Self-Hint 연구

이전 post에 이어지는 내용....
이전 글 내용 간략히 설명
- 나는 RT-DETR의 efficiency를 더욱 극대화할 수 있도록,
RT-DETR 내의 computational redundancy를 찾고 해당 부분에 adaptation을 적용할 수 있는 방법을 연구할 것이다.
이에 대한 연구 아이디어로는 다음과 같다.RT-DETR의 computational redundancy 1 :
RT-DETR에서는 set prediction을 위해
COCO dataset에서 한 image에 나타날 수 있는 최대 object 개수를 decoder의 Object Quries Length로 설정했다.
(Object Queries = 300을 default로 설정한 이유이다)
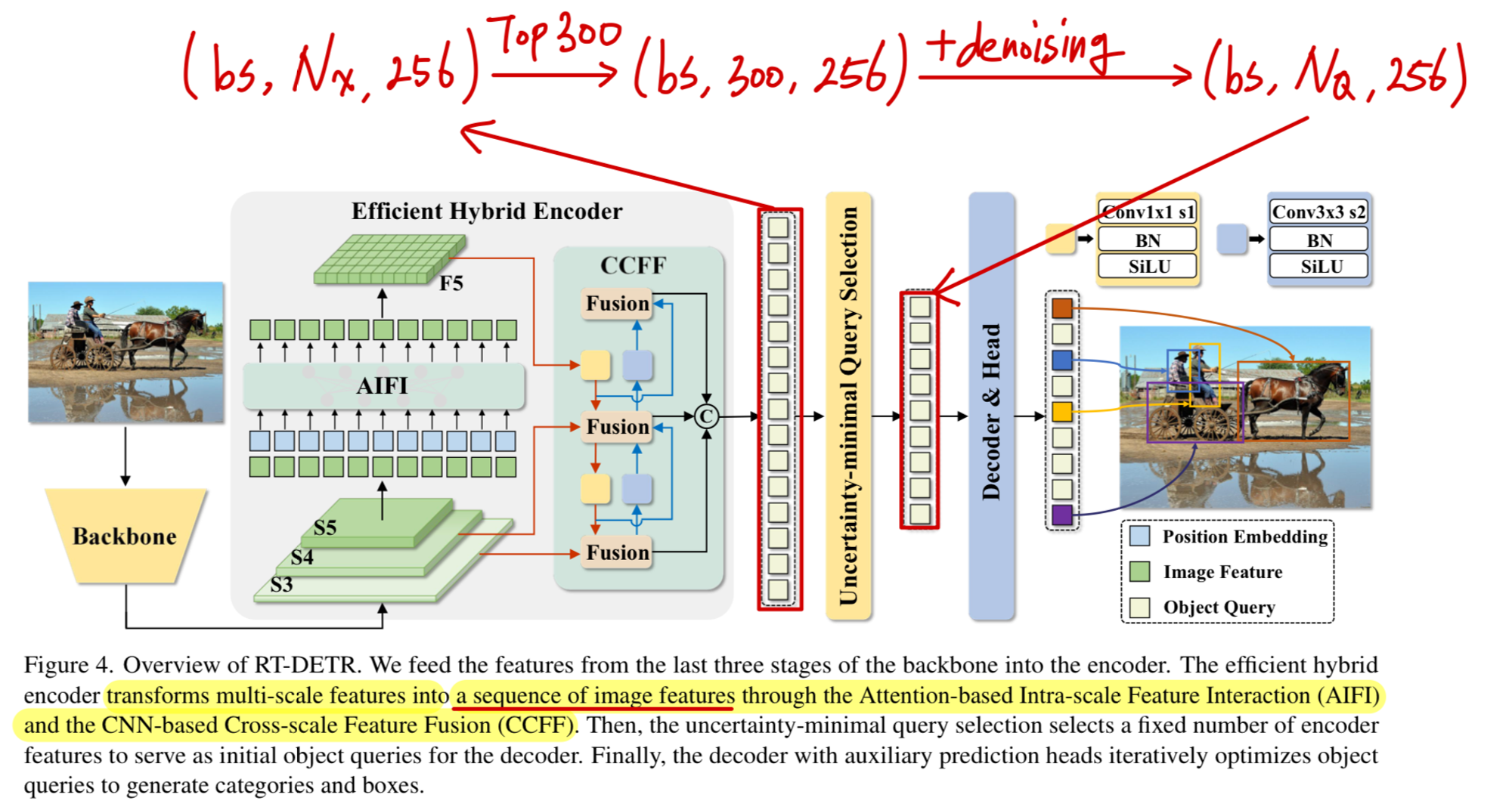 하지만 만약에 한 image에 object가 딱 1개 있는데 300개의 set prediction을 한다면,
하지만 만약에 한 image에 object가 딱 1개 있는데 300개의 set prediction을 한다면,
이는 꽤 많은 computational redundancy를 유발할 수 있다.RT-DETR의 computational redundancy 2 :
Encoder의 CCFF module은 RT-DETR 전체 GFLOPs의 34.26%를 차지할 정도로 큰 module인데,
이 이유는 Fusion block에 3개의 RepVggBlock이 stack되어 있기 때문이라고 추측하고 있다.
