[2018 CVPR]ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Paper Info.
CVPR 2018

Abstract
-
computation-efficient CNN architecture named ShuffleNet을 소개한다.
ShuffleNet은 mobile devices with very limited computing power를 위해 설계되었다. -
ShuffleNet은
두 개의 새로운 operations을 사용한다.- pointwise group convolution
- channel shuffle
1. Introduction
- mobile platforms에 초점을 맞춰 tens or hundreds of MFLOPs의 매우 제한된 computational budgets 안에서 best accuracy를 추구하는 기존 연구들은
pruning, compressing, or low-bit representing a "basic" network architecture에 초점을 맞추었다.
우리는 computing ranges를 만족시킬 수 있는 a highly efficient basic architecture를 설계하는 것을 목표로 했다.
-
Xception and ResNeXt와 같은 SOTA basic architectures는 dense 1x1 conv 때문에 extremely small networks에서 덜 효율적이다.
-
우리는 1x1 conv의 computation complexity를 줄이기 위한 pointwise group convolutions을 제안한다.
group conv의 부정적 영향을 극복하기 위해 feature channels들 간의 정보 흐름을 도울 수 있는 a novel channel shuffle operation을 제안한다.
이 두가지 기술에 기반하여, 우리는 highly efficient architecture calledShuffleNet을 만들었다.
2. Related Work
Group Convolution
-
GC의 개념은 AlexNet에서 model을 두 GPU로 나누는 것에서부터 시작되었고, ResNeXt and DeepRoots에서 그 효과성이 입증되어 왔다.
-
Xception에서 제안된 Depthwise separable conv는 Inception series에서 separable convs의 아이디어를 일반화하였다.
최근 MobileNet에서 depth-wise separable convs를 사용하여 는 lightweight models 사이에서 SOTA를 달성했다. -
우리의 연구는 GC와 depthwise separable conv을 새로운 형태로 일반화한다.
Channel Shuffle Operation
- channel shuffle 연산에 대한 아이디어는 efficient model design과 관련된 기존 연구에서 거의 언급되지 않았다.
아주 최근 또 다른 동시 연구 [42]에서 이 아이디어를 two-stage conv에 채택하였으나, [42]에서는 channel shufle 자체의 effectiveness나 이를 tiny model design에 활용하는 방법에 대해서는 특별히 조사하지 않았다.
3. Approach
3.1. Channel Shuffle for Group Convolutions
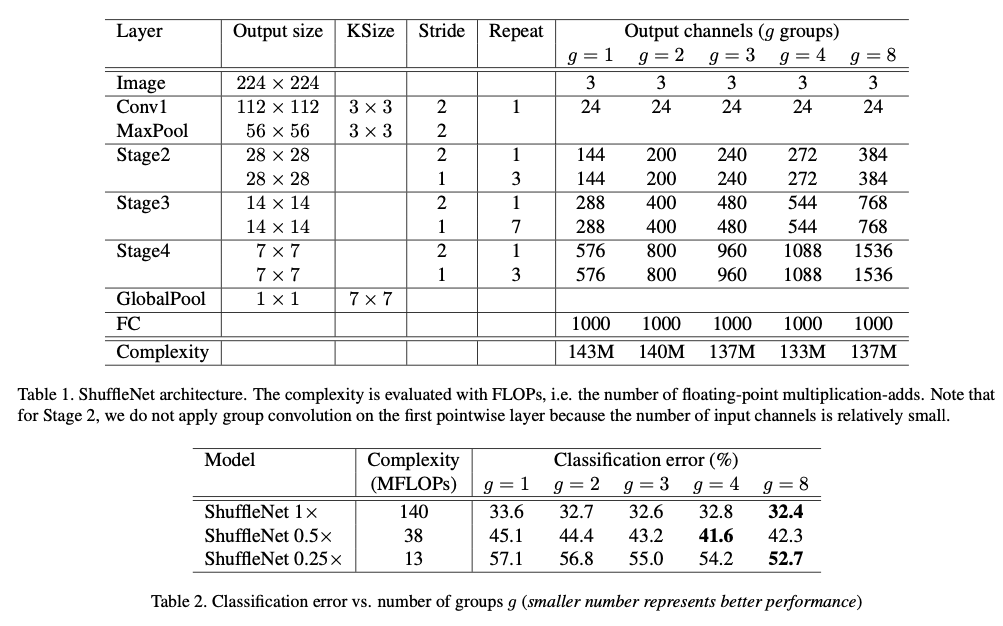
- 현대의 CNNs은 보통 same structure를 갖는 반복된 building blocks으로 구성된다.
