이 코드는 https://www.kaggle.com/code/willkoehrsen/start-here-a-gentle-introduction 을 참고하며 학습하였다
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, PolynomialFeatures, MinMaxScaler
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
import warnings
warnings.filterwarnings('ignore')1. 데이터셋 확인
- 해당 커널에는 9개의 파일이 있다
- Training 1, Test 1, 예시 1, 대출에 대한 추가 정보가 들어있는 파일 6
df_train = pd.read_csv('../input/home-credit-default-risk/application_train.csv')
df_test = pd.read_csv('../input/home-credit-default-risk/application_test.csv')
print('Training data shape: ',df_train.shape)
df_train.head()
- Target : 1인 경우, 대출을 제 날짜에 상환하지 못함
1.1 Null data 확인
df_train.isnull().sum()
def missing_values_table(df):
# 전체 missing values
mis_val = df.isnull().sum()
# missing values의 비율
mis_val_percentage = 100 * mis_val / len(df)
# 결과로 테이블 만들기
mis_val_table = pd.concat([mis_val, mis_val_percentage], axis = 1)
# 칼럼 이름 수정
mis_val_table_ren_columns = mis_val_table.rename(columns = {0: 'Missing values', 1: '% of total values'})
# 내림차순으로 missing value 정렬
mis_val_table_ren_columns = mis_val_table_ren_columns[mis_val_table_ren_columns.iloc[:, 1] != 0].sort_values('% of total values', ascending=False).round(1)
print('Selected dataframes has ' + str(df.shape[1]) + ' columns.\n'
'There are ' + str(mis_val_table_ren_columns.shape[0]) + 'columns that have missing values')
return mis_val_table_ren_columnsmissing_values = missing_values_table(df_train)
missing_values.head(20)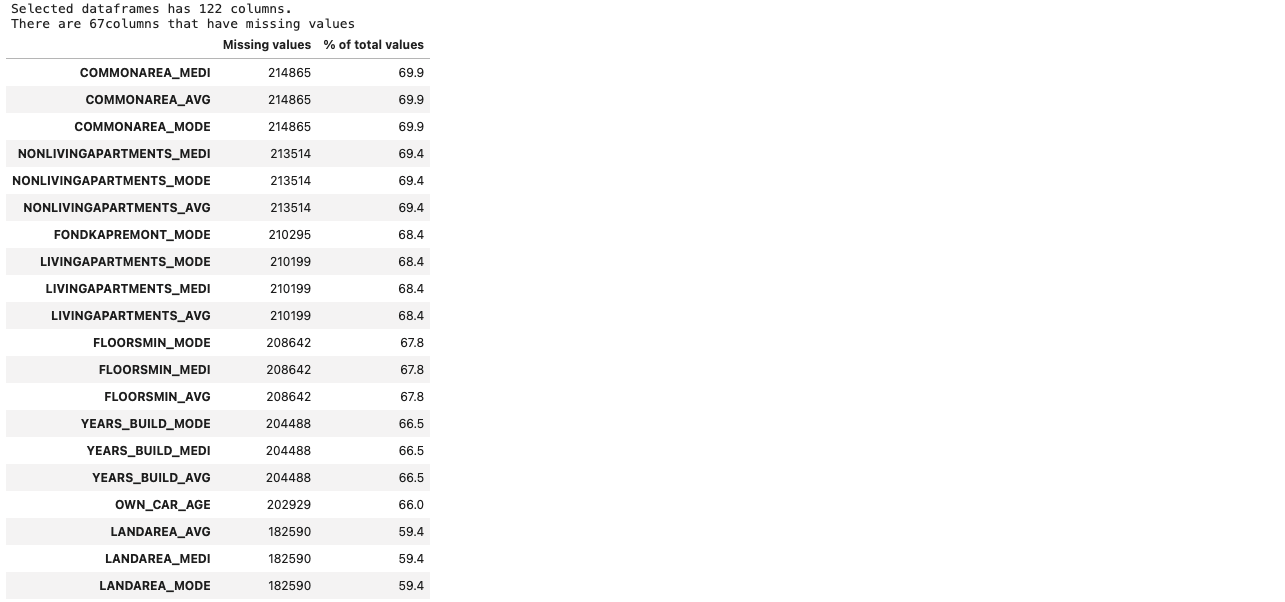
1.2 Target value 확인
