[2022 ICLR][EViT] Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations
[Paper Review] Efficient and Scalable
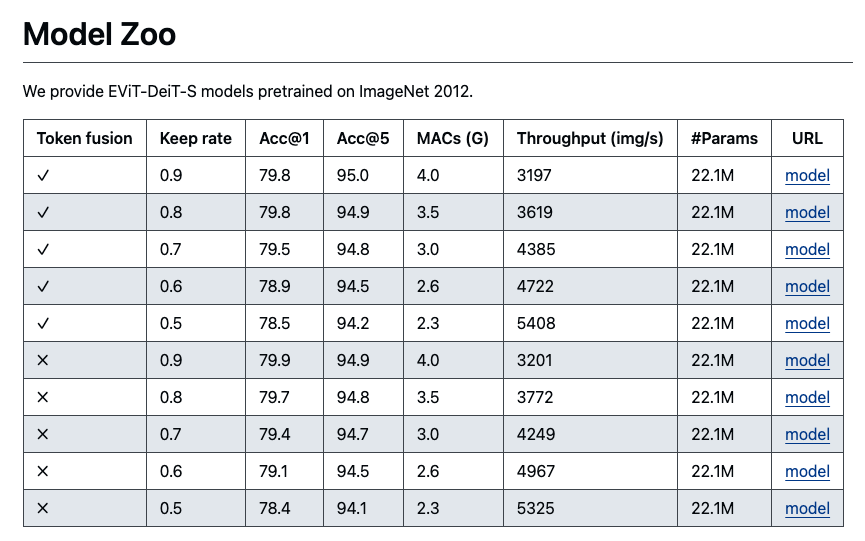
Paper Info.

Abstract
-
ViTs은 image patches를 모두 token 취급하고 이들 간에 multi-head self-attention(MHSA)을 구성한다.
그러나 이러한 image token을 완전히 활용하는 것은 redundant computations을 유발한다.
이는 MHSA에서 모든 token이 주목할 만한 것은 아니기 때문이다.
예를 들어, semantically meaningless이거나 distractive(주의를 분산시키는) image bg를 포함하는 token은 ViT prediction에 좋은 기여를 하지 않는다.
이 연구에서는 ViT model의 forward inference 동안에,
우리가 class token attention에 의해 안내되어 MHSA와 FFN module 사이에서 attentive(주목할 만한) image token을 식별한다.
그 다음, attentive image token을 유지하고, inattentive token들은 하나로 결합하여 이후 MHSA와 FFN computations을 가속화한다. -
이 방법을 통해 EViT는 두 가지 측면에서 ViT를 향상시킨다.
- 첫째, 동일한 input image token 수에서 MHSA와 FFN computations을 줄여 efficient inference를 제공한다.
예를 들어, ImageNet classification task에서 DeiT-S의 inference speed는 50% 증가하지만 인식 정확도는 0.3%만 감소한다. - 둘째, 동일한 계산 비용으로 ViT가 recognition accuracy improvement를 위해 더 많은 image token을 입력으로 받을 수 있게 한다.
이는 higher resolution images에서 더 많은 image token을 사용하는 것이다.
예를 들어, DeiT-S의 recognition performance를 vanilla DeiT-S와 동일한 계산 비용으로 1% 향상시킬 수 있었다.
- 첫째, 동일한 input image token 수에서 MHSA와 FFN computations을 줄여 efficient inference를 제공한다.
1. Introduction
-
ViTs 덕분에 Transformers로 Computer vision research가 진화되어져 왔다.
global self-attention을 이용하여, ViTs는 다양한 visual recognition scenearios에서 local convolution보다 impressive capability를 보였다.
ViT models의 개발과 함께, computation burden은 issue가 되고 있다.
또한 network convergence를 위한 더 많은 training iteration가 필요하다.
이러한 issue들은 practice usage을 위해 ViT를 가속화(expedite)해야 한다는 동기를 제공했다. -
ViT model의 가속화는 computational complexity를 줄이는 데 중요하지만, ViT acceleration에 초점을 맞춘 연구는 거의 없다.
이는 CNN과 ViT 간의 큰 model 차이 때문에 CNN model acceleration(pruning and distillation)을 ViT에 적용하는 것이 어렵기 때문이다.
그럼에도 불구하고 우리는 ViT를 다른 관점에서 분석한다.
ViT의 모든 image tokens이 final prediction에 긍정적으로 기여하지 않는다는 것을 관찰했다.
Fig. 1에서는 input image tokens 중 일부가 random하게 제거된 몇 가지 예시를 보여준다.
Fig. 1b에서는 해당 category의 visual content와 관련된 image token을 제거하면 ViT가 잘못된 예측을 하는 반면,
Fig. 1a에서와 같이 관련 없는 image token을 제거해도 ViT predictions에는 영향을 미치지 않는다.
 또한, ViT는 image를 non-overlapping tokens으로 나누고 이러한 token들에 대해 self attention computation을 수행한다.
또한, ViT는 image를 non-overlapping tokens으로 나누고 이러한 token들에 대해 self attention computation을 수행한다.
self-attention의 주목할 만한 특징 중 하나는 다양한 수의 token을 처리할 수 있다는 것이다.
이러한 관찰을 통해 우리는 ViT model accelerations을 위해 image token을 reorganize해야 한다는 동기를 얻게 되었다.
Nasser et al.(2017)에서도 ViT가 patch drop에 robust하다는 것을 보였으며, 이는 less informative patches를 제거해 ViT inference를 가속화할 수 있다는 아이디어를 뒷받침한다.
- 본 연구에서는, image tokens을 식별하고 fuse하기 위한
token reorganization method를 제안한다.
모든 image tokens이 input으로 주어진 상태에서, 이 token들과 class token 사이의 token attentiveness를 계산하여 식별한다.
그 후, attentive image tokens은 유지하고, inattentive tokens은 하나의 token으로 결합하여, inattentive token에서도 attentive token을 더 잘 식별할 수 있도록 gradient back-propagate한다.
이러한 방식으로, 우리는 network가 깊어질수록 image token 수를 점진적으로 줄여 computation cost를 줄인다.
