[2017 CVPR][Simple Review] (YOLO9000, YOLOv2) YOLO9000: Better, Faster, Stronger
[Paper Review] 2D Object Detection
Info
paper: YOLO9000: Better, Faster, Strongerauthor: Joseph Redmon, Ali Farhadisubject: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
참고자료
- object detection paper 흐름 파악을 위해 논문을 빨리 읽음.
이를 위해 다음의 자료를 참고 https://www.youtube.com/watch?v=vLdrI8NCFMs
Abstract
-
9000개 object category를 detect할 수 있는
state-of-the-art, real-time object detection system인
YOLO9000을 소개할 것이다. -
우선 우리는 YOLO detection method에 대한 다양한 개선책을 제시할 것이고,
이 개선책들은 새로 개발했거나 이전 연구들에서 착안했다. -
향상된 모델로,
YOLOv2는 PASCAL VOC and COCO와 같은 standard detection tasks에 대해
state-of-the-art가 되었다.
또한 다양한 size에서 동작할 수 있으며,
이는 easy tradeoff between speed and accuracy를 제공한다. -
마침내 우리는 object detection과 classification을 jointly train할 수 있는 방법을 제시한다.
우리의 joint training은 YOLO900가 detection data가 label되지 않은 object class를 예측할 수 있게 한다.
1. Introduction
-
우리는 이미 보유한 많은 classification data를 활용하여
현재의 detection system으로 확장하는 새로운 방법을 제안할 것이다.
우리의 방법은 object classification의 hierarchical view를 사용하여
서로 다른 datset을 서로 combine시켜준다. -
우리는 또한 detection과 classification data 둘 다에 대한
object detector를 train시킬 수 있는 joint training algorithm을 제안할 것이다.
우리의 방법은 label된 detection image를 활용하여 object를 정확하게 localize하는 데에 학습되고
classification image를 활용하여 vocabulary and robustness를 향상시키는 데에 사용된다.
우리는 이 방법으로 9000개의 다른 object category를 detect할 수 있는 real-time object detector인,
YOLO9000을 학습시키는 데에 사용했다. -
우선 우리는 YOLO detection system을 기초로 하여,
a state-of-the-art, real-time detector인 YOLOv2를 만들었다.
그런 다음, 우리는 ImageNet의 9000가지 이상의 클래스와 COCO의 detection data를 사용하여
model을 train시키기 위해dataset combination method와 joint training algorithm을 사용했다.
Main Contribution
1. YOLOv2 : YOLOv1의 단점을 개선하여 연산을 더 빠르고, 정확하게 높임
2. YOLO9000 : 기존의 VOC, COCO dataset은 class 개수가 매우 적음.
classification dataset과 joint training 통해 보지 못했던 object class(9000개 이상)에 대한 예측이 가능해짐.
그냥 dog가 아니라, 세분화된 dog 종까지 prediction 가능
Better, Faster -> YOLOv2
Stronger -> YOLO9000
2. Better (for YOLOv2)
-
YOLOv1은 region proposal-based method에 비해
localization error가 높았고, recall이 낮았다. -
Computer vision에서는 larger, deeper network로 만드는 것이 일반적이지만,
YOLOv2는 여전히 빠르고 정확하기를 원하기 때문에
network를 scale up하는 것 대신에,
network를 단순화하고, 학습하기에 더 쉬운 representation으로 바꾸었다.
우리는 이전의 연구에서의 idea와 우리의 새로운 idea를 도입하여 YOLOv1의 performance를 향상시키었다.
A summary of a resuls는 Table 2.에 있다.
 technique을 하나씩 추가할 수록 mAP가 향상되는 모습.
technique을 하나씩 추가할 수록 mAP가 향상되는 모습.
Batch Normalization
-
YOLO의 모든 conv layer에 batch normalization을 적용하여,
mAP를 2% 향상시킴. -
또한 model regularization 효과도 있음.
High Resolution Classifier
-
모든 state-of-the-art detection method들은 ImageNet에 pretrained된 classifier를 사용함.
-
YOLOv1에서도 224 x 224 image를 pretrain하고 나서,
detection을 위해 high resolution 448 x 448로 input을 바꾸었다.
하지만 이 의미는 network가 object detection을 학습하는 것과 동시에 새로운 input resolution을 학습하도록 바껴야 한다는 의미이다.
이는 학습을 오래 걸리게 한다. -
그래서 YOLOv2에서는 ImageNet에 대해서 10 epoch동안 448 x 448 resolution을 fine tune한다.
