[2022 CVPR] (중단) A-ViT: Adaptive Tokens for Efficient Vision Transformer
[Paper Review] Efficient and Scalable

Paper Info.
- CVPR2022

Abstract
-
우리는 서로 다른 complexity를 가진 image에 대해 ViT의 inference cost를 adaptively 조정하는 방법인, A-ViT를 제안한다.
A-ViT는 network에서 inference가 진행됨에 따라 ViT의 #tokens를 자동으로 줄임으로써 이를 달성한다.
이 작업을 위해 Adaptive Computation Time(ACT)[17]를 재구성했다.
재구성 내용은 redundant spatial tokens을 제거하기 위해 halting(중단)을 연장했다. -
ViT의 매력적인 architectural properties 덕분에 network architecture나 inference HW를 수정하지 않고도 우리의 adaptive token reudction mechanism이 inference를 speedup할 수 있었다.
A-ViT는 별도의 parameters나 halting을 위한 sub-network 없이, original network parameters에 대한 learning of adaptive halting을 수행한다.
또한, 기존 ACT 접근법에 비해 training을 안정화시키는 distributional prior regularization을 도입했다. -
image classification task(ImageNet1K)에서 우리가 제안한 A-Vit가
informative spatial features를 filtering하고 the overall compute를 cutting dlown하는 데에 매우 효과적임을 보였다.
제안된 방법은 DeiT-Tiny의 throughput을 62%, DeiT-Small을 38% 향상시키면서도 accuracy는 단 0.3%만 감소하여 이전 연구보다 큰 차이로 성능을 능가했다.
1. Introduction
-
ViT는 image classification, object detection, image generation, 그리고 semantic segmentation 등의
다양한 vision applications에서 성공적으로 적용되고 있지만,
token 간의 inter-/intra-calculations 수가 기하급수적으로 증가하여 computationally expensive하다.
이로 인해 datap processing clusters나 edge devices에 vision transformers를 deploying하는 것은 computational and memory resource 관점에서 큰 challenge이다. -
이 논문의 main focus는 the complexity of input image에 따라 ViT에서 계산량을 automatically adjust하는 방법을 연구하는 것이다.
거의 모든 vision transformer들은 input에 상관없이 inference 중에 고정된 cost를 가지지만,
the difficulty of a prediction task는 the complexity of the input image에 따라 달라진다.
예를 들어, homogeneous background에서 single image로부터 car와 human을 분류하는 것은 비교적 간단하지만,
complex background에서 다양한 견종을 분류하는 것은 더 어렵다.
이러한 영감을 바탕으로, input에 따라 vision transformer에서 사용되는 계산량을 adaptively adjust하는 framework를 개발했다. -
input-independent inference는 Graves[17]이 Adaptive Computation Time(ACT)와 같은 방법을 통해 연구되었다.
ACT는 discrete halting problem을 continuous optimization problem으로 변환하여 total compute에 대한 upper bound를 minimized하는 방식이다.
최근에는 stochastic(확률론적) 방법이나 spatial extension 버전의 ACT가 연구되었지만,
이 방법들은 high-performance HW에서 dense computations에 의존하기 때문에 faster inference를 만들진 못했다.
하지만, vision transformer's uniform shape and tokenization은 이러한 adaptive computation을 가능하게 한다는 점에서 이전 연구들의 efficiency-accuarcy tradeoff를 능가할 수 있다.
-
이 논문에서, 우리는 vision transformers를 위한 input-dependent adaptive inference mechanism을 소개할 것이다.
naive approach는 ACT를 따르는 것인데, 이는 residual layer에서 모든 token의 computation을 동시에 중단하는 방식이다.
우리는 이 방식이 소폭의 계산 감소와 바람직하지 않은 accuracy loss를 초래한다는 것을 발견했다.
