[2015 CVPR] (GoogleNet) Going deeper with convolutions
 (https://arxiv.org/abs/1409.4842)
(https://arxiv.org/abs/1409.4842)
Abstract
- 우리는
Inception이라고 불리는 deep convolutional neural network architecture를 제안한다. - 이 architecture의 주된 보증은 network 내부의 computing resource의 효율성을 향상시킨 것임.
이는 computational budget을 고정한 채로 network의 depth 와 width를 증가시켜서 신중히 만들어졌다. - ILSVRC14에 제출한 구체화된 network는
GoogleNet이라고 부른다.
GoogleNet은 22 layers deep network이다.
1. Introduction
-
지난 3년간 deep learning의 급속 발전으로 인해 image recognition과 object detection의 quality가 매우 정확해지고 있다.
-
하지만 한가지 우려되는 점은
대부분의 progress들이 오로지 powerful HW, larger dataset 그리고 bigger model을 사용하는 것 뿐만 아니라 new ideas, algorithm 과 improved network architecture가 없다는 점이다. -
ILSVRC 2014에 제출한 우리의 GoogleNet은 2년 전의 AlexNet보다 12배나 적은 parameter를 사용했지만,
더욱 높은 정확도를 보였다. -
GoogleNet은 inference time 동안,
a computational budget of 1.5 billions multiply-adds 를 유지하도록 설계되었다. -
이 논문에서,
우리는 Inception이라고 불리는 computer vision을 위한 효율적인 deep neural network architecture에 집중할 것이다.
'Inception'은 유명한 Internet meme인 "we need to go deeper"라는 문구에서 가져왔다.
 (https://knowyourmeme.com/memes/we-need-to-go-deeper)
(https://knowyourmeme.com/memes/we-need-to-go-deeper) -
우리의 경우, "deep" 이라는 단어는 2가지 의미로 해석된다.
- we introduce a new level of organization in the form of the "Inception module".
- the more direct sense of increased network depth.
2. Related Work
-
LeNet-5부터 시작하여 VNN은 전통적으로 standard structure를 갖는다.
➡️ stacked convolutional layers (optinally followed by contrast normalization and max-pooling) are followed by one or more fully-connected layers.
이러한 basic design은 image classification에서 유행처럼 사용되고, 좋은 결과를 얻고 있다.
Imagenet과 같은 larger dataset에 대해서는
the number of layers and layer size를 늘리고 있고, overfitting 문제를 위해 dropout도 사용된다. -
max-pooling layer가 accurate spatial information의 손실을 초래한다는 사실에도 불구하고,
CNN은 localization, object detection, human pose estimation 등에 성공적으로 사용되고 있다. -
영장류 시각 피질에 대한 생물학적 model에서 영감받은 신경과학 model은 Inception model과 비슷하게,
다양한 scale을 다루기 위해 각각의 다른 Gabor filter들을 사용했다.
하지만 이 2-layer deep model과는 달리,
Inception model의 모든 filter들은 학습되어진다.
게다가, GoogleNet model의 경우 22-layer deep model인데
Inception layer는 많이 반복된다. -
최근 object detection에 대한 선도적인 접근 방식은 Girshick et al.에 의해 제안된 R-CNN(Regions with Convolutional Neural Networks)이다.
R-CNN은 overall detection problem을 2가지 subproblem으로 나눈다.- category에 구애받지 않는 fashion에 대한 potential object proposal을 위한 color와 superpixel 일관성과 같은 low-level 단서들을 이용한다.
- 그리고나서 이러한 location에 대한 object category들을 식별하기 위해 CNN classifier를 사용한다.
-
우리는 R-CNN과 비슷한 pipline을 채택했다.
하지만 두 subproblem을 multi-box prediction과 ensemble 접근법과과 같은 방법으로 더욱 강화했다.
3. Motivation and High Level Consideration
-
deep neural network의 성능을 향상시키는 가장 직관적인 방법은 model의 size를 키우는 것이다.
