[중단] PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient
Paper Info
- Cao, Weihan, et al. "Pkd: General distillation framework for object detectors via pearson correlation coefficient." Advances in Neural Information Processing Systems 35 (2022): 15394-15406.
Abstract
- Knowledge Distillation(KD)는 object detection에서 compact models을 train시키기 위해 널리 사용되는 technique이다.
하지만, heterogeneous(이종의) detectors 사이읜 distill하는 방법에 대한 연구는 아직 부족한 상황이다.
이 논문에서,
비록 detection heads and label assignments가 다르더라도
heterogeneous teacher detector의 better FPN features가
student에게 도움이 된다는 것을 실험적으로 발견했다.
(문제점 제기)
- 그러나 detector를 distill하기 위해 feature map을 직접 aligning하는 것은 두 가지 문제를 발생시킨다.
- 첫째, teacher와 student 간의 feature magnitude(크기) 차이는 student에게 진나치게 strict constraints(엄격한 제한)를 가할 수 있다.
- 둘째, teacher model에서 feature magnitude가 큰 FPN stage와 channel이 distillation loss의 gradient를 지배할 수 있으며, 이는 KD에서 다른 feautre의 효과를 압도하고 많은 noise를 초래할 수 있다.
(제안)
- 이러한 문제를 해결하기 위해,
우리는 teacher의 relational information에 집중하고 feature magnitude에 대한 constraints를 완화하기 위해 Pearson Correlation Coefficient(피어슨 상관 계수)를 사용하여 feature를 imitate(모방)할 것을 제안한다.
(결과)
-
우리 method는 기존의 detector KD methods를 일관적으로 능가하며,
homogeneous and heterogeneous(동질적 및 이질적) student-teacher pair 모두에서 작동한다.
게다가, 더 빠르게 수렴한다. -
MaskRCNN-Swin detector를 teacher로 사용하여,
ResNet-50 based RetinaNet과 FCOS는 COCO2017에서 각각 41.5%와 43.9%의 mAP를 달성했으며,
이는 각각 baseline보다보다 4.1%와 4.8% 높다.
(Our implementation is available at https://github.com/open-mmlab/mmrazor.)
Introduction
- Knowledge Distillation(KD)는 object detection에서 compact model을 train시키기 위해 널리 사용되는 technique이다.
그러나 heterogeneous detectors 간의 distill하는 방법에 대한 연구는 여전히 부족하다.
대부분의 이전 연구들은 detector-specific design을 기반으로 하며 homogeneous(동질적인) detector에만 적용될 수 있었다.
[44, 50]에서는 heterogeneous(이질적인) backbone을 가진 detector에서 실험을 수행했지만,
heterogeneous detection heads와 다른 label assignments를 가진 detector는 항상 빠져있었다.
object detection은 빠르게 발전하고 있으며 better performance를 가진 algorithm이 계속해서 제안되고 있다.
그럼에도 불구하고 practical application에서 stability를 유지하기 위해 detection을 자주 변경하는 것은 쉽지 않다.
게다가, 일부 scenarios는 HW limitations으로 인해 특정 architecture를 가진 detector만 deploy할 수 있으며(e.g., two-stage detectors는 deploy가 어렵다),
대부분의 powerful teachers는 서로 다른 categories에 속한다. (?)
따라서 heterogeneous detector pairs 간의 knowledge distillation이 가능하다면 매우 유망하다.
또한, 현재의 distillation methods들은 성능을 더 높이기 위해 여러 complementary loss functions을 도입하는 경우가 많으며,
이로 인해 각 loss function의 기여도를 조정하기 위하 여러 hyper parameter가 사용되며,
이는 다른 dataset으로 transfer하는 능력에 큰 영향을 미친다.
-
이 논문에서는,
FPN feature imitation이 heterogeneous(이질적인) student-teacher detector pairs에서도 knowledge를 성공적으로 distill할 수 있음을 경험적으로 확인했다.