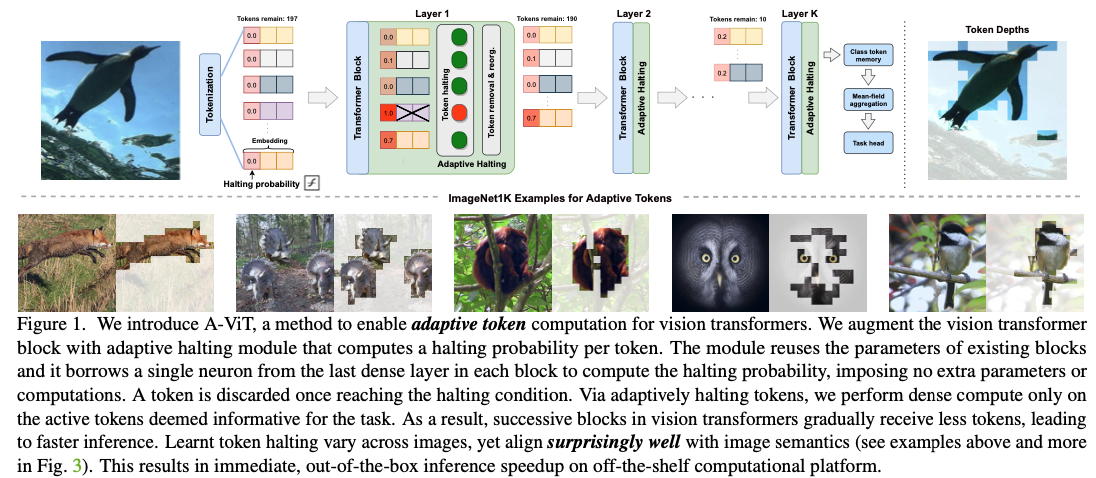
이를 해결하기 위해, 우리는 A-ViT라는 a spatially adaptive inference mechanism을 제안하며,
이는 서로 다른 token의 계산을 서로 다른 depth에서 중단하고, 동적으로 discriminative(변별력있는) token에만 계산을 할당한다.
우리의 spatial halting은 중단된 token을 underlying computation에서 효율적으로 제거할 수 있으므로 고성능 HW에서 직접적으로 지원된다.
게다가, entire halting mechanism은 model 내의 기존 parameter를 사용해 학습할 수 있으며, 추가적인 parameter를 도입할 필요가 없다.
우리는 또한 halting probability에 대한 distributional prior을 제안하여 특정 computational budgets을 목표로 할 수 있는 새로운 방법을 제안한다.
실험적으로, the depth of compute가 object semantic(객체의 의미)과 강하게 상관되어, 우리 model이 덜 관련 있는 background information을 무시할 수 있음을 확인했다.(Figure 1에서 quick examples을 확인하고 Figure 3에서 more examples 참조.).
제안된 방법은 inference cost를 크게 줄이며, ImageNet1K에서 DEIT-Tiny의 처리량을 62%, DEIT-Small의 처리량을 38% 향상시키면서 정확도는 단 0.3%만 감소했다.

-
Our main contributions are as follows :

2. Related Work
- transformer의 efficiency를 개선하는 방법은 여러 가지가 있다.
transformer block 간의 weight sharing[26], 각 token의 attention 범위를 동적으로 제어[5, 40], model이 earlier transformer block에서 결과를 출력할 수 있게 하는 방법 [38, 56], 그리고 pruning을 적용하는 방법 [53]이 그 예시이다.
여러 방법들은 token 간의 quadratic interactions을 줄여 transformer의 computationally complexity를 줄이는 것을 목표로 하고 있다.
우리는 input image의 complexity에 따라 adaptive inference를 수행하는 방법에 중점을 두고 있다.
Special architectures.
- model의 architecture를 변경하여 adaptive computations을 지원하는 방법이 있다.
예를 들어, neural network를 a fixed-point function으로 나타내는 model들은 기본적으로 adaptive computation의 속성을 가질 수 있다.