또한, ViT backbone의 capacity는 이 identification process를 통해 추가적인 parameter 없이 유연하게 조정할 수 있다.
우리가 제안한 token reorganization method를 대표적인 ViT model(DeiT, LV-ViT)에 적용하여 ImageNet classification evaluation을 수행했다.
2. Related Work
2.1 Vision Transformers
- "Vision Transformers have shown its strong potential as an alternative to the previously dominant CNNs."
2.2 Model Acceleration
- Neural networks는 일반적으로 overparameterized되어 있어서, 상당한 redundancy in computation을 야기한다.
deep neural networks를 mobile devices에 배포하기 위해서, 우리는 networks의 storage와 computational overhead를 줄여야만 한다.- parameter pruning은 최종 성능에 민감하지 않은 redundant parameters를 줄이는 것이다.
- knowledge distillation은 larger model로부터 a small and compact model에게 knowledge를 distill하는 것이다.
→ 이러한 model acceleration strategies는 CNNs에 제한되어 있다.
-
Transformer model의 computation 가속화를 위한 몇가지 시도들(more efficient attention mechanism, compressed Transformer structures)이 있었다.
이 방법들은 주로 인위적으로 designed된 module을 통해 network architecture의 complexity를 줄이는 데 중점을 뒀다.
ViT acceleration의 또 다른 접근법은 ViT inference에 참여하는 token 수를 줄이는 것이다.
특히 Wang et al. (2021b)는 image의 patch 수를 동적으로 결정하는 방법을 제안했으며,
ViT는 intermediate outpus에 대한 충분한 confidence가 있을 경우 input image에 대한 inference를 중단한다.
주목할 만하게 Ryoo et al. (2021)은 entire feature map을 weight가 부여된 dynamic attention map으로 aggregating하여 소수의 token을 학습하는 TokenLeaner를 제안했다.
이는 input image를 tokenizing하는 정교한 방법으로 볼 수 있다.
TokenLearner와 달리 본 연구는 학습 중 informative tokens을 점진적으로 선택하는 데 중점을 둔다. -
관련된 또 다른 연구인 DynamicViT는 fully trained된 ViT에 대해 token 수를 줄이는 방법을 소개하며,
추가의 learnable parameter를 ViT에 추가하여 일부 token을 선택한다.
본 연구는 새로운 관점에서 token reorganization 방법을 제안하여 inference의 computation overhead를 줄이며,
DynamicViT와 달리 fully trained ViT를 필요로 하지 않으며, 추가의 parameter를 도입하지 않는다.
Token Regorganizations
- 우리의 방법인 EViT는 ViT (Dosovitskiy et al., 2021) 및 그 variants를 기반으로 만들어졌다.
먼저 ViT를 간략히 설명한 후,
EViT 방법을 ViT training procedure에 어떻게 통합할 수 있는지 소개한다.
EViT의 각 구성 요소인 token identification과 inattentive token fusion에 대해 자세히 설명할 것이다.
또한 각 layer에서 attentive token을 시각화하여 우리의 방법이 얼마나 효과적인지 분석하고, EViT를 사용하여 higher resolution image로 학습하는 방법에 대해 논의할 것이다.
3.1 ViT Overview
-
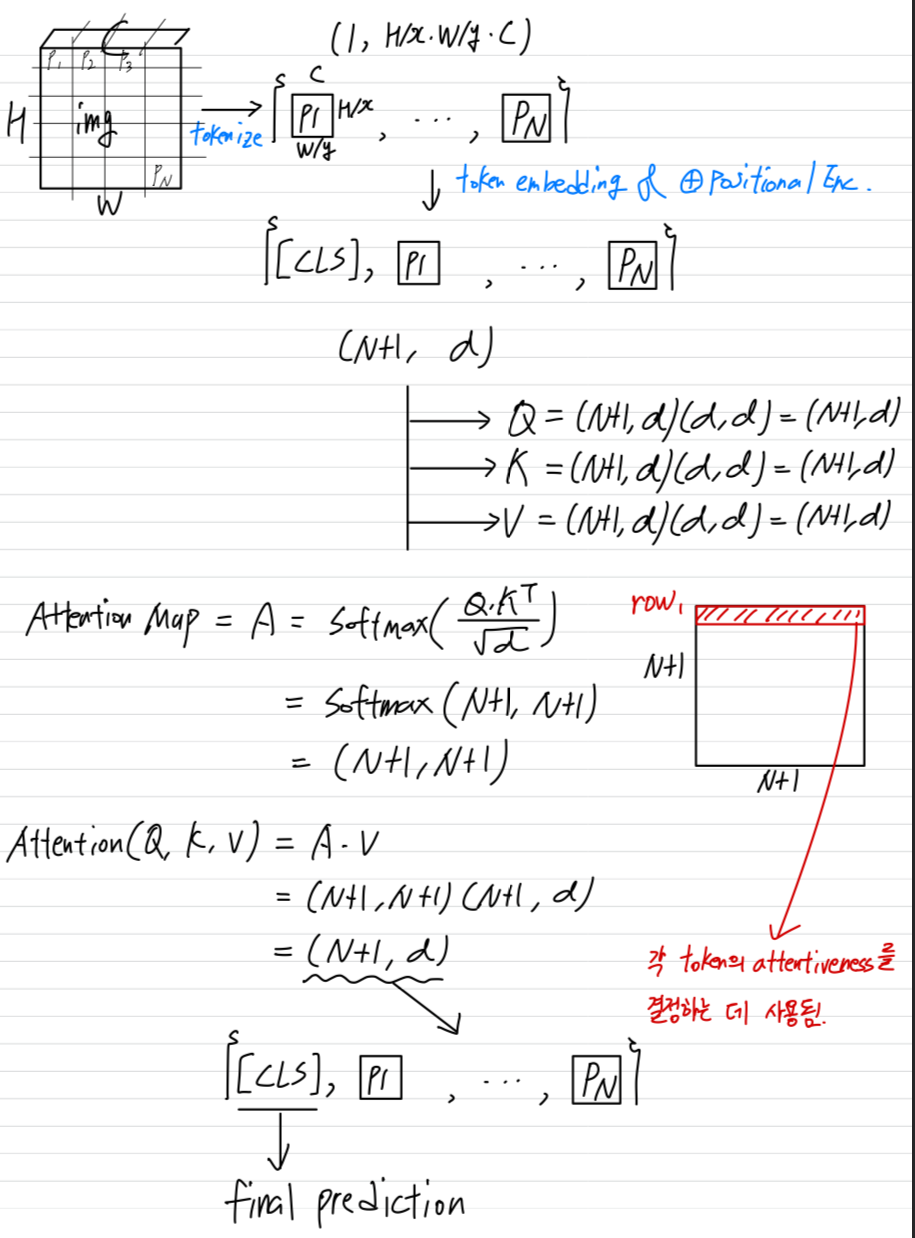
Vision Transformers(ViTs)는 Dosovitskiy et al.(2021)에서 처음으로 제안되었다.
