(어디에?) Computational Redundancy Analysis about RT-DETR
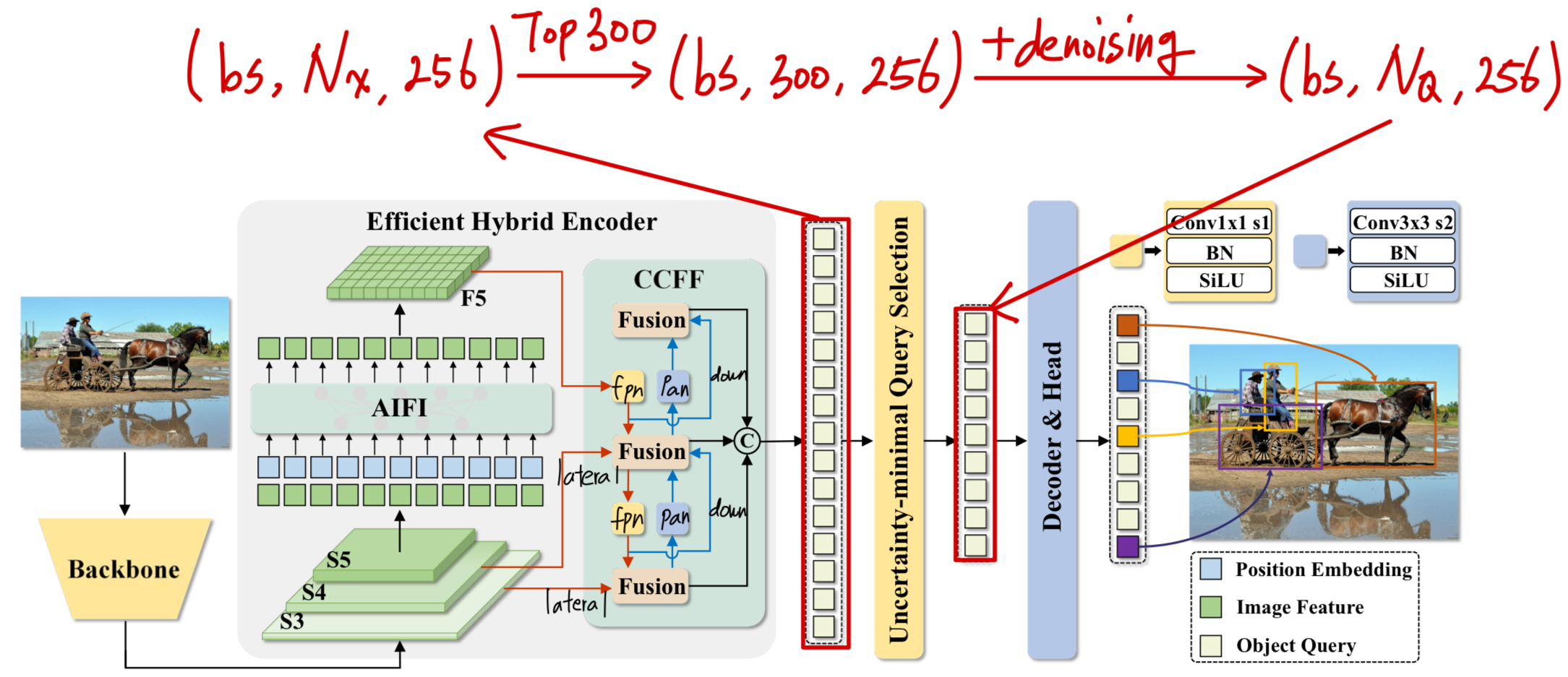
#objects에 따라 adapation을 어디에, 어떻게 적용할 것인가?
어디에는 이 글에서 연구할 것이다.
어떻게는 Adaptation 개발 글에서 연구가 될 것이다.
RT-DETR의 Data Flow 상세 분석
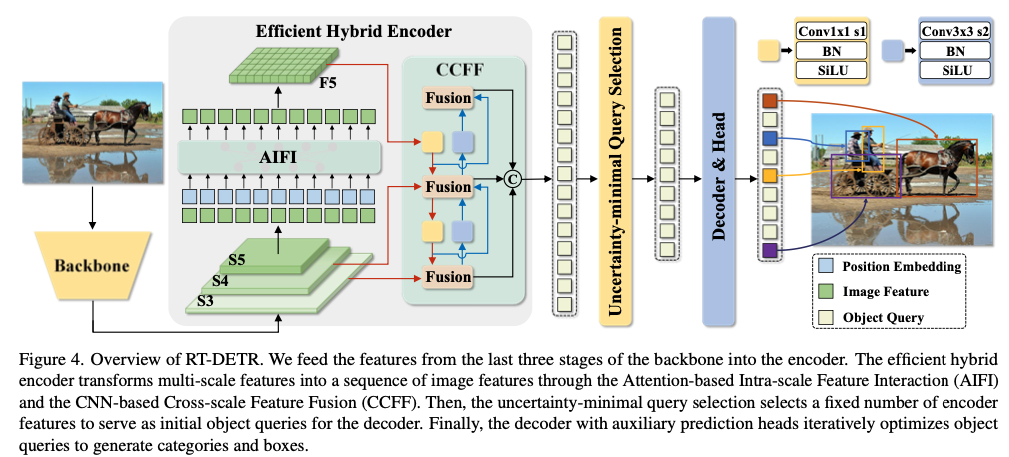
[raw image size]
x : torch.Size([1, 3, 640, 640])
[Backbone]
x[0] : torch.Size([1, 512, 80, 80])
x[1] : torch.Size([1, 1024, 40, 40])
x[2] : torch.Size([1, 2048, 20, 20])
[Encoder]
final fusion output : [torch.Size([1, 256, 80, 80]), torch.Size([1, 256, 40, 40]), torch.Size([1, 256, 20, 20])]
x[0] : torch.Size([1, 256, 80, 80])
x[1] : torch.Size([1, 256, 40, 40])
x[2] : torch.Size([1, 256, 20, 20])
[Decoder]
[get_encoder_input & input_proj]
proj_feats[0] : torch.Size([1, 256, 80, 80])
proj_feats[1] : torch.Size([1, 256, 40, 40])
proj_feats[2] : torch.Size([1, 256, 20, 20])
proj_feats[0] : torch.Size([1, 256, 80, 80])
feat_flatten[0] : torch.Size([1, 6400, 256])
spatial_shapes[0] : [80, 80]
level_start_index[0] : 6400
proj_feats[1] : torch.Size([1, 256, 40, 40])
feat_flatten[1] : torch.Size([1, 1600, 256])
spatial_shapes[1] : [40, 40]
level_start_index[1] : 8000
proj_feats[2] : torch.Size([1, 256, 20, 20])
feat_flatten[2] : torch.Size([1, 400, 256])
spatial_shapes[2] : [20, 20]
level_start_index[2] : 8400
init_ref_points_unact : tensor([[[-3.6636, -1.5506, -1.3863, -1.3863],
[-0.6466, -0.3795, -2.9444, -2.9444],
[-2.6061, -2.2687, -2.9444, -2.9444],
...,
[ 2.6061, -1.2730, -2.9444, -2.9444],
[-2.0043, -1.7845, -2.9444, -2.9444],
[ 0.4316, 0.5917, -2.9444, -2.9444]]], device='cuda:0')
reference_points_activation : tensor([[[0.0250, 0.1750, 0.2000, 0.2000],
[0.3438, 0.4063, 0.0500, 0.0500],
[0.0688, 0.0938, 0.0500, 0.0500],
...,
[0.9313, 0.2187, 0.0500, 0.0500],
[0.1187, 0.1438, 0.0500, 0.0500],
[0.6062, 0.6438, 0.0500, 0.0500]]], device='cuda:0')
[decoder layer 0 input] : torch.Size([1, 300, 256]) (object queries)
[self_attn]
q : tensor([[[-0.6376, -0.2872, 0.8715, ..., 0.3663, 0.2741, -0.1300],
[ 0.5430, 0.5057, 1.0871, ..., 0.1675, -0.5575, -0.2972],
[ 0.3979, 0.3384, 1.1335, ..., 0.0330, -0.9010, -0.2093],
...,
[ 0.6937, 0.4890, 0.9735, ..., 0.1117, -0.7265, -0.1495],
[ 0.4541, 0.6313, 1.0860, ..., -0.3480, -0.4247, -0.5664],
[ 0.4688, 0.6583, 1.2333, ..., 0.1352, -0.5471, -0.3343]]],
device='cuda:0')
k : tensor([[[-0.6376, -0.2872, 0.8715, ..., 0.3663, 0.2741, -0.1300],
[ 0.5430, 0.5057, 1.0871, ..., 0.1675, -0.5575, -0.2972],
[ 0.3979, 0.3384, 1.1335, ..., 0.0330, -0.9010, -0.2093],
...,
[ 0.6937, 0.4890, 0.9735, ..., 0.1117, -0.7265, -0.1495],
[ 0.4541, 0.6313, 1.0860, ..., -0.3480, -0.4247, -0.5664],
[ 0.4688, 0.6583, 1.2333, ..., 0.1352, -0.5471, -0.3343]]],
device='cuda:0')
value : tensor([[[-0.6799, -0.5388, 1.0170, ..., 0.1983, -0.0148, -0.7032],
[ 0.4599, 0.2719, 1.1969, ..., -0.0163, -0.8446, -0.9129],
[ 0.3567, 0.0848, 1.2800, ..., -0.1512, -1.2024, -0.7781],
...,
[ 0.5676, 0.2615, 1.0507, ..., -0.0698, -1.0082, -0.7658],
[ 0.4056, 0.3802, 1.2257, ..., -0.5330, -0.7231, -1.1433],
[ 0.3508, 0.4392, 1.3223, ..., -0.0535, -0.8287, -0.9826]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Key : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Value : torch.Size([1, 300, 256]) (encoder topk+a output)
self_attn output : torch.Size([1, 300, 256]) (next module query)
[cross_attn] MSDeformableAttention
Query : tensor([[[-1.2357, -0.9489, 0.5837, ..., 0.1697, 0.4410, -0.5152],
[-0.2184, -0.2316, 0.7594, ..., -0.0231, -0.3062, -0.7142],
[-0.3161, -0.4044, 0.8371, ..., -0.1469, -0.6310, -0.5930],
...,
[-0.1194, -0.2395, 0.6276, ..., -0.0727, -0.4559, -0.5787],
[-0.2658, -0.1328, 0.7899, ..., -0.4920, -0.1992, -0.9234],
[-0.3150, -0.0791, 0.8750, ..., -0.0576, -0.2952, -0.7781]]],
device='cuda:0')
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
Value : tensor([[[-0.0080, -0.0019, 0.0016, ..., -0.0390, -0.0016, -0.0138],
[-0.0007, 0.0213, 0.0012, ..., -0.0024, -0.0160, 0.0153],
[ 0.0078, 0.0235, -0.0179, ..., -0.0082, -0.0168, -0.0031],
...,
[-0.0325, 0.0227, 0.0153, ..., -0.0163, 0.0334, 0.0560],
[-0.0283, 0.0429, 0.0040, ..., -0.0286, 0.0321, 0.0444],
[-0.0228, 0.0577, -0.0137, ..., -0.0412, 0.0595, 0.0500]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (cross-attn input)
reference_points : torch.Size([1, 300, 1, 4])
Value : torch.Size([1, 8400, 256]) (encoder output)
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
cross_attn output : torch.Size([1, 300, 256]) (next module query)
[ffn]
ffn output : torch.Size([1, 300, 256])
[decoder layer 0 output] : torch.Size([1, 300, 256]) (next decoder layer input)
[decoder layer 1 input] : torch.Size([1, 300, 256]) (object queries)
[self_attn]
