1. 추천시스템이란?
사용자에게 취향에 맞는 아이템을 제시하는 모델
- 아이템?
유튜브 영상추천, 쿠팡 상품 추천 등등 - 제시한다?
사용자를 쿼리로 하는 전체 아이템 집합에서 선호하는 아이템 부분 집합을 찾는 문제다.- 즉, 정보 검색 문제의 일종인 것. (
IR분야)
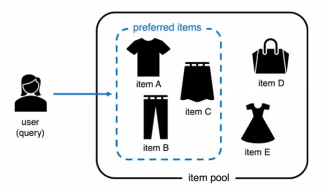
- 즉, 정보 검색 문제의 일종인 것. (
1.1 기호 정리

1.2 어떤 미래의 기록 (u,i)에 대하여

골자는 u라는 특정 유저에 대한 변수가 들어왔을때 i플러스라는 객체가 가장 큰 확률을 지녀야 한다. 라는 것
1.3 추천 모델의 예시
-
memory-based collaborative filtering (CF)
- 취향이 비슷한 사람의 기록을 참고하여 추천
- 모든 기록을 기억하고 있어야 함!
- 시간 복잡도 = 사용자별 최대 2NM
- 구현하기 나름이라 다를 수 있음
- 사용자 유사도 계산 (NM) + 아이템 선호도 계산(NM)
- 공간 복잡도 = 최소 2K
- 사용자 번호, 아이템 번호(기록 하나당 2개씩)
- 이런 기록이 K개
- 시간 복잡도 = 사용자별 최대 2NM
-
model-based collaborative filtering(CF)
- 사용자, 아이템에 d차원 임베딩 벡터를 할당하여, 이를 활용한 연산이 선호도가 되도록 학습
- 사용자/아이템별 벡터를 기억하고 있어야 함!
- 시간 복잡도 = (사용자별) 최대 Md
- 공간 복잡도 = 최소 Nd + Md
-
딥러닝 기반 추천 모델은 모두 model-based이다.
- 사용자, 아이템 별로 학습 가능한 임베딩 벡터를 만들고
- 이를 딥러닝 구조가 복잡하게 활용하여 선호도를 계산한다.
-
결국, 시간/공간 복잡도에 사용자/아이템의 수가 포함됨!
- 사용자와 아이템은 끝없이 늘어날 수 있음
-
자연어 처리 분야의 단어 임베딩과 비교
- 자연어 처리: 몇억개의 문장 x 몇만개의 단어
- 추천 시스템: 몇십만명의 사용자 x 몇십만개의 아이템
사용자를 알 수 없는 경우
- 이른바 session-based 추천 문제
- 현재 세션(웹, 앱 등에서 말하는 그 세션) 기록만을 사용
- 사용자라 할만한 것이 매번, 무한히 추가됨
- 사용자의 임베딩 벡터를 학습해 놓을 수가 없음
어떻게 해결하나요?
시퀀셜 추천을 이용하여 해결한다
만약 사용자별 아이템 소비 기록에 순서가 있다면, 시퀀셜 추천을 적용 가능하다.
사용자 = 아이템의 시퀀스로 대체
- 전체 M개의 아이템 집합 I
- 사용자 u는 아이템을 소비한 기록의 시퀀스
미래의 소비 아이템 i에 대하여
결국 시퀀셜 추천은 자연어 처리에서 말하는 따음 단어 맞추기문제와 완전 동일한 문제이다.
- 시퀀셜 추천의 장점
- 사용자 임베딩 벡터를 사용하지 않음
- 즉 사용자가 늘어도 파라미터가 늘지 않음
- 자연어 처리에서 연구된 방법론을 모두 빌려올 수 있다
- 단, 문장-단어와 사용자-아이템은 성질이 꽤 다르다.(수 스케일, 분포 모양 등)
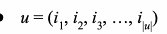
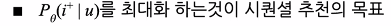

아이템이 많은 경우
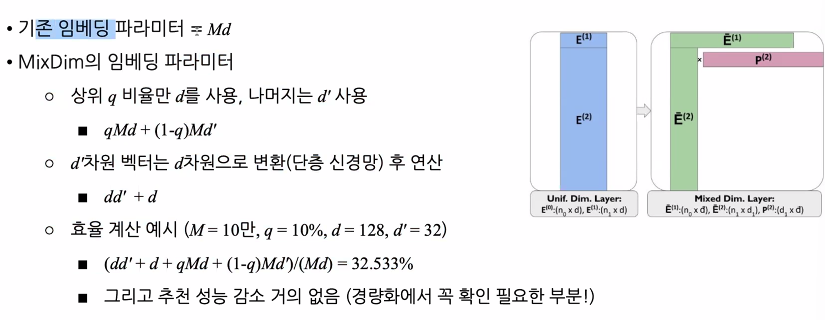
- MixDim
이제 사용자 증가에 따른 복잡도 증가는 해결했는데, 아이템은 여전히 문제이다.- 아이템이 아주 많은 경우엔? (유튜브 영상, 이커머스 상품 등)
- 소비 기록이 적은 아이템이 아주 많고 계속 추가된다.
