$D^3$ETR: Decoder Distillation for Detection Transformer
Abstract
-
CNN-based detectors에서 다양한 Knowledge Distillation(KD) methods들이
small student의 성능 향상에 효과적임을 보였지만,
DETR-based detectors를 위한 기준 및 방법론은 아직 확립되지 않았다. -
이 논문에서는 DETR-based detectors의 transformer decoder에 초점을 맞추어 KD methods 방법을 탐구한다.
transformer decoder의 outputs은 random한 순서로 나타나기 때문에,
teacher model과 student model의 predictions 간의 direct correspondence(직접적인 대응)이 없어서 knowledge distillation에 어려움이 발생한다. -
이를 해결하기 위해,
우리는 DETR-based teachers and students의 decoder output을 정렬하는 MixMatcher를 제안한다.
이는 teacher-student matching strategies인 Adaptive Matching과 Fixed Matching을 결합한 방식이다.
구체적으로,
Adaptive matching은 bipartite matching을 적용하여 각 decoder layer에서 teacher와 student의 output을 adaptive하게 matching하고,
Fixed matching은 teacher와 student의 output을 동일한 object queries로 고정하여 대응시킨다.
또한 teacher의 고정된 object queries는 student의 decoder에 auxiliary group으로 입력된다. -
MixMatcher를 기반으로 우리는 DEtection TRansformer의 decoder prediction 및 attention map에서 teacher로부터 student로
knowledge distillation하는 Decoder Distillation for DEtection TRansformer (DETR)를 만들었다.
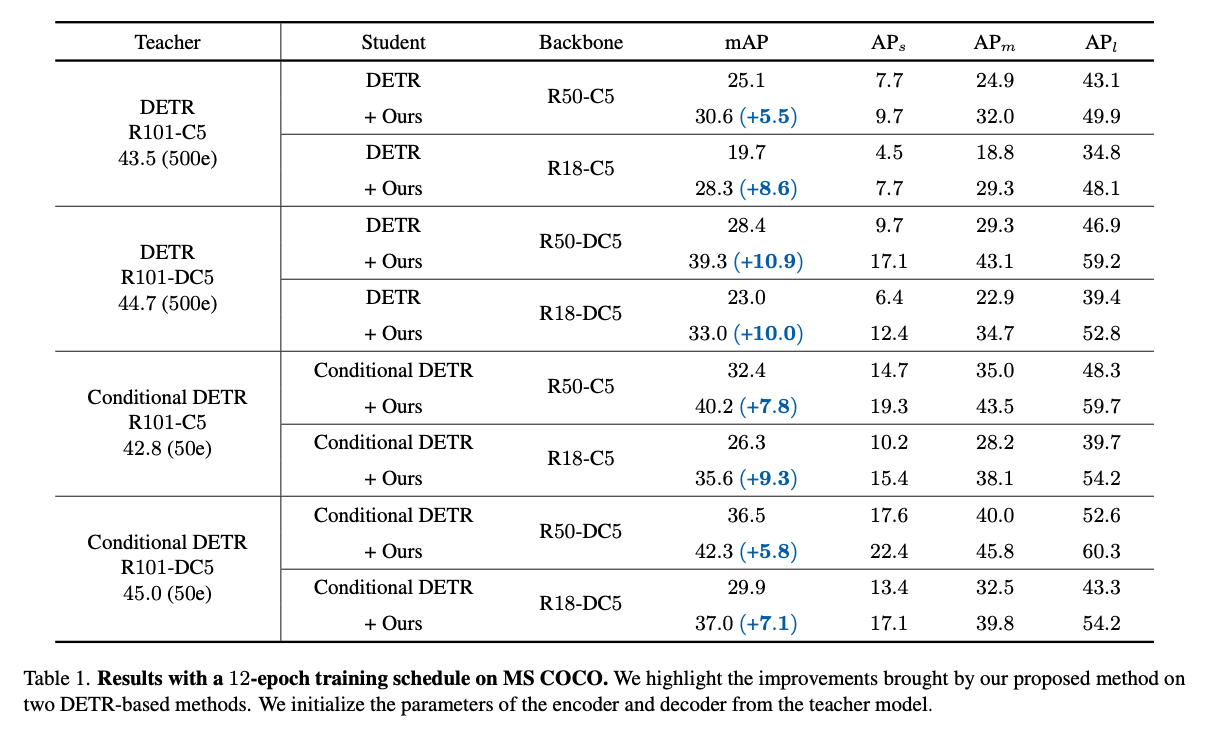
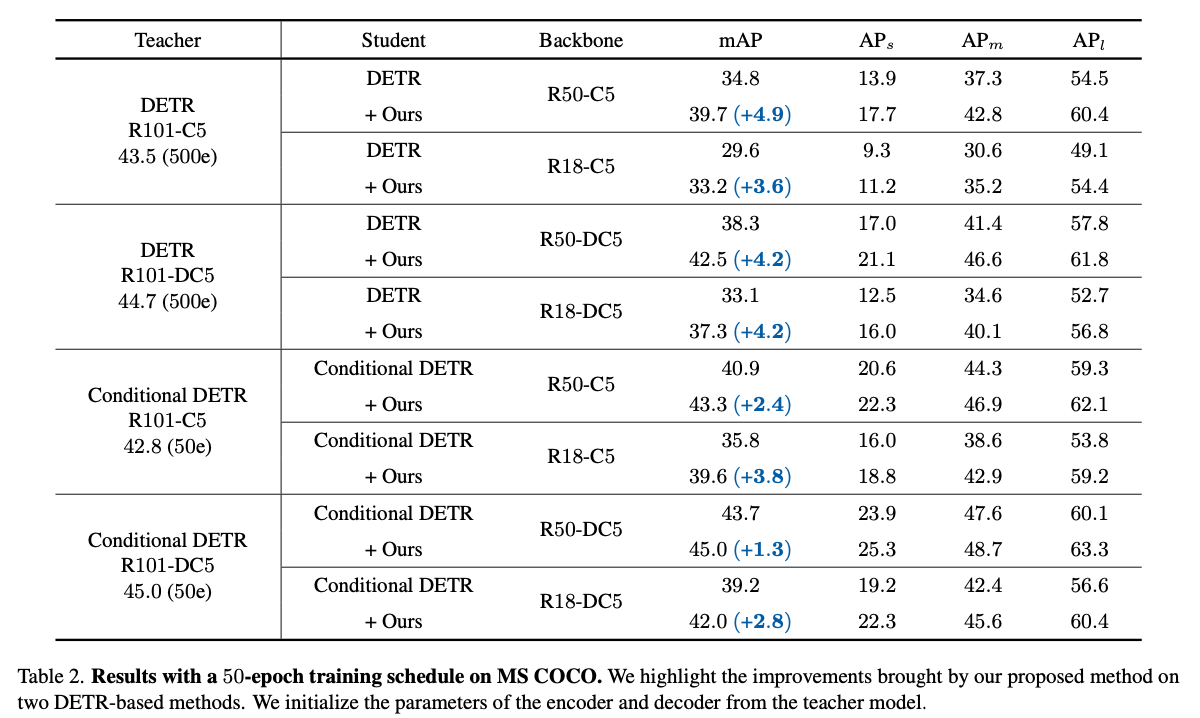
DETR은 다양한 backbone을 사용하는 DETR-based detector에서 뛰어난 성능을 보여준다.
예를 들어,
DETR는 Conditional DETR-R101-C5를 teacher model로 사용하여,
Conditional DETR-R50-C5의 성능을 12/50 epoch training setting에서 각각 7.8/2.4 mAP 향상시켰다.