(increasing the depth and its width : the number of units at each level)
이 방법은 쉽고 안전한 방법이지만, 이 간단한 방법은 2가지 주요한 단점을 갖는다.- 'Bigger size'라는 것은 일반적으로 parameter 수가 많음을 의미한다.
그리고 그것은 overfitting을 만든다.
특히 training에서 labeled example 개수가 제한될 때 심하다. - the dramatically increased use of computational resources.
- 'Bigger size'라는 것은 일반적으로 parameter 수가 많음을 의미한다.
-
위 두가지 issue를 해결하기 위한 기본적인 방법은
fully connected를 sarsely connected architecture로 바꾸는 것이다.
하지만 오늘날 computing infrastures는 non-uniform sparse data structure에 대한 numerical calculation이 비효율적이다.
Also, non-uniform sparse models require more sophisticated engineering and computing infrasture.(Seminar Discussion) -
(이후 내용 모르겠어서 생략)
4. Architectural Details
-
The main idea of the Inception architectureis based on finding out
how an optimal local sparse structure in a convolutional vision network
can be approximated and covered by readily(손쉽게) available dense components.
우리가 원하는 것은 optimal local construction을 찾는 것이고, 그것을 반복하는 것이다.
우리는 earlier layer의 각 unit이 input image의 some region에 해당한다고 가정하고,
이 unit들은 filter bank로 group화 된다.
input에 가까운 lower layer에서는 correlated된 unit들은 local region에 집중된다.
이는 많은 cluster가 single region에 집중되고 다음 layer에서는 NIN에서 제시된 것처럼 1 x 1 convolution layer로 cover될 수 있음을 나타낸다.
하지만 larger patch에 대한 convolution으로 cover할 수 있는 1 x 1 filter들은 적어지고,
이는 larger region에 대한 patch가 줄어듦을 의미한다. -
이러한 patch alignment issue를 피하고자,
Inception architecture는 filter size를 1x1, 3x3, 5x5로 제한했다.
이 결정은 necessity가 아닌 convenience에 기반한다.
추가적으로 현재 state of the art CNN에 기반하여 pooling operation은 필수적이기 때문에
alternative parallel pooling path를 추가했다.
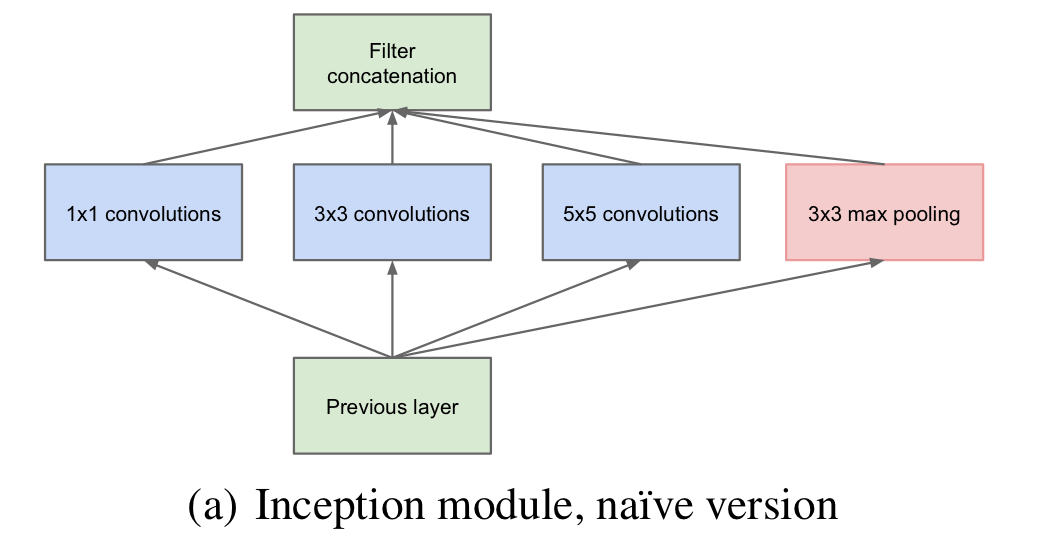
-
위 naive version Inception module은 하나의 큰 문제가 있다.
