[2020 PMLR] Deep Mixture of Experts via Shallow Embedding
[Paper Review] Efficient and Scalable
Paper Info
2020 PMLR (Proceedings of Machine Learning Research)

Abstract
-
Larger networks는 일반적으로 greater representational power를 갖지만, 그 대가로 computational complexity도 증가한다.
이러한 network를 sparsifying하는 것은 활발히 연구되어 온 분야이지만, 주로 static regularization 또는 RL을 사용하는 dynamic approaches에 제한되어 있다. -
우리는 per-example로 network의 certain experts를 activates하는 dynamic routing 방식의 MoE approach를 탐구한다.
새로운 DeepMoE architecture는 각 conv layer에서 channel-wise features를 adaptively sparsifying하고 recalibrating하여
standard conv networks의 representational power를 향상시킨다.
우리는 mluti-headed sparse gating network를 활용해 각 input에 대해 channel의 selection and scaling을 결정하며,
a single CNN 내에서 exponential combinations을 활용한다. -
제안된 architecture는 4개의 benchamrk dataset과 task에서 평가되었으며,
DeepMoE는 standard CNNs보다 lower computation으로 higher accruacy를 달성할 수 있음을 보여준다.
1. Introduction
- CV에서 network depth를 늘리는게 dominant trend가 되어 왔다.
그런데 depth가 증가하면 computational overhead and increased training time의 단점이 있다.
이와 같은 문제를 해결하기 위해, Shazeer et al. [22]는 최근 sparsely-gated MoEs design을 탐구했다.
이 model은 expert라고 불리는 단순한 network combination을 활용하여 전체 network의 output을 결정했다.
그 결과, shallow models이 computational costs를 줄이면서 prediction accuracy를 향상시킬 수 있음을 입증했다.
하지만 이 model의 SOTA translation acc를 회복하기 위해 기존 model보다 훨씬 큰 scale이 필요했다.
(문제 제기)
- 이를 확장하여, Eigen et al. [9]의 초기 연구는 MNIST digits classification에서 두 개의 MoEs models의 layer를 stacking하는 방식의 장점을 보여줬다.
이러한 결과를 바탕으로 자연스럽게 다음과 같은 질문이 제기된다:
"can we stack and train many layers of mixture of experts models to improve accuracy and reduce prediction cost without radically increasing the network width?"
= "MoE models의 많은 layers들을 stack and train하여 network width를 급격하게 늘리지 않고도 acc를 향상시키고 prediction cost를 줄일 수 있을까?"
(key challenges)
- 이 논문에서, 우리는 deep mixture of experts models (DeepMoEs)의 design을 탐구한다.
DeepMoEs는 deep models의 향상된 acc와 sparsely-gated MoEs의 computational efficiency을 결합한 구조이다.
하지만 DeepMoEs를 설계하고 학습하는 데에는 몇 가지 key challenges가 있다.- mixture decisions이 network layer 간에 상호작용하여, joint reasoning and optimization을 요구한다.
- discrete expert selection process는 non-differentiable하므로, gradient-based training을 복잡하게 만든다.
- 여러 MoE models을 composition할 경우, 각 layer에서 퇴행적(즉, singular(단수)) combinations of experts가 발생할 가능성이 증가한다.
(제안)
- 이러한 challenges를 해결하기 위해, 우리는 a general DeepMoE architecture를 제안한다.
