Research Motivation & Thesis
RT-DETR의 가능성 & 잠재력
-
DETR > Deformable-DETR > RT-DETR의 핵심 아이디어를 순서 기반으로 Review했던 글
-
RT-DETRRT-DETR은 Real-Time DEtection TRansformer의 약자로,
현재 DETR variants에서 가장 Real-Time한 Detector이다.
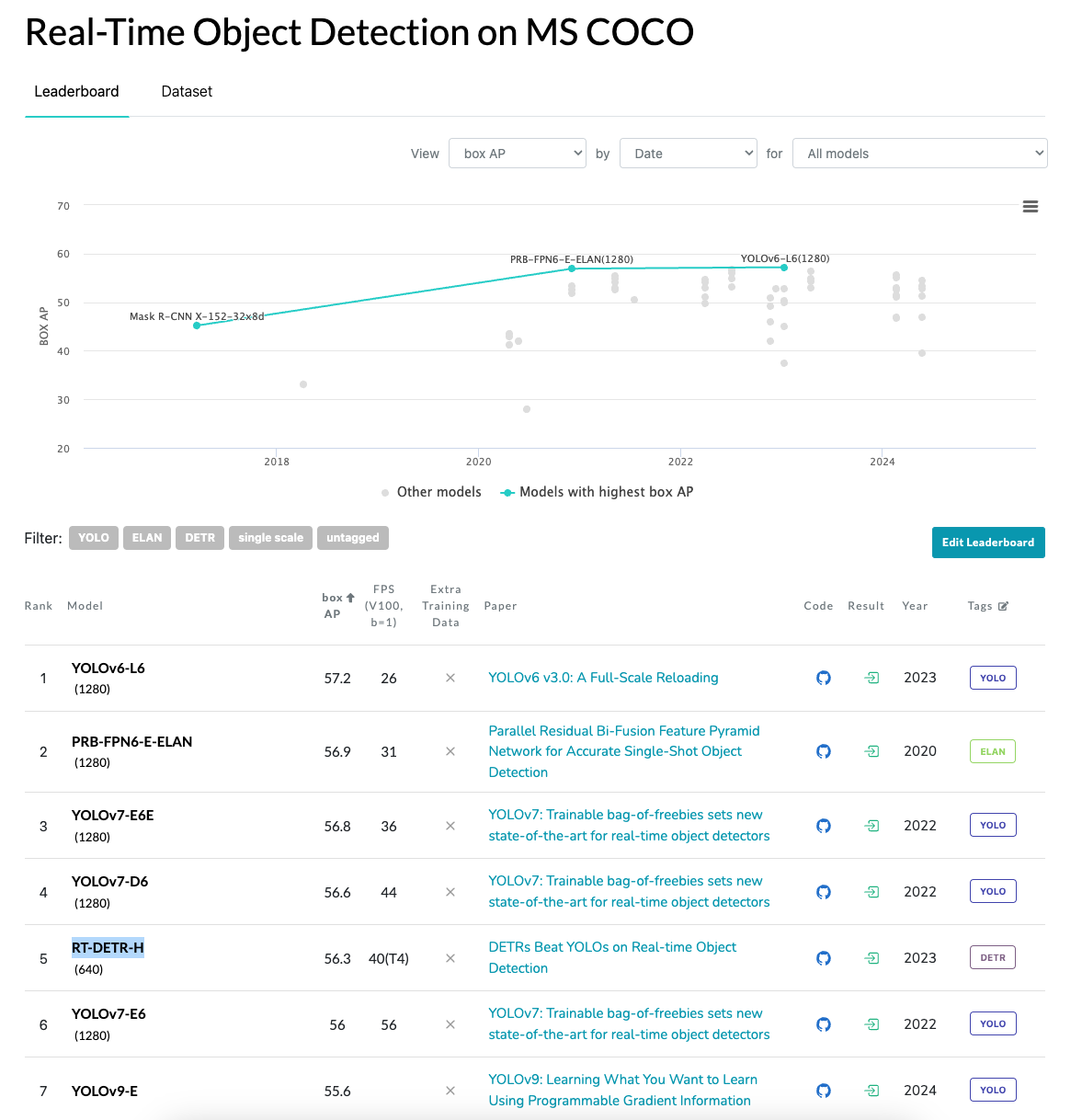
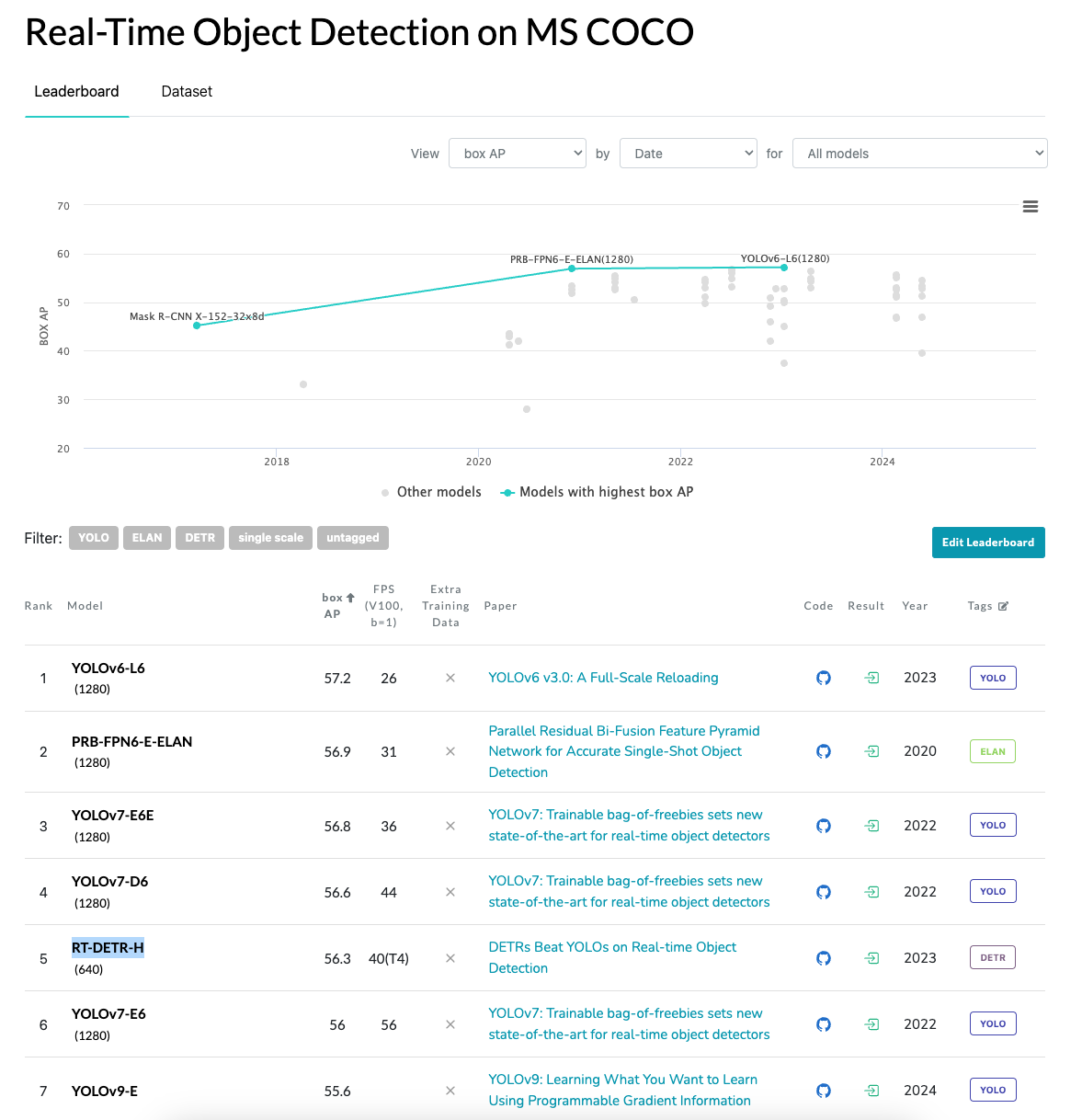
성능이 워낙 좋아서 상업적으로 많이 사용되는 YOLO Series들이 SOTA Leaderboard를 꽉 잡고 있는데,
