
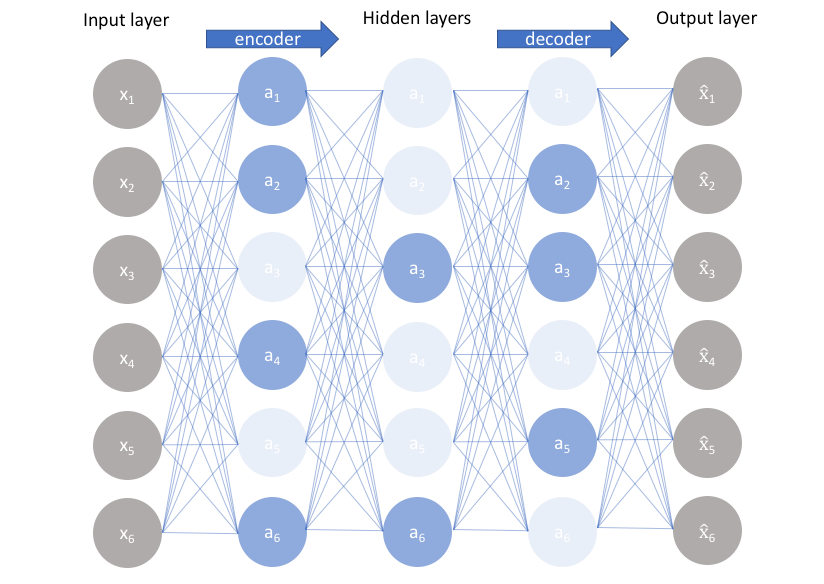
1. 오토인코더 (Autoencoder)
오토인코더는 입력 데이터를 효율적으로 압축하고 다시 복원하는 것을 목표로 하는 인공신경망 기반의 비지도 학습 모델이다.
인코더(encoder)라는 신경망 구조를 통해 입력 데이터를 저차원(latent space)의 잠재 표현으로 변환하고, 디코더(decoder)를 통해 이를 다시 원래의 입력 데이터로 복원한다.
학습은 원본 입력과 복원된 출력 간의 재구성 오류(reconstruction error)를 최소화하는 방식으로 이루어진다.
→ 데이터의 핵심 특징 추출, 노이즈 제거, 차원 축소 등에 활용.
오토인코더는 생성 모델의 기초가 되는 구조로서, 이후 변분 오토인코더(VAE)나 GAN과 같은 발전된 모델에도 큰 영향을 주었다.
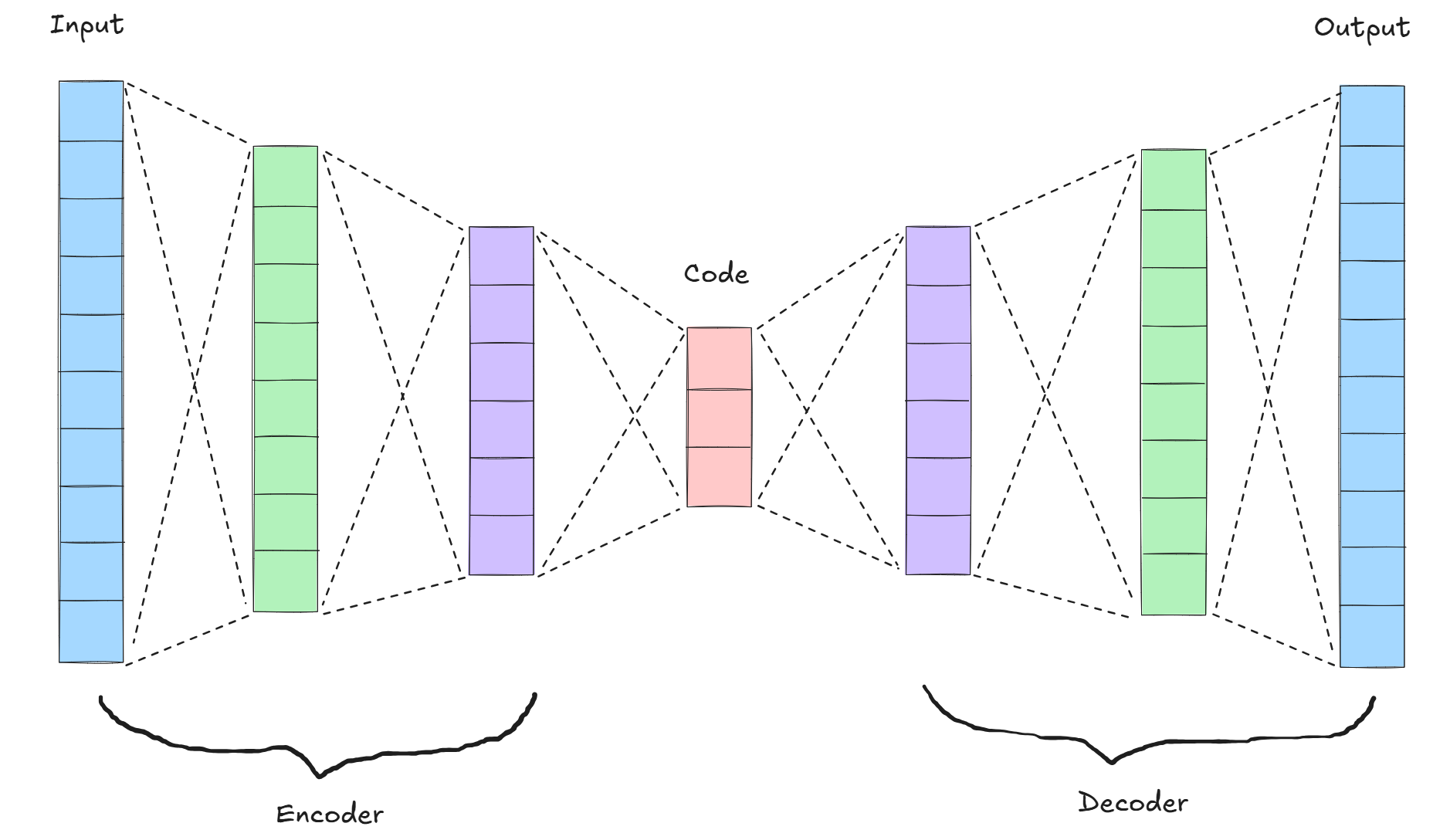
1. 인코더 (Encoder)
- 데이터를 요약하는 압축기
- 인코더는 고차원 데이터를 받아서, 핵심적인 특징만을 담은 저차원 잠재 표현(latent vector)으로 바꿔준다.
- 입력 이미지가 28x28 픽셀이라면, 총 784개의 숫자가 들어온다.
- 인코더는 이 784개의 숫자 중에서 정말 중요한 특징만 뽑아낸다.
ex) 32차원 벡터로 요약. → 잠재 공간(latent space)
2. 디코더 (Decoder)
- 요약 정보를 복원하는 재생기
- 디코더는 인코더가 만든 요약 정보를 보고, 최대한 원래 데이터와 비슷하게 복원하려고 한다.
- 인코더가 만든 32차원의 벡터를 받아서,
- 다시 784개의 숫자 (28x28 이미지)로 복원하려고 한다.
- 인코더에서 잃은 정보를 복원하기 때문에, 완전히 같진 않을 수 있지만 비슷하게 재현하려고 한다.
2. 오토인코더 구현하기
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D, Flatten, Reshape# MNIST 데이터셋을 불러온다.
(X_train, _), (X_test, _) = mnist.load_data()X_train.shape, X_train.shape[0]((60000, 28, 28), 60000)데이터 전처리