1. Introduction
-
KD는 large teacher model의 지식을 small student model에 전달하여 model inference 과정에서 student model의 성능을 무료로 향상시키는 방법으로 제안되었다.
다양한 방법이 제안되었지만, 주로 CNN-based models에 중점을 두며,
특히 object detection에서 model structure와 관련된 경우가 많다.
기존의 KD 방법을 DETR-based detector와 같은 새로운 detector에 적용하는 것은 challenge이며, trivial improvements에 그칠 것이다.
이 논문은 이러한 격차를 해소하고 DETR-based detectors를 위한 KD 방법을 탐구하는 것을 목표로 한다. -
DETR은 Transformer layer를 사용하는 end-to-end detector이다.
DETR과 그 variants들은 (1) backbone으로 image feature를 extracting하고, (2) transformer encoder로 global context를 modeling하고, (3) image features와 object queries를 기반으로 transformer decoder를 통해 object를 prediction하는 pipelne을 따른다.
DETR-based detector를 위한 KD baselines과 방법론을 구축하기 위해,
우리는 기본으로 돌아가 앞서 언급한 구성 요소들의 영향을 조사했다.
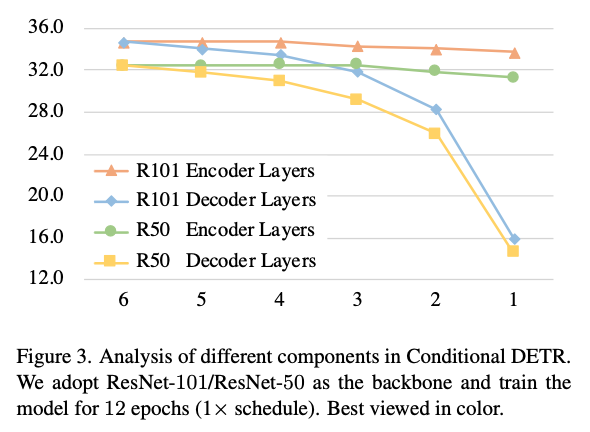
그 결과, transformer decoder가 좋은 성능을 유지하는 데 중요한 역할을 한다는 것을 발견했고(Figure 3), 이에 따라 transformer decoder에서 KD methods를 탐구하기 시작했다.
-
CNN-based object detectors들과는 달리, DETR decoder의 outputs은 random orders로 나타나기 때문에
teacher model과 student model 간의 direct correspondence가 없다.
이 문제를 해결하기 위해, 우리는 teacher와 student의 decoder output을 정렬하기 위해 MixMatcher를 제안한다.
MixMatcher는 Adaptive Matching과 Fixed Matching이라는 두 가지 matching 전략을 결합한 것이다.
Adaptive Matching은 각 decoder layer에서 teacher와 student model의 predictions 간의 optimal bipartite matching을 계산하고 teacher-student 간 correspondence를 결정한다.
