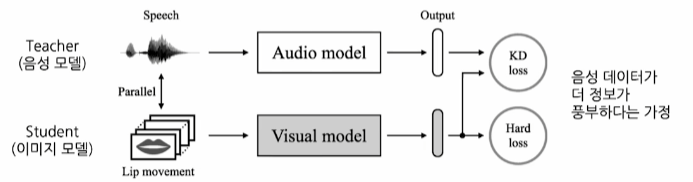
1. Distillation: Feature-based
-
white-box 에서 사용할 수 있는 지식증류 기법이다.
-
Teacher 모델의 레이어 특질값(Featrue)를 사용한다.
중간 계산 결과, 혹은 추론과정이라고도 해석 가능
- 레이어 크기가 달라도 중간 결과는 비슷하도록!
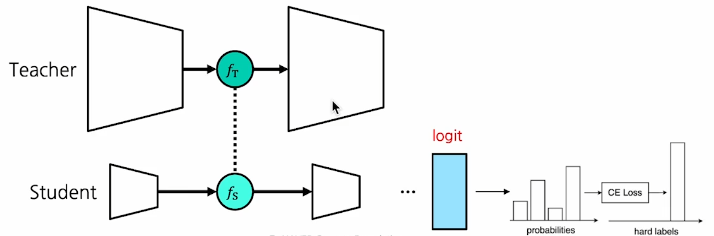
- Logit-base:
KL Loss추가 - Featrue-based:
MSE Loss추가

-
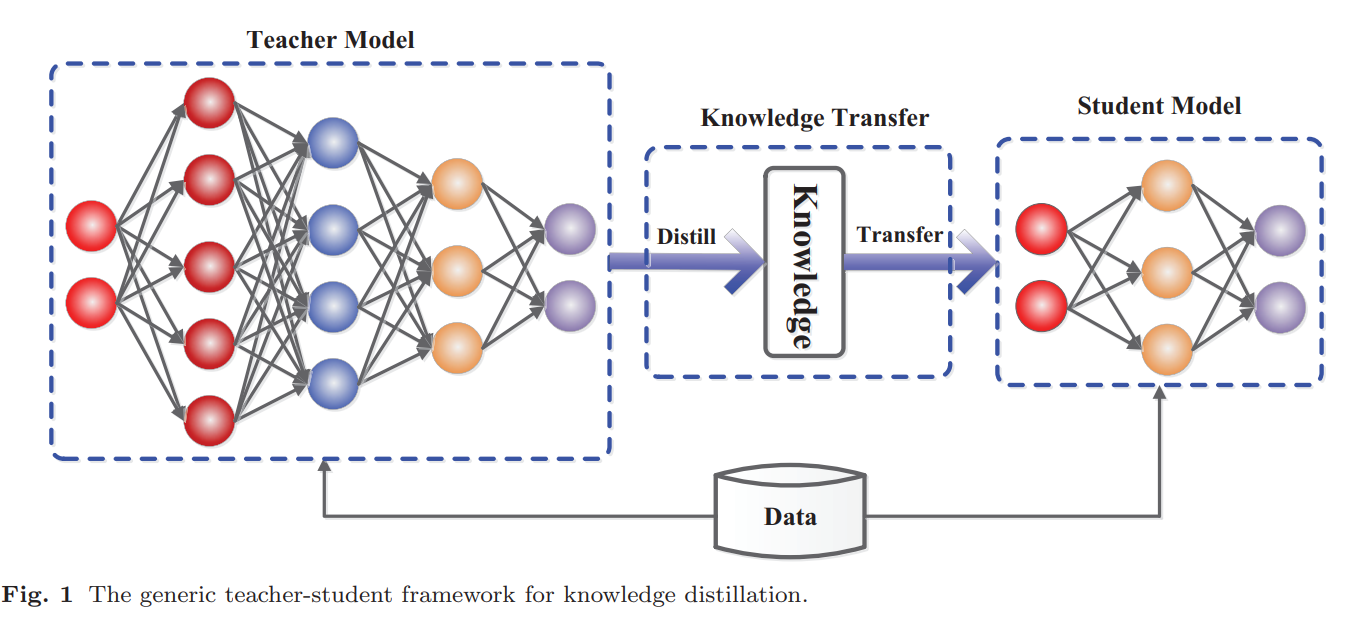
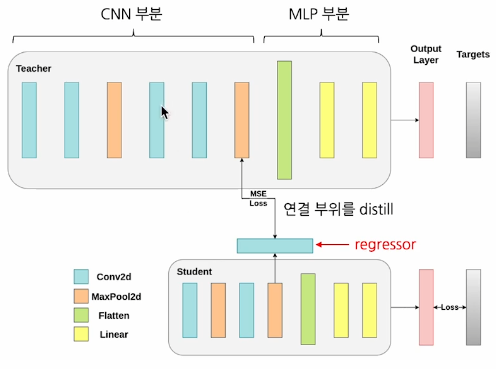
Feature-based KD를 위해서는 Teacher의 중간레이어와 Student의 중간레이어를 맞춰주는 과정이 필요하다
- 두 Feature는 차원이 다를 수 있기 때문에(구조가 다르므로 D
t와 Ds가 다르다)
Student가regressor Layer인 R을 사용하게 된다.
