[중단] LGD: Label-guided Self-distillation for Object Detection
https://arxiv.org/abs/2109.11496
Paper Info.
- Zhang, Peizhen, et al. "LGD: Label-guided self-distillation for object detection." Proceedings of the AAAI conference on artificial intelligence. Vol. 36. No. 3. 2022.
Abstract
-
이 논문에서는 general object detection을 위한
first self-distillation framework인 LGD(Label-GUided self-Distillation)을 제안한다.
이전 연구들은 강력하게 pretrained된 teacher model을 사용하여 실제 환경에서얻기 어려운 knolwedge를 제공받았지만,
우리는 student representations과 regular labels만을 기반으로 knowledge를 생성한다. -
우리의 framework는 sparse label-appearance encoder, inter-object relation adapter and intra-object knowledge mapper를 포함하여,
training 단계에서 label과 진화하는 student representations에 동적으로 의존하는 implicit(암묵적인) teacher를 형성한다.
이들은 detector와 함께 end-to-end trained되며 inference 시에 discarded된다. -
실험적으로, LGD는 다양한 detectors, datasets, instance segmentation과 같은 extensive tasks에서도 좋은 결과를 얻는다.
https://github.com/megvii-research/LGD.
1. Introduction
-
Knowledge Distillation(KD)는 초기에 image classification을 위해 제안되었으며 인상적인 결과를 얻었다.
일반적으로 이는 pretrained된 model(teacher)로부터 더 작은 model(student)로 knowledge를 transferring하는 과정이다.
최근에는 KD가 fundamental object detection task에 적용되면서 researcher들의 관심을 끌었다.
기존의 연구들은 존경할만한 성과를 달성했지만 teacher model의 선택이 sophisticated and inconsistent(까다롭고 일관되지 않음)하다.
공통된 점은 최근 연구들에서 distillation의 efficacy가 stronger teacher에 의해 향상될 수 있음을 발견한 결과,
모두 heavy pretrained teacher를 필요로한다는 것이다.
그러나 이상적인 teacher model을 찾는 과정은 real-world applications에서는 거의 만족되지 않으며,
많은 efforts on trial and error(시행착오)가 필요할 수 있다.
대신 "KD for generic detection without pretraind teacher(pretrained teacher 없이 generic detection을 위한 KD)"는 거의 연구되지 않았다. -
pretrained teacher dependence를 완화하기 위해, teacher-free scheme이 제안되었다.
예를 들어 (a) self-distillation, (b) collaborative learning, (c) label regularization 등이 있다.
하지만 이렇나 방법들은 classification을 위해 design되었으며,
detection은 single image classification과 달리 여러 objects를 다뤄야 하기 때문에 detection에는 inapplicable하다. -
최근에는 LabelEnc가 기존의 label regularization을 확장하여 location-category modeling을 isolated network로 도입했다.
이를 통해 student features를 supervise할 label representations을 생성한다.
인상적인 결과를 얻었지만, detector가 더 강력해질수록(larger backbones and multi-scale training) 개선이 saturates된다는 것을 알아냈다. (Figure 3)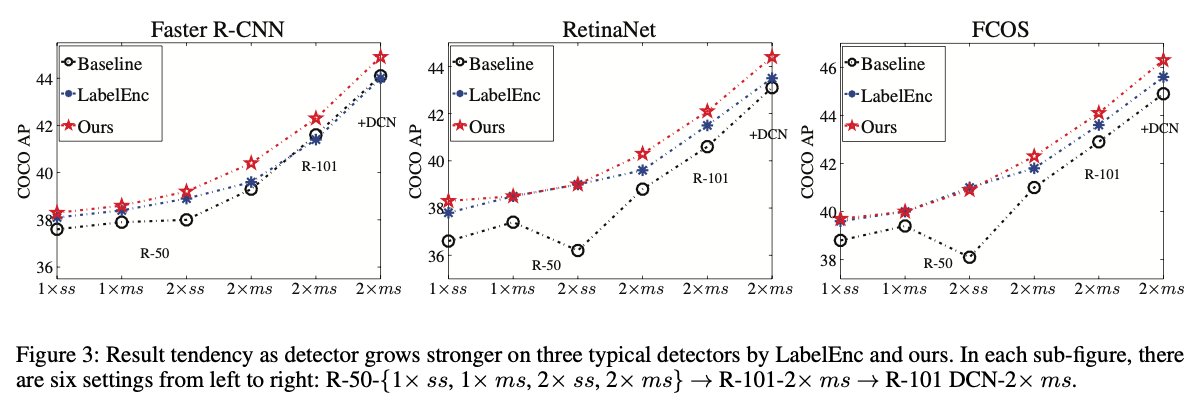 이는 label 자체가 object-wise categories and locations만을 설명하고,
이는 label 자체가 object-wise categories and locations만을 설명하고,
inter-object relationship(object 간의 관계)를 고려하지 않기 때문일 것으로 추측한다.