- Target 값에 null value는 없으므로
value_counts()로 확인
df_train['TARGET'].value_counts()
fig, ax = plt.subplots(figsize=(6, 6))
x = df_train['TARGET'].value_counts().index
y = df_train['TARGET'].value_counts()
sns.barplot(x = x, y = y)
plt.ylabel('Frequency', fontsize = 12)
plt.xlabel('Target value', fontsize = 12)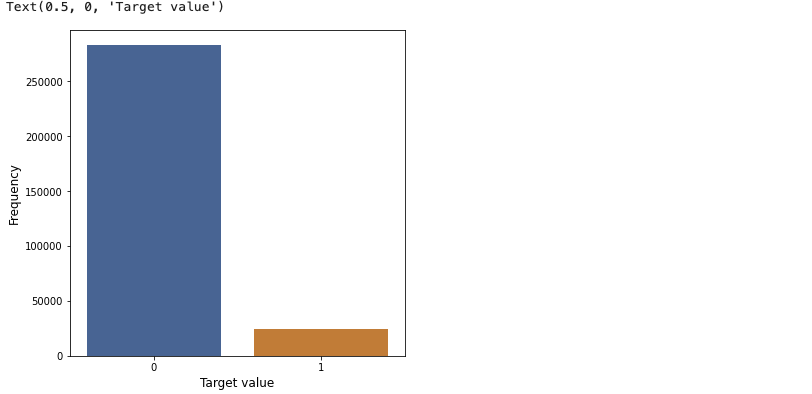
- 위의 결과를 보아, 대출을 상환한 사람이 상환하지 못한 사람보다 훨씬 많음을 알 수 있다
2. 탐색적 데이터 분석(Exploratory Data Analysis)
칼럽 타입 확인
df_train.dtypes.value_counts()
# 오브젝트 타입을 가진 칼럼의 유니크 값 개수 확인
df_train.select_dtypes('object').apply(pd.Series.nunique, axis = 0)
범위형 변수 인코딩
# Label encoder object 생성
le = LabelEncoder()
le_count = 0
for col in df_train:
if df_train[col].dtype == 'object':
if len(list(df_train[col].unique())) <= 2:
le.fit(df_train[col])
df_train[col] = le.transform(df_train[col])
df_test[col] = le.transform(df_test[col])
le_count += 1
print('%d columns were label encoded.' % le_count)
# One-hot encoding
df_train = pd.get_dummies(df_train)
df_test = pd.get_dummies(df_test)
print('Training Features shape: ', df_train.shape)
print('Testing Features shape: ', df_test.shape)
Training 데이터셋과 Test 데이터셋 맞추기
- 위의 결과를 보면, Training 데이터셋에는 Test 데이터셋에 존재하지 않는 데이터가 존재한다
- Test 데이터셋에 존재하지 않는 Training 데이터셋을 삭제하기 위해 dataframe을 align
train_labels = df_train['TARGET']
# training, test dataframe에 모두 있는 칼럼들은 유지
df_train, df_test = df_train.align(df_test, join='inner', axis=1)
df_train['TARGET'] = train_labels
print('Training Features shape : ', df_train.shape)
print('Testing Features shape : ', df_test.shape)