그 중에서 DETR variants인 RT-DETR의 이름이 올라간 것을 볼 수 있다. (현재 2024.07.08 기준)
- 조금 더 자세히 설명하자면,
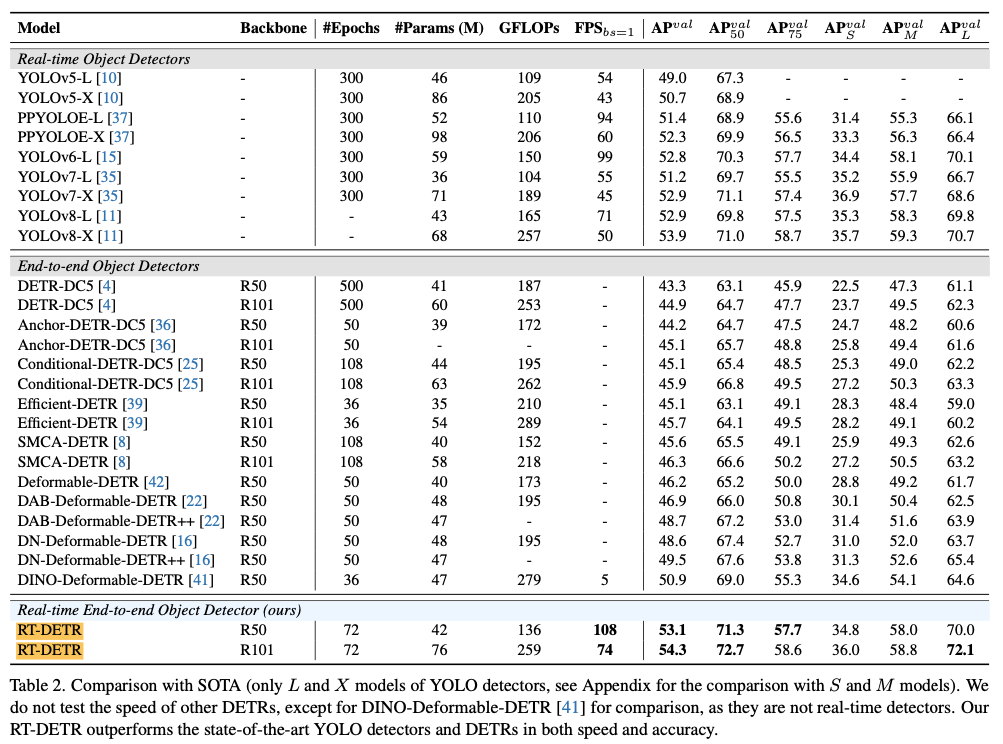
YOLO series는 여태껏 NMS를 포함한 post-processing 시간을 포함하지 않은 결과를 제시했기 때문에,
RT-DETR에서는 이 시간을 포함한 새로운 benchmark로 비교하였고,
논문에서는 새로운 benchmark로 비교했을 때의 결과는 RT-DETR이 YOLO series보다 더 우세하다고 주장한다.