바로 5x5 convolution은 computational 비용이 많이 든다는 것이다.
그래서 naive version을 개선한 (b) Inception moduel with dimension reductions architecture를 만들었다.
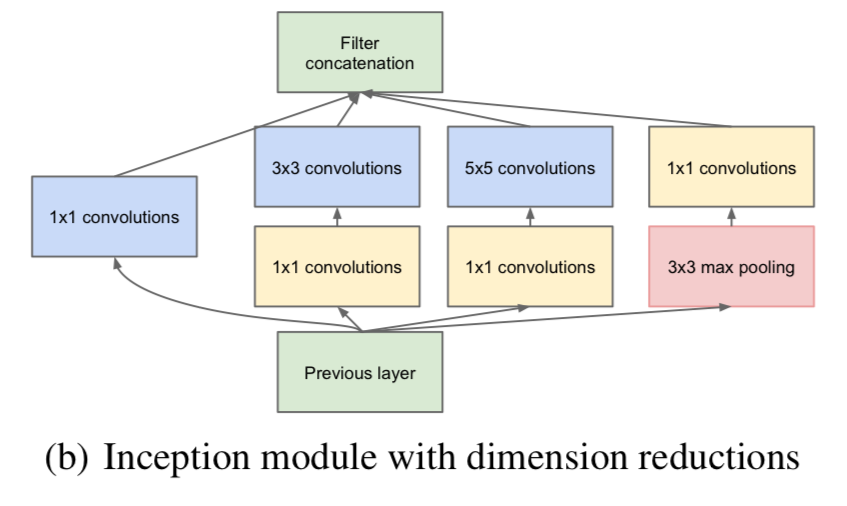 1x1 convolution이 3x3과 5x5 convolution하기 전에 reduction을 수행하기 위해 사용된다.
1x1 convolution이 3x3과 5x5 convolution하기 전에 reduction을 수행하기 위해 사용된다.
reduction으로 사용되기도 하지만, ReLU activation이 포함되어 있기 때문에 dual-purpose를 갖는다. -
In general,
Inception network는 (b) module이 stack되어 만들어진 network이다.
with occasional max-pooling layers with stride 2 to halve the resolution of the grid.- 이 architecture에 대한 one of the main beneficial aspects는
과도한 computational complexity 없이 각 stage마다 unit수를 늘릴 수 있다는 것이다. - Another practically useful aspect는
visual 정보가 다양한 scale로 처리되고, 다음 layer는 동시에 서로 다른 feature를 추출할 수 있다는 것이다.
- 이 architecture에 대한 one of the main beneficial aspects는
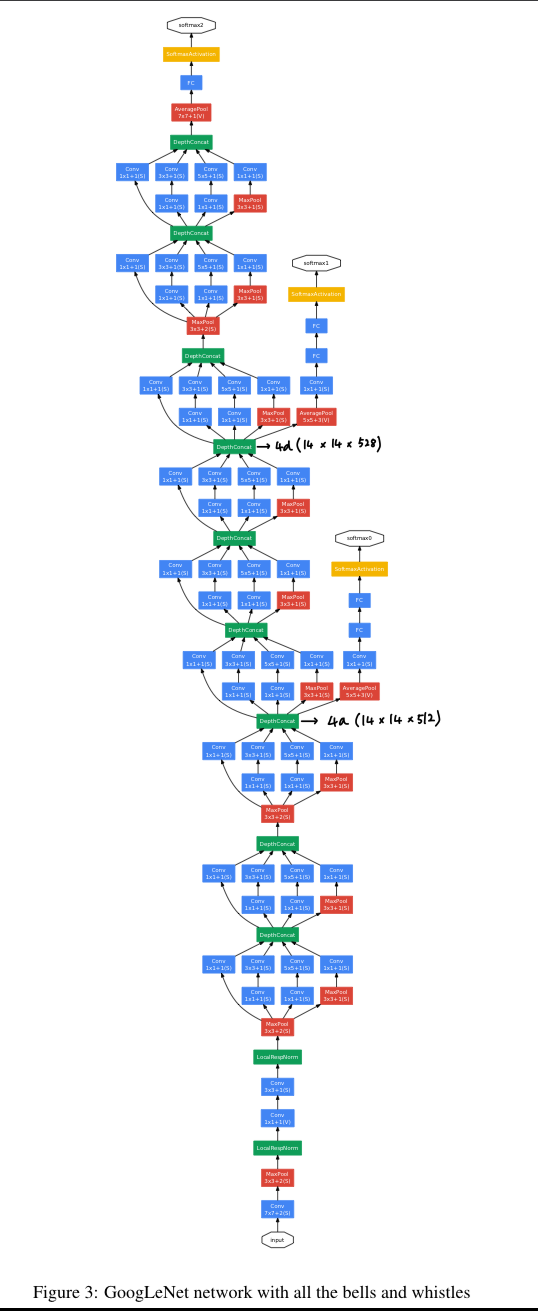
5. GoogLeNet
-
우리는 ILSVRC14 competition에 team-name을
GoogLeNet이라고 정했다.
