[2018 arXiv][Simple Review] (YOLOv3) YOLOv3: An Incremental Improvement
[Paper Review] 2D Object Detection
Info
paper: YOLOv3: An Incremental Improvementauthor: Joseph Redmon, Ali Farhadisubject:
1. Introduction
- 나는 YOOLO에 대한 몇가지 improvement를 다뤘었다.
- 하지만 이 논문에서는 super interesting한 것은 없다.
- 단지 기존의 YOLO를 더 좋게 만드는 조그마한 변화를 소개할 것이다.
이 논문은 TECH REPORT에 가깝다.- 우리는 이 tech report에서 다음의 내용들을 말할 것이다.
- First we’ll tell you what the deal is with YOLOv3.
- Then we’ll tell you how we do.
- We’ll also tell you about some things we tried that didn’t work.
- Finally we’ll contemplate what this all means.
2. The Deal
- 우리는 다른 사람들로부터 좋은 아이디어들을 착안한 YOLOv3를 다룰 것이다.
2.1 Bounding Box Prediction
-
YOLO9000과 같이 YOLOv3는 dimension clusters로써 anchor boxes를 사용하여 bounding box를 예측한다.
(사전에 설정한 anchor box(검은 점선)를 갖고 bbox를 예측.)
network는 각 bbox마다, 4개의 coordinates 를 예측한다.
만약 cell이 image 왼쪽 상단으로부터 offset을 갖고 있고,
bbox의 width and height가 라면,
prediction은 다음과 같다.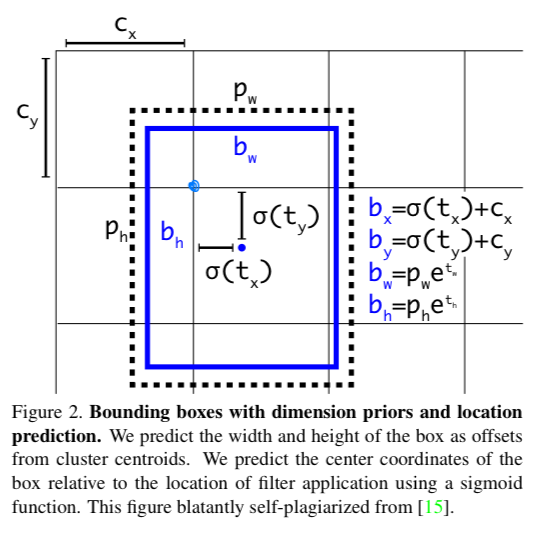 Durining training we use sm of squared error loss.
Durining training we use sm of squared error loss. -
YOLOv3 predicts an objectness socre (=confidence score?) for each bbox using logistic regression.
만약 다른 bbox prior보다 ground truth와 IOU가 크다면, objectness score가 1이 되어야 함. -
Unlike [17] our system only assigns one bounding box prior for each ground truth object.
If a bounding box prior is not assigned to a ground truth object
it incurs no loss for coordinate or class predictions, only objectness.
2.2 Class Prediction
- each box predicts the classes the bbox may contain using multilabel classification.
"We do not use a softmax as we have found it is unnecessary for good performance,
instead we simply use independent logistic regression"- 왜냐하면, 더 복잡한 domain을 갖는 Dataset들에 대해서는 overlapping labels가 너무 많음.
예를 들어, Woman and Person은 똑같은 domain이지만
softmax는 각 box를 정확히 한 class로 assumption하기를 강요하기 때문에
multilabel classification에 좋지 않음.
이를 위해, Woman에 대해서 1 Person에 대해서 1로 predict할 수 있는 logistic regression을 사용함.
- 왜냐하면, 더 복잡한 domain을 갖는 Dataset들에 대해서는 overlapping labels가 너무 많음.
2.3 Predictions Across Scales
-
YOLOv3 predicts boxes at 3 different scales.
We predict 3 boxes at each scale.
The last of predicts a 3-d tensor encoding bbox, objectness, and class predictions.- so the tensor is
for the 4 bbox offsets, 1 objectness prediction, and 80 class predictions.