limited capacity의 detector에서는 LabelEnc가 strong complementary supervision을 제공하지만, object-wise hint를 충분히 추출할 수 있는 stronger detectors에서는 LabelEnc 사용이 덜 유익하거나 심지어 해로울 수 있다. (Figure 3의 가장 왼쪽 그림)
이는 heterogeneous(이질적인) input(image vs. label)과 분리된 modeling으로 인한 semantic discrepancy에서 기인할 수 있다.
- 이와 같은 동기로 인해,
우리는 object detection을 위한 새로운 teacher-free method인 Label-Guided self-Distillation(LGD)를 제안한다. (Figure 2.)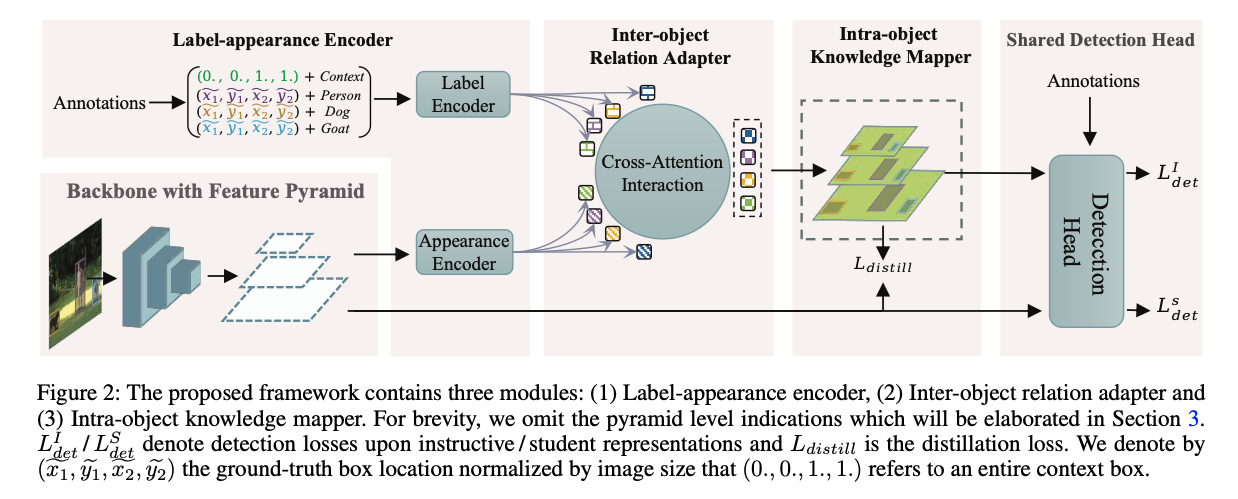 LGD에서 우리는 inter-object relation adapter와 intra-object knowledge mapper를 설계하여
LGD에서 우리는 inter-object relation adapter와 intra-object knowledge mapper를 설계하여
knowledge 형성과정에서 relation을 공동으로 modeling한다.- relation adapter는 cross-attention interaction을 통해 상호작용된 embedding을 계산한다.
구체적으로, 각 object의 상호작용된 embedding은 먼저 해당 object의 appearance embedding과 모든 label embedding 간의 cross-modal similarity를 측정하고, 그 위에 weight-aggregation를 수행하여 계산된다. - knwoledge mapper는 intra-object representation consistency와 localization heuristics을 고려하여
상호작용된 embedding을 feature map space에 final knowledge으로 mapping한다.
