[2016 CVPR] (YOLOv1) You Only Look Once : Unified, Real-Time Object Detection
[Paper Review] 2D Object Detection
Info
paper: You Only Look Once: Unified, Real-Time Object Detectionauthor: Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadisubject: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016 pp. 779-788.
Abstract
-
우리는 object detection에 대한 새로운 접근법인
YOLO를 소개한다. -
이전에 object detection에 대한 연구들은 detection을 하기 위해 classifier 문제로 재정의했었는데,
우리는 object detection을
separated bounding boxes와 associated(연관된) class probabilities에 대한 regression 문제로 재정의할 것이다. -
A single neural network는 한 번의 evaluation 안에 전체 image로부터 bounding boxes와 class probabilities를 즉시 예측한다.
전체의 detection pipeline이 a single network이기 때문에, detection performance에 대해 end-to-end로 optimize될 수 있다. -
우리의 unified architecture는 매우 빠르다.
우리의 base YOLO model은 real-time에 image를 45fps를 처리한다. -
조금 더 작은 version인,
Fast YOLO는 다른 real-time detectors들의 2배의 mAP를 달성하면서 155fps를 처리할 수 있다. -
state-of-the-art detection system들과 비교했을 때,
YOLO는 더 많은 localization error를 만들지만(?),
background에 대해 false positive 예측이 더 적다.
결과적으로 YOLO는 object들의 very general representations을 학습한다.
따라서 YOLO는 DPM and R-CNN을 포함한 다른 detection method들보다 더 우수하다.
1. Introduction
(이전 detection system들의 문제점)
-
현재 detection systems은 detection을 수행하기 위해 classifier로 재정의된다.
object를 detect하기 위해서 detection systems는 object에 대한 classifier를 취하고,
test image에 대한 다양한 locations and scales를 평가한다. -
deformable(변형될 수 있는) parts models (DPM)과 같은 system들은
classifier가 전체 image에 걸쳐 균일한 간격의 위치에서 작동하는 sliding window 방법을 사용한다. -
더욱 최근 기법인 R-CNN은
한 image에서 potential bounding boxes를 생성하기 위해 region proposal method를 사용한다.
그리고나서 이러한 proposed boxes에 대해 classifier를 동작시킨다.
classification 이후에 post-processing은 bounding box를 정제하고, duplicate detections을 제거하고, 다른 object들을 기준으로 box를 재평가하기 위해 사용된다.
이러한 복잡한 pipeline은 각각의 component들이 따로 따로 학습되어져야 하기 때문에 optimize하기에 느리고 힘들다.
(YOLO 장점)
-
우리는 object detection을 image pixel에서 bounding box coordinates(좌표)와 class probability까지의 a single regression problem으로 재구성한다.
-
우리의 system을 사용한다면,
You Only Look Once(YOLO) at an image to predict what objects are present and where they are. -
YOLO는 매우 간단하다.
 Figure 1.에서 볼 수 있듯이,
Figure 1.에서 볼 수 있듯이,
하나의 single convolutional network는 multiple bounding boxes와 그 box들에 대한 class probability를 동시에 predict할 수 있다.
YOLO는 full images를 학습하고 즉시 detection performance를 optimize한다.
이러한unified model은 object detection의 traditional method들에 비해 몇가지 장점이 있다.- YOLO는 매우 빠르다.
우리는 detection을 regression problem으로 재구성하였기 때문에 복잡한 pipeline이 필요가 없다.
detection을 predict하기 위해 test time에 새로운 image에 대해 우리의 neural network를 실행시키면 된다.
우리의 base network는 아무런 batch preprocessing 없이 Titan X GPU에서 45fps로 동작한다.
더 빠른 version은 150fps 이상으로 동작한다.
이는 우리가 25 millisecond 미만의 latency로 streaming video를 처리할 수 있다는 것을 의미한다.
게다가, YOLO는 다른 real-time system들의 2배 이상의 mAP(mean Average Precision)를 달성했다.
(webcam으로 real-time을 작동하는 demo는 다음의 project webpage를 참고해라 : http://pjreddie.com/yolo/)
- YOLO는 prediction할 때, image에 대해 전체적으로 추론한다.
sliding window와 region proposal-based technique들과는 달리,
YOLO는 training과 test time 동안 entire image를 보기 때문에 class 뿐만 아니라 appearance에 대한 contextual information(맥락적인 정보)도 encode한다.
top detection method인 Fast R-CNN은 전체적인 context를 볼 수 없기 때문에 image에서 background patch를 object로 잘못 인식한다.
YOLO는 Fast R-CNN에 비교하여 background error를 절반 미만으로 만들 수 있다.
- YOLO는 object의 generalizable representations을 학습한다.
natural image로 training하고 artwork로 test할 때,
YOLO는 DPM과 R-CNN과 같은 top detection method들을 능가한다.
YOLO는 굉장히 generalizable하기 때문에 새로운 domain이나 unexpected inputs이 들어와도 붕괴될 가능성이 적다.
- YOLO는 매우 빠르다.
-
YOLO는 여전히 state-of-the-art detection system들보다 accuracy가 뒤처진다.
image에서 빠르게 object를 식별할 수는 있지만, 특히 작은 object를 정확하게 localize하는 것에 어려움을 겪고 있다.
우리는 이러한 tradeoff를 experiment에서 자세히 설명할 것이다. -
우리의 모든 training and testing code는 open source이다.
다양한 pretrained models들을 download할 수 있다.
2. Unified Detection
-
우리는 object detection의 separate components들을 하나의 single neural network로 통합시켰다.
-
우리의 network는 각각의 bounding box를 predict하기 위해 entire image로부터 feature를 사용한다.
또한 YOLO는 imaeg에 대해 모든 class에 대한 모든 bounding box를 동시에 prediction한다.
이것은 우리의 network가 전체 image와 image에 있는 모든 object들에 대해 global하게 추론한다는 것을 의미한다.
YOLO design은 end-to-end training과 high average precision을 유지하면서 real-time speed를 유지할 수 있게 한다.- 우리의 system은 input image를 grid로 나눈다.
만약 object의 중심이 grid cell 안에 위치하면 해당 grid cell은 해당 object를 detection해야 하는 책임이 있다. - 각각의 grid cell은 개의 bounding box들을 예측하고, 그 box들에 대한 confidence score를 예측한다.
이 confidence score는 model이 해당 box에 object가 포함되어 있다고 확신하는 정도를 의미하며, 또한 예측한 box의 accuracy에 대한 model의 확신을 나타낸다.
공식적으로 우리는 confidence score를 라고 정의한다.