그러나 teacher와 student의 feature 사이에서 MSE를 직접 minimizing하는 것은 sub-optimal results이며, 이는 Table 5.에 나와있다.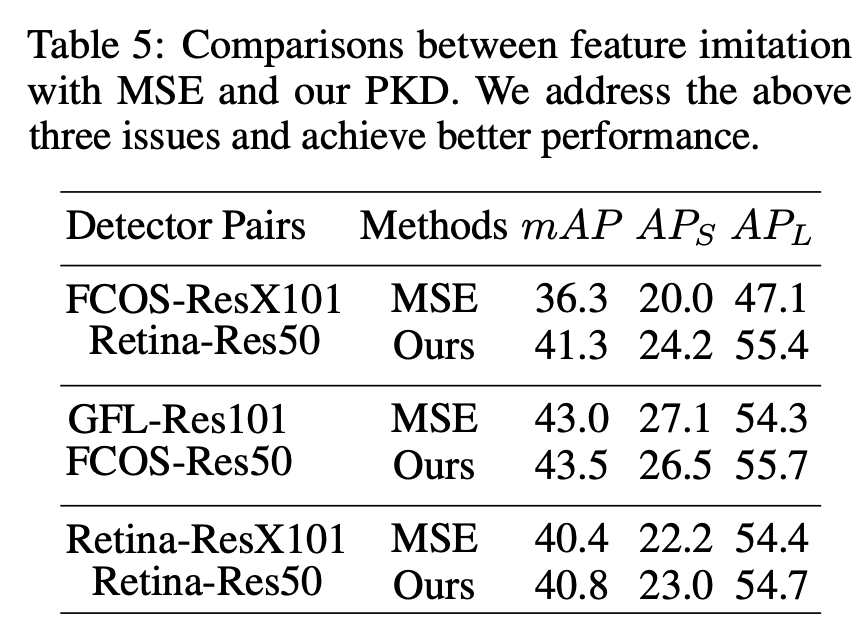 유사한 결론이 여러 연구에서도 도출되었었다.
유사한 결론이 여러 연구에서도 도출되었었다.
MSE의 limitations을 탐구하기 위해서, 우리는 Figure 1에 나타난 대로 teacher와 student의 FPN feature response를 정교하게 시각화했다.
구체적으로, -th FPN stage의 output feature 에 대해서,
각 pixel에서 dimension 에서 maximum value를 선택하고 2-D matrix를 얻는다.
그런 다음, 이러한 2-D matrices의 maximum and minimum values에 따라 값을 0-255로 normalize한다.
이러한 비교를 통해, 우리는 다음과 같은 observations을 얻었다 :- teacher와 student의 feature value magnitudes는 다르며,