위의 relation modeling 덕분에, final knowledge는 student representations에 자연스럽게 적응되어
강력한 student detector를 위한 효과적인 distillation과 semantic discrepancy mitigation(완화)를 촉진한다.
efficacy 외에도, 우리의 method는 efficient하다.
- relation adapter는 cross-attention interaction을 통해 상호작용된 embedding을 계산한다.
- 우리는 strong CNN을 teacher로 사용하지 않고 효율적인 instance-wise embedding design을 채택하기 때문에
efficacy를 넘어, 우리의 method는 efficient하다.
이러한 효율적인 design 덕분에 LGD는 student와 공동으로 훈련할 수 있으며, Pipeline을 단순화하고 training cost를 절감한다 (Table 7)
inference 동안에는 student detector만 유지되어 추가 비용이 발생하지 않는다.
요약하자면, 우리의 contribution은 three-fold로 요약된다 :- general object detection을 위한 새로운 self-distillation framework를 제안.
이전 방법들과는 달리 LGD은 pretrained teacher 없이 실시간으로 knowledge를 생성하며, 제한된 training cost로 detection quality를 향상시킨다. - 우리는 단순히 student와 teacher로부터 기존 relation을 추출하는 대신, 새로운 knowledge를 Modeling하기 위해 inter-and-intra relation(객체 간 및 객체 내 관계)을 도입한다.
- 제안된 방법은 이전의 teacher-free SOTA를 능가하며, 강력한 student setting에서 전통적인 teacher-based method인 FGFI보다 더 우수하다.
본질적인 student learning 외에도, classical teacher-based distillation에 비해 51%의 training time을 절약한다.
- general object detection을 위한 새로운 self-distillation framework를 제안.
2. Related Work
2.2 Teacher-free Methods
-
teacher-free schemes을 3가지 categories로 나눌 수 있다.
- self-distillation :
self-distillation은 model 자체에서 knowledge를 발굴한다.
예를 들어,
(Yang et al. 2019; Kim et al. 2020)은 이전에 저장된 snapshots을 teacher로 사용했다.
(Zhang et al. 2019)에서는 network를 여러 Section으로 나누어, deeper layer가 shallower layer를 가르치도록 했다. - collaborative learning :
collaborative learning은 여러 학생이 서로를 돕는 것이다.
(Zhang et al. 2018)는 동일한 architecture를 가진 student network들이 협력하여 학습하는 deep mutual learning(DML)을 제안했다.
(Lan, Zhu, and Gong 2018)은 branch-granularity(branch-단위) ensemble learning을 고려한 ONE을 제안했다. - label regularization :
(Yuan et al. 2020)는 label smoothing을 넘어선 regularized label distribution을 위한 tf-KD를 제안했다.
- self-distillation :
-
그러나 위 방법들은 모두 classification만을 위해 design되었다.
최근에는 isolated nework를 사용하여 label을 feature로 명시적으로 modeling하여 supervision을 제공하는 새로운 label regularization methods가 등장했고, 이들은 인상적인 결과를 얻었다.
(Hao et al. 2020)에서는 category와 location information을 포함한 dense color maps을 생성하고 이를 auto-encoder like network에 입력하여 label representations을 가져왔다.
그러나 이들은 각각의 object modeling만 고려하여 suboptimal이다.
대신, 우리는 inter-object and intra-object relation modeling을 통해 knowledge를 생성하여 higher upper limit을 가진 self-distillation scheme을 제안한다.
(higher upper limit을 가졌다는 의미는 다른 model들보다 성능의 상한선이 더 높다는 얘기.
즉, 더 좋은 성능을 달성할 수 있는 잠재력을 가졌다는 의미)
3. Method
- Fig. 2에서 보이는 바와 같이,
우리는 LGD module을 다음과 같이 설명한다 :
(1) label과 appearance embeddings을 계산하는 encoder
(2) object의 label과 appearance embedding을 받아 interacted embedding을 생성하는 inter-object relation adapter
(3) interacted embedding을 feature map space로 back-projects(다시 투영)하여 distillation을 위한 knowledge를 얻는 intra-object knowledge mapper
3.1 Label-appearance Encoder
(1) Label Encoding
- 각 object에 대해 descriptor를 얻기 위해,
우리는 그 object의 normalized GT box 와 one-hot category vector를 concatenate했다.
