CrossKD: Cross-Head Knowledge Distillation for Object Detection
Paper Info.
-
Wang, Jiabao, et al. "CrossKD: Cross-head knowledge distillation for object detection." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
Abstract
- Knolwedge Distillation(KD)는 compact object detector를 학습시키기 위한
effective model compression technique으로 검증되어 왔다.
object detection을 위한 기존의 SOTA KD methods들은 주로 feature imitation(모방)에 기반하고 있다.
이 논문에서는 일반적이고 효과적인 prediction mimicking(모방) distillation scheme인CrossKD를 제안한다.
-
CrossKD는 student's detection head의 intermediate features를 teacher's detection head로 전달한다.
그 후 teacher's prediction을 mimic(모방)하도록 cross-head prediction을 강제한다.
이러한 방식은 student model's head가
annotations과 teacher's predictions으로부터 contradictionary(모순된) supervision signals을 받는 것을 완화하여
student's detection performance를 크게 향상시킨다.(?) -
게다가,
teacher's prediction을 mimicking하는 것이 KD의 목표이기 때문에,
CrossKD는 feature imitation에 비해 더 task-oriented information을 제공한다.
MS COCO dataset에서 prediction mimicking losses만 적용했을 때,
CrossKD는 1x training schedule을 가진 GFL ResNet-50의 average precision을 40.2에서 43.7로 향상시켰으며,
기존의 모든 KD methods를 능가했다.
추가적으로, 우리 방법은 heterogeneous(이질적인) backbones을 가진 detectors를 distilling할 때도 잘 동작한다.
1. Introduction
- KD는 model compression technique으로서 object detection에서 깊이 연구되어 왔다.
detector의 distillation position에 따라, 기존의 KD 방법은 대략 두 가지 categories로 분류될 수 있다 :
prediction mimicking과 feature imitation이다.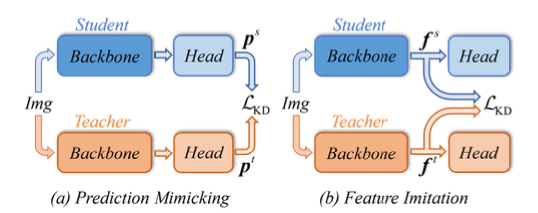
- prediction mimicking은 [24]에서 처음으로 제안되었으며,
teacher's prediction의 smooth distirbution이 teacher가 학습하기에 ground truth의 Dirac distribution보다 더 적합하다고 지적된다.
즉, prediciton mimicking은 teacher의 prediction distribution을 닮도록 강제한다. - feature imitation은 FitNet에서 제안된 idea를 따르며,
intermediate feature가 teacher의 prediction보다 더 많은 정보를 포함하고 있다고 주장한다.
이 방법은 teacher-student pair의 feature consistency를 강화하는 것을 목표로 한다.
- prediction mimicking은 [24]에서 처음으로 제안되었으며,
- prediction mimicking은 object detection model의 KD에서 중요한 역할을 한다.
그러나 오랫동안 feature imitation보다 비효율적이라고 여겨져왔다.
최근 Zheng et al. [73]은 localization distillation(LD) transferring을 통해
prediction mimicking을 개선하는 LD method를 제안하여 prediction mimicking을 새로운 수준으로 끌어올렸다.
비록 LD가 PKD[5]와 같은 advanced feature imitation methods와 겨우 맞먹는 수준이지만,
LD는 prediction mimicking이 feature imitation과는 다른 측면에서 teacher에게 이익을 주는 task-specific knowledge를 transter할 수 있음을 보여줬다.
이는 우리가 prediction mimicking을 더 탐구하고 개선하도록 motivation되었다.
-
조사 결과,
기존의 prediction mimicking은 student's assigner가 제공하는 GT target과 teacher가 predicted한 distillation targets 간의
충돌로 인해 문제가 발생할 수 있음을 발견했다.
prediction mimicking으로 detector를 training할 때, student's predictions은 동시에 GT targets과 teacher's predictions을 mimic하도록 강제된다.
그러나 teacher가 예측한 distillation targets은 일반적으로 studnet에게 할당된 GT targets과 큰 차이가 있다.
Fig. 2(a)와 Fig. 2(b)에 표시된 바와 같이,
teacher는 녹색 원으로 표시된 영역에서 class probabilities를 생성하며, 이는 student에게 할당된 GT target과 충돌한다.