이는 smooth하게 차원을 맞춰주는 레이어로써 다음 그림에서 점선의 역할을 하게된다.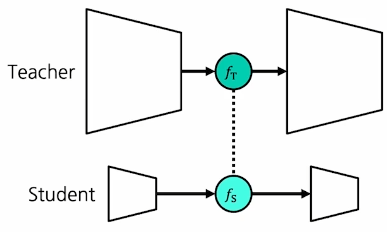

해당 Loss를 추가하면 자연스럽게 ft와 fs가 비슷해질 것이다가 주요한 논리
- 두 Feature는 차원이 다를 수 있기 때문에(구조가 다르므로 D
-
그렇다면 어떤 Feature들을 전달해줄 것인가?
일반적으로 중간레이어에서 추출한 (1~10레이어가 있다면 3,4번째 레이어 feature를 추출) 레이어를 사용하여 지식증류에 사용함.- 왜 그러한가?
3,4번째 레이어는 다양한 수준의 정보가 포함되어 있다.- 초기 레이어는 주로 저수준 특징(엣지, 텍스쳐 등)을
- 후반 레이어는 고수준 특징(클래스 수준 정보)을 표현
- 중간 레이어는 이 둘의 중간, distillation의 효과가 극대화되는 정보가 포함된다.
- 의미 있는 표현:
이 feature map은 최종 결과에 직접적으로 영향을 미치며, Student이 중요한 표현을 학습할 수 있다.
- 왜 그러한가?
-
그렇다면 다른 선택지는 없는가?
- 초기 레이어
저수준읭 정보를 학습하며 일반적으로 특정한 데이터에 덜 특화되어 있기에 distillation의 효율이 낮다. - 최종 레이어
최종 레이어의 출력은 손실함수와 직접 연결되어 지나치게 고수준의 정보를 가지고 있다.- Logit-based KD와 큰 차이를 보지 못한다.
둘은 거의 유사한 정보를 담고 있기 때문이다.
따라서 중간 레이어가 가진 중간 정도 수준의 정보가 딱 적당하다
- Logit-based KD와 큰 차이를 보지 못한다.