- 아이템 임베딩 벡터의 파라미터는 Md라고 하면
이게 계쏙 늘어나고 있는 것.- M이 계쏙 늘어나는 것이 문제
- d를 줄이자니 성능이 떨어지게 됨.
그럼 어떻게 해결하나요?
MixDim을 활용하자
추천 데이터셋은 long-tail 분포이다.
- 자연어 처리에서 단어와 추천의 아이템의 큰 차이
- 상위 아이템의 인기도가 아주 높음
- 그래서 인기순 추천이 가장 좋은 lower bound
- 그러나 하위 아이템의 기록 수를 무시할 수 없음
- 이 long-tail을 잘 다뤄야 고성능의 개인화된 추천이 가능하다.
하위 아이템은 소비한 사용자가 적음
- 즉, 기억해야할 정보가 적음
- 적은 차원 벡터로도 충분
마치 mixed precision처럼, 차원수를 섞어서 사용
상위 아이템 = d 차원, 하위 아이템 = d` 차원
추천 성능 감소가 거의 없다는 점에서 경량화 할 때에 꼭 확인하면 좋은 부분이다.
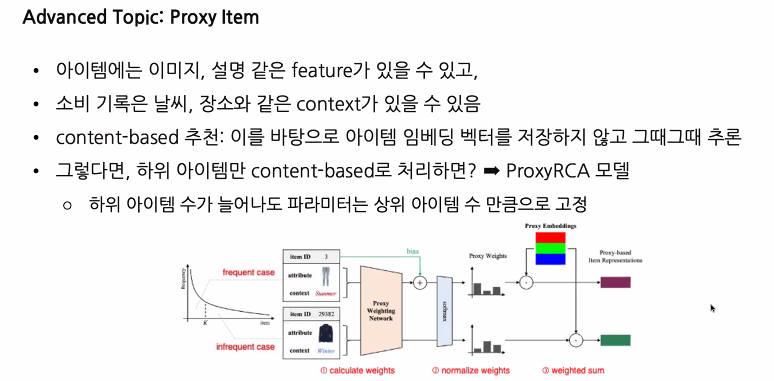
2. 추천 모델 학습 효율화
추천 모델은 빠른 학습도 매우 중요하다.
-
T + 1 문제
- 추천 모델은 T일째까지의 데이터로 학습
- 그러나 추천 모델이 사용되는 날짜는 T+1 이다.
- 하루(zero-day)동안 생성되는 데이터가 모델에 반영이 안 되는 문제가 존재한다는 것.
- 해결책:
더 자주 학습한다. 가량 1시간 주기로 빠른 학습을 하는 것 (trivial solution: 더 최근 기록만 사용하는 것도 하나의 방법) - 해결책2:
신규 데이터를 학습 없이 반영한다.
새로운 사용자나 아이템이 추가되면 임베딩 벡터는 어떻게 처리하나?
보통content-based를 강화하여 해결한다.
- 해결책:
- 추천 모델은 T일째까지의 데이터로 학습
-
학습 과정
추천 모델의 목표는 아래와 같다.
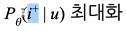
-
구체적으로 어떻게?
- 자연어 처리의
다음 단어 맞추기에서는 전체 단어 중 정답 단어를 맞추게끔 학습- 보통 softmax로 구현
- 그러나 추천에서는 전체 단어에 대응되는 전체 아이템 수가 훨씬 많다.
- 단어는 몇만개, 아이템은 몇십만, 백만개
- softmax 함수에서 큰 문제가 발생
- 자연어 처리의
-
Bayesian Personalized Ranking
통계학에서는 이럴 때 네거티브 샘플링을 사용하여 해결한다.- 원래 문제
10만개의 아이템 중 정답 한 개 맞추기 - 네거티브 샘플링
- 10만개 중 오답 100개 랜덤하게 선정
- 정답 1개를 포함한 101개의 아이템 중 정답 한개 맞추기
- 이때도 실제 구현은 softmax로 수행, 그러나 훨씬 가벼운 계산~
- 고맙게도 추천에서는 이 방법이 유효하다는 것이 수학적으로 증명되어 있다.
- 이른바 BPR이라고도 부르는 loss
- 오답은 1개씩만 있어도 가능하지만, 보통 많을 수록 학습이 빨라진다.
- 원래 문제

3. 현업에서의 추천 모델
실제 사례를 보자.