(GFLOPs 차지 비율은 더 조사해봐야 하지만, 분명 3개 layer가 stack되어 있기 때문에 redundancy는 존재할 것으로 판단된다)

RT-DETR의 computational redundancy 3 :
Decoder layer를 6개 사용하는 것은 redundancy가 될 수 있다.
재차 얘기하면,
Table 5.에서 Decoder layer를 6개가 아니라 더욱 줄여서 사용해도 큰 성능 하락이 없기 때문에
이를 효과적으로 활용할 수 있다면 RT-DETR의 efficiency를 증가시킬 수 있을 것이다.
hint 정보(= predicted #objs)를 갖고,
Fusion block과 decoder에 어떻게 adaptation을 적용할 것인지? Loss는 어떻게 구성해야 할지? 생각해봐야 함.
이 글에서는 hint 정보를 어떻게 prediction할 것인지에 대한 연구 내용을 다룸.
과연 #objs를 잘 예측할 수 있는가?
- #objs를 잘 예측하도록 학습이 가능한지를 살펴볼 것이다.
#objs를 예측하기 위한 새로운 sub-network를 연구해야 한다.
나는 두가지 idea를 갖고 실험을 해볼 것이다.
(1) backbone 또는 (2) Encoder(AIFI)에서 image-specific한 #objects에 대해 prediction을 한다.
이는 몇 개의 set prediction을 할지에 대한 'hint'가 되고, 이 기준에 따라 adaptive computation을 구성한다.
baseline (original RT-DETR)
Idea 1 : Backbone Hint
idea 1: backbone hint
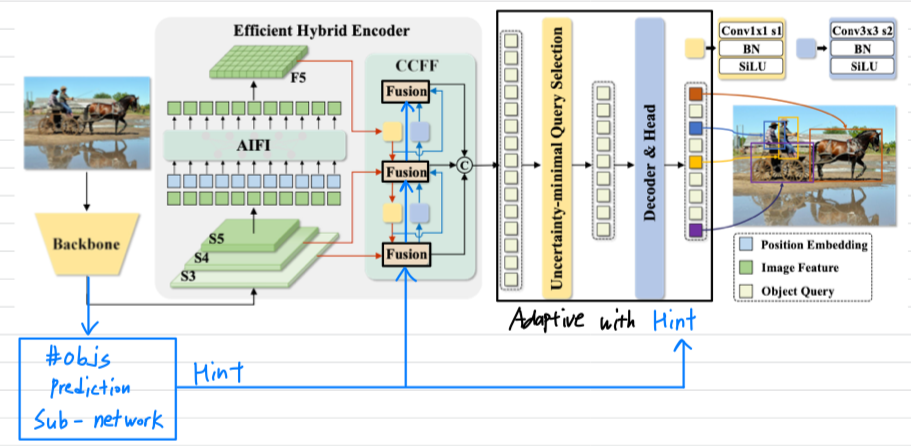 idea 2보다 parameter와 computation은 더 많이 추가될 것 같다.
idea 2보다 parameter와 computation은 더 많이 추가될 것 같다.
하지만 #objs를 더 잘 예측할 수 있을 것 같다.