- so the tensor is
-
We still use -means clustering to determine our bbox priors.
We just sort of chose 9 clusters and 3 scales arbitrarily and then
divide up the clusters evenly across scales.
2.4 Feature Extractor
- 우리는 feature extraction을 위해서
YOLOv2에서 사용했던 Darknet-19에 최신의 residual network 기술을 혼합한 접근 방식을 사용한다.
우리의 network는 3 × 3과 1 × 1 conv layer를 사용하지만
some shortcut connection이 추가되어 매우 크다.
이것은 53개의 conv layer를 가지고 있으니, Darknet-53이라고 부를 것이다.
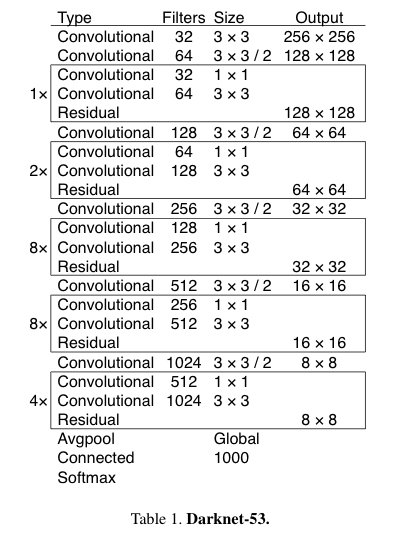
 Darknet-53은 더 적은 floating point operations과 더 빠른 speed로 state-of-the-art classifer로 동작함.
Darknet-53은 더 적은 floating point operations과 더 빠른 speed로 state-of-the-art classifer로 동작함.
또한 BFLOP/s가 가장 높음.
이는 GPU 효율이 더 좋다는 의미이고, 이게 더 빠르고 효율적으로 만드는 것이다.
4. Things We Tried That Didn't Work
Anchor box offset predictions.
Linear predictions instead of logistic
- We tried using the normal anchor box prediction mechanism where. you predict the offset as a multiple of the box width or height using a linear activation.
We found this formulation decreased model stability and didn't work very well.
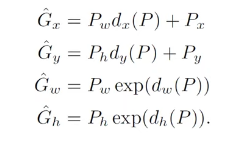
Focal loss
- We tried using focal loss.
It dropped our mAP about 2 points.
Dual IOU thresholds and truth assignment
- We tried dual IOU threshold but couldn't get good results.
5. What This All Means
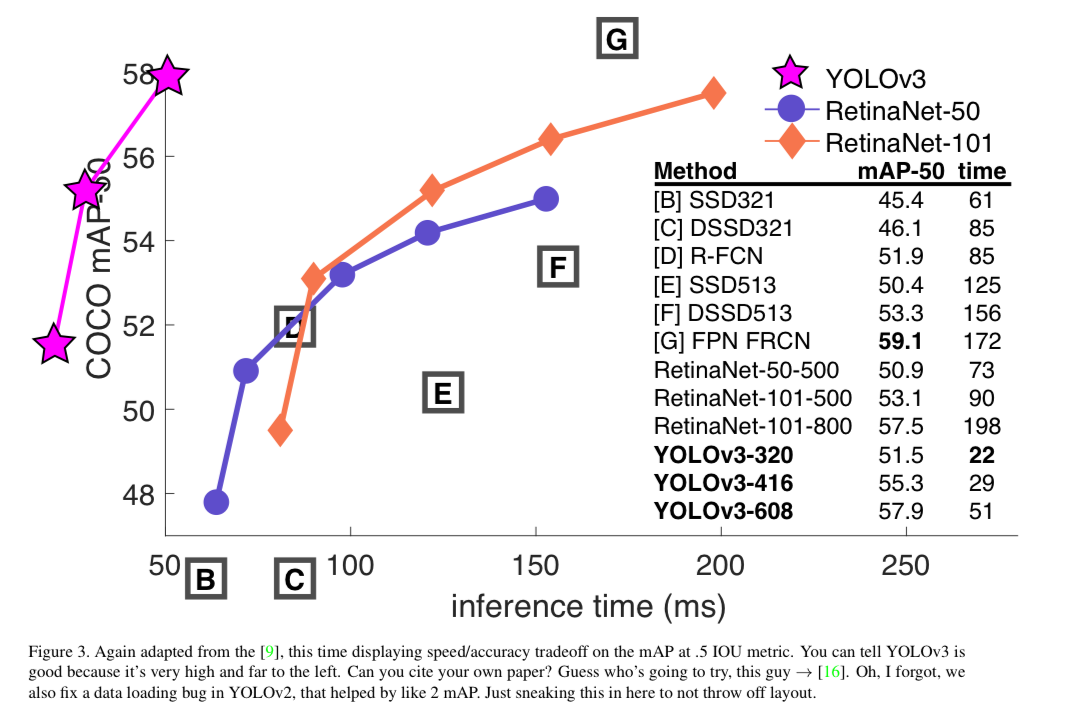
- It's not as great on the COCO average AP between .5 and .95 IOU metric.