그 object-wise descriptor들은 refined label embedding 을 위해 label encoding module로 전달되며,
여기서 는 object index를 나타내고, 은 intermediate feature dimension, 은 #objects를 나타낸다.
은 context object를 indexing한다.
label descriptors 간의 basic relation modeling을 도입하고 permutation-invariant property를 유지시키기 위해,
우리는 classical PointNet을 label encoding module로 채택했다.
이는 MLP와 spatial transformer network로부터 modeling된 local-global modeling으로 descriptor를 처리한다.
또한, label descriptor는 point set과 유사하여 PointNet에 적합하다. (bbox는 4-dimensional Cartesian space에 point로 볼 수 있다.)
경험적으로, PointNet을 encoder로 사용하는 것이 MLP나 transformer encoder보다 약간 더 성능이 좋다. (Table 4)
우리는 또한 BatchNorm을 LayerNorm으로 대체하여 small-batch detection에 적응시켰다.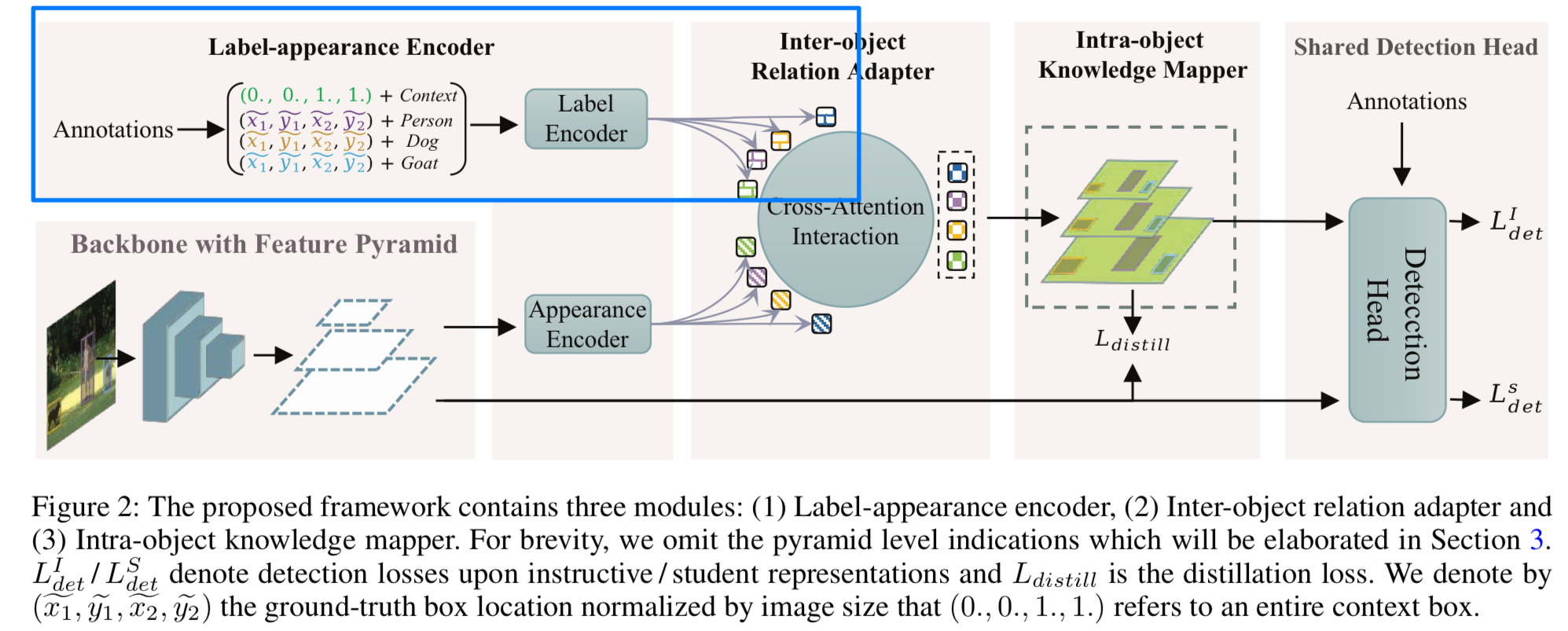
(2) Appearance Encoding
-
label encoding 외에도,
우리는 인식된 object의 appearance feature를 포함하는 student detector의 pyramid feature로부터 compact appearance embedding을 만든다.
