[2017 ICML] How Do Adam and Training Strategies Help BNNs Optimization?
Paper Info.
ICML 2017

Abstract
-
Binary Neural Networks, BNNs은 일반적으로 Adam optimization을 사용하여 얻어진다.
하지만, Adam이 BNN optimization에서 SGD와 같은 다른 optimizers보다 우수한 근본적인 이유를 탐구하거나 특정 학습법을 뒷받침하는 분석적 설명을 제공하는 연구는 거의 없었다. -
이를 해결하기 위해, 본 논문에서는 먼저 BNN의 학습 과정에서 gradients and weights의 trajectories(경로)를 조사한다.
우리는 Adam의 second-order momentum이 가지는 regularization effect가 BNNs의 activation saturation으로 인해 소멸된 weights를 되살리는 데 중요한 역할을 한다는 것을 보여준다.
또한, Adam은 adaptive learning rate strategy를 통해 BNN의 rugged(거친) loss surface을 보다 효과적으로 처리하고, 더 나은 optimum에 도달하며 generalization ability가 높다는 것을 발견했다. -
더 나아가, BNN에서 real-valued weights가 가지는 intriguing(흥미로운) role을 조사하고,
weight decay가 BNN optimization의 안정성과 sluggishness(학습 속도 저하)에 미치는 영향을 밝혀낸다.
1. Introduction
- BNN의 high compression ratio에도 불구하고, binary weights의 discrete한 특성은 optimization 과정에서 challenge를 제시한다.
conventional DNNs은 highly non-convex optimizing space에서 good optima를 찾는 능력에 크게 의존한다고 알려져 있다.
real-valued neural network와 달리, BNNs은 weights and activations이 discrete value(-1, +1)로 제한하며,
이는 model의 representational capacity를 자연스럽게 제한하고 real-valued networks와는 다른 optimization landscapes를 초래한다.
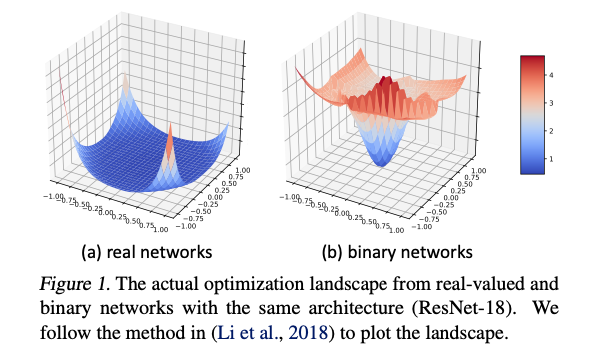
Figure 1에서와 같이, BNN은 real-valued networks보다 더 혼란스럽고, 많은 Local minima로 인해 optimization이 어렵다.
- Wilson et al. (2017)의 최근 이론적 연구에 따르면,
Adam과 같은 adptive learning rate 방법은 momentum이 적용된 SGD보다 optimal minima를 더 적게 찾는 경향이 있으며,
이는 SGD로 찾은 minima가 Adam으로 찾은 minima보다 generalization ability가 더 뛰어나다는 것을 의미.
이는 Adam이 더 좋은 convergence guarantee를 제공하고 SGD보다 더 나은 성능을 발휘할 것으로 예상된다는 점을 고려할 때 직관에 반대되는 결과이다.
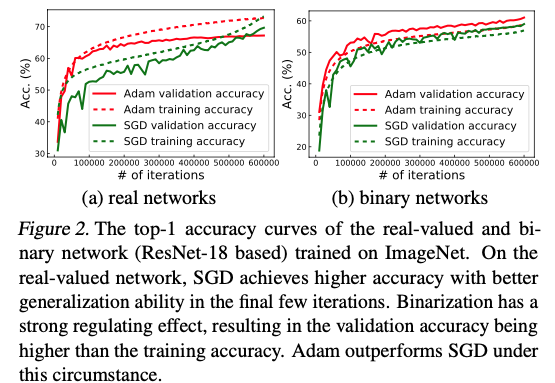 그런데 우리는 real-valued networks가 Figure 2 (a)에서 보이듯이 training data에 "overfit"될 수 있도록 강력하지만, 이러한 현상이 BNN에서는 성립하지 않는다는 것을 확인했다.
그런데 우리는 real-valued networks가 Figure 2 (a)에서 보이듯이 training data에 "overfit"될 수 있도록 강력하지만, 이러한 현상이 BNN에서는 성립하지 않는다는 것을 확인했다.