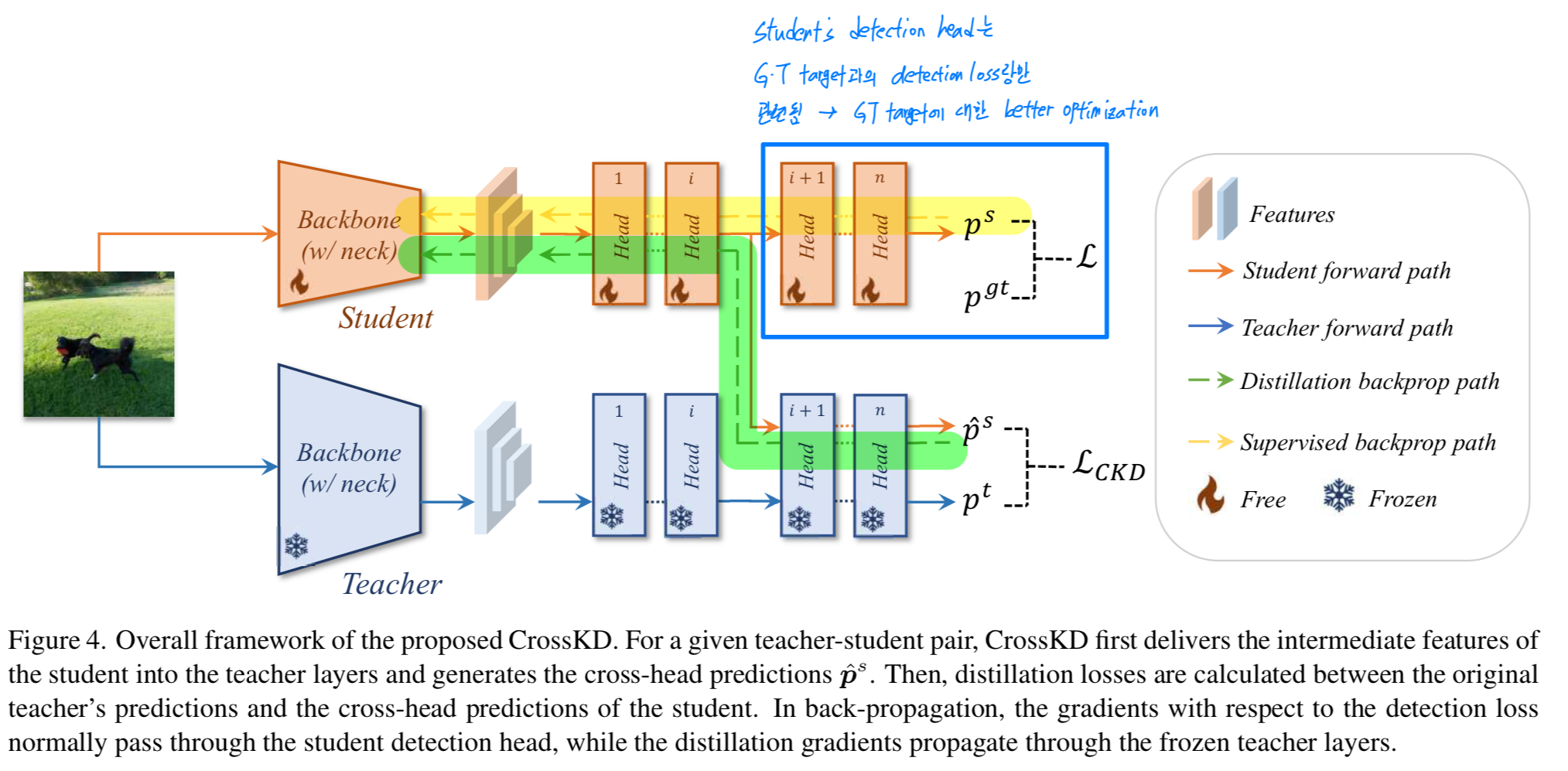
그 결과, student detector는 distillation 도중에 contradictory learning process를 겪게 되어 optimization에 심각한 방해를 받게 된다.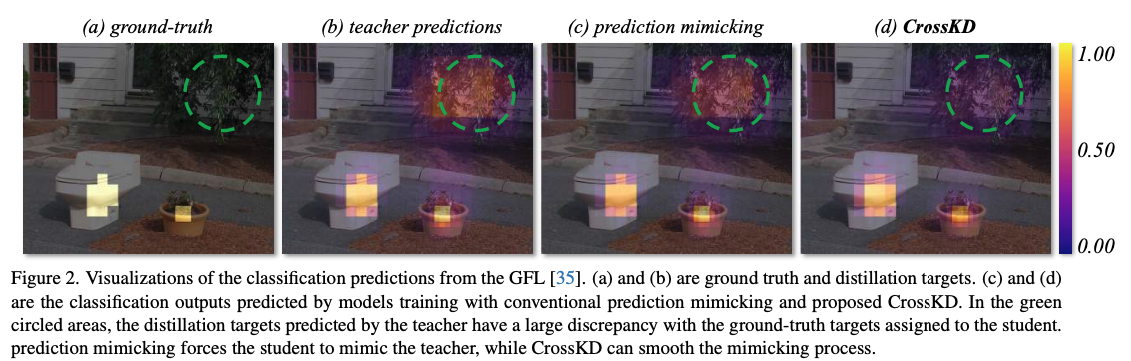
-
위에서 언급한 충돌을 완화시키기 위해,
이전의 prediction mimicking 방법들은 일반적으로 mediate teacher-student discrepancies(중간 불일치)를 포함하는 region 내에서 distillation을 수행하는 경향이 있었다.