만약 해당 cell 안에 object가 없다면, confidence는 0이 되어야 한다.
만약 해당 cell 안에 object가 있다면, confidence는 GT와 predicted box 사이의 Intersection over union(IOU : 교차 영역을 합집합으로 나눈)값과 같도록 하길 원한다. - 각각의 bounding box는 5개의 prediction으루 구성되어 있다 :
- : gride cell 경계에 대한 box의 중심좌표
- : 전체 image에 대한 width and height
- : (실제 IoU가 아니라, "Predicted bbox는 GT bbox와 어느 정도 겹칠 것이다"를 예측)
"GT box와 predicted box 간의 IoU가 얼만큼 될 것 같은지"를 확률적으로 나타낸게 confidence socre임.
Training 시에는, object가 있는 경우 와 없는 경우 을 알 수 있으니까
가 를 따라갈 수 있도록 loss를 만들고 학습시키는 것임.
- 각각의 grid cell은 개의 conditional class probabilities, 를 예측한다.
이 probability는 grid cell에 object가 포함되어 있는 경우에만 조건이 부여된다.
box의 개수 와 상관없이 grid cell마다 하나의 class probabiliy set을 예측한다.
test time에는 conditional class probability와 individual box confidence prediction을 곱하여 각 box에 대해 class별 confidence score를 얻는다.
이 scores들은 box에 해당 class가 나타날 probability와 predicted box가 object에 얼마나 잘 맞는지를 모두 encoding한다.

- PASCAL VOC에 YOLO를 evaluating하기 위해,
우리는 를 사용했다.
PASCAL VOC는 20 labelled classes가 있기 때문에 이다.
따라서 final prediction은 tensor이다. - test시에는,
conditional class prpobabilities와 individual box confidence predictions을 곱해서
각 box별 class-specific confidence scores를 얻는다.
이 scores들은 box에 해당 class가 나타날 확률과 predicted box가 object에 얼마나 잘 맞는지를 encoding한다.

- 우리의 system은 input image를 grid로 나눈다.
2.1. Network Design
-
우리는 이 model을 convolutional neural network로 구현했고, PASCAL VOC detection dataset에 evaluate했다.
-
초기 network의 conv layer들은 image에서 feature를 추출하고, fc layer는 output probabilities와 coordinates를 예측한다.
우리의 network architecture는 image classification을 위한 GoogLeNet model에 의해 영감 받았다.
우리의 networksms 24개의 conv layer에 2개의 fc layer가 따른다.
GoogLeNet에서 사용했던 inception modules 대신에, 우리는 3x3 conv layers 뒤에 1x1 reduction layer를 사용했다.
전체 network는 Figure 3.에 나와있다.

-
또한 빠른 object detection의 경계를 넓히기 위해 설계된 a fast version of YOLO를 훈련시켰다.
Fast YOLO는 24개보다 더 적은 9개의 conv layer를 갖고, 그 layer들의 filter개수도 더 적다.
network size말고는, YOLO와 Fast YOLO의 모든 training and testing parameters들은 똑같다.
network의 final output은 tensor of predictions이다. -
(내 생각)
YOLO의 architecture는 GoogLeNet model에 의해 영감을 받았다고 했는데, 어떤 부분에서 영감을 받은 것인지 궁금했다...
➡️ GoogLeNet의 핵심 아이디어는 크게 2가지,
(1) inception module (2) deeper model 이라고 할 수 있을 것 같은데
inception module을 사용하지 않고 3x3 conv layer 뒤에는 Network In Network의 1x1 conv layer를 사용했다고 하니 (1) inception module 아이디어에서 영감을 받지 않은 것 같다.
YOLO는 24 conv layer로 되어있다고 하니,
이는 당시에는 깊은 model이었기 때문에
확실하진 않지만 model을 깊게 만들었던 GoogLeNet 아이디어에 영감을 받았다고 생각할 수 있을 것 같다.
2.2. Training
-
우리는 conv layer들을 ImageNet 1000-class competition dataset에 pretrain시켰다.
pretraining을 위해 우리는 average pooling layer와 fc layer가 딸려있는 처음 20개 conv layer를 사용했다.
우리는 이 network를 학습시키는 데에 약 일주일 걸렸고 ImageNet 2012 validation set에 대한 top-5 accuracy 88%를 달성했다.
우리는 모든 training and inference를 위해 Darknet framework를 사용했다. -
처음 20개의 conv layer들을 pretrain하고 나서, 우리는 detection을 수행하는 model로 변환했다.
Ren et al.에서는 pretrained network에 conv layer와 fc layer를 추가하면 performance가 향상된다는 것을 보여줬다.
그들의 실험에 따라, 우리는 4개의 randomly initialized weights인 conv layer와 2개의 fc layer를 추가했다.
detection은 보통 fine-grained visual information(세밀한 시각 정보)가 필요하므로
우리는 network의 input dimensiondmf 에서 로 늘렸다.

-
우리의 마지막 layer는 class probablities와 bouding box coordinates를 예측한다.
우리는 bounding box의 width와 height를 image의 width와 height로 normalization하여, 0과 1 사이의 값으로 만들었다.
bounding box의 x, y 좌표를 특정 grid cell 위치의 offset으로 parametrize하여, 이를 0과 1 사이의 값으로 만들었다. -
마지막 layer에서는 linear activation function을 사용해고,
나머지 다른 layer에서는 leaky relu를 사용했다.
