[2015 NeurIPS] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[Paper Review] 2D Object Detection
Info
paper: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networksauthors: Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sunsubmission: Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems 28 (2015).
사전지식
- R-CNN ➡️ SPPnet ➡️ Fast R-CNN ➡️
Faster R-CNN
R-CNN
-
Algorithm- input image에 selective search algorithm을 이용하여 2k개의 region proposal을 생성
- 2k개 각각의 region proposal을 고정된 크기로 warping하여 CNN input으로 사용.
(CNN은 ImageNet을 활용한 pre-trained network들을 사용 + fine tune(object detection용 dataset)) - CNN을 거친 feature map을 사용하여 class 별로 SVM Classifier를 학습, regressor를 통한 Bounding box regression을 진행.
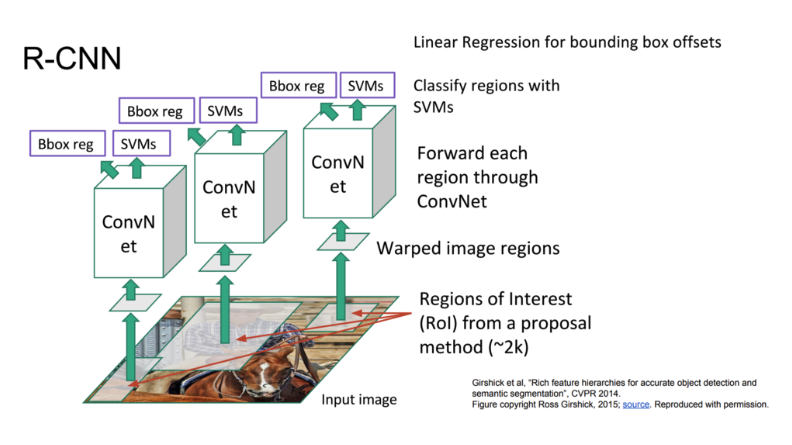
-
단점 :
- 2k개 region proposal마다 CNN을 적용해야 하기 때문에 시간이 오래 걸림
- 학습이 여러 단계(conv, SVM, Bounding box regression)로 이루어지기 때문에 학습이 오래 걸림, 대용량의 storage 필요
- object detection 속도 느림
Fast R-CNN
Algorithm:
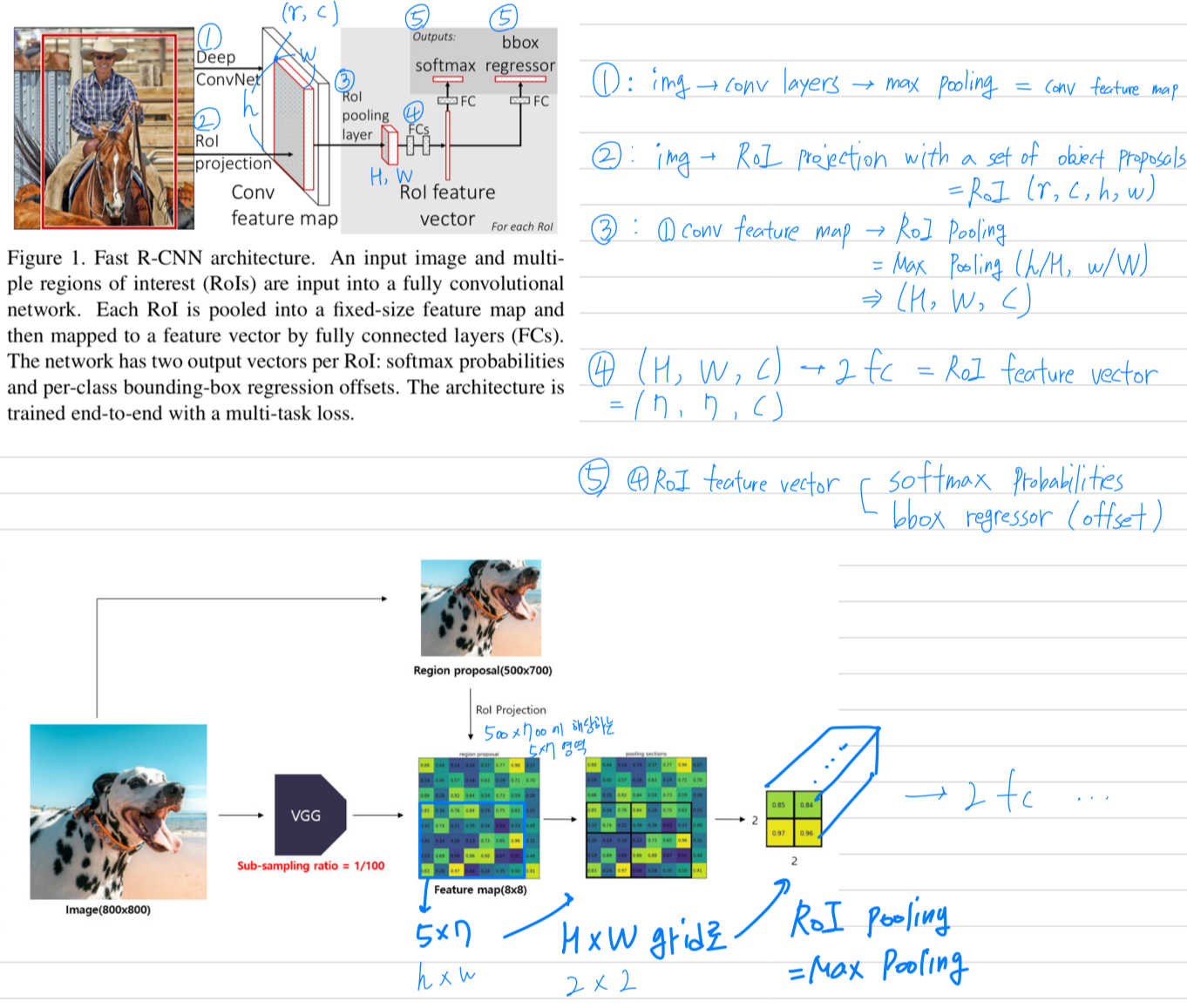
1. Introduction
- 최근 object detection의 발전은 region-based convolutional neural network에 기반한다.
Fast R-CNN에서 region proposal에 드는 시간만 제외한다면, 거의 real-time을 달성했다.
이제, proposal은 state-of-the-art detection system에서