그러나 우리는 불확실성이 높은 region이 일반적으로 student에게 유익한 더 많은 정보를 포함하고 있다고 주장한다.
이 논문에서 새로운 cross-head knowledge distillation pipeline, 약칭 CrossKD를 제안한다.
Fig. 1(c)에 설명된 바와 같이,
우리는 stduent's head에서 나온 intermediate features를 teacher's head로 전달하여 cross-head preidction을 생성하는 방법을 제안한다.
그런 다음, 새로운 cross-head predictions과 teacher's predictions 사이에서 KD operations을 수행할 수 있다.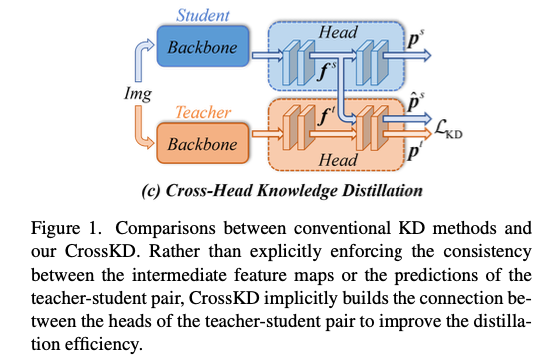
-
simplicity에도 불구하고,
CrossKD는 두 가지 주요 이점을 제공한다.- 첫째, cross-head prediction과 teacher's predictions이 모두 teacher's detection head의 일부를 공유하여 생성되므로 cross-head prediction은 teacher's prediction과 상대적으로 일치한다.
이는 teacher-student pair 간의 discrepancy를 완화하고 prediction mimicking의 training stability를 높여준다. - 또한, teacher's prediction을 모방하는 것이 KD의 목표이므로, CrossKD는 이론적으로 최적이며 feature imitation과 비교했을 때
더 많은 task-oriented information을 제공한다.
- 첫째, cross-head prediction과 teacher's predictions이 모두 teacher's detection head의 일부를 공유하여 생성되므로 cross-head prediction은 teacher's prediction과 상대적으로 일치한다.
-
이러한 두 가지 이점 덕분에 CrossKD는 teacher의 prediction에서 효율적으로 knowledge를 distill할 수 있으며, 결과적으로 이전 SOTA feature imitation methods보다 더 나은 성능을 보인다.
특별한 기법 없이도, 우리의 방법은 student detector의 성능을 크게 향상시키며 training convergence를 높인다.
2. Related Work
2.2. Knolwedge Distillation for Object Detection
-
KD는 lage-scale teacher model에서 small-scale student model로 knowledge를 transfer하는 효과적인 기법이다.
classification task에서 광범위하게 연구되었지만, detection model에서 distill하는 것은 여전히 극도록 어려운 과제이다.
선구적인 연구인 [7]은 feature imitation과 prediction model을 단순히 결합하여 object detection을 위한 첫 번째 distillation framework를 제안했다.
그 이후로 feature imitation은 점점 더 많은 research attention을 받았다.