- 조금 더 자세히 설명하자면,
Research Motivation
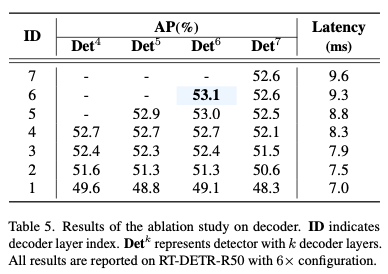
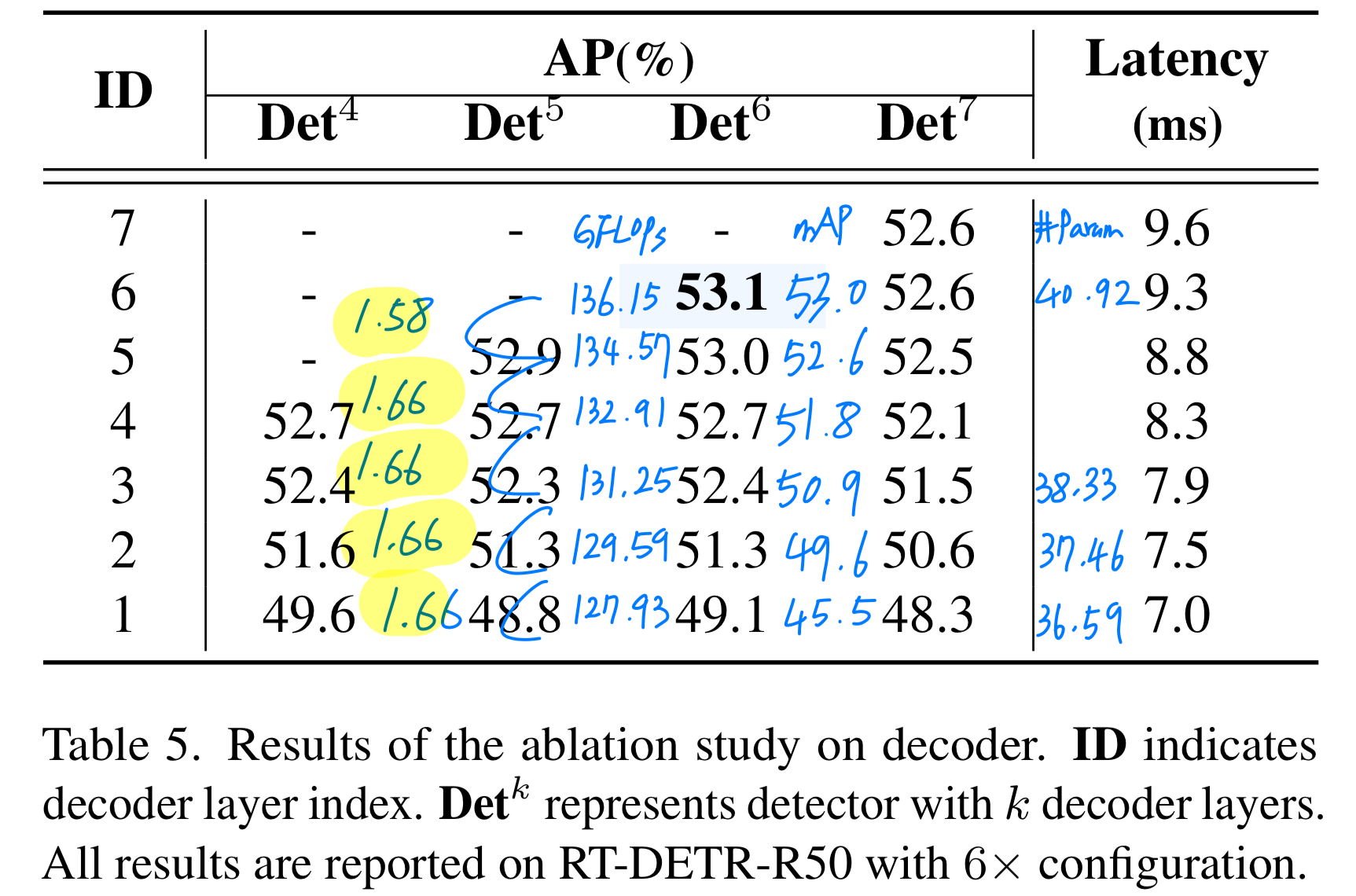
- 논문에서는 Table 5.의 실험 근거로, decoder에서 6개(default)의 layer를 사용한다.
Decoder Computational Cost 탐구
-
위 Table 5.의 결과가 눈에 띄었다.
column은 6개의 layer를 전체 학습시키고나서, inference 때 layer(row)까지만 forward했을 때의 결과를 나타낸다.
여기서 생각할 수 있는 것은 Decoder의 각 layer들은 약간의 성능 향상을 도와줄 뿐, 거의 대부분의 성능은 backbone & encoder에서 형성되는 듯 하다.
➡️ 따라서 "decoder의 computatoin을 많이 줄여도 성능 하락이 적을 것이다"라는 가설을 세웠다.
만약 이 가설이 맞다면, RT-DETR의 efficiency를 더욱 높힐 수 있는 여러 방법을 생각할 수 있을 것이다.
예를 들어,
(1) Decoder를 없애고 다른 효율적인 방법을 제시할 수 있다.
(2) decoder의 Object Queries 수를 동적으로 조절하여 decoder의 computation을 조절함과 동시에 성능을 유지시킬 수 있다.
(3) decoder의 layer 수를 동적으로 조절하여 decoder의 computation을 조절함과 동시에 성능을 유지시킬 수 있다.- 그래서 위 가설이 맞는지 확인해보기 위해 decoder의 GFLOPs(computation)를 파악해봤다.
 파악한 결과,
파악한 결과,
Decoder의 한 layer의 computational cost는 1.66GFLOPs로, 내 예상보다 훨씬 적은 computational cost였다.
- decoder의 object queries에 따른 GFLOPs 변화도 파악해봤다.
아래 그림에서 가 decoder의 Object Queries의 Length이다.