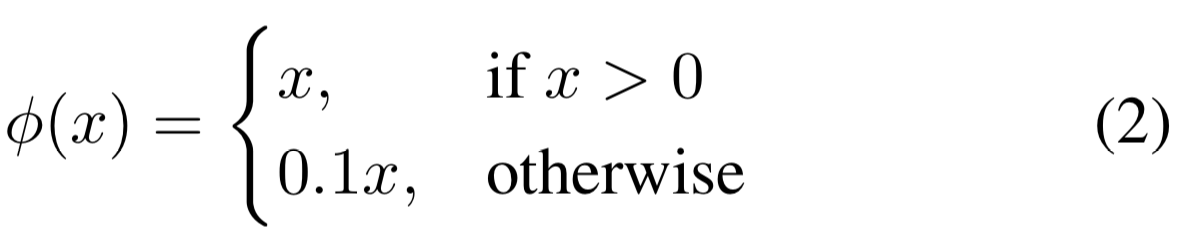
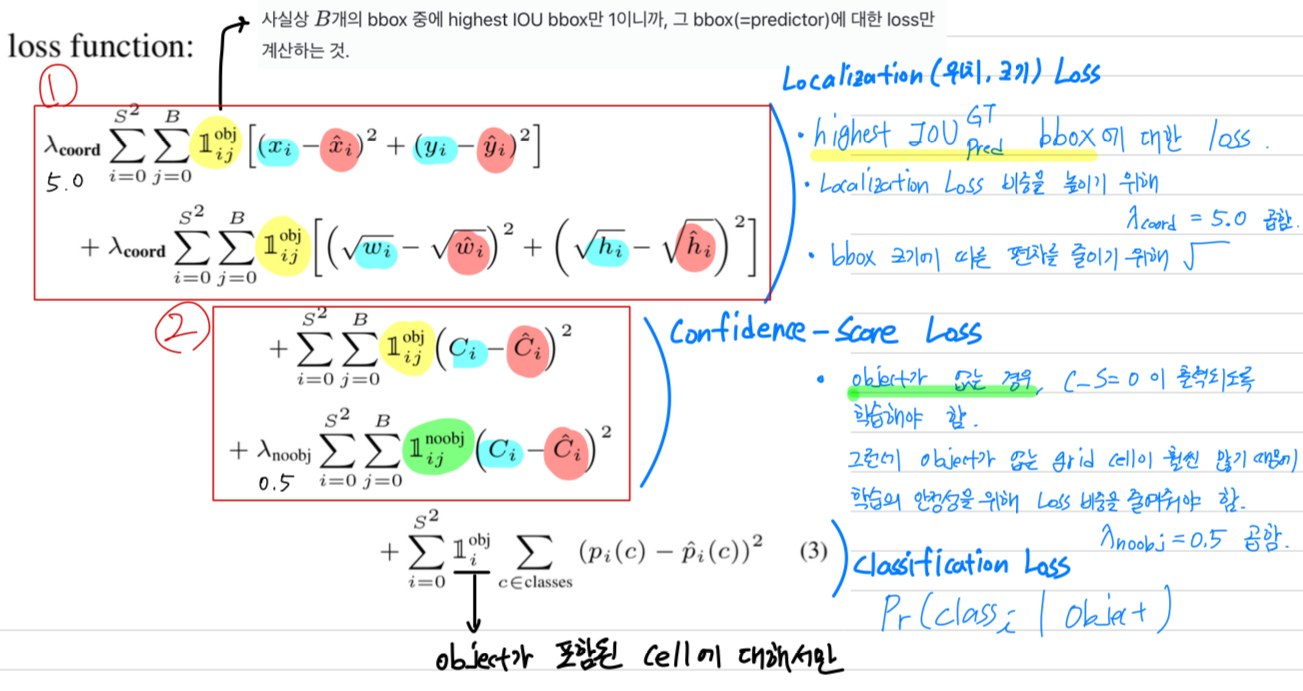
Loss function
- (2)
우리는 optimize하기 쉬운 sum-squared error를 사용했다.
하지만 sum-squared error는 Average Precision을 maximizing하는 우리의 목표에 완전히 일치하진 않았다.
왜냐하면 classification error와 localization error를 동일하게 가중하는 것은 이상적이지 않기 때문이다.
또한 대부분의 image grid cell에는 object가 포함되지 않는다.
이는 해당 cell의 "confidence" score를 0으로 만들게 하며,
object를 포함하고 있는 cell들로부터 gradient를 overpowering될 수 있다.
이는 model instability를 야기하며, training이 일찍 발산하게 할 수 있다. - (1), (2)
이를 해결하기 위해,
object가 포함되지 않은 box에 대한
bounding box coordinate prediction의 loss를 증가시키고,
confidence prediction의 loss 감소시켰다.
이를 위해 두 개의 parameters, 와 를 사용했다.
우리는 , 로 설정했다.
- (1)
sum-squared error는 또한 큰 box와 작은 box에 대한 error를 동일하게 가중한다.
우리의 error metric은 큰 box에서의 작은 편차가 작은 box에서의 작은 편차보다 중요하지 않다.
(해석 : 작은 box의 a만큼의 error의 비율이 큰 box의 a만큼의 error의 비율보다 크기 때문에 작은 box에서의 error가 metric에 더욱 중요하다)
이를 해결하기 위해,
우리는 bounding box의 width와 height를 바로 예측하는 것이 아니라,
width와 height의 square root를 예측한다.
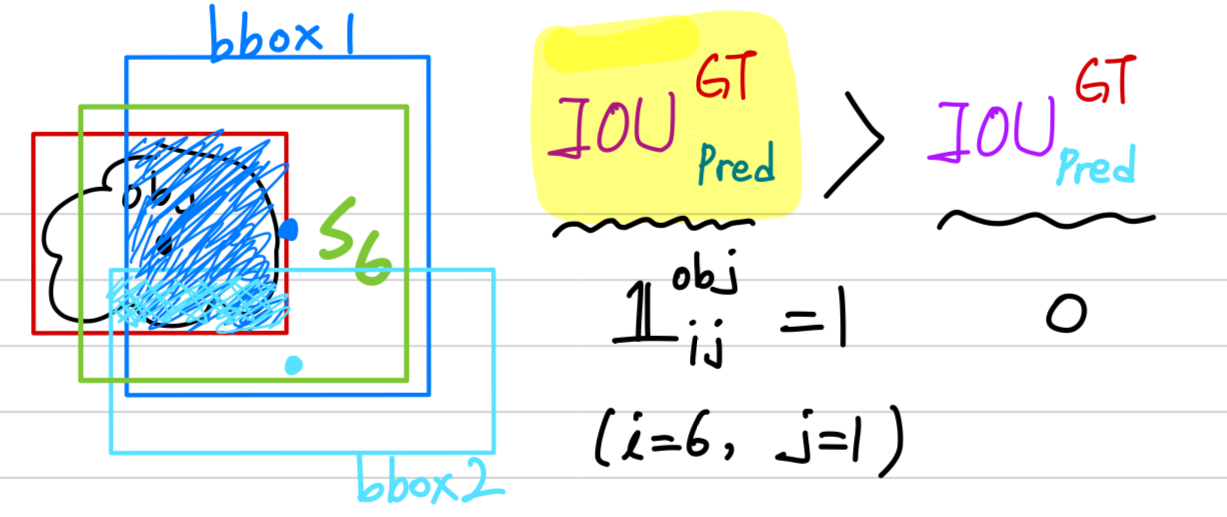
- YOLO는 grid cell마다 여러개의 bounding box를 예측한다.
우리는 training time에 각 object를 책임지는 하나의 bounding box predictor를 원한다.