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255
# → 원래는 (28,28) 흑백이미지인데 CNN은 채널 차원을 요구하므로 (28,28,1)로 바꿔준다.
# 또한 픽셀값 0~255 → 0~1 범위로 정규화(normalization) 해준다.오토인코더 모델 생성
# 생성자 모델을 만든다.
autoencoder = Sequential()
# 인코더
# 입력 이미지를 점점 압축하는 과정 (특징 추출)
autoencoder.add(Conv2D(16, kernel_size=3, padding='same', input_shape=(28,28,1), activation='relu'))
autoencoder.add(MaxPooling2D(pool_size=2, padding='same')) # (14, 14, 16)
autoencoder.add(Conv2D(8, kernel_size=3, activation='relu', padding='same')) # (14, 14, 8)
autoencoder.add(MaxPooling2D(pool_size=2, padding='same')) # (7, 7, 8)
autoencoder.add(Conv2D(8, kernel_size=3, strides=2, padding='same', activation='relu')) # (4, 4, 8)
# 디코더
# 압축된 특징을 다시 원본 이미지 크기로 복원하는 과정
autoencoder.add(Conv2D(8, kernel_size=3, padding='same', activation='relu')) # (4, 4, 8)
autoencoder.add(UpSampling2D()) # (8, 8, 8)
autoencoder.add(Conv2D(8, kernel_size=3, padding='same', activation='relu')) # (8, 8, 8)
autoencoder.add(UpSampling2D()) # (16, 16, 8)
autoencoder.add(Conv2D(16, kernel_size=3, activation='relu')) # (14, 14, 16)
autoencoder.add(UpSampling2D()) # (28, 28, 16)
autoencoder.add(Conv2D(1, kernel_size=3, padding='same', activation='sigmoid')) # (28, 28, 1)
# 전체 구조 확인
autoencoder.summary()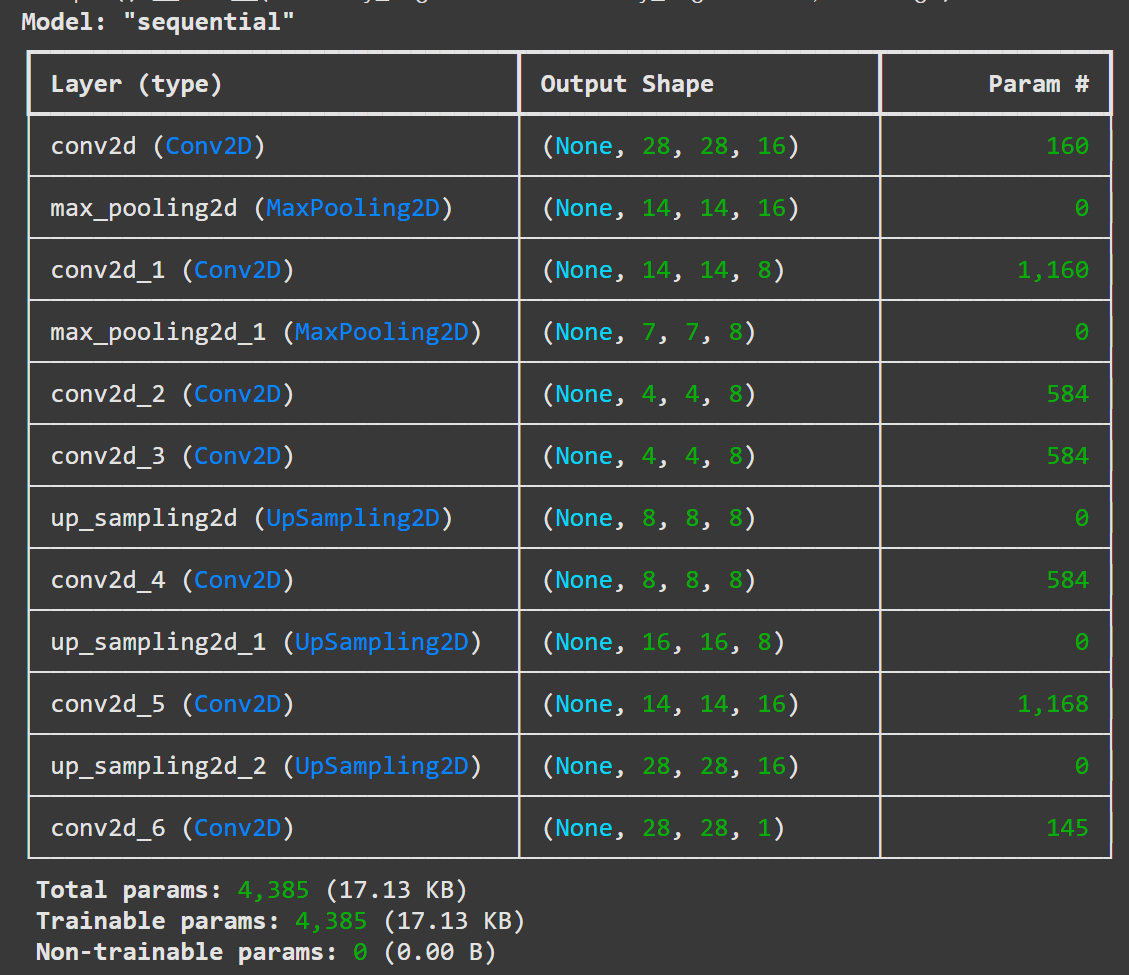
Conv2D 출력 크기 공식
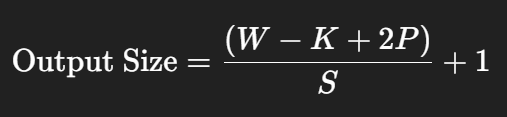
- W: 입력 크기 (여기서는 16)
- K: 커널 크기 (여기서는 3)
- P: padding (0이면 valid, 1 이상이면 same 등)
- S: stride (기본값 1)
모델 학습 준비
# 컴파일 및 학습을 하는 부분
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 옵티마이저: adam (학습 속도 좋음)
# 손실함수: binary_crossentropy → 픽셀 단위로 0/1 차이를 계산학습 실행
autoencoder.fit(X_train, X_train, epochs=50, batch_size=128, validation_data=(X_test, X_test))
# 입력도 X, 출력도 X (자기 자신을 복원하는 훈련)
# validation_data → 테스트셋에서도 결과 확인# 학습된 결과를 출력하는 부분
random_test = np.random.randint(X_test.shape[0], size=5) # 테스트할 이미지를 랜덤하게 불러온다.