일부 연구들[13, 25, 33, 60]은 더 나은 Feature imitation을 위해 효과적인 distillation regions을 선택하는 데 중점을 두고 있으며,
다른 연구[19, 31, 74]들은 imitation loss를 더 잘 가중하는 데 초점을 맞추고 있다.
또한, teacher-student consistency function 설계를 시도하는 방법들[5, 64, 65, 58]도 있으며,
이는 더 많은 concsistency information을 탐색하거나 MSE loss의 엄격한 제한을 해소하는 것을 목표로 한다. -
[24]에서 처음 제안된 distillation strategy로서,
prediction mimicking은 classification distillation에서 중요한 역할을 한다.
최근에는 object detection에 적응하기 위해 개선된 prediction mimicking 방법들이 제안되었다.
예를 들어, Rank mimicking[31]은 teacher의 score rank를 일종의 knowledge로 간주하고 student가 instance를 teacher처럼 rank(순위 매기도록) 강요한다.
LD[73]은 bbox의 localization distribution을 distill하여 localization knowledge를 transfer하는 방법을 제안한다.
본 논문에서는 prediction mimicking의 target conflict problem을 완화하기 위해 detection과 distillation을 다른 head로 분리하는 CrossKD pipeline을 구축한다.
HEAD가 heterogeneous(이질적인) teacher-student pairs 사이의 gap을 줄이기 위해 independent assistant head로 student feature를 전달하는 것과 달리,
우리는 단순히 student feature를 teacher에게 전달하는 것만으로도 SOTA results를 달성하는 데 충분히 효과적이라는 것을 관찰했다.
이는 우리 방법을 매우 간결하게 만들며 HEAD와는 다르다.
또한, 우리 방법은 [1, 28, 32, 63]과 관련이 있지만, 이들은 모두 classification model을 distill하는 것을 목표로 하며 object detection에 맞춰져 있지 않다.
3. Methodology
3.1. Anaylsis of the Target Conflict Problem
-
Target conflict는 기존 preidction mimicking methods에서 흔히 직면하는 문제이다.
모든 image에 특정 category를 할당하는 classification task와는 달리,
advacned detector에서는 보통 label이 동적으로 할당되고 deterministic하지 않은 경우가 많다.
일반적으로 detector는 각 location에서 label을 결정하기 위해 hand-crafted principle, i.e., assigner에 의존한다.
대부분의 경우, detector는 assigner의 label을 정확히 재현할 수 없기 때문에 teacher-student targets 간에 conflict가 발생한다.
게다가, real-world 시나리오에서 student와 teacher의 assigner가 일치하지 않으면, GT와 distillation targets 간의 distance가 더욱 멀어진다. -
target conflict의 정도를 정량적으로 측정하기 위해,
우리는 COCO minival에서 다양한 teacher-student discrepancy 내의 conflict area의 ratios를 통계적으로 계산하고 그 결과를 Fig.3.에 보고했다.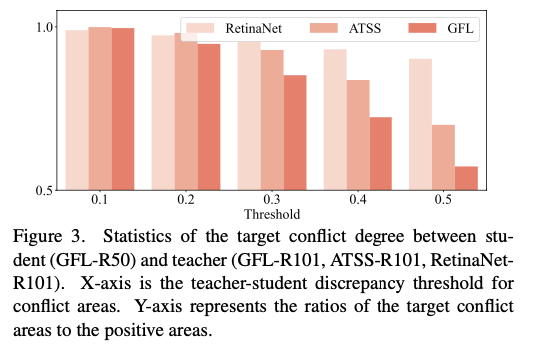 teacher(ATSS and GFL)와 student(GFL)이 동일한 label assignment strategy를 사용하더라도,
teacher(ATSS and GFL)와 student(GFL)이 동일한 label assignment strategy를 사용하더라도,
실제 label과 distillation target 사이에 discrepancy가 0.5를 초과하는 위치가 여전히 많이 있다.
다른 assigner (RetinaNet)을 사용하는 teacher로 student (GFL)을 distill할 때, 충돌 영역은 크게 증가한다.
Sec. 4.5.의 추가 실험에서도 target conflict problem이 prediction mimicking method를 심각하게 저해한다는 것을 보여준다.
target confilct의 큰 영향에도 불구하고, 이 문제는 이전의 prediction methods들에서 오랫동안 간과되어 왔다.
이러한 방법들은 teacher-student predictions 간의 discrepancy를 직접 최소화하려고 한다.