q : tensor([[[-1.0534, -0.1576, 0.8183, ..., 0.5421, 0.6120, -0.2228],
[-0.0824, 0.2819, 0.7169, ..., 0.3269, 0.1855, -0.3673],
[-0.2725, 0.1208, 0.7732, ..., 0.2236, -0.1261, -0.2192],
...,
[-0.0058, 0.1630, 0.6198, ..., 0.2619, 0.0187, -0.2100],
[-0.1832, 0.3805, 0.7290, ..., -0.0601, 0.2233, -0.5759],
[-0.1865, 0.3819, 0.8306, ..., 0.3279, 0.1635, -0.4061]]],
device='cuda:0')
k : tensor([[[-1.0534, -0.1576, 0.8183, ..., 0.5421, 0.6120, -0.2228],
[-0.0824, 0.2819, 0.7169, ..., 0.3269, 0.1855, -0.3673],
[-0.2725, 0.1208, 0.7732, ..., 0.2236, -0.1261, -0.2192],
...,
[-0.0058, 0.1630, 0.6198, ..., 0.2619, 0.0187, -0.2100],
[-0.1832, 0.3805, 0.7290, ..., -0.0601, 0.2233, -0.5759],
[-0.1865, 0.3819, 0.8306, ..., 0.3279, 0.1635, -0.4061]]],
device='cuda:0')
value : tensor([[[-1.0957, -0.4091, 0.9639, ..., 0.3741, 0.3231, -0.7960],
[-0.1655, 0.0481, 0.8267, ..., 0.1430, -0.1016, -0.9831],
[-0.3137, -0.1328, 0.9197, ..., 0.0394, -0.4275, -0.7880],
...,
[-0.1319, -0.0645, 0.6970, ..., 0.0804, -0.2630, -0.8264],
[-0.2318, 0.1293, 0.8687, ..., -0.2451, -0.0751, -1.1528],
[-0.3044, 0.1628, 0.9196, ..., 0.1392, -0.1182, -1.0544]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Key : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Value : torch.Size([1, 300, 256]) (encoder topk+a output)
self_attn output : torch.Size([1, 300, 256]) (next module query)
[cross_attn] MSDeformableAttention
Query : tensor([[[-1.3829, -0.6323, 0.4261, ..., 0.4616, 0.5959, -0.7756],
[-0.6279, -0.2632, 0.3209, ..., 0.2757, 0.2494, -0.9365],
[-0.7501, -0.4127, 0.3957, ..., 0.1900, -0.0156, -0.7763],
...,
[-0.6003, -0.3559, 0.2162, ..., 0.2232, 0.1165, -0.8078],
[-0.6819, -0.1964, 0.3596, ..., -0.0443, 0.2709, -1.0793],
[-0.7433, -0.1694, 0.4005, ..., 0.2725, 0.2345, -0.9992]]],
device='cuda:0')
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
Value : tensor([[[-0.0080, -0.0019, 0.0016, ..., -0.0390, -0.0016, -0.0138],
[-0.0007, 0.0213, 0.0012, ..., -0.0024, -0.0160, 0.0153],
[ 0.0078, 0.0235, -0.0179, ..., -0.0082, -0.0168, -0.0031],
...,
[-0.0325, 0.0227, 0.0153, ..., -0.0163, 0.0334, 0.0560],
[-0.0283, 0.0429, 0.0040, ..., -0.0286, 0.0321, 0.0444],
[-0.0228, 0.0577, -0.0137, ..., -0.0412, 0.0595, 0.0500]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (cross-attn input)
reference_points : torch.Size([1, 300, 1, 4])
Value : torch.Size([1, 8400, 256]) (encoder output)
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
cross_attn output : torch.Size([1, 300, 256]) (next module query)
[ffn]
ffn output : torch.Size([1, 300, 256])
[decoder layer 1 output] : torch.Size([1, 300, 256]) (next decoder layer input)
[decoder layer 2 input] : torch.Size([1, 300, 256]) (object queries)
[self_attn]
q : tensor([[[-0.9493, -0.0141, 0.5664, ..., 0.8450, 0.8194, -0.3198],
[-0.3067, 0.1523, 0.3424, ..., 0.5464, 0.6858, -0.5335],
[-0.5126, 0.0472, 0.3662, ..., 0.5060, 0.4361, -0.3671],
...,
[-0.2849, -0.0103, 0.2802, ..., 0.5132, 0.5497, -0.3730],
[-0.4147, 0.2222, 0.3368, ..., 0.3175, 0.6896, -0.6704],
[-0.4095, 0.2201, 0.4100, ..., 0.6004, 0.6440, -0.5523]]],
device='cuda:0')
k : tensor([[[-0.9493, -0.0141, 0.5664, ..., 0.8450, 0.8194, -0.3198],
[-0.3067, 0.1523, 0.3424, ..., 0.5464, 0.6858, -0.5335],
[-0.5126, 0.0472, 0.3662, ..., 0.5060, 0.4361, -0.3671],
...,
[-0.2849, -0.0103, 0.2802, ..., 0.5132, 0.5497, -0.3730],
[-0.4147, 0.2222, 0.3368, ..., 0.3175, 0.6896, -0.6704],
[-0.4095, 0.2201, 0.4100, ..., 0.6004, 0.6440, -0.5523]]],
device='cuda:0')
value : tensor([[[-9.9153e-01, -2.6559e-01, 7.1198e-01, ..., 6.7697e-01,
5.3047e-01, -8.9305e-01],
[-3.8984e-01, -8.1521e-02, 4.5220e-01, ..., 3.6254e-01,
3.9871e-01, -1.1493e+00],
[-5.5375e-01, -2.0643e-01, 5.1277e-01, ..., 3.2175e-01,
1.3462e-01, -9.3594e-01],
...,
[-4.1096e-01, -2.3783e-01, 3.5742e-01, ..., 3.3168e-01,
2.6805e-01, -9.8932e-01],
[-4.6332e-01, -2.8981e-02, 4.7649e-01, ..., 1.3245e-01,
3.9113e-01, -1.2473e+00],
[-5.2750e-01, 9.3705e-04, 4.9907e-01, ..., 4.1172e-01,
3.6238e-01, -1.2006e+00]]], device='cuda:0')
Query : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Key : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Value : torch.Size([1, 300, 256]) (encoder topk+a output)
self_attn output : torch.Size([1, 300, 256]) (next module query)
[cross_attn] MSDeformableAttention
Query : tensor([[[-1.1082, -0.3943, 0.2149, ..., 0.8410, 0.5982, -0.9883],
[-0.6392, -0.2516, 0.0142, ..., 0.5971, 0.4961, -1.1924],
[-0.7663, -0.3494, 0.0609, ..., 0.5640, 0.2896, -1.0237],
...,
[-0.6557, -0.3746, -0.0592, ..., 0.5722, 0.3936, -1.0669],
[-0.6963, -0.2100, 0.0352, ..., 0.4162, 0.4905, -1.2720],
[-0.7487, -0.1875, 0.0524, ..., 0.6367, 0.4677, -1.2360]]],
device='cuda:0')