2.1 Anomalies
- EDA를 진행하며 항상 주시해야 하는 것은, 눈에 띄게 범위를 벗어난 값 그리고 잘못 입력된 값이다
- Anomalies를 확인하기 위해
describe메소드를 사용한다 DAYS_BIRTH칼럼은 현재 대출 어플리케이션과 상대적인 값이므로 음수로 표현되어있다
(df_train['DAYS_BIRTH'] / -365).describe()
- min, max, 평균값을 보았을 때 outlier는 없는 것으로 확인된다
(df_train['DAYS_EMPLOYED']).describe()
- max가 100년이 넘는다
df_train['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram')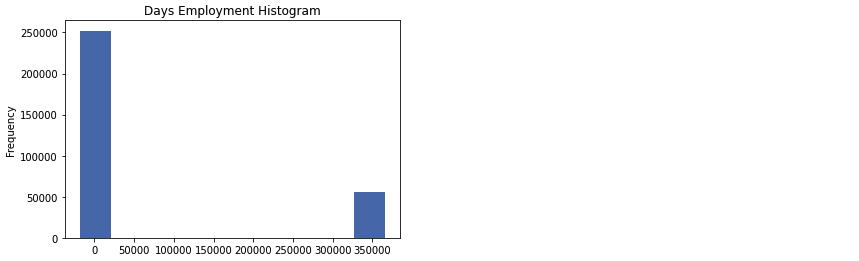
anom = df_train[df_train['DAYS_EMPLOYED'] == 365243]
non_anom = df_train[df_train['DAYS_EMPLOYED'] != 365243]
print('The non-anomalies default on %0.2f%% of loans' % (100 * non_anom['TARGET'].mean()))
print('The anomalies default on %0.2f%% of loans' % (100 * anom['TARGET'].mean()))
print('There are %d anomalous days of employment' % len(anom))
- Anomalies는 정해진 규칙 없이 상황에 맞게 다루어야 한다. 가장 안전한 방법은 anomalies를 missing value로 놓고 머신러닝 전에 채우는 것이다
- 여기에서는 anomalies가 모두 같은 값을 가지기 때문에, 해당 값들을 같은 값으로 대체하는 것이 타당하다
- 하지만 그 값이 무엇인지는 정확하게 모르기 때문에, 숫자가 아닌 값으로 대체한 다음(np.nan) 불리안 값으로 이것이 anomalies였는지 아닌지로 구분하는 것이 타당하다
df_train['DAYS_EMPLOYED_ANOM'] = df_train['DAYS_EMPLOYED'] == 365243
# Anomalous 값 nan으로 채우기
df_train['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
df_train['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram')
plt.xlabel('Days Employment')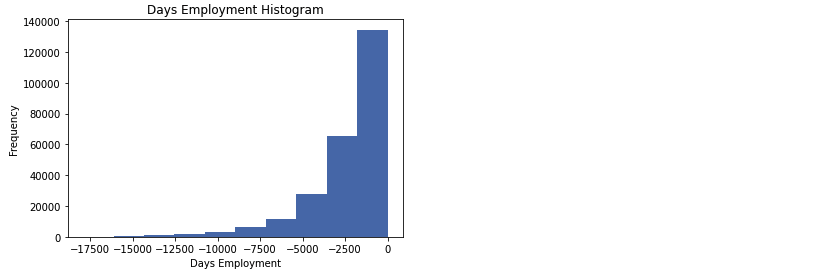
df_test['DAYS_EMPLOYED_ANOM'] = df_test['DAYS_EMPLOYED'] == 365243
df_test['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
print('There are %d anomalies in the test data out of %d entries' % (df_test['DAYS_EMPLOYED_ANOM'].sum(), len(df_test)))
