[2022 NeurIPS] EfficientFormer: Vision Transformers at MobileNet Speed
[Paper Review] Efficient and Scalable
Paper Info.

Abstract
-
ViT는 CV task에서 빠르게 발전하며 다양한 benchmarks에서 promising results를 보여주고 있다.
하지만 ViT-based models은 매우 많은 parameters와 attention mechanism과 같은 model deisgn으로 인해, 일반적으로 lightweight CNNs보다 훨씬 느리게 동작한다.
따라서 ViT를 mobile devices와 같은 resource-constrained HW에서 real-time applications에 deploy하는 것은 특히 challenging하다.
최근에는 ViT의 computation comlexity를 줄이기 위해 NAS 또는 MobileNet block을 결합한 hybrid design 등의 시도가 이어지고 있지만, inference speed는 여전히 unsatisfactory이다.
이로 인해 an important question이 제기된다: can transformers run as fast
as MobileNet while obtaining high performance? -
이를 탐구하기 위해, 본 연구에서는 먼저 ViT-based model에서 사용되는 network architecture and operators를 재검토하고, inefficient designs을 식별한다.
그 다음, MobileNet blocks 없는 a dimension-consistent pure transformer를 제안한다.
마지막으로, latency-driven slimming을 수행하여 EfficientFormer라는 a series of final models을 완성한다. -
Extensive experiments는 EfficientFormer가 mobile devices에서 performance and speed에서 superiority를 보여준다.
Our fastest model, EfficientFormer-L1은 ImageNet-1K에서 Top-1 acc 79.2% 달성하며,
iPhone 12 (compiled with CoreML)에서 1.6ms inference latency로 실행된다.
이는 MobileNetV2 ×1.4 (1.6ms, 74.7% top-1)와 동일한 속도이다.
결론적으로, 이 연구는 적절히 설계된 transformer가
mobile devices에서도 high performance를 유지하면서 extremely low latency를 달성할 수 있다는 것을 입증한다.
1. Introduction
(배경)
- transformer architecture는 NLP에서 처음 제안되었다... MHSA mechanism을 도입해서 long-term dependencies를 modeling하는 network이고 parallelize가 쉽다.
ViT는 the attention mechanism을 2D image에 적용한 연구이고, CNN에 비교해서 promising results를 보여줬다.
이후에 ViT를 개선하기 위한 training strategies, 그리고 여러 vision tasks (cls, seg, detect)에 적용되고 있다.
(ViT-based model의 한계점)
- 한가지 downside는 transformer models이 보통 competitive CNNs보다 느리다는 것이다.
the inference speed of ViT에 제한을 거는 많은 factors가 있다.
(massive #params, quadratic-increasing computation complexity with respect to token length, non-foldable normalization layers, and lack of compiler level optimizations.)
이러한 high latency로 인해 transformers는 real-world apps on resource-constrained HW에 impractical하다.
그래서 lightweight CNNs이 여전히 real-time inference에서 default choice로 여겨진다.
(기존 연구)
-
the latency of transformers를 경감하기 위해, 많은 방법들이 제안되어 왔다.
예를 들어, some efforts는 linear layers를 CONV로 바꾸거나,
self-attention을 MobileNet block과 결합하거나,
sparse attention을 도입하는 방식으로 연산 비용을 줄이려는 시도를 하고 있다.
또 다른 접근법으로는, NAS나 pruning을 통해 efficiency를 높이려는 방법도 있다.
이처럼 기존 연구들은 computation-performance trade-off를 개선해왔지만,
transformer models의 applicability (실용성)에 관련된 fundamental question은 여전히 답을 얻지 못하고 있다: Can powerful vision transformers run at MobileNet speed and become a default option for edge applications? -
본 연구는 이에 대한 해답을 찾기 위해 다음의 contributions을 제시한다:
 EfficientFormer는 image detection and segmentation의 backbone으로도 사용해서 superior performance를 보인다.
EfficientFormer는 image detection and segmentation의 backbone으로도 사용해서 superior performance를 보인다.
2. Related Works
(skip)
3. On-Device Latency Analysis of Vision Transformers
- 대부분의 기존 방법들은 server GPU로부터 얻은 computation complexity (MACs) or throughput (images/sec)를 통해 the inference speed of transformers를 optimize한다.
이러한 metrics은 실제 on-device latency를 제대로 반영하지 못한다.