ae_imgs = autoencoder.predict(X_test) # 앞서 만든 오토인코더 모델에 집어 넣는다.plt.figure(figsize=(7, 2)) # 출력될 이미지의 크기를 정한다.
for i, image_idx in enumerate(random_test): # 랜덤하게 뽑은 이미지를 차례로 나열한당.
ax = plt.subplot(2, 7, i + 1)
plt.imshow(X_test[image_idx].reshape(28, 28)) # 테스트할 이미지를 먼저 그대로 보여준다.
ax.axis('off')
ax = plt.subplot(2, 7, 7 + i +1)
plt.imshow(ae_imgs[image_idx].reshape(28, 28)) # 오토인코딩 결과를 다음열에 출력
ax.axis('off')
plt.show()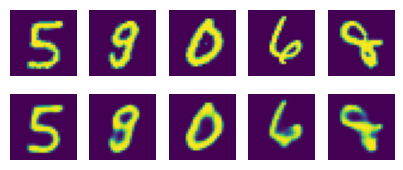
3. Sparse Autoencoder
Sparse Autoencoder는 입력 데이터를 압축된 형태로 표현하는 오토인코더의 한 종류로, 잠재 공간(latent space)에서 대부분의 뉴런이 0에 가깝고 일부만 활성화되도록 강제하는 구조이다.
이렇게 희소성을 주기 위해 L1 정규화나 KL Divergence 기반의 제약을 추가하여, 모델이 단순히 모든 뉴런을 다 쓰는 대신 중요한 특징만 선택적으로 사용하도록 유도한다.
그 결과, Sparse Autoencoder는 데이터의 핵심적인 특징을 더 해석 가능하고 압축된 방식으로 표현할 수 있으며, 차원 축소, 특징 추출, 이상 탐지 등 다양한 분야에서 활용된다.
4. Denoising Autoencoder
Denoising Autoencoder는 입력 데이터에 일부러 노이즈를 추가한 뒤, 그 손상된 데이터를 원래의 깨끗한 데이터로 복원하도록 학습하는 오토인코더이다.
이렇게 학습하면 모델은 단순히 입력을 복사하는 대신 데이터의 본질적 패턴과 구조를 더 잘 학습하게 되며, 잡음에 강인한 표현을 얻을 수 있다.
Denoising Autoencoder는 특징 추출, 데이터 전처리, 이상 탐지 등에서 활용되며, 노이즈 제거뿐 아니라 일반적인 강건한 표현 학습(robust representation learning) 방법으로 사용된다.