그들은 input image를 dividing하여 tokenization하고 각 patch를 token embedding으로 projecting한다.
An extra class token [CLS]는 the set of iamge tokens에 추가되고, global image information과 final classification 임무를 책임진다.
모든 token들은 learnable vector(i.e., positional encoding)에 더해지고 나서,
multi-head self-attention(MHSA) layer와 feed-forward network(FFN)으로 구성된 sequentially-stacked Transformer encoder에 입력된다. -
MHSA에서, tokens들은 linearly mapped되어지고, 라고 하는 3개의 matrices로 가공된다.
attention operations은 다음과 같이 수행된다.
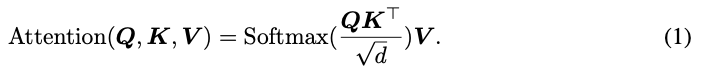 는 query vector의 length이다.
는 query vector의 length이다.
는 attention map이라고 불리는 square matrix이다.
The first row of attention map은 [CLS]에서 모든 token으로의 attention을 나타내며,
각 token의 attentiveness(importance)를 결정하는 데 사용된다. (detailed in the next subsection)
MHSA의 output tokens은 두 FC layer와 그 사이에 GELU activation layer가 있는 FFN으로 보내진다.
final Transformer encoder layer에서는 [CLS] token이 추출되어 object caetgory prediction에 사용된다.
3.2 Attentive token identification
