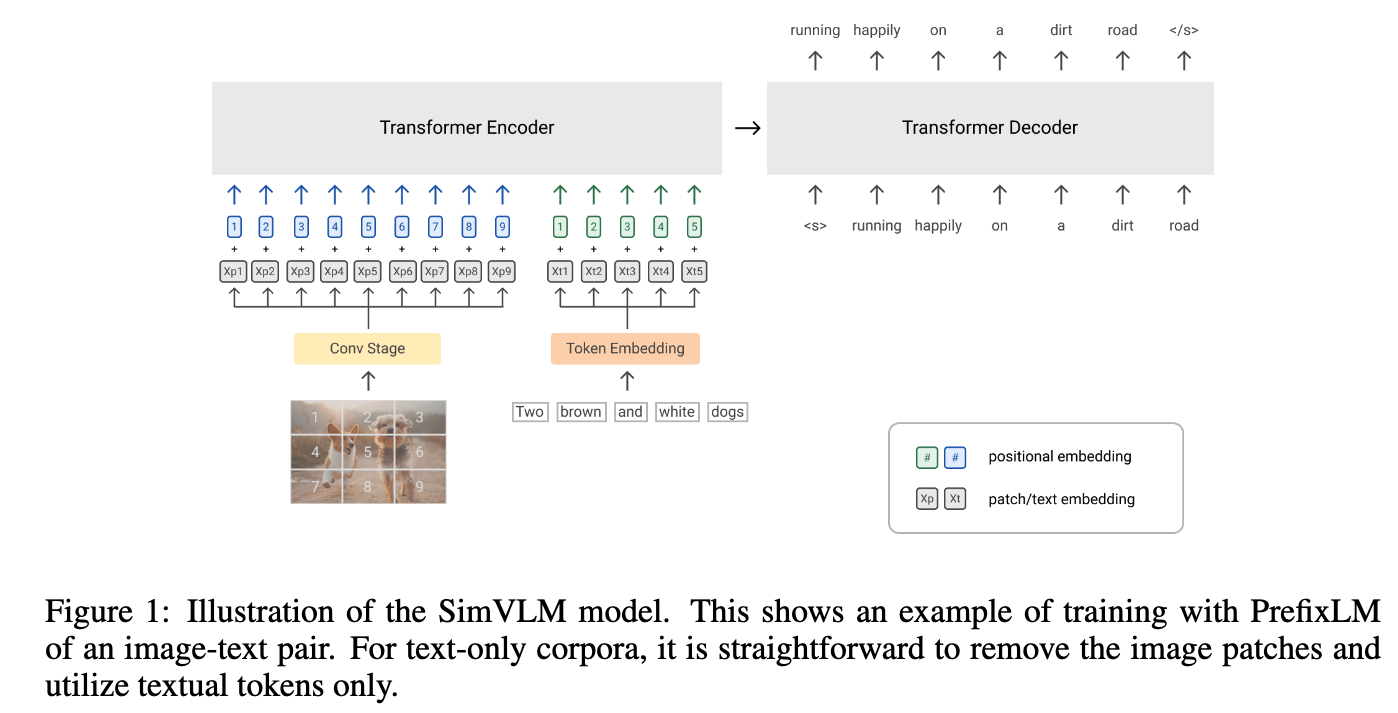
(내가 이해한 내용: 3. 또 다른 연구 흐름에 대한 설명은 SimVLM(ICLR2022에 나온)을 설명하는 것 같다.
SimVLM은 image encoder- text decoder model로, image를 입력받아 text를 생성하는 방식으로 학습하는데,
image vector와 text vector가 독립적으로 전재하면서 서로 matching되는 구조가 없다.
즉, image encoder는 있지만 text encoder는 없다.
image와 text가 decoder 안에서 뒤섞여야만 처리가 되기 때문에, retrieval같은 task에서는 계산이 비효율적이다.
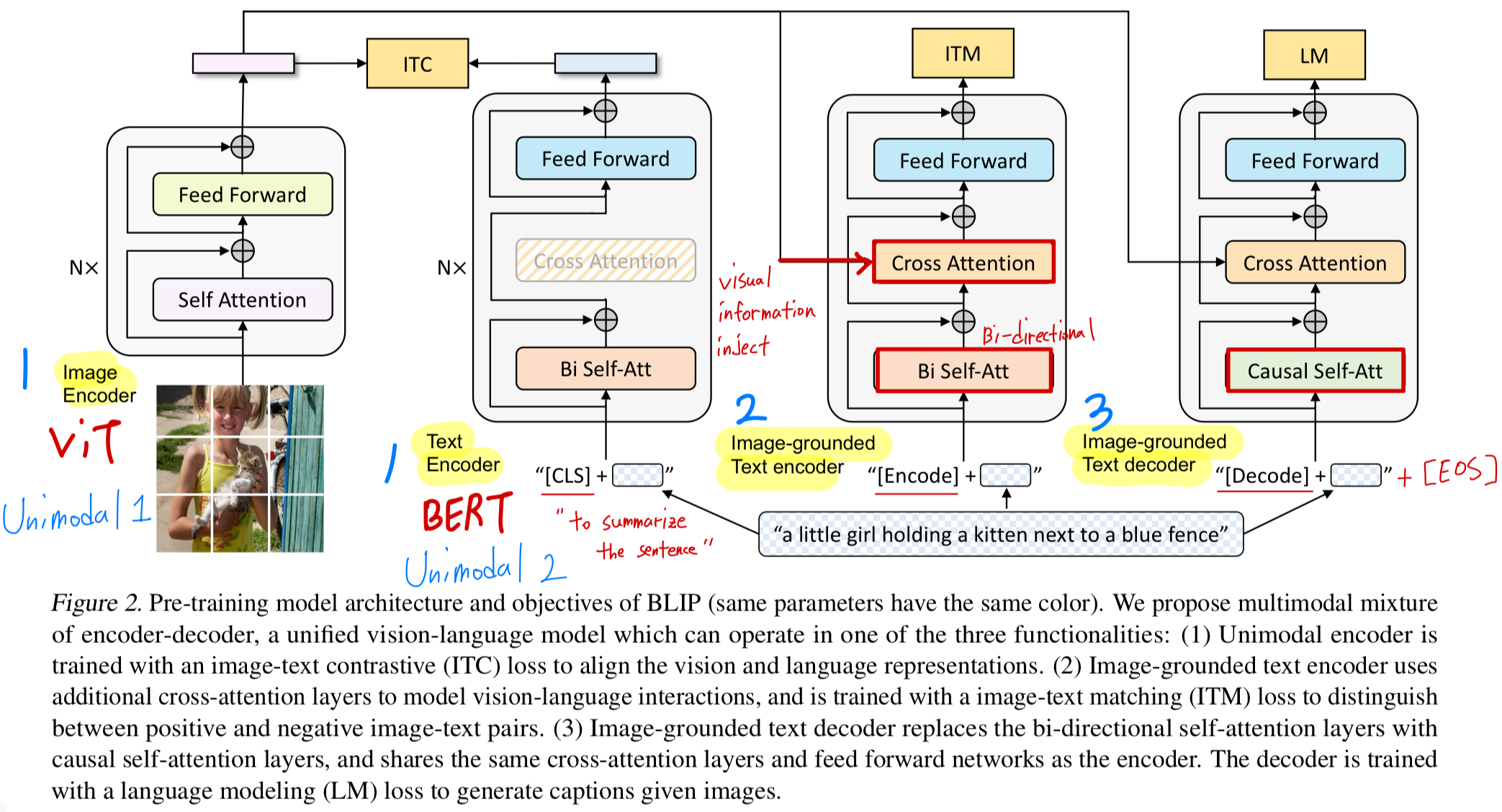
BLIP은 CoCa와 같이, 앞선 한계에 대한 문제의식을 가짐.
generation model의 alignment 부재 문제를 해결하기 위해, retrieval 같은 task를 위한 multimodal alignment(image encoder와 text encoder 각각의 결과를 contrastive loss 학습)와 generating용 multimodal decoder로 작동하게 만듦.)