이러한 model들은 internal state와의 차이를 계산하며, 여러 interations을 통해 원하는 solution에 수렴하게 된다.
예를 들어, Ordinary Differential Equations(ODEs)는 the dynamics of procss를 학습하기 위한 반복적인 computation을 사용하는 새로운 architecture를 사용한다.
OEDs를 사용하면 specific solver가 필요하며, 이는 fix depth models보다 느리고 model design에 추가적인 제약을 요구한다.
[54]에서는 서로 다른 resolutions로 여러 classifier를 학습하고, model의 confidence가 threshold를 초과할 때 계산을 중단하는 방식을 제안했다.
[27]은 weight를 공유하는 residual variant와 halting mechanism을 제안했다.
Stochastic and reinforcement learning (RL) methods.
- residual neural network의 depth는 inference 중에 일부 residual layer를 skip함으로써 변경할 수 있다.
이는 residual network가 동일한 input 및 output feature dimension을 가지며, 반복적으로 feature refinement를 수행한다는 사실 때문에 가능하다.
개발 추가의 models을 학습하여 backbone 위에 얹어 computational graph를 변경할 수 있다.
여러 접근법에서는 별도의 network를 RL을 통해 학습하여 언제 중단할지 결정하는 방식을 제안했다.
이러한 방식은 전용 중단 model의 학습을 요구하며, RL에서의 high-variance training signal로 인해 학습이 어려울 수 있다.
Adaptive inference in vision transformers.
-
DynamicViT [36]는 Gumbel-softmax trick으로 학습된 추가 control gates를 사용하여 token을 중단시키며, 이는 Conv-AIG [45] 및 [46]과 유사한 점이 있다.
Gumbel-softmax-based relaxation solutions은 regularization의 어려움, 학습의 stochasticity, 그리고 stochastic loss의 early convergence로 인해
최적의 결과를 내지 못할 수 있으며, 이로 인해 heuristic guidance로써 multi-stage token sparsification가 필요하다. -
이 논문에서는 이 문제를 다른 관점에서 접근하여, ACT와 유사한 방식은 어떻게 vision transformers에서 spatially adaptive computation으로 정의할 수 있는지를 탐구한다.
우리는 the need for the extra halting sub-networks를 제거할 수 있음을 완전히 입증하였으며,
efficiency, accuracy, token-importance allocation 모두에서 model이 개선된 결과를 가져온다는 것을 보여줄 것이다.
3. A-ViT
-
input image 를 갖는 vision transformer network가 있다고 가정하자.
이 network는 다음과 같이 input을 prediction으로 만든다 :
 encoding network 는 image 를 positioned tokens 로 만들어, image patches로 tokenize한다.
encoding network 는 image 를 positioned tokens 로 만들어, image patches로 tokenize한다.
(여기서 는 the total number of tokens이고,
는 각 token의 embedding dimension이다.
는 전체 stack 이후에 변형된 class token을 post-process한다.
그리고 개의 intermediate transformer blocks 는 self-attention을 이용하여 input을 변형한다.)
layer 에 있는 transformer block()을 고려하자.
이 block은 layer 의 모든 tokens을 다음과 같이 변환한다 :
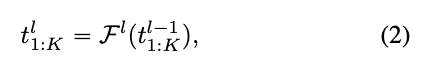 는 개의 updated token을 나타낸다. ()
는 개의 updated token을 나타낸다. ()
transformer blocks 의 내부 계산 흐름은 layer마다 token의 개수인 를 변경할 수 있다는 점에 유의하자.
이는 token이 halting mechanism으로 인해 dropped될 때 out-of-the-box computational gains(즉각적인 계산 이점)을 제공한다.
Vision transformer[11, 43]는 모든 layer에서 모든 tokens에 대해 consistent feature dimension 를 활용한다.
이는 모든 layer를 종합적으로 monitoring하는 global halting mechanism을 학습하고 포착하기 쉽게 만든다.