But it's very good on the old detection metric of .5 IOU.
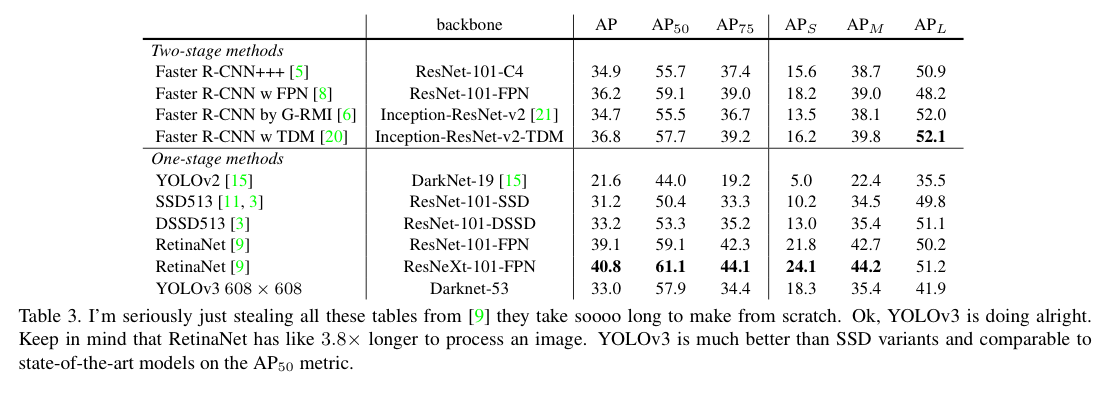
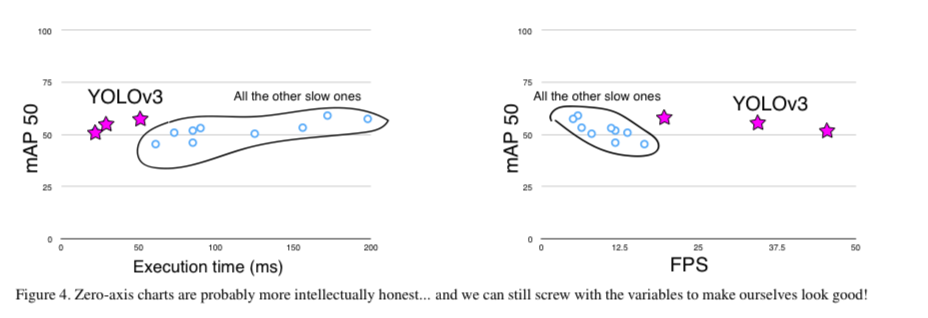
- (COCO dataset에 대한 비판)
"Training humans to visually inspect a bbox with IOU of 0.3 and distinguish it from one with IOU 0.5 is surprisingly different."
If humans have a hard time telling the difference, how much does it matter?
인간도 IOU가 0.3인지 0.5인지 구분하는 것을 매우 어려워하는데,
COCO에서 0.5 ~ 0.95까지 GT까지 매우 유사하게 그리는 것이 굳이 필요한지? 지적하는 내용...