특히 heterogeneous detectors의 경우는 특히 그렇다. (Figure 1 left)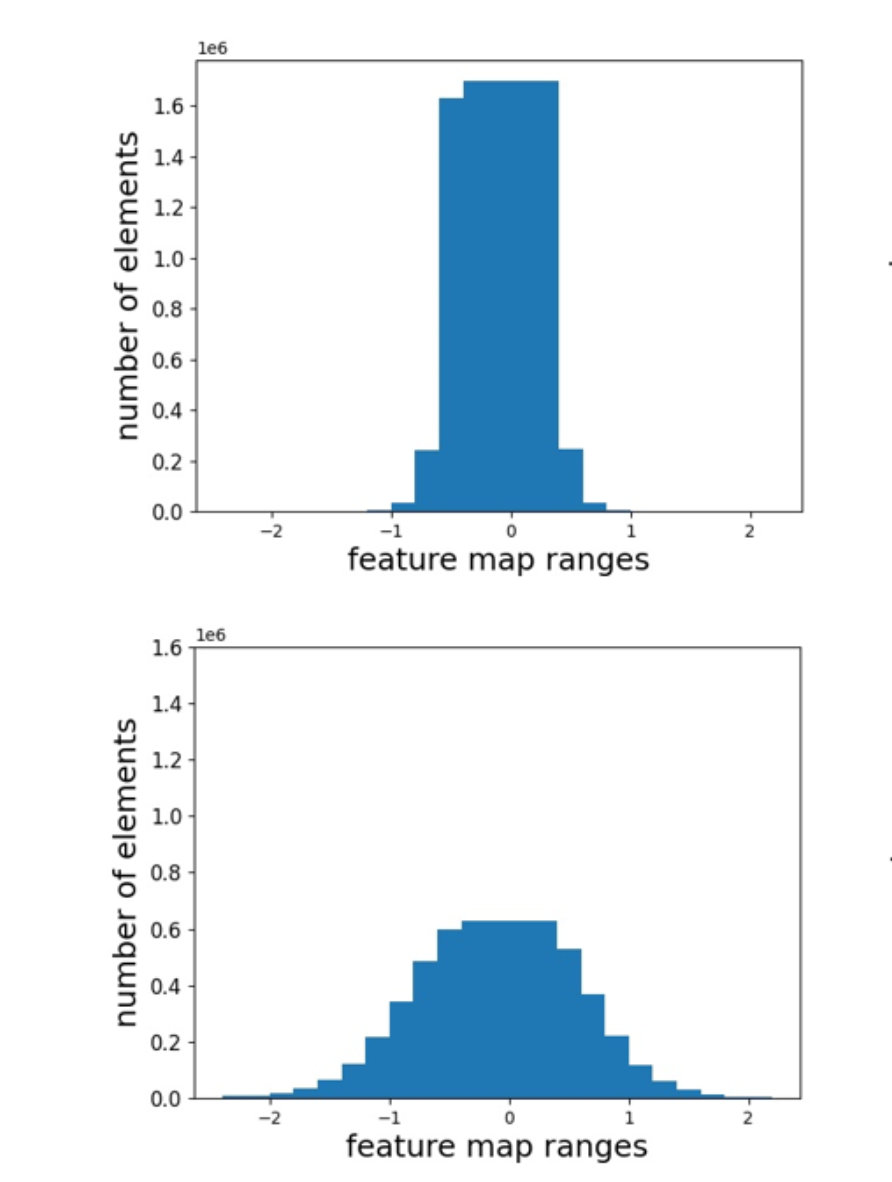 따라서 feature map을 teacher와 student 간에 직접 aligning하려는 것은 너무 strict constraints를 가하게 되어 student에게 해를 끼칠 수 있다.
따라서 feature map을 teacher와 student 간에 직접 aligning하려는 것은 너무 strict constraints를 가하게 되어 student에게 해를 끼칠 수 있다. - Figure 1 right에 나타나 있듯이, 몇몇 FPN stages의 value가 다른 stage보다 크다.
 teacher의 FPN stage 'P6'가 FPN stage 'P3'보다 덜 activated된 것이 분명하다.
teacher의 FPN stage 'P6'가 FPN stage 'P3'보다 덜 activated된 것이 분명하다.
그러나 RetinaNet 및 FCOS와 같은 detector의 경우, 모든 FPN stages는 동일한 detection head를 공유한다.
따라서 값이 큰 FPN stages가 distillation loss의 gradient를 지배할 수 있으며,
이는 다른 feature의 효과를 압도하고 sup-optimal results를 초래할 수 있다. - Figure 1 middle에 나타나 있듯이,
일부 channel의 value가 다른 channel보다 상당히 크다.