test-timee computational bottleneck이 되었다.- 가장 대표적인 region proposal 방법인 Selective Search는 efficient detection networks와 비교했을 때, 매우 느리다.
Selective Search보다 더 빠른 속도를 갖는 EdgeBoxes도
여전히 detection network만큼의 running time이 소요된다.
- 가장 대표적인 region proposal 방법인 Selective Search는 efficient detection networks와 비교했을 때, 매우 느리다.
-
이 논문에서,
우리는 deep convolutional neural network를 사용하여
proposals 제안을 computing하는 algorithmic change가
detection network's computation을 고려할 때,
proposal 계산 비용이 거의 들지 않는 solution으로 이어진다는 것을 보여줄 것이다.
이를 위해, state-of-the-art object detection networks과 conv layer를 공유하는
새로운Region Proposal Networks(RPNs)을 소개할 것이다.
test-time에 convolutions을 공유함으로써, proposal을 computing하는 데 드는 추가 비용이 적다. -
우리가 관찰한 결과,
Fast R-CNN과 같은 region-based detectors에 의해 사용되는
convolutional feature maps을
region proposal을 생성하는 데에 사용할 수 있다. -
이러한 convolutional features에,
우리는 각 location에서 regular grid와 object score를 동시에 regression하는
몇 개의 conv layer를 추가하여 RPN을 만들었다.- 따라서 RPN은 fully convolutional network (FCN)의 한 유형이며,
detection proposals을 생성하는 task에 대해서 end-to-end train될 수 있다.
- 따라서 RPN은 fully convolutional network (FCN)의 한 유형이며,
-
RPNs은 다양한 scale과 aspect ratios를 가진 region proposal을
효율적으로 예측하기 위해 설계되었다.