import torch.nn as nnclass Encoder(nn.Module):
def __init__(self, num_input_channels, base_channel_size, latent_dim):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(num_input_channels, base_channel_size, kernel_size=3, padding=1, stride=2), # 32x32 => 16x16
nn.GELU(),
nn.Conv2d(base_channel_size, base_channel_size, kernel_size=3, padding=1),
nn.GELU(),
nn.Conv2d(base_channel_size, 2 * base_channel_size, kernel_size=3, padding=1, stride=2), # 16x16 => 8x8
nn.GELU(),
nn.Conv2d(2 * base_channel_size, 2 * base_channel_size, kernel_size=3, padding=1),
nn.GELU(),
nn.Conv2d(2 * base_channel_size, 2 * base_channel_size, kernel_size=3, padding=1, stride=2), # 8x8 => 4x4
nn.GELU(),
nn.Flatten(), # (배치, 채널, H, W) → (배치, 채널*H*W) 평탄화
# 최종 latent 벡터로 매핑
# 출력 크기 = latent_dim (압축된 특징 벡터)
nn.Linear(16 * base_channel_size * 2, latent_dim),
)
def forward(self, x):
# 순전파: 입력 이미지를 latent vector로 인코딩
return self.net(x)GELU를 사용하는 이유
reLU와 GELU <출처: https://en.wikipedia.org/wiki/Rectifier_%28neural_networks%29>
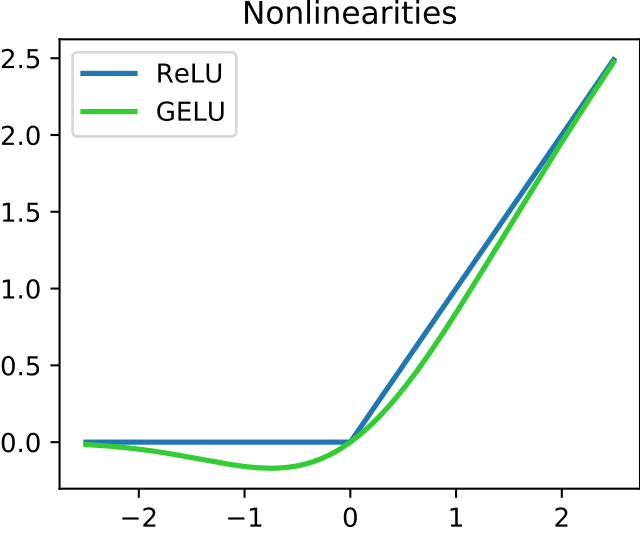
-
부드러움(Smoothness)
0 부근에서 미분이 연속이라 기울기 소실/폭주 완화에 유리하고, 학습이 안정적이다. (ReLU는 0에서 미분이 뚝 끊김.) -
정보 보존
작은 음수도 조금은 통과시켜서, ReLU처럼 음수 영역 뉴런이 “죽어버리는(dead)” 현상을 줄인다. -
경험적 성능
NLP의 Transformer(BERT, GPT 계열), 비전의 최신 아키텍처에서 GELU가 ReLU보다 성능이 더 좋은 경우가 자주 보고되었다. CNN에도 무난히 잘 맞는다.
# Encoder의 반대 역할
# latent vector를 입력받아 원래 이미지의 크기(예: 32 * 32 * 채널)로 복원하는 구조
class Decoder(nn.Module):
def __init__(self, num_input_channels, base_channel_size, latent_dim):
super().__init__()
self.linear = nn.Sequential(nn.Linear(latent_dim, 16 * base_channel_size * 2), nn.GELU())
self.net = nn.Sequential(
# 다운 샘플링의 반대, 업샘플링을 해줌
nn.ConvTranspose2d(
2 * base_channel_size, 2 * base_channel_size, kernel_size=3, output_padding=1, padding=1, stride=2
), # 4x4 => 8x8
nn.GELU(),
nn.Conv2d(2 * base_channel_size, 2 * base_channel_size, kernel_size=3, padding=1),
nn.GELU(),
nn.ConvTranspose2d(2 * base_channel_size, base_channel_size, kernel_size=3, output_padding=1, padding=1, stride=2), # 8x8 => 16x16
nn.GELU(),
nn.Conv2d(base_channel_size, base_channel_size, kernel_size=3, padding=1),
nn.GELU(),
nn.ConvTranspose2d(
base_channel_size, num_input_channels, kernel_size=3, output_padding=1, padding=1, stride=2
), # 16x16 => 32x32
nn.Tanh(), # -1~1
)
def forward(self, x):
x = self.linear(x)
x = x.reshape(x.shape[0], -1, 4, 4)
