1. 지식증류(KD)에 대하여
-
고성능 Teacher 모델로부터 지식전달을 받아 Student 모델을 학습시키는 기법
- 경량화의 한 종류로써 성능 저하를 최소화하면서 모델을 압축하는 하나의 방법이다.
작고 가벼운 학생 모델을 쓴다.
- 경량화의 한 종류로써 성능 저하를 최소화하면서 모델을 압축하는 하나의 방법이다.
-
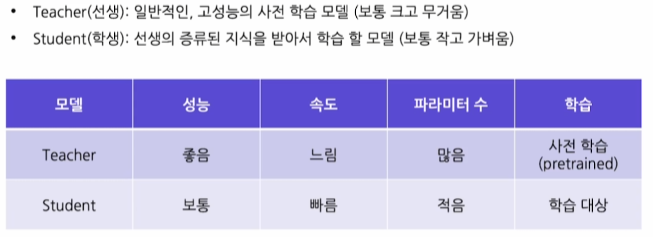
knowlegd: 증류할 지식의 종류에 대한 분류
- Response-based
- Logit-based
Teacher의 Logit 값을 사용 - Output-based
Teacher의 output을 사용
- Logit-based
- Feature-based
Teacher의 중간 레이어의 feature/representation을 사용
- Response-based
-
Transparency
모델 내부 구조/파라미터 열람 가능 여부에 따른 분류-
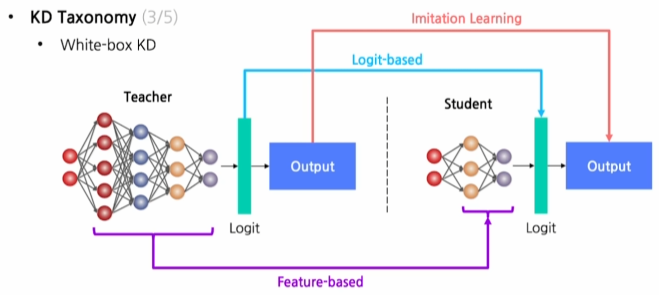
White-box
Teacher의 내부 구조, 파라미터들을 알 수 있는 경우
-
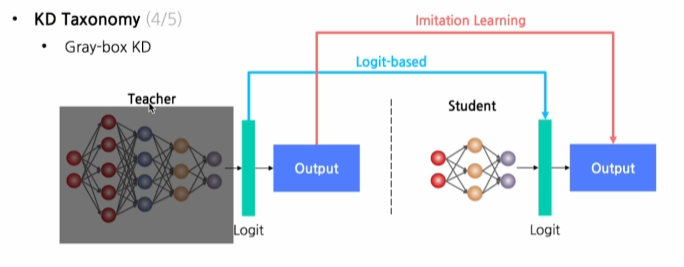
Gray-box
Teacher의 output 및 최종 Logit값 / 제한된 정보를 알 수 있는 경우
-
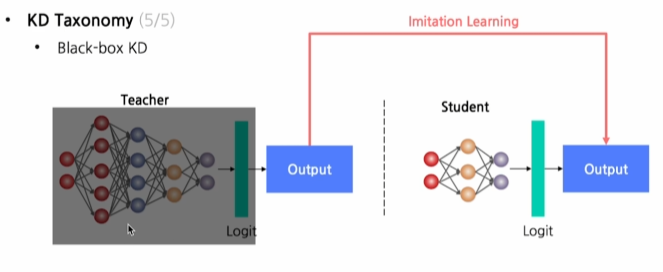
Black-box
Teacher의 output만 알 수 있는 경우
-

Logit-based KD를 가장 많이 여태 사용했음.
2. Logit- based KD
- Intuition
정답 학습과 더불어 세부적인 선택지 간의 차이와 의미를 이해하도록 함- Teacher: 교수
- Student: 학생
- 선택지 간의 차이 - Logit 값, Softmax 확률 분포
- Logit 값 안에는 정답 외에도 선택지 간의 상대적 가능성 및 유사도 정보가 들어 있음
- Logit-based KD란?