2.2 Correlations
# Target 값과의 상관계수 찾고 sorting
correlations = df_train.corr()['TARGET'].sort_values()
print('Most Positive Correlations:\n', correlations.tail(15))
print('\nMost Negative Correlations:\n', correlations.head(15))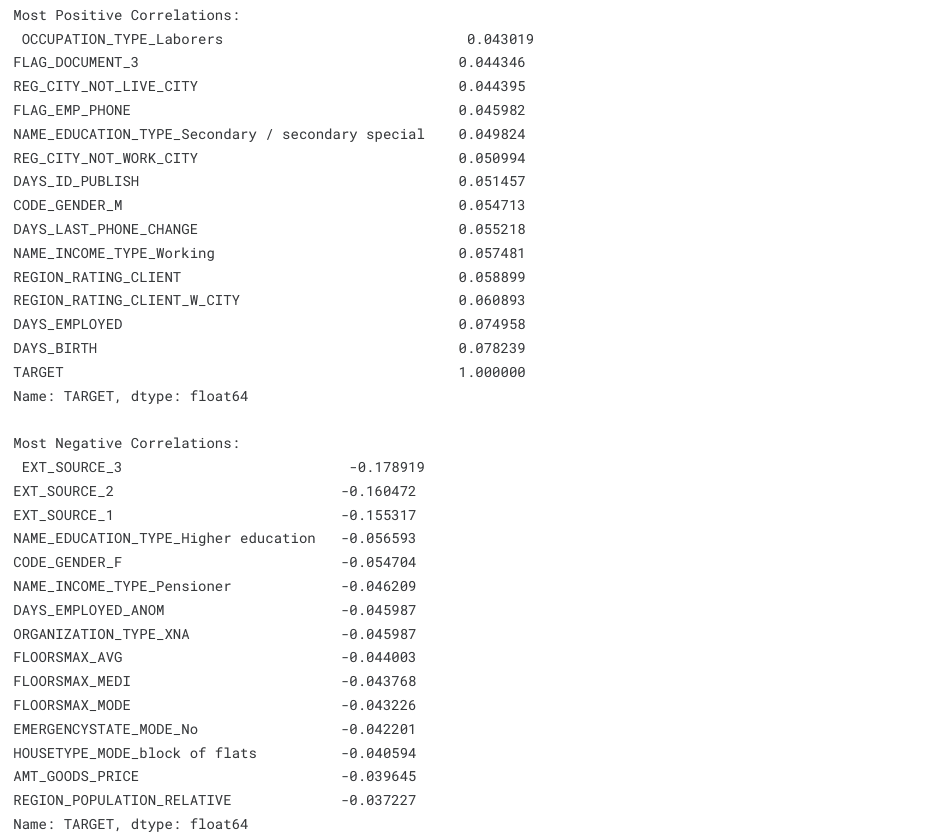
2.2.1 Ages
df_train['DAYS_BIRTH'] = abs(df_train['DAYS_BIRTH'])
df_train['DAYS_BIRTH'].corr(df_train['TARGET'])
plt.hist(df_train['DAYS_BIRTH'] / 365, edgecolor = 'k', bins=25)
plt.title('Age of Client'); plt.xlabel('Age (years)'); plt.ylabel('Count');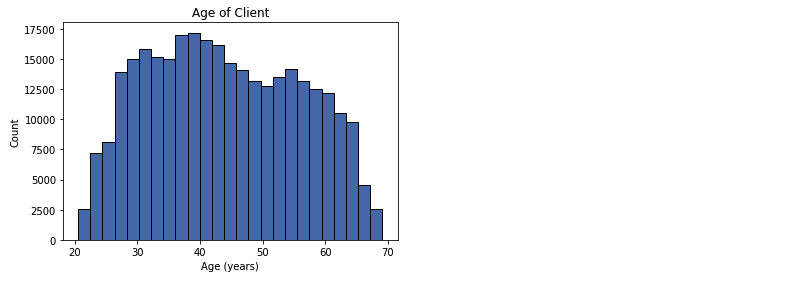
plt.figure(figsize = (10,8))
# 상환 날짜에 대출을 갚은 KDE plot
sns.kdeplot(df_train.loc[df_train['TARGET'] == 0, 'DAYS_BIRTH'] / 365, label = 'target == 0')
# 상환 날짜를 어긴 KDE plot
sns.kdeplot(df_train.loc[df_train['TARGET'] == 1, 'DAYS_BIRTH'] / 365, label = 'target == 1')
plt.xlabel('Age (years)'); plt.ylabel('Density'); plt.title('Distribution of Ages');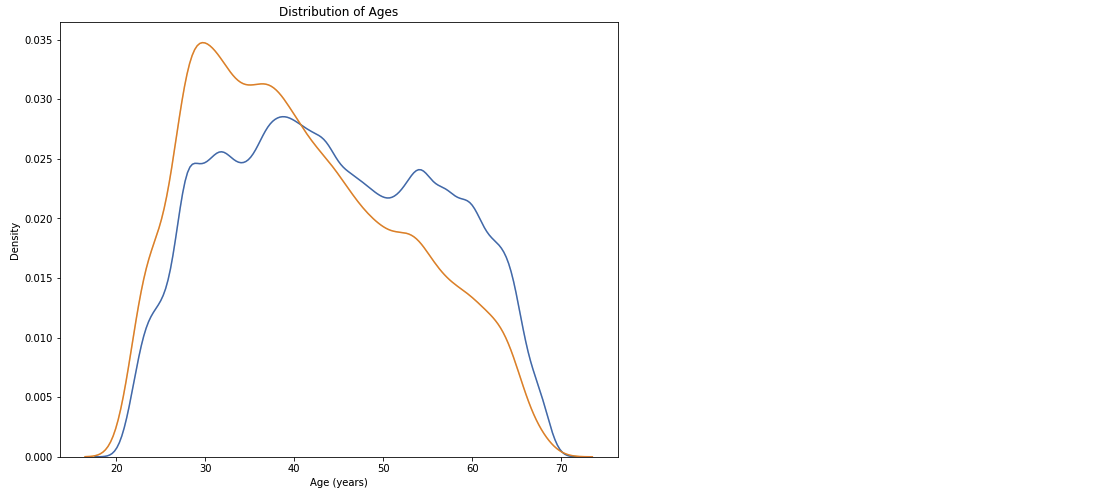
- 나이와 타겟의 상관계수는 -0.07이지만, 상관이 없다고는 할 수 없다
- 따라서 나이를 5년 단위로 끊은 뒤, 평균을 구해 각 나이 카테고리별 상환율을 구한다
age_data = df_train[['TARGET','DAYS_BIRTH']]
age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / 365
age_data['YEARS_BINNED'] = pd.cut(age_data['YEARS_BIRTH'], bins = np.linspace(20, 70, num = 11))
age_data.head(10)
age_groups = age_data.groupby('YEARS_BINNED').mean()
age_groups
plt.figure(figsize = (8, 8))
plt.bar(age_groups.index.astype(str), 100 * age_groups['TARGET'])
plt.xticks(rotation = 75); plt.xlabel('Age Group (years)'); plt.ylabel('Failure to Repay (%)')