이는 network가 higher resolution input에 대해 더욱 잘 작동하도록 filter를 조정할 시간을 주는 것이다.
그런 다음, detection에 대한 network 결과를 fine tune한다.
이 high resolution classification network는 대략 4% mAP 향상을 제공한다. -
사실 input image size를 448 x 448이 아닌, 416 x 416으로 했다.
"We do this because we want an odd number of locations in our feature map so there is a single center cell.
Objects, expecially large objects, tend to occupy the center of the image so it's good to have asingle location right at the center to predict these objects instead of four locations that are all nearby."
Convolutional With Anchor Boxes
-
YOLOv1에서는 fc layer를 사용해서 bboxes의 좌표를 directly하게 예측했었다.
Faster R-CNN에서는 hand-picked priors를 이용하여 bboxes를 예측했었다. -
Faster R-CNN의 region proposal network (RPN)은
오직 conv layer만 사용하여 anchor box에 대한 offset과 confidence을 예측한다.
coordinates보다 offset을 prediction하는 것은 problem을 더 쉽고 network가 학습하기 더 쉽게 만든다. -
우리는 YOLOv1의 fc layer를 모두 없애고,
anchor box를 이용하여 bbox를 예측하도록 했다.- 먼저 우리는 conv layer의 higher resolution을 만들기 위해서
하나의 pooling layer르 제거했다. - 또한 448 x 448 대신에 416 input image로 바꾸었다.
YOLOv1의 conv layer는 input image를 32의 배수로 downsampling하므로
416 input image를 입력하면, 13 x 13의 feature map을 얻는다 - Anchor box로 이동할 때,
우리는 class prediction mechanism을 spatial location에서 분리하고,
대신 각 anchor box에 대해 conditional probability와 object가 있는지를 prediction한다.
- 먼저 우리는 conv layer의 higher resolution을 만들기 위해서
-
anchor box를 사용하면서 우리는 69.5 mAP에서 69.2 mAP로 작은 accuracy 감소가 있었지만,
recall이 81%에서 88%로 증가했다.
이는 anchor box로 prediction한 것 중 잘 맞춘 box가 증가했다는 의미. -
Faster R-CNN의 RPN에서 연산되는 anchor box에서 착안
-
image를 S x S grid로 나눔
-
각 grid 별로 anchor box 5개를 예측
-
단, anchor box의 원점은 grid cell 내에 존재
(안정적인 anchor box 예측을 위함) -
YOLOv1과는 달리, anchor box 별로 class probability 를 가짐
 Output tensor :
Output tensor :
Dimension Clusters
-
YOLOv2에서 anchor box를 어떻게 정할 것인가
이전의 Fast R-CNN에서는 anchor box의 ratio와 size를 미리 정하는 hand picked 방식이었는데,
이 방식보다는 k-means clustering을 통해 GT와 가장 유사한 optimal anchor box를 탐색.
하지만 여기서, Euclidean distance를 이용해서 clustering을 수행하는 것이 아니라
IOU score를 통한 clustering을 수행하였음.
➡️ 그 이유는?
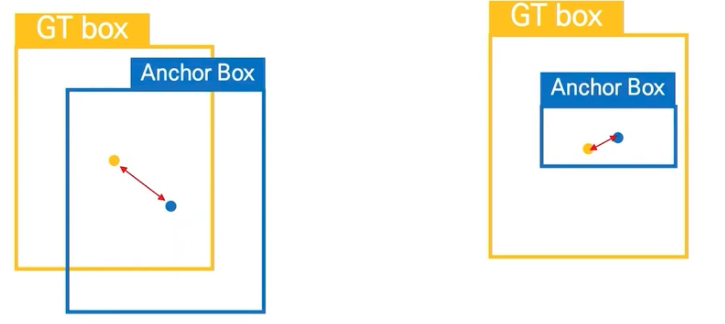 왼쪽의 그림이 IOU가 더 높기 때문에 왼쪽의 Anchor Box가 더 예측을 잘 한 것이지만,
왼쪽의 그림이 IOU가 더 높기 때문에 왼쪽의 Anchor Box가 더 예측을 잘 한 것이지만,
만약 anchor box의 중심점 간의 Euclidean distance로 계산하게 되면,
오른쪽의 Anchor Box가 GT box의 중심점과의 거리가 적기 때문에
오른쪽의 Anchor Box가 더 예측을 잘 한 것으로 된다.