-
내가 이해한 CoCa의 문제 제기:
CLIP에서는 image-encoder, text-encoder가 각각 존재하였지만 generating을 위한 decoder는 없었음.
즉, 두 multimodal을 align해서 understanding(retrieval)하는 것은 잘하지만 VQA와 같은 generating tasks에 적용하기 제한적인 문제가 있음.
반대로, SimVLM에서는 generating tasks에 좋은 구조이지만 understanding(retrieval)을 하기에 비효율적임.
왜 비효율적이냐면, retrieval을 하려면 모든 pair를 model에 forward시켜야 함. (?)
(SimVLM을 읽어보지 않아서 잘 이해하지 못했음...)
그래서 CoCa는 understanding(retrieval과 같은)과 generating(VQA와 같은) 동시에 할 수 있지만서도 효율적인 encoder-decoder를 제안
BLIP도 CoCa와 유사한 문제를 해결하기 위해, 즉 understanding & generating을 하기 위해 multimodal mixture encoder-decoder (MED)를 제안했음.
(아직 CoCa를 다 읽어보진 않았지만, BLIP보다 더 효율적인 설계인 것 같음...
하나의 decoder를 반으로 나눠서 text encoding과 decoding까지 할 수 있도록.)
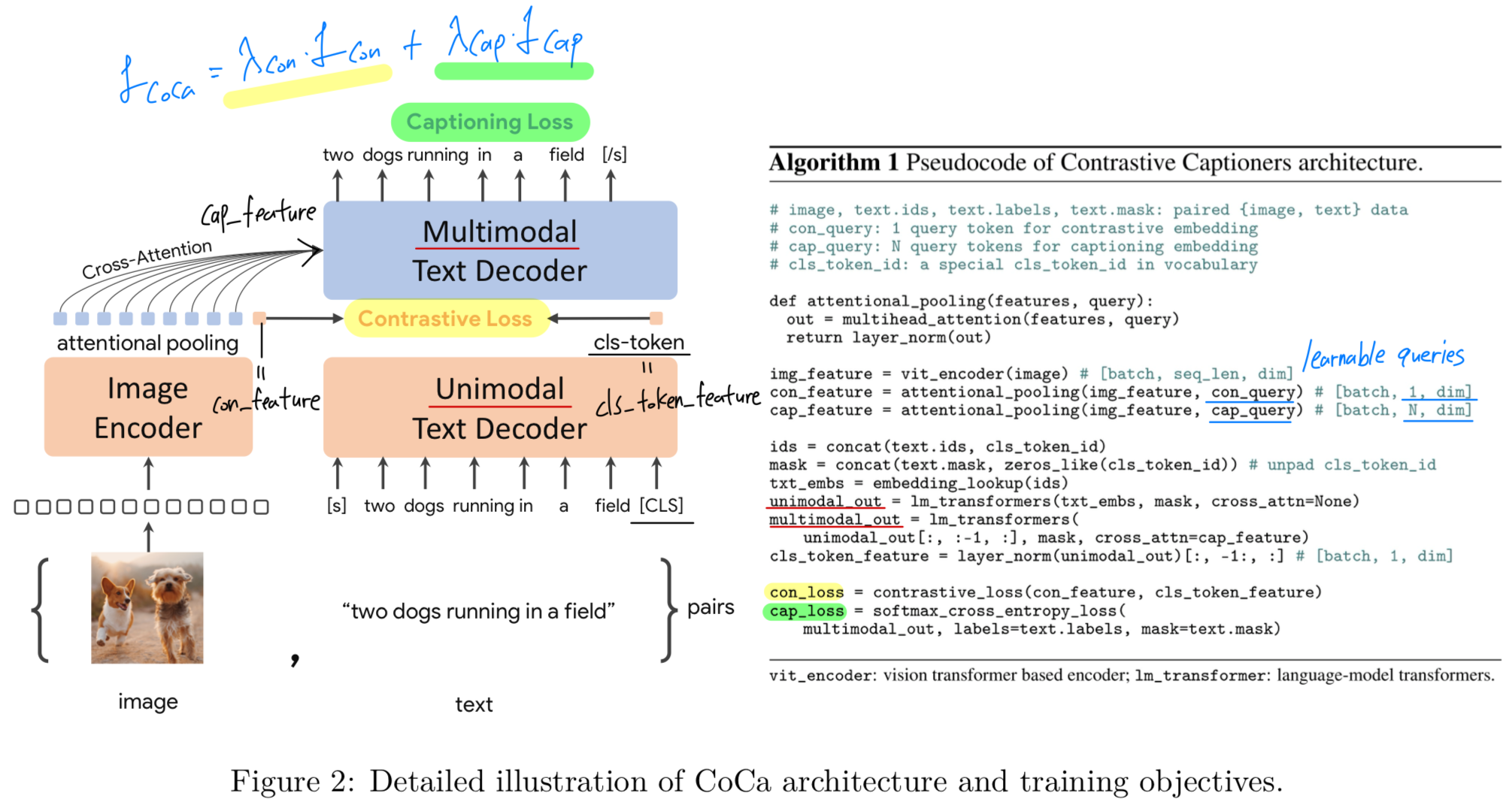
-
이 연구에서, 우리는 (1) single-encoder, (2) dual-encoder and (3) encoder-decoder paradigms을 통합하여,
이 세 가지 approaches의 능력을 모두 포괄하는 one image-text foundation model을 train한다.
이를 위해 Contrastive Captioners (CoCa)라는 simple model family를 제안하며,
이는 contrastive loss와 captioning(generative) loss를 함께 사용하여 학습되는 a modified encoder-decoder architecture를 갖는다. -
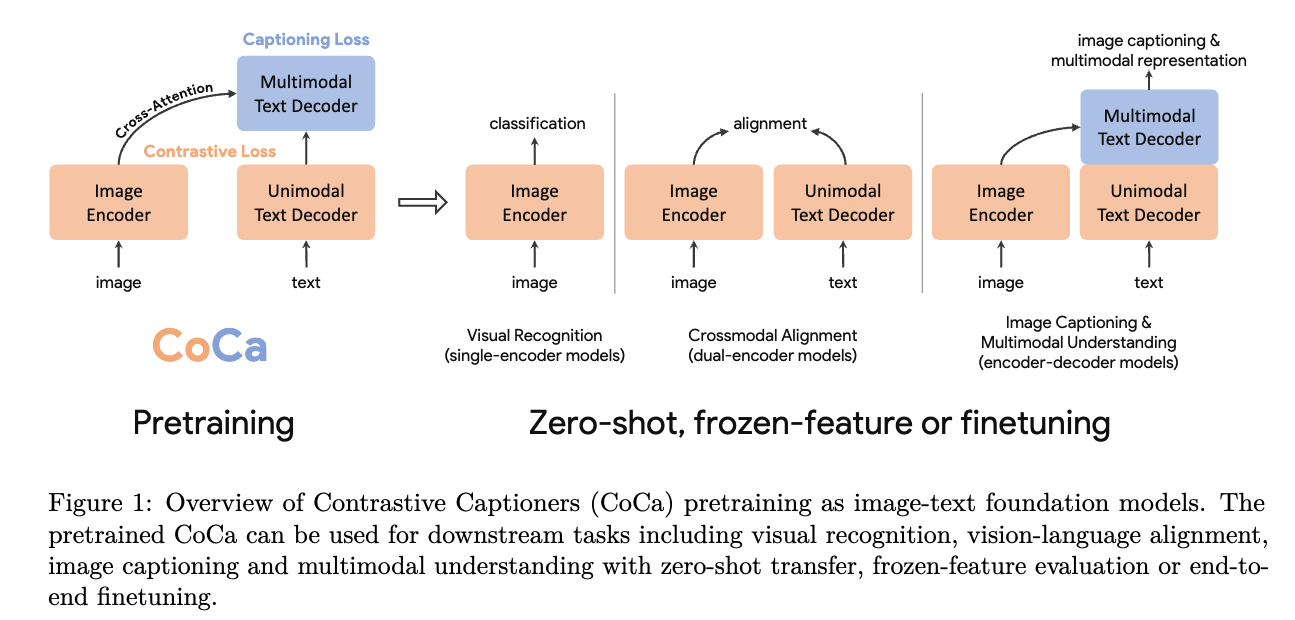
Figure 1에 나타난 바와 같이, 우리는 decoder transformer를 unimodal decoder와 multimodal decoder의 두 부분으로 분리한다.
unimodal decoder layer에서는 cross-attention을 제거하여 text-only representations을 encoding하고,
이후 multimodal decoder layer에서는 image encoder outputs에 대해 cross-attention을 수행하도록 layer를 cascade(연쇄적으로) 구성하여
multimodal image-text representations을 학습할 수 있도록 한다.