plt.title('Failure to Repay by Age Group')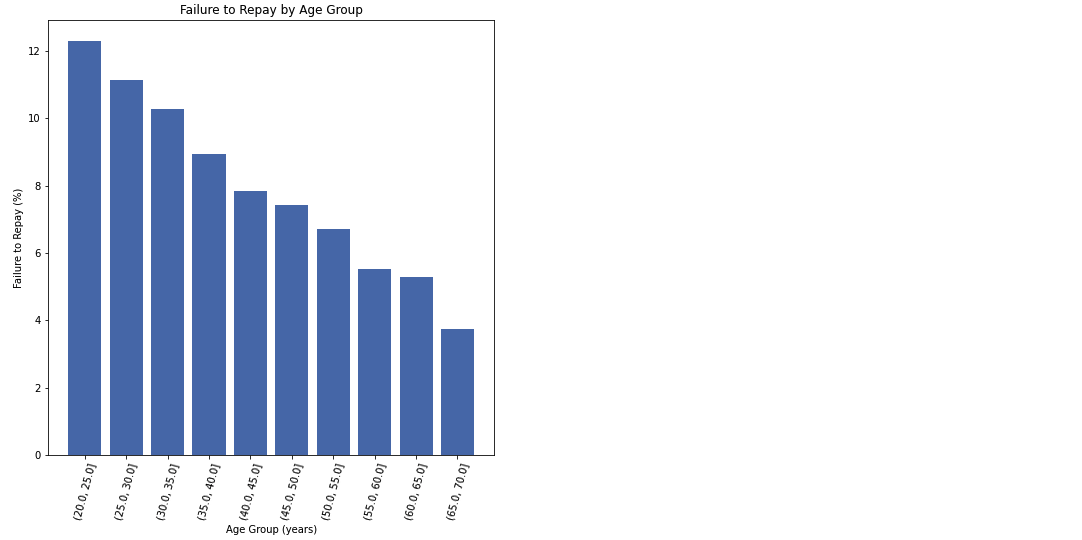
- 나이가 어릴수록 상환에 어려움을 겪고있다
2.2.2 Exterior Sources
- 상관계수가 가장 낮은 3개의 변수는
EXT_SOURCE_1,EXT_SOURCE_2,EXT_SOURCE_3이다 - 문서에 따르면 해당 변수들은 '외부 데이터 소스로부터 추출된 정규화된 점수'이다
ext_data = df_train[['TARGET','EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3','DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
plt.figure(figsize = (8, 6))
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6)
plt.title('Correlation Heatmap')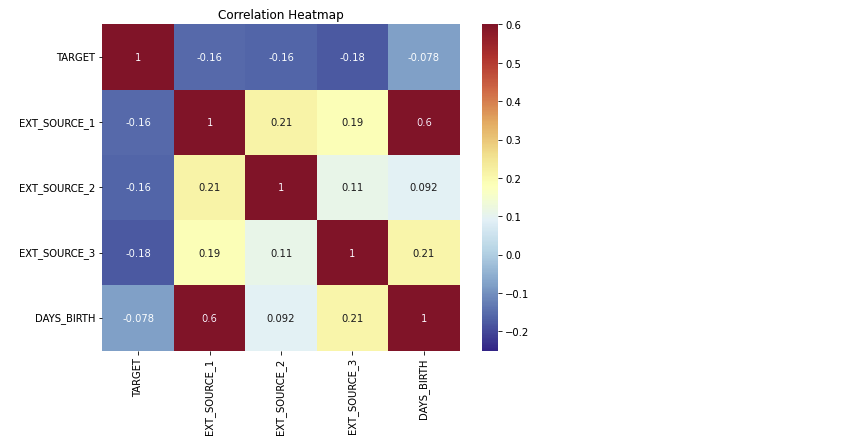
plt.figure(figsize = (10,12))
for i, source in enumerate(['EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3']):
plt.subplot(3,1,i+1)
sns.kdeplot(df_train.loc[df_train['TARGET'] == 0, source], label = 'target == 0')
sns.kdeplot(df_train.loc[df_train['TARGET'] == 1, source], label = 'target == 1')
plt.title('Distribution of %s by Target Value' % source)
plt.xlabel('%s' % source); plt.ylabel('Density');
plt.tight_layout(h_pad = 2.5)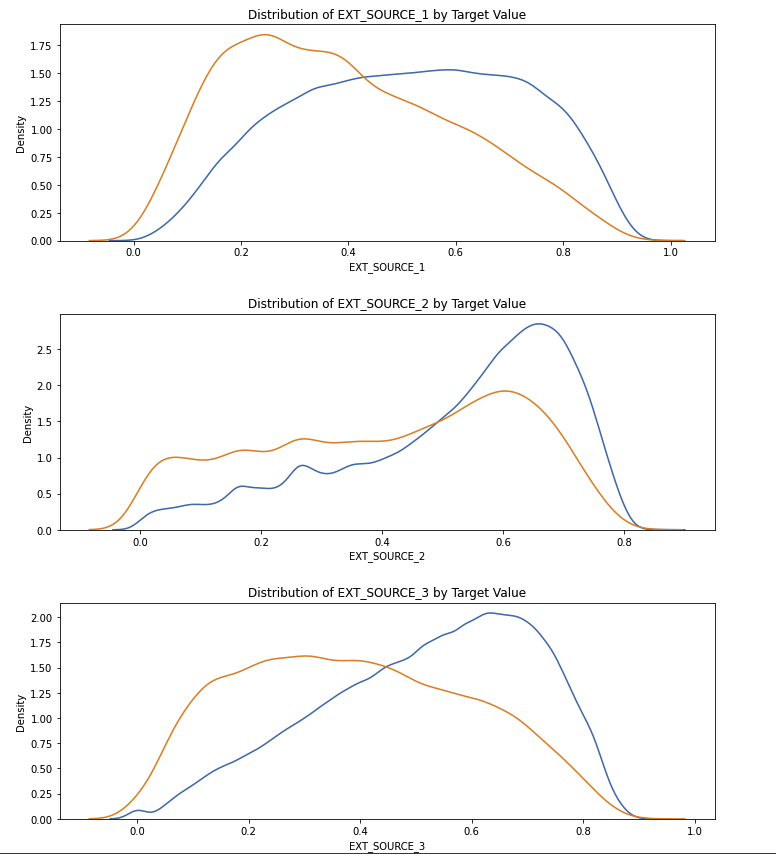
- 3개의 변수 모두 낮은 상관계수를 가지지만,
EXT_SOURCE_3은 어느정도 참고할만한 데이터이다
2.2.3 Pairs plot
EXT_SOURCEvsDAYS_BIRTH
plot_data = ext_data.drop(columns = ['DAYS_BIRTH']).copy()
plot_data['YEARS_BIRTH'] = age_data['YEARS_BIRTH']
plot_data = plot_data.dropna().loc[:100000, "]
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1]
ax = plt.gca()
ax.annotate('r = {:.2f}'.format(r), xy=(.2, .8), xycoords=ax.transAxes, size=20)
grid = sns.PairGrid(data = plot_data, size = 3, diag_sharey = False, hue = 'TARGET',
