[2019 ICLR] Slimmable Neural Networks
Paper Info.

https://github.com/JiahuiYu/slimmable_networks
이 논문을 읽게 된 이유
- 현재(24.10.28) Object Detection의 Neck에서 width를 줄이는 연구를 하고 있는데,
다양한 width configuration을 하나의 single network에서 조화롭게 학습시킬 수 있는 방법을 찾고 있는 중이다.
➔ 결론 : 요약으로 가시오..
Abstract
-
우리는 runtime 시에 즉각적이고 adaptive accuracy-efficiency trade-offs를 조절할 수 있는 a simple and general method를 제안한다.
이를 통해 다양한 widths에서 a single neural network를 실행할 수 있게 된다. -
개별 width configuration에 따라 각각의 network를 train하는 대신,
우리는 하나의 shared network를 swichable batch normalization과 함께 학습을 시켰다. -
우리의 학습된 networks를
slimmable neural networks라고 부르고,
서로 다른 wdiths를 각각 독립적으로 학습시킨 MobileNet v1, MobileNet v2, ResNet-50에 대해서 ImageNet classification accuracy는 유사하게 달성될 수 있다. -
또한 hyper-parameter tuning 없이 bbox object detection, instance segmentation and person keypoint detection을 할 수 있다.
이 또한 개별 network 각각을 학습시킨 models에 비교했을 때 slimmable models이 더 좋은 성능을 보였다.
1. Introduction
- DNNs이 mobile phone, autonomous cars 등 널리 사용되고 있음.
이러한 app 중 다수는 short response time을 요구함.
이를 위해, manually designed된 lightweight networks가 low computational complexities and small memory footprint를 특징으로 하며 제안되었음.
자동화된 Neural Architecture Search 또한 on-device latency를 탐색 목표에 통합했음.
하지만 runtime에서는 이러한 network들이 동일한 response time budget 내에서 다양한 device 별로 유연하게 재구성되지 못함.
예를 들어, 2015년에만 24,000개 이상의 android device들이 존재했으며, 이 기기들은 동일한 neural netwok에 대해 크게 다른 runtime 성능을 보임.

- lightweight network에서는 latency와 accuracy 간 trade-off를 위해 global hyper-parameter인 width multiplier를 제공함.
하지만, 이 방식은 유연성이 부족하고 많은 제약이 있다.- 다른 width multipliers를 가진 model들은 각각 개별적으로 trained, benchmarked and deployed되어야 한다.
따라서 time and energy budget에 따라 다양한 model을 device에 할당하기 위한 big offline table이 필요하다. - 동일한 기기에서도 compuational budget(예를 들어, bg app이 과도하게 실행될 경우 가용 연산 용량이 줄어듦) 및 energy 연산(mobile phone이 저전력 또는 절전 모드일 때)이 달라질 수 있다.
- larger or smaller model로 전환될 때, model download 및 offloading에 필요한 시간과 data 비용 또한 무시할 수 없다.
- 다른 width multipliers를 가진 model들은 각각 개별적으로 trained, benchmarked and deployed되어야 한다.
-
문제는 이러하다.
"Given budgets of resources, how to instantly, adaptively and efficiently trade off between accuacy and latency for neural networks at runtime?"
본 연구에서는 accuracy and latency를 실시간으로 조정할 수 있는 새로운 종류의 network인 slimmable neural networks를 소개한다.
이 network는 다양한 width에서 실행 가능하며, 이를 통해 accuacy and latency 간의 trade off를 손쉽게 조절할 수 있는 일반적인 solution을 제안한다.