그러나 teacher-student 간의 Adaptive Matching에서 발생할 수 있는 instability issue를 완화하기 위해,
우리는Fixed Matching도 제안한다.
teacher의 fixed object queries를 student의 decoder에 auxiliary group으로 입력하고 Fixed matching을 적용하여,
동일한 object queries를 가진 teacher와 student models 간의 outputs을 고정된 correspondence으로 설정한다.
-
MixMatcher는 teacher와 student model 간의 correspondence를 modeling할 수 있게 해준다.
MixMatcher를 기반으로, 우리는 decoder distillation for DETR-based methods ()을 구축했다.
단순히 predictions만 고려하는 것이 아니라, distillation을 수행할 때 decoder layers의 attention modules(self-attention and cross-attention)도 고려했다.
attention module에 대해서는 attention map에 포함된 knowledge를 distill한다.
COCO datset에서 extensive experiments를 통해 의 효과가 검증되었다.
이는 다양한 DETR-based student model에 큰 성능 향상을 가져왔다.
예를 들어,
DETR는 Conditional DETR-R101-C5를 teacher model로 사용하여,
Conditional DETR-R50-C5의 성능을 12/50 epoch training setting에서 각각 7.8/2.4 mAP 향상시켰다. -
간단히 말해, 우리의 contributions은 세 가지로 요약할 수 있다 :
- DETR-based detector를 위한 knowledge distillation을 탐구하고, transformer decoder에서 KD를 수행하는 문제를 해결하려고 시도했다.
- 우리는 Adaptive Matching과 Fixed Matching을 적용하여 DETR-based teacher와 student 간의 관계를 Modeling하는 MixMatcher를 제안했다.
그후, 간단하면서도 효과적인 distillation method인 를 만들었다. - 제안된 방법인 은 DETR-based detector에 적용되어 성능을 크게 향상시킬 수 있었다.
2. Related Work
Knowledge distillation in object detection
- these efforts focus on the distillation on ordered outputs in CNN-based detectors
- ICD : instance-based conditional distillation framework, ... the teacher's parameters will lead to faster convergence
- DeFeat : decouples the fg and bg in the feature maps and distills them separately
- FGD : focal and globla distillation to guide the student model
- ViDT : transformer-based detector를 제안하고, 그 위에 KD를 적용하여 teacher와 student model 간에 patch token과 detection queries에 대해 직접적으로 distillation.
그러나 우리는 DETR에서 decoder의 output은 unordered이기 때문에, teacher queries와 student queries를 직접적으로 대응하지 않는다는 점을 발견했다. - Incremental-DETR과 DETRDistill은 bipartite matching을 통해 teacher와 student prediction 간의 correspondence를 구성하는 방법을 제안함.
하지만, 그들은 bipartite matching이 early training stage에서 unstable할 수 있다는 문제를 간과했다.
우리는 이 idea를 따르면서 한 걸음 더 나아가, 이러한 문제를 완화하는 데 도움이 되는 MixMatcher를 제안함.
DETR-based object detection
-
DETR이 transformer를 object detection에 도입한 선구적인 연구로 인해,
점점 더 많은 후속 연구들이 DETR을 기반으로 다양한 advanced extensions이 만들어지고 있다.
이는 NMS나 initial anchor boxes generation과 같은 hand-designed components로 설계된 구성요소가 필요 없기 때문이다.
Deformable-DETR은 reference 지점 주변의 소수의 점에만 주의를 기울이는 multi-scale deformable attention scheme을 도입하여 DETR보다 더 나은 성능을 달성했다. -
여러 연구들은 DETR의 decoder 설계를 개선하는 데 중점을 두고 있다.
Conditional DETR은 극단적인 영역 판별을 용이하게 하기 위해 reference points에 기반한 positional queries를 rebuilt했다.
DAB-DETR은 성능을 향상시키기 위해 query를 4D anchor box로 확장했다.
후속 연구인 DN-DETR과 DINO-DETR은 decoder 학습ㅇ르 가속화하기 위해 a novel query denosing algorithm을 도입했다.
Group DETR과 H-DETR은 여러 positive query가 빠른 수렴의 핵심이라고 주장하며 decoder 입력에 auxiliary group을 도입했다.
이러한 노력들은 decoder design이 DETR에 매우 중요하다는 것을 보여준다.
기존 연구들이 decoder에서 새로운 방식의 designing scheme에 초점을 맞춘 것과 달리, 우리는 다른 관점에서 시작하여 Large model에서 small model로 knowledge를 transfer하는 방법을 제안한다.
3. Preliminary
- 이 section에서, 우리는 DETR archietecture와 attention mechanism에 대해 review할 것이다.
그리고나서 DETR structure의 몇가지 분석과 어떤 part가 performance에서 중요한 영향을 미치는지 조사할 것이다.
3.1. DETR Architecture
- DETR architecture는 backbone, transformer encoder, transformer decoder and object class and box positoin predictors로 구성되어 있다.
image features는 backbone에 의해 추출되어지고
encoder layer는 global context를 modeling한다.
transformer decoder는 개의 object queries를 input으로 사용한다 :
decoder에서 각 query는 ground-truth object(with class and bbox) 또는 "no object" class를 예측하는 역할을 한다.
query는 high-dimensional feature vector, anchor point coordinates, and the box coordinates와 같은 다양한 형태가 될 수 있다.
object query는 decoder embedding에 결합되어 decoder의 self-attention and cross-attention layer에서 사용되는 query가 된다.