vars = [x for x in list(plot_data.columns) if x != 'TARGET'])
grid.map_upper(plt.scatter, alpha = 0.2)
grid.map_diag(sns.kdeplot)
grid.map_lower(sns.kdeplot, cmap = plt.cm.OrRd_r)
plt.suptitle('Ext Source and Age Features Pairs Plot', size = 32, y = 1.05)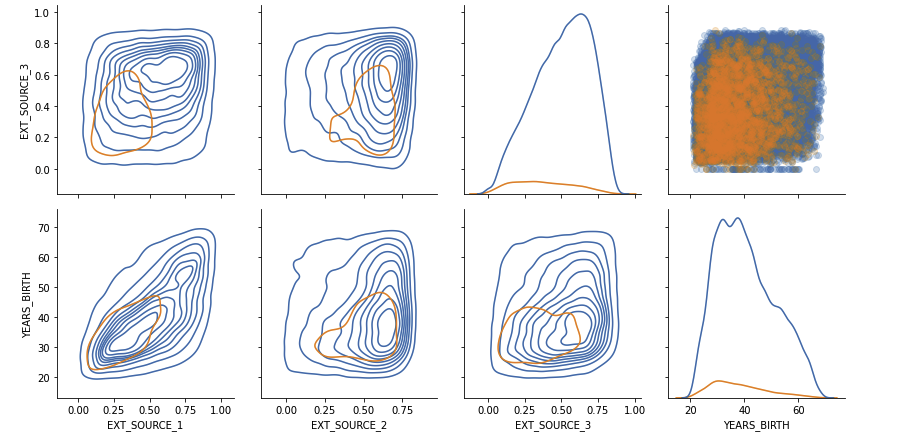
3. Feature Engineering
3.1 Polynomial Features
# polynomial features를 위한 새로운 데이터프레임 생성
poly_features = df_train[['EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3','DAYS_BIRTH','TARGET']]
poly_features_test = df_test[['EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3','DAYS_BIRTH']]
# missing value 핸들링
imputer = SimpleImputer(strategy = 'median')
poly_target = poly_features['TARGET']
poly_features = poly_features.drop(columns = ['TARGET'])
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
poly_transformer = PolynomialFeatures(degree = 3)# polynomial features 트레이닝
poly_transformer.fit(poly_features)
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
print('Polynomial Features shape: ', poly_features.shape)
poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1','EXT_SOURCE_2',
'EXT_SOURCE_3','DAYS_BIRTH'])[:15]
- 새롭게 생성된 polynomial features와 target과의 상관계수 구하기
poly_features = pd.DataFrame(poly_features, columns =
poly_transformer.get_feature_names(['EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3','DAYS_BIRTH']))
poly_features['TARGET'] = poly_target
poly_corrs = poly_features.corr()['TARGET'].sort_values()
print(poly_corrs.head(10))
print(poly_corrs.tail(5))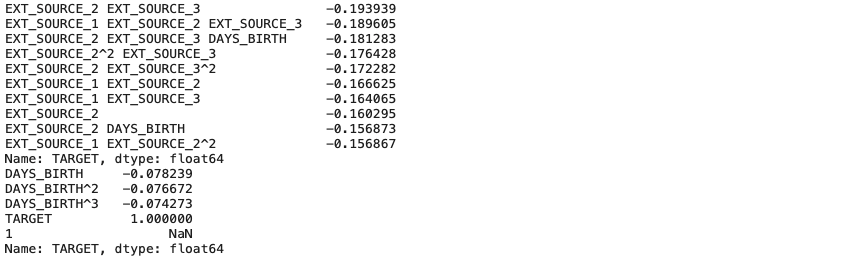