또한 이는 서로 다른 depth에서 #channels와 같은 다양한 architectural dimensions을 명시적으로 처리해줘야 하는 CNN과 비교하 transformer의 halting design을 더 쉽게 만든다. -
tokens을 적응적으로 중단하기 위해, 각 token에 input-dependent halting score를 도입했다.
이는 layer 에서 halting probability 로 정의된다 :
 는 halting module이다.
는 halting module이다.
ACT[17]과 유사하게, 각 token 의 halting score 가 범위에 있도록 강제하며,
inference가 deeper layers로 진행되면서 token을 중단하는 acuumulative importance를 사용한다.
이를 위해, 우리는 cumulative halting score가 을 초과할 때 token stopping을 수행한다 :
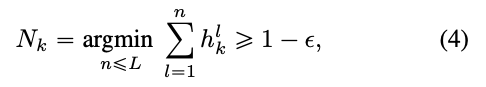 여기서 은 한 layer에서 halting을 허용하는 a small positive constant(작은 양수 상수)이다.
여기서 은 한 layer에서 halting을 허용하는 a small positive constant(작은 양수 상수)이다.
인접한 layer 사이에서 동적으로 중단된 token에 대한 의존성을 완화하기 위해,
token이 중단되고 남은 모든 depth 에 대한 token 를 masking한다.
이 과정은 (i) token value를 0으로 만들고, (ii) 다른 tokens에 대한 attention을 blocking하여,
Eqn.2.에서 에 미치는 영향을 차단한다.
우리는 모든 token이 모든 마지막 layer에서 중단하도록 로 정의했다.
우리의 token masking은 training iterations의 계산 비용을 original vision transformer의 계산 비용과 비슷하게 유지한다.
그러나 inference할 때는 중단된 token을 단순히 계산에서 제거하여 우리의 halting mechanism에 의해 얻어진 실제 속도 향상을 측정한다. -
우리는 기존 vision transformer block에 를 통합하여 MLP layer에 single neuron을 할당하여 이 작업을 수행한다.
따라서 halting mechanism을 위한 any additional learnable parameter나 계산을 도입하지 않는다.
구체적으로, 우리는 각 token의 embedding dimension 가 adaptive halting을 수용할 수 있는 충분한 용량을 제공한다는 점을 관찰했으며,
이를 통해 haltingscore calculation은 다음과 같이 할 수 있다 :
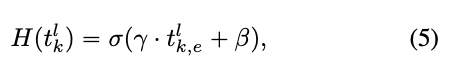 는 token 의 dimension을 나타내고,
는 token 의 dimension을 나타내고,
는 logistic sigmoid function을 나타낸다.
와 는 non-linearity를 적용하기 전 embedding을 조정하는 shifting and scaling parameters이다.
이 두 개의 scalar parameters는 모든 layer의 모든 token에 대해 공유된다.
halting score calculation에는 embedding dimension 의 only one entry(단일 항복?)만 사용된다.
경험적으로 우리는 (the first dimension)이라는 간단한 선택이 잘 작동하며, index를 변경해도 성능이 변하지 않는다는 것을 관찰했다.
따라서 우리의 halting mechanism은 두 개의 scalar parameters and 를 제외하고는 추가적인 parameters나 sub-network를 도입하지 않는다.
몰랐던 내용
- Adaptive Computation Time(ACT)?
model이 input을 처리하면서, "halting" 여부를 결정하는 halting probability를 학습하는 것.
각 단계에서 계산된 halting probability가 특정 기준을 넘어서면, 그 시점에서 model은 해당 입력에 대해 더 이상의 계산을 수행하지 않고 결과를 반환.
ACT 논문은 처음에 RNN에 적용되는 목적으로 나옴.
중단
- 나는 input-independent adaptive network 연구에 관심이 있는데,
이 논문은 input-dependent adaptive network이므로 중단한다.