따라서 Anchor Box를 Clustering하는 것에는 Euclidean Distance보다는 IOU를 기준으로 삼는 것이 더 적절하다. -
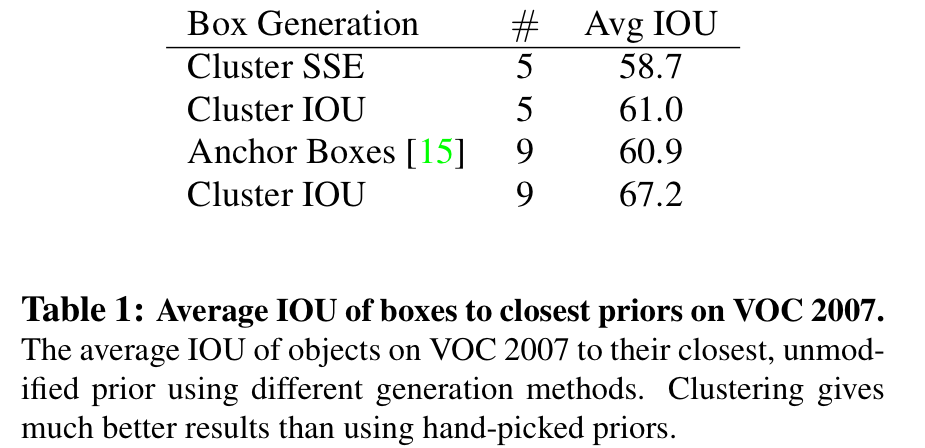
Cluster IOU가 기존의 Anchor Boxes보다 더 좋은 성능을 보임.
그리고 로 했을 때, model complexity와 high recall 사이 tradeoff가 가장 좋았음.

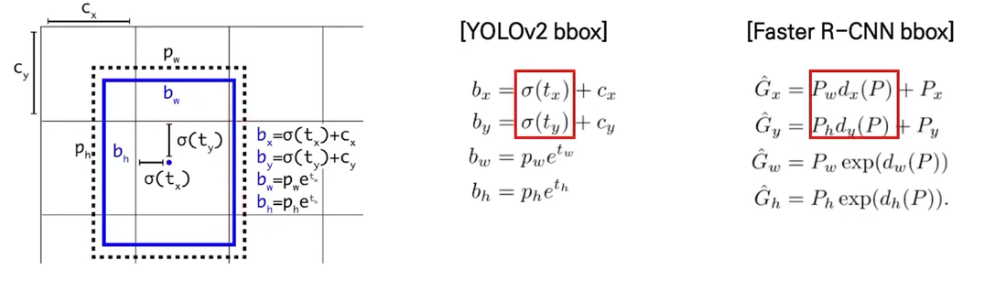
Direct location prediction
- anchor box의 각 좌표인 에 sigmoid function을 적용해서,
grid cell 내에서만 존재하도록 만든다
즉, 0~1 사이의 값으로 만든다.
왜냐하면 location prediction을 제약함으로써 parameterization이 학습을 더 쉽게 만들고,
network를 더욱 stable하게 만들 수 있다.
만약 Faster R-CNN model과 같이 bbox를 찾는 수식의 함수 에 아무런 제약이 없다면,
grid cell을 벗어난 random한 위치에 anchor box가 생성된다.
Fine-Grained Features
-
수정된 YOLO는 13 x 13 feature map을 예측한다.
이것은 large object에 대해서는 충분하지만,
smaller object의 localizing에 대해서는 더 정교한 feature가 필요할 것이다. -
Faster R-CNN과 SSD는
그들의 proposal network를 a range of resolution을 얻기 위해 network의 다양한 feature map에 적용시켰는데,
우리는 26 x 26 resolution의 earlier layer로부터 featuree를 뽑아 passthrough layer에 간단히 추가하였다.