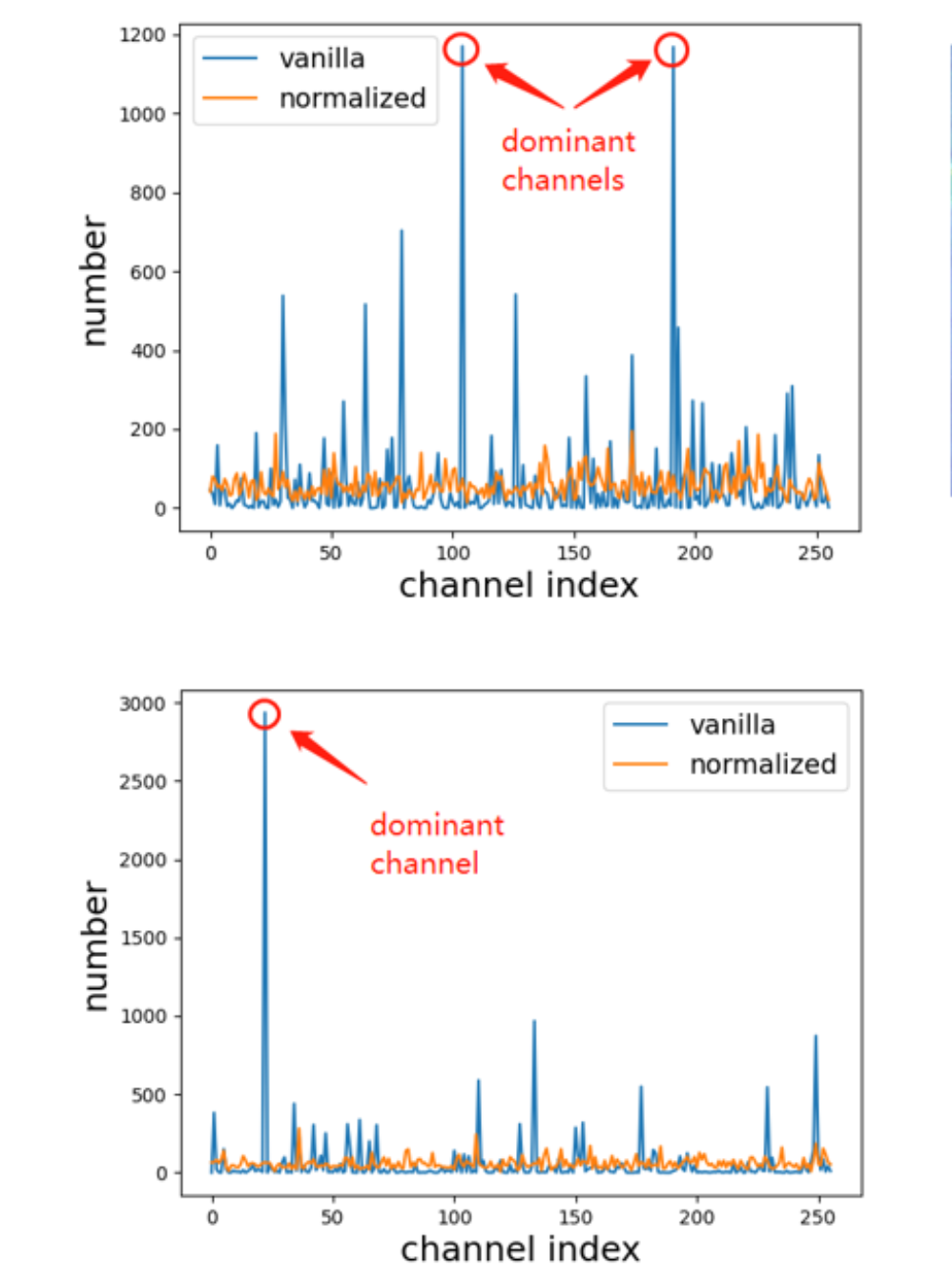 그러나 [35, 48]에 언급된 바와 같이, less activated features들도 distillation에 유용하다.
그러나 [35, 48]에 언급된 바와 같이, less activated features들도 distillation에 유용하다.
이들이 적절히 균형을 맞추지 않으면, less activated channels에서 생성된 작은 gradient가 dominant(지배적인) channel에서 생성된 큰 gradient에 의해 묻혀 refinement(세부 조정)이 제한될 수 있다.
또한, the first column of Figure 1 right에서 볼 수 있듯이
 특정 channel의 pixel value값이 다른 channel보다 현저히 크기 때문에, object-irrelevant area에 많은 noise가 있다.