더 나아가, CoCa는 both image annotation data와 noisy image-text data로 train되며, 이때 모든 label을 단순히 text로 취급한다.
image annotation text에 대해 적용되는 generative loss는 single-encoder cross-entropy loss approach와 유사한 a fine-grained training signal을 제공하며,
이를 통해 세 가지 pretraining paradigms를 a single unified method로 포괄한다.
2. Related Work
Vision Pretraining
- (skip...) vision modality만을 대상으로 학습하므로, image와 text inputs에 대한 joint reasoning이 요구되는 task에는 적용될 수 없다.
Vision-Language Pretraining
-
최근 수년간 vision-language pretraining(VLP)는 vision과 language를 하나의 fusion model로 jointly encoding하는 것을 목표로 빠른 발전을 이루어왔다.
초기 연구들은 Faster R-CNN과 같은 pretrained object detection modules을 활용하여 visual representations을 extract하는 방식에 의존했다. -
이후 ViLT(Kim et al., 2021)와 VLMo(Wang et al., 2021a)와 같은 연구들은 vision과 language transformers를 통합하고,
multimodal transformer를 from scratch로 train시키는 방향으로 발전하였다. -
더 최근에는 pretrained LLMs을 re-using하여 vision-language tasks에서 zero-shot/few-shot learning을 수행하는 연구들 또한 제안되었다.
-
기존 방법들과 비교하여, 본 논문은 multimodal understanding and generation을 scratch부터 학습하는 데 집중한다.
Image-Text Foundation Models
-
최근 연구들은 vision and VLP를 동시에 포괄할 수 있는 image-text foundation models을 제안해왔다.
CLIP과 ALIGN은 noisy image-text pairs에 대해 contrastive objectives로 pretrained된 dual-encoder model이
crossmodal alignment tasks 및 zero-shot image classification에서 strong and text representations을 학습할 수 있음을 보였다.
Florence는 unified contrastive objective를 도입하여 이 접근법을 확장하였으며,
다양한 vision and image-text benchmarks에 적응 가능한 foundation models을 학습한다. -
zero-shot image classification accuracy를 더욱 향상시키기 위해,
- LiT와 BASIC은 large-scale image annotation dataset에서 cross-entropy로 먼저 pretrain한 뒤,
noisy alt-text image dataset에 대해 contrastive loss로 finetuning하는 방식을 제안했다. - 또 다른 연구 흐름은 generative losses를 활용해 encoder-decoder models을 제안했으며,
vision-language benchmark에서 우수한 성능을 보이는 동시에 visual encoder가 image classification에서도 경쟁력 있는 성능을 유지함을 보여주었다.
- LiT와 BASIC은 large-scale image annotation dataset에서 cross-entropy로 먼저 pretrain한 뒤,
-
본 연구에서는 이러한 접근법들을 통합하기 위해, a single pretraining stage에서 image-text foundation model을 scratch부터 train하는 데 초점을 맞춘다.
최근의 일부 연구 역시 image-text image-text unification을 탐구하였으나, 우수한 성능을 달성하기 위해 unimodal 및 multimodal module에 대해 multiple pretraining stages가 필요했다.
예를 들어, ALBEF(Li et al., 2021)는 dual-encoder design에서 contrastive loss와 masked language modeling(MLM)을 결합한다. -
반면, 우리의 방법은 학습이 simpler and more efficient하면서도 더 다양한 model capabilities를 제공한다:
- CoCa는 image-text pairs에 대해 one forward and backward propagation만을 수행하는 반면,
ALBEF는 corrupted inputs and another without corruption에 대해 two forwarnd and backward propagation을 요구한다. - Coca는 two objectives만을 사용하여 scratch부터 train되는 반면,
ALBEF는 pretrained visual and textual encoders로 초기화되며 momentum modules 등 additional training signals을 필요로 한다. - generative loss를 사용하는 decoder architecture는 natural language generation에 더 적합하므로, image captioning을 직접적으로 가능하게 한다.
- CoCa는 image-text pairs에 대해 one forward and backward propagation만을 수행하는 반면,
3. Approach
- natural language supervision을 서로 다른 방식으로 활용하는 three foundation models을 먼저 살펴본다.
구체적으로, single-encoder classification pretraining, dual-encoder contrastive learning, and encoder-decoder image captioniing.
이후, 단순한 architecture 하에서 contrastive learning과 image-to-caption generation을 동시에 공유하는 Contrastive Captioner(CoCa)를 소개한다.
또한 CoCa model이 zero-shot transfer 또는 minimal task adaptation으로 빠르게 transfer될 수 있음을 논의한다.
3.1 Natural Language Supervision
Single-Encoder Classification
- classic single-encoder approach는 large crow-sourced image annotation dataset(e.g., ImageNet, Instagram, JFT)을 이용한 image classification을 통해 visual encoder를 pretrain한다.
이때 the vocabulary of annotation texts는 보통 고정되어 있다.
image annotations은 discrete class vectors로 mapping되며, 다음과 같은 cross-entropy loss를 통해 학습된다:
 여기서 는 a one-hot, multi-hot or smoothed label distribution from GT label 를 의미한다.
여기서 는 a one-hot, multi-hot or smoothed label distribution from GT label 를 의미한다.
이렇게 학습된 image encoder는 이후 downstream tasks를 위한 generic visual representation extractor로 사용된다.
Dual-Encoder Contrastive Learning
- human annotated labels와 data cleaning이 필요한 single-encoder classification의 pretraining과 달리,
dual-encoder approach는 web-scale text descriptions을 활용하며,
free-form texts를 encoding하기 위한 learnable text tower(?)를 도입한다.
두 encoder는 batch 내의 다른 sample들과 paired text를 contrasting함으로써 jointly optimied된다:
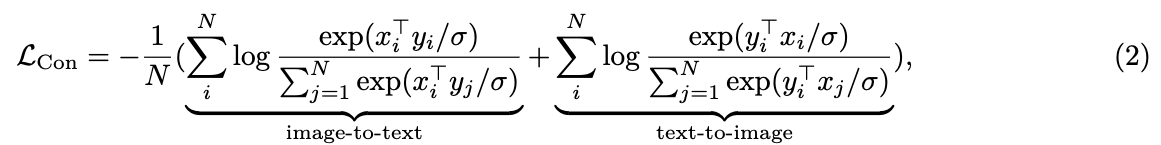 여기서 와 는 각각 -th pair에서 normalized embeddings of the images이고
여기서 와 는 각각 -th pair에서 normalized embeddings of the images이고
-th pair에서 normalized embeddings of the text이다.
은 batch size이며, 는 logit을 scaling하기 위한 temperature이다.
image encoder에 추가로,
dual-encoder approach는 image encoder뿐만 아니라 an aligned text encoder도 함께 학습함으로써,
image-text retrieval and zero-shot image classification과 같은 crossmodal alignment applications을 가능하게 한다.