# (batch, channel*?, 4, 4) 형태로 다시 reshape.
# x.shape[0] → 배치 크기 (샘플 개수, 예: 32, 64, 128...)
# -1 → 남는 차원은 자동 계산해서 채워라 (flexible)
# 4, 4 → 마지막 두 차원을 4x4 블록 형태로 만들겠다
x = self.net(x)
return x# Autoencoder: Encoder + Decoder를 합쳐놓은 전체 모델
class Autoencoder(nn.Module):
def __init__(self, num_input_channels, base_channel_size, latent_dim):
super().__init__()
# 인코더: 입력 이미지를 latent vector로 변환
self.encoder = Encoder(num_input_channels, base_channel_size, latent_dim)
# 디코더: latent vector를 다시 이미지로 복원
self.decoder = Decoder(num_input_channels, base_channel_size, latent_dim)
def forward(self, x):
# 1) 입력 이미지를 latent vector로 변환
latent = self.encoder(x)
# 2) latent vector → 다시 원래 이미지 크기로 복원
output = self.decoder(latent)
return latent, output# 실제 모델 생성 (예시)
# 3채널(RGB), base_channel_size=64, latent_dim=256
model = Autoencoder(num_input_channels=3, base_channel_size=64, latent_dim=256)
modelAutoencoder(
(encoder): Encoder(
(net): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): GELU(approximate='none')
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): GELU(approximate='none')
(4): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(5): GELU(approximate='none')
(6): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GELU(approximate='none')
(8): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(9): GELU(approximate='none')
(10): Flatten(start_dim=1, end_dim=-1)
(11): Linear(in_features=2048, out_features=256, bias=True)
)
)
(decoder): Decoder(
(linear): Sequential(
(0): Linear(in_features=256, out_features=2048, bias=True)
(1): GELU(approximate='none')
)
(net): Sequential(
(0): ConvTranspose2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(1): GELU(approximate='none')
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): GELU(approximate='none')
(4): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(5): GELU(approximate='none')
(6): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GELU(approximate='none')
(8): ConvTranspose2d(64, 3, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(9): Tanh()
)
)
)import torch
from torchvision.transforms import v2데이터 전처리 (학습용 / 테스트용)
trn_transforms = v2.Compose([
v2.ToImage(),
v2.RandomResizedCrop(size=(32, 32), antialias=True), # 무작위 크롭 후 32x32로 리사이즈
v2.RandomHorizontalFlip(p=0.5), # 좌우 반전 확률 50%
v2.RandomVerticalFlip(p=0.5), # 상하 반전 확률 50%
v2.ToDtype(torch.float32, scale=True), # float32 변환 + 0~1 스케일링
v2.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]), # -1 ~ 1 정규화
])
test_transforms = v2.Compose([
v2.ToImage(),
v2.Resize(size=(32, 32), antialias=True), # 테스트셋은 크롭 없이 리사이즈만
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])from torchvision.datasets import CIFAR10
# CIFAR-10 학습 데이터셋/테스트 데이터셋
trn_dataset = CIFAR10(".", train=True, download=True, transform=trn_transforms)
test_dataset = CIFAR10(".", train=False, download=True, transform=test_transforms)import matplotlib.pyplot as plt
import numpy as np
import torchvision.utils as vutils
# 이미지 시각화 함수
def imshow(inputs, title):
mean = 0.5
std = 0.5
# 정규화 풀기 (원래 색상으로 되돌림)
inputs = std * inputs + mean