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
Value : tensor([[[-0.0080, -0.0019, 0.0016, ..., -0.0390, -0.0016, -0.0138],
[-0.0007, 0.0213, 0.0012, ..., -0.0024, -0.0160, 0.0153],
[ 0.0078, 0.0235, -0.0179, ..., -0.0082, -0.0168, -0.0031],
...,
[-0.0325, 0.0227, 0.0153, ..., -0.0163, 0.0334, 0.0560],
[-0.0283, 0.0429, 0.0040, ..., -0.0286, 0.0321, 0.0444],
[-0.0228, 0.0577, -0.0137, ..., -0.0412, 0.0595, 0.0500]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (cross-attn input)
reference_points : torch.Size([1, 300, 1, 4])
Value : torch.Size([1, 8400, 256]) (encoder output)
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
cross_attn output : torch.Size([1, 300, 256]) (next module query)
[ffn]
ffn output : torch.Size([1, 300, 256])
[decoder layer 2 output] : torch.Size([1, 300, 256]) (next decoder layer input)
[decoder layer 3 input] : torch.Size([1, 300, 256]) (object queries)
[self_attn]
q : tensor([[[-0.5768, 0.0943, 0.2483, ..., 1.0985, 0.8718, -0.3987],
[-0.2190, 0.0795, 0.0445, ..., 0.7793, 0.9075, -0.7209],
[-0.4217, 0.0304, 0.0222, ..., 0.7670, 0.7439, -0.5687],
...,
[-0.2281, -0.0910, 0.0108, ..., 0.7769, 0.8222, -0.5833],
[-0.3270, 0.1326, 0.0062, ..., 0.6428, 0.9147, -0.8018],
[-0.2868, 0.1272, 0.0709, ..., 0.8606, 0.8653, -0.7264]]],
device='cuda:0')
k : tensor([[[-0.5768, 0.0943, 0.2483, ..., 1.0985, 0.8718, -0.3987],
[-0.2190, 0.0795, 0.0445, ..., 0.7793, 0.9075, -0.7209],
[-0.4217, 0.0304, 0.0222, ..., 0.7670, 0.7439, -0.5687],
...,
[-0.2281, -0.0910, 0.0108, ..., 0.7769, 0.8222, -0.5833],
[-0.3270, 0.1326, 0.0062, ..., 0.6428, 0.9147, -0.8018],
[-0.2868, 0.1272, 0.0709, ..., 0.8606, 0.8653, -0.7264]]],
device='cuda:0')
value : tensor([[[-0.6191, -0.1572, 0.3939, ..., 0.9305, 0.5829, -0.9719],
[-0.3022, -0.1543, 0.1543, ..., 0.5954, 0.6204, -1.3367],
[-0.4629, -0.2232, 0.1688, ..., 0.5828, 0.4425, -1.1375],
...,
[-0.3541, -0.3185, 0.0880, ..., 0.5954, 0.5405, -1.1997],
[-0.3756, -0.1186, 0.1459, ..., 0.4578, 0.6163, -1.3787],
[-0.4048, -0.0919, 0.1600, ..., 0.6719, 0.5837, -1.3747]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Key : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Value : torch.Size([1, 300, 256]) (encoder topk+a output)
self_attn output : torch.Size([1, 300, 256]) (next module query)
[cross_attn] MSDeformableAttention
Query : tensor([[[-0.6523, -0.2546, 0.0016, ..., 1.1457, 0.4977, -1.0902],
[-0.4100, -0.2526, -0.1819, ..., 0.8892, 0.5276, -1.3725],
[-0.5328, -0.3054, -0.1707, ..., 0.8782, 0.3905, -1.2178],
...,
[-0.4498, -0.3793, -0.2324, ..., 0.8887, 0.4660, -1.2669],
[-0.4655, -0.2247, -0.1876, ..., 0.7826, 0.5243, -1.4055],
[-0.4894, -0.2050, -0.1771, ..., 0.9487, 0.4993, -1.4033]]],
device='cuda:0')
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
Value : tensor([[[-0.0080, -0.0019, 0.0016, ..., -0.0390, -0.0016, -0.0138],
[-0.0007, 0.0213, 0.0012, ..., -0.0024, -0.0160, 0.0153],
[ 0.0078, 0.0235, -0.0179, ..., -0.0082, -0.0168, -0.0031],
...,
[-0.0325, 0.0227, 0.0153, ..., -0.0163, 0.0334, 0.0560],
[-0.0283, 0.0429, 0.0040, ..., -0.0286, 0.0321, 0.0444],
[-0.0228, 0.0577, -0.0137, ..., -0.0412, 0.0595, 0.0500]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (cross-attn input)
reference_points : torch.Size([1, 300, 1, 4])
Value : torch.Size([1, 8400, 256]) (encoder output)
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
cross_attn output : torch.Size([1, 300, 256]) (next module query)
[ffn]
ffn output : torch.Size([1, 300, 256])
[decoder layer 3 output] : torch.Size([1, 300, 256]) (next decoder layer input)
[decoder layer 4 input] : torch.Size([1, 300, 256]) (object queries)
[self_attn]
q : tensor([[[-0.1952, 0.1167, -0.0453, ..., 1.2676, 0.7616, -0.4166],
[-0.0151, 0.0238, -0.1950, ..., 0.9693, 0.8983, -0.8072],
[-0.2055, 0.0088, -0.2512, ..., 0.9704, 0.7939, -0.6789],
...,
[-0.0340, -0.1301, -0.1900, ..., 0.9898, 0.8497, -0.7030],
[-0.1067, 0.0651, -0.2480, ..., 0.8861, 0.9292, -0.8621],
[-0.0566, 0.0567, -0.1828, ..., 1.0550, 0.8603, -0.8123]]],
device='cuda:0')
k : tensor([[[-0.1952, 0.1167, -0.0453, ..., 1.2676, 0.7616, -0.4166],
[-0.0151, 0.0238, -0.1950, ..., 0.9693, 0.8983, -0.8072],
[-0.2055, 0.0088, -0.2512, ..., 0.9704, 0.7939, -0.6789],
...,
[-0.0340, -0.1301, -0.1900, ..., 0.9898, 0.8497, -0.7030],
[-0.1067, 0.0651, -0.2480, ..., 0.8861, 0.9292, -0.8621],
[-0.0566, 0.0567, -0.1828, ..., 1.0550, 0.8603, -0.8123]]],
device='cuda:0')
value : tensor([[[-0.2375, -0.1348, 0.1002, ..., 1.0996, 0.4727, -0.9898],
[-0.0982, -0.2100, -0.0852, ..., 0.7855, 0.6112, -1.4229],
[-0.2467, -0.2448, -0.1047, ..., 0.7861, 0.4925, -1.2477],
...,
[-0.1600, -0.3576, -0.1128, ..., 0.8083, 0.5680, -1.3194],