그 후 출력된 query embedding은 detection head로 전달되어 개의 object predictions을 생성한다.
3.2. Attention Mechanism
-
attention은 scaled dot-product를 사용하여 계산된다.
input : a set of queries , a set of keys , and a set of values
attention weights는 queries와 keys 간의 dot-products의 softmax를 적용하여 계산된다 :
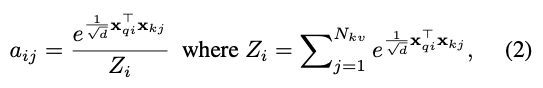 는 query index고 는 key index이다.
는 query index고 는 key index이다.
각 query 에 대한 attention output은 attention weights로 가중된 값들의 aggregation이다.
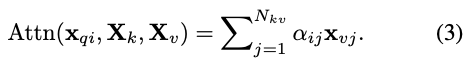
-
multi-head attention은 개의 parallel attention heads로 이루어져 있다.

-
만약 self-attention이라면,
keys, values, queries는 모두 같다. -
만약 cross-attention이라면,
keys와 values는 같지만 key에는 positional embedding이 포함될 수 있으며 queries는 다르다.
3.3. Analysis on the DETR structure
- DETR-like methods는 세 가지 parts로 이루어져 있다 :
backbone, the transformer encoder, and the transformer decoder.
우리는 어느 part가 detection performance에 가장 큰 영향을 미치는지 조사하기 위해 실험을 진행했다.
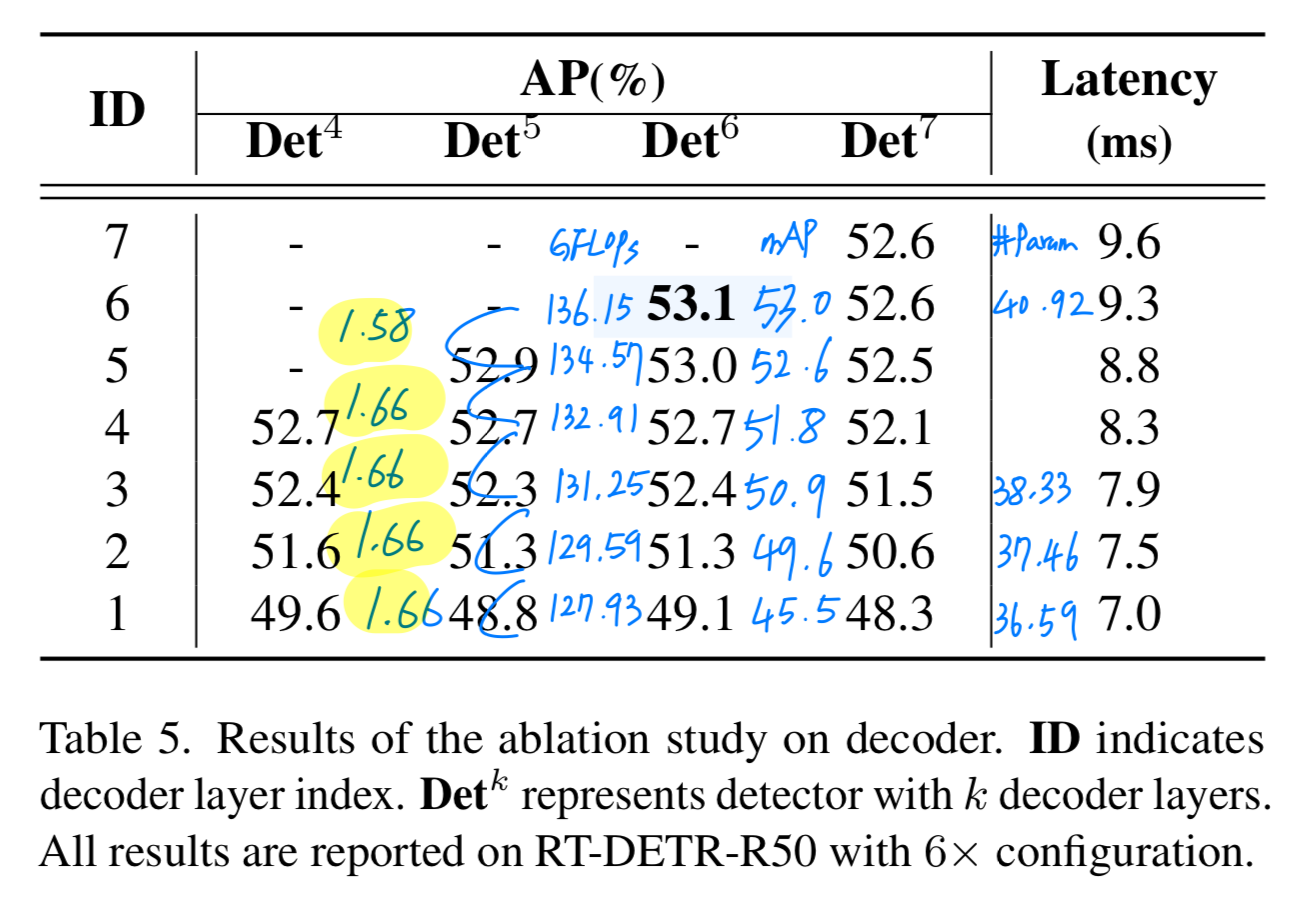
결과는 Figure 3에 나와 있다.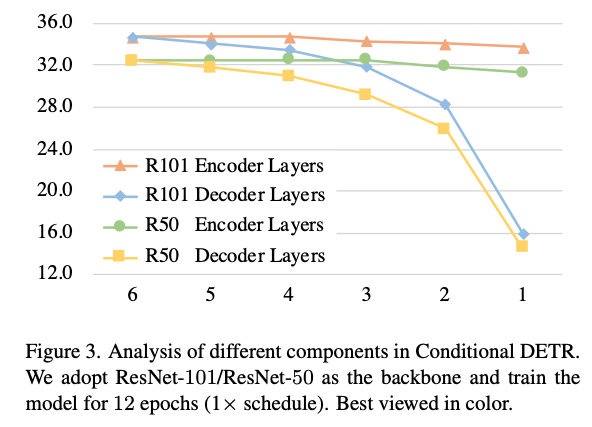 decoder layer 수를 6개에서 1개로 줄이는 것이 R50/R101 backbone에서 각각 17.8/18.3 mAP 성능 저하를 초래한다는 것을 발견했다.