특정 channel의 pixel value값이 다른 channel보다 현저히 크기 때문에, object-irrelevant area에 많은 noise가 있다.
따라서 feature map을 직접 imitating하는 것은 많은 noise를 도입할 수 있게 된다.
- teacher와 student의 feature value magnitudes는 다르며,
-
위 observations들에 따라서,
우리는 teacher와 student의 features 간의 lienar correlation에 중점을 두는Knowledge Distilation via Pearson Correlation Coefficient(PKD)를 제안한다. (Figure 2)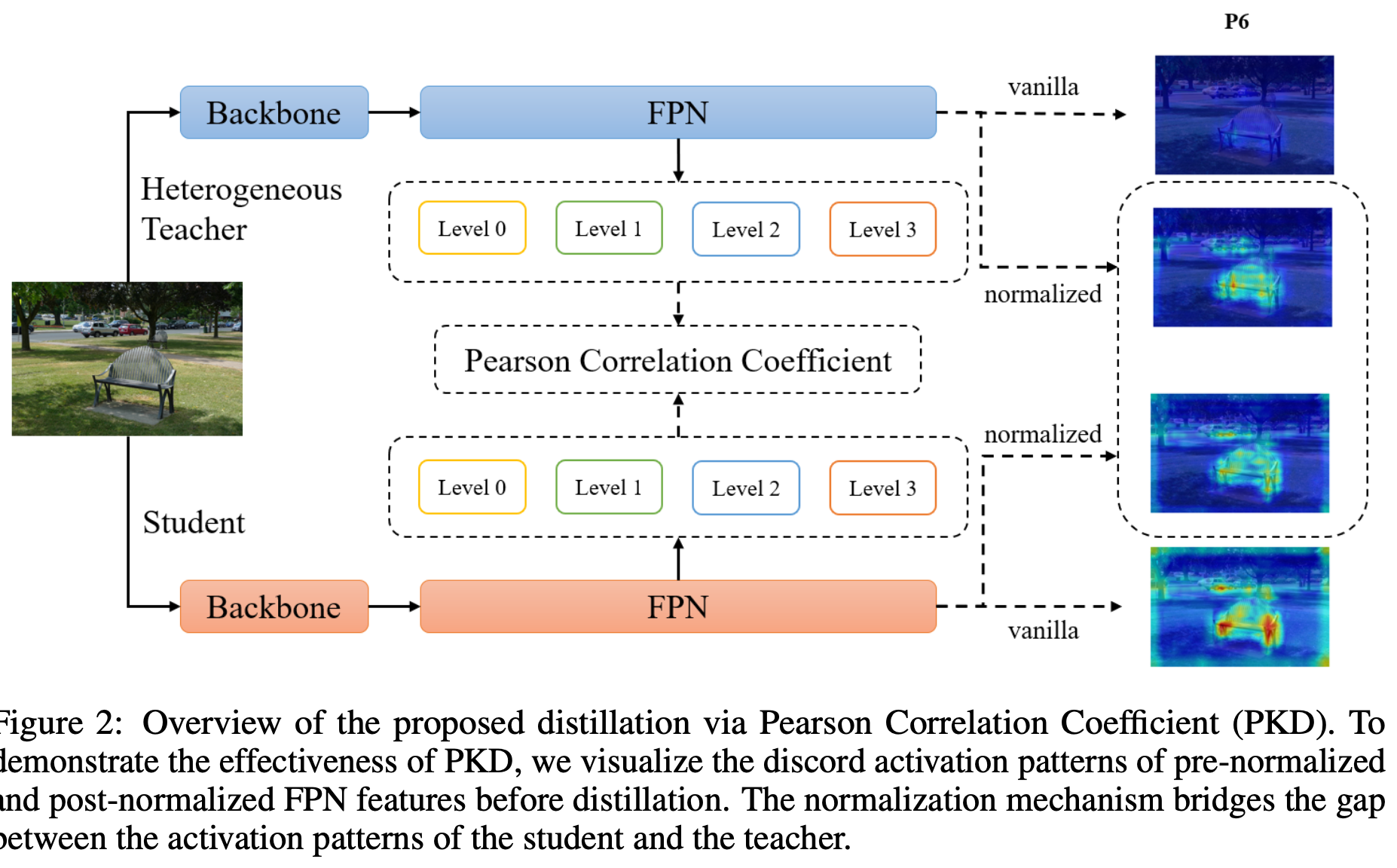 teacher-student detector pair 간의 서로 다른 FPN stages와 channel 내의 magnitude difference로 인한 부정적인 영향을 제거하기 위해,
teacher-student detector pair 간의 서로 다른 FPN stages와 channel 내의 magnitude difference로 인한 부정적인 영향을 제거하기 위해,
먼저 feature map을 zero mean and unit variances로 normalize하고
normalized features 간의 MSE loss를 minimize한다.