그 목표는 다음과 같이 설명될 수 있다 :
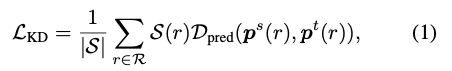 여기서 와 는 각각 student와 teacher가 생성한 prediction vectors이다.
여기서 와 는 각각 student와 teacher가 생성한 prediction vectors이다.
는 와 사이의 discrepancy를 계산한 Loss function을 의미한다.
(예를 들어, classification에 대한 KL Divergence와 regression에 대한 L1 Loss and LD를 의미.)
는 전체 image region 에서 각 position 에 대한 weight를 만들어내는 region selection principle이다.
는 어느 정도 teacher-student 간 discrepancies가 큰 region의 weight를 낮춤으로써 target conflict problem을 완화할 수 있다.
그러나 일반적으로 heavily uncertain regions은 undisputed(명백한) area보다 student에게 더 많은 information benefits을 제공한다.
이러한 regions을 무시하면 preidction mimicking 방법의 효과에 큰 영향을 미칠 수 있다.
따라서 prediction mimicking의 envelope(한계)를 극복하려면 직접적으로 weight를 낮추기보다는 target conflict problem을 처리하는 것이 필요하다.
3.2. Cross-Head Knowledge Distillation
-
Sec. 3.1에 묘사된 것처럼,
우리는 teacher의 predictinos을 직접 mimicking하는 것은 target conflict problem에 직면하여 좋은 성과를 달성하는 것을 방해한다는 것을 관찰했다.
이 문제를 완화하기 위해, 우리는 이 section에서 새로운 Cross-head Knowledge Distillation(CrossKD)를 제안한다.
overall framework는 Fig.4에 설명되어 있다.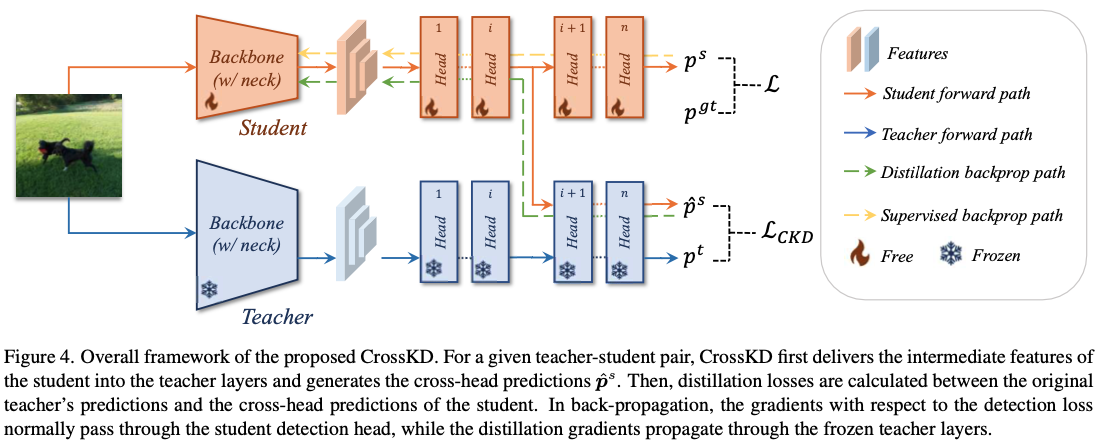 이전의 많은 prediction mimicking methods과 같이, 우리 CrossKD는 preidction에 대한 distillation process를 수행한다.
이전의 많은 prediction mimicking methods과 같이, 우리 CrossKD는 preidction에 대한 distillation process를 수행한다.
차이점으로는, CrossKD는 student의 intermediate feature를 teacher의 detection head로 전달하고 distillation을 수행하기 위한 cross-head predictions을 생성한다. -
RetinaNet과 같은 dense detector를 고려할 때,
각 detection head는 보통 로 나타낼 수 있는 일련의 conv layers로 구성된다.
간단히 말해서, 각 detection head에는 총 개의 conv layer가 있다고 가정한다.
(e.g. RetinaNet에서는 4개의 hidden layer와 1개의 prediction layer가 있어 총 5개)
우리는 에 의해 생성된 feature map을 로 나타내고 의 input feature map을 로 나타낸다.
predictions 는 last conv layer 에 의해 생성된다.