[-0.1553, -0.1861, -0.1083, ..., 0.7011, 0.6308, -1.4390],
[-0.1746, -0.1624, -0.0938, ..., 0.8663, 0.5787, -1.4607]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Key : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Value : torch.Size([1, 300, 256]) (encoder topk+a output)
self_attn output : torch.Size([1, 300, 256]) (next module query)
[cross_attn] MSDeformableAttention
Query : tensor([[[-0.2049, -0.2183, -0.1691, ..., 1.3476, 0.2892, -1.0786],
[-0.0996, -0.2757, -0.3107, ..., 1.1093, 0.3958, -1.4114],
[-0.2128, -0.3023, -0.3255, ..., 1.1094, 0.3051, -1.2771],
...,
[-0.1468, -0.3887, -0.3316, ..., 1.1269, 0.3629, -1.3326],
[-0.1426, -0.2571, -0.3279, ..., 1.0440, 0.4105, -1.4232],
[-0.1580, -0.2396, -0.3171, ..., 1.1713, 0.3709, -1.4406]]],
device='cuda:0')
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
Value : tensor([[[-0.0080, -0.0019, 0.0016, ..., -0.0390, -0.0016, -0.0138],
[-0.0007, 0.0213, 0.0012, ..., -0.0024, -0.0160, 0.0153],
[ 0.0078, 0.0235, -0.0179, ..., -0.0082, -0.0168, -0.0031],
...,
[-0.0325, 0.0227, 0.0153, ..., -0.0163, 0.0334, 0.0560],
[-0.0283, 0.0429, 0.0040, ..., -0.0286, 0.0321, 0.0444],
[-0.0228, 0.0577, -0.0137, ..., -0.0412, 0.0595, 0.0500]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (cross-attn input)
reference_points : torch.Size([1, 300, 1, 4])
Value : torch.Size([1, 8400, 256]) (encoder output)
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
cross_attn output : torch.Size([1, 300, 256]) (next module query)
[ffn]
ffn output : torch.Size([1, 300, 256])
[decoder layer 4 output] : torch.Size([1, 300, 256]) (next decoder layer input)
[decoder layer 5 input] : torch.Size([1, 300, 256]) (object queries)
[self_attn]
q : tensor([[[ 0.1554, 0.0477, -0.2533, ..., 1.3658, 0.5256, -0.3483],
[ 0.2287, -0.0469, -0.3343, ..., 1.1128, 0.6962, -0.7618],
[ 0.0527, -0.0463, -0.4089, ..., 1.1131, 0.6451, -0.6601],
...,
[ 0.2097, -0.1699, -0.3168, ..., 1.1465, 0.6849, -0.6784],
[ 0.1555, -0.0015, -0.4001, ..., 1.0586, 0.7571, -0.8100],
[ 0.2016, -0.0196, -0.3386, ..., 1.1952, 0.6585, -0.7659]]],
device='cuda:0')
k : tensor([[[ 0.1554, 0.0477, -0.2533, ..., 1.3658, 0.5256, -0.3483],
[ 0.2287, -0.0469, -0.3343, ..., 1.1128, 0.6962, -0.7618],
[ 0.0527, -0.0463, -0.4089, ..., 1.1131, 0.6451, -0.6601],
...,
[ 0.2097, -0.1699, -0.3168, ..., 1.1465, 0.6849, -0.6784],
[ 0.1555, -0.0015, -0.4001, ..., 1.0586, 0.7571, -0.8100],
[ 0.2016, -0.0196, -0.3386, ..., 1.1952, 0.6585, -0.7659]]],
device='cuda:0')
value : tensor([[[ 0.1131, -0.2038, -0.1077, ..., 1.1978, 0.2367, -0.9215],
[ 0.1456, -0.2807, -0.2245, ..., 0.9289, 0.4091, -1.3776],
[ 0.0115, -0.2999, -0.2623, ..., 0.9289, 0.3436, -1.2289],
...,
[ 0.0837, -0.3974, -0.2396, ..., 0.9650, 0.4032, -1.2947],
[ 0.1069, -0.2527, -0.2604, ..., 0.8736, 0.4587, -1.3869],
[ 0.0836, -0.2387, -0.2496, ..., 1.0065, 0.3769, -1.4143]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Key : torch.Size([1, 300, 256]) (object queries embedded by query_pos_embed)
Value : torch.Size([1, 300, 256]) (encoder topk+a output)
self_attn output : torch.Size([1, 300, 256]) (next module query)
[cross_attn] MSDeformableAttention
Query : tensor([[[ 0.1976, -0.2605, -0.2567, ..., 1.4620, 0.0085, -0.9641],
[ 0.2221, -0.3193, -0.3461, ..., 1.2592, 0.1403, -1.3136],
[ 0.1199, -0.3340, -0.3750, ..., 1.2595, 0.0904, -1.2006],
...,
[ 0.1751, -0.4086, -0.3578, ..., 1.2876, 0.1359, -1.2513],
[ 0.1928, -0.2976, -0.3732, ..., 1.2162, 0.1780, -1.3202],
[ 0.1748, -0.2874, -0.3652, ..., 1.3184, 0.1156, -1.3416]]],
device='cuda:0')
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
Value : tensor([[[-0.0080, -0.0019, 0.0016, ..., -0.0390, -0.0016, -0.0138],
[-0.0007, 0.0213, 0.0012, ..., -0.0024, -0.0160, 0.0153],
[ 0.0078, 0.0235, -0.0179, ..., -0.0082, -0.0168, -0.0031],
...,
[-0.0325, 0.0227, 0.0153, ..., -0.0163, 0.0334, 0.0560],
[-0.0283, 0.0429, 0.0040, ..., -0.0286, 0.0321, 0.0444],
[-0.0228, 0.0577, -0.0137, ..., -0.0412, 0.0595, 0.0500]]],
device='cuda:0')
Query : torch.Size([1, 300, 256]) (cross-attn input)
reference_points : torch.Size([1, 300, 1, 4])
Value : torch.Size([1, 8400, 256]) (encoder output)
reference_points : tensor([[[[0.0250, 0.1750, 0.2000, 0.2000]],
[[0.3438, 0.4063, 0.0500, 0.0500]],
[[0.0688, 0.0938, 0.0500, 0.0500]],
...,
[[0.9313, 0.2187, 0.0500, 0.0500]],
[[0.1187, 0.1438, 0.0500, 0.0500]],
[[0.6062, 0.6438, 0.0500, 0.0500]]]], device='cuda:0')
cross_attn output : torch.Size([1, 300, 256]) (next module query)
[ffn]
ffn output : torch.Size([1, 300, 256])
[decoder layer 5 output] : torch.Size([1, 300, 256]) (next decoder layer input)
[Final Output]
pred_logits : torch.Size([1, 300, 80])
pred_boxes : torch.Size([1, 300, 4])RT-DETR의 Computational Cost