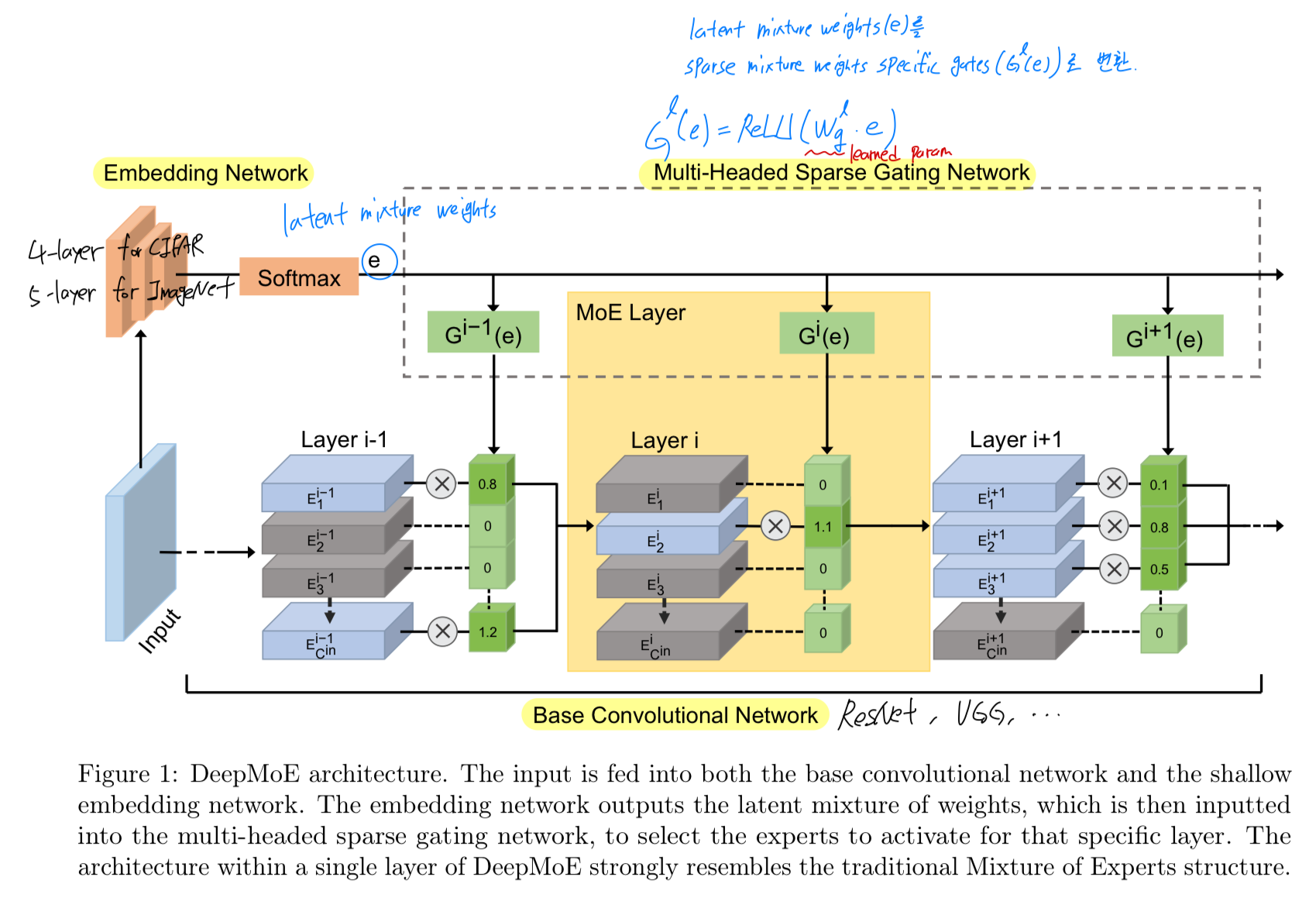
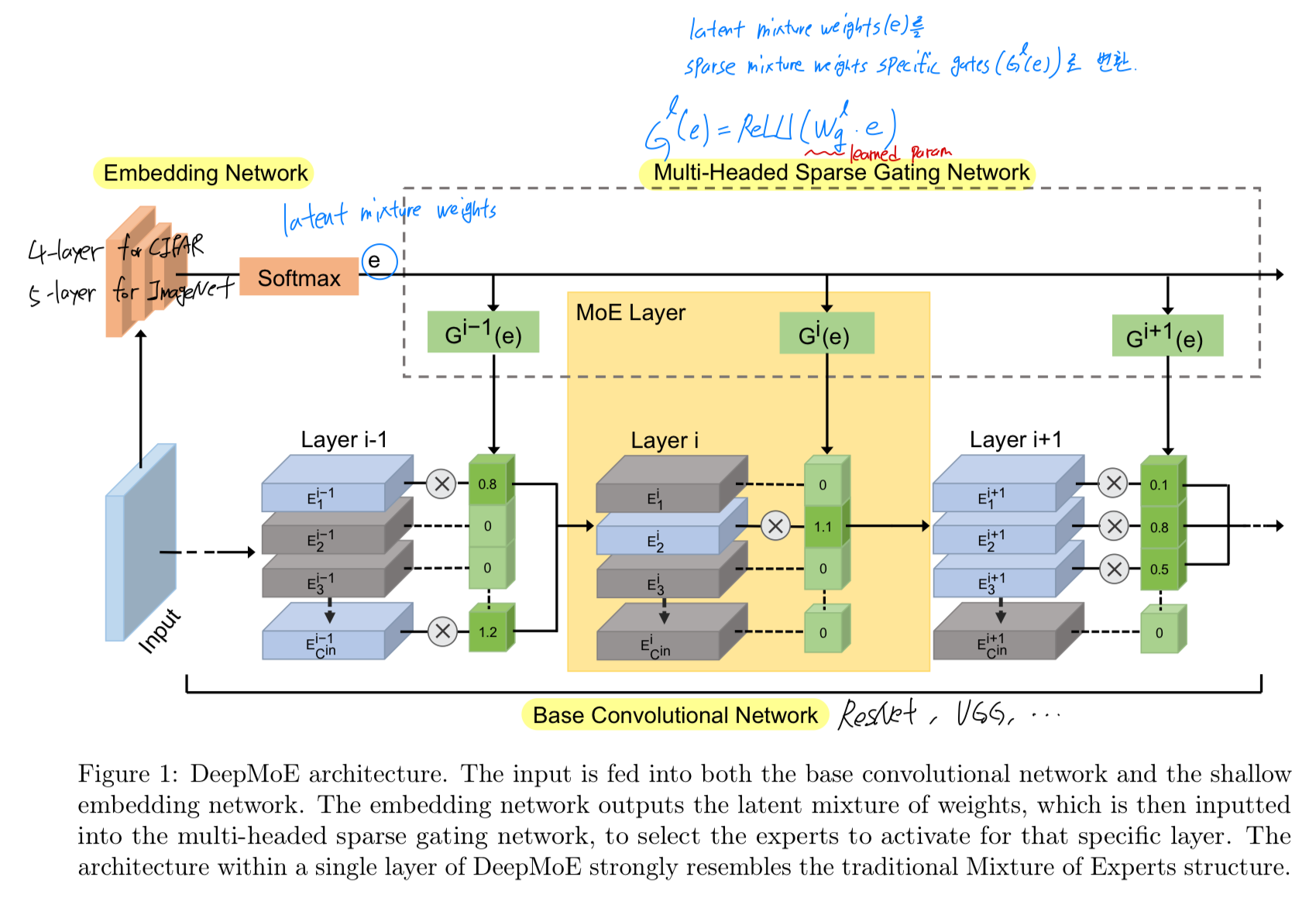
이 architecture는 a deep CNN, shallow embedding network, a multi-headed sparse gating network를 결합한 구조이다. (Fig. 1)