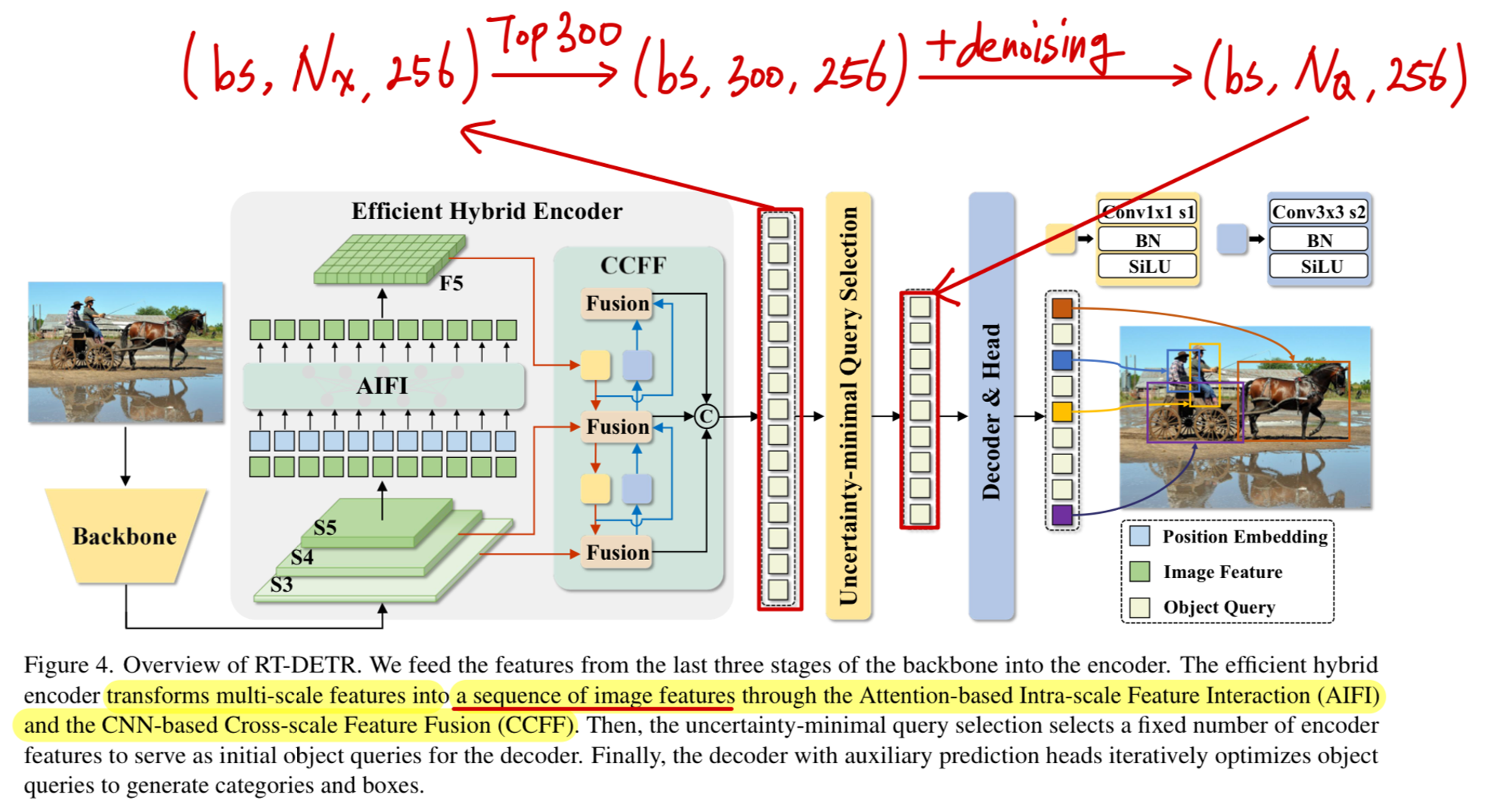

실제로 해보니, object queries 길이는 decoder computation에 크게 영향을 주지 않는다.
- 그래서 위 가설이 맞는지 확인해보기 위해 decoder의 GFLOPs(computation)를 파악해봤다.
-
위 1., 2.의 실험을 바탕으로 생각해볼 수 있는 것은 decoder의 computation은 이미 매우 최적화되어 있고,
다른 Transformer decoder에 비하면 computational cost가 매우 작다는 것을 알 수 있다.
그렇다면 왜 RT-DETR Decoder의 Layer들은 computational cost가 이렇게 적을까?- (내 생각)
decoder의 한 layer는 'Self-Attn ➡️ Cross-Attn(DeformableAttn) ➡️ FFN'으로 구성되어 있는데,
아직은 DeformableAttn의 정확한 계산 원리를 이해하지 못했지만,
DeformableAttn의 효율적인 계산 방식으로 인해 computational cost가 적은 것으로 예상한다.
(추후 DeformableAttn의 계산 방식 이해와 GFLOPs를 탐구해볼 예정)
- (내 생각)
RT-DETR의 구성요소 별 Computational Cost 탐구
- RT-DETR의 구성요소는 크게 3가지 Backbone, Encoder(AIFI + CCFF), Decoder로 되어 있다.
각 구성요소 별 Computational Cost를 찍어보면, 다음과 같다.
(사용한 library : https://github.com/facebookresearch/fvcore/tree/main/fvcore)
| module | #parameters or shape | #flops |
|:----------------------------------------|:-----------------------|:-----------|
| model | 42.891M | 68.984G |
| backbone | 23.474M | 35.321G |
| backbone.conv1 | 28.512K | 2.92G |
| backbone.conv1.conv1_1.conv | 0.864K | 88.474M |
| backbone.conv1.conv1_2.conv | 9.216K | 0.944G |
| backbone.conv1.conv1_3.conv | 18.432K | 1.887G |
| backbone.res_layers | 23.446M | 32.401G |
| backbone.res_layers.0.blocks | 0.213M | 5.453G |
| backbone.res_layers.1.blocks | 1.212M | 8.389G |
| backbone.res_layers.2.blocks | 7.078M | 11.954G |
| backbone.res_layers.3.blocks | 14.942M | 6.606G |
| decoder | 7.467M | 8.156G |
| decoder.input_proj | 0.198M | 0.555G |
| decoder.input_proj.0 | 66.048K | 0.423G |
| decoder.input_proj.1 | 66.048K | 0.106G |
| decoder.input_proj.2 | 66.048K | 26.419M |
| decoder.decoder.layers | 5.975M | 5.275G |
| decoder.decoder.layers.0 | 0.996M | 0.879G |
| decoder.decoder.layers.1 | 0.996M | 0.879G |
| decoder.decoder.layers.2 | 0.996M | 0.879G |
| decoder.decoder.layers.3 | 0.996M | 0.879G |
| decoder.decoder.layers.4 | 0.996M | 0.879G |
| decoder.decoder.layers.5 | 0.996M | 0.879G |
| decoder.denoising_class_embed | 20.736K | |
| decoder.denoising_class_embed.weight | (81, 256) | |
| decoder.query_pos_head.layers | 0.134M | 0.24G |
| decoder.query_pos_head.layers.0 | 2.56K | 3.686M |
| decoder.query_pos_head.layers.1 | 0.131M | 0.236G |
| decoder.enc_output | 66.304K | 0.561G |
| decoder.enc_output.0 | 65.792K | 0.551G |
