1. pruning 후 연산 문제
- Unstructured pruning의 경우 파라미터 값을
0으로 바꾸는 형식이다. - 이러한 방식으로는 곧바로 구조가 바뀌거나 해당 파라미터에 대한 계산이 사라진 것은 아니기 때문에 계산 속도가 빨라지지는 않는다.
- 왜냐하면 여전히 0을
저장하고 있고 (space) - 또한 여전히
0을 곱하고 있기 때문이다.(time)
- 그래서 해결책은?
딥러닝의 계산량 대부분은 행렬 연산이 차지하므로
- Sparsity가 심한경우
Sparse Matrix Representation
행렬에서 0이 아닌 값들의 좌표들을 기억하는 것
메모리 및 연산 효율을 높일 수 있음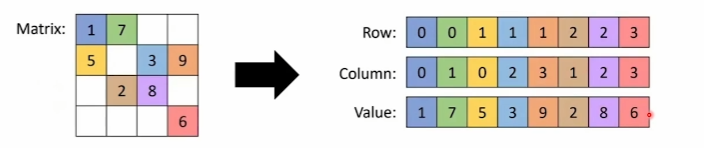

굉장히 희소한 경우가 아니라면 이걸로 메모리 연산 이득을 보기는 어렵다..!
- 왜냐하면 여전히 0을
- Sparsity가 적당한 경우
전용 하드웨어 사용
곱셈 수행 전, 스캔을 통해 0의 위치를 파악(overhead 약간 발생)
해당 위치를 건너 뛰고 계산되도록 조정
2. pruning 적용 효과에 대한 분석법 이해
- Sensitivity Analysis
-
Pruning Ratio
-
파라미터의 몇 %를 제거할 것인지 비율
-
Local
레이어별로 동일하게 일정 비율을 제거 -
동일한 비율이라서 Uniform Shrink이라고도 함
-
-
더 좋은 방법은?
레이어별로 비율을 다르게 설정해보자
-
-
네트워크가 복잡하거나 / 층별 특성이 상이한 모델의 경우
각 레이어의 특성을 반영하여- 민감도가 높은 부분은 덜 pruning
- 낮은 부분은 더 pruning
-
각 레이어의 pruning 비율을 설정하는 중요도를 측정하는 개념의 방법. (Global pruning의 일종)
- 실험을 통해 측정하는 empirical, practical한방법
-
Sensitivity(민감도)를 측정
- 파라미터/레이어의 민감도
해당 파라미터/레이어를 pruning 했을 때의 성능 저하 정도 측정
- 파라미터/레이어의 민감도
-
일반적으로는
가장 앞 부분 레이어가 민감- 비유: 인식/감각 기관에 해당하기 때문
-
뒷 부분 레이어는 덜 민감
-
비유: 최종 판단을 내릴 때엔 그만큼의 연산량이 필요 없다.
-
한 레이어를 고르고
-
해당 레이어의 파라미터를 일정 비율만큼 prune 후 fine-tuning
-
이를 레이어별로 또는 비율별로 성능을 측정
-
성능 저하 허용 범휘 T(%)를 고정하고
그것을 기준으로 레이어별로 prune할 비율을 설정
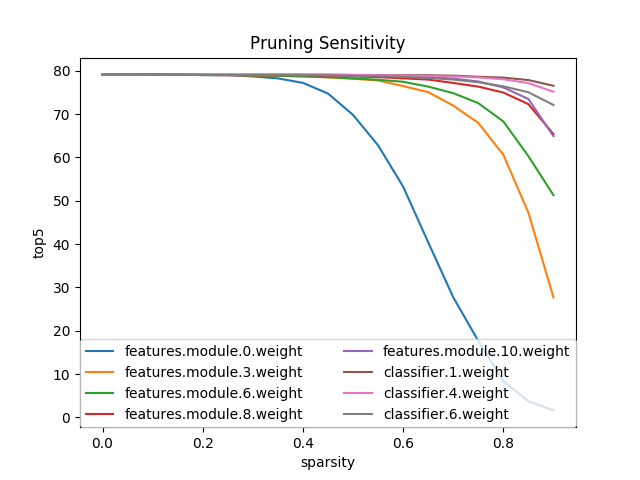
출처: https://intellabs.github.io/distiller/pruning.html레이어별로, 비율 별로 각각 측정해야하고
측정 한번에 pruning 전체 과정 1번 만큼의 iteration이 소요됨.