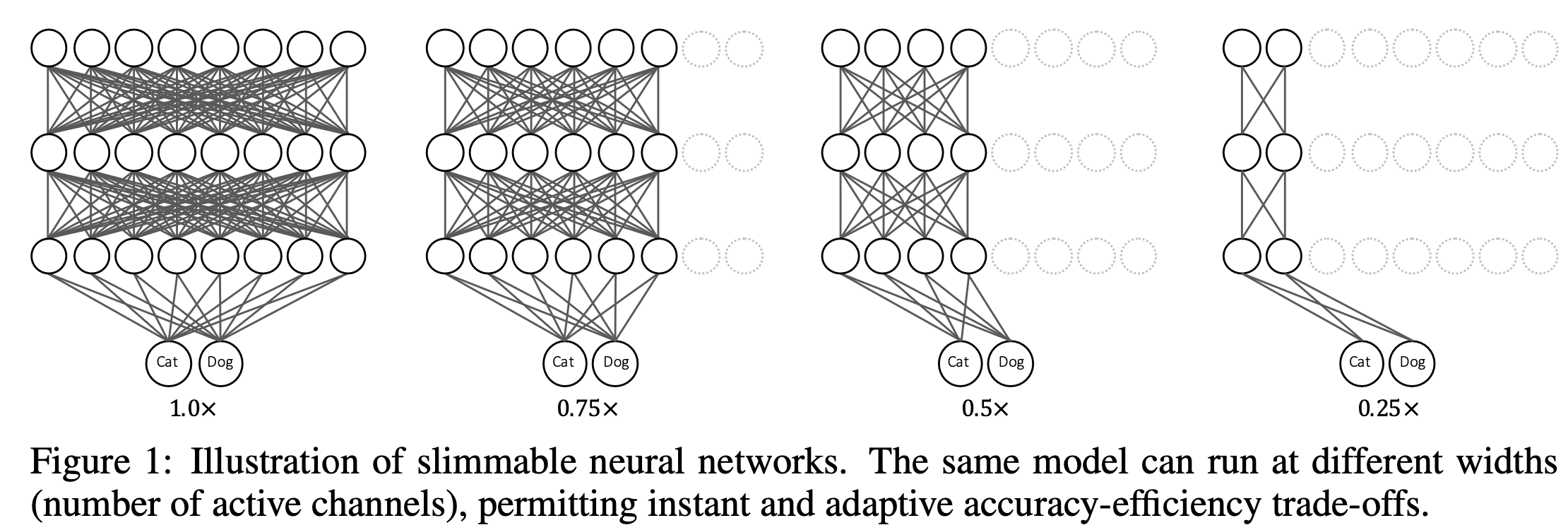
Figure 1은 slimmable network의 예시를 보여주며,
active channels의 수는 다른 네 가지 model variants 간에 전활될 수 있다.
모든 model variants의 parameters는 공유되며, 각 layer의 active channel의 수는 조정 가능하다.
간단하게, slimmable networks에서 하나의 model variants를 switch라 하고,
switch에서 active channel의 수를 width라고 부른다.
예를 들어, 0.25x는 모든 layer의 width가 전체 model의 0.25배로 조정됨을 의미한다.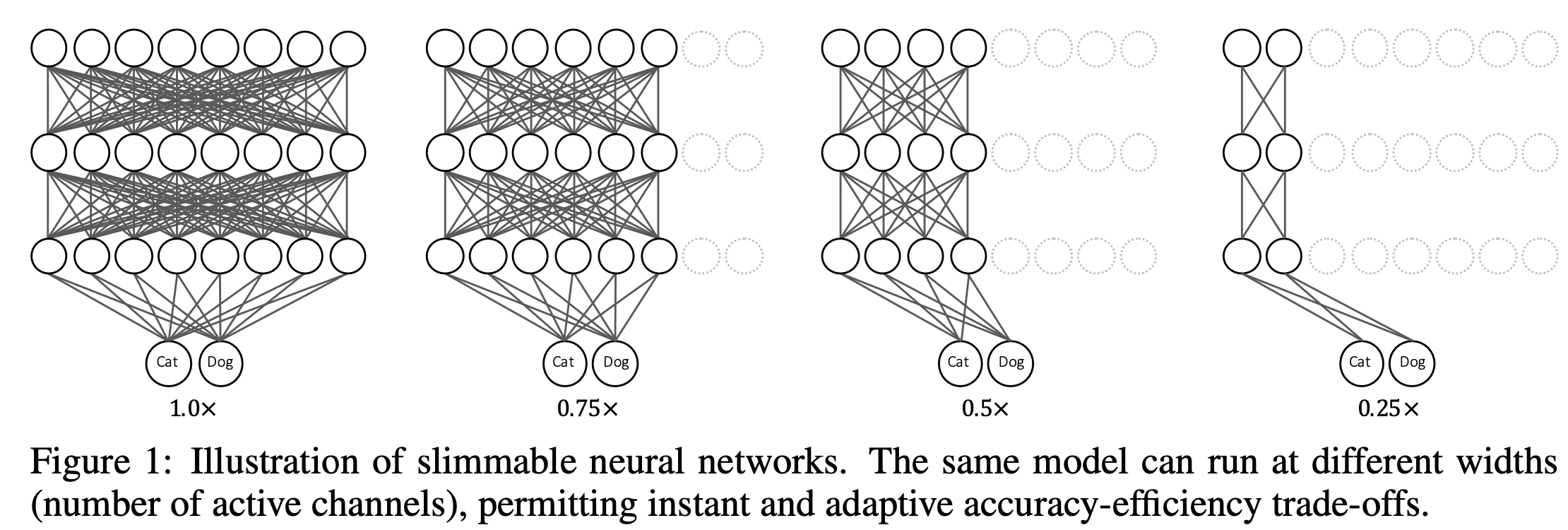 다른 solution들과 달리 slimmable network는 몇 가지 장점이 있다:
다른 solution들과 달리 slimmable network는 몇 가지 장점이 있다:- 다양한 conditions에 대해 single model만 trained, benchmarkded and deployed하면 된다.