Encoder-Decoder Captioning
- dual-encoder 방식이 text 전체를 하나의 표현으로 encoding하는 것과 달리,
generative approach(a.k.a. captioner)는 보다 detailed granularity를 목표로 하며,
tokenized texts of 를 autoregressively 정확히 predict하도록 model을 학습시킨다.
standard encoder-decoder architecture를 따라, image encoder는 latent encoded features (ViT 또는 ConvNets)을 생성하고,
text decoder는 the forward autoregressive factorization에 따라
the conditional likelihood of the paird text 를 maximize하기 위해 학습된다.

encoder-decoder model은 teacher-forcing을 통해 parallelize computation과 learning efficiency를 maximize한다.
기존 방법들과 달리, captioner approach는 vision-language understanding에 활용 가능한 joint image-text representations을 제공함과 동시에,
natural language generation을 통한 image captioning applications을 직접적으로 수행할 수 있다.
3.2 Contrastive Captioners Pretraining
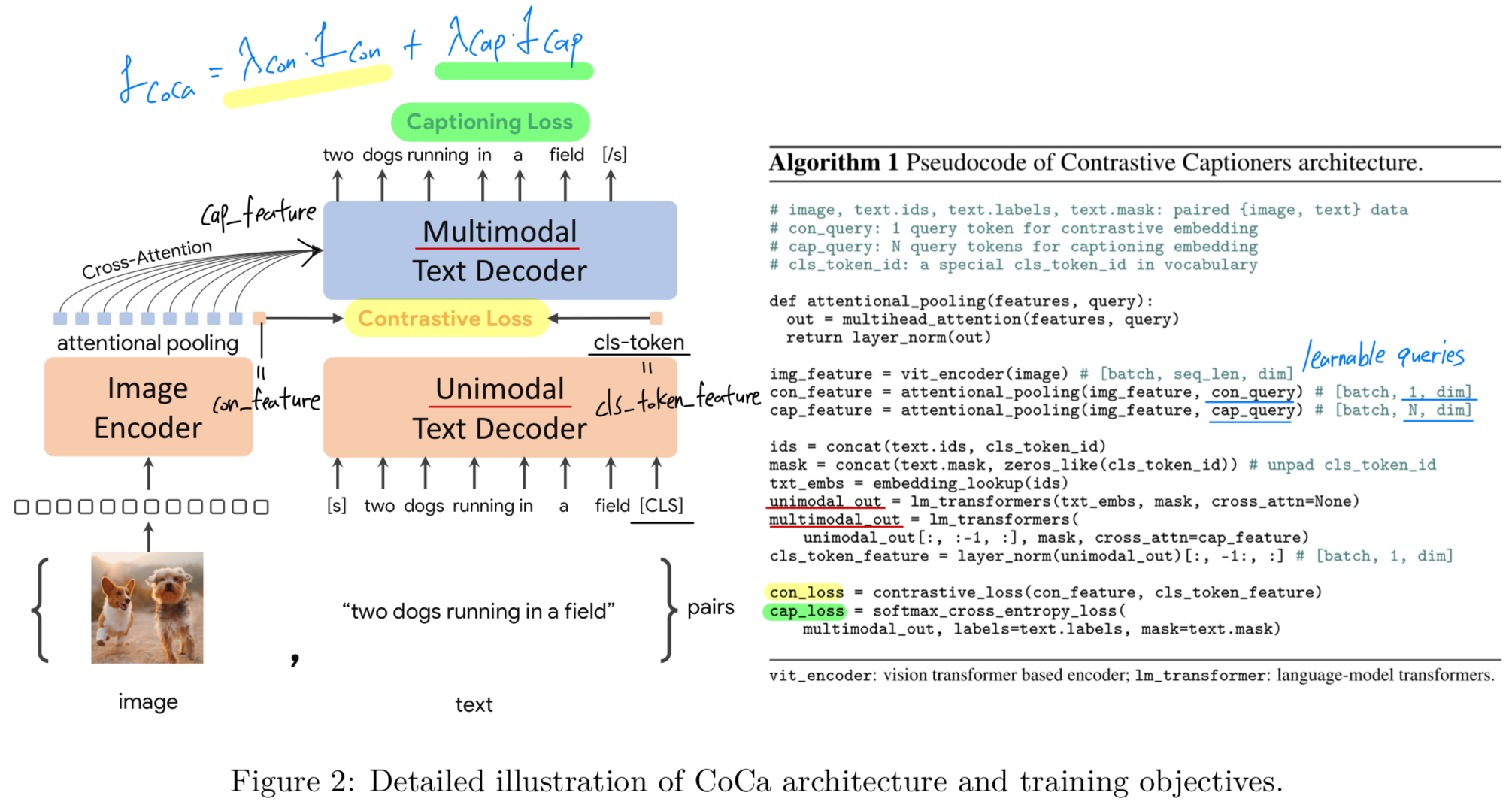
- Figure 2에서 proposed contrrastive captioner (CoCa)를 보여준다: three training paradigms를 통합하는 a simple encoder-decoder approach.
standard image-text encoder-decoder models와 유사하게, CoCa는 neural network encoder를 통해 images를 latent representations으로 encode한다.
보통은, ViT(또는 ConvNet과 같은 다른 image encoder도 사용)를 사용하며, a causal masking transformer decoder로 texts를 Decodeing한다.
- standard decoder transformers와 달리,
CoCa는 unimodal text representations을 encoding하기 위해 decoder layers의 첫 절반의 cross-attention을 생략하고,
이후 나머지 decoder layer에서는 image encoder output에 대해 cross-attending을 수행함으로써 multimodal image-text representations을 학습한다.
결과적으로, CoCa decoder는 contrastive and generative objectives 둘 다 허용하는 unimodal and multimodal text representations을 동시에 생성한다.
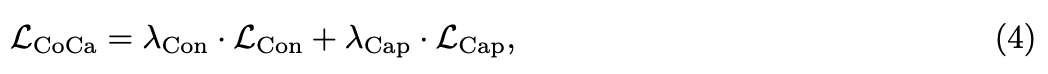 은 은 loss weighting hyper-parameters이다.
은 은 loss weighting hyper-parameters이다.
the single-encoder cross-entropy classification objective는 vocabulary가 the set of all label names로 구성된 경우,
a special case of the generative approach applied on image annotation data로 해석될 수 있다.(?)
(이게 무슨 뜻인가? 예를 들어, classification은 1000개의 label 중에서 하나를 고르는 객관식 문제인데
Generation은 30,000개의 vocabulary를 이용해서 문장을 만드는 주관식 문제임.
generation 문제에서 답을 딱 한 단어만 쓰게 하고, 쓸 수 있는 단어들을 set으로 구성해준다면
결국 그게 바로 객관식처럼 classification하는 문제와 똑같아진다는 것.)