- Teacher 모델의 Logit 값을 지식으로 활용한 KD 방법
- Logit이란?
- 넓은 의미로는
Unnormalized prediction value이고 - 좁은 의미로는
Softmax 함수를 씌우면 클래스 확률값이 되는 것들을 의미한다.
- 넓은 의미로는
- 사용할 Teacher의 지식
- Logit으로 계산된 클래스 확률값
- 클래스 간의 유사도 정보가 간접적으로 있기 때문
- Teacher는 데이터를 학습하면서 클래스 간 유사도를 자연스럽게 파악함
- 이 정보가 유용한 지식이라는 가정
- Student의 학습
- 일반적인 분류기 학습
- 추가적으로, Teacher의 지식을 학습
- Teacher의 지식 = 출력의 확률 분포
- 따라서 Student는 자신의 클래스 예측이 선생의 클래스 예측이 유사해지도록 추가 학습을 진행
- 이 과정이 바로 지식 전달
- 용어
- Hard Label: 정답 클래스
- Soft Label: 클래스별 확률
- 학습
- Teacher 모델은 Hard로 학습
- Student 모델은 Hard, Soft로 학습
- Soft는 Teacher 모델의 Logit
- Soft 학습
- 확률 분포가 비슷해지도록
- Teacher의 학습
분류 문제를Cross-entropy Loss로 사전에 학습 (Hard Label)
이후 클래스 확률값 (Softmax 결과값)을 지식으로 전달 - Student
분류 문제를 푸는Cross-entropy Loss에 더해 (Hard Label)
Student의 확률 값을 Teacher의 확률값으로 모사하는KL-divergence Loss를 추가 (Soft Label)
확률값(분포)이 비슷한 정도:KL-divergence를 일반적으로 사용

- Temperature에 대하여
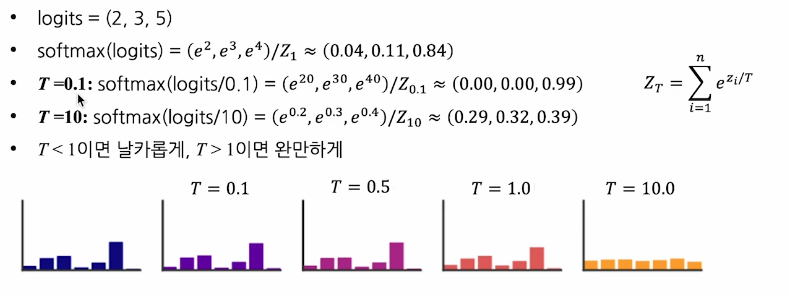
모든 클래스에 대한 Logit을 동일한 Temperature로 나눈 후에 Softmax를 적용- 확률분포를 보다 날카롭게/완만하게 변형할 수 있다.
- 적절한 값이 KD에 크게 도움이 되는 것으로 알려짐
- T < 1 이면 날카롭게
T > 1 이면 완만하게 해준다.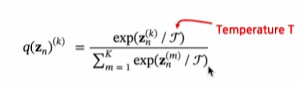
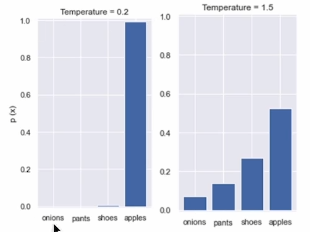
- 확률분포를 보다 날카롭게/완만하게 변형할 수 있다.
우측에 있는 그림이 보다 학습에 좋은 데이터일 것이다(정보가 많음: 유사도 등)
- 그래서 Logit-based가 뭐가좋나요?
- 성능 향상에 효과가 있다.