따라서, 주어진 teacher-student pair에 대해서, teacher와 student의 prediction은 각각 와 로 나타낼 수 있다.
teacher와 student의 original predictions외에도,
CrossKD는 student의 intermediate features 을 teacher의 detection head의 -th conv layer 로 전달하여 cross-head predictions 를 생성한다.
가 주어지면, 와 사이의 KD loss를 계산하는 대신,
우리는 CrossKD의 목표로서 cross-head prediction 와 teacher의 original predictions 사이의 KD loss를 사용하는 것을 제안한다.
이는 다음과 같이 설명 된다 :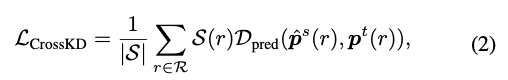 여기서 와 는 region selection principle과 normalization factor를 의미한다.
여기서 와 는 region selection principle과 normalization factor를 의미한다.
복잡한 를 designing하는 대신, 우리는 entire prediction map에서 와 사이의 distillation을 동일하게 수행한다.
구체적으로, CrossKD에서는 가 1의 값을 갖는 constant function(상수 함수)이다.
각 branch의 서로 다른 tasks(classification or regression)에 따라, 우리는 student에게 task-specific knowledge를 효과적으로 전달하기 위해 다른 유형의 를 수행한다.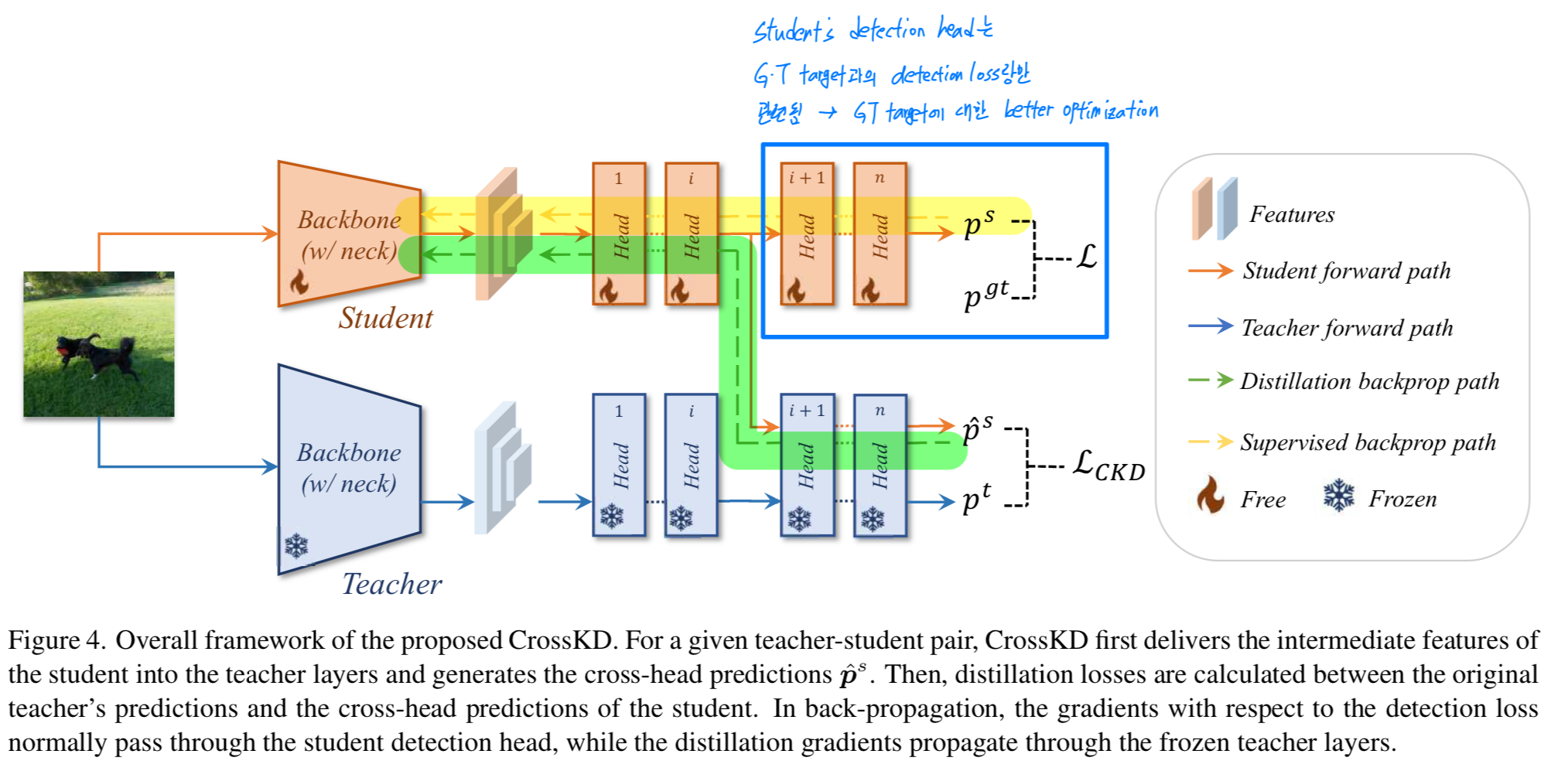 CrossKD를 수행함으로써, detection loss와 distillation loss는 서로 다른 branch에 별도로 적용된다.