따라서, ViT의 inference를 edge device에서 느리게 만드는 operations and design choices들을 정확히 파악하기 위해,
우리는 다양한 models and operations에 대해 a comprehensive latency analysis를 수행하였고,
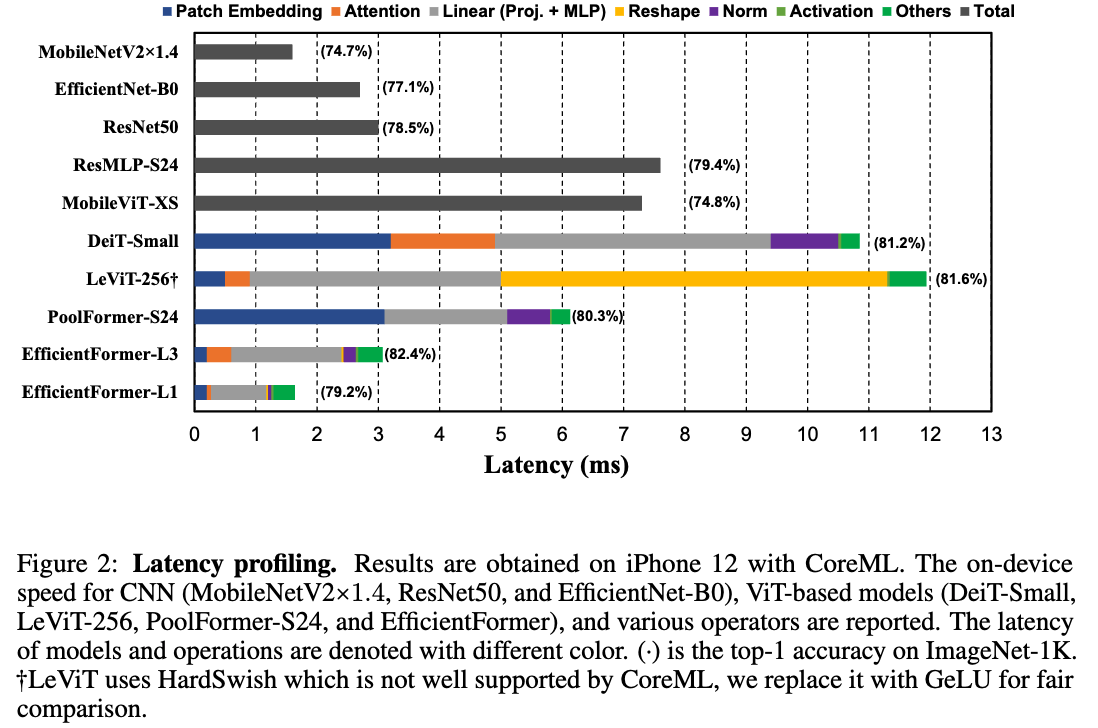
그 결과 Fig. 2에 나타난 다음과 같은 observations을 얻었다.
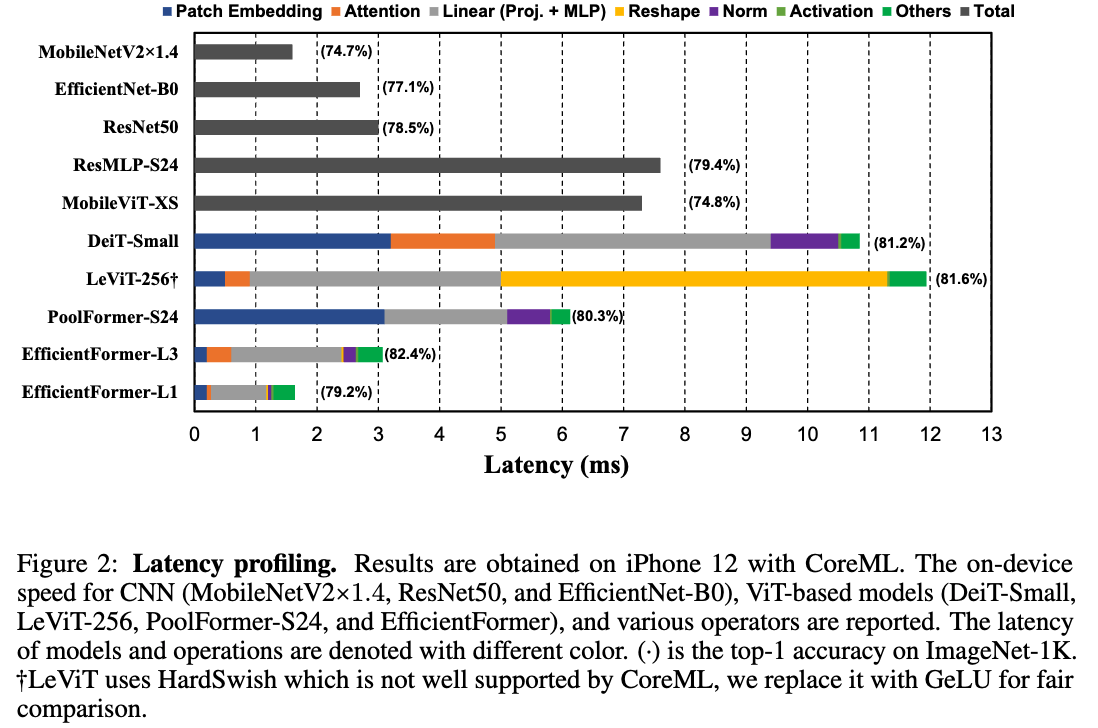
Observation 1: Patch embedding with large kernel and stride is a speed bottleneck on mobile devices.