Label smoothing의 일종
- 오답에도 약가느이 점수를 받는 방식
- robustness가 증가해서 generalization 능력이 향상됨
- soft label은 오답의 가중치가 각기 다른 label smoothing 방법 (더 좋음)
- Continuous distribution
Entropy가 더 높음 (더 어려운 문제를 제공)- Intra-class variance
고양이 내에서도 다양한 인스턴스가 존재- Inter-class variance
(개, 고양이)가 (개, 소)보다 유사
3. Logit-based KD 실습
- Teacher 모델
class Teacher(nn.Module):
def __init__(self, num_classes=10):
super(Teacher, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(2048, 512),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
- Student 모델
class Student(nn.Module):
def __init__(self, num_classes=10):
super(Student, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 16, kernel_size=3, padding=1),
mm.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classfier = nn.Sequential(
nn.Linear(1024, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn,Linear(256, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
returen x- 모델 크기 비교
Teacher와 Student 모델을 비교한다
total_params_teacher = sum(p.numel() for p in teacher.parameters())
total_params_student = sum(p.numel() for p in student.parameters())- Teacher 모델의 학습
Cross-entropy를 사용
Cross-entropyLoss함수: Logit 값들과 정답 번호를 주면 softmax를 사용해서 loss를 계산
def train(model, train_loader, epochs, learning_rate, device):
ce_losser = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr-learning_rate)
model.train()
for epoch in range(epochs):
running_loss = 0.0
for inputs, labels in iter(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
logits = model(inputs)
loss = ce_losser(input=logits, target=labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
.item이 메서드는 텐서에 포함된 단일 값을 Python의 기본 데이터 타입(보통은 float)으로 반환해줌.
loss가tensor(1.2039, grad_fn=<NllLossBackward0>)라는 텐서 객체일 때 loss.item()을 호출하면 단순히 1.2039722204208374라는 float 값이 반환됨.
이를 통해 손실 값을 보다 쉽게 읽고 사용할 수 있다는 이점이 있음
- 성능 테스트
Teacher, Student 공용
테스트 데이터에서 inference를 수행, 가장 logit이 높은 클래스 번호를 정답으로 제출하고 채점
def test(model, test_loader, device):
model.to(device)
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in iter(test_loader):
inputs = inputs.to(device)
labels = labels.to(device)
logits = model(inputs)
_, prediected = torch.max(logits,data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / toal
return accuracy- KL-Divergence loss 적용 전 Student 모델 성능
torch.manual_seed(42)
student = Student(num_classes=10).to(device)
train_loader, test_loader = get_dataloaders()
train(student, train_loader, epochs = 10, learning_rate = 0.001, device=device)
test_accuracy_student = test(student, test_loader, device)Test: 정확도 => 70.02%
-
KL-Divergence loss 적용
- KL-Divergence loss는 KLDivLoss 함수 사용
kl_losser = nn.KLDivLoss(reduction='batchmean', log_target=True)- 선생과 학생의 클래스 확률값을 구하고
KL-Divergence를 계산
with torch.no_grad(): teacher_logits = teacher(inputs) student_logits = student(inputs) teatcher_log_prob = nn.functional.log_softmax(teacher_logits / T, dim = -1) student_log_prob = nn.functional.log_softmax(student_logits / T, dim = -1) soft_loss = kl_losser(input=student_log_prob, target=teacher_log_prob)- Logit-based KD 구현 세부
CE와KL loss를 합쳐서 최종 loss 반환
합치는 비율은 하이퍼파라미터로 조정
hard_loss = ce_losser(input=student_logits, target=labels) loss = soft_loss_weight * soft_loss + hard_loss_weight * hard_loss -
KD 학습
T = 2 사용, KL:CE 비율은 1:3 사용
torch.manual_seed(42)
student_new = Student(num_classes=10).to(device)
train_loader, test_loader = get_dataloaders()train_kd(
teacher=teacher,
student=student_new,
train_loader=train_loader,
epochs=10,
learningj_rate=0.001,
T=2,
soft_loss_weight=0.25,
hard_loss_weight=0.75,
device=device,
)
하이퍼 파라미터를 조정하면 더 좋은 성능 향상이 있을 것.
요약
- Knowledge Distillation
- 고성능
Teacher 모델로부터 지식전달을 받아Student 모델을 학습시키는 경량화 기법이다.- knowlege
- Response_based
Logit-base, Imitation Learning- Feature-based
- Transparency
- White-box, Gray-box, Black-box
- Logit-base KD
- Hard Label, Soft Label, Temperature

헤매는 만큼 자기 땅이다.