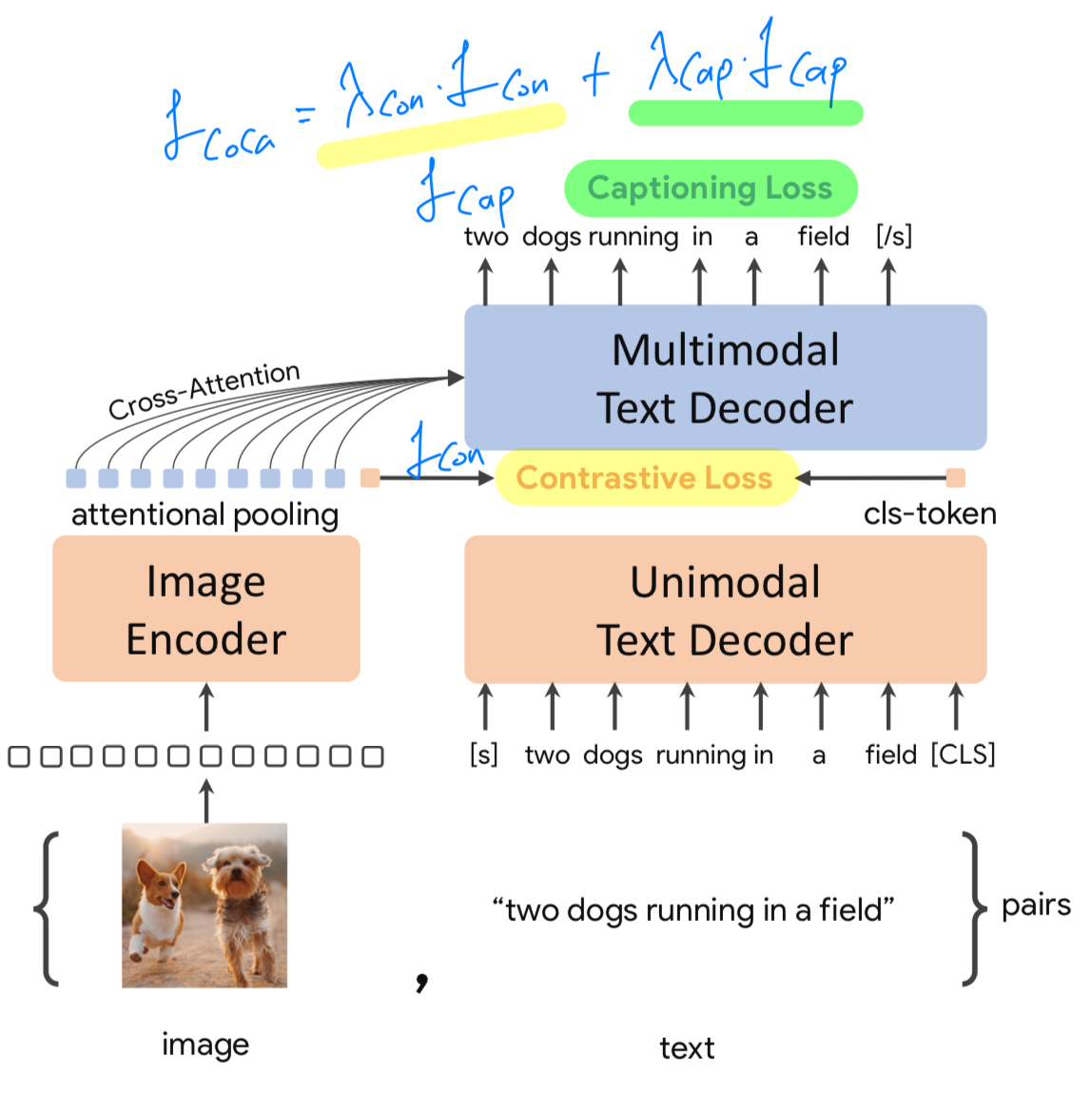
Decoupled Text Decoder and CoCa Architecture
-
contrastive approach는 an unconditional text representation을 사용하는 것과 달리,
captioning approach는 the conditional likelihood of text를 optimize한다.
이러한 dilemma를 해결하고 두 methods를 a single model로 결합하기 위해,
우리는 a simple decoupled decoder를 설계한다.
decoupled decoder는 decoder를 unimodal decoder과 multimodal decoder로 split한다.
여기서 unimodal decoder에서는 cross-attention mechanism을 생략한다.- 즉, the bottom 는 causally-masked self-attention을 통해 input text를 latent vectors로 encoder하는 unimodal decoder layers이고,
- the top 는 casually-masked self-attention에 추가로 visual encoder의 output과 cross-attention을 수행하는 multimodal layers이다.
-
모든 decoder layers는 future tokens에 대한 attention을 금지한다. (masked)
그리고 multimodal text decoder output을 captioning objective 에 직접 사용할 수 있다.
contrastive objective 에 대해, 우리는 input sentence 끝에 learnable token을 붙이고 그 unimodal decoder의 결과를 text embedding으로 사용한다. -
우리는 처럼 decoder의 절반을 split했다.
ALIGN에 따라, 우리는 image resolution of and patch size , resulting in a total of image tokens 으로 Pretrain했다.
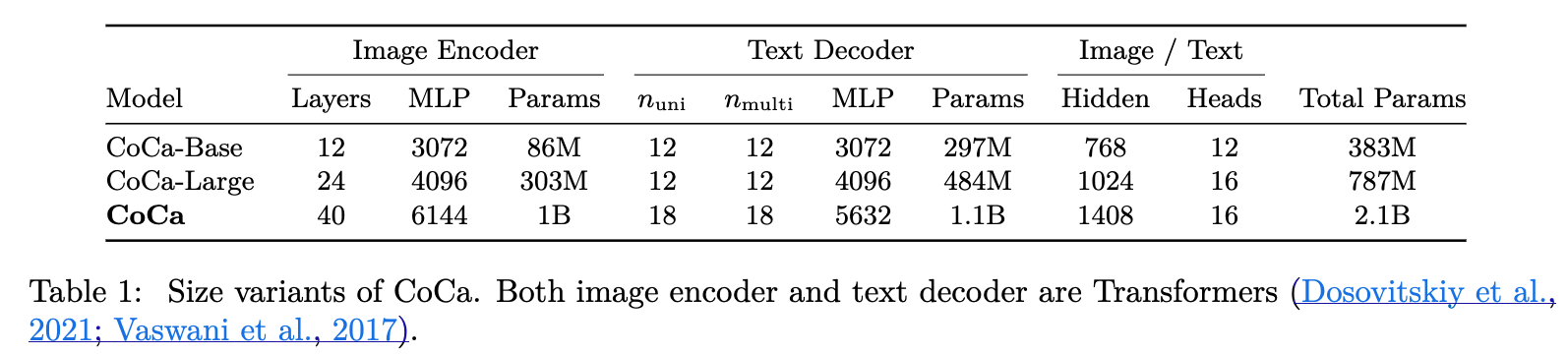
Our largest CoCa model ("CoCa" in short)은 image encoder로 1B-params을 갖고 text decoder로 2.1B-params을 갖는 ViT-giant setup을 따른다.
또한 우리는 two smaller variants of "CoCa-Base" and "CoCa-Large"를 Table 1에 자세히 적어놨다.
Attentional Poolers
- contrastive loss는 각 image에 대해 single embedding을 사용하는 반면,
encoder-decoder captioner에서는 decoder가 일반적으로 a sequece of image output tokens에 attend를 수행한다는 점은 주목할 만하다.
우리의 preliminary experiments 결과,
single pooled image embedding은 global representation으로서 visual recognition tasks에 유리한 반면,
더 많은 visual tokens (즉 more fin-grained)은 region-level features를 요구하는 multimodal understanding tasks에 더 효과적임을 확인했다.
이에 따라 CoCa는 서로 다른 training objectives and downstream tasks에 맞기 visual representations을 조정하기 위한
task-specific attentional pooling을 채택한다.
여기서 pooler는 single multi-head attention layer로 구성되며, 개의 learnable queries를 사용하고,
encoder output은 key and values로 사용된다.
이를 통해 model은 two training objectives에 대해 서로 다른 길이의 embedding을 pooling할 수 있도록 학습할 수 있으며, 이는 Figure 2에 나타나 있다.
task-specific pooling은 각 tasks에 따른 요구를 충족시킬 뿐만 아니라,
pooler를 natural task adapter로 도입하는 효과도 제공한다.
pretraining 단계에서, generative loss에는 을, contrastive loss에는 을 사용한다.
Pretraining Efficiency
-
decoupled autoregressive decoder design의 key benefit 중 하나는 two training losses를 효율적으로 계산할 수 있다는 점이다.
unidirectional language models은 전체 sentences에 대해 causal masking을 적용하여 학습되므로,
decoder는 단 한 번의 forward propagation만으로 contrastive loss와 generative loss를 모두 계산할 수 있다 (bidirectional approach에서는 two passes가 필요함).