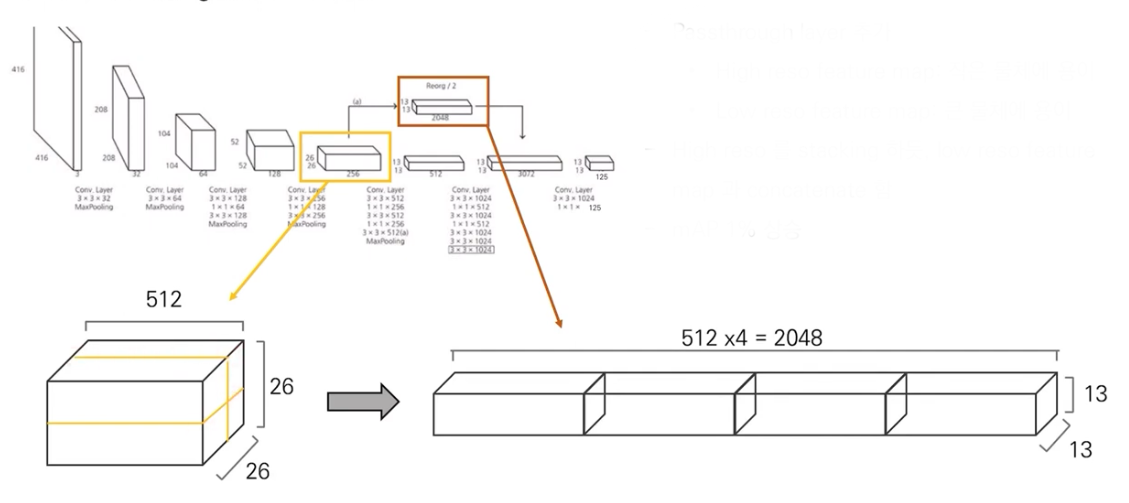
The passthrough layer는 high resolution feature와 low resolution feature를 concat하기 위해 spatial location이 아닌 adjacent feature를 stack하는 방식으로 동작한다.
26 x 26 x 512 feature map을 13 x 13 x 2048 feature map으로 만들고,
그것은 original feature map과 차원이 맞기 때문에 바로 concat되어질 수 있다.
passthrough layer를 통해
작은 물체와 큰 물체를 모두 잘 detection할 수 있도록 하였다.
이를 통해 1% mAP 상승
Multi-Scale Training
-
우리는 YOLOv2가 다양한 size의 image에서 잘 동작되도록 훈련시켰다.
input image size를 고정시키는 대신에 매 몇번의 iteration마다 input size를 바꿨다. -
매 10 batch마다 network는 random하게 새로운 image size 선택한다.
model은 32의 배수에서 선택함: {320, 352, ..., 608}.
(가장 작은 옵션은 320 × 320이고 가장 큰 옵션은 608 × 608.)
우리는 network를 해당 dimension으로 resize하고, 훈련을 계속 진행시켰다. -
이 방법은 network가 다양한 input dimension에서 잘 예측하도록 학습하도록 한다.
이는 동일한 network가 다른 resolution에서 detection을 prediction할 수 있다는 것을 의미함.
Furter Experiments