CrossKD를 수행함으로써, detection loss와 distillation loss는 서로 다른 branch에 별도로 적용된다.
Fig. 4에서 설명한 바와 같이, detection loss의 gradients는 student의 전체 head를 통과하고,
distillation loss의 gradient는 frozen teacher layers를 통해 student의 latent(잠재) features로 전달되어,
teacher와 student 간의 consistency를 증가시킨다.
teacher-student pair 간의 predictions을 직접적으로 일치시키는 것과 비교하여, CrossKD는 student's detection head가 detection loss랑만 관련되도록 하여,
GT targets에 대한 더 나은 optimization을 가능하게 한다.
(quantitative(정량적) analysis는 experiments section에서 제시.)
3.3. Optimization Objectives
-
training 동안의 overall loss는
detection loss와 distillation loss의 weighted sum으로 formulated된다 :
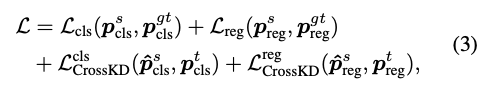 와 는 student predictions 과 그에 대응하는 GT targets 간의 계산된 detection loss이다.
와 는 student predictions 과 그에 대응하는 GT targets 간의 계산된 detection loss이다.
추가적인 CrossKD loss는 와 로 나타내고, 이들은 cross-head predictions 과 teacher's predictions 사이에서 계산된다. -
우리는 각 branch에 task-specific information transfer를 위해
서로 다른 distance functions 를 적용했다.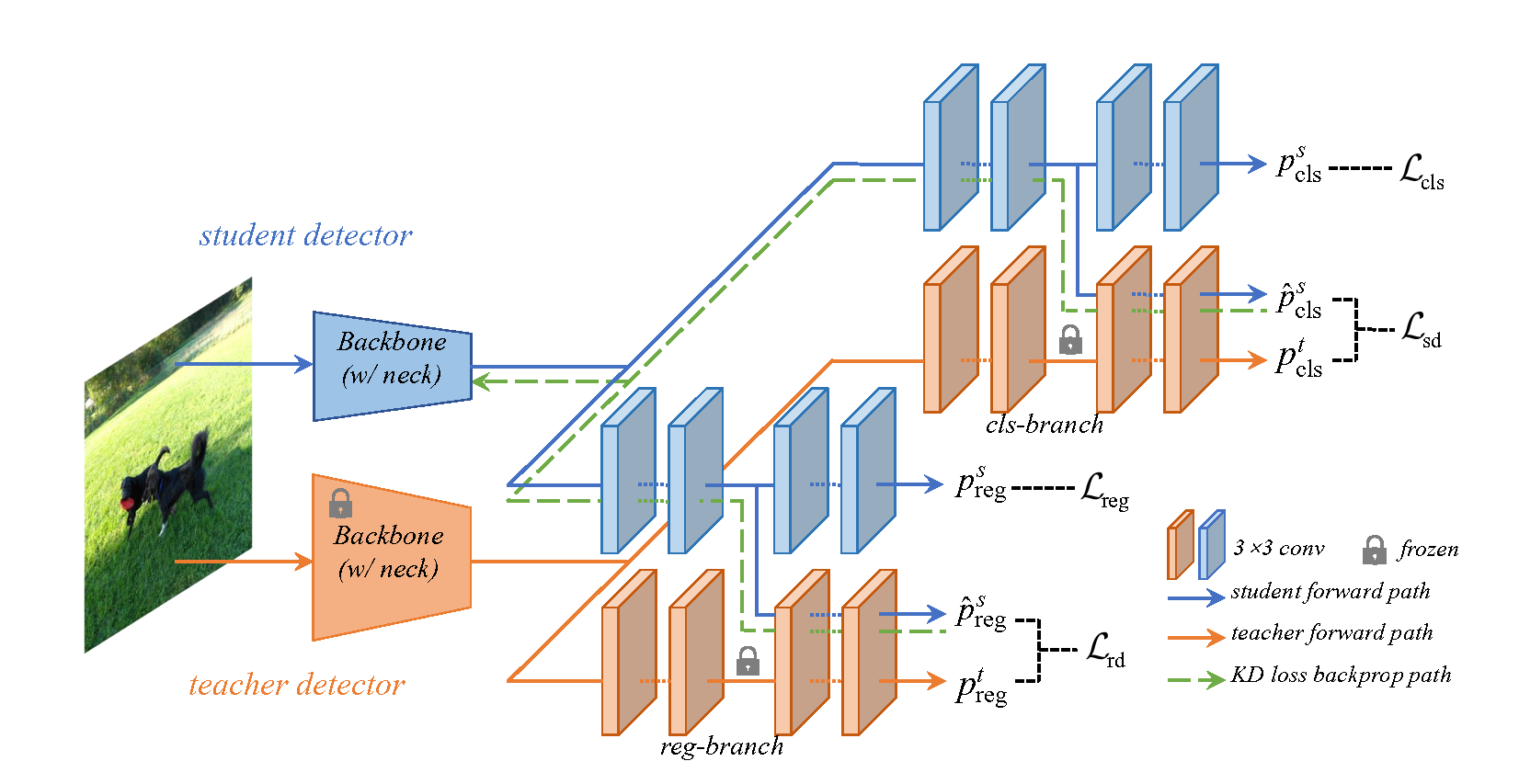
- classification branch에서는 teacher가 예측한 classification score를 soft label로 간주하고,
GFL에서 제안된 Quality Focal Loss(QFL)을 사용하여 teacher와 student 사이의 distance를 좁힌다. - regression branch의 경우, dense detector에서 주로 두 가지 형태의 regression이 존재한다.
- 첫 번째 regression 형태는 anchor box(e.g., RetinaNet, ATSS) or points(e.g., FCOS)