-
ViT encoder에 입력되는 input tokens의 개수를 개라고 하자.
ViT의 마지막 encoder에서, [CLS] token은 classification을 위해 사용된다.
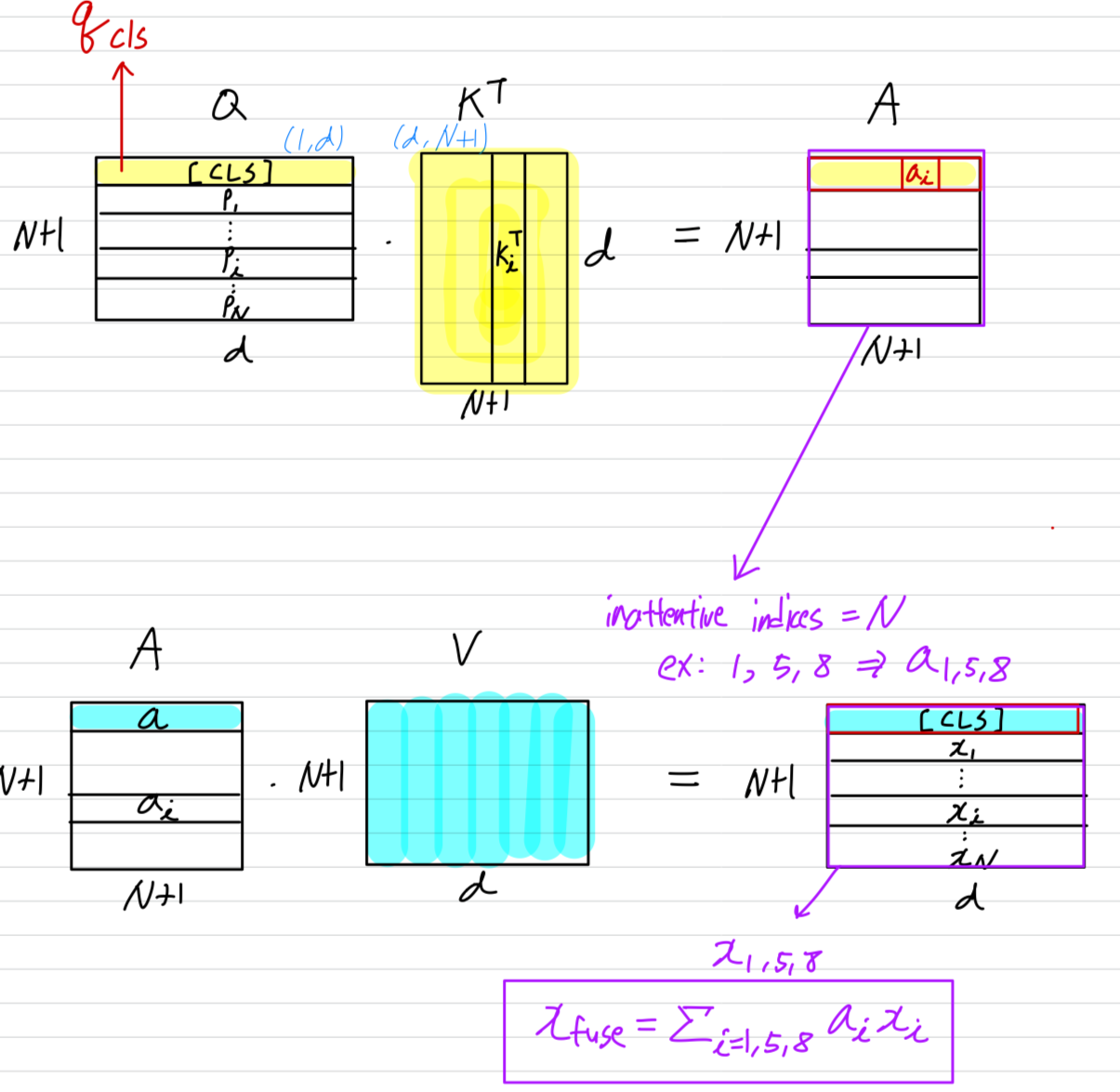
[CLS] token과 다른 tokens 사이의 interactions은 ViT encoders의 attention mechanism에 의해 수행된다 :
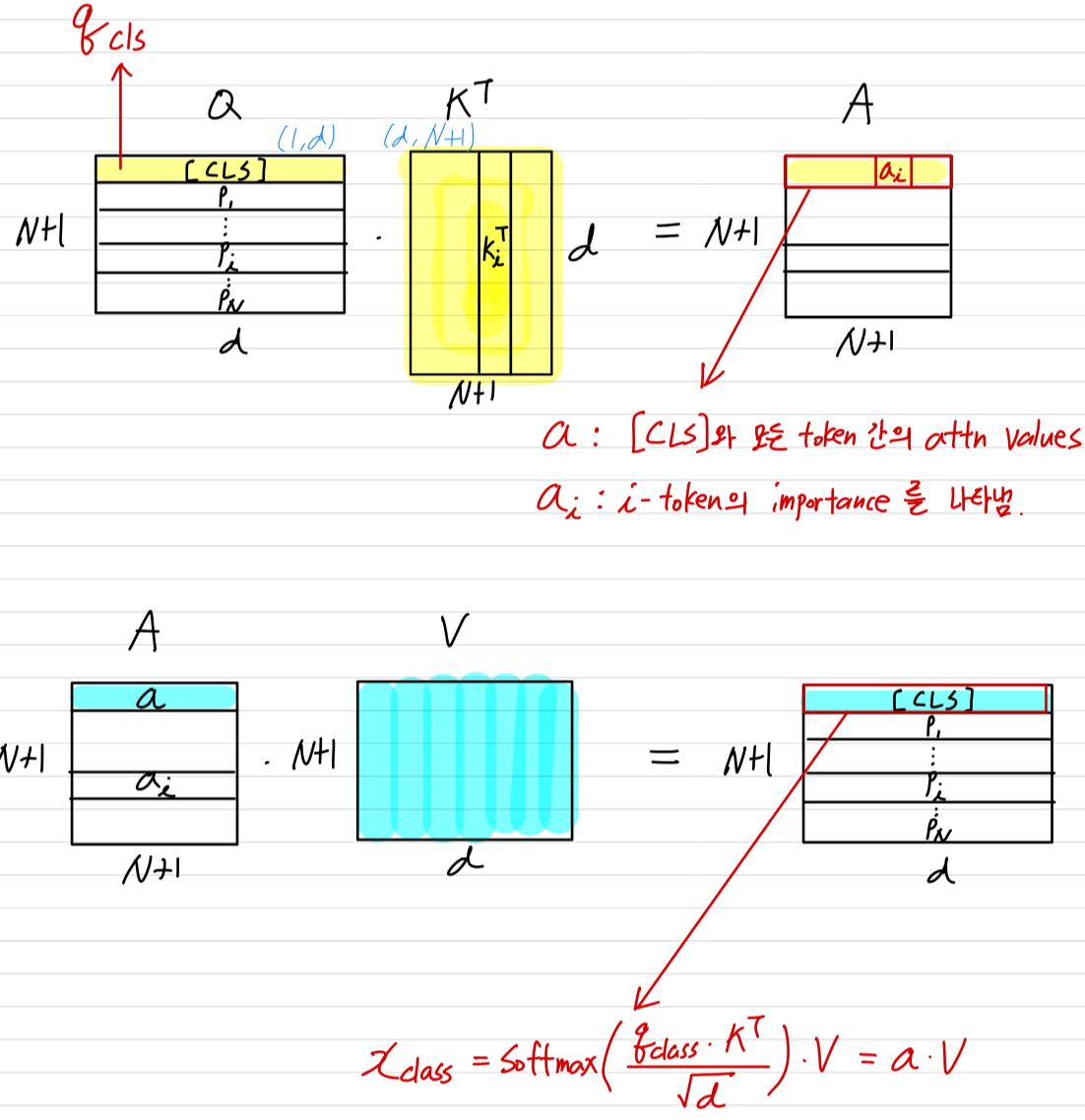
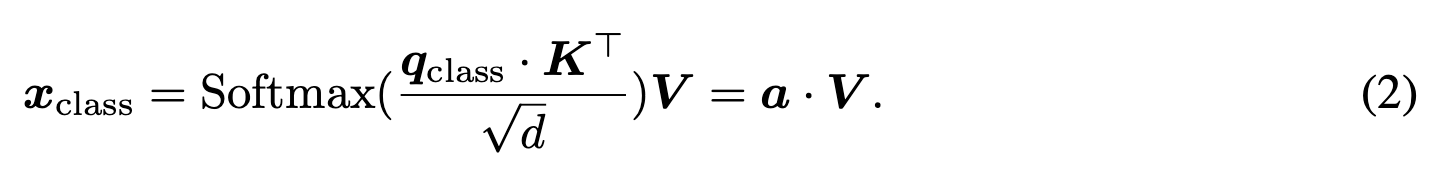 , K, and V는 각각 [CLS] query vector, Key matrix, and Vlaue matrix를 의미한다.
, K, and V는 각각 [CLS] query vector, Key matrix, and Vlaue matrix를 의미한다.
다시 말해, [CLS] token의 output 는 value vector 의 linear combination으로 표현되며, combination coefficients(Eq.2에서 로 표시된)는 [CLS]와 모든 tokens 간의 attention values이다.
는 -th token으로부터 오기 때문에, attention value (의 i-th entry)는 -th token이 linear combination을 통해 [CLS]의 output ()에 얼마나 반영되는지를 결정한다.
따라서 attention value 가 -th token의 importance를 나타낸다고 보는 것이 자연스럽다.
-
게다가 Caron et al. (2021)은 ViTs의 [CLS] token이 non-object regions의 tokens보다 class-specific tokens에 더 많은 attention을 기울인다는 것(즉, 더 큰 attention values를 갖는 것)을 보여줬다.