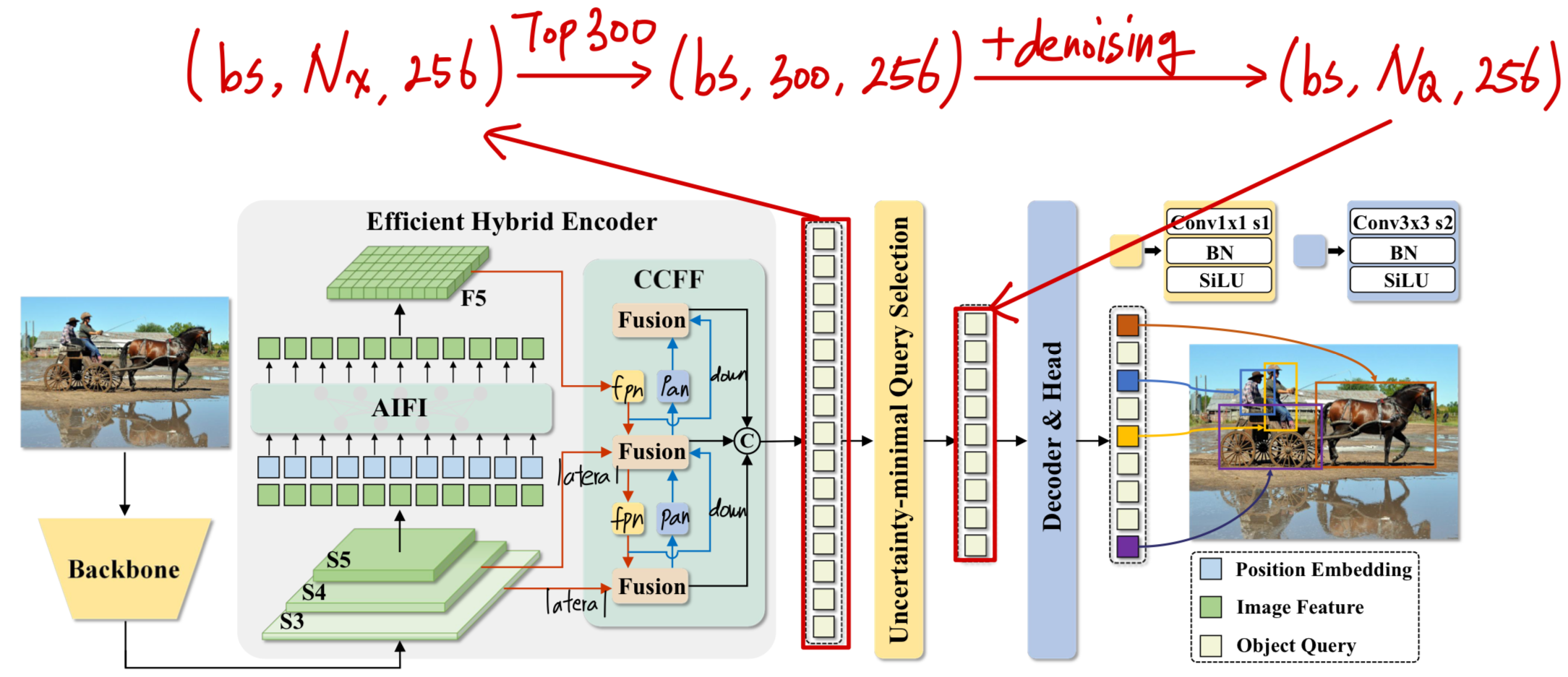
| module | #parameters or shape | #flops |
|:----------------------------------------|:-----------------------|:-----------|
| model | 42.891M | 68.984G |
| backbone | 23.474M | 35.321G |
| backbone.conv1 | 28.512K | 2.92G |
| backbone.conv1.conv1_1.conv | 0.864K | 88.474M |
| backbone.conv1.conv1_2.conv | 9.216K | 0.944G |
| backbone.conv1.conv1_3.conv | 18.432K | 1.887G |
| backbone.res_layers | 23.446M | 32.401G |
| backbone.res_layers.0.blocks | 0.213M | 5.453G |
| backbone.res_layers.1.blocks | 1.212M | 8.389G |
| backbone.res_layers.2.blocks | 7.078M | 11.954G |
| backbone.res_layers.3.blocks | 14.942M | 6.606G |
| decoder | 7.467M | 8.156G |
| decoder.input_proj | 0.198M | 0.555G |
| decoder.input_proj.0 | 66.048K | 0.423G |
| decoder.input_proj.1 | 66.048K | 0.106G |
| decoder.input_proj.2 | 66.048K | 26.419M |
| decoder.decoder.layers | 5.975M | 5.275G |
| decoder.decoder.layers.0 | 0.996M | 0.879G |
| decoder.decoder.layers.1 | 0.996M | 0.879G |
| decoder.decoder.layers.2 | 0.996M | 0.879G |
| decoder.decoder.layers.3 | 0.996M | 0.879G |
| decoder.decoder.layers.4 | 0.996M | 0.879G |
| decoder.decoder.layers.5 | 0.996M | 0.879G |
| decoder.denoising_class_embed | 20.736K | |
| decoder.denoising_class_embed.weight | (81, 256) | |
| decoder.query_pos_head.layers | 0.134M | 0.24G |
| decoder.query_pos_head.layers.0 | 2.56K | 3.686M |
| decoder.query_pos_head.layers.1 | 0.131M | 0.236G |
| decoder.enc_output | 66.304K | 0.561G |
| decoder.enc_output.0 | 65.792K | 0.551G |
| decoder.enc_output.1 | 0.512K | 10.752M |
| decoder.enc_score_head | 20.56K | 0.172G |
| decoder.enc_score_head.weight | (80, 256) | |
| decoder.enc_score_head.bias | (80,) | |
| decoder.enc_bbox_head.layers | 0.133M | 1.11G |
| decoder.enc_bbox_head.layers.0 | 65.792K | 0.551G |
| decoder.enc_bbox_head.layers.1 | 65.792K | 0.551G |
| decoder.enc_bbox_head.layers.2 | 1.028K | 8.602M |
| decoder.dec_score_head | 0.123M | 6.144M |
| decoder.dec_score_head.0 | 20.56K | |
| decoder.dec_score_head.1 | 20.56K | |
| decoder.dec_score_head.2 | 20.56K | |
| decoder.dec_score_head.3 | 20.56K | |
| decoder.dec_score_head.4 | 20.56K | |
| decoder.dec_score_head.5 | 20.56K | 6.144M |
| decoder.dec_bbox_head | 0.796M | 0.238G |
| decoder.dec_bbox_head.0.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.1.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.2.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.3.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.4.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.5.layers | 0.133M | 39.629M |
| encoder | 11.951M | 25.508G |
| encoder.input_proj | 0.919M | 1.472G |
| encoder.input_proj.0 | 0.132M | 0.842G |
| encoder.input_proj.1 | 0.263M | 0.42G |
| encoder.input_proj.2 | 0.525M | 0.21G |
| encoder.encoder.0.layers.0 | 0.79M | 0.398G |
| encoder.encoder.0.layers.0.self_attn | 0.263M | 0.187G |
| encoder.encoder.0.layers.0.linear1 | 0.263M | 0.105G |
| encoder.encoder.0.layers.0.linear2 | 0.262M | 0.105G |
| encoder.encoder.0.layers.0.norm1 | 0.512K | 0.512M |
| encoder.encoder.0.layers.0.norm2 | 0.512K | 0.512M |
| encoder.lateral_convs | 0.132M | 0.132G |
| encoder.lateral_convs.0 | 66.048K | 26.419M |
| encoder.lateral_convs.1 | 66.048K | 0.106G |
| encoder.fpn_blocks | 4.465M | 17.859G |
| encoder.fpn_blocks.0 | 2.232M | 3.572G |
| encoder.fpn_blocks.1 | 2.232M | 14.287G |
| encoder.downsample_convs | 1.181M | 1.181G |
| encoder.downsample_convs.0 | 0.59M | 0.945G |
| encoder.downsample_convs.1 | 0.59M | 0.236G |
| encoder.pan_blocks | 4.465M | 4.465G |
| encoder.pan_blocks.0 | 2.232M | 3.572G |
| encoder.pan_blocks.1 | 2.232M | 0.893G |#decoder_layers
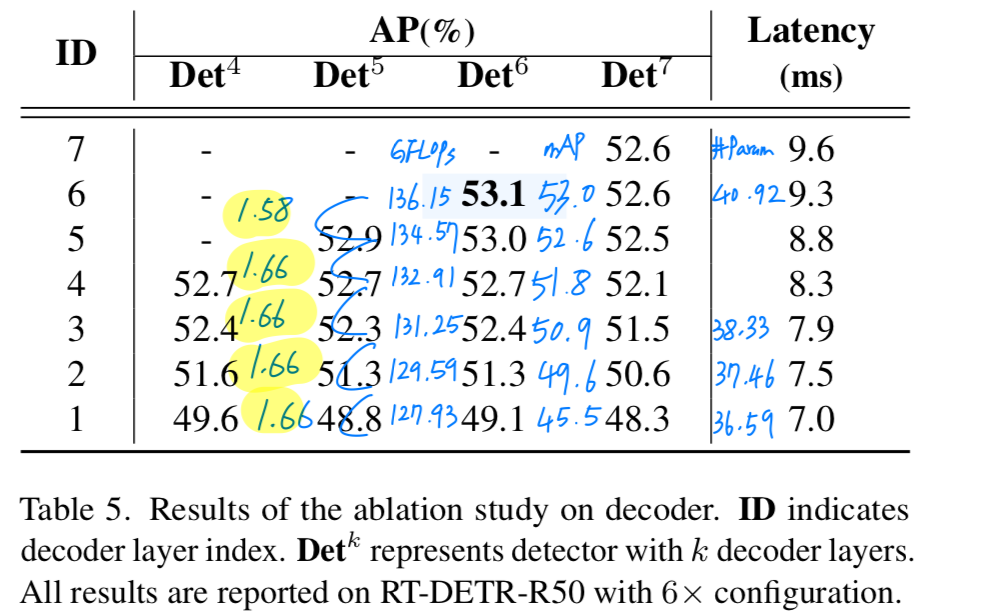
layer 6개 사용 (default)
6개 사용: (#Mparams, #GFLOPs, mAP) = (42.891, 137.968, 53.0)
layer 4개 사용
- 6개 사용 : (#Mparams, #GFLOPs, mAP) = (42.891, 137.968, 53.0)
4개 사용: (#Mparams, #GFLOPs, mAP) = (42.891, 134.134, 51.8)
layer 2개 사용
- 6개 사용 : (#Mparams, #GFLOPs, mAP) = (42.891, 137.968, 53.0)
- 4개 사용 : (#Mparams, #GFLOPs, mAP) = (42.891, 134.134, 51.8)
2개 사용: (#Mparams, #GFLOPs, mAP) = (42.891, 130.3, 49.6)
이 중에서 decoder의 computational cost는 생각보다 매우 적다. ➡️ 16.312GFLOPs
16.312GFLOPs 중에서 (self-attn, MSDeformAttn, FFN)로 이루어진 layer 6개는 10.55GFLOPs이다.
이는 납득이 안될 정도로 적은 computational cost이다.
왜 decoder의 computational cost는 생각보다 적을까?
-
내 생각에는 MSDeformAttn이 매우 효율적이기 때문이라고 생각하는데... 추측일 뿐이다.
그래서 decoder의 computational cost에 대해서 자세히 탐구해보겠다. -
decoder의 computational cost를 자세히 파악하기 위해 decoder의 구조를 뜯어보자.
Decoder Data Flow 상세 분석
-
먼저
self-attn에서 사용되는 (Key = Query, Value)와
cross-attn에서 사용되는 (reference_points, Query, Value)에 대해서 살펴보자.