그래서 우리는 ground truth와 IOU가 가장 높은 predction을 기반으로,
object를 predicting하기 위한 하나의 predictor를 지정한다.
이것은 bounding box predictor 간의 전문화를 이끈다.
각각의 predictor는 점점 더 특정 size, aspect ratios, 또는 object class를 예측 하는 데에 좋아지며,
이는 전체적인 recall을 향상시키게 된다.
training 동안, 우리는 다음과 같은 multi-part loss function으로 optimize하였다.- : denotes if object appears in cell (1 or 0)
- : denotes that the th bounding box predictor in cell is “responsible” for that prediction.
 사실상 개의 bbox 중에 highest IOU bbox만 1이니까, 그 bbox(=predictor)에 대한 loss만 계산하는 것.
사실상 개의 bbox 중에 highest IOU bbox만 1이니까, 그 bbox(=predictor)에 대한 loss만 계산하는 것.
hyper parameters
- 135 epochs on the training and validation data sets from PASCAL VOC 2007 and 2012.
- When testing on 2012 we also include the VOC 2007 test data for training.
- batch size of 64
- momentum 0.9
- decay 0.0005
- learning rate schedule is as follows :
For the first epochs we slowly raise the learning rate from to .
If we start at a high learning rate our model often diverges due to unstable gradients.
We continue trainin with for 75 epochs,
then for 30 epochs,
and finally for 30 epochs. - To avoid overfitting we use dropout and extensive data augmentation
- dropout layer with rate = .5 after the first fc layer prevets co-adaptation between layers.
- For data augmentation we introduce random scaling and translations of up to 20% of the original image size.
We also randomly adjust the exposure and saturation of the image by up to a factor of 1.5 in the HSV color space.
2.3. Inference
-
training에서와 같이,
test image에 대한 detection을 predicting하는 것은 하나의 network evaluation만 있으면 된다. -
PASCAL VOC에 대해서,
network는 image당 98개의 bounding box를 예측하고, 각 box에 대해서 class probability를 예측한다. -
YOLO는 single network evaluation이기 때문에, test시에 매우 빠른 속도를 갖는다.
-
grid design은 bounding box prediction에 대해 spatial diversity(공간적 다양성)을 강화한다.
object가 어느 grid cell에 속하는지 명확하며, network는 각 object에 대해 하나의 box만 예측한다. -
그러나 일부 큰 object나 multiple cell의 경계에 가까운 object는
multiple cell에 의해 잘 localized될 수 있다.
Non-maximum Suppression은 이러한 multiple detection을 해결하는 데에 사용될 수 있다.
R-CNN or DPM에서처럼 performance에 중요한 부분은 아니지만, non-maximal suppression은 2~3%의 mAP 향상을 도왔다.

2.4. Limitations of YOLO
-
YOLO는 각 grid cell이 2개의 box만 예측하고, 하나의 class만 가질 수 있으므로
bounding box prediction에 대한 강력한 sptial constraints를 부여한다.
이 spatial constraint는 model이 예측할 수 있는 근처 object의 수를 제한한다.
그래서 우리의 model은 무리를 이루는 작은 object를 detection하는 데에 어려움을 겪는다. -
우리 model은 data로부터 bounding box를 예측하는 것을 학습하기 때문에,
새롭거나 비정상적인 aspect ratio 또는 구성을 갖는 object에 대해 generalization하는 데에 어려움을 겪는다.
또한 우리의 architecture가 input image로부터 여러 downsmapling layer를 갖고 있기 때문에
상대적으로 coarse(굵은) 특징을 사용하여 bounding box를 예측한다. -
마지막으로, 우리는 detection performance를 근사하는 loss function을 train시키지만,
우리의 loss function은 작은 bbox와 큰 bbox에서의 error를 똑같이 처리한다.
큰 상자에서의 작은 error는 일반적으로 무해하지만,
작은 상자에서의 작은 error는 IOU에 더 큰 영향을 미치게 된다.
우리의 주요 error 원인은 incorrect localization이다.
3. Comparison to Other Detection Systems
- Object detection은 computer vision에서 중요한 문제이다.
Detection pipeline은 일반적으로 input image로부터 a set of robust features를 추출함으로써 시작된다.
(Haar, SIFT, HOG, convolutional features).
그리고나서, classifier or localizer는 feature space에서 object를 식별하기 위해 사용된다.
이러한 classifier or localizer는 전체 image를 sliding window 방식으로 실행하거나 image의 일부 영역에서 실행된다.
우리는 YOLO detection system을 몇가지 top detection frameworks과 주요 유사점과 차이점을 강조하여 비교할 것이다.- Deformable parts models. :
- sliding window approach to object detection.
- a disjoint pipeline to extract static features, classify regions, predict bounding boxes, etc.
➡️ YOLO replaces all these disparate parts with a single CNN.
Instead of static features, the network trains the feature in-line nad optimizes them for the detection task.
YOLO leads to a faster, more accurate model than DPM.
- Other Fast Detectors : DPM의 전체 pipeline의 구성하는 작은 pipeline들을 개선하려는 많은 연구들이 존재.
- many efforts to speedup HOG computation.
- use cascade, push computations to GPUs.
➡️ but, only 30Hz DPM runs in real-time.
YOLO는 작은 pipeline이 개별적인 속도를 개선시키지 않고, pipline을 없애어 하나의 fast design으로 만듦.
- R-CNN :
- region proposals instead of sliding window to find objects.
- Selevtive Search generates potential bboxes.
- CNN extracts features.
- SVM scores the boxes
- linear model adjusts the bboxes.
- non-max suppression eliminates duplicate detections.
➡️ Each stage of this complex pipeline must be tuned independently and resulting system is ver slow.
(역시나 복잡한 pipelines으로 인해 train, test 속도 느림)
- Fast R-CNN :
- using neural networks to propose regions instead of Selective Search.
➡️ neural network를 사용하여 proposed region를 찾는 시도를 통해 R-CNN에 비해 accuracy, speed 증가.
하지만 아직 real-time 성능에 부족.
- using neural networks to propose regions instead of Selective Search.
- Deep MultiBox :
- train a CNN to predict regions of interest instead of using Selective Search.
- can also perform single object detection by replacing the confidence prediction with a single class prediction.
➡️ CNN으로 RoI를 predict하는 것은 YOLO와 동일하지만,
YOLO와 같이 여러 object를 detection하기 위해 추가의 image patch classification이 필요함.
이는 Deep MultiBox가 general object detection을 수행하지 못하므로
YOLO가 더욱 complete detection system이라고 할 수 있음.