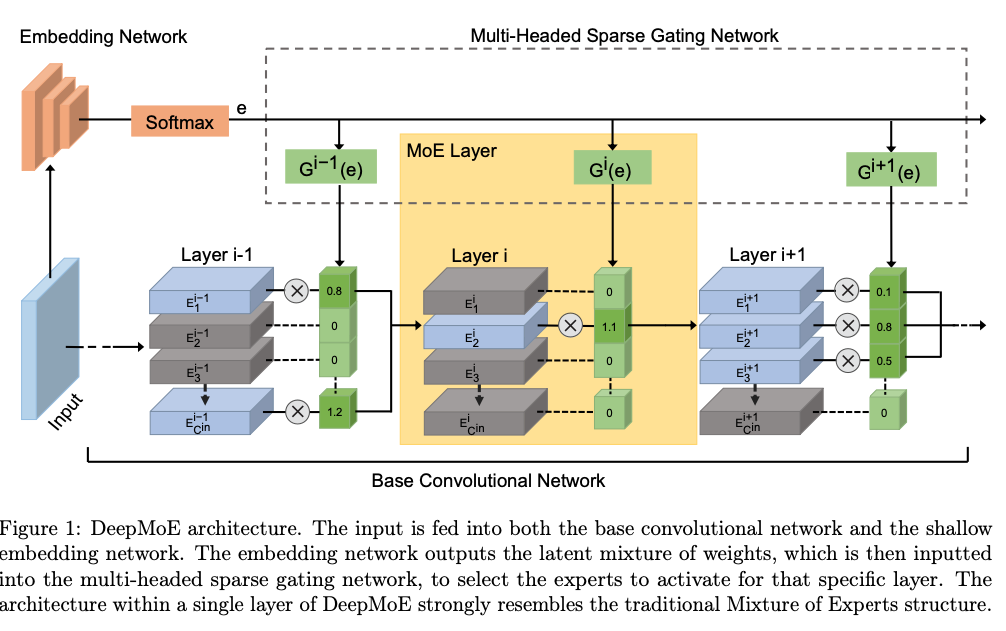 shallow embedding network는 soft-max output layer에서 종료되며,
shallow embedding network는 soft-max output layer에서 종료되며,
a fixed set of latent experts에 대한 latent(잠재) mixture weights를 계산한다.