이전의 method(Figure a., Figure b.)와는 달리,
여러 scale과 aspect ratio에서 references로 작동하는 새로운anchorboxes를 도입했다.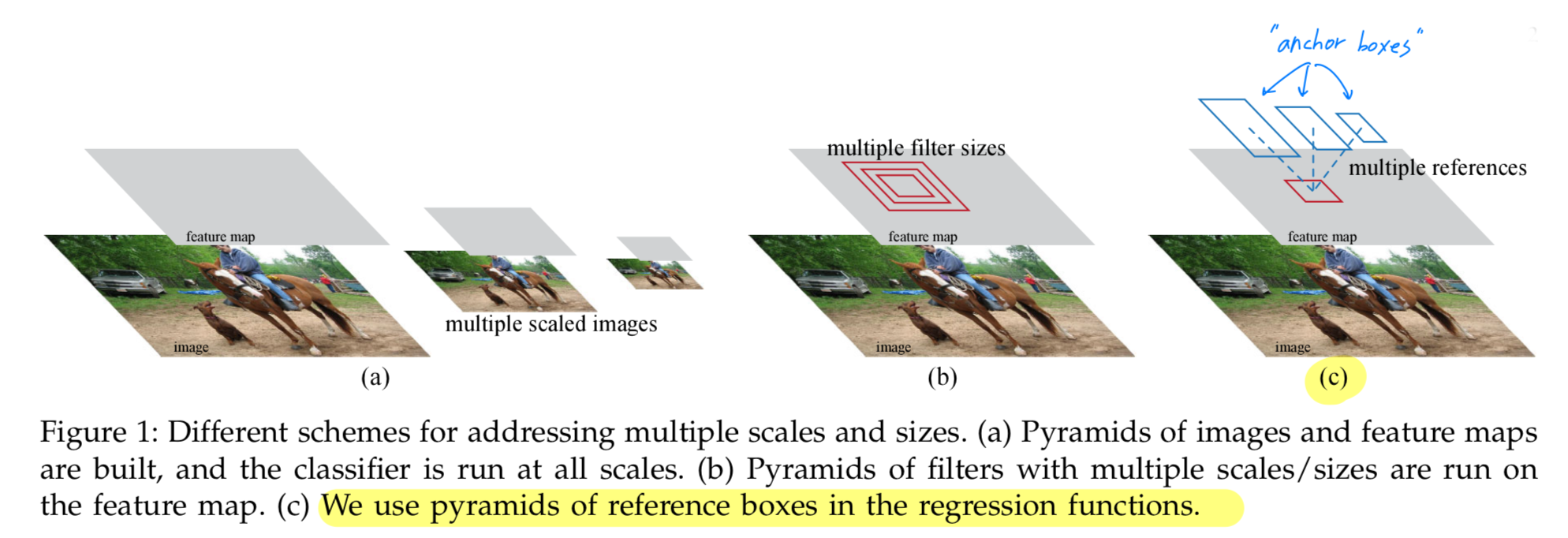
- anchor boxes를 regression references의 pyramid로 생각할 수 있으며,
이는 여러 scale이나 aspect ratios의 image 또는 filter를 열거하는 것을 피한다.
즉, single-scale images를 사용하기 때문에 train 및 test될 때 실행 속도에 이점이 있다.
- anchor boxes를 regression references의 pyramid로 생각할 수 있으며,
-
RPN과 Fast R-CNN object detection networks를 통합시키기 위해,
우리는 region proposal에 대한 fine-tuning과 object detection에 대한 fine-tuning 간을
왔다갔다하며 region proposal을 고정시키는 training scheme을 제안한다.
이 scheme는 빠르게 수렴하며 두 작업 간에 공유되는 convolutional features을 가진 unified network를 생성함.
2. Related Work
Object Proposals
- object proposal method에 대한 많은 literature가 존재한다.
널리 사용되는 object proposal method에는- grouping super-pixels을 base로 하는
- Selective Search
- CPMC
- MCG
- sliding window를 base로 하는
- objectness in windows
- EdgeBoxes
- grouping super-pixels을 base로 하는
- Object proposal methos들은 detection에 독립적으로 채택되어진다.
Deep Networks for Object Detection
-
R-CNN method는 object category 또는 background을 classification하는 CNNs을 train시킨다.
R-CNN은 주로 classifier로써 역할을 하고,
object bounds를 예측하지는 않는다.(bbox regression에 의해 refining하는 것을 제외하고)
그래서 R-CNN의 accuracy는 region proposal module의 performance에 의존한다.
몇가지 paper에서는 object bounding box를 predicting하는 방법을 제안함.- OverFeat method에서는,
fc layer가 single object를 추정하는 localization task의 box coordinates를 predict하도록 훈련된다.
그 후에, fc layer는 multiple class-specific objects를 detecting하기 위한 conv layer로 전환된다. - MultiBox method들은
여러 class에 대해 동시에 여러 class-agnostic boxes(class 중립적인)를 예측하는 network에서 region proposals을 생성한다.