- OverFeat :
- train a CNN to perform localization
- adapt that localizer to perform detection.
➡️ DPM과 같이, localizer는 오로지 local information만 보기 때문에
OverFeat은 global context를 추론할 수 없고, 그러므로 post-processing이 굉장히 중요함.
- MultiGrasp :
- YOLO의 grid approach는 grasp하기 위해 regression을 하는 MultiGrasp에 기반함.
➡️ MultiGrasp는 한 image에서 single graspable region을 predict하는데,
YOLO는 한 image에서 bboxes와 여러 objects의 class probabilities를 predict하기 때문에 더욱 고급의 task임.
- YOLO의 grid approach는 grasp하기 위해 regression을 하는 MultiGrasp에 기반함.
- Deformable parts models. :
4. Experiments
- 우선 우리는 YOLO를 PASCAL VOC 2007의 다른 real-time detection system들과 비교했다.
YOLO와 R-CNN variants를 비교하기 위해, 우리는 YOLO와 R-CNN의 highest performing version인 Fast R-CNN이 만든
error를 탐구하였다.- 다른 error profiles를 기반으로,
우리는 YOLO가 Fast R-CNN detection을 resocre하고
background에 대한 false positive error를 줄여줌으로써
유의미한 성능 향상을 제공할 수 있음을 보여준다. - 우리는 또한 VOC 2012 result를 제시하고 state-of-the-art methods의 mAP와 비교했다.
- 마지막으로 YOLO가 두 개의 artwork datasets에서 다른 detectors들보다 새로운 domain에 대해 일반화되는 경향을 보여준다.
- 다른 error profiles를 기반으로,
4.1. Comparison to Other Real-Time Systems
-
object detection에 대한 많은 research efforts는 standard detection pipeline을 빠르게 만드는 것이다.
하지만 오로지 M. A. Sadeghi and D. Forsyth. 30hz object detection with dpm v5.만이
real-time에 동작하는(30 fps or better) detection system을 만들었다.
우리는 YOLO를 30Hz 또는 100Hz에서 동작하는DPM v5의 GPU implementation과 비교했다.
우리는 또한 object detection systems의 accuracy-performance tradeoffs를 조사하기 위해 상대적인 mAP and speed도 비교했다. -
우리가 알기로는,
Fast YOLO가 PASCAL에서 fastest object detection method이다.
52.7% mAP로, 이전의 real-time detection accuracy의 2배 이상 정확하다.
YOLO는 real-time performance를 유지하면서 63.4% mAP로 끌어올렸다. -
우리는 또한
YOLO using VGG-16을 train시켰다.
이 model은 YOLO보다 더 정확하지만 훨씬 느리다.
VGG-16을 기반으로한 다른 detection system과 비교할 수 있지만,
real-time보다는 느리기 때문에 논문의 나머지 부분은 더 빠른 model에 초점을 맞출 것이다. -
Fastest DPM은 DPM의 mAP를 떨어뜨리지 않으면서 효과적으로 속도를 올렸다.
하지만 real-time performance는 여전히 2배 정도 모자라다. (15 fps)
또한 neural network approaches와 비교하여 detection에서 DPM의 상대적으로 낮은 accuracy로 인해 약한 모습을 보임. -
R-CNN minus R은 R-CNN의 Selective Search 방식을 static bounding box proposals로 교체한 model이다.
R-CNN보다 빨라지긴 했지만, 여전히 real-time에는 못 미치며 good proposals도 없어서 accuracy가 상당히 감소함. -
Fast R-CNN은 R-CNN의 classification 단계를 가속화한 model이다.
하지만 여전히 주어진 image마다 bbox를 생성하는 데 약 2초 정도 걸리는 selective search를 사용한다.
그래서 높은 mAP를 갖지만 0.5fps로 여전히 real-time에는 거리가 멀다. -
최근인
Faster R-CNN은 bboxes를 propose하는 것을 selective search 대신 neural network로 바꾸었다.
우리의 test에서, 그들의 가장 정확한 model은 7 fps를 달성하며,
더 작고 정확도가 낮은 model은 18 fps로 동작한다.
VGG-16 version of Faster R-CNN은 10 mAP가 높지만 6배 느리다.
The Zeiler Fergus Faster R-CNN은 YOLO보다 정확도도 낮지만 속도도 2.5배 느리다
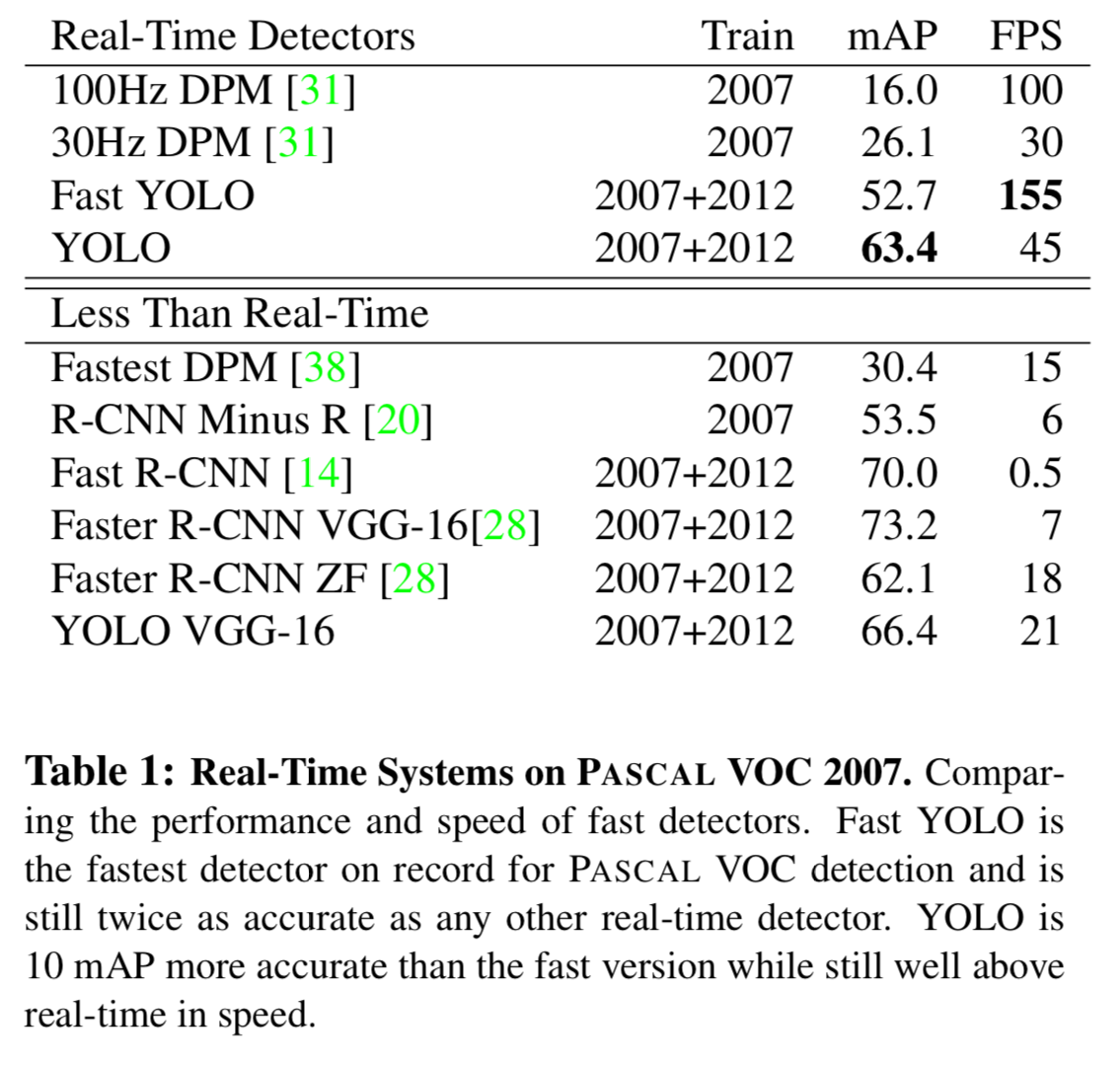
real-time performance에 달성한 기존 model은 DPM 밖에 없어서 비교 대상이 DPM model밖에 없다.