- 몇 가지 feature들은 기존의 feature보다 더 높은 상관계수를 가진다
poly_features_test = pd.DataFrame(poly_features_test, columns = poly_transformer.get_feature_names(
['EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3','DAYS_BIRTH']))
# Polynomial features를 트레이닝 데이터에 합치기
poly_features['SK_ID_CURR'] = df_train['SK_ID_CURR']
df_train_poly = df_train.merge(poly_features, on = 'SK_ID_CURR', how = 'left')
poly_features_test['SK_ID_CURR'] = df_test['SK_ID_CURR']
df_test_poly = df_test.merge(poly_features_test, on = 'SK_ID_CURR', how = 'left')
df_train_poly, df_test_poly = df_train_poly.align(df_test_poly, join = 'inner', axis = 1)
print('Training data with polynomial features shape: ', df_train_poly.shape)
print('Testing data with polynomial features shape: ', df_test_poly.shqpe)
3.2 Domain Knowledge Features
CREDIT_INCOME_PERCENT: 고객 수입과 채권 비율ANNUITY_INCOME_PERCENT: 고객 수입과 연금 비율DAYS_EMPLOYED_PERCENT: 고객 나이와 고용일 비율
df_train_domain = df_train.copy()
df_test_domain = df_test.copy()
df_train_domain['CREDIT_INCOME_PERCENT'] = df_train_domain['AMT_CREDIT'] / df_train_domain['AMT_INCOME_TOTAL']
df_train_domain['ANNUITY_INCOME_PERCENT'] = df_train_domain['AMT_ANNUITY'] / df_train_domain['AMT_INCOME_TOTAL']
df_train_domain['CREDIT_TERM'] = df_train_domain['AMT_ANNUITY'] / df_train_domain['AMT_CREDIT']
df_train_domain['DAYS_EMPLOYED_PERCENT'] = df_train_domain['DAYS_EMPLOYED'] / df_train_domain['DAYS_BIRTH']# Domian features 시각화
plt.figure(figsize = (12, 20))