수학적으로 이는 두 original feature vectors 간의 Pearson Correlation Coefficient ()을 계산하고 을 feature imitation loss로 사용하는 것과 동일하다. -
이전 방법들과 비교했을 때,
우리의 방법은 다음과 같은 장점을 제공한다.- 첫째, distillation loss가 FPN features에서 계산되므로 heterogeneous backbone, heterogeneous detection heads and label assignmetn와 같은 training strategies을 포함한 heterogeneous detector에서 쉽게 적용될 수 있다.
- 둘째, teacher의 detection head를 거칠 필요가 없으므로 특히 cascaded heads를 가진 model의 경우 training time을 크게 단축시킬 수 있다.
또한 PKD는 이전 방법들보다 더 빠르게 수렴한다. - 마지막으로, 단 하나의 hyper parameter(distillation loss weight)만 있어서
다른 dataset에 쉽게 적용할 수 있다.
- 요약하면, 이 논문의 contributions은 threefold이다 :

2. Related Works
2.2 Knowledge Distillation
-
Knowledge Distillation(KD)는 teacher model이 student model로 knowledge를 transferring하는 model compression and acceleration approach이다.
이는 [16]에 의해 대중화되었으며, 이후 image classification에서의 효과가 후속 연구들에 의해 탐구되었었다. -
그러나 KD를 object detector에 적용하는 것은 nontrivial하다. (간단하지 않다)
student model에게 limited performance 향상만을 가져오기 때문이다.
이러한 문제를 해결하기 위해 기존의 methods에서는 다음 세 가지 strategies를 주로 채택했다.- 첫째, multi-scale intermediate features 간의 distillation이 일반적으로 수행되며,
이는 detection에 rich spatial information을 제공한다. - 둘째, foreground-background imbalance를 극복하기 위해 다양한 feature selection methods들이 제안되었다.
대부분의 이러한 연구들은 feature selection approach에 따라 세 가지 종류로 나눌 수 있다 : proposal-based, rule-based and attention-based - 셋째, 다양한 objects 간의 relation은 valuable information을 포함하고 있기 때문에,
많은 이전 연구들은 non-local modules, global distillation and structured instance graph와 같은 방법을 통해 detector의 성능을 향상시키고자 노력했다.
기존 연구들과 달리,
우리는 magnitude difference, dominant FPN stages and channels을 key problem으로 고려한다.
우리는 우리의 방법이 solid baseline이 되어 향후 object detectors의 knowledge distillation 연구를 용이하게 하기를 바란다.
- 첫째, multi-scale intermediate features 간의 distillation이 일반적으로 수행되며,
3 Method
3.1 Preliminaries
-
이 Part에서, 우리는 object detection에 대한 traditional knowledge distillation을 간단히 요약한다.
최근에는 detection을 위해 rich spatial information을 처리하기 위해 multi-scale features에 대한 feature-based distillation이 채택되었다.
서로 다른 imitation masks 은 foreground features에 대한 attention mechanism을 형성하고 background의 noise를 없애기 위해 제안되었다.