inputs = torch.clip(inputs, 0, 1) # 0~1 범위 클리핑
grid = vutils.make_grid(inputs, padding=2, normalize=True) # 여러 이미지를 그리드로 합치기
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title(title)
plt.imshow(np.transpose(grid, (1,2,0))) # (C,H,W) → (H,W,C)
plt.show()
plt.close()DataLoader 정의
trn_loader = torch.utils.data.DataLoader(trn_dataset, batch_size=64, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=2)GPU/CPU 설정
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")from tqdm import tqdm
# 오토인코더 학습 함수 (기본)
def train(model, criterion, optimizer, trn_loader, test_loader, device, num_epochs):
for epoch in range(num_epochs):
# --- 학습 단계 ---
model.train()
trn_loss = 0.0
for inputs, _ in tqdm(trn_loader):
inputs = inputs.to(device)
_, outputs = model(inputs) # 오토인코더: 입력 -> latent -> 출력
loss = criterion(outputs, inputs) # 원본 vs 복원 결과 MSE
optimizer.zero_grad()
loss.backward()
optimizer.step()
trn_loss += loss.item() * inputs.size(0)
trn_epoch_loss = trn_loss / len(trn_loader.dataset)
print(f"[Train] Loss: {trn_epoch_loss:.4f}")
# --- 평가 단계 ---
with torch.no_grad():
model.eval()
test_loss = 0.0
for inputs, _ in tqdm(test_loader):
inputs = inputs.to(device)
_, outputs = model(inputs)
loss = criterion(outputs, inputs)
test_loss += loss.item() * inputs.size(0)
test_epoch_loss = test_loss / len(test_loader.dataset)
print(f"[Test] Loss: {test_epoch_loss:.4f}")
# 👀 시각화: 마지막 배치의 '원본' vs '복원 결과'를 확인
# - imshow 내부에서 역정규화(+클리핑) 후 그리드로 보여줌
imshow(inputs.cpu(), "Inputs")
imshow(outputs.cpu(), "outputs")import torch.optim as optim
model = model.to(device)
criterion = nn.MSELoss() # 손실 함수: 입력과 출력 차이를 줄이는 MSELoss 사용
optimizer = optim.Adam(model.parameters(), lr=0.001) # 옵티마이저: Adam 사용 (학습률 0.001)train(model, criterion, optimizer, trn_loader, test_loader, device, num_epochs=10)이미지 → 잠재 벡터 추출 함수


def get_embed(model, data_loader):
image_list, embed_list = [], []
model.eval()
with torch.no_grad():
for inputs, _ in tqdm(data_loader):
inputs = inputs.to(device)
latents = model.encoder(inputs)
image_list.append(inputs.cpu())
embed_list.append(latents)
image_list = torch.cat(image_list, dim=0)
embed_list = torch.cat(embed_list, dim=0)
return image_list, embed_list이미지 유사도 검색 함수
def find_similar_images(query_image, query_embed, key_images, key_embeds, k=7):
# torch.cdist : 두 텐서 사이의 거리 계산 (여기선 유클리드 거리, p=2)
dist = torch.cdist(query_embed[None, :], key_embeds, p=2) # (1, N)
dist = dist.squeeze(dim=0) # (N, )
# largest=False, 가장 작은 거리 = 가장 유사한 Top-k의 인덱스를 얻음
_, topk_indices = torch.topk(dist, k, largest=False)
# 이미지를 맨 앞에 붙이고, Top-k 이미지들을 이어붙여 그리드로 보여줌
topk_images = torch.cat([query_image[None], key_images[topk_indices.cpu()]], dim=0)
imshow(topk_images, f"Top-{k} images")
# 가장 멀리 떨어진 Bottom-k 이미지도 확인
_, bottomk_indices = torch.topk(dist, k, largest=True)
bomttomk_images = torch.cat([query_image[None], key_images[bottomk_indices.cpu()]], dim=0)
imshow(bomttomk_images, f"Bottom-{k} images")test set에서 임베딩 추출
test_images, test_embeds = get_embed(model, test_loader)앞의 몇 개 이미지를 기준으로 유사 이미지 검색
for i in range(8):