다른 model들은 대부분 Fast R-CNN variants인데,
accuracy는 높지만 속도가 real-time performance에는 너무 멀어 사실상 비교하기 힘들어 보인다.
4.2. VOC 2007 Error Analysis
-
YOLO와 state-of-the-art detectors들과 추가로 비교하기 위해,
우리는 VOC 2007 결과에 대한 자세한 분석을 살펴봤다. -
Fast R-CNN은 PASCAL에서 highest performing detectors이기 때문에
우리는 YOLO와 Fast R-CNN을 비교했다.
object detection을 위한 비교, 분석 방법으로 D.Hoiem,Y.Chodpathumwan,andQ.Dai.Diagnosingerror in object detectors.의
methodology and tools를 사용했다.- test time에 각 category마다 top predictions을 확인했다.
각 prediction은 correct 이거나 the type of error에 따라 classified된다.
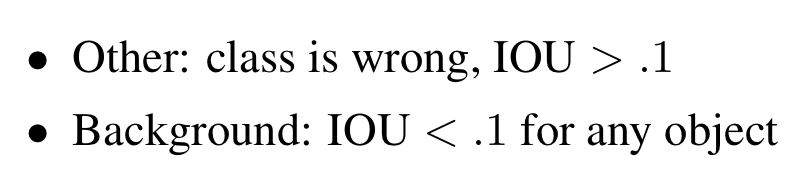
- Figure 4는 모든 20개의 class의 각각 평균화된 error type의 세부 사항을 보여준다.
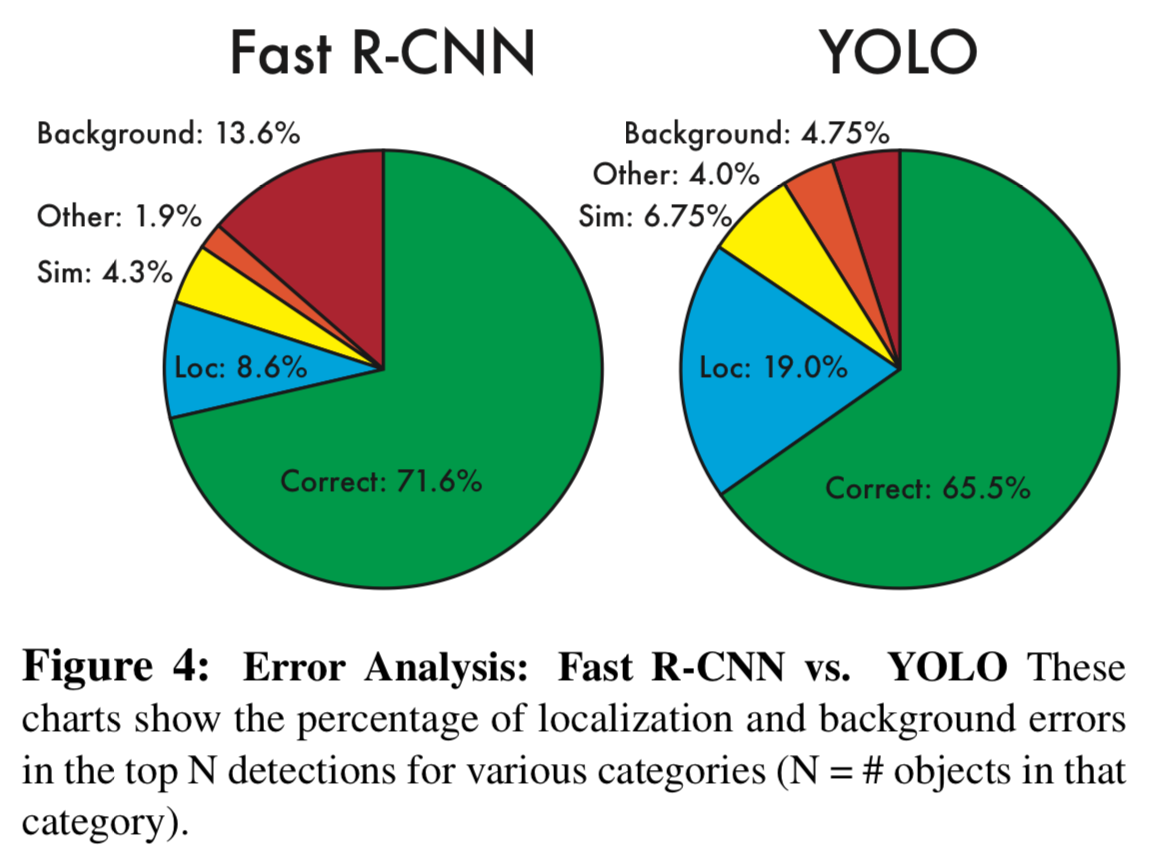 ➡️ YOLO는 object를 올바르게 localize하는 데에 어려움을 겪는다. (Fast R-CNN의 Loc error = 8.6% < YOLO의 Loc error = 19.0%)
➡️ YOLO는 object를 올바르게 localize하는 데에 어려움을 겪는다. (Fast R-CNN의 Loc error = 8.6% < YOLO의 Loc error = 19.0%)
Localization errors는 YOLO의 모든 다른 원인(Sim, Other, Background)을 합친 것보다 더 많은 비중을 차지한다.