이를 바탕으로 우리는 [CLS] token이 다른 token에 대해 갖는 attention value를 사용하여 가장 중요한 token을 식별하는 방법을 제안한다.
이러한 논리에 기반해, ViT에서 계산을 줄이는 간단한 방법은 attention value가 가장 작은 token들을 제거하는 것이다.
그러나, 이러한 token을 직접 제거하면 classification accuracy가 심각하게 저하된다는 것을 Table 1에서 보여주고 있다.
 따라서 우리는 ViT training 과정에서 image token reorganization을 포함할 것 제안한다.
따라서 우리는 ViT training 과정에서 image token reorganization을 포함할 것 제안한다. -
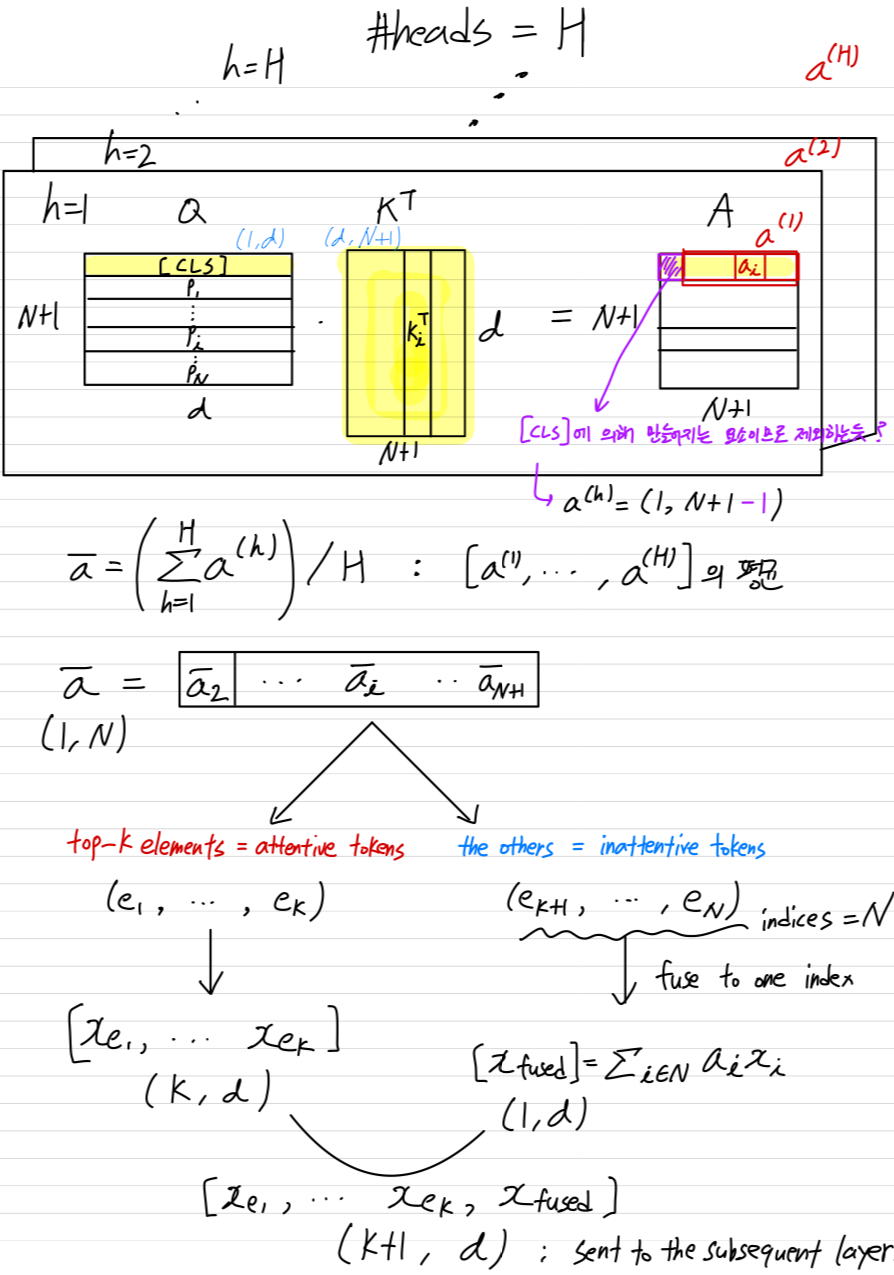
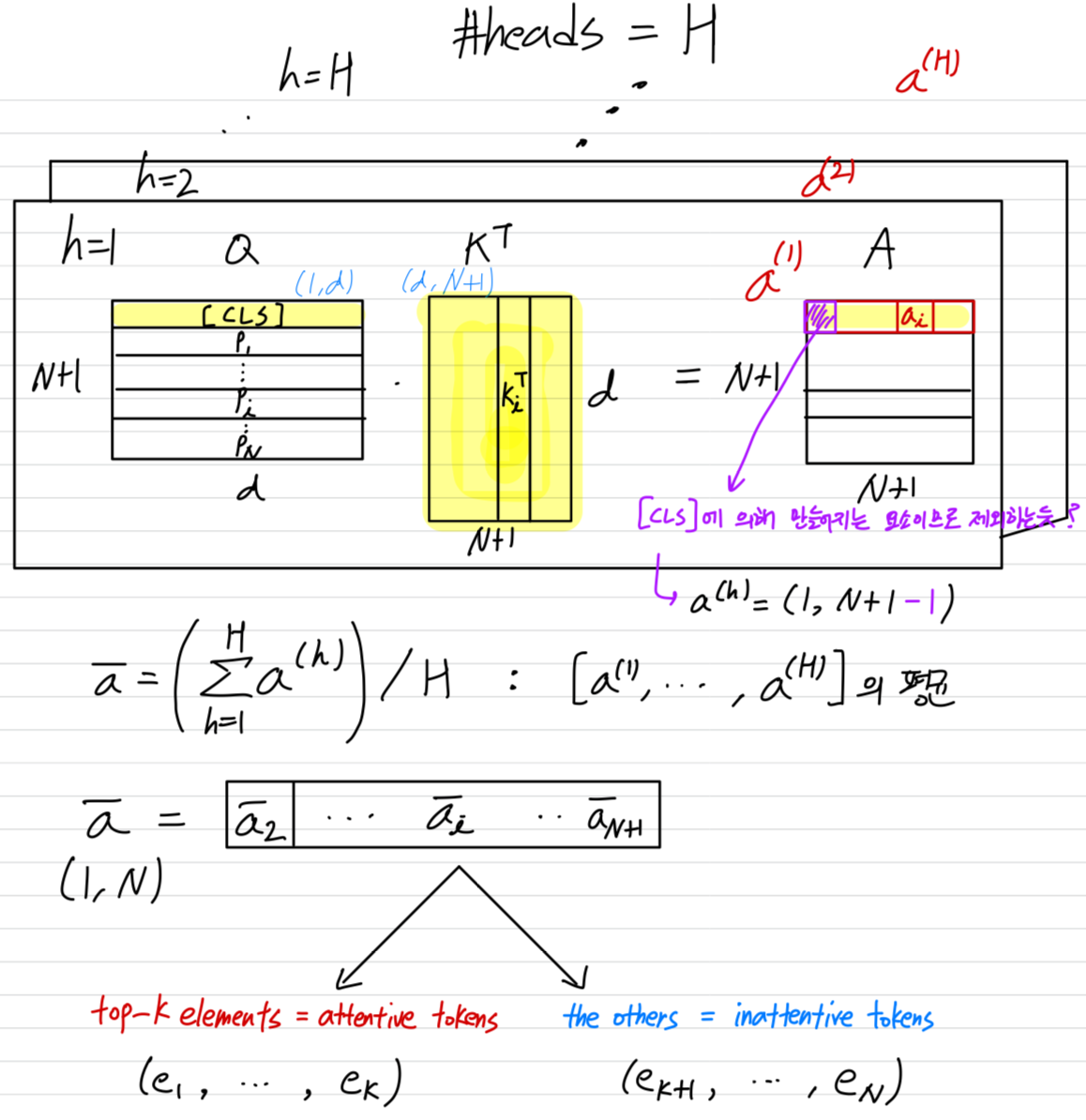
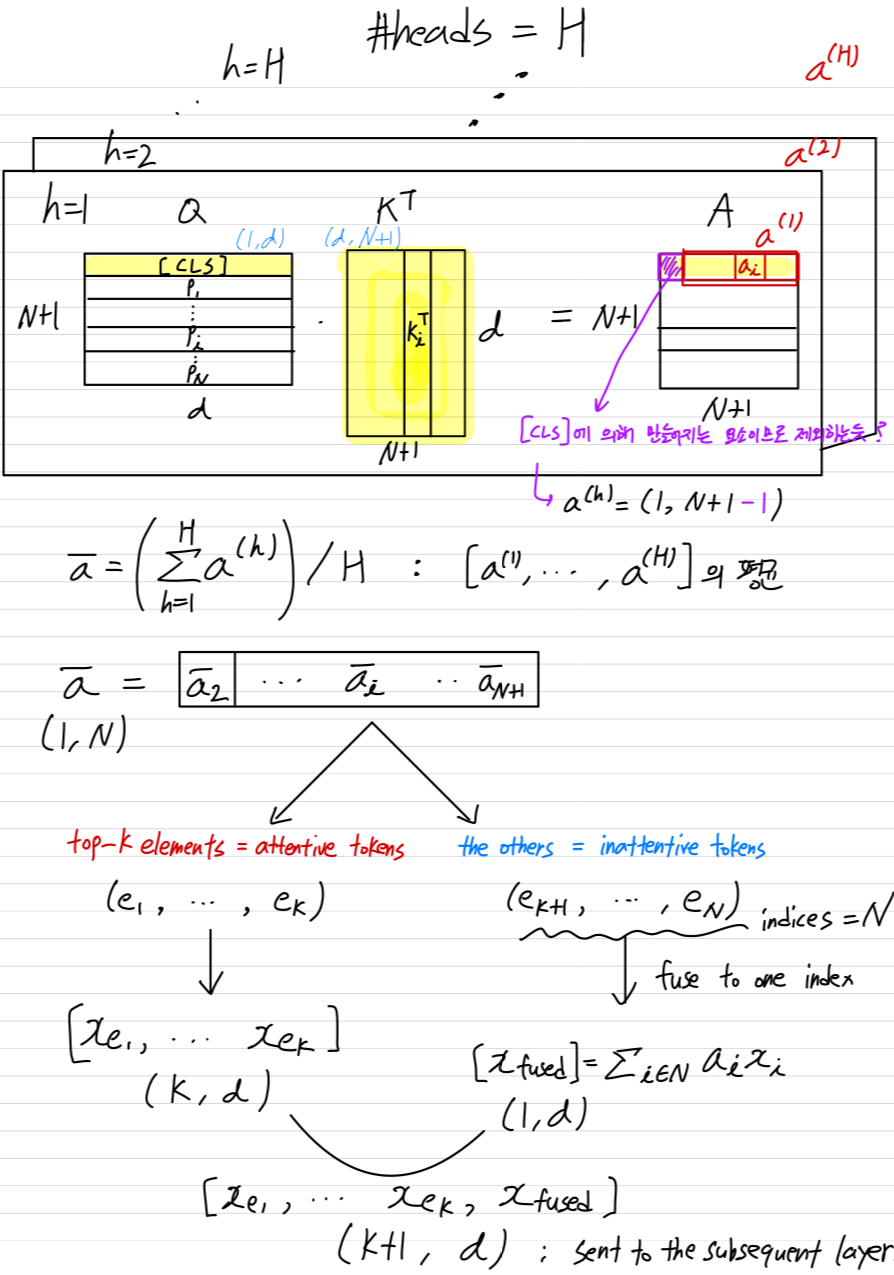
multi-head self-attention layer에서, 여러 head들이 Eq. 1을 병렬로 계산한다.
따라서, 여러 [CLS] attention vector 가 존재한다.
(여기서, , 는 총 attention heads의 개수이다.)