BNN의 경우, limited model capacity로 인해 train set에 오히려 underfitting되는 경향이 있으며, 이는 긴 학습 budget에도 개선되지 않는다.
Figure 2(b)에서 확인할 수 있듯이, BNNs에서 SGD를 사용할 경우 val acc가 Adam보다 더 크게 변동하며 이는 SGD가 discrete weight optimization space의 rugged surface에 쉽게 갇혀 generalizable local optima를 찾는 데 실패함을 나타낸다.
(BNNs에서 SGD는 계속해서 local space에 갇혀 optima를 찾기 힘들다는 의미인듯)
- 이러한 관찰을 바탕으로, 본 논문에서는 BNN에서 Adam이 SGD보다 더 효과적인 근본적 이유를 탐구한다.
BNN 학습 과정에서는 activation saturation 효과로 인해 일부 gradient가 0이 되는 경향이 있다.
SGD를 optimizer로 사용할 때는 개별 weight의 updating step은 gradient 크기와 일치하기 때문에 초기화가 잘못거나 local minima에 빠진 상태의 "dead" weights를 변경하기 어렵다.
직관적으로, "dead" weights에 적절한 gradients를 활성화하면 BNN의 accuracy를 크게 향상시킬 수 있으며, 이는 우리의 시각화 결과와 최종 정확도를 통해 입증된다.
3. Methodology
3.2. Observations
3.2.4. PHYSICAL MEANING OF REAL-VALUED WEIGHT
 SGD with modmentum과는 다르게,
SGD with modmentum과는 다르게,
second momentum term(Algorithm 1에서 )을 나눠줌으로써 parameter update시 gradient가 0로 되는 것을 방지할 수 있다.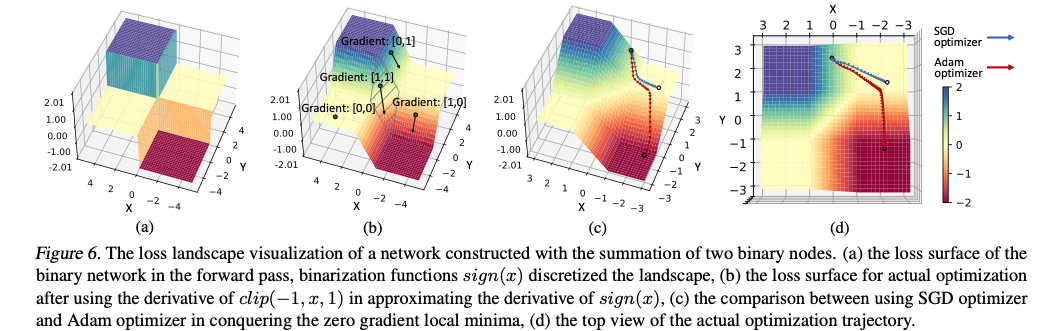 그래서 위 그림처럼 gradient가 거의 없는 X, Y축 동시에 2~4에서 SGD optimizer는 수렴하고, Adam optimizer는 그 평평한 local space를 빠르게 빠져나올 수 있게 된다.
그래서 위 그림처럼 gradient가 거의 없는 X, Y축 동시에 2~4에서 SGD optimizer는 수렴하고, Adam optimizer는 그 평평한 local space를 빠르게 빠져나올 수 있게 된다.
3.3. Metrics for Understanding BNN Optimization
- FF: Flip-flop ratio는 optimization stability를 나타내는 지표로, quantization된 후 값이 threshold를 넘어 부호가 반전되었다면 +1이 된다.
예를 들어, BNN이니까 quantization 전 +1이 었던 weight가 parameter update 이후 quantization 했더니 -1이 되었다면, 이는 flip-flop이 된 것이다.
학습 초기에 flip-flop이 많이 발생하는 것이 좋지만, 학습이 진행될수록 flip-flop이 덜 발생하는 것이 좋다.
학습 후기에도 FF ratio가 크다는 것은 학습이 불안정하다는 것을 의미하기 때문이다.

- : 초기 weight의 sign과 학습이 종료된 후 final weight의 sign의 일치를 나타내는 지표이다.

3.3.3. Pratical Training Suggestion
-
zero값 근처에 몰려 있는 weights들에 대해서,
zeero 주변으로 weights들을 모이게 유도한다면,
아주 약간의 값 변화는 binary weights에 큰 영향을 줄 수 있다. -
우리는 최근 two-step training algorithm에 대한 좋은 weight decay scheme을 찾았다.