이 경우, 우리는 GIoU를 로서 직접적으로 사용했다. - 두 번쨰 형태는 box location의 distribution을 나타내는 vector를 예측하는 형태이다(e.g.m GFL)
이 형태는 bbox representation의 Dirac distribution보다 더 풍부한 정보를 포함한다.
localization knowledge를 효율적으로 distillation하기 위해, 우리는 KL divergence를 사용했다.
(자세한 loss function에 대한 내용은 supplementary materials에서 제공)
- 첫 번째 regression 형태는 anchor box(e.g., RetinaNet, ATSS) or points(e.g., FCOS)
- classification branch에서는 teacher가 예측한 classification score를 soft label로 간주하고,
Appendix



4. Experiments
4.1. Implement Details
Critique
-
prediction mimicking 계열의 knowledge distillation을 잘 연구했다고 생각함.
특히나 object detection에서의 knowledge distillation 논문 중 가장 이해가 쉽고, 아이디어가 간단하다고 생각이 듦.
또한 범용적으로 적용할 수 있는 KD이기 때문에 사용 접근성(?)이 좋다고 생각함. -
내가 연구한다면 이렇게 간단하고 범용적으로 사용될 수 있는 아이디어를 self-distillation에서 제시하고 싶음.
이 논문은 하나의 efficient detector를 Training 시키는 것이 contribution이라면,
나는 self-distillation을 통해 teacher와 student를 adaptive하게 동시에 사용할 수 있도록 하여 두 개의 detector를 training시키고 싶음. -
내 연구 motivation에 대해 아쉬운 점 :
나는 neck의 intermediate feature를 backbone에 효율적으로 KD하여
teacher는 original model, student는 original without neck으로 self-distillation을 하고 싶다.
이를 위해서는 feature imitation이 필요하다.
이 논문이 내가 하고자 하는 detector를 위한 knowledge distillation이라고 하여 읽어봤지만....
이 논문은 prediction mimicking이었기 때문에 내가 하고자 하는 연구(feature imitation)와는 조금은 다른 연구라고 판단이 된다.