| decoder.enc_output.1 | 0.512K | 10.752M |
| decoder.enc_score_head | 20.56K | 0.172G |
| decoder.enc_score_head.weight | (80, 256) | |
| decoder.enc_score_head.bias | (80,) | |
| decoder.enc_bbox_head.layers | 0.133M | 1.11G |
| decoder.enc_bbox_head.layers.0 | 65.792K | 0.551G |
| decoder.enc_bbox_head.layers.1 | 65.792K | 0.551G |
| decoder.enc_bbox_head.layers.2 | 1.028K | 8.602M |
| decoder.dec_score_head | 0.123M | 6.144M |
| decoder.dec_score_head.0 | 20.56K | |
| decoder.dec_score_head.1 | 20.56K | |
| decoder.dec_score_head.2 | 20.56K | |
| decoder.dec_score_head.3 | 20.56K | |
| decoder.dec_score_head.4 | 20.56K | |
| decoder.dec_score_head.5 | 20.56K | 6.144M |
| decoder.dec_bbox_head | 0.796M | 0.238G |
| decoder.dec_bbox_head.0.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.1.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.2.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.3.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.4.layers | 0.133M | 39.629M |
| decoder.dec_bbox_head.5.layers | 0.133M | 39.629M |
| encoder | 11.951M | 25.508G |
| encoder.input_proj | 0.919M | 1.472G |
| encoder.input_proj.0 | 0.132M | 0.842G |
| encoder.input_proj.1 | 0.263M | 0.42G |
| encoder.input_proj.2 | 0.525M | 0.21G |
| encoder.encoder.0.layers.0 | 0.79M | 0.398G |
| encoder.encoder.0.layers.0.self_attn | 0.263M | 0.187G |
| encoder.encoder.0.layers.0.linear1 | 0.263M | 0.105G |
| encoder.encoder.0.layers.0.linear2 | 0.262M | 0.105G |
| encoder.encoder.0.layers.0.norm1 | 0.512K | 0.512M |
| encoder.encoder.0.layers.0.norm2 | 0.512K | 0.512M |
| encoder.lateral_convs | 0.132M | 0.132G |
| encoder.lateral_convs.0 | 66.048K | 26.419M |
| encoder.lateral_convs.1 | 66.048K | 0.106G |
| encoder.fpn_blocks | 4.465M | 17.859G |
| encoder.fpn_blocks.0 | 2.232M | 3.572G |
| encoder.fpn_blocks.1 | 2.232M | 14.287G |
| encoder.downsample_convs | 1.181M | 1.181G |
| encoder.downsample_convs.0 | 0.59M | 0.945G |
| encoder.downsample_convs.1 | 0.59M | 0.236G |
| encoder.pan_blocks | 4.465M | 4.465G |
| encoder.pan_blocks.0 | 2.232M | 3.572G |
| encoder.pan_blocks.1 | 2.232M | 0.893G |이를 취합해보면 다음과 같다.
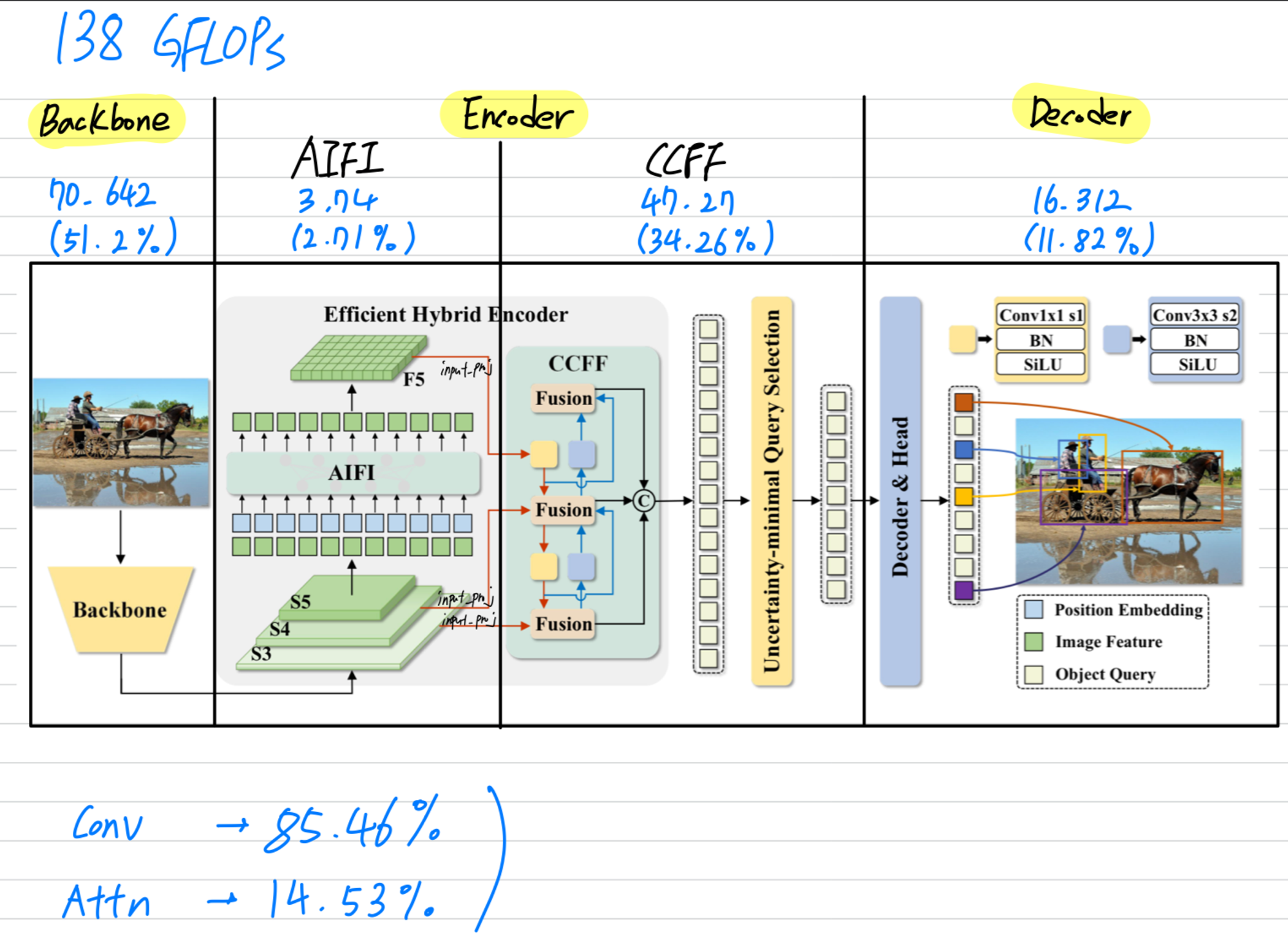 RT-DETR은
RT-DETR은
convolution에 대한 (GFLOPs, #Params)의 비율이 전체의 (GFLOPs:85.46%, #Params:80.74%)이고,
attention에 대한 (GFLOPs, #Params)의 비율이 전체의 (GFLOPs:13.54%, #Params:19.26%)이다.