- target device에서 active channels을 조정하여 near-optimal trade-off를 달성할 수 있다.
- 이 solution은 일반적으로 (normal, group, depthwise-separable, dilated) convolutions, fc layeres, pooling layers 그리고 neural networks의 많은 다른 layers에 적용 가능하며,
classification, detection, identification, image restoration 등 다양한 task에도 적용이 가능하다. - 실제로 기존 runtime library를 통해 mobile에 쉽게 deploy할 수 있다.
새로운 configuraion으로 switching 이후 추가적인 runtime and memory cost 없이 하나의 normal network로 실행된다.
-
하지만 neural networks는 본질적으로 전체가 한꺼번에 실행되며, 일반적으로 #channels을 동적으로 조정할 수 없다.
여러 switch에서 networks를 학습할 경우, ImageNet-1000에서 test accuracy가 약 0.1%로 매우 낮아진다는 경험적 결과가 있다.
우리는 이를 channel 수가 다름에 따라 feature mean and variance가 달라지는 문제 때문이라고 conjecture(추정)한다.
서로 다른 switch 간 feature mean and varaince가 불일치하면 공유된 BN layer의 통계가 부정확해지며, 이는 중요한 training stabilizer이다.- 이를 해결하기 위해, slimmable networks의 서로 다른 switch에 대한 BN을 개별화하는 간단하고 효과적인 방법인 switchable batchnormalization을 제안한다.
이는 각 switch에서 개별적으로 moving averaged means and vraiance를 축적할 수 있도록 한다. - 또한, BN은 동일한 representation space를 보장하기 위해 두 가지 추가적인 learnable scale 및 bias parameter를 갖는데,
이는 width configuration에 따라 slimmable network의 computation graph가 달라지므로 각 switch에 대한 conditional parameters로 작용할 수 있다.
주목할 점은 scale and bias를 moving mean and varaince에 병합할 수 있으며,
기본적으로 별도의 scale and bias를 사용하는 것이 추가 비용 없이 가능하다는 것이다.
일반적으로 BN layer는 model 내에서 매우 적은 크기(1% 미만)을 차지함.
- 이를 해결하기 위해, slimmable networks의 서로 다른 switch에 대한 BN을 개별화하는 간단하고 효과적인 방법인 switchable batchnormalization을 제안한다.
2. Related Work
Adaptive Computation Graph
-
nerual network의 computation을 줄이기 위해서, neural network의 cmoputation graph을 동적으로 구축하는 몇 가지 연구가 있었다.
어떤 연구는 현재 input에 기반하여 computation graph을 결정하는 추가의 controller moduels or gating function을 제안했고,
어떤 연구에서는 average execution depth를 줄이기 위해 early exiting prediction branches를 실행했다. -
하지만 위 방법들은 input에 conditioned되거나, lower theoretical computational complexity로 달성되었다.
3. Slimmable Neural Networks
3.1. Naive Training or Incremental Training
-
slimmable neural networks를 학습시키기 위해, 우리는
naive approach로 서로 다른 width configurations을 사용하여 a shared neural network를 학습했다.
이 training framework는 우리의 최종 approach와 유사하며, Algorithm 1에 나와 있다.