이 latent mixture weights는 multi-headed sparse gating networks (with ReLU outputs)에 전달되어,
base CNN의 각 layer에 대한 channels을 re-weights한다.
우리는base model,shallow embedding network, andmulti-headed gating network를 jointly train하며,
embedding network에 대한 auxiliary classification loss function과 gating network outputs에 대한 sparse regularization을 적용하여
latent mixture weights에 대한 diversity와 layer selection에 대한 sparsity를 장려한다.
이를 통해 expert utilization을 균형 있게 유지하고 computation costs를 낮춘다.
- 최근 연구 [5]에 따르면, deep neural network의 expressive power는 network의 width를 기준으로 depth에 따라 super-exponentially 증가한다고 입증되었다.
우리는 다수의 MoE layers를 stacking하고 sparse channel weights를 dynamically generating함으로써,
DeepMoEs가 unsparsified deep networks의 expressive power를 유지한다는 것을 Sec. 4에서 분석한다.
이 theoretical analysis를 바탕으로, 우리는 wide-DeepMoE와 narrow-DeepMoE라는 two variants를 제안하여,
standard CNN과 비교했을 때 acc를 향상시키고 computational cost를 줄인다.- wide-DeepMoEs에 대해서,
우리는 standard CNN의 #channels을 두 배로 늘리고,
widened(확장된) conv layers를 MoE layers로 대체한다.
실험 결과, inference 시 widened layer의 channel 중 절반만 선택해도 model capacity 증가로 인해
더 높은 prediction acc를 달성하며, 계산 비용은 unwidened network와 동일하기 유지된다. - narrow-DeepMoEs에 대해서,
standard CNN의 conv layer를 MoE layer로 직접 대체한다.
이는 기존의 dynamic channel pruning 연구 [18]을 일반화하며, 기존 channel pruning literature보다 more accurate and more efficient model을 생성한다.
- wide-DeepMoEs에 대해서,
- Our contributions can be summarizedas:
- inference시 network의 일부를 dynamically 선택하고 실행할 수 있는 novel DeepMoE design을 제안했다.
- 제안된 DeepMoE design이 computational cost를 줄이면서도 standard CNN의 expressive power를 유지함을 이론적으로 분석했다.
- 다양한 benchmarks에서 기존 방법보다 더 정확하고 효율적인 two DeepMoE variants를 추가로 도입했다.
2. RELATED WORK
Mixture of experts
- 우리는 layer outputs 대신 a shared shallow embedding을 기반으로 수백 개의 MoE layer로 deep models을 구성하며,
이를 통해 DeepMoE가 gate decisions이 미리 결정되므로 batch parallelism이 가능한 parallel HW에 더 적합하도록 만든다.
또한 multi-layer MoE models의 design and training에서 발생하는 여러 key challenges를 해결한다.
최근에는 MoE design이 다양한 apps에 적용되었다.
Conditional computation
- MoEs와 관련하여, Bengio et al. [2, 3, 4]의 최근 연구는 input에 따라 network의 일부만 선택적으로 실행하는 conditional computation을 neural networks의 맥락에서 탐구했다.
그들은 discrete selection decisions을 위해 RL을 사용했으나,
우리의 sparsely-gated가 있는 DeepMoE design은 standard CNN에 embedded할 수 있으며,
SGD를 사용하여 optimized할 수 있다.
Dynamic channel pruning
-
storage와 computation overhead를 줄이기 위해 많은 연구들은
network의 각 layer에서 entire channel을 제거하는 channel level pruning을 탐구했으며,
이를 통해 structured sparsity를 유도했다.