➡️ 다시 생각해보면,
RT-DETR은 DETR variants이긴하지만, CNN-based Detector인 YOLO에 더 가깝다고 충분히 생각할 수 있다.
물론 약간의 attention 연산과 convolution이 혼합되어 시너지 효과가 있을 수는 있어도,
Detector에서 더욱 우세적인 YOLO series는 거의 대부분을 conv 연산을 사용하기 때문에 전체 성능에 대한 기여량은 conv 연산이 더 많을 것이라고 볼 수 있다.
➡️ 그래서,
RT-DETR에 있는 attention computation에 대해 ablation study를 통해,
소량의 attention computation이 과연 전체 RT-DETR의 성능 향상을 얼만큼 이뤄내는지 살펴볼 것이다.
attention computation이 있는 곳은 딱 두 곳 뿐이다.
1. Encoder의 AIFI module
2. Decoder (위에서 이미 했음. Table 5.)
AIFI Ablation Study
-
AIFI(Attention-based Intra Feature Interaction) Module은
Deformable-DETR에서의 단점이었던 Encoder의 input length(concat())를 줄이기 위해
backbone의 intermediate feature 만 Self-Attn 연산을 적용하는 Module이다. -
AIFI는 RT-DETR의 전체 computational cost 중 2.71%만 차지한다.
과연 이 AIFI module은 RT-DETR에서 꼭 필요한 module일까?
이를 알아보기 위해,
AIFI module을 제거하여 1x schedule로 training(12 epochs)을 시켜봤다.
AIFI module을 제거했기 때문에 기존의 Multi-Scale을 fusion하는 module이었던 CCFF의 input으로 (AIFI(), , ) 대신 (, , )이 사용되었다. w/o(=without) AIFI는 1x schedule training에서 0.7 mAP 성능 하락만 발생하였다.
w/o(=without) AIFI는 1x schedule training에서 0.7 mAP 성능 하락만 발생하였다.
앞서 RT-DETR에 대해서 6x schedule(72 epochs)로 많은 실험을 진행해본 결과,
1x(12 epochs)에서 0.7 mAP 성능 차이는 6x(72 epochs)에서 충분히 극복할 수 있을 정도의 아주아주 작은 성능 하락이다.
(6x training이었다면 최종 성능에서는 차이가 아예 없을 것으로 예상한다)
(이에 대한 근거로 아래 그림을 첨부.)
(1x에서 1.6mAP 차이가 났었지만 6x에서는 0.1mAP 차이로 극복됨.)- 1x(12 epochs)에서의 RT-DETR-SwinT vs. Original :
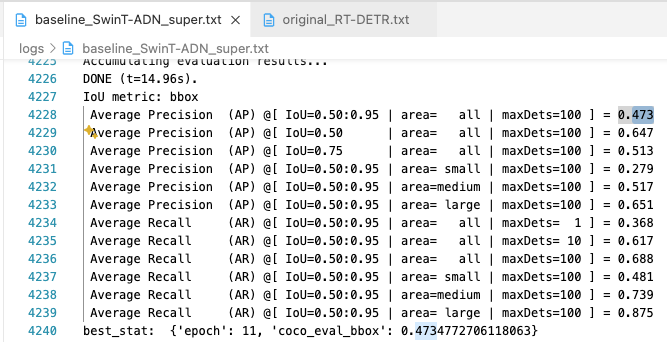
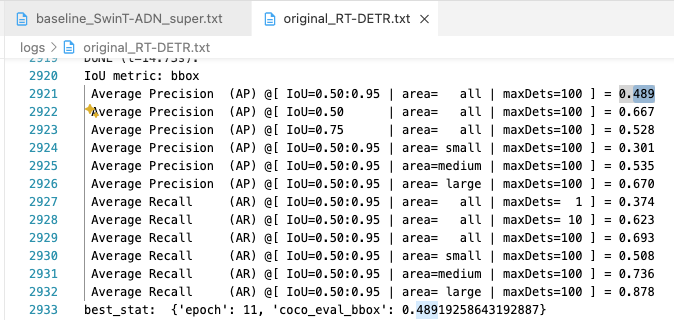 1.6 mAP 성능 차이
1.6 mAP 성능 차이
- 6x(72 epochs)에서의 RT-DETR-SwinT vs. Original :
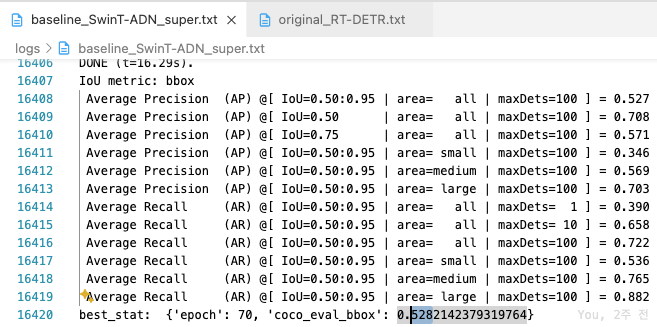
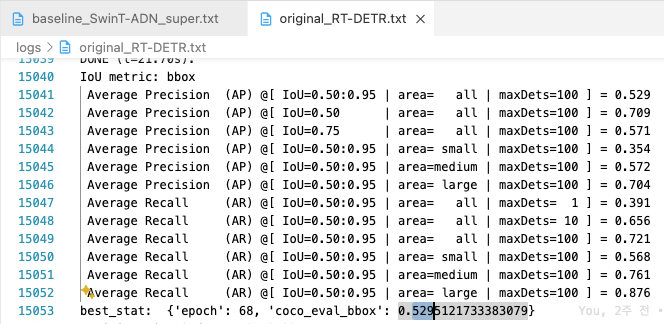 0.1 mAP 성능 차이
0.1 mAP 성능 차이
1.6mAP 차이(1x)에서 0.1mAP 차이(6x)로 좁혀짐.