그 중 Xception과 ResNeXt와 같은 SOTA networks는 efficient depthwise separable convolutions or group convolutions을 building block에 도입하여 representation capability and computational cost 사이에서 뛰어난 trade-off를 이룬다.
-
예를 들어, ResNeXt에서는 layer에만 group conv를 장착하고 있다.
그 결과, ResNeXt의 각 residual unit에서는 pointwise conv간 93.4$ multiplication-adds을 차지한다 (cardinality=32).
tiny networks에서는, expensive pointwise convolutions 때문에 complexity 제약을 맞추기 위해 channel 수가 제한되어, 이는 accuracy를 크게 떨어뜨릴 수 있다. -
이를 해결하기 위한 간단한 방법은 layer도 group conv와 같은 channel sparse connections을 적용하는 것이다.
각 convolution이 해당 input channel group에 대해서만 작동하도록 보장함으로써, GC는 computation cost를 크게 줄일 수 있다.
그러나 여러 GC를 stack할 경우, 한 가지 부작용이 발생한다:
특정 channel에서 나오는 output은 input channels의 어느 작은 일부분으로부터 나온다는 것이다.
Fig 1 (a)는 두 개의 GC layer가 쌓인 상황을 보여준다.
특정 group에서 나오는 output은 그 group 내의 input에만 관련이 있다는 것이 분명하다.
이 특성은 channel group 간 information flow를 차단하고 representation 능력을 약화시킨다.
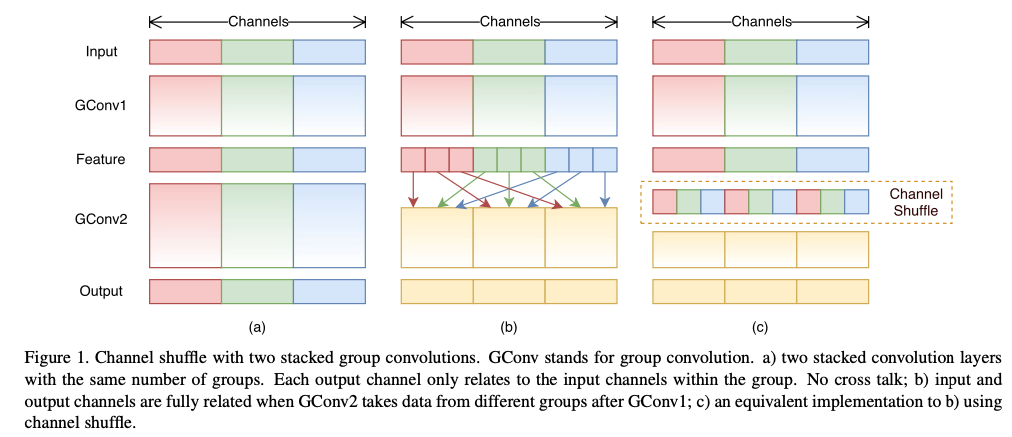
- 만약 GC가 서로 다른 group에서 input data를 얻도록 허용한다면(Fig 1 (b)), input and output channels은 완전히 연관된다.
구체적으로, 이전 group layer에서 생성된 feature map에 대해, 각 group의 channel을 여러 개의 sub-groups으로 나누고,
그 다음 layer에서 각 group에 다른 sub-groups을 제공할 수 있다.