그 결과, 대부분의 연산이 two losses 간에 공유되며, CoCa는 standard encoder-decoder models에 비해 매우 적은 overhead만을 유발한다. -
한편, 기존의 많은 방법들은 다양한 데이터 소스 및/또는 모달리티에 대해 여러 단계에 걸쳐 모델 구성 요소를 학습하는 반면, CoCa는 주석이 달린 이미지와 노이즈가 포함된 alt-text 이미지 등 다양한 데이터 소스를 사용하여, 모든 라벨을 텍스트로 취급함으로써 대조적 목표와 생성적 목표를 동시에 고려하는 방식으로 처음부터 끝까지(end-to-end) 사전학습된다.
3.3 Contrastive Captioners for Downstream Tasks
- skip
4. Experiments
4.1. Training Setup
skip
4.2. Main Results
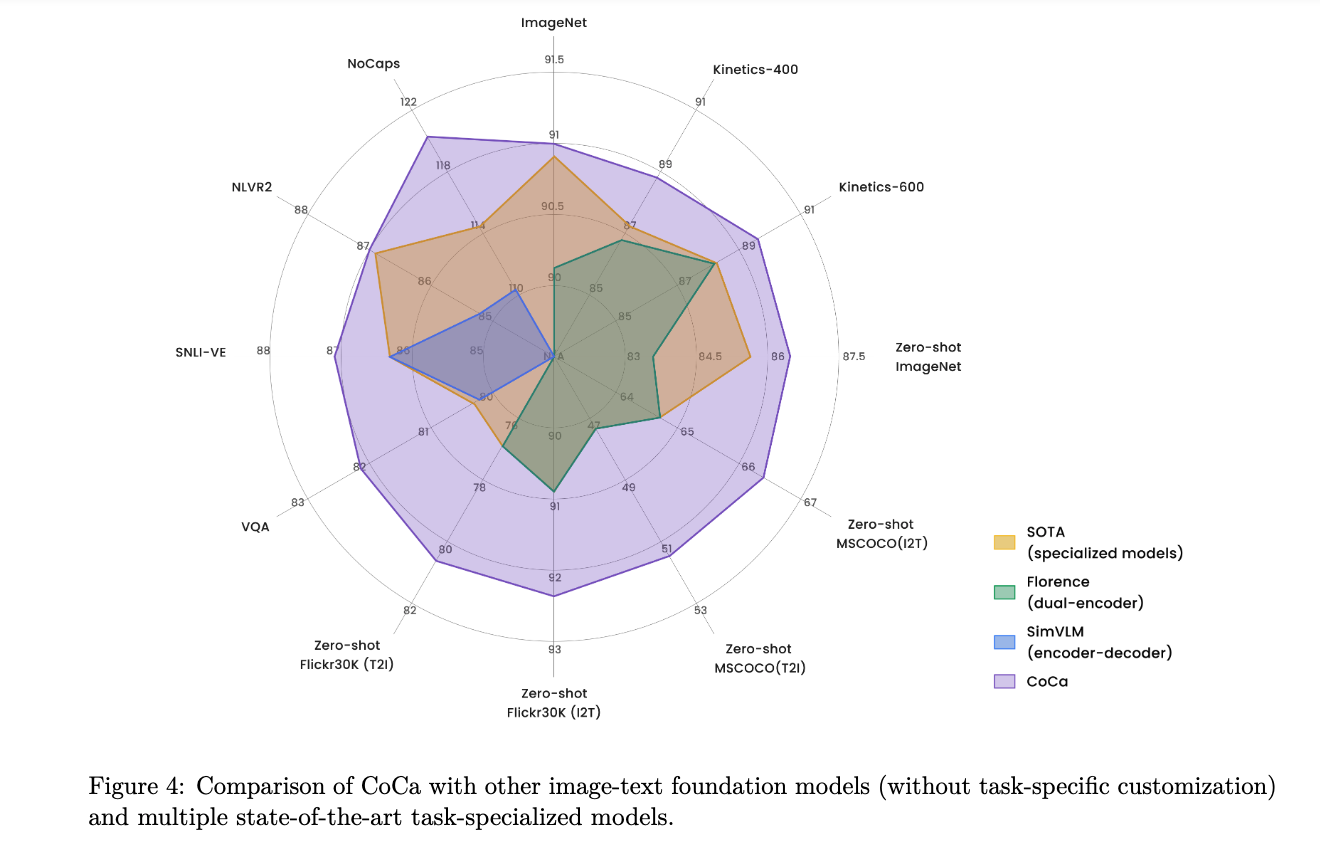
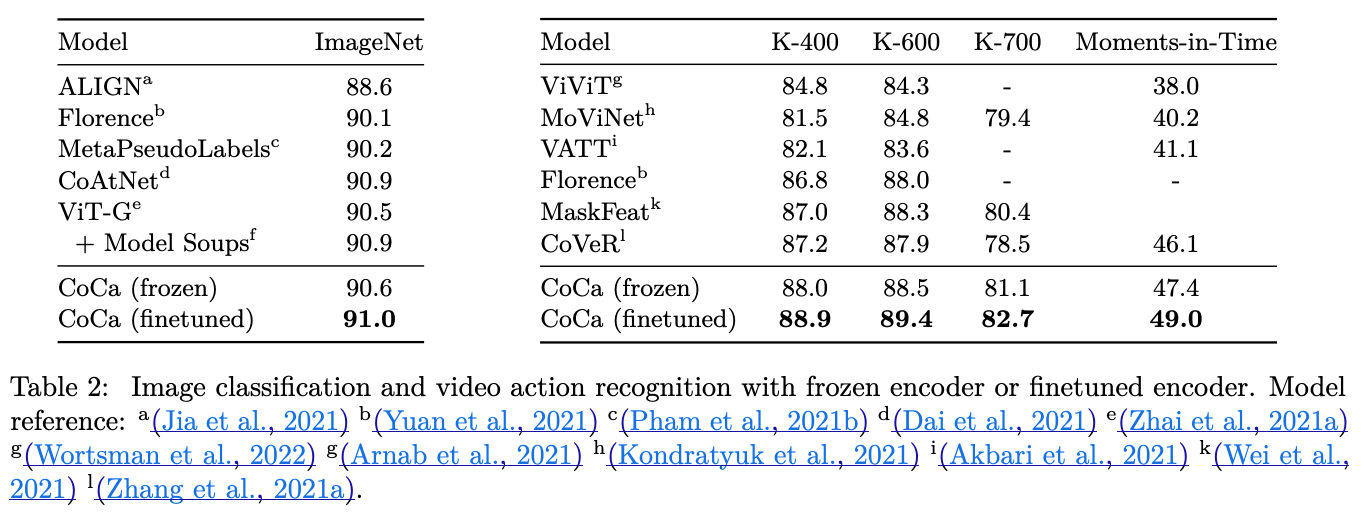
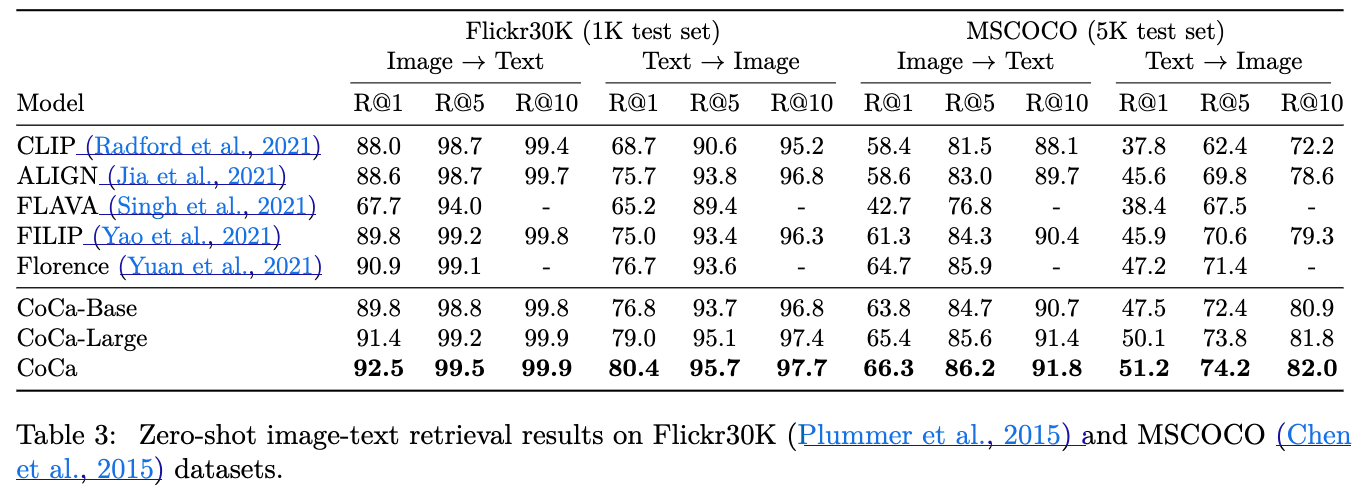
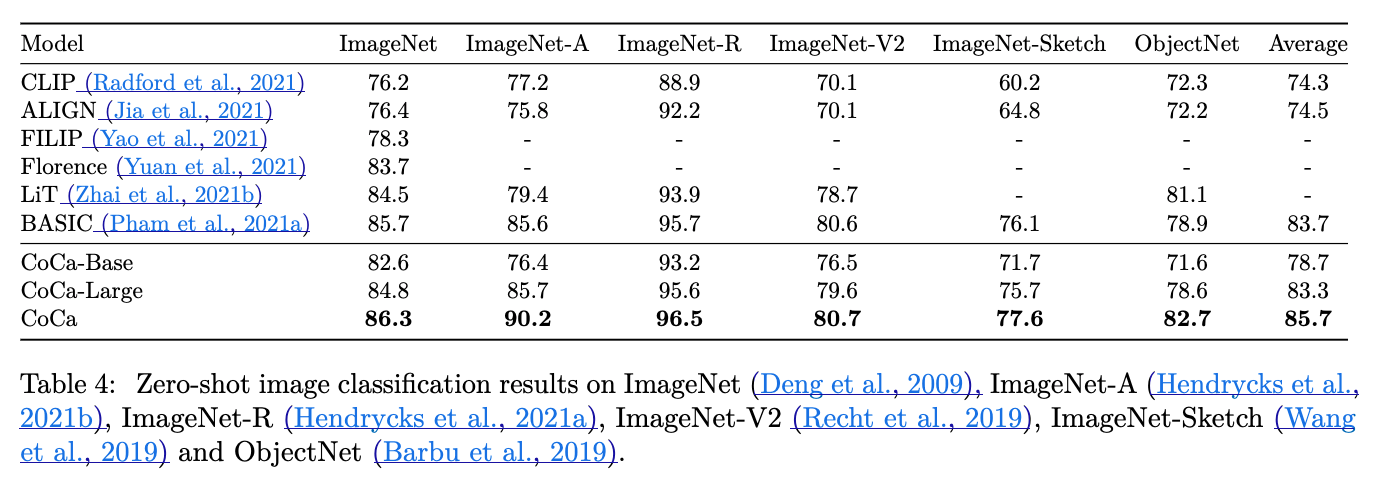
skip...
이 논문의 핵심 (BLIP과 비교하여)
-
BLIP과 CoCa이 가진 문제 제기는 똑같기 때문에 BLIP과 공통점?
- 기존 model들은 understanding 또는 generation 중 하나만 잘했던 것과 달리, understanding과 generation을 한 model에 통합하려고 함.