이 이름은
LeCun의 LeNet5 network를 오마주한 것이고,
competition을 위해 Inception architecture를 적용한 network 이름으로도 사용했다. -
Here, the most successful particular instance(named GoogLeNet) is described in Table 1 for demonstrational purposes.
우리의 ensemble 7개 model 중 6개 model에 대해 정확히 동일한 topology가 사용되었다.
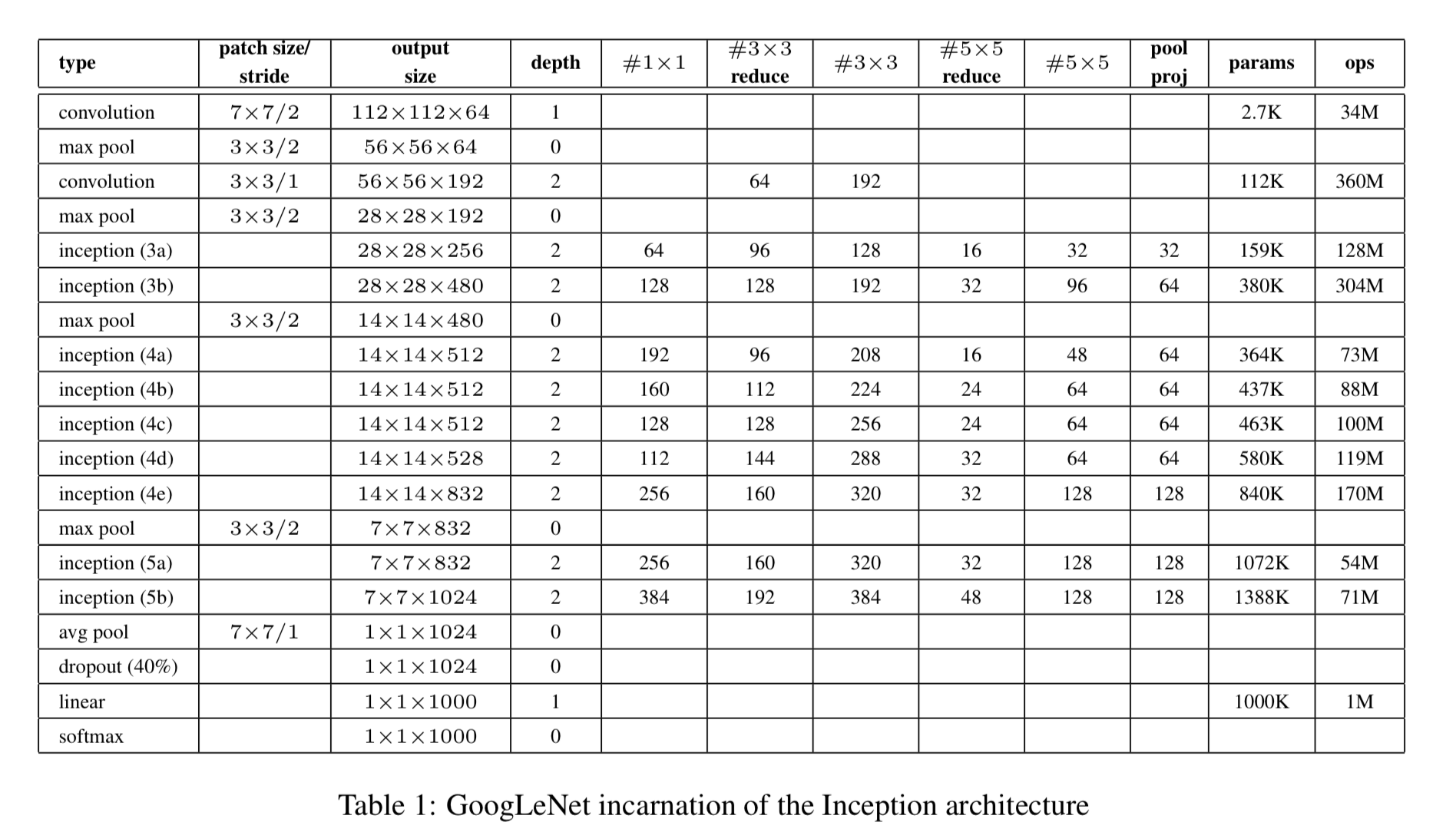
- Inception moduels에 있는 모든 convolution 연산은 ReLU activation을 사용했다.
- 우리 network의 receptive field size는 mean subtraction을 한 224 x 224 RGB color channel이다.
- "#3x3 reduce", "#5x5 reduce"는 3x3, 5x5 convolution을 하기 전에
1x1 filter를 사용한 reduction layer를 나타낸다. - 모든 reduction/projection layer도 마찬가지로 ReLU를 사용했다.
- 이 network는 computational efficiency와 practicaity를 유념하여 design되어졌다,
그래서 inference는 low-memory를 갖고 있고, limited computational resource를 갖는 device에서 동작할 수 있다. - network는 parameter만 있는 layer만 고려하면 22 layer로 되어있다.
(pooling layer까지 세면 27 layer) - classifier 전에 average pooling을 사용하는 것은 NIN에 기초했다.
- model의 depth가 깊은 경우, gradient vanishing 문제가 발생할 수 있다.
이때, 상대적으로 shallower network의 strong performance는 매우 discriminative할 수 있다.
그래서 중간 layer에서 auxiliary(보조의) classifier를 추가하여,
back propagation 동안 gradient signal을 더욱 더 증가시켰고,
추가적인 regularization 효과를 제공할 수 있다.
auxiliary classifier는 Inception (4a) and (4d) modules의 output에 붙였다.
training 동안에 이들의 loss가 전체 loss에 지나치게 영향을 미치는 것을 막기 위해 auxiliary classifier의 loss에 0.3을 곱하여 가중을 두었다.
inference 동안에는 이 auxiliary network는 사용하지 않았다.
auxiliary classifier를 포함한 정확한 struxture는 다음과 같다.