Step1에서는, 단지 activations만 binarized하고, real-valued weights에는 weight decay를 적용하여 작읍 update value를 accumulate한다.
real-valued networks는 FF ratio에 대한 걱정이 없으므로, weight decay를 추가하여 initialization dependency를 줄이며 이점을 얻을 수 있다.
Step2에서는 BNNs의 latent real weights를 Step1에서 학습된 weights로 initialization하고, weight decay를 0으로 설정한다.
이 방법으로 FF ratio를 감소시켜 training stability를 개선하고, random init이 아닌 Step1의 good init을 활용할 수 있다.
이 단계에서는 C2I ratio optmization에 해가 되지 않는다.
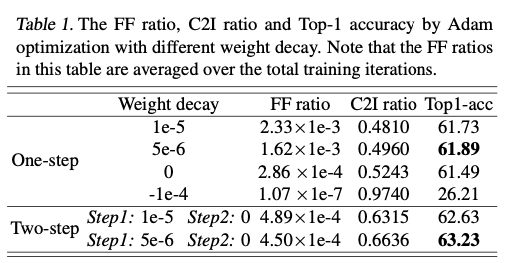
(단, One-step에서 weight decay를 너무 크게 해서는 안됨.
사실, one-step에서는 weight decay를 써서 weight가 0 주변에서 모이도록 유도하여 부호 변경을 보다 자유롭게 만드는 것이긴 하지만,
그렇다고 weight decay를 너무 크게하는 것은 학습을 불안정하게 만듦.
요약하자면 weight decay가 필요하지만, 적당한 값을 취하는게 좋다)
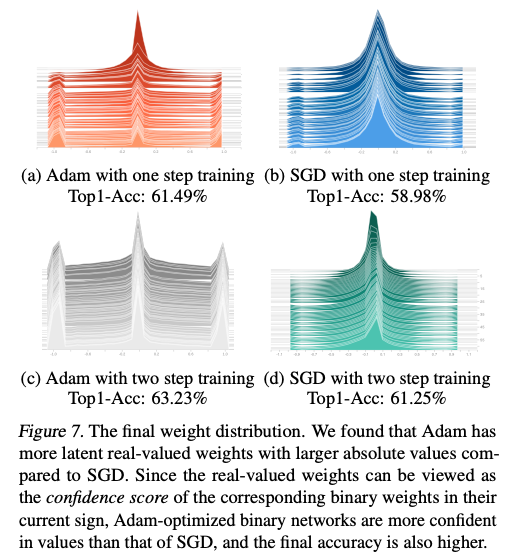
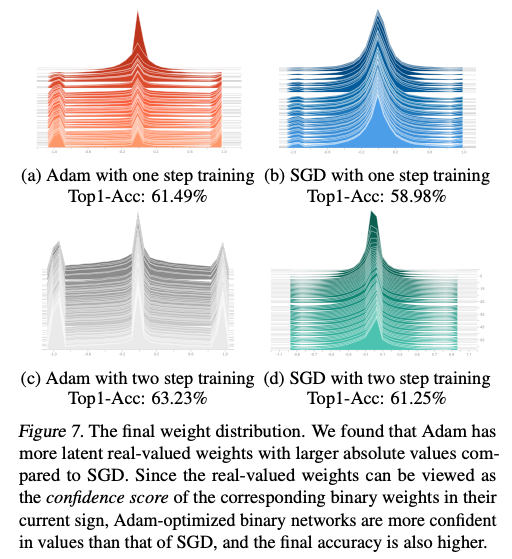
학습 결과,
Adam이 더 많은 절대값이 큰 real-valued weight를 유지
real-valued weights를 confidence score의 개념으로 볼 수 있기 때문에 Adam의 real-valued weights는 더 confidence를 갖고 있음을 의미.
결론
Adam의 2차 momentum이 weight update시 scale 조정을 더 잘 수행하기 때문에
dead weights 문제를 SGD with momentum보다 잘 해결할 수 있고, 안정적이고 강한 gradient signal을 유지할 수 있음.
또한 two-step training에서 one-step 때는 weight decay를 사용하여 weights들이 0근처에 몰려서 sign을 보다 자유롭게 바꿀 수 있도록 유도하고,
two-step에서는 weight들의 학습 진행 상황과 안정성을 고려하여 weight decay를 없애서 더 이상 0에 가까워지도록 유도하지 않고 confidence를 갖게 내버려둠로써 학습 결과를 향상.