decoder layer 수를 6개에서 1개로 줄이는 것이 R50/R101 backbone에서 각각 17.8/18.3 mAP 성능 저하를 초래한다는 것을 발견했다.
이러한 관찰을 바탕으로, 우리는 decoder에서 knowledge를 증류하는 방법을 제안한다.- (RT-DETR에서는 decoder layer 수를 감소시키는 것이 이렇게 큰 성능 감소로 이어지지 않음. ➡️ Critique에 내 생각을 적어놓음)
- (RT-DETR에서는 decoder layer 수를 감소시키는 것이 이렇게 큰 성능 감소로 이어지지 않음. ➡️ Critique에 내 생각을 적어놓음)
4. Methodology
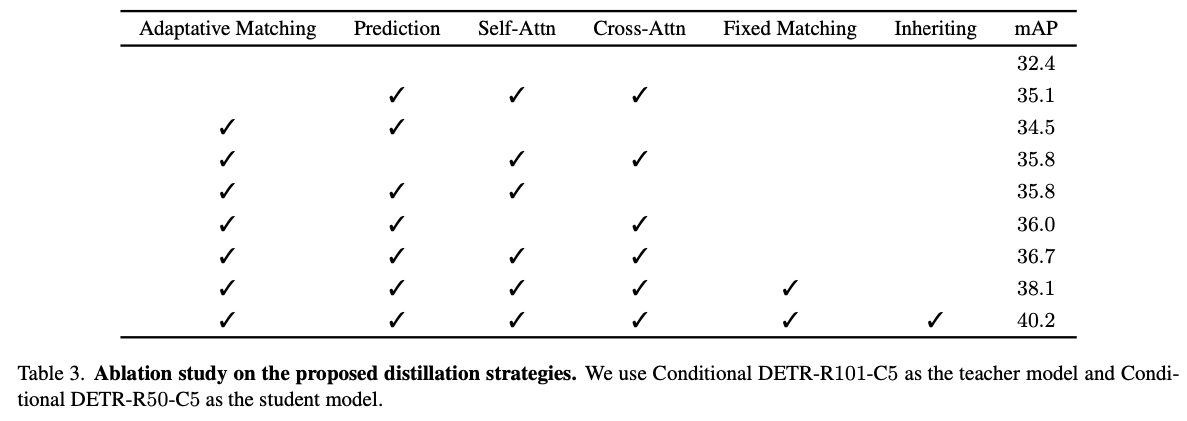
- 우리는 먼저 teacher-student matching strategies인 Adaptive Matching과 Fixed Matching으로 구성된 MixMatcher를 소개한다.
그런 다음, decoder predictions, self-attention, and cross-attention에서 teacher model의 knowledge를 distill하는 을 소개한다.
4.1. MixMatcher
Adaptive Matching.
-
DETR decoder의 output은 sparse and unordered하기 때문에 teacher와 student outputs 간의 direct one-to-one correspondence가 없다.
예측된 object와 ground-truth object 간에 bipartite matching을 수행하는 DETR에서 영감을 받아,
teacher와 student output 간의 correspondence를 bipartite matching 문제로 간주할 것을 제안한다. -
teacher prediction 와 student prediction
(는 category prediction에 대한 soft logits이고 는 box prediction에 대한 4-D vector임)
가 주어졌을 때,
pair-wise matching cost는 다음과 같이 정의된다.
 teacher와 student 간의 bipartite matching을 찾기 위해,
teacher와 student 간의 bipartite matching을 찾기 위해,
우리는 lowest cost를 갖는 elements 들의 permutation을 검색한다.