우리는 object-wise embedding을 feature map에서 추출하기 위해 간편한 mask pooling을 채택한다.
구체적으로,
우리는 object-wise mask를 사전에 계산한다 :
총 개의 objects에 대해 input level에서
와 전체 image를 덮는 location (0., 0., 1., 1.)를 가진 context object를 포함한다.
각 object 에 대해, 는 binary matrix로, 값이 GT region에서는 1로 set되고 그 외에는 0으로 set된다. -
mask pooling은 모든 pyramid level에서 동시에 수행되며,
각 level에서 input level의 object-wise mask는 해당 resolution에 맞게 down-scaled된다.
-th scale에서, appearance embedding 은
투영된 feature map 과 축소된 object mask 간의 channel-broadcasted Hadamard product를 계산한 후, global sum pooling을 통해 얻는다.
은 single conv layer이다.
따라서, 우리는 각 level 에서 각 object에 대해 appearance embedding: 을 수집한다.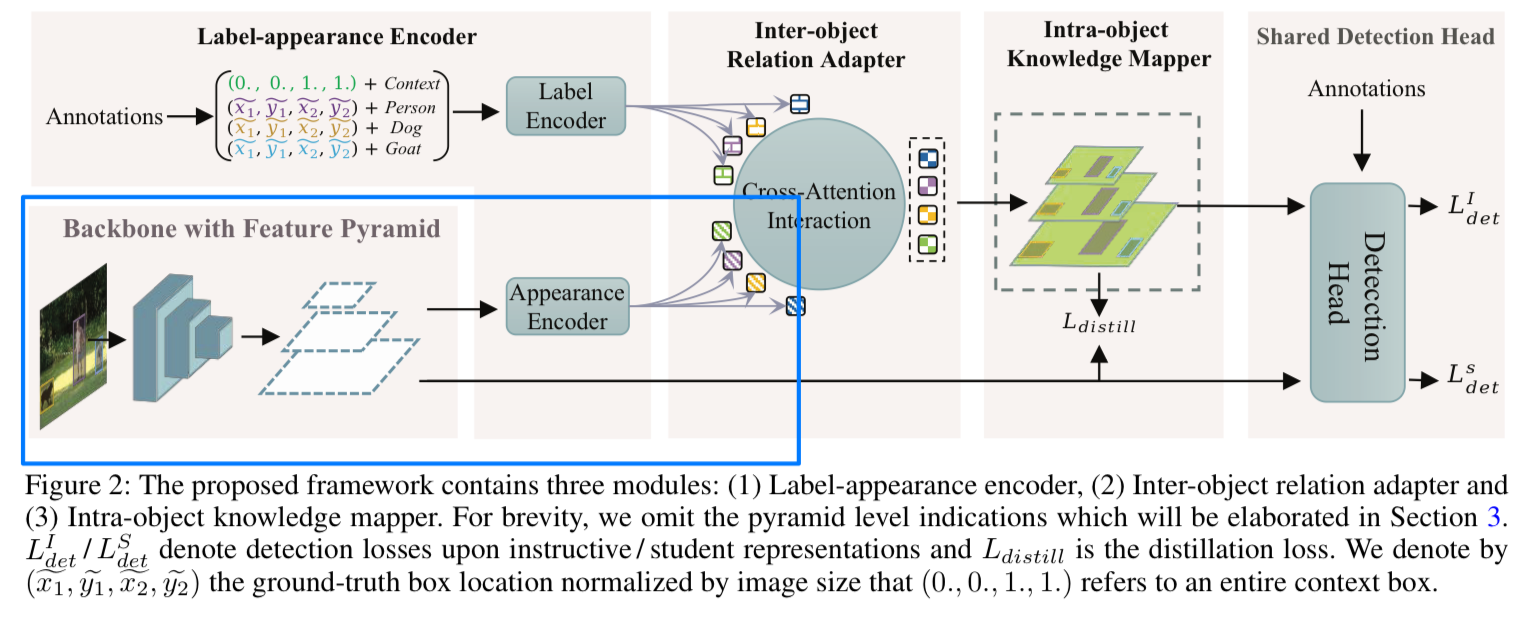
3.2 Inter-object Relation Adapter
- label embedding과 appearance embedding을 고려하여,
우리는 cross-attention process를 통해 inter-object relation adaption을 형성한다.