모든 head의 average attentiveness value를 다음과 같이 계산한다.
➔
Figure 2에서 보여지듯이, 에서 개의 largest(top-) elements들을 선택하여 해당 token들을 유지하며, 이를 attentive tokens이라고 부른다.
(여기서 는 hyperparameter이다.
우리는 token keeping rate를 으로 정의한다.)
나머지 tokens(inattentive tokens)들은 하나의 새로운 token으로 합친다.
이 token fusion 과정은 다음 paragraph에서 자세히 설명한다.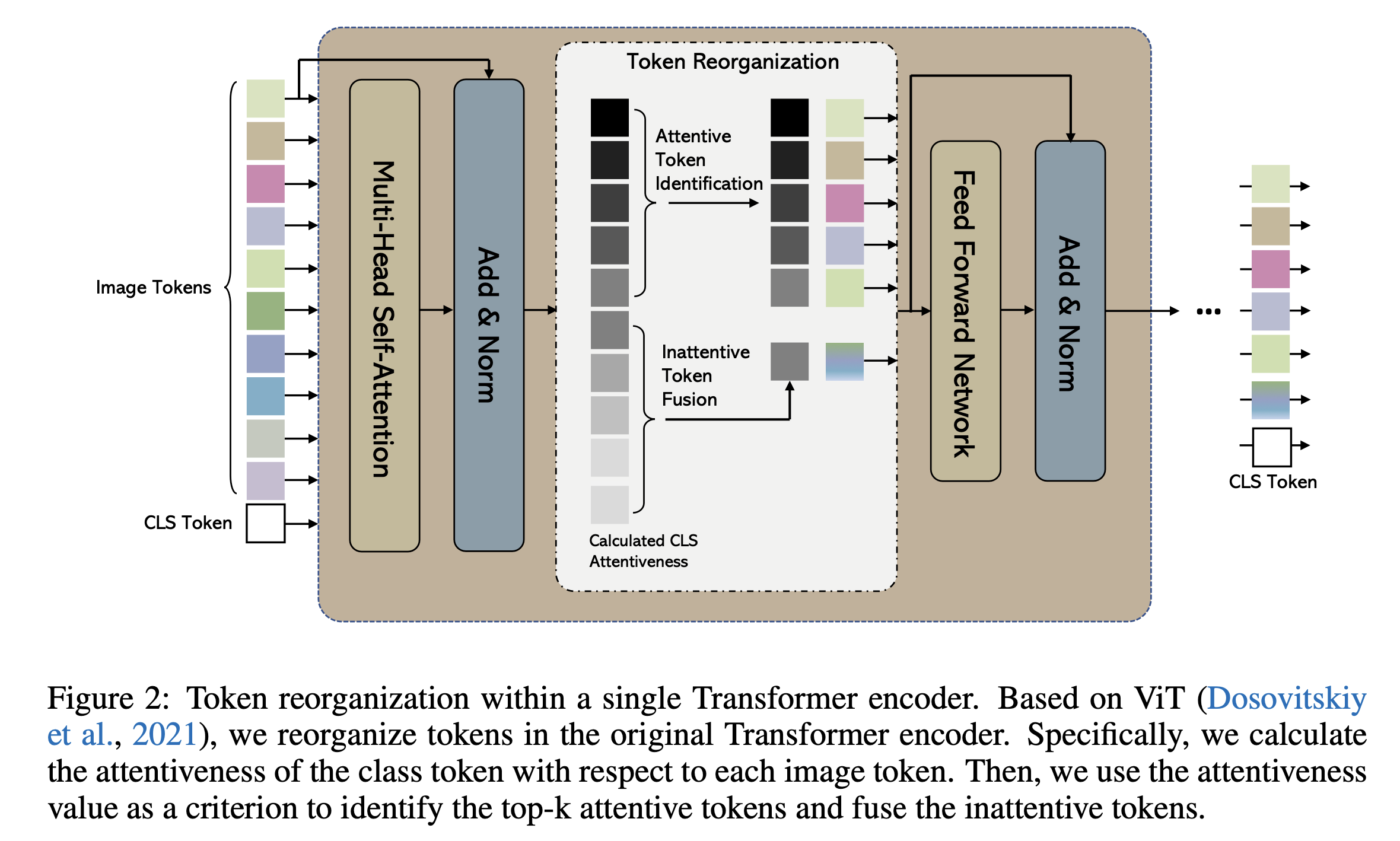
3.3 Inattentive token fusion
-
비록 images의 backgrounds에 대한 tokens들이 less informative하고 ViT model의 성능에 대단한 효과가 없어도,
그 tokens들은 여전히 prediction results에 큰 기여를 하고 있다.
다른 한편으로는, 일부 images의 경우 large objects가 images의 많은 부분을 차지할 수 있다.
따라서 ViT encoder에서 고정된 수의 token을 유지하도록 선택할 때, 이러한 object 부분에 해당하는 일부 token을 제거할 수 있으며,
이는 image recognition performance에 부정적 영향을 미칠 수 있다.
이러한 문제를 완화하기 위해, 우리는 현재 단계에서 inattentive tokens을 attentive tokens에 보완하기 위해 융합하는 방법을 제안한다.
inattentive token fusion은 inattentive tokens이 제공하는 정보를 더 많이 보존할 수 있도록 우리의 방법에 이점을 제공한다.
이는 Figure 2.에 설명되어 있다. -
구체적으로, the indices set of the inattentive tokens을 이라고 한다.
제안된 inattentive token fusion은 a weighted average operation으로, 다음과 같이 표현될 수 있다.
(아래 그림에서 inattentive indices 과 검은색 글씨로 써져있는 은 다름... 수정하기 귀찮아서 냅뒀음.)
 (내 생각인데... 이러면 값이 엄청 커지지 않나?)