➡️ Fast R-CNN은 훨씬 적은 localization error를 만들지만, background error가 훨씬 많다.
Fast R-CNN의 top detections 중 13.6%는 아무 object가 포함되어 있지 않는 false positive(없는데 있다고 predict)이다.
Fast R-CNN은 YOLO보다 background error 확률이 거의 3배 높다.
- test time에 각 category마다 top predictions을 확인했다.
4.3. Combining Fast R-CNN and YOLO
- YOLO는 Fast R-CNN보다 훨씬 적은 background error를 만든다.
Fast R-CNN으로부터 YOLO를 사용하여 background error를 감소시킴으로써, 성능을 크게 향상시켰다.- R-CNN이 예측한 모든 bounding box마다 YOLO가 similar box를 예측했는지 check한다.
만약 그렇다면, 우리는 YOLO가 예측한 probability와 두 box 사이의 overlap에 기반하여 해당 prediction을 향상시킨다. - the best R-CNN model은 VOC 2007 test set에서 71.8% mAP를 달성했다.
YOLO와 결합했을 때는, 3.2%가 오른 75.0이 되었다. - 우리는 또한 the top Fast R-CNN model을 여러 다른 version의 Fast R-CNN과 결합했다.
그 ensemble은 0.3, 0.6%의 작은 mAP 향상을 만들어냈다.
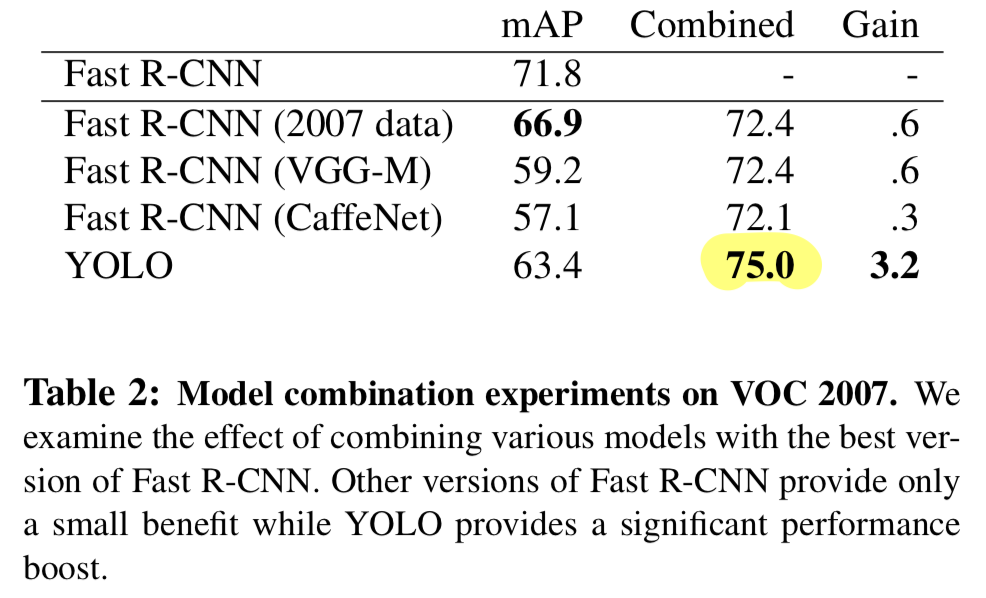
- YOLO는 다양한 version의 Fast R-CNN을 결합하는 것에는 거의 이점이 없기 때문에
YOLO는 단순히 model ensembling의 부산물이 아니다.
오히려, YOLO가 test 시간에 다른 유형의 error들을 만드는 것이 Fast R-CNN의 성능을 향상시키는 데에 효과적인 이유이다. - 유감스럽게도,
이 결합은 각 model을 별도로 실행한 다음 결과를 결합하기 때문에
YOLO 입장에서는 속도에서 이점을 얻지 못한다.
하지만 Fast R-CNN 입장에서는 YOLO가 매우 빠르기 때문에 속도가 느려지지는 않는다.
- R-CNN이 예측한 모든 bounding box마다 YOLO가 similar box를 예측했는지 check한다.
4.4. VOC 2012 Result
-
VOC 2012 test set에 대해서, YOLO는 57.9% mAP를 달성했다.
이는 현재 state of the art보다 작으며, VGG를 사용했던 R-CNN에 더 가깝다. -
우리의 system을 가까운 경쟁 상대(R-CNN VGG)와 비교하면,
small object에 더 어려움을 겪는다.
bottle, sheep, and tv/monitor같은 category들에 대해서 YOLO는 R-CNN과 Feature Edit에 비해 8~10% 작다.
하지만, cat and train과 같은 category에 대허서 YOLO는 더 높은 performance를 달성했다.
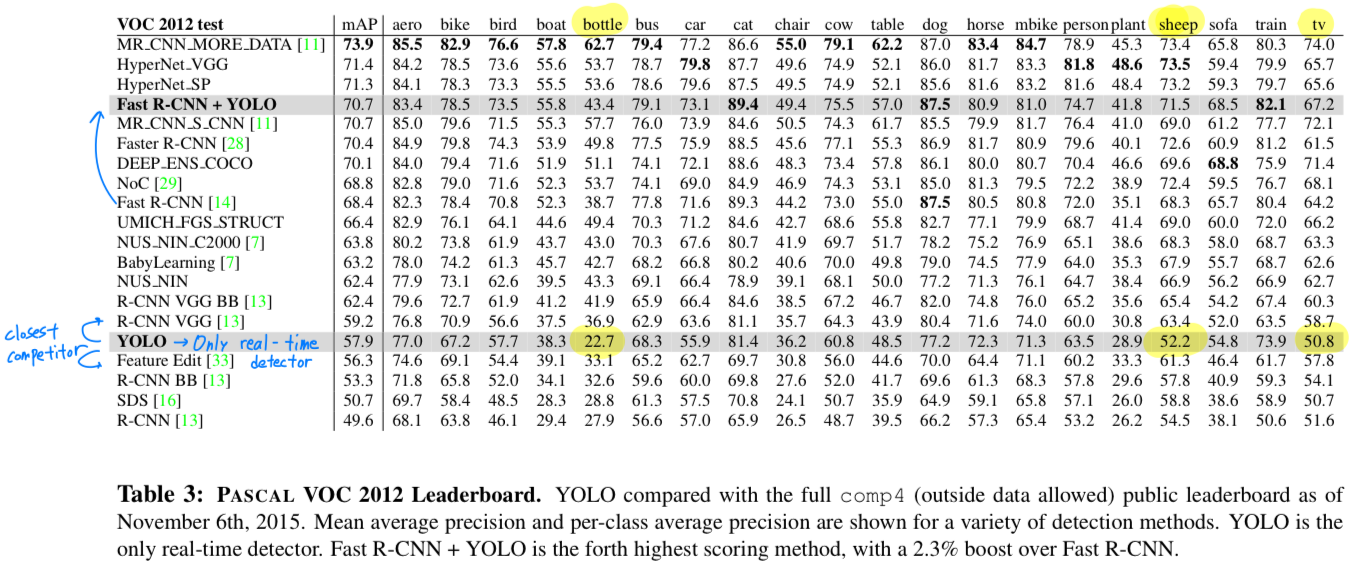
- 우리의 combined Fast R-CNN + YOLO model은 highest performing detection method들 중 하나이다.