즉, 오래 걸리는 작업이기 때문에 주로 분석용으로 사용한다.
다만, 모델 구조가 같고 데이터만 다른 경우, 한번 계산해둔 비율은 재사용이 어느정도 가능하다.
-
-
3. 분야별 pruning을 잘 적용하는 방법
Pruning in CNNs
어디서 가지치기를 해야할까요?
-
보통의 CNN모델은 CNN부분과 FC 부분으로 나눠진다,
- FC
Fully-connected, 일반적인 신경망 구조
- FC
-
대부분의 파라미터는 FC부분에 있음
-
그러나 연산 속도의 bottleneck은 CNN부분에 있음
-
따라서 공간과 시간의 효율을 모두 챙기려면 각각 pruning이 필요하다.
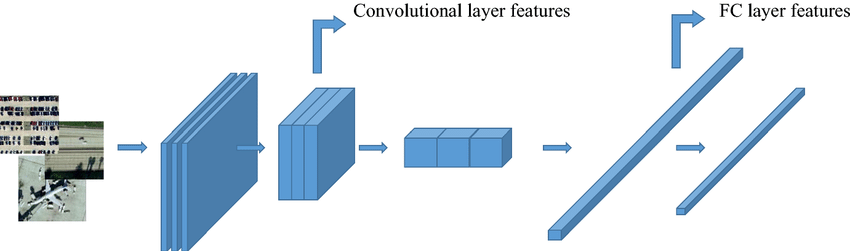
출처: https://www.researchgate.net/figure/Deep-features-from-the-convolutional-layer-and-FC-layer-of-CNN_fig1_350935646 -
CNN FIlters
- CNN은 이미지에 적용할 적절한 filter를 학습함
- Filter란?
코 모양, 입 모양, 얼굴 윤곽 같은 이미지의 단위
이 filter가 이미지의 어느 위치에 있는지를 찾고
그 정보들을 조합하여 이미지를 분류할 수 있게 됨
좋은 filter들을 학습해 내는 것이 CNN의 목표
- Filter란?
- 실제의 filter 한장은 행렬 한개
- CNN은 이미지에 적용할 적절한 filter를 학습함
-
레이어 별로 각각 여러 개의 filter가 있음
- 보통 앞쪽 레이어는 디테일을
- 뒤쪽 레이어는 전체적인 구조를 파악하는 경향이 있음
-
Filter Pruning
이 중 중요도가 작은 filter를 제거하는 것이 CNN의 pruning- Structured한 방법, 속도를 그 즉시 향상시킴
- Unstructured는 sparse convolution 연산 구현이 필요
- sparse한 filter를 우선적으로 제거 (sparsity가 높은 순으로)
- Structured한 방법, 속도를 그 즉시 향상시킴
-
한 레이어에 있는 실제 filter들의 모습을 보면
절반 정도는 sparse하거나 거의 0에 가까운 값들로 이루어진다.

출처: https://arxiv.org/pdf/1608.08710 -
Sparse 한 filter를 제거하는 것이 정말 좋은 기준이 되는가? => Sensitivity analysis 해봐라!
- Sparse한 filter의 비율이 높은 레이어의 경우 pruning을 많이 해도 성능 저하가 덜하다.