(내 생각인데... 이러면 값이 엄청 커지지 않나?)
fused token 는 attentive tokens에 추가되어 다음 layer로 전달된다.
token fusion의 computation cost는 ViT의 대규모 computation과 비교하면 무시할 수 있다.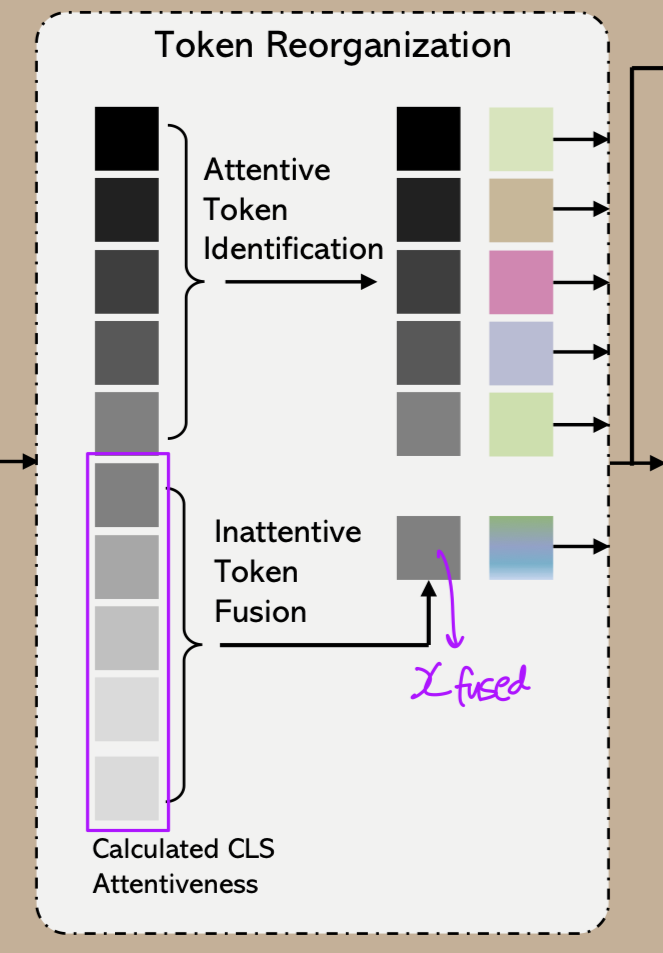
(My) Summary

3.4 Analysis
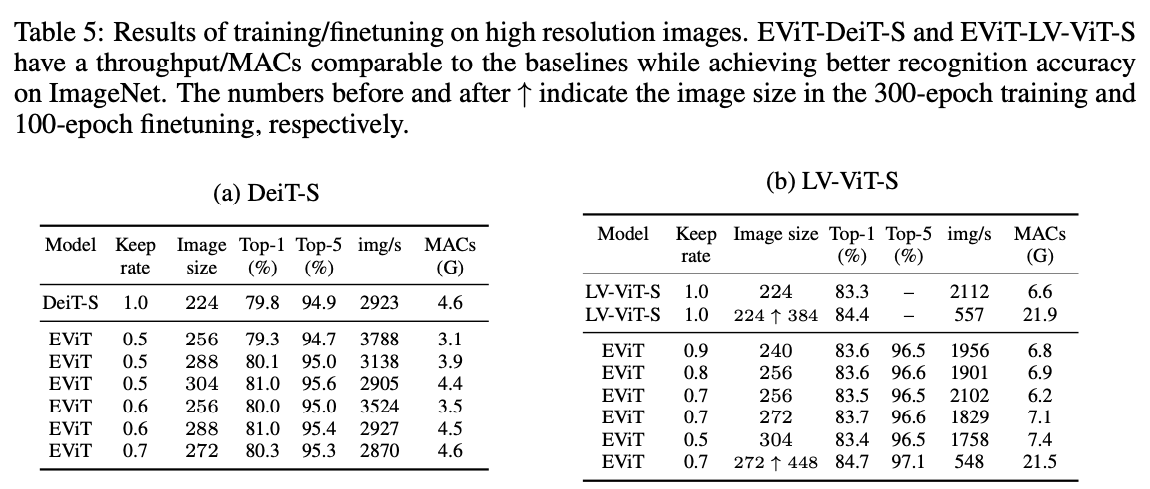
Training with higher resolution images.
- 우리 방법은 image token을 효율적으로 처리하기 때문에, EViT에 더 많은 token을 입력하면서도 computational cost를 기존 ViT와 같은 수준으로 유지할 수 있다.
더 많은 token을 얻는 간단한 방법은 input image를 higher resolution으로 크기를 조정하고 patch 크기는 그대로 유지하는 것이다.
이러한 high resolution image는 반드시 더 높은 resolution image에서 얻을 필요는 없다.
ImageNet에서 실험을 할 때, 우리는 단순히 표준 input image 크기 를 더 큰 spatial size()으로 bicubic interpolation을 통해 크기를 조정하여 high resolution image를 얻었다.
그런 다음, 이 고해상도 image를 더 많은 token으로 나눈다.
따라서 기존 ViT와 비교할 때, EViT는 training and infereence 과정에서 prediction results를 얻기 위해 image로부터 추가적인 정보를 사용하지 않는다.
Table 5에서 제안된 방법의 효과를 입증한다.
Visualization.
- EViT는 iamge에서 attention tokens을 식별하고 redundant 계산을 줄여 ViT를 가속화했다.
다양한 layer에서 시각화 결과는 network가 깊어질수록 inattentive token이 제거되고 attentive token이 유지되는 과정을 보여주며, EViT가 다양한 image background에 대해 효과적임을 입증한다.

4. Experiments
Implementation details.
5. Conclusion
- 이 논문에서는 token reorganization method를 제시한다.
class token으로부터 largest attention을 받는 token을 식별함으로써, 제안된 EViT는 다양한 visoin transformer model보다 accuracy와 efficiency 사이의 better trade-offs를 달성한다.
또한, less informative tokens을 하나의 새로운 token으로 병합하는 inattentive token fusion을 제안하며, 이 방법은 recognition accuracy와 training stability를 모두 향상시킨다.
제안된 EViT는 ViTs에 쉽게 적용할 수 있으며 추가적인 parameter를 필요로 하지 않으며, 복잡한 training strategies도 요구하지 않는다.
이 token reorganization method는 vision transformer acceleration을 위한 효과적인 방법으로 사용될 수 있다.
Github