이는 channel shuffle 연산을 통해 효율적으로 구현할 수 있다(Fig 1 (c)):
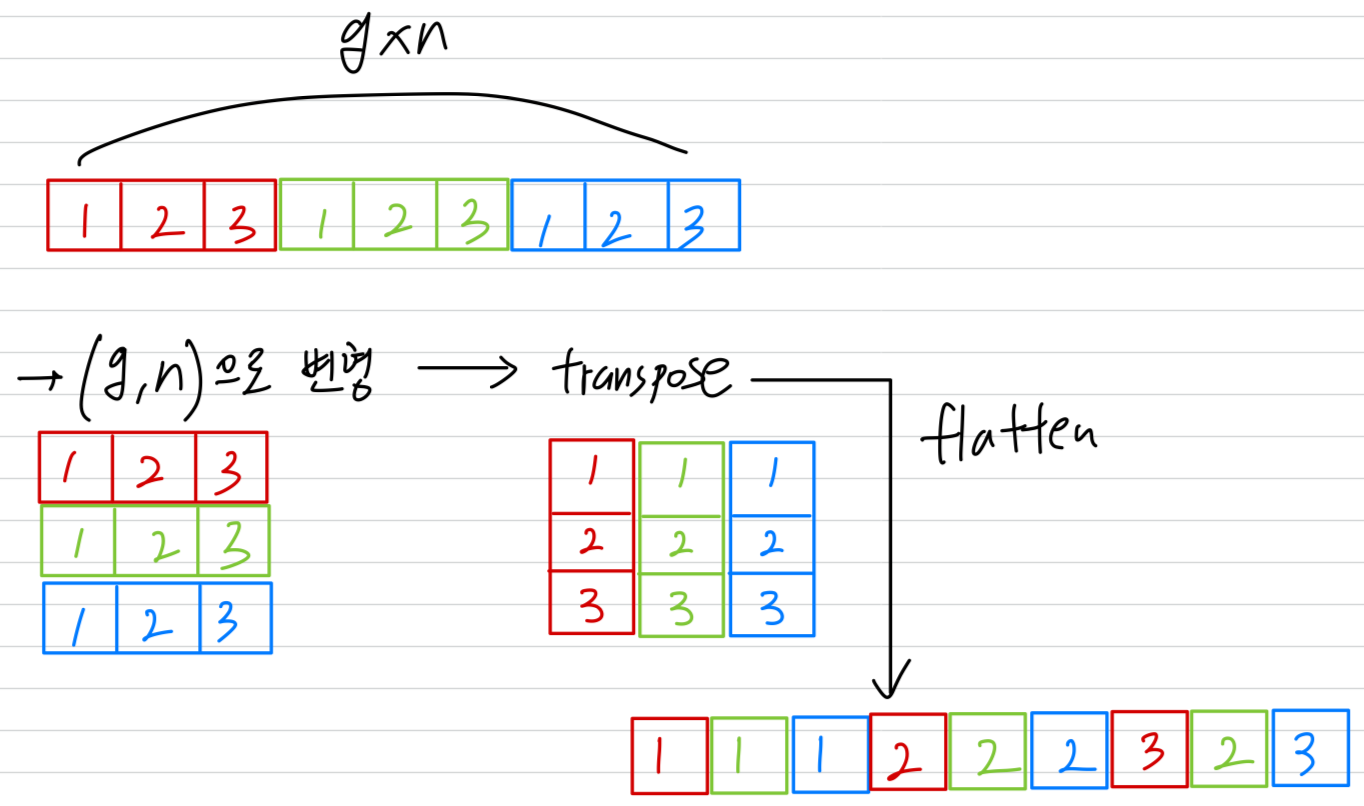
예를 들어, output이 channels인 개의 group을 가진 conv layer가 있다고 가정하면, 먼저 output channel dimensions을 으로 변형한 뒤,
transposing하고 flattening하여 다음 layer의 input으로 사용할 수 있다.
두 convolutions의 group 수가 다르더라도 이 연산은 여전히 유효하다.
또한, channel shuffle은 differentiable하므로 network 구조에 내장되어 end-to-end training이 가능하다.
3.2. ShuffleNet Unit