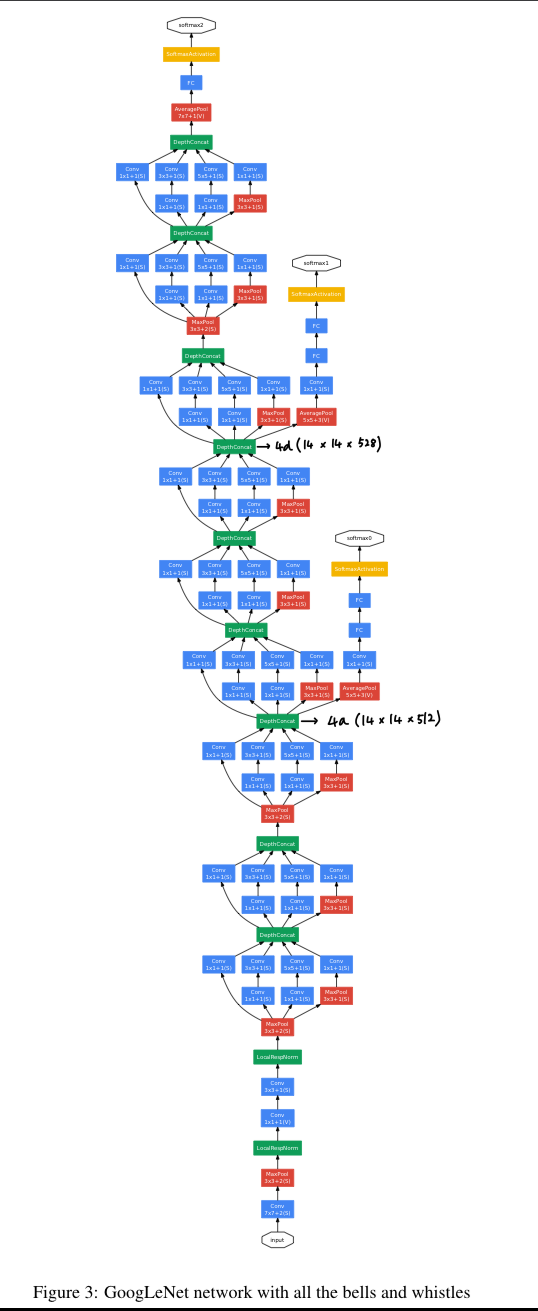
- An average poolilng layer with 5x5 filter size and stirde 3,
resulting in an 4x4x512 output for the (4a), and 4x4x528 for the (4d) stage. - A 1x1 convolution with 128 filters for dimension and ReLU
- FC layer with 1024 units and ReLU
- A dropout layer with 70% ratio of dropped outputs.
- A linear layer with softmax loss as the classifier (1000 classes)
- An average poolilng layer with 5x5 filter size and stirde 3,
6. Training Methodology
-
우리의 main limitation은 memory usage이기 때문에, CPU 기반 구현만 사용했지만
대략적인 추정으로는 GoogLeNet network가 몇 개의 고급 GPU를 사용하지 않고도
일주일 내에 수렴하도록 train되어질 수 있다는 것을 시사한다. -
0.9 momentum으로 stochastic gradient descent,
8 epoch마다 learning rate를 4% 줄임,
inference time에 Polyak averaging을 사용. -
우리의 image sampling method는 competion이 시작된 몇 달 동안 계속해서 바뀌었으며,
때로는 dropout과 learning rate와 같은 hyperparameter의 option들이 바뀌면서 train되어졌다.
그래서 이 network를 train시키기에 가장 효율적인 방법을 명확히 하기 어렵다 -
image의 가로, 세로 비율을 3:4와 4:3 사이로 유지하며
원래 size의 8%~100%가 포함되도록 다양한 크기의 patch를 사용했고
photometric distortions을 통해 training data를 augmentation했다.
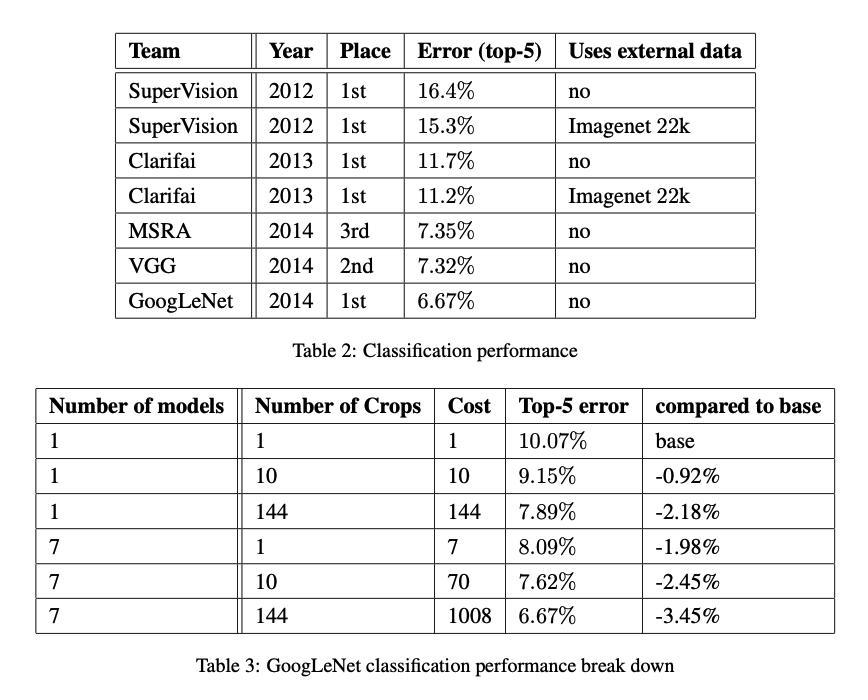