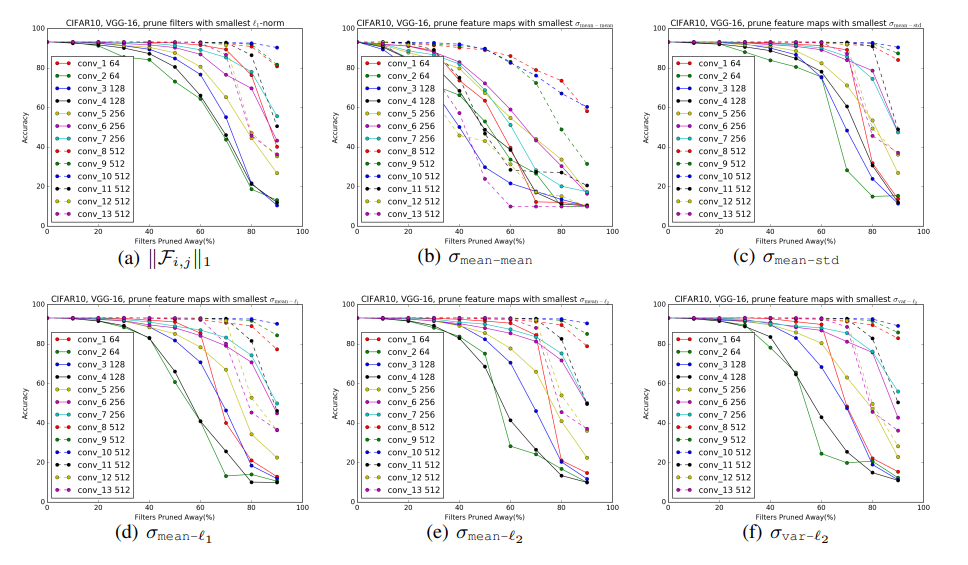
- Sparse한 filter의 비율이 높은 레이어의 경우 pruning을 많이 해도 성능 저하가 덜하다.
-
Sensitivity analysis에 따르면
- 뒤쪽 레이어는 덜 민감하고
- 일부 레이어는 90%이상 삭제대호 문제가 없엇다.
- 큰 형태는 다양성이 비교적 적기 때문에..
- 반면, 앞쪽 레이어는 너무 많이 제거하면 모델이 이미지 자체를 파악할 수 없게 되어 버리는데, 이는 작은 형태는 다양성이 크기 때문이라고 볼 수 있다.
- 따라서 CNN을 pruning 할 때에는
전체 제거 비율을 레이어 별로 나눠서 분배하는 것이 중요하다.
요약
CNN 같은 경우의 가지치기 방법은
CNN 파트와 FC 파트 나눠서 진행하고
그 구조는 Structured Pruning이 맞고
레이어 별 filter 단위로 prune한다.그리고 prune할 대상을 정하는
Scoring의 경우 Filter의 sparsity를 중요도로 사용하고 Practical 하게는 L2-norm을 사용한다.
또한 레이어 별로 비율을 다르게 설정한다.
pruning in BERT
LLM 시대 직전에 있었던 다용도 언어 모델
BERT-base는 12개의 transformer layer로 이루어져 있음
-
어떻게 Pruning 할것인가?
-
Layers of BERT
언어모델도 보통은- 앞쪽 레이어: 작은 형태(단어 등)
- 뒤쪽 레이어: 큰 형태 (문장 등)
-
그러나 레이어 별로 sparsity가 비일관적이다.
- sparsity가 낮아졌다 높아졌다 하는 특이 패턴을 보인다.
- 따라서 Global Pruning은 그 자체로 부적합하고
- Structured Pruning도 위험하다. 왜냐하면 레이어 별 역할이 명확할 것으로 예상되기 때문이다.
- 그러나 여전히... 대부분의 파라미터가 0에 가깝다.
따라서 절대값 기준 pruning이 유효하다.
First Layer
단어 모음인 vocabulary
- 벡터의 모음 = 행렬
- 실제로는 이 vocabulary가 첫번째 레이어를 담당하고
-정확히는, 이에 대응하는 embedding matrix- 특징: 짧은 단어일수록 벡터가 더 sparse 하다.