- Student는 원래 task와 feature를 동시에 학습
- 초기 레이어
Feature-based KD 구현 과제
- 베이스
이미지를 분류하는 CNN 모델 - CNN 모델은 대부분 CNN 부분과 MLP 부분으로 나눠져 있음
- CNN 부분의 결과에서 MLP 부분으로 갈 때 계산된 fature를 distill 하는 것이 목표
- 이 feature가 일반적으로이미지 벡터로 해석됨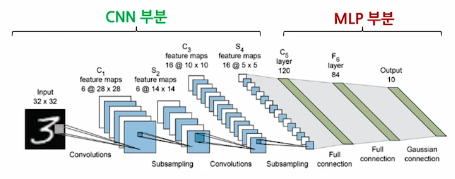


CNN 구조와 채널의 변화: 이미지 특징 추출 과정
1. 전체 신경망 구조
이 신경망은 CNN(Convolutional Neural Network)과 MLP(Multi-Layer Perceptron)를 결합한 구조로써
크게 특징 추출을 담당하는 CNN 부분과 분류를 담당하는 MLP 부분으로 구성된다.class Teacher(nn.Module): def __init__(self, num_classes=10): super(Teacher, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 128, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(128, 64, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(64, 32, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2), ) self.classifier = nn.Sequential( nn.Linear(2048, 512), nn.ReLU(), nn.Dropout(0.1), nn.Linear(512, num_classes) )2. CNN의 핵심 구성 요소
2.1 Conv2d (합성곱 레이어)
- 2차원 합성곱 연산을 수행하는 레이어
- 주요 매개변수:
- 입력 채널 수
- 출력 채널 수
- kernel_size: 필터 크기 (3x3 사용)
- padding: 입력 주변 패딩 크기 (1로 설정)
2.2 ReLU (활성화 함수)
- Rectified Linear Unit의 약자
- 동작 방식:
- 음수 입력 → 0 출력
- 양수 입력 → 입력값 그대로 출력
- 네트워크에 비선형성을 추가하여 표현력 향상
2.3 MaxPool2d (풀링 레이어)
- 특징 맵의 크기를 줄이는 다운샘플링 수행
- 설정:
- kernel_size=2: 2x2 영역 검사
- stride=2: 2칸씩 이동
- 특징을 압축하고 계산량을 줄이면서 주요 특징 보존
3. 채널의 변화 과정
3.1 RGB에서 시작 (3채널)
- 입력 이미지는 RGB 3개 채널로 시작
- 각 픽셀은 3가지 기본 색상 정보만 포함
- 가장 기초적인 시각 정보 표현 단계
3.2 특징 확장의 단계 (3 → 128채널)
- 다양한 특징을 감지할 수 있도록 확장
- 감지 가능한 특징들:
- 다양한 방향의 엣지
- 여러 종류의 텍스처 패턴
- 색상의 미세한 변화
- 기본적인 형태들
- 이미지를 128개의 서로 다른 관점에서 분석
3.3 정보의 압축과 정제 (128 → 64채널)
- 감지된 특징들 중 중요한 정보 선별
- 덜 중요한 정보는 제거
- 더 추상적이고 고차원적인 특징으로 변환
3.4 특징 재조정 단계 (64 → 64채널)
- 같은 채널 수를 유지하며 특징을 재가공
- 이 단계의 중요성:
- 특징 재조정: 채널 수는 유지하되 각 채널의 정보를 더 정교하게 가공
- 수용 영역 확장: 3x3 커널을 한번 더 사용하여 더 넓은 영역의 정보 통합
- 네트워크 깊이 증가: 더 복잡한 패턴 학습 가능
3.5 최종 압축 (64 → 32채널)
- 최종적으로 가장 중요한 특징들만 추출
- 분류에 필요한 핵심 정보로 압축
4. MLP 구조와 2048의 의미
4.1 MLP 구조
self.classifier = nn.Sequential( nn.Linear(2048, 512), nn.ReLU(), nn.Dropout(0.1), nn.Linear(512, num_classes) )4.2 2048 입력 크기의 계산
- CNN의 출력 크기는 입력 이미지 크기에 따라 결정
- 32x32 입력 이미지 기준:
- 초기: 32x32
- 첫 MaxPool2d 후: 16x16
- 두 번째 MaxPool2d 후: 8x8
- 최종: 32채널 x 8 x 8 = 2048
5. 전체 데이터 흐름
- 이미지 입력 → CNN 특징 추출
- 추출된 특징 → MLP 분류
- 최종 출력: 분류 결과와 중간 특징
-
Student

-
기본 과제에서 KD: Feature-based를 하기 위해서는
이미지의 dimension인 (b, 3, 32, 32)을 기준으로
- 처음에는 32x32 RGB색상(3채널)을 b개씩(batch) 입력 받아
- Teacher의 2번째 conv, maxpool이후에 (b, 64, 16, 16)이 된 것을
- Student의 1번째 conv, maxpool이후 (b, 16, 16, 16)이 된 것과 그 입력 차원을 맞춰주는 작업이 필요한데
이때 필요한 것이 바로 Regressor이다
Feature map 사이즈를 유지하면서 filter 수를 4배로 늘리는 CNN이 필요한 것!
아까 student의 1번째 conv, maxpool이후의 출력에 대해 아래를 통과시켜 주면 된다.
nn.Conv2d(16, 64, kerenl_size = 3, padding =1)
Filter수만 건드려주는 작업!