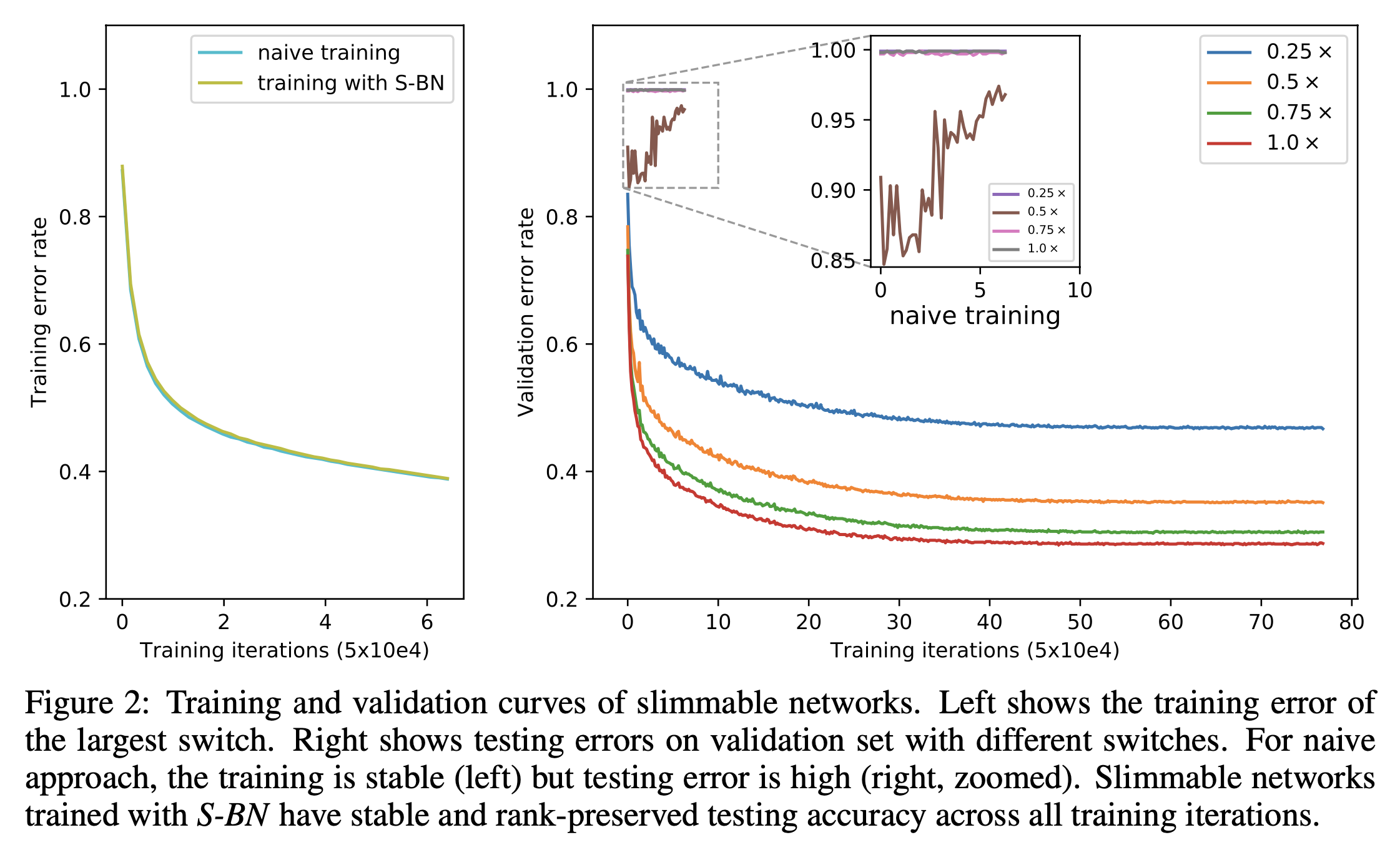
training은 안정적이지만, network는 1000-class ImageNet classification에서 약 0.1%의 매우 낮은 top-1 testing accuracy를 얻었다.
naive approach의 error curve는 Figure 2에 나타나 있다.
navie approach의 주요 문제점은 한 layer의 한 single channel에서, 이전 layer에서 input channel 수가 다르면 aggregated feature의 means and variances가 달라지고,
이 값들이 a shared bn layer로 folling averaged된다는 점이라고 추정한다.
이 inconsistency는 layer-by-layer propagating(layer 별로 전달)되며 bn statistics을 부정확하게 만든다.
이러한 bn statistics(moving average means and variances)는 test 주에만 사용되며, training 중에는 현재 mini-batch의 means and variances가 사용된다. -
그 후, 우리는
incremental training approach(a.k.a progressive training)을 조사했다.
먼저 base model A(MobileNet v2 0.35×)를 학습한 후 고정하고,
parameters B를 추가하여 확장된 모델 A+B(MobileNet v2 0.5×)로 만든다.
추가된 parameters는 training data에서 A의 고정된 parameter와 함께 fine-tuned된다.
이 방법은 training and testing에서 모두 안정적이지만, Top-1 accuracy는 A의 60.3%에서 A+B의 61.0%로 약간만 증가한다.
반면에 개별적으로 학습된 MobileNet v2 0.5×는 ImageNet 검증 세트에서 65.4%의 정확도를 달성한다.
➔ accuracy가 저하되는 주된 이유는 base model A를 다음 단계인 A+B로 확장할 때,
B에서 B로의 connection뿐만 아니라 B에서 A로, A에서 B로의 새로운 connection이 computation graph에 추가되기 때문이다.
그래서 incremental training은 A와 B의 weights의 joint adaptation을 금지하여 전체 성능을 크게 저하시킨다.