Patch Embedding은 종종 large kernel size and stride를 가진 non-overlapping convolution layer으로 구현된다.
많은 연구에서는 Patch Embedding의 computation cost가 눈에 띄지 않거나 negligible하다고 믿어왔다.
그러나, 우리가 수행한 DeiT-S와 PoolFormer-S24 (둘 다 large kernel and stride 사용)과, LeViT-256 및 EfficientFormer (해당 방식 사용 X) 사이의 비교 결과,
Patch Embedding이 실제로 mobile device에서는 speed bottleneck으로 작용함을 확인했다.
이처럼 large-kernel convolution은 대부분의 compiler에서 잘 지원되지 않으며, Winograd와 같은 기존의 가속 algorithms도 가속화할 수 없다.
대안으로는,
겹치지 않는 Patch Embedding을,
여러 개의 HW-efficient convolution으로 구성된 빠른 down sampling (conv stem) 구조로 대체할 수 있으며,
이 구조는 Fig.3에 제시되어 있다.
Observation 2: Consistent feature dimension is important for the choice of token mixer. MHSA is
not necessarily a speed bottleneck.
최근 연구들은 ViT-based models을 MetaFormer architecture로 확장하고 있다.
MetaFormer는 MLP block과 unspecified token mixer로 구성되며, 이 중 어떤 token mixer를 선택할 것인가는 ViT-based models을 설계할 때 essential design choice이다.
선택 option은 많다: (1) the conventional MHSA mixer with a global receptive field, (2) more sophisticated shifted window attention, (3) or a non-parameteric operator like pooling.
우리는 비교 대상을 MHSA(1)와 Pooling(3), 두 가지 mixers로 좁혔다.
MHSA는 better performance 때문에 선택했고, Pooling은 simplicity and efficiency 때문에 선택했다.
한편, Shifted Window attention(2)과 같은 복잡한 token mixer는 대부분의 public mobile compilers에서 지원되지 않기 때문에 본 연구 범위에서 제외했다.
또한, 우리는 Lightweight convolution 없이 architecture를 설계하기 위해 Depth-wise Convolution으로 Pooling을 대체하지는 않았다.
두 token mixer의 latency를 이해하기 위해 아래의 두 가지 비교를 수행했다.
1. PoolFormer-S24과 LeViT-256의 비교.
LeViT-256의 bottleneck은 Reshape operation임을 확인했다.
LeViT-256은 대부분이 4D tensor에서의 CONV 연산으로 구성되어 있으며, MHSA에 feature를 전달할 때는 3D tensor (patchified 형태)가 필요하므로, 빈번한 Reshape operation이 발생한다.
특히 attention head의 the extra dimension은 제거되어야 하므로, 이러한 변환이 빈번하게 반복되어 mobile에서 speed 저하의 원인이 된다. (Fig.2 참조)
반면에, Pooling 연산은 4D Tensor와 자연스럽게 호환되며, network가 주로 CONV-based implementations (예: 1x1 CONV MLP, CONV stem for downsampling)으로 구성될 때 효율적이다.
따라서 PoolFormer는 faster inference speed를 보인다.
2. DeiT-Small vs LeViT-256의 비교.
feature dimension이 consistent하고 Reshape이 필요 없다면, MHSA는 mobile에서 큰 speed 저하를 일으키지 않았다.
비록 MHSA는 computation이 훨씬 많지만, DeiT-Small은 3D feature를 일관되게 유지함으로써, 새로운 ViT variants인, LeViT-256과 유사한 속도를 달성할 수 있다.
결론적으로, 본 논문에서는 4D feature implementation과 3D feature MHSA가 동시에 가능한 dimension-consistent network를 제안한다 (Sec. 4.1).
이로써 비효율적으로 빈번하게 사용되는 Reshape operations을 제거할 수 있다.
Observation 3: CONV-BN is more latency-favorable than LN (GN)-Linear and the accuracy drawback is generally acceptable.
Choosing the MLP implementation은 또 다른 essential design choice이다.
보통, 두 가지 options 중 선택한다: layer nomalization (LN) with 3D linear projection (proj)과 CONV 1x1 with bathc normalization (BN).
CONV-BN은 latency 측면에서 더 유리하다.