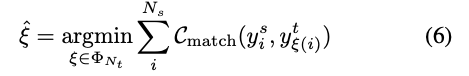 training의 용이성을 위해, DETR은 각 decoder layer가 detection predictions을 수행하도록 하는 auxiliary decoding loss를 채택한다.
training의 용이성을 위해, DETR은 각 decoder layer가 detection predictions을 수행하도록 하는 auxiliary decoding loss를 채택한다.
이는 현재 단계의 prediction이 이전 단계의 refinement 작업이 되도록 만든다.
따라서, 우리는 각 decoder layer에서 teacher model과 student model의 prediction을 adaptive하게 matching한다.
decoder layer 수를 이라고 가정하면, adaptive matching algorithm을 각 decoder layer에 적용하여 개의 matching results를 얻을 수 있다 :
Fixed Matching.
-
bipartite graph matching의 instability는 초기 training 단계에서 optimization 목표가 inconsistent할 수 있다.
이러한 문제를 완화하기 위해서,
teacher-student adaptive matching에서 우리는 auxiliary group을 설계하여
고정된 teacher query를 student decoder에 입력한다.
동일한 input queries를 제공함으로써, auxiliary group과 teacher model이 잘 정렬되기를 기대한다. -
불행히도,
decoder prediction과 GT 간의 bipartite graph matching에서도 instability가 존재한다.
이로 인해 같은 object query에서 생성된 두 outputs(auxiliary group and teacher model)이 서로 다른 GT 값으로 supervised되는 상황이 발생할 수 있다.
이 문제를 해결하기 위해, 우리는 마지막 decoder layer에서 auxiliary group의 label assignment results를 teacher model의 결과로 대체한다 :
 이러한 제약 조건 내에서
이러한 제약 조건 내에서
student model의 teacher model과 auxiliary group의 각 query가 동일한 GT(또는 "no obj")로 supervised되어 one-to-one correspondence를 강화한다.
우리는 두 matching 전략을 결합하는 정교한 설계를 했다.
우리는 훈련 중에 student group과 auxiliary group 모두 student decoder에 입력한다.
두 group은 decoder parameter를 공유하지만, Decoder self-attention에서 상호작용하지 않는다.
inference 시에는 auxiliary group이 제외되고 student group만 사용된다.
4.2.
- teacher와 student 간의 query correspondence를 얻은 후, 우리는 teacher의 knowledge를 student model로 distill할 수 있다.
decoder의 구조에 따라 세 가지 distillation objectives를 설계했다 : prediction distillatoin, self-attention distillation, and cross-attention distillation
Self-attention distillation.
- Decoder self-attention은 object queries 간의 관계를 modeling하여, 중복 prediction을 제거하는 역할을 할 수 있다.
개의 Object queries를 입력으로 주면,
번째 decoder layer에 대한 multi-head self-attention weight map 을 와 에 따라 얻을 수 있다.
마찬가지로, teacher model의 multi-head self-attention weight map 을 얻을 수 있다.
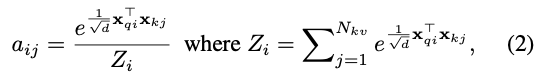
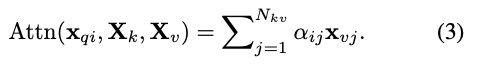
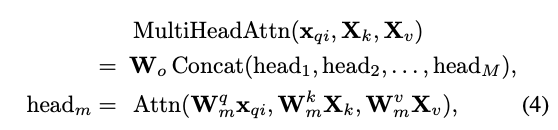 teacher queries의 수가 student queries 수보다 많을 수 있지만,
teacher queries의 수가 student queries 수보다 많을 수 있지만,
teacher-student correspondence에 따라 query를 선택할 수 있다.
그런 다음, decoder self-attention distillation loss는 다음과 같이 정의된다 :
Cross-attention distillation.
- Decoder cross-attention은 self-attentino layer의 output을 queries로 사용하고,
encoder의 output을 keys와 values로 사용한다.
이를 통해 encoder output에서 object의 영역을 검색하고 이를 aggregates한다.
encoder output 와 개의 queries가 주어지면,
student model과 teacher model의 multi-head cross-attention weight map 와 을 얻을 수 있다.
그런 다음, decoder cross-attention distillation loss는 다음과 같이 정의된다 :
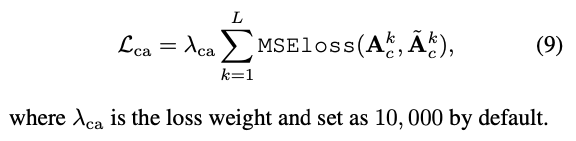
Prediction distillation.
- teacher-student correspondence를 얻고난 후,
우리는 student's prediction을 teacher's prediction으로 정렬한다.
그리고나서 번째 layer의 prediction disillusion losss는 다음과 같이 정의된다 :

Overall distillation loss function.
- 위 모든 Losses들은 student group과 auxiliary group 모두에 적용된다.
전체 loss function은 다음과 같이 정의된다 :
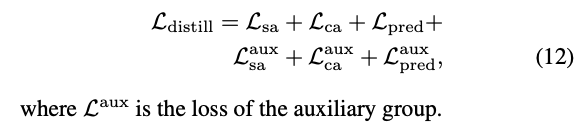
4.3. Discussion
- DETRDistill은 우리 연구와 가장 관련이 있다.