find_similar_images(test_images[i], test_embeds[i], test_images[i+1:], test_embeds[i+1:])
입력에 노이즈를 추가하는 함수
def add_noise(inputs):
noise = torch.randn(inputs.size()) * 0.2 # 정규분포(평균0, 분산1) * 0.2
noisy_inputs = inputs + noise
return noisy_inputs노이즈 추가 학습 (Denoising Autoencoder 학습)
def train_with_noise(model, criterion, optimizer, trn_loader, test_loader, device, num_epochs):
for epoch in range(num_epochs):
model.train()
trn_loss = 0.0
for inputs, _ in tqdm(trn_loader):
inputs_with_noise = add_noise(inputs)
inputs_with_noise = inputs_with_noise.to(device)
inputs = inputs.to(device)
# Autoencoder forward (Encoder+Decoder)
_, outputs = model(inputs_with_noise)
# 손실 = 노이즈 입력 → 원래 입력 복원 차이
loss = criterion(outputs, inputs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
trn_loss += loss.item() * inputs.size(0)
trn_epoch_loss = trn_loss / len(trn_loader.dataset)
print(f"[Train] Loss: {trn_epoch_loss:.4f}")
with torch.no_grad():
model.eval()
test_loss = 0.0
for inputs, _ in tqdm(test_loader):
inputs_with_noise = add_noise(inputs)
inputs_with_noise = inputs_with_noise.to(device)
inputs = inputs.to(device)
_, outputs = model(inputs_with_noise)
loss = criterion(outputs, inputs)
test_loss += loss.item() * inputs.size(0)
test_epoch_loss = test_loss / len(test_loader.dataset)
print(f"[Test] Loss: {test_epoch_loss:.4f}")
# 시각화: 입력(깨끗한 원본), 출력(복원된 이미지)
imshow(inputs.cpu(), "Inputs")
imshow(outputs.cpu(), "outputs")model = Autoencoder(num_input_channels=3, base_channel_size=64, latent_dim=256)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 노이즈 추가 학습 실행
train_with_noise(model, criterion, optimizer, trn_loader, test_loader, device, num_epochs=10)

!pip install medmnistimport medmnist
# PathMNIST 데이터셋 정보 불러오기
pathmnist_info = medmnist.INFO['pathmnist']
DataClass = getattr(medmnist, pathmnist_info['python_class'])
# 학습/테스트 데이터셋 로드 (변환 적용)
pathmnist_trn_datset = DataClass(split='train', download=True, transform=trn_transforms)
pathmnist_test_dataset = DataClass(split='test', download=True, transform=test_transforms)
# DataLoader 생성
pathmnist_trn_loader = torch.utils.data.DataLoader(pathmnist_trn_datset, batch_size=64, shuffle=True, num_workers=2)
pathmnist_test_loader = torch.utils.data.DataLoader(pathmnist_test_dataset, batch_size=64, shuffle=False, num_workers=2)model = Autoencoder(num_input_channels=3, base_channel_size=64, latent_dim=256)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
train(model, criterion, optimizer, pathmnist_trn_loader, pathmnist_test_loader, device, num_epochs=3)

# 테스트셋 임베딩 추출
test_images, test_embeds = get_embed(model, pathmnist_test_loader)
# 유사한 이미지 찾기 (예시로 8개 비교)
for i in range(8):
find_similar_images(test_images[i], test_embeds[i], test_images[i+1:], test_embeds[i+1:])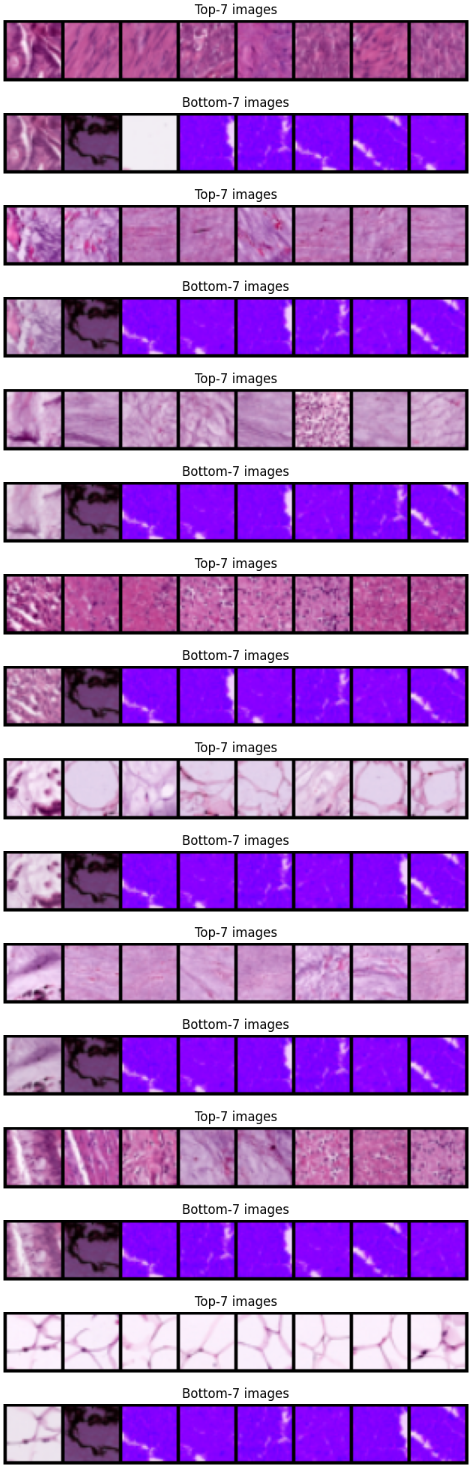
# Denoising Autoencoder 학습 (잡음 추가 버전)
model = Autoencoder(num_input_channels=3, base_channel_size=64, latent_dim=256)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_with_noise(model, criterion, optimizer, pathmnist_trn_loader, pathmnist_test_loader, device, num_epochs=3)