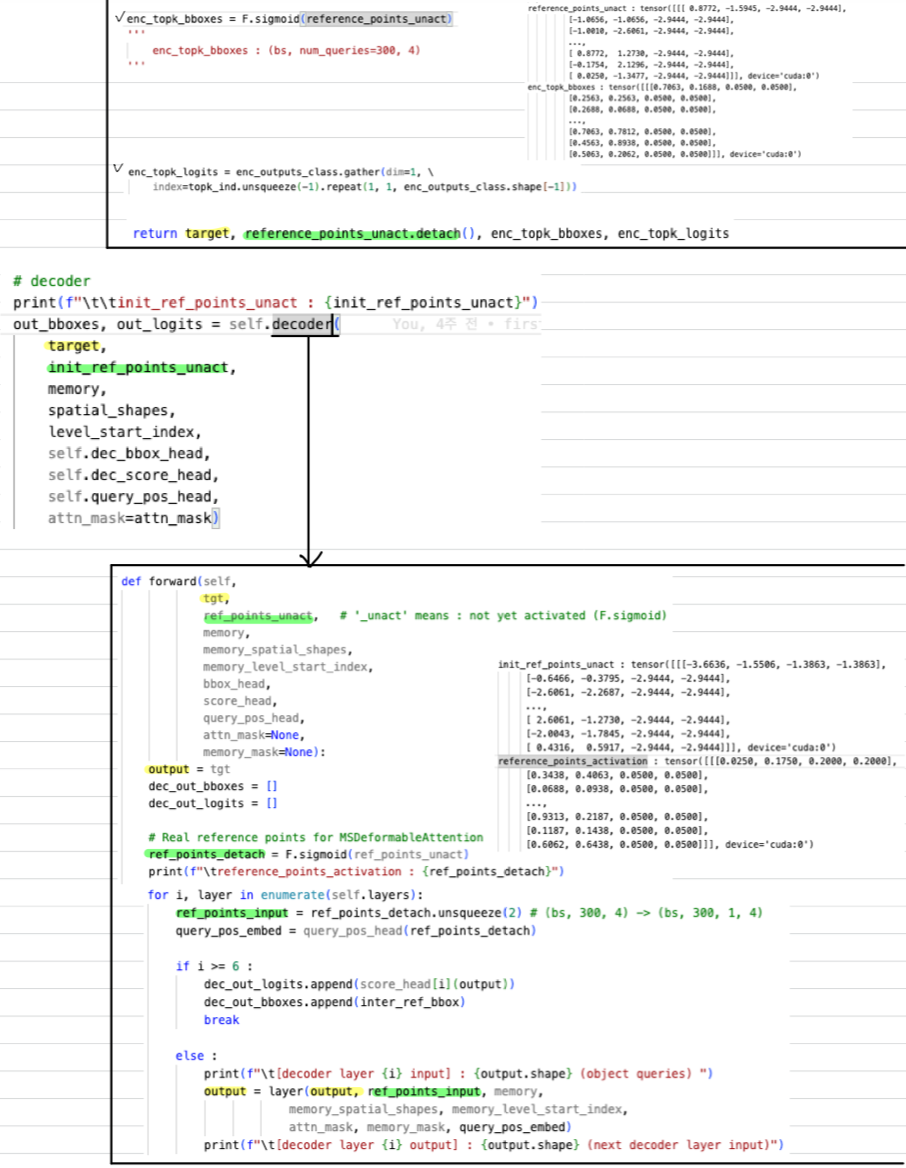
-
self-attn:- Key = Query

- Query = tgt(encoder topk) with self.with_pos_embed
- Value : tgt(encoder topk) without self.with_pos_embed
- Key = Query
-
MSDeformAttn:- reference_points : (encoder output의 topk개 bbox offset).unsqueeze(2)
(6개 layer의 모든 MSDeformAttn Value는 똑같은 Tensor)
- Query : self-attn output
- Value : encoder output,
(6개 layer의 모든 MSDeformAttn Value는 똑같은 Tensor)
- FFN :

- reference_points : (encoder output의 topk개 bbox offset).unsqueeze(2)
-
Decoder는 (self-attn, MSDeformableAttn, FFN)으로 구성된 layer가 6개 stack되어 있다.
각각의 구성 요소의 computational cost는 어떨까?- self-attn :
- MSDeformAttn :
- FFN :
#obj_queries in decoder
300(default), 200, 100, 50
- 300 : (42.891M, 137.968GFLOPs)
- 200 : (42.891M, 136.21GFLOPs)
- 100 : (42.891M, 134.572GFLOPs)
- 50 : (42.891M, 133.8GFLOPs)
object_queries 수를 줄이는 것은 효과적이지 않을 듯.
predicted #objs를 그대로 objec_queries에 adaptation하는 것보다는 비율에 맞게 적절히 정하는게 좋아 보임
(CCFF Depth 줄이기) RepVggBlock in Fusion Block
- Fusion Block 안에서 3개의 RepVggBlock이 stack되어있고, 이 부분에서 computation이 증가한다.
이를 두개 또는 한개만 사용했을 때의 performance & efficiency의 trade-off는?
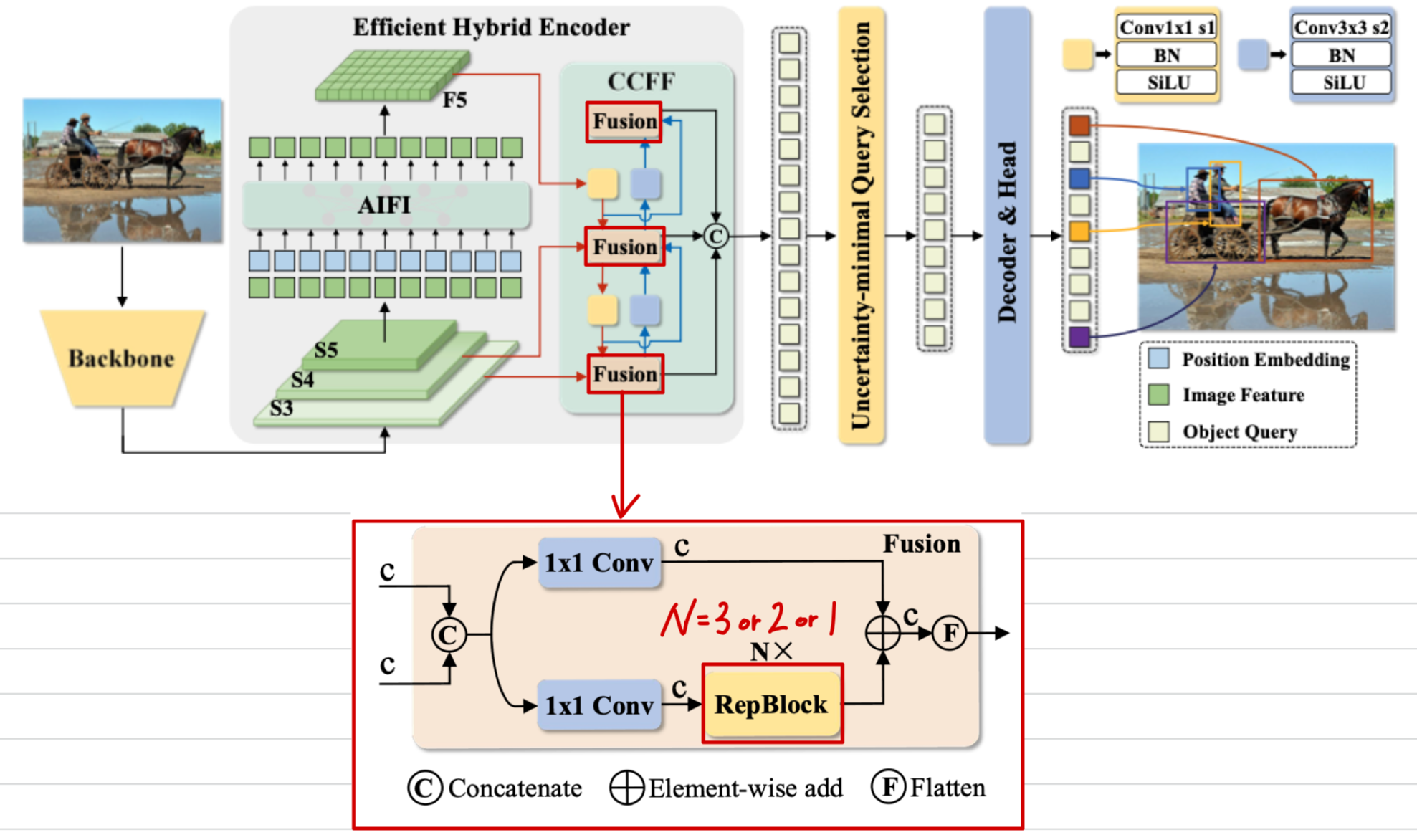
RepVggBlock 3개 사용 (default)
3개일 때: (#Mparams, #GFLOPs, mAP) =(42.891, 137.968, 53.0)
RepVggBlock 2개 사용
- 3개 사용 : (#Mparams, #GFLOPs, mAP) = (42.891, 137.968, 53.0)
2개 사용: (#Mparams, #GFLOPs, mAP) =(40.266, 124.842, 1.9)
| module | #parameters or shape | #flops |
|:----------------------------------------|:-----------------------|:-----------|
| model | 40.266M | 62.421G |
| backbone | 23.474M | 35.321G |
| backbone.conv1 | 28.512K | 2.92G |
| backbone.conv1.conv1_1.conv | 0.864K | 88.474M |
| backbone.conv1.conv1_2.conv | 9.216K | 0.944G |
| backbone.conv1.conv1_3.conv | 18.432K | 1.887G |
| backbone.res_layers | 23.446M | 32.401G |
| backbone.res_layers.0.blocks | 0.213M | 5.453G |
| backbone.res_layers.1.blocks | 1.212M | 8.389G |
| backbone.res_layers.2.blocks | 7.078M | 11.954G |
| backbone.res_layers.3.blocks | 14.942M | 6.606G |
| decoder | 7.467M | 8.156G |
| decoder.input_proj | 0.198M | 0.555G |
| decoder.input_proj.0 | 66.048K | 0.423G |
| decoder.input_proj.1 | 66.048K | 0.106G |
| decoder.input_proj.2 | 66.048K | 26.419M |
| decoder.decoder.layers | 5.975M | 5.275G |
| decoder.decoder.layers.0 | 0.996M | 0.879G |
| decoder.decoder.layers.1 | 0.996M | 0.879G |
| decoder.decoder.layers.2 | 0.996M | 0.879G |
| decoder.decoder.layers.3 | 0.996M | 0.879G |
| decoder.decoder.layers.4 | 0.996M | 0.879G |
| decoder.decoder.layers.5 | 0.996M | 0.879G |
| decoder.denoising_class_embed | 20.736K | |
| decoder.denoising_class_embed.weight | (81, 256) | |
| decoder.query_pos_head.layers | 0.134M | 0.24G |
| decoder.query_pos_head.layers.0 | 2.56K | 3.686M |
| decoder.query_pos_head.layers.1 | 0.131M | 0.236G |
| decoder.enc_output | 66.304K | 0.561G |
| decoder.enc_output.0 | 65.792K | 0.551G |
| decoder.enc_output.1 | 0.512K | 10.752M |
| decoder.enc_score_head | 20.56K | 0.172G |
| decoder.enc_score_head.weight | (80, 256) | |
| decoder.enc_score_head.bias | (80,) | |
| decoder.enc_bbox_head.layers | 0.133M | 1.11G |
| decoder.enc_bbox_head.layers.0 | 65.792K | 0.551G |
| decoder.enc_bbox_head.layers.1 | 65.792K | 0.551G |
| decoder.enc_bbox_head.layers.2 | 1.028K | 8.602M |
| decoder.dec_score_head | 0.123M | 6.144M |
| decoder.dec_score_head.0 | 20.56K | |
| decoder.dec_score_head.1 | 20.56K | |
| decoder.dec_score_head.2 | 20.56K | |
| decoder.dec_score_head.3 | 20.56K | |
| decoder.dec_score_head.4 | 20.56K | |
| decoder.dec_score_head.5 | 20.56K | 6.144M |
| decoder.dec_bbox_head | 0.796M | 0.238G |
| decoder.dec_bbox_head.0.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.1.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.2.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.3.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.4.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.5.layers | 0.133M | 39.629M |
| encoder | 9.325M | 18.944G |
| encoder.input_proj | 0.919M | 1.472G |
| encoder.input_proj.0 | 0.132M | 0.842G |
| encoder.input_proj.1 | 0.263M | 0.42G |
| encoder.input_proj.2 | 0.525M | 0.21G |
| encoder.encoder.0.layers.0 | 0.79M | 0.398G |
| encoder.encoder.0.layers.0.self_attn | 0.263M | 0.187G |
| encoder.encoder.0.layers.0.linear1 | 0.263M | 0.105G |
| encoder.encoder.0.layers.0.linear2 | 0.262M | 0.105G |
| encoder.encoder.0.layers.0.norm1 | 0.512K | 0.512M |
| encoder.encoder.0.layers.0.norm2 | 0.512K | 0.512M |
