(어떻게?) Adaptation 연구
Self-Hint를 성공적으로 개발했다고 가정.
즉, #objects를 잘 맞춘다고 가정.
#objects에 따라 adapation을 어디에, 어떻게 적용할 것인가?
어디에는 computational redundancy analysis글에서 연구할 것이다.
이 글에서는 어떻게에 해당하는 연구가 될 것이다.
Idea1 : 3-level
- coco detection train dataset을 살펴봤다.
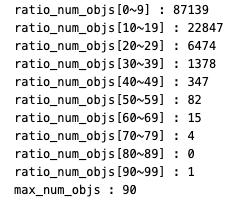
- 1-level : #objects 적음 (0~9)
- 2-level : #objects 평균 (10~29)
- 3-level : #objects 많음 (30~)
- 생각해볼 것 :
이 구간을 정하는 것으로 performance & efficiency trade-off에 대한 hyper parameter가 됨..
또한 이 구간을 정하는 것은 dataset domain에 따라 다르다는 것도 단점..

Efficient Deep Learning