- Local Pruning을 하면, 짧은 단어 위주로 pruning을 하기 때문에 유효
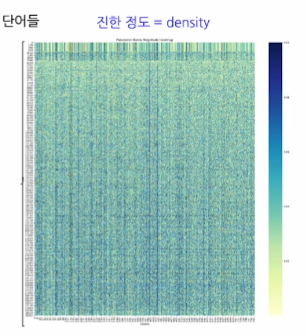
- Pruning Result
- 파란선 (일반 pruning) 기준
- 30% 가량의 파라미터는 완전 제거 가능
- 파라미터가 처음부터 너무 많았다는 이야기..
- 60% 가량 제거해도 성능 저하가 크지 않음
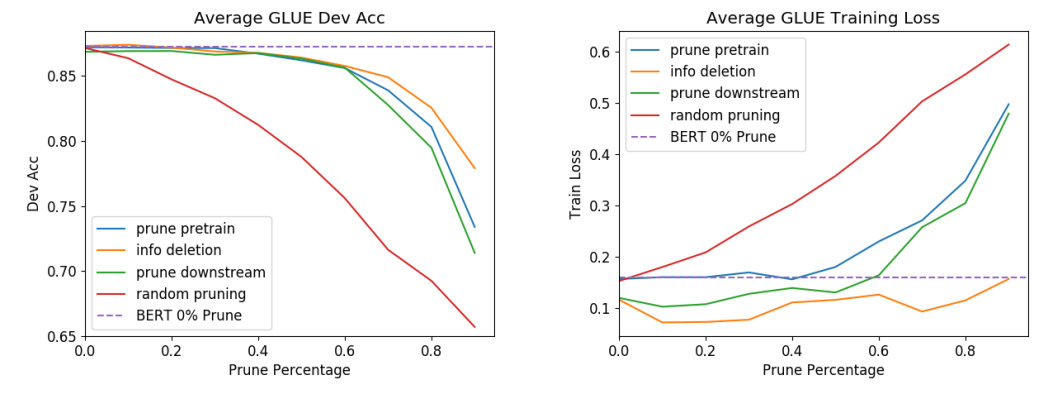
출처: Gordon, Mitchell A., Kevin Duh, and Nicholas Andrews. 'Compressing bert: Studying the effects of weight pruning on transfer learning.' arXiv preprint arXiv:2002.08307 (2020)
BERT Pruning Summary
- Structure
- Unstructured Pruning
- Scoring
- 레이어별로 진행하는 Local Pruning
- 절댓밗을 기준으로 파라미터를 제거
4. PyTorch 실습
- 데이터
- 입력: x,y 좌표
- 출력: 클래스 (0혹은 1)
- train data 1000개, test data 100개 준비
- 모델
- 2-layer MLP
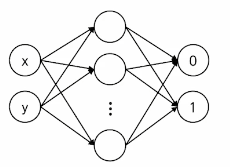
- 2-layer MLP
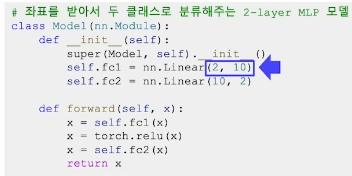
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(2, 10)
self.fc2 = nn.Linear(10, 2)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x- 목표
- 첫번째 레이어를 50% 줄이자!
- 중간 레이어 노드 수가 10개나 된다..!
- 이 데이터에는 너무 큰 편..!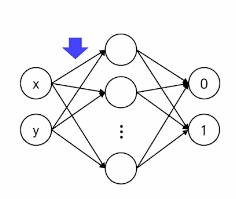
- 첫번째 레이어를 50% 줄이자!