그러나 channel을 영구적으로 dropping하는 것은 network capacity를 제한한다.
conditional computation과 channel pruning을 연결하는 최근 연구들은 dynamic pruning을 탐구했으며,
이는 이전 layer의 output을 기반으로 각 layer에서 개별 channel 또는 entire layers를 dynamically drop하는 per-layer gating networks를 사용했다.
따라서 dropped될 channels은 input에 따라 달라지며, 이는 static pruning techniques을 적용하는 network보다 더 expressive network를 만든다. -
conditional computation에 대한 연구처럼, dynamic pruning은 sample inefficient RL techniques에 의존한다.
본 연구에서는 dynamic channel pruning에 대한 이전 연구를 확장하여,
더 효율적인 shared convolutional embedding and simple ReLU based gating을 도입하고,
이를 통해 sparsification and feature re-calibration을 가능하게 하여 SGD를 사용한 end-to-end training을 허용했다.
3. DEEP MIXTURE OF EXPERTS
- 이 section에서, 우리는 DeepMoE formulation을 먼저 설명하고
detailed architecture design and loss function formulation을 소개할 것이다.
3.1. MIXTURE OF EXPERTS
- original MoEs formulation은
주어진 input 에 대한 distribution을 return하는 a mixture (gating) function 를 사용하여
a set of experts (classifiers), , ..., 를 결합하는 것이다.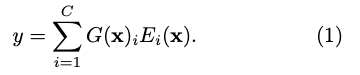 여기서 는 expert 에 assigned되는 weight이다.
여기서 는 expert 에 assigned되는 weight이다.
나중 연구 [7]에서는 gating function 가 experts에 대한 probabilities 대신 arbitrary(임의의) weights를 출력하는
non-probabilistic setting(비확률적 설정)으로 MoE formulation을 일반화했다.
우리는 이 non-probabilistic setting이
expert outputs의 re-scaling and composing에 대한 flexibility를 증가시킬 수 있기 때문에
이 non-probabilistic setting 관점을 채택했다.- non-probabilitic setting이 뭘까?
전통적인 MoE formulation에서는 gating function이 각 expert에 대한 확률을 출력했지만,
non-probabilistic setting에서는 확률값이 아닌 임의의 가중치를 출력함. - non-probabilistic setting은 왜 flexibility가 더 좋은거지?
probabilities는 모든 확률의 합이 1이되어야 하므로 특정 expert에 큰 가중치를 부여하려면 다른 experts의 가중치를 낮춰야 함..
이는 특정 expert의 중요성을 충분히 반영하지 못 할 수 있음.
그래서 flexibility가 떨어지는 듯.
- non-probabilitic setting이 뭘까?
3.2. DEEPMOE FORMULATION
-
이 연구에서는 DeepMoE architecture를 제안한다.
이 architecture는 standard single-layer MoE model을 하나의 CNN network 내에서 여러 layer로 확장한다.
traditional MoE frameworks는 experts의 model level combinations에 초점을 맞추는 반면,
DeepMoE는 single model 내에서 각 channels을 expert로 간주하여 작동한다.
각 MoE layer의 experts들은 이전 convolution 연산의 output channels로 구성된다. -
이 section에서는 conv layer에서의 gated된 channels과 classic MoE formulation 간의 equivalence를 유도한다.
input tensor 가 spatial resolution 와 input channels을 가지며,
dimension 의 conv kernel 을 갖는
conv layer는 다음과 같이 쓸 수 있다:
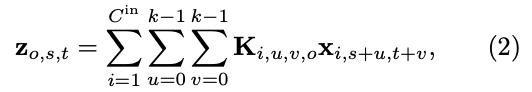 여기서 는 output tensor이다.
여기서 는 output tensor이다.