7. ISLVRC 2014 Classification Challenge Setup and Results
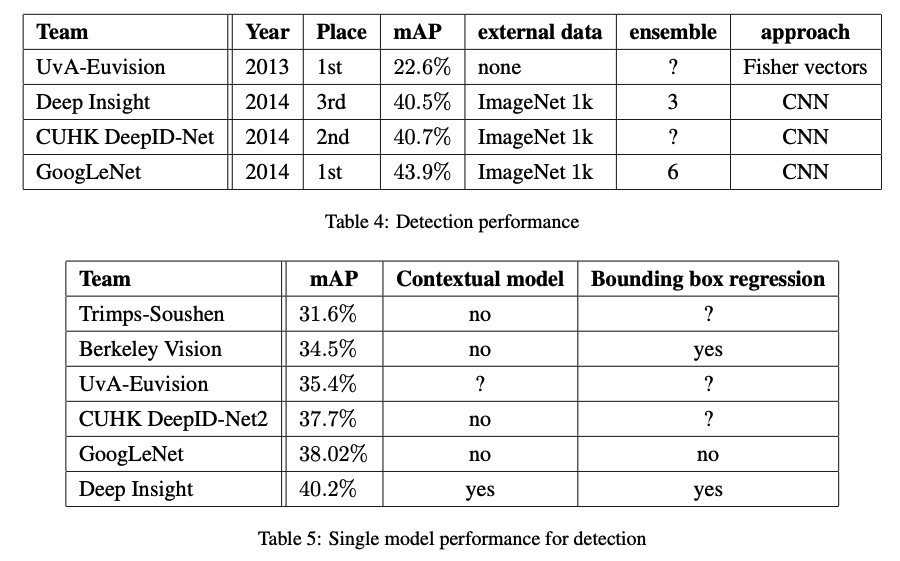
8. ILSVRC 2014 Detection Challenge Setup and Results
9. Conclusions
-
우리의 결과는 쉽게 이용할 수 있는 dense building block에 의해 예상되어지는
sparse structure를 approximating하는 것이
computer vision을 위한 neural network 개선을 위한 실행 가능한 방법이라는 확실한 evidence를 제시한 것 같다. -
이 방법의 가장 큰 장점은
shallow and less wide network에 computational requirements를 늘리지 않고 quality를 향상시킬 수 있다.
Seminar - discussion
-
sparse matrix는 parameter가 줄어들지만, 연산량은 생각보다 크게 줄지 않는다.
sparse matrix는 dense matrix로 복원하는 작업 후에 연산을 진행해야 하기 때문에 추가적인 연산이 필요하여 속도가 느려진다.
그리고 병렬화가 어렵다. 그래서 cuda sparse라고 하는 sparse matrix multiplication을 지원해주는 library가 있긴 하지만 그래도 느리다.
결론 : sparse matrix multiplication은 parameter가 줄지만, 연산량이 크게 줄지도 않고 연산속도가 매우 느려진다 -
GoogleNet은 depth가 너무 크다.
그 시절에는 BN, skip connection 아이디어가 없어서 gradient vanishing 문제가 심했다.
그래서 softmax2, softmax1, softmax0이 있는 것이다.
기존에 end to end model(input-only one softmax)과는 달리
학습의 순서가
(forward) input→softmax0
(backward) softmax→0 → input
(forward) input → softmax 1
(backward) softmax 1→ input
(forward) input → softmax2
(backward) softmax2→input
➡️ 이와 같이 된다.