이렇게 생성된 proposals들은 R-CNN에 사용된다.
이렇듯, MultiBox는 proposals과 detection 간에 feature를 공유하지 않는다.
- OverFeat method에서는,
-
우리의 방법과 관련하여 나중에 OverFeat와 MultiBox를 더 깊에 discussion할 것임.
-
Shared computation of convolutions은 효율적이면서도 정확한 visual recognition을 위해
점점 더 많은 관심을 받고 있다.
OverFeat paper은 classification, localization, and detection을 위한
image pyramid로부터 convolutional features를 계산한다.
Adaptively-sized pooling(SPP)는 효율적인 region-based object detection 및 semantic segmentation을 위해 개발되었다.
Fast R-CNN은 공유된 convolutional features에서의 end-to-end detector training을 가능하게 하며, 좋은 accuracy와 speed를 보여준다.
3. Faster R-CNN
Faster R-CNN이라고 불리는 우리의 object detection system은
두가지 modules로 구성되어 있다.- The first module is a deep fully convolutional network that proposes regions
- The second module is the Fast R-CNN detector that uses the proposed regions.
The entire system is a single, unified network for object detection. (Figure 2)
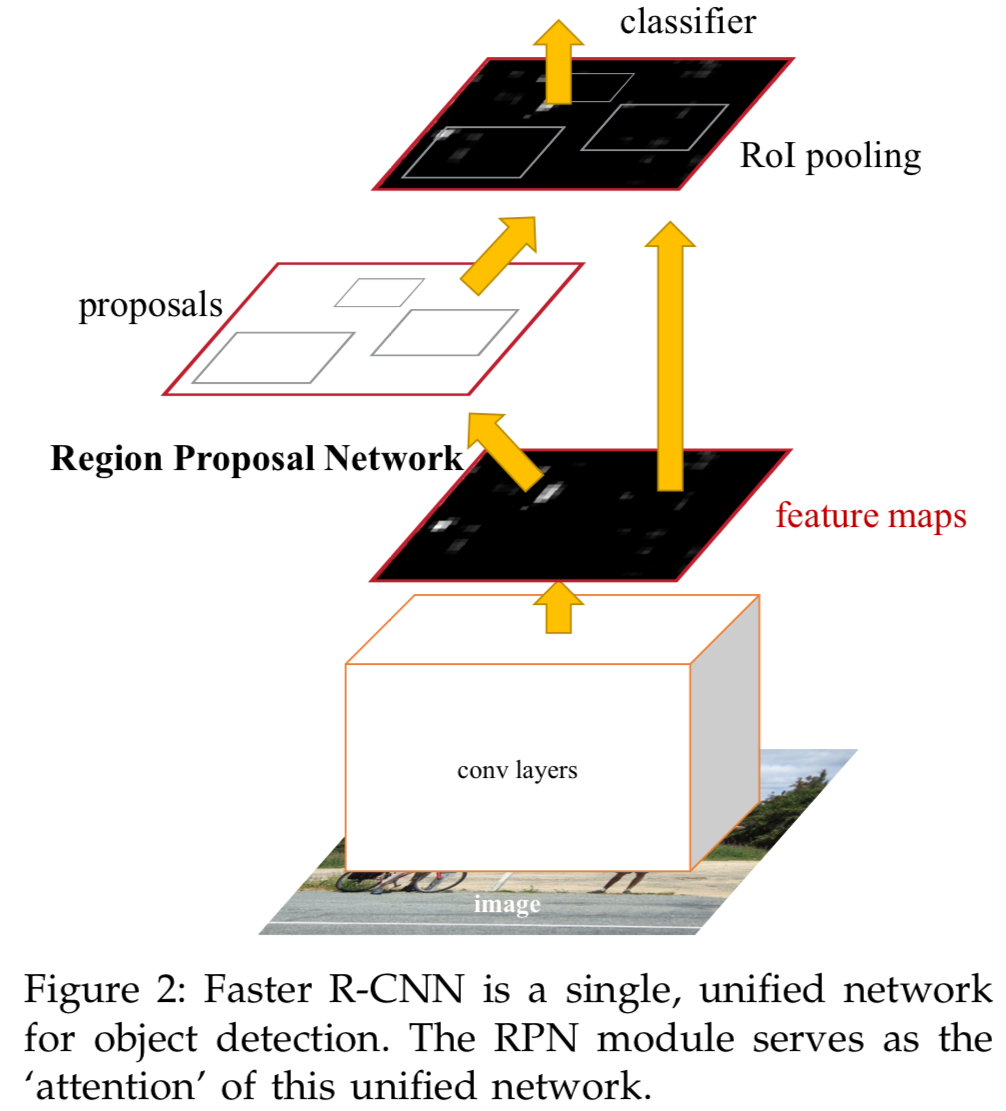 최근 neural network에서 'attention' mechanisms으로 유명한 용어를 사용하면,
최근 neural network에서 'attention' mechanisms으로 유명한 용어를 사용하면,
RPN module은 Fast R-CNN module에게 어디를 봐야할지 말해준다.