-
기본 모델
- 학습 진행
# 모델 인스턴스 생성 및 학습 torch.manual_seed(42) model = Model() train(model, train_data, device)- 기본 모델의 테스트 성능
# 성능 평가 test(model, test_data, device) # Accuracy: 91%- 모델 전체에서 0이 아닌 파라미터의 비율
# 전체 파라미터 수 total_params = sum(p.numel() for p in model.parameters()) # 0이 아닌 파라미터의 수 total_params_nz = sum((p != 0.0).sum() for p in model.parameters()) # 0이 아닌 파라미터의 비율 print(f"non-ziro portion: (100*total_params_nz / total_params: 6.02f)%")
Random pruning
-
torch 내장 라이브러리 사용
-
`import torch.nn.utils.prune as prune
-
랜덤하게 첫번째 레이어에서 50%를 제거 (prune.random_unstructured 함수)
layer = model.fc1 layer.weighttorch.manual_seed(42) prune.random_unstructured(layer, name='weight', amount =0.5) # 제거된 (0으로 바뀐) 파라미터 확인 layer.weight

- Pruning 직후에는 성능이 크게 감소하고
- 추가 Fine-tuning을 진행하면 회복됨

- 제거한 파라미터 수 측정
# 0이 아닌 파라미터의 비율
total_params = sum(p.numel() for p in model.parameters())
total_params_nz = sum((p != 0.0).sum() for p in model.parameters())
print(f"non-zero portion: (100*total_params_nz / total_params: 5.02f)%")
- fc1: 2x10 + 10(weight & bias) = 30개
- fc2: 10x2 + 2(weight & bias) = 22개
- 총 30 + 22 = 52 개
- fc1.weight에서 10개 제거 -> 총 42개
- 42/52 = 80.77 %그렇다면 랜덤하게 50%가 아니라, 파라미터 절대값이 작은 순으로 50%를 제거한다면?
- Magnitude Pruning
Magnitude Pruning
- prune.l1_unstructured 함수
layer = model.fc1
prune.l1_unstructured(layer, name='weight', amount = 0.5)
- 추가 파인튜닝 진행시에 기존 모델보다 성능이 향상해버림..!
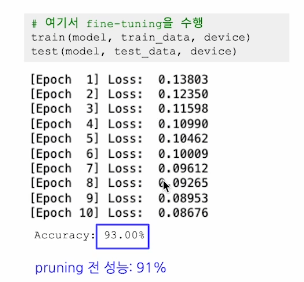
- 이유? overfitting을 방지하는 역할도 해버림
- 이번에는 첫번째 레이어만이 아니라, 두번째 레이어에서 pruning 시도
layer=model.fc2
prune.l1_unstructured(layer, name='weight', amount = 0.5)
amount를 바꿔가며 변경할 수도 있다.
| Pruning 대상 | Pruning 방식 | Pruning 비율 | 학습 상태 | 성능 | 파라미터 압축률 |
|---|---|---|---|---|---|
| 기본 모델 | 학습 완료 | 91% | 100% | ||
| 레이어 1 | random | 50% | pruning 직후 | 72% | 80.77% |
| + fine-tuning 이후 | 90% | 80.77% | |||
| 레이어 1 | magnitude | 50% | pruning 직후 | 93% | 80.77% |
| + fine-tuning 이후 | 93% | 80.77% | |||
| 레이어 2 | magnitude | 50% | pruning 직후 | 82% | 80.77% |
| + fine-tuning 이후 | 92% | 80.77% | |||
| 레이어 1 | magnitude | 80% | pruning 직후 | 76% | 69.23% |
| + fine-tuning 이후 | 84% | 69.23% |
5. 정리
- Advanced Concepts
- Matrix Sparsity
얼마나 0이 많은지 지표 - Sensitivity Analysis
레이어 별/비율 별 pruning에 따른 성능 영향 측정, 레이어 별 최적 비율 설정
- Matrix Sparsity
- Pruning in Practice
- Pruning in CNNs
- Filter 자체를 제거하는 Structured Pruning 기법이 필요
- 뒤쪽 레이어 위주로 pruning 진행
- Pruning in BERT
- Unstructured & Local Pruning으로 충분
- BERT처럼 좋은 모델도 30%가량 파라미터 제거 가능하다.
- Pruning in CNNs