Fast R-CNN은 YOLO와 결합되어 2.3% 향상을 얻어 public leaderboard에 5계단 상승하였음.
4.5. Generalizability : Person Detection in Artwork
-
object detection을 위한 academic datasets은
same distribution의 training and testing data이다. -
real-time application에서는 모든 가능한 경우를 predict하기 어렵고
test data는 system이 이전에 봤던 data들과는 다를 수 있다.
우리는 YOLO를 the Picasso Dataset and the People-Art Dataset과 비교하였고,
이 두 dataset은 예술작품에서 person detection을 위한 dataset이다.

- Figure 5는 YOLO와 다른 detection methods들과의 성능 비교를 나타낸다.
참고로, 우리는 VOC 2007 data만을 train하여 person에 대한 AP를 제공한다.
Picasso models은 VOC 2012에 train되었고,
People-Art는 VOC 2010에 train되었다. - R-CNN은 VOC 2007에 대해서 높은 AP를 보였다.
하지만 예술작품에 적용했을 때, 급격히 감소했다.
R-CNN은 bounding box proposal을 위해 natural image에 특화된 Selective Search를 사용했다.
R-CNN에 대한 classifer step은 small regions만을 볼 수 있으며 good proposals을 필요로 한다. - DPM은 artwork에 적용했을 때도 AP를 잘 유지했다.
prior work는 DPM이 objet의 shape와 layout에 대해 strong spatial model이라고 했기 때문에 잘 수행된다고 가설을 세웠다.
DPM은 R-CNN만큼 degrade되지 않았지만, R-CNN보다 작은 AP에서 시작했다. - YOLO는 VOC 2007에 대해 좋은 performance를 보였다.
그리고 artwork에 적용했을 때, 다른 method들보다 더 적은 degrade를 보였다.
DPM과 마찬가지로 YOLO는 object의 size와 shape 뿐만 아니라
object 간의 relationshiops 및 object가 일반적으로 나타나는 위치를 modeling한다.
예술 작품과 자연 이미지는 픽셀 수준에서 매우 다르지만,
객체의 크기와 모양 측면에서 유사하므로 YOLO는 여전히 좋은 bbox와 detection을 predict할 수 있음.
- Figure 5는 YOLO와 다른 detection methods들과의 성능 비교를 나타낸다.
5. Real-Time Detection In The Wild
-
YOLO는 fast, accurate object detector이므로 computer vision applications에 이상적이다.
우리는 YOLO를 webcam에 연결하고 image를 camera에서 가져오고 detection을 display하는 시간을 포함하여 real-time performance를 유지하는지 확인하였다. -
The resulting system은 interactive and engaging(매력적)하다.
YOLO가 images를 개별적으로 처리하지만,
webcam에 연결되면 object를 추적하는 시스템처럼 작동하여 object가 이동하고 appearance(외관)이 변경될 때 detecting한다.
system demo 및 source code는 project website(http://pjreddie.com/yolo/)에서 확인할 수 있다.
6. Conclusion
- 우리는 a unifed model for object detection인, YOLO를 소개했다.
YOLO는 construct하기에 simple하고 full images를 direct하게 train할 수 있다.
classifer-based approahces들과는 다르게,
YOLO는 detection perforamnce와 직접적으로 대응되는 하나의 loss function으로 train되며,
전체 model이 함께 train된다.
Fast YOLO는 literature(문헌)에서 가장 빠른 genral-purpose object detector이며
real-time object detection에서 state-of-the-art로 되었습니다.
또한 YOLO는new domain에 대해 잘 generalization되어 fast, robust object detection에 의존하는 application에 이상적이다.
이해가 안된 것
-
object detection에서 localization이란?
"Compared to state-of-the-art detection systems, YOLO makes more localization errors ..."
-> object가 있는 곳을 찾아내는 능력인듯 = bounding box의 정확도? -
"우리는 detection을 regression problem으로 재구성하였기 때문에 복잡한 pipeline이 필요가 없다."
기존의 classification problem과 regression problem이 무엇이 다르길래 복잡한 pipeline이 필요없다고 하는 것인지, 구체적인 내용은? -
Pr(Object)는 어떻게 구할 수 있지?
이거는 우리가 직접 계산하여 구하는게 아니고, training 시에 해당 grid cell에 object가 있으면 1이고, 없으면 0으로 바뀌는 값임.
Discussion
- 저자들은 왜 로 했는가? 에 대한 hyper-parameter tuning table도 제시하면 좋았을 것 같다.
추측컨대, 에 따라 small object detection 성능과 efficiency 간의 Trade-off도 존재할 수 있을 것 같다.
지금 은 전체 image resolution 을 grid cell로 나눈다는 의미이고, 그러면 각 cell은 pixel을 담당하게 된다.
small object는 보통 더 작은 pixel 범위에 존재하기 때문에 로 늘리게 될 경우,
각 cell은 각각 pixel을 담당하게 되어 small object detection 성능이 더 높아지지 않을까? 생각한다.
대신, NMS 비용은 증가하게 될 것이고,
object가 포함되지 않는 grid cell (noobj)의 비중도 늘어나게 되어 confidence score를 0으로 밀어내려는 gradient가 강화되어 divergence하거나 training efficiency가 떨어질 수도 있을 것 같다..