| encoder.lateral_convs | 0.132M | 0.132G |
| encoder.lateral_convs.0 | 66.048K | 26.419M |
| encoder.lateral_convs.1 | 66.048K | 0.106G |
| encoder.fpn_blocks | 3.152M | 12.607G |
| encoder.fpn_blocks.0 | 1.576M | 2.521G |
| encoder.fpn_blocks.1 | 1.576M | 10.086G |
| encoder.downsample_convs | 1.181M | 1.181G |
| encoder.downsample_convs.0 | 0.59M | 0.945G |
| encoder.downsample_convs.1 | 0.59M | 0.236G |
| encoder.pan_blocks | 3.152M | 3.152G |
| encoder.pan_blocks.0 | 1.576M | 2.521G |
| encoder.pan_blocks.1 | 1.576M | 0.63G |
RepVggBlock 1개 사용
- 3개 사용 : (#Mparams, #GFLOPs, mAP) = (42.891, 137.968, 53.0)
- 2개 사용 : (#Mparams, #GFLOPs, mAP) = (40.266, 124.842, 1.9)
1개 사용: (#Mparams, #GFLOPs, mAP) =(37.64, 111.714, 2.2)1개 사용: (#Mparams, #GFLOPs, mAP) =(37.64, 111.714, 52.1)(train 6x)
| module | #parameters or shape | #flops |
|:----------------------------------------|:-----------------------|:-----------|
| model | 37.64M | 55.857G |
| backbone | 23.474M | 35.321G |
| backbone.conv1 | 28.512K | 2.92G |
| backbone.conv1.conv1_1.conv | 0.864K | 88.474M |
| backbone.conv1.conv1_2.conv | 9.216K | 0.944G |
| backbone.conv1.conv1_3.conv | 18.432K | 1.887G |
| backbone.res_layers | 23.446M | 32.401G |
| backbone.res_layers.0.blocks | 0.213M | 5.453G |
| backbone.res_layers.1.blocks | 1.212M | 8.389G |
| backbone.res_layers.2.blocks | 7.078M | 11.954G |
| backbone.res_layers.3.blocks | 14.942M | 6.606G |
| decoder | 7.467M | 8.156G |
| decoder.input_proj | 0.198M | 0.555G |
| decoder.input_proj.0 | 66.048K | 0.423G |
| decoder.input_proj.1 | 66.048K | 0.106G |
| decoder.input_proj.2 | 66.048K | 26.419M |
| decoder.decoder.layers | 5.975M | 5.275G |
| decoder.decoder.layers.0 | 0.996M | 0.879G |
| decoder.decoder.layers.1 | 0.996M | 0.879G |
| decoder.decoder.layers.2 | 0.996M | 0.879G |
| decoder.decoder.layers.3 | 0.996M | 0.879G |
| decoder.decoder.layers.4 | 0.996M | 0.879G |
| decoder.decoder.layers.5 | 0.996M | 0.879G |
| decoder.denoising_class_embed | 20.736K | |
| decoder.denoising_class_embed.weight | (81, 256) | |
| decoder.query_pos_head.layers | 0.134M | 0.24G |
| decoder.query_pos_head.layers.0 | 2.56K | 3.686M |
| decoder.query_pos_head.layers.1 | 0.131M | 0.236G |
| decoder.enc_output | 66.304K | 0.561G |
| decoder.enc_output.0 | 65.792K | 0.551G |
| decoder.enc_output.1 | 0.512K | 10.752M |
| decoder.enc_score_head | 20.56K | 0.172G |
| decoder.enc_score_head.weight | (80, 256) | |
| decoder.enc_score_head.bias | (80,) | |
| decoder.enc_bbox_head.layers | 0.133M | 1.11G |
| decoder.enc_bbox_head.layers.0 | 65.792K | 0.551G |
| decoder.enc_bbox_head.layers.1 | 65.792K | 0.551G |
| decoder.enc_bbox_head.layers.2 | 1.028K | 8.602M |
| decoder.dec_score_head | 0.123M | 6.144M |
| decoder.dec_score_head.0 | 20.56K | |
| decoder.dec_score_head.1 | 20.56K | |
| decoder.dec_score_head.2 | 20.56K | |
| decoder.dec_score_head.3 | 20.56K | |
| decoder.dec_score_head.4 | 20.56K | |
| decoder.dec_score_head.5 | 20.56K | 6.144M |
| decoder.dec_bbox_head | 0.796M | 0.238G |
| decoder.dec_bbox_head.0.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.1.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.2.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.3.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.4.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.5.layers | 0.133M | 39.629M |
| encoder | 6.7M | 12.38G |
| encoder.input_proj | 0.919M | 1.472G |
| encoder.input_proj.0 | 0.132M | 0.842G |
| encoder.input_proj.1 | 0.263M | 0.42G |
| encoder.input_proj.2 | 0.525M | 0.21G |
| encoder.encoder.0.layers.0 | 0.79M | 0.398G |
| encoder.encoder.0.layers.0.self_attn | 0.263M | 0.187G |
| encoder.encoder.0.layers.0.linear1 | 0.263M | 0.105G |
| encoder.encoder.0.layers.0.linear2 | 0.262M | 0.105G |
| encoder.encoder.0.layers.0.norm1 | 0.512K | 0.512M |
| encoder.encoder.0.layers.0.norm2 | 0.512K | 0.512M |
| encoder.lateral_convs | 0.132M | 0.132G |
| encoder.lateral_convs.0 | 66.048K | 26.419M |
| encoder.lateral_convs.1 | 66.048K | 0.106G |
| encoder.fpn_blocks | 1.839M | 7.356G |
| encoder.fpn_blocks.0 | 0.92M | 1.471G |
| encoder.fpn_blocks.1 | 0.92M | 5.885G |
| encoder.downsample_convs | 1.181M | 1.181G |
| encoder.downsample_convs.0 | 0.59M | 0.945G |
| encoder.downsample_convs.1 | 0.59M | 0.236G |
| encoder.pan_blocks | 1.839M | 1.839G |
| encoder.pan_blocks.0 | 0.92M | 1.471G |
| encoder.pan_blocks.1 | 0.92M | 0.368G |
RepVggBlock은 decoder layer와 달리 retraining이 필요함.