그들은 bipartite matching을 통해 teacher-student correspondence를 구성하고 decoder training을 돕기 위해 auxiliary group을 도입했다.
우리의 연구는 두 가지 측면에서 그들과 다르다.- 우리는 MixMatcher를 제안하며, 이에는 auxiliary group이 포함되어 있어 teacher-student pairs의 instability issue를 완화하는 데 도움을 준다.
하지만 그들으 auxiliary group은 teacher model과 상호작용하지 않는다. - 우리는 decoder attention에서 knowledge를 distill하는 데 집중하는 반면, 그들을 qeury feature를 distill한다.
- 우리는 MixMatcher를 제안하며, 이에는 auxiliary group이 포함되어 있어 teacher-student pairs의 instability issue를 완화하는 데 도움을 준다.
5. Experiments
Critique
- 3.3. Analysis on the DETR structure에서 Conditional DETR을 1xschedule(12 epochs)에서
decoder layer 수를 6개에서 1개로 줄이는 Figure 3을 보여주면서,
decoder layer가 성능에 중요한 영향을 미치는 것을 주장했다.- 하지만 이는 Conditional DETR에서만 적용되는 얘기일 수도 있다.
- 1x schedule이기 때문에 충분한 학습이 안된 상태여서 차이가 크게 보여지는 것이지,
6x schedule에서 실험을 진행했으면 큰 차이가 없을 수 있다.
RT-DETR에서는 6x schedule에서 decoder layer가 성능에 미치는 영향이 이 논문에서 주장하는 바처럼 크진 않았다.
RT-DETR-R50에서 -4mAP 성능 저하
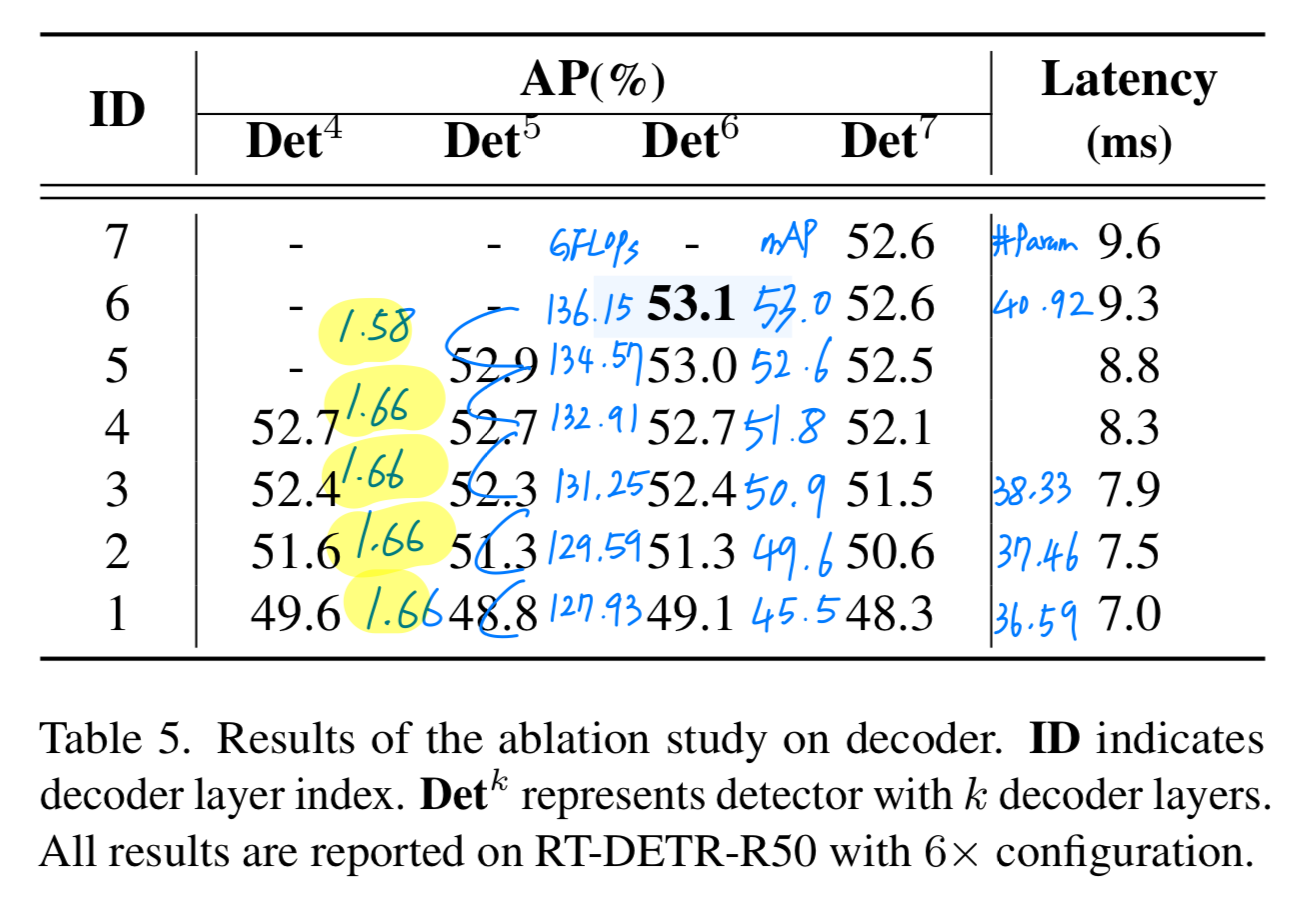
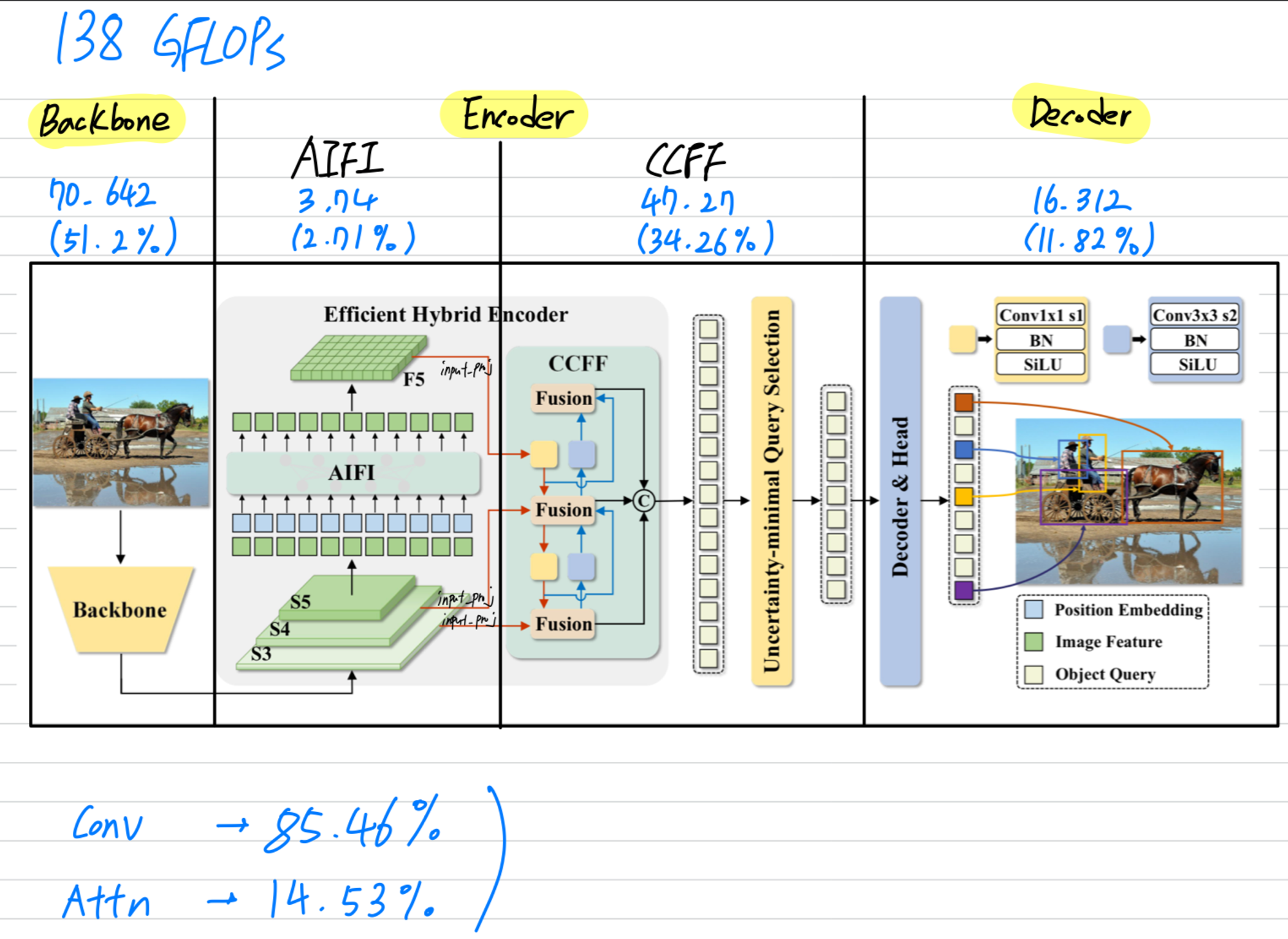
- 2.에서 RT-DETR의 decoder layer 수를 줄이는 것이 큰 성능 감소로 이어지지 않았던 이유는
RT-DETR은 decoder의 computation이 전체의 11.82%로, backbone과 encoder에 비하면 상대적으로 적은 비중을 차지하기 때문일 수도 있음.
즉, 만약에 Conditional DETR의 decoder의 computation 비중이 크다면 decoder layer 수를 줄이는 것은 성능 감소가 큰게 당연한 것이기 때문에
모든 DETR variants에서 decoder layer가 중요하다고 주장하는 것은 잘못된 주장이라고 생각함.
또한 RT-DETR은 이 논문에서 소개한 (= decoder에서의 KD)을 적용하는 것보다 computation 비중이 매우 높은 backbone & encoder에서 KD를 적용하는 것이 더 효과적일 것이라 생각함.
따라서 이 논문의 아이디어인 (= decoder에서의 KD)은 RT-DETR에서 효과적이지 못할 것임.
ㄷ