Idea 2 : AIFI #objs Token(=Hint)
idea 2: AIFI #objs token(=hint)
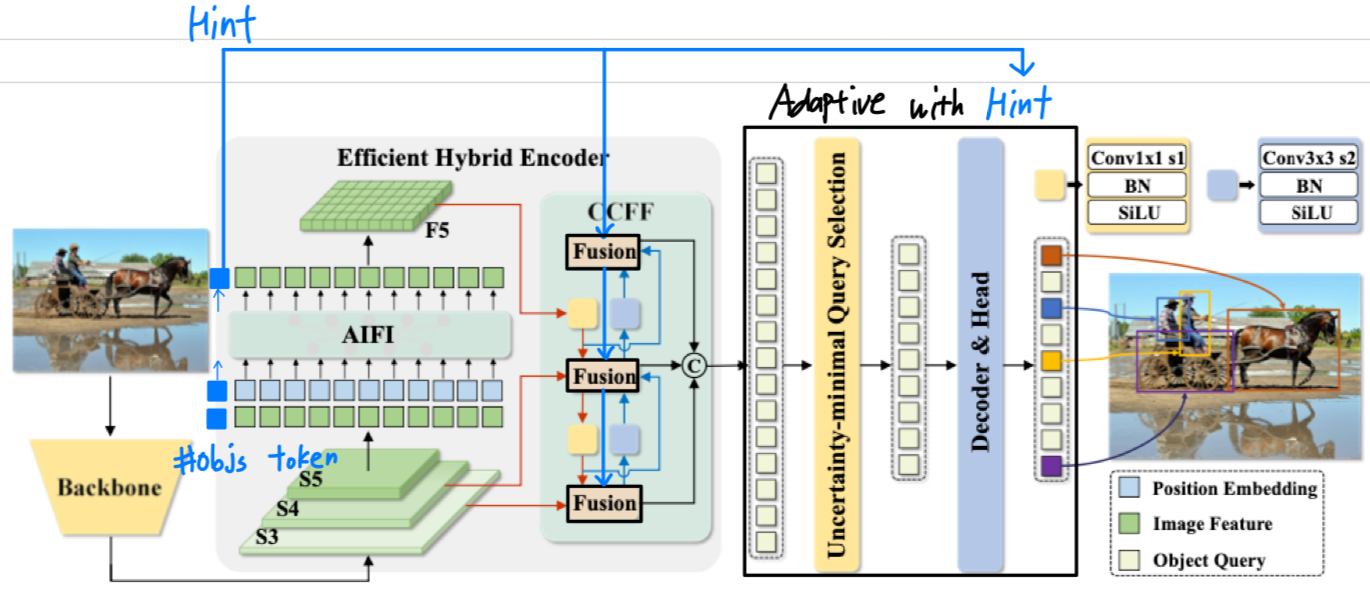
idea 1보다 parameter와 computation이 더 적게 추가될 것 같다.
하지만 #objs를 더 잘 예측하지 못 할 수 있을 것 같다.
Hint token
-
ViT의 Class token에 영감을 받아, hint token을 추가하는 idea이다.
ViT class token의 동작원리와 유사하게 만들었다. -
coco detection train dataset에서 한 image에서 등장하는 최대 object 개수는
90개이다.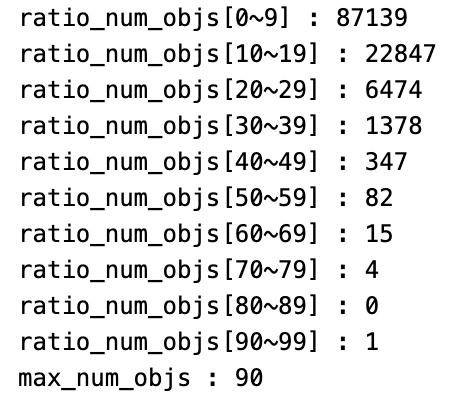
-
coco detection validation dataset에서 한 image에서 등장하는 최대 object 개수는
62개이다.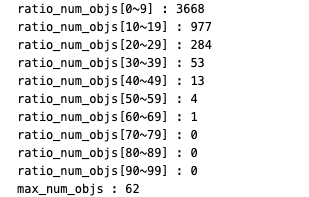
문제점 발견
- batch size가 4라고 가정하고, Hint로 [5, 220, 18, 110]을 prediction했다고 가정하자.
이는 첫 번째 image 내의 object수는 5개, 두 번째 image 내의 object수는 220개, 세 번째 image 내의 object수는 18개, 네 번째 image 내의 object수는 110개라고 예측한 것임.
➡️ 그렇다면, training할 때 adaptive를 어떻게 적용할 것인가?
adaptive network이기 때문에 image-specific하게 network가 구성되어서 학습이 돼야 하는데,
batch 단위로 training하고 있기 때문에 문제가 발생한다.
예를 들어, Hint[0]=5이기 때문에 network의 구성을 최소로 하여 forward & backward해야 하는데
Hint[1] = 220는 network의 구성을 최대로 하여 forward & backward해야 한다.
➡️ 쉽게 떠오르는 해결할 수 있는 방법은 다른 dynamic network처럼 super network, sub network를 모두 forward시켜서 학습하는 것.


Efficient Deep Learning