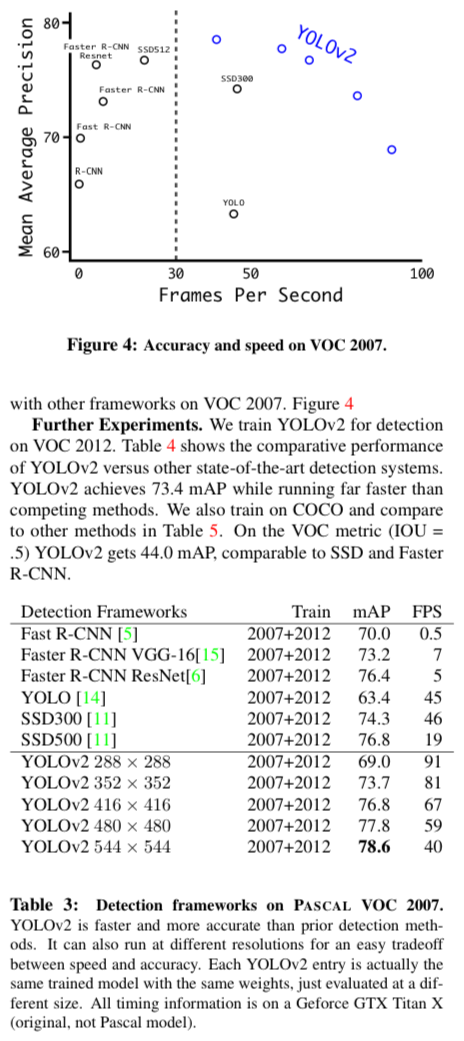
- PASCAL VOC data에 대해서 mAP 상승, fps 개선
여전히 mAP와 fps 간에 trade off 존재(accuracy-speed)
3. Faster (for YOLOv2)
Darknet-19
-
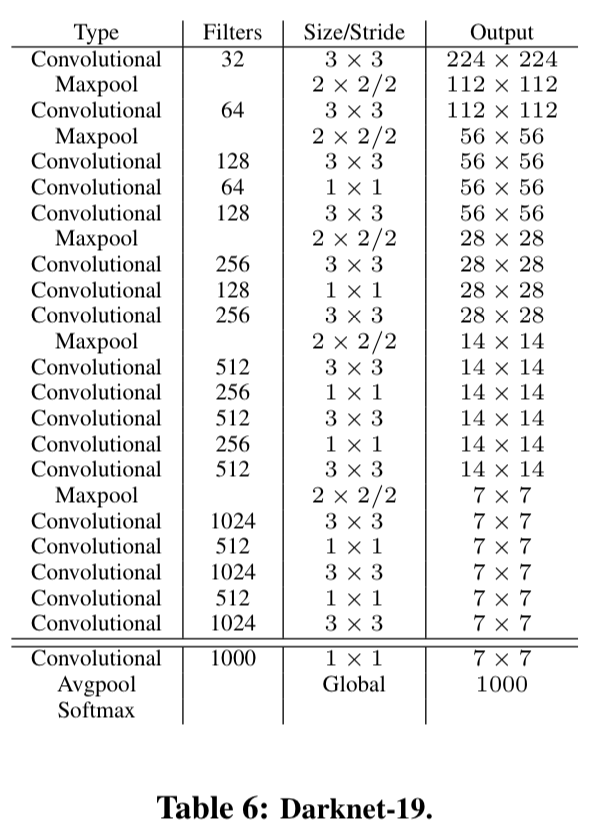
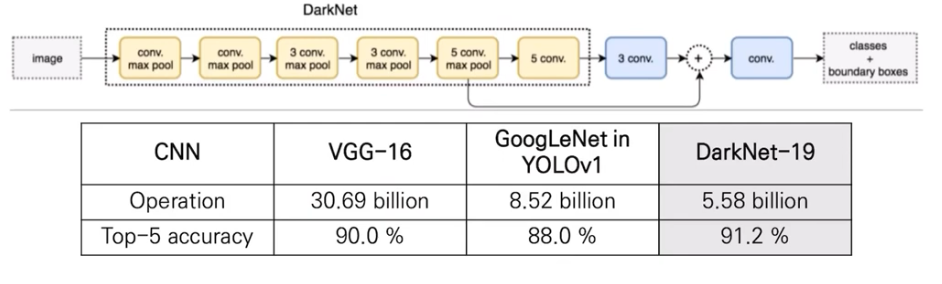
우리는 YOLOv2의 base에 사용할 새로운 classification model인 Darknet-19를 제안한다.
VGG model과 유사하게 3 x 3 filter를 사용하고, 매 pooling step마다 2배의 channel을 늘렸다. -
NIN 구조 이후 global average pooling 사용.
또한 1 x 1 filter를 사용해서 feature representation을 compression하는 데에 사용. -
Darknet-19는 19개의 convn layer와 5개의 max pooling layer를 가짐.
Training for classification
- dataset과 hyper parameter의 내용.

Training for detection
- 초반에 network 수정 내용과 마찬가지로 hyper parameter의 내용

4. Stronger (for YOLO9000)
Hierarchical classification
- ImageNet label은 WordNet 기반(tree 기반이 아닌, directed graph 형태)으로 구성됨.
Hierarchical classification 학습을 통해 WordTree 생성.