그래서 이거 어떻게 학습하나요?
for inputs, labels in iter(train_loader): inputs = inputs.to(device) labels = labels.to(device) optimizer.zero_grad() # teacher는 freeze with torch.no_grad(): _, teacher_features = teacher(inputs) student_logits, student_features = student(inputs) # 'mse_loss' 라는 변수가 완성되어야 한다. # CODE를 완성하시오 # # ce_loss = ce_losser(input=student_logits, target=labels) loss = mse_losos_weight * mse_loss + ce_loss_weight * ce_loss
2. Imitation Learning
- Black-box
모델 내부구조, 추론 과정 등은 알 수 없고 입력에 따른 결과만 접근 가능한 모델- 모델 레이어, 파라미터, 가중치 등에 접근 불가
- 보통 API로만 접근가능하다.
ChatGPT API, GPT4o, Claude
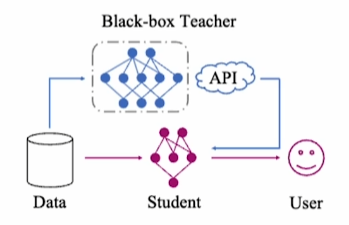
그런데 이런 Black-box 모델도 지식증류를 할 수 있다면 좋지 않을까?
-
NLP 분야에서 특히 많이 사용한다.
-
Imitation Learning(모방학습)
- 다른 에이전트의 행동을 관찰하고 모방하여 자신의 정책을 학습하는 기계 학습 방법
- 다른 에이전트(ChatGPT), 자신(SLM), 다른 에이전트 행동(ChatGPT의 응답)
- 출력 결과 외 모델정보를 얻을 수 없는
Black-box모델의 지식을 전달 받는 방법- NLP분야에서 많이 사용
- 데이터 증강 관점으로도 볼 수 있음
- 다른 에이전트의 행동을 관찰하고 모방하여 자신의 정책을 학습하는 기계 학습 방법
-
Imitaition Learning의 과정
- 모방 데이터 수집
- Seed 질문 설정
Teacher모델에게 어떠한 질문을 할 것인가?- 공개 데이터 활용
- Teacher 모델에게 부탁하여 자동 생성(다양한 질문들을 생성하도록 만듦)
- 지식 추출
어떻게 Teacher 모델로부터 더 유의미한 답변(지식)을 추출할 것인가?- 주로 Prompt Engineering을 활용한다
- 다양한 형태의 답변을 생성하도록 유도
- 구체적인 과정 및 설명 과정을 답변하도록 유도
- 데이터 전처리
- 수집된 데이터의 품질 확인 및 검증
- 의미 없는 대화, 매우 짧거나 불충분한 답변 제거
- Halluciantion이 존재하는지 검증(RAG 활용 등)
- 특정 유형의 질문-답변 페어가 지나치게 많거나 적지 않도록 균형
- 다양한 검증 방법 존재
- 모델 학습
- Example
VicunaORCAWizardLM - 품질 검증이 끝난 데이터를 활용한 모델 재학습
- Imitation Learning 데이터 특징
- 인조 데이터
모델의 출력으로 구성된 데이터이다 보니 인조 데이터이며 아래와 같은 특징을 가짐- Noisy 데이터
LLM 출력 또한 오류 또는 비정확한 예측, 편향된 데이터가 포함될 수 있음 - 저렴한 데이터 수집 비용
사람이 생성하는 데이터 가격에 비해 매우 저렴함
- Noisy 데이터
- 설명 가능한 답변 생성
다른 KD 기법에 비해 증류하는 지식이 인간이 해석 가능한 형태
- 인조 데이터
Imitation Learning의 장단점
- 장점
- Black-box 모델의 유일한 KD 접근법
내부 접근이 불가능한 경우에도 모델 지식 획득 가능- 설명 가능한 지식
다른 KD 기법과 다르게 증류하는 지식이 인간이 해석 가능한 형태이다.
- 단점
- 제한된 정보량
출력된 응답만으로는 LLM의 내부 지식의 이해 및 심층적 학습이 어려움- 데이터 품질의 민감성
LLM의 응답에 수렴하여 답변의 다양성이 떨어지거나 새로운 상황에 대한 대응력이 떨어질 수 있음
- 출력의 다양성과 품질이 학습의 효과에 큰 영향을 줌
3. Other Variants
- Multi-teacher
- 앙상블처럼 모든 출력을 합쳐서 실수를 줄임
- Cross-modal
다른 modality를 지닌 선생에게 배우기