3.2. Switchable Batch Normalization
-
위 연구 결과에 영감을 받아, 우리는 slimmable network의 각 switch에 독립적인 BN을 적용하는 간단하면서도 매우 효과적인
Switchable Batch Normalization (S-BN)을 제안한다.
BN은 원래 feature의 internal covariate shift를 줄이기 위해 제안되었으며,
feature를 normalized하여 의 형태로 나타낸다.
여기서 는 normalized될 input이고 은 output,
는 learnable scale and bias parameter이며,
은 학습 중 현재 mini-batch의 mean and variance이다.
test 시에는 모든 training images에 대한 mean and variance를 moving averaged한 statistics을 사용한다.
BN은 DNNs의 학습을 더 빠르고 안정적으로 만들어 줄 뿐만 아니라 feature representation에 conditional information을 encoding할 수 있다. -
slimmable networks를 학습시키기 위해, S-BN은 network의 각 switch에 대해 모든 BN layer를 개별적으로 설정한다.
이는 test 중에 독립적으로 feature의 mean and variance를 normalized하여 다른 switch 간의 feature aggregation inconsistency를 해결한다.
S-BN의 scale과 bias는 현재 switch의 width configuration에 대한 conditional information을 encode할 수 있다. (학습 후에 scale과 bias를 moving mean and variance로 병합할 수 이어, 기본적으로 독립적인 scale과 bias를 free로 사용할 수 있다.) (?)
또한, S-BN을 사용하면 incremental training과 달리 다양한 width의 모든 switch를 jointly train할 수 있어 모든 weights가 jointly updated되어 더 나은 성능을 달성할 수 있다.
S-BN을 사용한 training and validation error curve는 Figure 2에 있다.
-
S-BN은 또한 두 가지 중요한 장점을 갖고 있다.
- 추가되는 parameter의 수는 무시할 만한 수준이다.
Table 2는 bn layer에 있는 #parameters와 ratio를 나열하고 있다.
(학습 후에는 가 두 개의 parameter로 병합된다)(?)
대부분의 경우, bn layer는 model 크기의 1% 미만이다. - deploy 시 runtime overhead도 무시할 수 있는 수준이다.
실제로 bn layer는 efficient inference를 위해 통상적으로 conv layer와 병합된다.
slimmable network의 경우, bn의 re-fusing(재병합)은 runtime 시 실시간으로 수행할 수 있으며, 이는 거의 시간이 걸리지 않는다.
새로운 configuration으로 전환한 후, slimmable network는 추가적인 runtime and memory cost 없이 a normal network로 실행될 수 있다.

- 추가되는 parameter의 수는 무시할 만한 수준이다.
3.3 Training Slimmable Neural Networks
- slimmable neural network를 학습하는 primary objective는
모든 switches로부터 그것의 accuracy averaged를 optimize하는 것이다.
이를 위해 model의 loss를 각 switch의 training losses를 un-weighted sum하여 계산한다.
(가중치 없이 합산하여 계산)
Algorithm 1은 현재 neural network libraries에 쉽게 통합할 수 있는 memory-efficient implementation of training framework를 보여준다.
switchable width list는 사전에 정의되어 있으며, 이는 slimmable network에서 사용 가능한 switch를 나타낸다.
training 중에는 모든 switch의 back-propagated된 gradient를 누적하여, weights를 udpate한다.
모든 실험에서 특별히 조정해야 하는 hyper-parameters는 없다는 것을 경험적으로 확인헀다.

이해를 못한 부분
- "(학습 후에 scale과 bias를 moving mean and variance로 병합할 수 이어, 기본적으로 독립적인 scale과 bias를 free로 사용할 수 있다.)"
- "(학습 후에는 가 두 개의 parameter로 병합된다)"
어떻게 병합된다는 걸까?
요약 (그래서 어떻게 학습시켰는가?)
- slimmable neural network를 학습하는 primary objective는
모든 switches로부터 그것의 accuracy averaged를 optimize하는 것이다.
이를 위해 model의 loss를 각 switch의 training losses를 un-weighted sum하여 계산한다.
(가중치 없이 합산하여 계산)
Algorithm 1은 현재 neural network libraries에 쉽게 통합할 수 있는 memory-efficient implementation of training framework를 보여준다.
switchable width list는 사전에 정의되어 있으며, 이는 slimmable network에서 사용 가능한 switch를 나타낸다.
training 중에는 모든 switch의 back-propagated된 gradient를 누적하여, weights를 udpate한다.
모든 실험에서 특별히 조정해야 하는 hyper-parameters는 없다는 것을 경험적으로 확인헀다.