MoE conv layer를 구성하려면 해당 layer의 gate values 을 사용하여 input channels을 scale하고,
rearrange한다: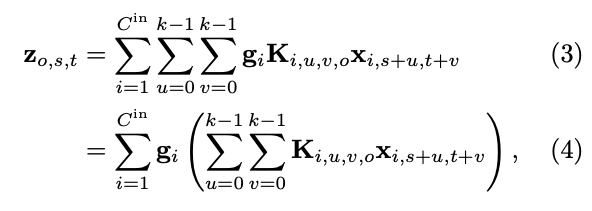 convolution operator 을 정의하면서, (4)의 summations과 subscripts를 제거할 수 있어 다음과 같이 쓸 수 있다:
convolution operator 을 정의하면서, (4)의 summations과 subscripts를 제거할 수 있어 다음과 같이 쓸 수 있다: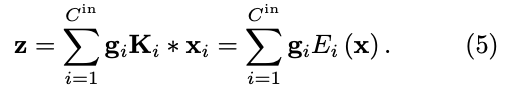 따라서 input channels을 conv network에 gating하는 것이 각 output channel에 대해 MoEs를 구성하는 것과 같다는 것을 보였다.
따라서 input channels을 conv network에 gating하는 것이 각 output channel에 대해 MoEs를 구성하는 것과 같다는 것을 보였다. -
이후 section에서는 각 layer에 대해 gate values 를 얻는 방법을 설명하고, 개별 MoE layer를 어떻게 효율적으로 구성하고 훈련할 수 있는지에 대해 설명한다.
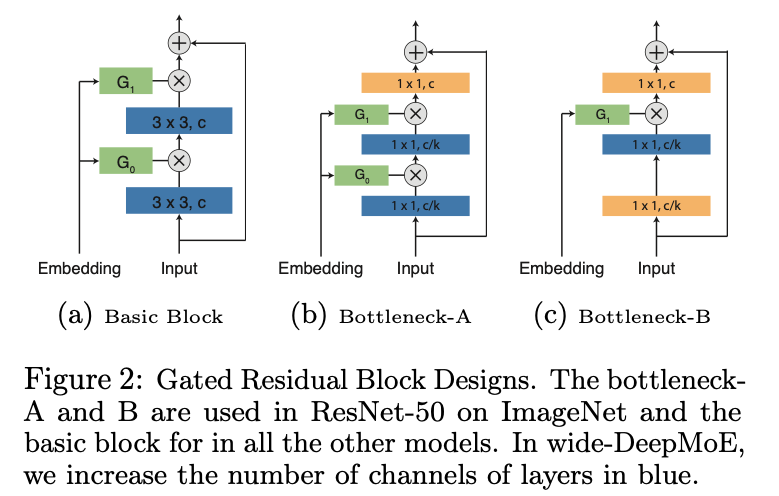
3.3. DEEPMOE ARCHITECTURE
- DeepMoE는 three components로 이루어져 있다:
- a base conv network,
- a shallow embedding network,
- and a multi-headed sparse gating network
-
base conv network는 각 conv layer가 앞서 설명한 MoE conv layer로 대체된 deep network이다.
실험에서는 ResNet과 VGG를 base conv networks로 썼다. -
shallow embedding network는 raw input image를 latent(잠재) mixture weights로 mapping하여 multi-headed sparse gating network에 전달한다.
embedding network의 computational overhead를 줄이기 위해,
4-layer (for CIFAR) or 5-layer (for ImageNet) CNN을 사용하며,
각 layer는 with 3-by-3 filters with stride 2(base models의 computation의 약 2%)를 갖는다. -
multi-headed sparse gating network는 shallow embedding network에서 생성된 latent mixture weights를 각 conv network의 sparse mixture weights로 변환한다.
layer 에 대한 gate는 다음과 같이 정의된다:
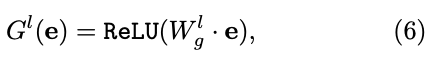 여기서 는 shared embedding network 의 output이고,
여기서 는 shared embedding network 의 output이고,
는 learned parameters로, ReLU 연산을 사용하여 latent mixture weights를 sparse layer specific gates로 변환한다.
우리는 이 gating design을 on demand gating이라고 부른다.
각 level에서 선택된 #experts는 data에 따라 달라지며, 서로 다른 layer에서 expert selection을 jointly optimzed할 수 있다.
[22]의 "noisy Top-K" design과 달리, 각 layer에서 #experts를 미리 정할 필요가 없으며, 실제로 각 layer는 다른 #experts를 사용할 수 있다.
3.4. DEEPMOE TRAINING
-
standard CNNs처럼, DeepMoE models도 gradient based methods를 사용하여 end-to-end trained될 수 있다.