RepVggBlock1 1x training
- baseline : (#Mparams, #GFLOPs, mAP) = (42.891, 137.968, 48.6)
RepVggBlock1: (#Mparams, #GFLOPs, mAP) =(37.64, 111.714, 47.4)
RepVggBlock1 6x training
- baseline : (#Mparams, #GFLOPs, mAP) = (42.891, 137.968, 53.0)
RepVggBlock1: (#Mparams, #GFLOPs, mAP) =(37.64, 111.714, 52.1)
(CCFF Width 줄이기) S_3 제외
-
resolution이 가장 큰 를 제외한다면 모든 computataion은 많이 줄어들 것이다.
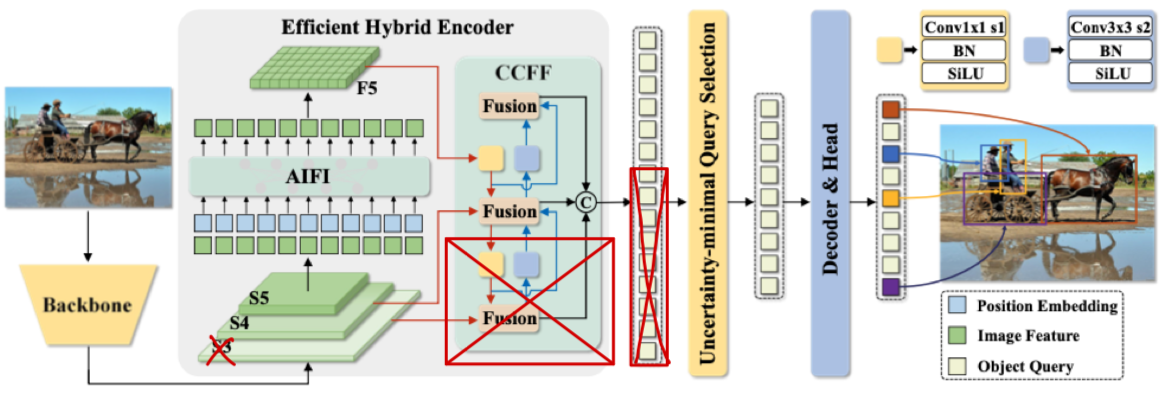 구체적으로 어디의 computation이 줄어드는가?
구체적으로 어디의 computation이 줄어드는가? -
baseline : (#Mparams, #GFLOPs, mAP) = (42.891, 137.968, 53.0)
Exclude_S3: (#Mparams, #GFLOPs, mAP) =(37.425, 89.674, ?)
| module | #parameters or shape | #flops |
|:----------------------------------------|:-----------------------|:-----------|
| model | 37.425M | 44.837G |
| backbone | 23.474M | 35.321G |
| backbone.conv1 | 28.512K | 2.92G |
| backbone.conv1.conv1_1.conv | 0.864K | 88.474M |
| backbone.conv1.conv1_2.conv | 9.216K | 0.944G |
| backbone.conv1.conv1_3.conv | 18.432K | 1.887G |
| backbone.res_layers | 23.446M | 32.401G |
| backbone.res_layers.0.blocks | 0.213M | 5.453G |
| backbone.res_layers.1.blocks | 1.212M | 8.389G |
| backbone.res_layers.2.blocks | 7.078M | 11.954G |
| backbone.res_layers.3.blocks | 14.942M | 6.606G |
| decoder | 7.252M | 3.761G |
| decoder.input_proj | 0.132M | 0.132G |
| decoder.input_proj.0 | 66.048K | 0.106G |
| decoder.input_proj.1 | 66.048K | 26.419M |
| decoder.decoder.layers | 5.827M | 2.707G |
| decoder.decoder.layers.0 | 0.971M | 0.451G |
| decoder.decoder.layers.1 | 0.971M | 0.451G |
| decoder.decoder.layers.2 | 0.971M | 0.451G |
| decoder.decoder.layers.3 | 0.971M | 0.451G |
| decoder.decoder.layers.4 | 0.971M | 0.451G |
| decoder.decoder.layers.5 | 0.971M | 0.451G |
| decoder.denoising_class_embed | 20.736K | |
| decoder.denoising_class_embed.weight | (81, 256) | |
| decoder.query_pos_head.layers | 0.134M | 0.24G |
| decoder.query_pos_head.layers.0 | 2.56K | 3.686M |
| decoder.query_pos_head.layers.1 | 0.131M | 0.236G |
| decoder.enc_output | 66.304K | 0.134G |
| decoder.enc_output.0 | 65.792K | 0.131G |
| decoder.enc_output.1 | 0.512K | 2.56M |
| decoder.enc_score_head | 20.56K | 40.96M |
| decoder.enc_score_head.weight | (80, 256) | |
| decoder.enc_score_head.bias | (80,) | |
| decoder.enc_bbox_head.layers | 0.133M | 0.264G |
| decoder.enc_bbox_head.layers.0 | 65.792K | 0.131G |
| decoder.enc_bbox_head.layers.1 | 65.792K | 0.131G |
| decoder.enc_bbox_head.layers.2 | 1.028K | 2.048M |
| decoder.dec_score_head | 0.123M | 6.144M |
| decoder.dec_score_head.0 | 20.56K | |
| decoder.dec_score_head.1 | 20.56K | |
| decoder.dec_score_head.2 | 20.56K | |
| decoder.dec_score_head.3 | 20.56K | |
| decoder.dec_score_head.4 | 20.56K | |
| decoder.dec_score_head.5 | 20.56K | 6.144M |
| decoder.dec_bbox_head | 0.796M | 0.238G |
| decoder.dec_bbox_head.0.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.1.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.2.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.3.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.4.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.5.layers | 0.133M | 39.629M |
| encoder | 6.698M | 5.755G |
| encoder.input_proj | 0.787M | 0.63G |
| encoder.input_proj.0 | 0.263M | 0.42G |
| encoder.input_proj.1 | 0.525M | 0.21G |
| encoder.encoder.0.layers.0 | 0.79M | 0.398G |
| encoder.encoder.0.layers.0.self_attn | 0.263M | 0.187G |
| encoder.encoder.0.layers.0.linear1 | 0.263M | 0.105G |
| encoder.encoder.0.layers.0.linear2 | 0.262M | 0.105G |
| encoder.encoder.0.layers.0.norm1 | 0.512K | 0.512M |
| encoder.encoder.0.layers.0.norm2 | 0.512K | 0.512M |
| encoder.lateral_convs.0 | 66.048K | 26.419M |
| encoder.lateral_convs.0.conv | 65.536K | 26.214M |
| encoder.lateral_convs.0.norm | 0.512K | 0.205M |
| encoder.fpn_blocks.0 | 2.232M | 3.572G |
| encoder.fpn_blocks.0.conv1 | 0.132M | 0.211G |
| encoder.fpn_blocks.0.conv2 | 0.132M | 0.211G |
| encoder.fpn_blocks.0.bottlenecks | 1.969M | 3.151G |
| encoder.downsample_convs.0 | 0.59M | 0.236G |
| encoder.downsample_convs.0.conv | 0.59M | 0.236G |
| encoder.downsample_convs.0.norm | 0.512K | 0.205M |
| encoder.pan_blocks.0 | 2.232M | 0.893G |
| encoder.pan_blocks.0.conv1 | 0.132M | 52.634M |
| encoder.pan_blocks.0.conv2 | 0.132M | 52.634M |
| encoder.pan_blocks.0.bottlenecks | 1.969M | 0.788G |
- 그리고 Fusion Block의 RepVggBlock을 3개에서 1개로 줄이는 것은 성능 하락 폭이 매우 클 것 같다. (실험 중)
(Depth) RepVggBlock & (Width) N_x 줄이기
- 는 encoder의 output length이다.
이 값은 decoder의 MSDeformAttn Block에서 Value로 사용하는데,
이 length를 줄여보자.
RepVggBlock1 & flatten(E_5)
flatten(E_4)
flatten(E_3)
concat(flatten(E_5), flatten(E_4))
- 는 resolution이 훨씬 크기 때문에 length가 길다.