- 1x(12 epochs)에서의 RT-DETR-SwinT vs. Original :
결론 (연구 주제 & thesis)
- 만약 YOLO Series에서 Post-processing(anchor-free, no NMS)이 없도록
DETR의 End-to-End 아이디어(Set prediction, bipartite matching loss)를 차용한다면,
RT-DETR에서 세운 benchmark(post-processing 시간까지 포함)에서 RT-DETR을 압도적으로 이길 수 있을 것이다.
➡️ 하지만 이미 한 달 전에, 이 아이디어로 연구를 진행한 YOLOv10가 나옴... (NMS-free training for YOLOs)

➡️ YOLO series의 특징으로 상업적인 용도가 더 강하고, 학술적 뒷받침이 조금은 떨어지기 때문에 연구에 적합하지 않다고 판단.
문제 제기 & 연구 주제
- 그래서 나는 RT-DETR의 efficiency를 더욱 극대화할 수 있도록,
RT-DETR 내의 computational redundancy를 찾고 해당 부분에 adaptation을 적용할 수 있는 방법을 연구할 것이다.
이에 대한 연구 아이디어로는 다음과 같다.RT-DETR의 computational redundancy 1 :
RT-DETR에서는 set prediction을 위해
COCO dataset에서 한 image에 나타날 수 있는 최대 object 개수를 decoder의 Object Quries Length로 설정했다.
(Object Queries = 300을 default로 설정한 이유이다)
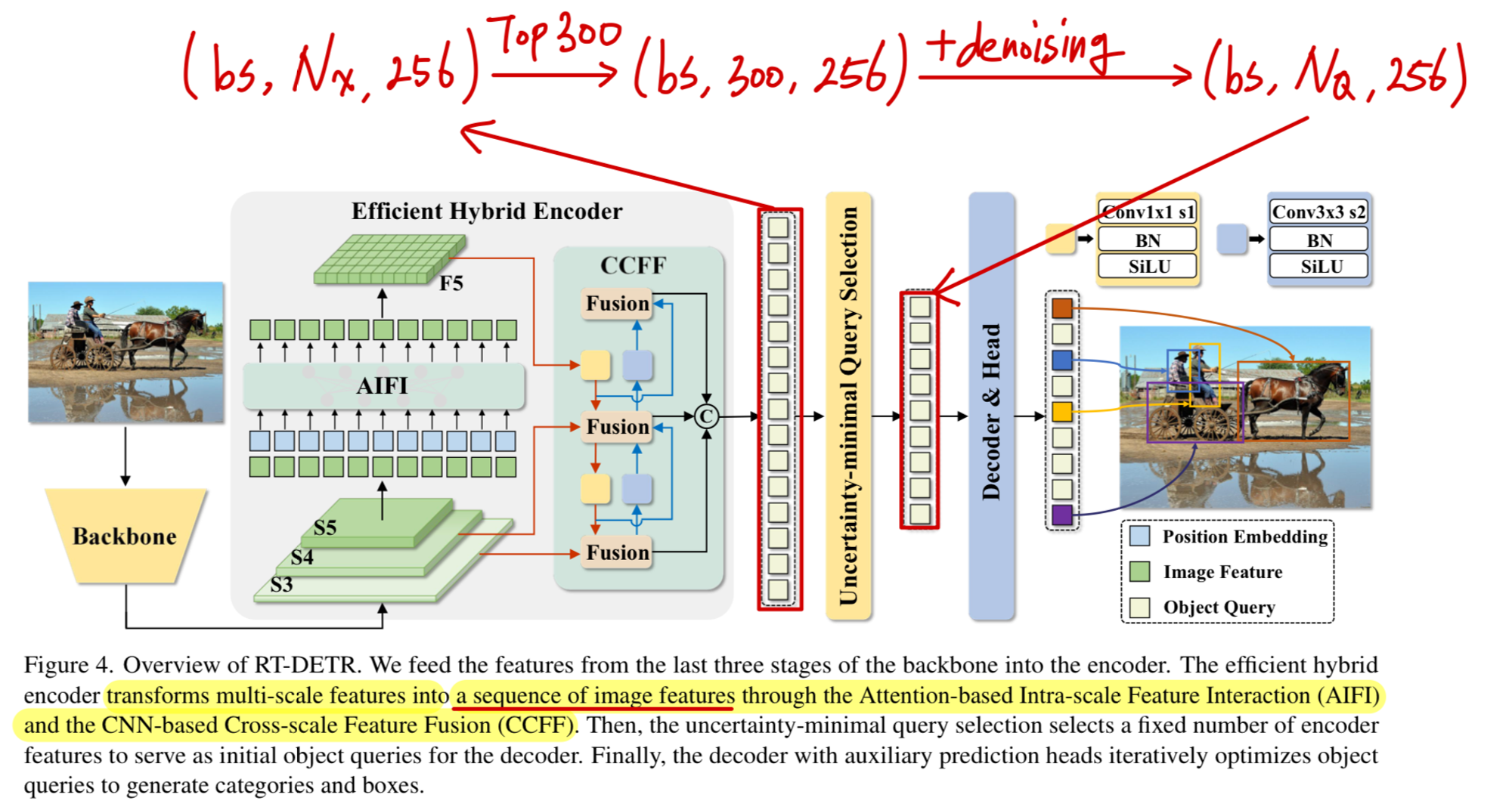 하지만 만약에 한 image에 object가 딱 1개 있는데 300개의 set prediction을 한다면,
하지만 만약에 한 image에 object가 딱 1개 있는데 300개의 set prediction을 한다면,
이는 꽤 많은 computational redundancy를 유발할 수 있다.RT-DETR의 computational redundancy 2 :
Encoder의 CCFF module은 RT-DETR 전체 GFLOPs의 34.26%를 차지할 정도로 큰 module인데,
이 이유는 Fusion block에 3개의 RepVggBlock이 stack되어 있기 때문이라고 추측하고 있다.