이는 BN이 inference phase 이전에 convolution 연산에 미리 fold (병합)될 수 있기 때문이고, 결국 속도가 향상된다.
반면, Dynamic Normalization인 Layer Normalization (LN)이나 Group Normalization (GN)은 inference 단계에서도 여전히 running statistics를 수집하므로, latency에 영향을 미친다.
DeiT-Small과 PoolFormer-S24 (Fig.2) 및 이전 연구에 따르면, LN으로 인한 latency는 전체 network latency의 약 10~20%를 차지한다.
Appendix Tab. 3에 제시된 ablation study에 따르면, CONV-BN은 GN에 비해 성능이 약간 떨어지지만, channel-wise LN과는 비슷한 성능을 보인다.
따라서 본 논문에서는 모든 4D latent feature 구간에서는 latency gain with a negligible performance drop을 위해 CONV-BN을 최대한 적용하고, 3D feature 구간에서는 ViT의 원래 MHSA design과 align되고 accuracy가 더 높은 LN을 적용.Observation 4: The latency of nonlinearity is hardware and compiler dependent.
마지막으로 우리는 GeLU, ReLU, HardSwish를 포함한 nonlinearity에 대해 연구했다.
이전 연구에서는 GeLU가 HW에서 비효율적이며 inference를 저하시킨다고 제안한 바 있습니다.
하지만 우리의 실험에서는, GeLU가 iPhone 12에서 잘 지원되며 ReLU와 비교해 거의 느리지 않음을 관찰했다.
반면, HardSwish는 놀라울 정도로 느린 성능을 보였으며, 이는 해당 연산이 compiler에서 잘 지원되지 않기 때문일 수 있다.
따라서 본 연구에서는 GeLU 활성 함수를 채택하였다.
4. Design of EfficientFormer
- 위에서 했던 latency analysis에 기반해서, 우리는 Fig.3.에 그려진 the design of Efficient Former을 제안한다.
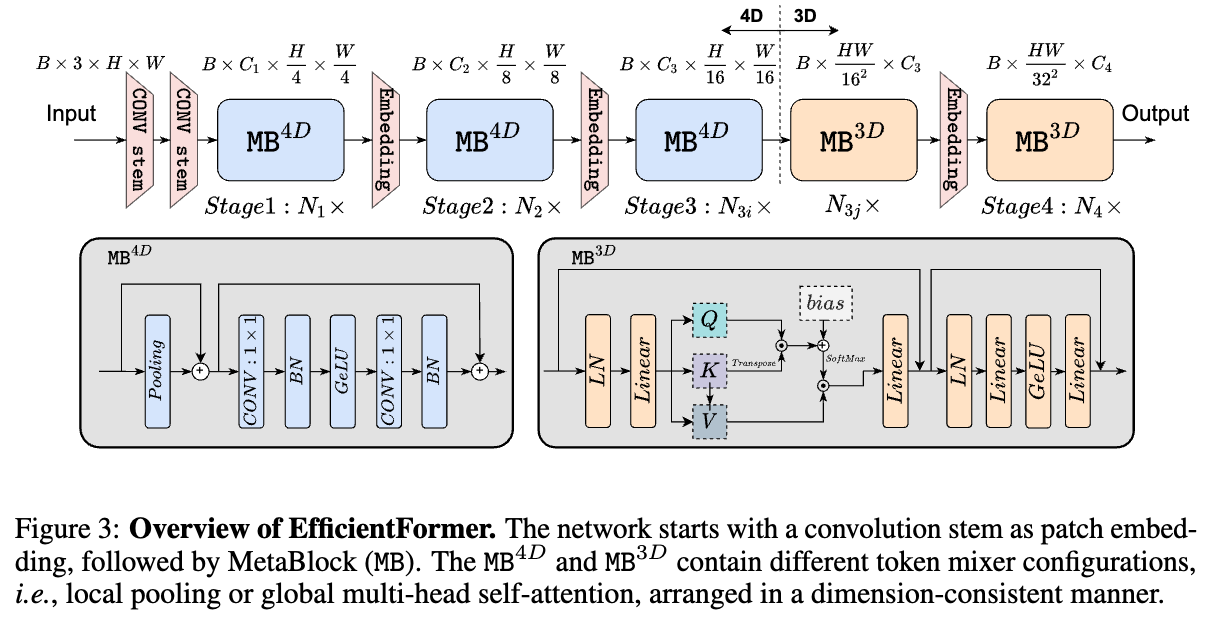
4.1. Dimension-Consistent Design

4.2. Latency Driven Slimming
skip
5. Experiments

요약
- 이 논문은 mobile device에서 연산자별로 bottleneck을 비교 및 분석하여, 그 분석을 기반으로 EfficientFormer를 설계함