for i, feature in enumerate(['CREDIT_INCOME_PERCENT', 'ANNUITY_INCOME_PERCENT', 'CREDIT_TERM', 'DAYS_EMPLOYED_PERCENT']):
plt.subplot(4, 1, i + 1)
sns.kdeplot(df_train_domain.loc[df_train_domain['TARGET'] == 0, feature], label = 'target == 0')
sns.kdeplot(df_train_domain.loc[df_train_domain['TARGET'] == 1, feature], label = 'target == 1')
plt.tight_layout(h_pad = 2.5)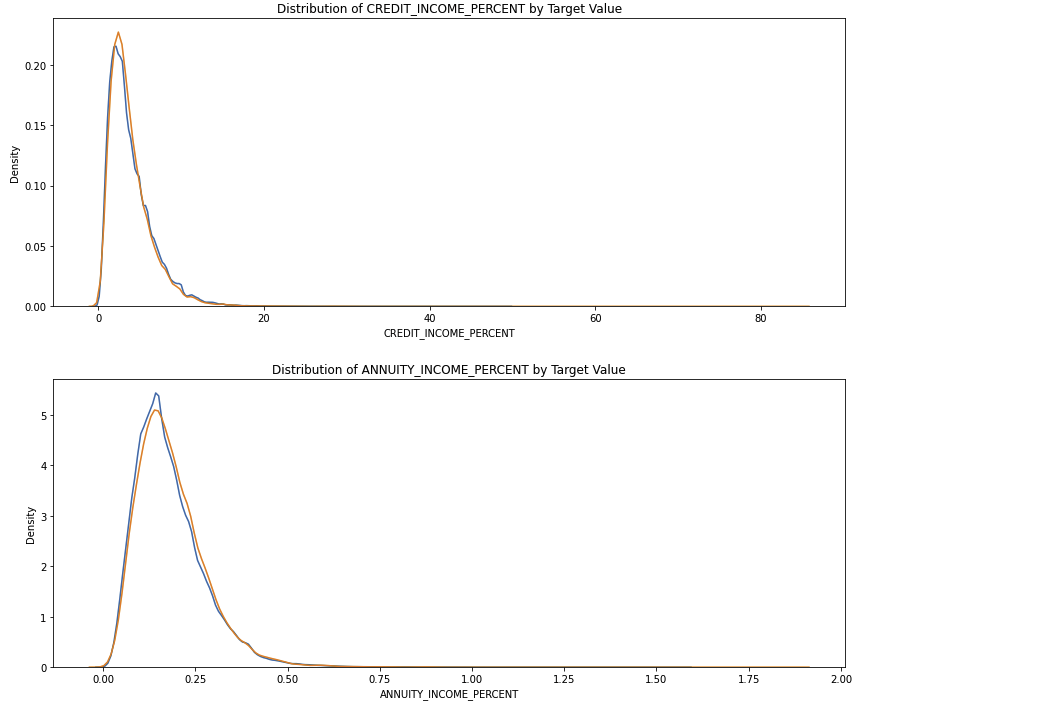
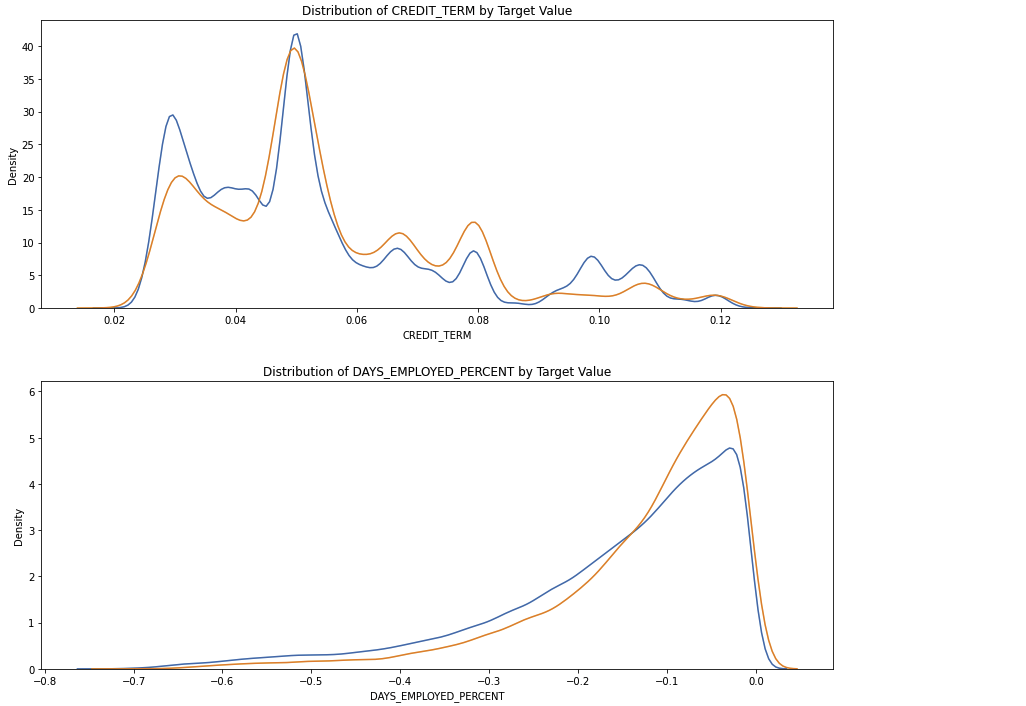
- Domain Feature들은 새로운 직관을 얻어내는 데에 도움이 되지 않았다
4. Building machine learning model and prediction using the trained model
from sklearn.preprocessing import MinMaxScaler
# Training 데이터에서 target 제거
if 'TARGET' in df_train:
train = df_train.drop(columns = ['TARGET'])
else:
train = df_train.copy()
# Feature names
features = list(train.columns)
# Testing 데이터 카피
test = df_test.copy()
# Missing value 모두 평균값으로 대체하기
imputer = SimpleImputer(strategy = 'median')
# 각 feature 모두 0~1로 대체
scaler = MinMaxScaler(feature_range = (0, 1))
# Training 데이터 fitting
imputer.fit(train)
# Training 데이터와 Testing 데이터 변환
train = imputer.transform(train)
test = imputer.transform(df_test)
# Scaler 반복
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Training data shape : ', train.shape)
print('Testing data shape : ', test.shape)
log_reg = LogisticRegression(C = 0.0001)
lot_reg.fit(train, train_labels)predict.proba메소드 이용하여 대출을 상환하지 않을 확률 구하기
log_reg_pred = log_reg.predict_proba(test)[:, 1]- 예측 결과는
sample_submission.csv파일처럼SK_ID_CURR과TARGET칼럼만 있어야 한다
submit = df_test[['SK_ID_CURR']]
submit['TARGET'] = log_reg_pred
submit.head()

데이터 엔지니어로 전향중인 백엔드 개발자입니다