Kaggle
1.Titanic survival rate(Random Forest)
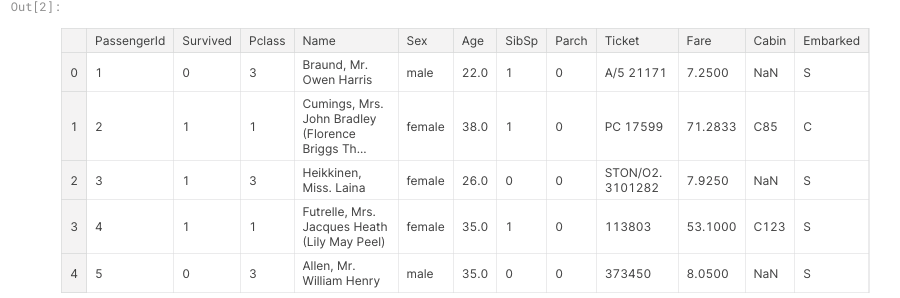
Kaggle Link : https://www.kaggle.com/code/yoontaeklee/titanic-survival-rate-random-forest: 여러 feature들을 개별적으로 분석하고, feature들 간의 상관관계 확인, 여러 시각화 툴
2.Porto Seguro’s Safe Driver Prediction
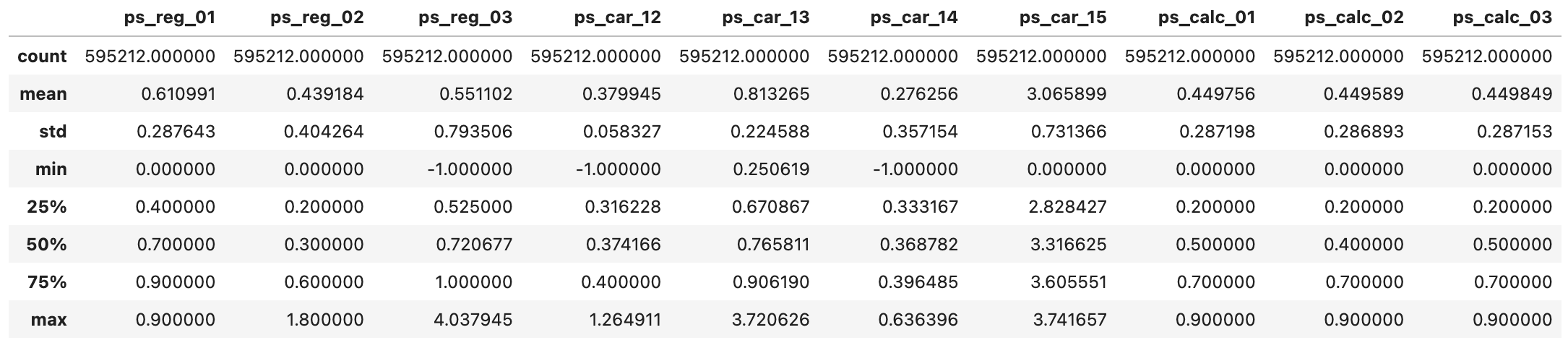
Kaggle Link : https://www.kaggle.com/code/yoontaeklee/porto-seguro-s-safe-driver-prediction 1. 데이터셋 확인 1.1 Null data 확인 Null data 개수 확인 실제 기업 데이터이기
3.3. Home Credit Default Risk

이 코드는 https://www.kaggle.com/code/willkoehrsen/start-here-a-gentle-introduction 을 참고하며 학습하였다 1. 데이터셋 확인 해당 커널에는 9개의 파일이 있다 Training 1, Test 1, 예시 1,
4.Costa Rican Household Poverty Level Prediction - 1. 데이터셋 확인

해당 코드는 https://www.kaggle.com/code/willkoehrsen/a-complete-introduction-and-walkthrough/notebookInteger type이 130개, float type이 8개, object type이
5.Costa Rican Household Poverty Level Prediction - 2. Feature Engineering(1)

전 포스트에 이어, Feature Engineering을 진행하며 머신러닝 모델에 들어갈 데이터를 가공한다가정 레벨과 개인 레벨 변수 나누기개인 레벨의 데이터에서 적당히 합칠 수 있는 변수들 확인순서를 확인할 수 있는 변수는 통계에 사용참/거짓 변수 또한 통합할 수 있
6.SpaceX Falcon9 First Stage Landing Prediction
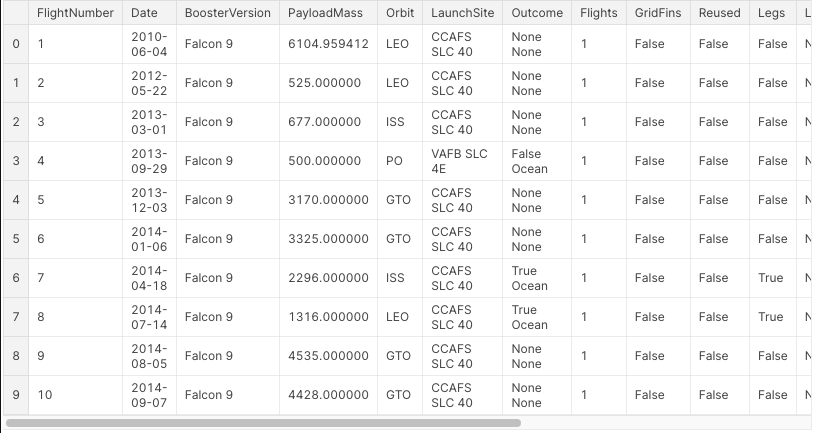
Kaggle Link : https://www.kaggle.com/code/yoontaeklee/spacex-falcon-9-firsts-stage-landing-prediction데이터셋 확인 (null data)EDA (Exploratory Data Ana
7.Costa Rican Household Poverty Level Prediction - 3. Individual Level Variables
Individual level variable에는 2가지 종류가 있다참/거짓을 나타내는 Boolean값순서를 나타내는 값필요 없는 변수들을 제거하기 위해 상관계수 절댓값이 0.95가 넘어가는 것만 남기도록 한다female 상관계수가 굉장히 높으므로 그 반대인 male
8.Anomaly Detection in Credit Card Transactions

https://www.kaggle.com/code/yoontaeklee/credit-card-fraud-detection통계나 데이터 분석에서, outlier는 대다수의 데이터에서 벗어난 데이터를 말한다. 이는 해당 데이터가 다른 데이터와는 다른 메커니즘으로