이를 위해, contrasitve loss와 generative loss로 학습. - image encoder로 image understanding을 하고, text decoder를 통해 text를 생성하는 기본 골격이 비슷함.
- 기존 model들은 understanding 또는 generation 중 하나만 잘했던 것과 달리, understanding과 generation을 한 model에 통합하려고 함.
-
BLIP과 CoCa의 차이점은? CoCa 논문의 핵심은?
-
architecture 관점:
-
BLIP의 architecture는 Multimodal mixture of encoder-decoder(MED)임.
즉, image encoder 1개 + text encoder 1개 + image-grounded text encoder 1개 + imge-grounded text decoder 1개.
image encoder를 제외한 나머지들은 서로 weight sharing을 하되 mask와 cross-attention 유무에 따라 역할을 다르게 함.
text encoder는 Bi Self-Attn, Cross-Attn X
image-grouned text encoder에서는 Bi Self-Attn, Cross-Attn O
image-grouned text decoder에서는 Causal Self-Attn, Cross-Attn O
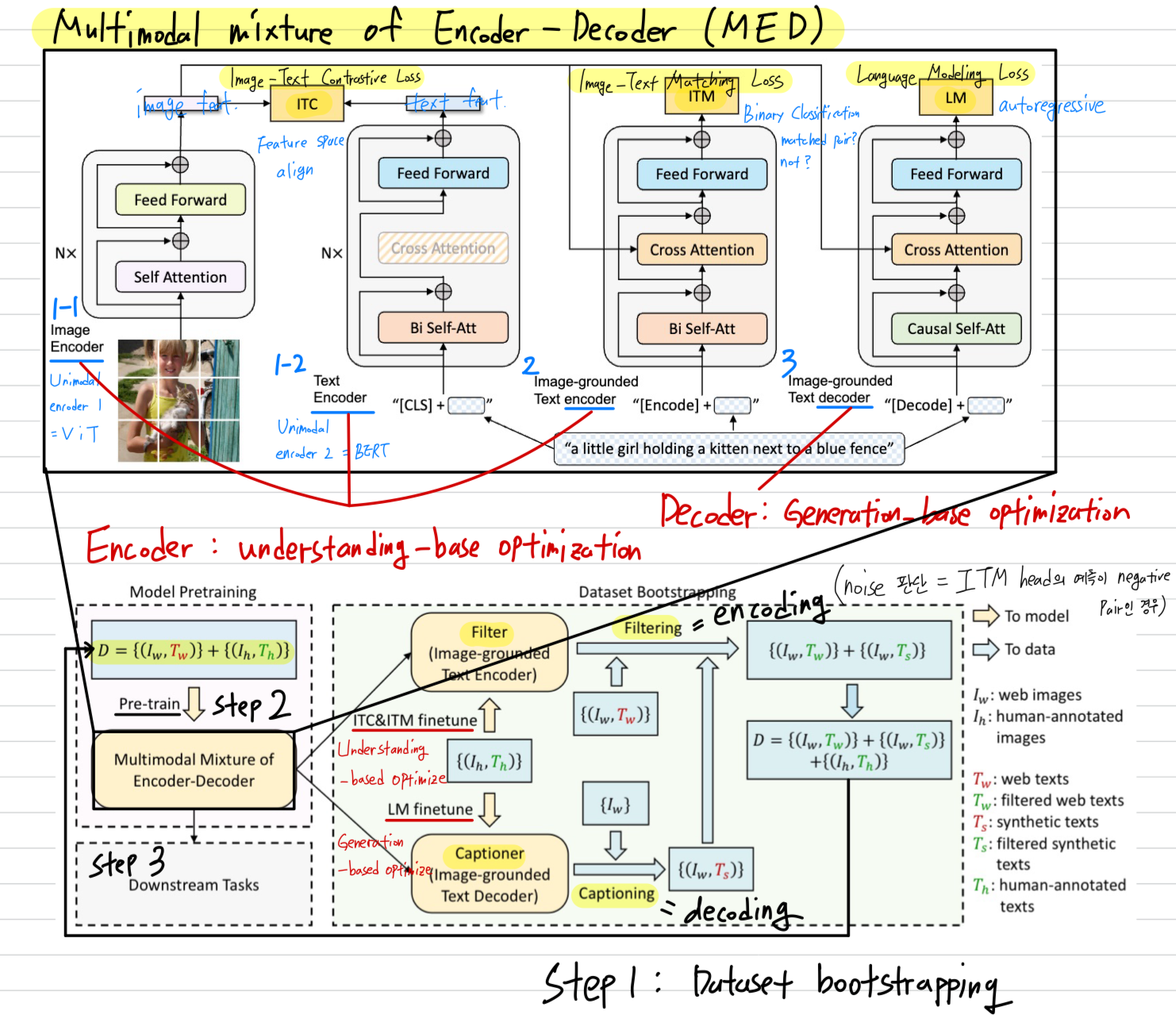
-
CoCa의 architecture는 decoupled head임.