label 서로 완전히 상호배제적이지 않기 때문에 WordNet 구조로 공통 root를 갖는 label을 묶는 작업
('Norfolk terrier'와 'Yorkshire terrier'는 모두 "terrirer"의 합성어이므로 "hunting dog"또는 "dog"또는 "canine"으로도 정답 Label로)
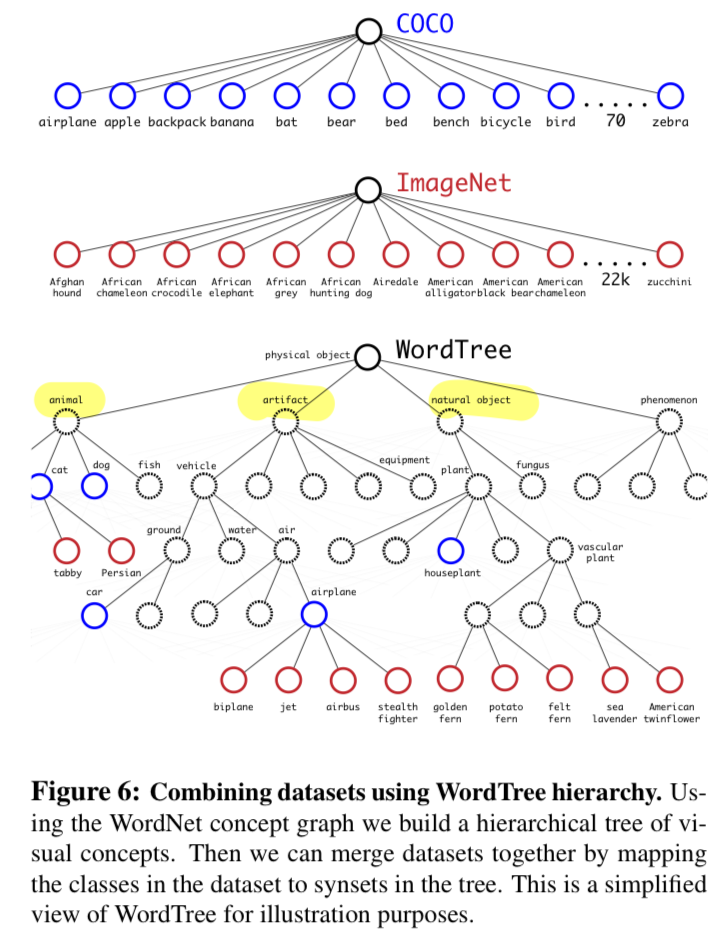
Datset combination with WordTree
- classification dataset의 ImageNet과
detection datset의 COCO와
ImageNet의 detection dataset을 모두 합쳐서
9000개의 object를 학습
Joint classification and detection
- detection dataset과 classification dataset 개수 차이가 크므로, oversampling으로 개수를 맞춤

- detection image를 볼때, 평범하게 loss를 backprogate한다.
classification loss에 대헛, we only baackpropagate loss at or above the corresponding level of the label. - classification image를 볼 때,
우리는 오직 classification loss만 backpropagate한다.
- detection image를 볼때, 평범하게 loss를 backprogate한다.
- "Using this joint training, YOLO9000 learns to find ob- jects in images using the detection data in COCO and it learns to classify a wide variety of these objects using data from ImageNet."
classification
- 1000 class ImageNet에 대해서 classification experiment
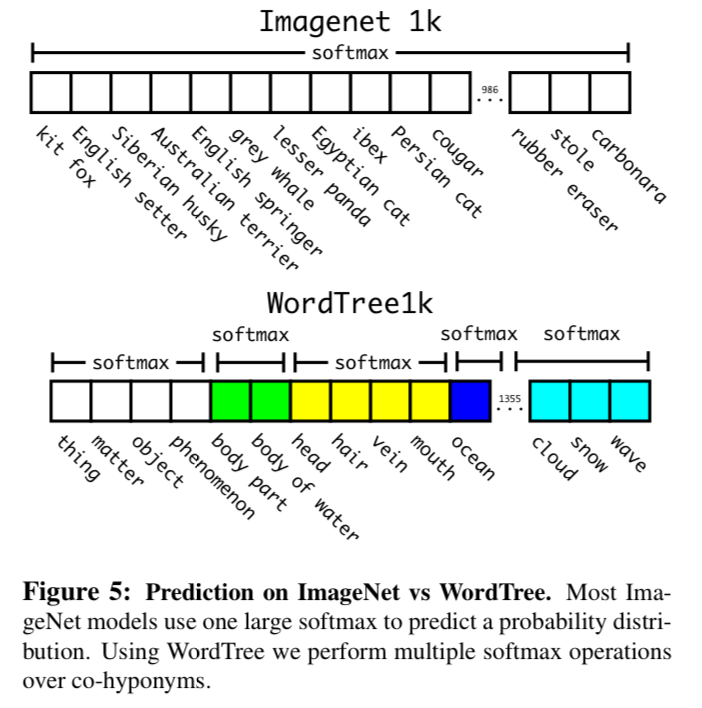 WordTree를 Darknet-19로 검증.
WordTree를 Darknet-19로 검증.
WordNet -> Tree 과정에서 369개의 node 생성(1000 -> 1369)
같은 node로부터 나온 node끼리 softmax 계산하여 probability를 계산.
detection
- ImageNet detection + COCO dataset 사용
- 9000개 class로 WordTree 만들고 나서, YOLOv2 학습
- train 시 등장했던 class 44개에 대해서 성능이 좋음

5. Conclusion