Fig. 2에서는 이 과정이 student appearance pyramid scale에서 실행되어 interacted embeddings을 검색한다.
간결함을 위해 아래에서는 pyramid scale 첨자를 생략한다.
-
cross-attention 과정에서는 Key와 Query token이 KQ-attention relation을 계산하는 데 활용되어 Value를 aggregating하고 attention output을 얻는다.
현재 scale에서 appearance embedding 를 Query로 사용하고,
scale-invariant label embedding 을 Key와 Value로 사용한다.
attention scheme은 object 간의 lower level structural appearance information와 high-level label semantics 간의 correlation을 측정한 다음,
dynamic adaption을 위해 정보성 있는 label embedding을 재구성한다. -
attention을 진행하기 전에,
Query, Key, Value는 각각 , , linear layer를 통해 변환된다.
그런 다음, 각 변환된 label embedding 를 label-appearance correlation factor 로 가중하여
번째 object에 대한 interacted embeddings 를 계산한다.
(는 scaled dot-product between -th appearance embeddings 와 -th label embeddings followed by a softmax operation에 의해 계산된다.)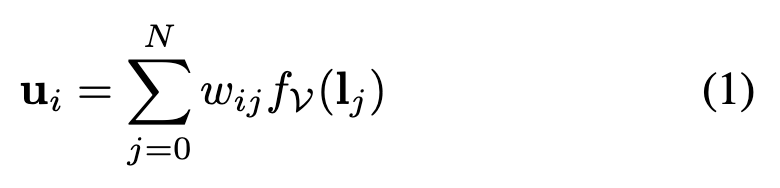 보다 robust한 attention modeling을 위해, 이 paradigm은 실제로 T set의 concurrent operation을 'heads'라고 불리는 용어로 병렬로 수행하여
보다 robust한 attention modeling을 위해, 이 paradigm은 실제로 T set의 concurrent operation을 'heads'라고 불리는 용어로 병렬로 수행하여
부분적으로 interacted된 embedding을 얻는 과정을 포함한다.
모든 heads로부터 부분적으로 상호 작요된 embedding을 연결하고 linear projection 를 적용하여, 모든 object에 대해 interacted된 embedding 을 얻는다. 여기서 [;]는 channel dimension에 따라 partial embedding을 결합하는 concatenation operator를 의미한다.
여기서 [;]는 channel dimension에 따라 partial embedding을 결합하는 concatenation operator를 의미한다.
resulting embeddings은 appearnce embeddings처럼 scale-sensitive하다.
앞서 언급한 바와 같이, 모든 scale에 대해 반복하여 interacted된 embedding을 얻는다.
기술적으로, 위의 계산은 multi-head self attention(MHSA)를 통해 수행된다.
우리의 framework는 특정 선택에 구애받지 않는다.
본 논문에서 보는 바와 같이, LGD는 naive transformer로도 효과를 나타낸다.
더욱 발전된 변형, 예를 들어 focal transformer를 사용하면 더 나은 성능을 발휘할 가능성이 있지만, 이는 본 논문의 범위를 벗어난다.
3.3 Intra-object Knowledge Mapper
-
1D interacted embedding을 널리 사용되는 intermediate feature distillation에 적용 가능하도록 하기 위해,
interacted embeddings을 2D feature map space로 mapping하여 유익한 지식을 얻는다.
자연스럽게, 각 pyramid scale 에 대해, 생성된 map의 resolution은 해당 student feature map과 동일하게 제한된다. (?) -
직관적으로, spatial topology(공간적 위상)가 compact representations(압축 표현)을 위한 label encoding에서 유지되지 않기 때문에,
각 object에 대한 localization information을 복원하여 geometric perspective(기하학적인 관점)에서 alignment(정렬)를 달성하는 것이 중요하다.
자연스럽게, object bbox regions이 좋은 heuristic 역할을 한다.
각 object-binding interacted embedding을 zero-initialized feature map의 해당 GT box region 내에 채운다.