즉, image encoder 1개 + (unimodal=text decoder 1개 + multimodal=image-grounded text decoder 1개)
understanding task에서 중요한 image-text feature의 alignmnet를 하기 위해 unimodal decoder에 token을 추가하여 image encoder의 token과 contrastive learning.
(근데 내 생각은 decoder를 분리했다고 설명하긴 하지만, 사실상 text encoder 1개와 multimodal text decoder 1개를 순차적으로 이어붙인거 아닌가?)
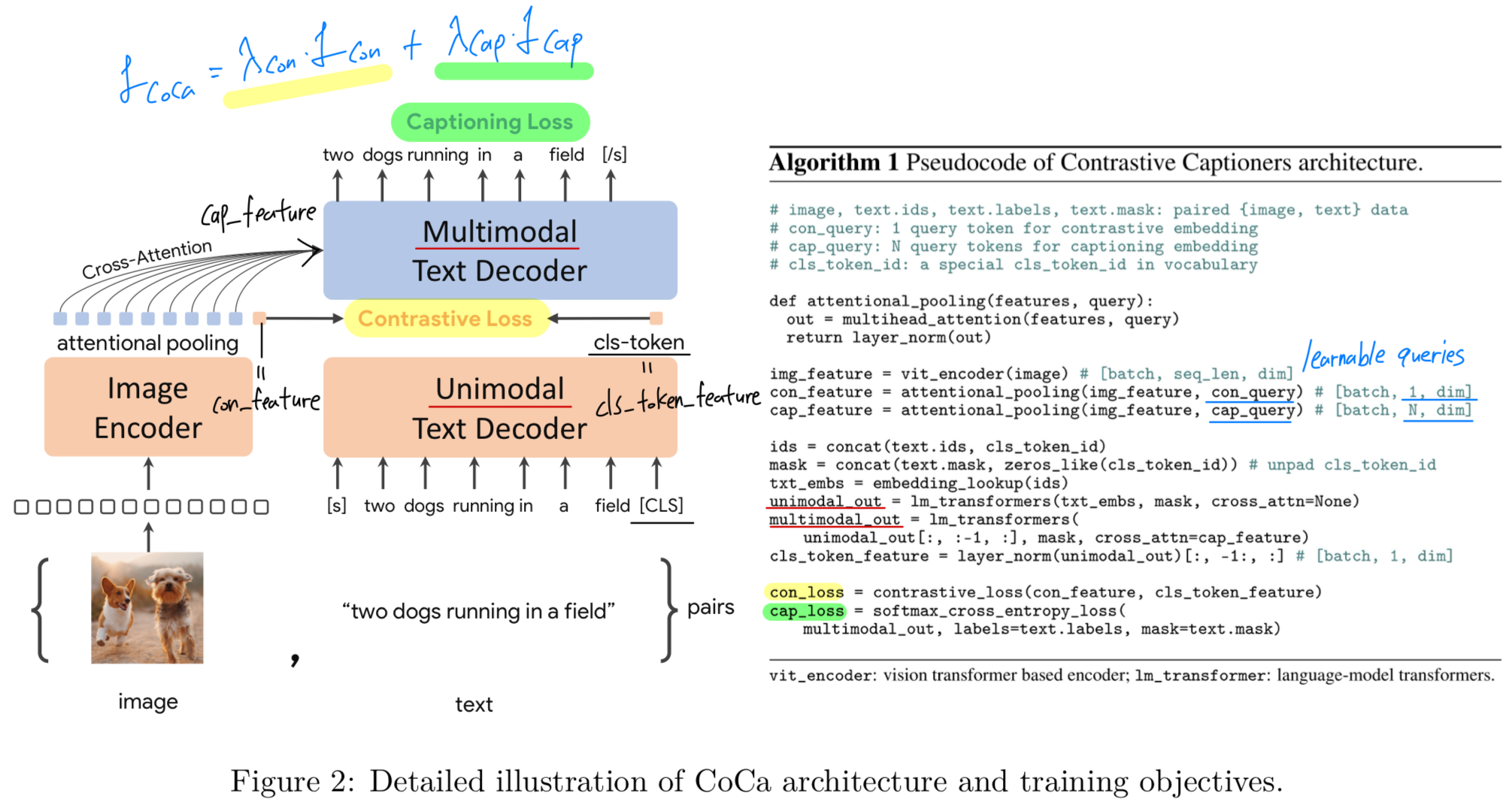
-
-
training 시 연산 효율성
- BLIP은 서로 다른 training objectives(understanding, generating)를 위해 여러 encoder/decoder를 독립적으로 사용.
구체적으로,
Image–Text Contrastive (ITC) loss를 계산하기 위해 image encoder와 text encoder를 각각 1회 forward.
Image–Text Matching (ITM) loss를 위해 image-grounded text encoder를 1회 forward.
Language Modeling (LM) loss를 위해 image-grounded text decoder를 1회 forward
총 4회의 forward pass가 필요.
이 중 ITC(contrastive) loss와 LM(generating) loss만 고려하더라도, image encoder의 forward를 제외하면 2회의 forward pass가 요구된다. - CoCa는 decoupled autoregressive decoder 구조를 통해 학습 효율을 개선한다.
Image–Text Contrastive loss를 위해 image encoder와 unimodal text decoder를 각각 1회 forward.
Captioning loss (BLIP의 LM loss에 해당)를 위해 multimodal text decoder를 1회 forward
총 3회의 forward pass가 필요하다.
마찬가지로 image encoder의 forward를 제외하면, contrastive loss와 captioning loss 계산을 위해 2회의 decoder forward가 필요하다. - 표면적으로 보면 CoCa 역시 두 번의 forward를 수행하는 것으로 보일 수 있다.
그런데 CoCa 저자들은 이를 single forward로 설명한다.
그 이유는 CoCa의 decoupled decoder가 기존 모델에서 사용하던 단일 decoder를 절반으로 나눈 것이기 때문이다.
즉, unimodal decoder와 multimodal decoder는 각각 전체 decoder의 절반 수준의 연산을 담당하며,
두 단계를 모두 수행하더라도 기존 단일 decoder를 한 번 forward하는 것과 유사한 연산 효율을 가진다는 점을 강조한다.
이러한 설계 덕분에 CoCa는 contrastive learning과 captioning learning을 동시에 수행하면서도,
multi-decoder를 사용하는 기존 방법들에 비해 추가적인 계산 overhead를 줄일 수 있다.
- BLIP은 서로 다른 training objectives(understanding, generating)를 위해 여러 encoder/decoder를 독립적으로 사용.
-
pretraining dataset
- BLIP에서는 data의 quality를 명시적으로 해결하려고 CapFilt module을 제안함.
Captioner는 noisy web data에 대해서 새로운 caption을 생성하고,
filter는 기존+새로운 caption을 cleaning해서
새롭게 단장한 data로 pre-train했다.
즉, BLIP은 data 자체를 확장, 정제하여 dataset 자체의 quality를 끌어올림. - CoCa에서는 data를 최대한 단순하게 통합해서 사용.
모든 supervision을 text로 통일 (class label, caption, description 모두 text로 취급)
즉, CoCa는 data 정제 작업보다는 model 구조로 End-to-end & Unified Training을 하려고 시도함
- BLIP에서는 data의 quality를 명시적으로 해결하려고 CapFilt module을 제안함.
-