(GFLOPs 차지 비율은 더 조사해봐야 하지만, 분명 3개 layer가 stack되어 있기 때문에 redundancy는 존재할 것으로 판단된다)

RT-DETR의 computational redundancy 3 :
Decoder layer를 6개 사용하는 것은 redundancy가 될 수 있다.
재차 얘기하면,
Table 5.에서 Decoder layer를 6개가 아니라 더욱 줄여서 사용해도 큰 성능 하락이 없기 때문에
이를 효과적으로 활용할 수 있다면 RT-DETR의 efficiency를 증가시킬 수 있을 것이다.
-
위 세가지 RT-DETR의 computational redundancy를 줄일 수 있는 나의 연구 아이디어는 다음과 같다.
-
backbone 또는 Encoder(AIFI)에서 image-specific한 #objects에 대해 prediction을 한다.
이는 몇 개의 set prediction을 할지에 대한 'hint'가 되고, 이 기준에 따라 adaptive computation을 구성한다.- idea 1 : backbone hint
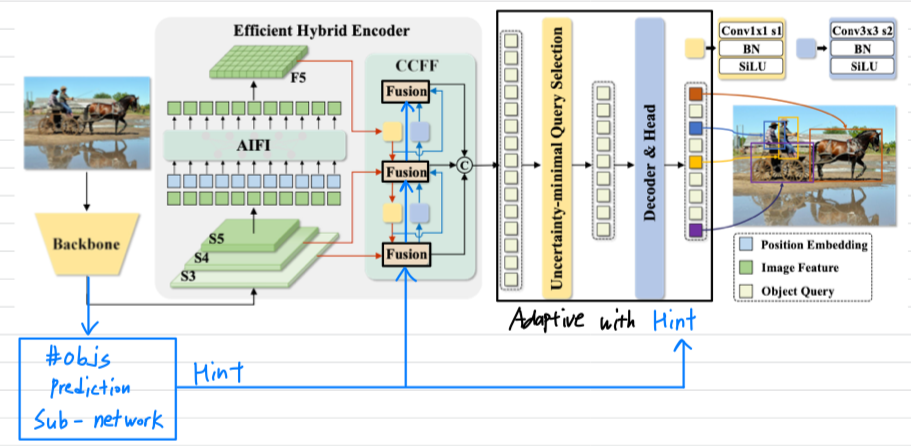 idea 2보다 parameter와 computation은 더 많이 추가될 것 같다.
idea 2보다 parameter와 computation은 더 많이 추가될 것 같다.
하지만 #objs를 더 잘 예측할 수 있을 것 같다. - idea 2 : AIFI #objs token(=hint)
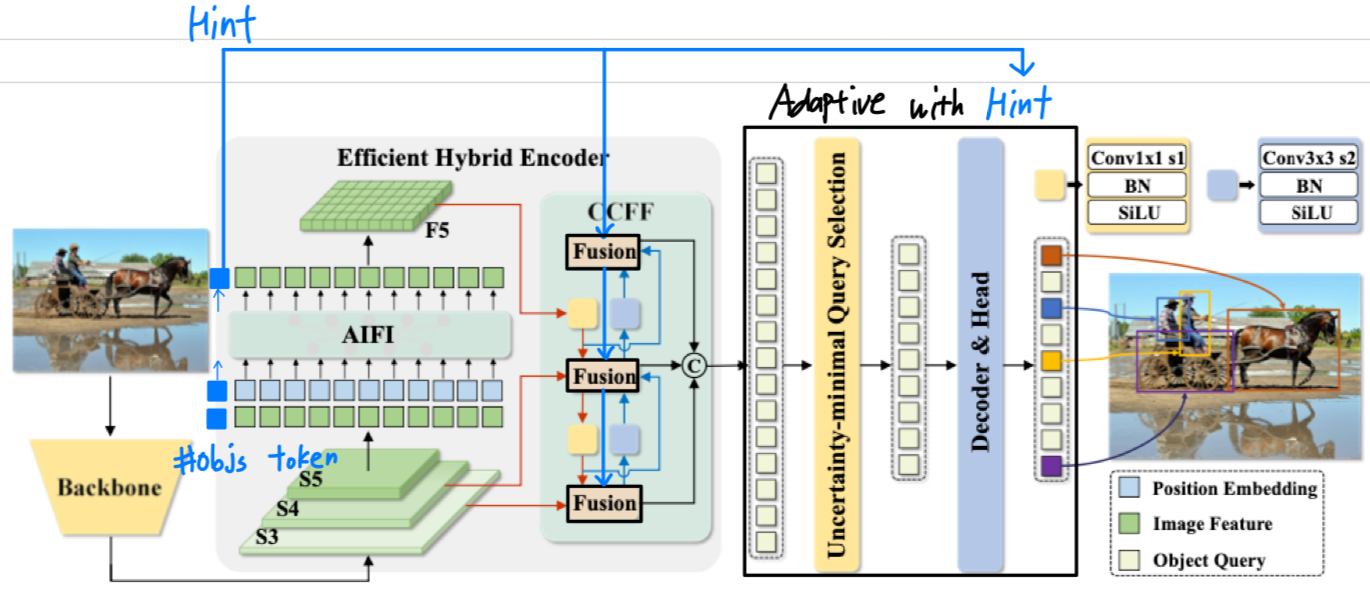
idea 1보다 parameter와 computation이 더 적게 추가될 것 같다.
하지만 #objs를 더 잘 예측하지 못 할 수 있을 것 같다.
(실험적으로 idea 1 vs. idea 2를 해봐야 함.
paramter & computation이 얼마 만큼 늘어나는 대신 #objs를 얼마 만큼 정확하게 맞추는지에 대한 효과적인 trade-off를 달성할 수 있는 것으로.)
- idea 1 : backbone hint
-
hint 정보(= predicted #objs)를 갖고, Fusion block과 decoder에 어떻게 adaptation을 적용할 것인지? Loss는 어떻게 구성해야 할지?
생각해봐야 함.
-
thesis
Backbone 또는 AIFI에서 예측한 object 개수로 adaptive set prediction을 할 수 있는
image-specific Adaptive RT-DETR을 만든다.