그 objective는 다음과 같이 formulated될 수 있다 :
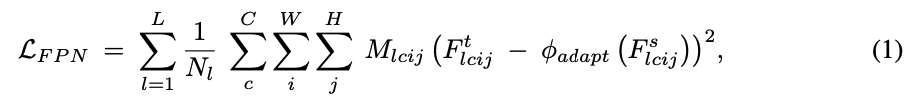 은 FPN layers의 개수이고,
은 FPN layers의 개수이고,
은 -th FPN layer를 나타내고,
은 width 와 height 를 갖는 feature map에 대응하는 location을 나타낸다.
과 는 각각 student와 teacher detector의 -th layer를 나타낸다.
는 만약 teacher와 studnet 간에 channel 개수 mismatch가 있다면 channel 개수를 upsample하기 위한 convolution layer이다. -
의 정의는 다음의 methods들과는 다르다.
예를 들어,
FRS [50]에서는 FPN layer에서 aggregated된 classification score map을 사용하고,
FGD [44]에서는 spatial attention, channel attention, object size and foreground-background information을 동시에 고려한다.
3.2 Is FPN feature imitation applicable for heterogeneous detector pairs?
-
대부분의 기존 연구는 FPN에서 distillation을 수행한다.
FPN은 backbone의 여러 layer를 통합하고 multi-scale objects의 풍부한 spatial information을 제공하므로,
student model이 동일한 detection head와 label assignmetn를 가진 homogeneous(동일한) teacher model로부터 FPN feature를 imitate하게 하는 것이 합리적이다.
이는 better features가 better performance로 이어질 수 있기 때문이다.
그러나 heterogeneous(두) detectors 간의 distillation에 대한 연구는 여전히 부족하다.
[44, 50]은 heterogeneous backbones을 가진 detector에 대한 실험을 수행했으나, heterogeneous detection head와 different label assignment를 가진 detector는 항상 제외되었다.
따라서 우리는 이러한 heterogeneous detector pairs에서도 FPN feature imitation이 여전히 유효한지 탐구하게 되었다. -
세 가지 popular detectors(GFLS, FCOS, RetinaNet)에서 backbone과 neck 교체 실험을 수행했다.
먼저, FCOS의 backbone과 neck을 12 epoch 동안 well-trained된 GFL의 backbone과 neck으로 교체했다.
feature-based distillation methods의 main idea는 teacher와 student의 feature activation을 직접 align(정렬)하는 것이므로,
이는 FCOS와 GFL 간의 feature imitation의 extreme case(극단적인 사례)로 간주될 수 있다.
그런 다음, 교체된 GFL backbone과 neck을 frozen한 상태에서 FCOS head를 finetuned했다.
실험 결과, GFL의 backbone과 neck으로 교체함으로써 detector의 성능이 36.5에서 37.6으로 향상되었다.
이는 FPN feature imitation이 heterogeneous 간에도 어느정도 적용 가능함을 확인해준다.
반면, RetinaNet의 backbone과 neck을 FCOS의 것으로 교체했을 때, FCOS head에서 group normalization으로 인한 feature value 크기 차이 때문에 mAP가 36.3에서 35.2로 크게 감소했다.
이는 두 heterogeneous detectors 간의 knowledge distillation에서 feature value의 크기 차이가 방해 요소가 될 수 있음을 의미한다.
3.3 Feature Imitation with Pearson Correlation Coefficient
- Section 3.2에서 discussed된 것처럼, promising feature distillation approach는
두 pairs 간의 imitation을 수행할 때 magnitude(크기)를 고려할 필요가 있다.
게다가, Figure 1에서처럼 activation patterns을 비교함으로써
중단 이유
- 나는 detector의 self-distillation(homogeneous)을 연구하기 위해 관련 논문을 찾고 있다.
이 논문은 두 detector 간의 distillation(heterogeneous)을 연구하고 있기 때문에
얼핏 비슷한 연구같지만 사실은 전혀 다른 연구이다..feature map의 activation magnitude 차이로 인해 두 detector 간의 feature imitation이 힘들다는 intuition만 얻고 논문 리뷰를 중단한다.