3.1. Region Proposal Networks
-
RPN은 어떠한 size의 image든 input으로 받고,
set of rectangualr object proposal, each with objectness score을 output으로 내보낸다.
(objectness score : object class에 대한 소속성을 평가하는 것으로,
해당 object가 background인지, a set of object classes인지 측정) -
우리의 최종 목표는 Fast R-CNN object detection network와 computation을 공유하는 것이므로,
RPN을 CNN으로 modeling하여 두 network가 a common set of convolutional layers를 공유한다고 가정한다.
experiments에서,
우리는 5개의 shareable conv layers를 가진 the Zeiler and Fergus(ZF) model과
13 shareable conv layers를 가진 VGG-16 model을 조사했다. -
region proposal을 생성하기 위해,
우리는 last shared conv layer에 의해 출력된 conv feature map을 기준으로
a small network를 sliding한다. -
이 small network는 input으로 spatial window를 받는다.
each sliding window는 lower-dimensional feature로 mapping된다.
이 feature는 두 fc layer로 입력된다.
(1. a box-regression layer(reg), 2. a box-classification layer(cls)).
이 논문에서, 을 사용함. -
mini-network가 sliding-window 방식으로 작동하기 때문에
fc layers는 모든 spatial locations에 대해 공유되어진다. (?) -
이 architecture는 자연스럽게 conv layer 다음에
두 개의 conv layer(reg, cls)가 이어지는 것으로 구현된다.
3.1.1 Anchors
-
각 sliding-window location에서,
동시에 여러 개의 region proposals을 예측하며,
각 location마다 가능한 최대의 proposal 수를 로 denote. -
그래서 layer는 개 boxes의 coordinates를 encoding하는 output을 가지고,
layer는 각 proposal에 대한 object 또는 not object의 probability를 추정하는 scores를 출력. -
개의 proposal은 개의 reference boxes,
즉 anchors에 대해 parameterized된다.
anchor는 해당 sliding window를 중심으로 하며,
scale and aspect ratio와 관련이 있다.
기본적으로 우리는 3개의 scale과 3개의 aspect ratio를 사용하여,
각 sliding position에서 개의 anchor를 생성한다.
크기가 인 conv feature map의 경우,
총 개의 anchor가 있음.
Translation-invariant Anchors
- Anchor box를 sliding window 방식으로 사용하면서, object translation에 invariant함.
Multi-Scale Anchors as Regression References
- pyramid of image, pyramid of filters 방법은 feature sharing이 힘듦.
pyramid of anchors는 고정된 크기의 filter들이 feature map을 받기 때문에 feature sharing이 훨씬 용이.
3.1.2 Loss Function

- : the index of an anchor in a mini-batch
- : the predicted probability of anchor being an object
- : ground-truth label. 1 if the anchor is positive, and 0 if the anchor is negative.
- : vector representing the 4 paramterized coordinates of the predicted bbox
- : ground-truth box associated with a positive anchor.
- : log loss(=cross entropy) over two classes (object vs. not object)
- where R is the robust loss function(smooth ),
- : mini-batch size
- = 10 : both cls and reg terms are roughly equally weighted.
의 값의 범위는 mAP에 크게 sensitive하지 않음.
여기서는 default로 10을 사용.

3.1.3 Training RPNs

3.2. Sharing Features for RPN and Fast R-CNN
4-Step Alternating Training
 (나의 세미나 자료..)
(나의 세미나 자료..)
3.3 Implementation Details
4. Experiments
4.1. Experiments on PASCAL VOC
4.2. Experiments on MS COCO
4.3. From MS COCO to PASCAL VOC
5. CONCLUSION