DeepMoE의 overall goals은 threefold이다:- high prediction acc 달성
- lower computation costs
- keep the network highly expressive
-
따라서 DeepMoE는 각 input에 대해 diverse, low-cost MoEs를 선택학하는 gating policy를 학습해야 한다.
이를 위해 input 와 target 가 주어졌을 때, learning objective는 다음과 같이 정의된다:
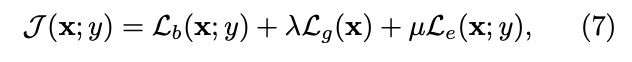 여기서 는 base conv model에 대한 cross entropy loss로, high prediction accuracy를 촉진한다.
여기서 는 base conv model에 대한 cross entropy loss로, high prediction accuracy를 촉진한다.
term은 다음과 같이 정의된다:
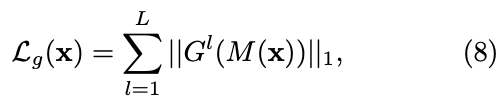 이 term은 gating network에서 sparsity를 장려함으로써 computational cost를 제어하는 데 사용된다( parameter를 통해).
이 term은 gating network에서 sparsity를 장려함으로써 computational cost를 제어하는 데 사용된다( parameter를 통해).
마지막으로, 추가적인 embedding classification loss 를 도입했다.
이는 cross-entropy classification loss로, embedding 또는 embedding의 변환이 class label을 예측하도록 유도하여 gating network가 converging to an imbalanced utilization of experts 현상을 방지한다.
이 loss 구조의 intuition은 same class에서 나온 examples들은 비슷한 embedding을 가져야 하며, 따라서 비슷한 subsequent gate decision을 내려야 한다는 것이다.
반면, 서로 다른 class의 examples들은 다른 embedding을 가지게 되어, network가 a certain subset of channels을 over-using(과도하게 사용하는 것)을 방지한다. -
DeepMoE loss는 all three sub-networks를 jointly train하기 위해 stochastic gradient descent를 사용한다.
학습이 완료되면, 와 를 0으로 설정하고 a few more epochs을 학습하여 base conv net을 refine한다.
The full training algorithm은 Procedure 1에 설명되어 있다.

4 EXPRESSIVE POWER
skip
5 EXPERIMENTS
wide-DeepMoE
wide-DeepMoE는 conv network의 #channels을 늘려 network의 표현력을 높인 후, 확장된 layer를 MoE layer로 대체.
실험 결과, wide-DeepMoE는 standard ResNet보다 낮은 prediction error rate를 보임
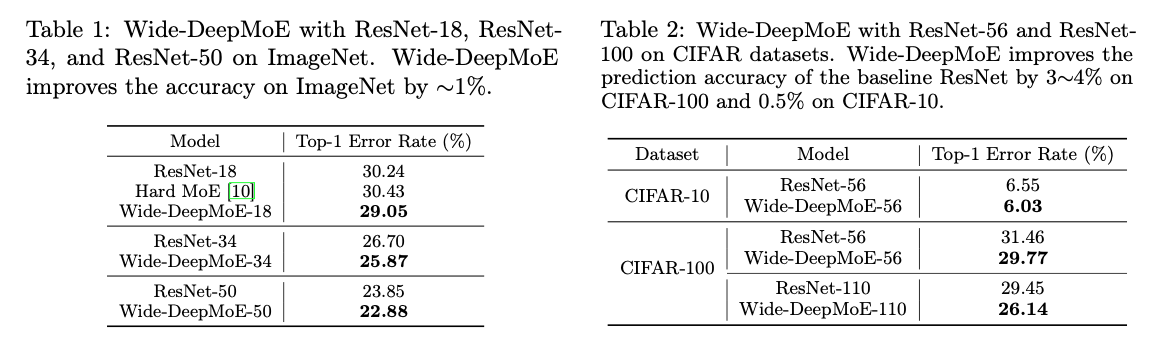
narrow-DeepMoE
narrow-DeepMoE는 standard conv layer를 MoE layer로 직접 대체.
narrow-DeepMoE는 기존의 dynamic and static channel pruning보다 prediction acc에서 우수하면서 computaional costs를 유지하거나 줄임.
Critique
- DeepMoE는 gating network와 embedding network에 대한 추가적인 memory space를 필요로 함..
이는 memory 용량이 제한된 system에서 사용이 어려울 수도 있음.