3.1 Funnel 구조
- 추천의 성능은 보통 두가지 요소로 구성 됨
- 모델이 추천으로써 반환한 k개의 아이템에 대해서
- Recall@k: 정답 아이템을 가져 왔었는지
- NDCG@k: 정답 아이템을 높은 등수로 가져왔는지
- 이 둘은 높은 상관관계가 있지만 역할이 다르다.
- 그리고 엄연히 다른 문제이기 때문에, 최적의 학습 지점이 다르다
언제 학습을 끊어야 할지가 다르게 작용한다. - 대체적으로 그럴싸한 추천 후보들이면 충분한 경우 = Recall에 집중
- 추천을 딱 1개만 할 수 있어서 랭킹이 아주 중요한 경우 = NDCG에 집중
- 그리고 엄연히 다른 문제이기 때문에, 최적의 학습 지점이 다르다
-
일반론
크고 복잡한 모델은 성능이 좋지만 느리고 무겁다.(and vice versa)- 추천에서는 약간 다른 의미를 지님
- 크고 복잡한 모델은 NDCG 성능 지표가 높다.
- 작고 간단한 모델도 Recall 성능 지표는 높을 수 있다.
- 이를 토대로, 많은 현업 모델이 funnel 구조를 사용
- 작고 간단한 모델이 추천 후보를 선정
- 크고 복잡한 모델이 선정된 후보를 정렬시킨다.
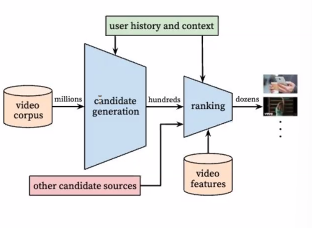
- 추천에서는 약간 다른 의미를 지님
-
Funnel 구조
- candidate generation model
아주 많은 아이템 풀에서 후보를 빠르게 찾는 것에 집중 - ranking model
고정된 수의 후보에서, 랭킹을 잘 하는 것에 집중
- candidate generation model
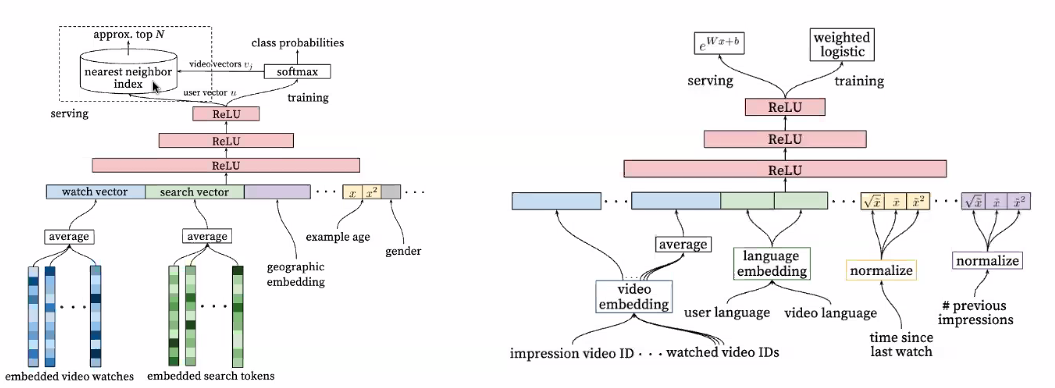
3.2 현실적인 방법
경량화가 정말 필요한가?
물론 필요하겠지만,,, 정말로?!
-
더 일반적으로는
- 딥러닝 모델을 만들 필요가 있는가?
- 그렇지 않다면 고전적인 머신러닝 방법론이 필요한가?
- 그렇지 않다면 문제를 해결해야하는 상황이 맞는가?
- 정말로??? 진짜로 ??? 문제 해결이 필요 없는가?
- 그렇다면 안 한다.
-
딥러닝의 경량화, 최적화 작업 자체도 코스트다.
-필요하지 않은 상황이라면, 안 하는 것도 최적화다. 그런 비용과 이윤의 균혀을 잘 고려하는 것이 필요하다. -
현실사례
- 딥러닝 기반의 복잡한 추천 모델들이 성능이 물론 좋긴 하겠지만
- memory-based CF에 비해 가성비가 과연 얼마나 좋을지 먼저 확인하는 작업이 꼭 필요하다.
- 딥러닝 모델
- 다수의 큰 GPU 필요
- 추천 모델 특성상 계속되는 학습
- 고전적인 memory-based CF
- 가장 대표적인 (고전적인 방식의 머신러닝 기반) 추천 모델
- SQL로 구현하는 것도 가능하다. 데이터를 DB로써 가지고 있으면 그걸 SQL 잘 구현하면 된다. 파라미터 베이스가 아니므로 가능한 일!
- 필요했던 추천
필터링이 잘 될 것 + 재밌는 것 발견- 즉, 랭킹 성능이 중요하지 않음
- 다양성과 CTR을 주요 지표로 사용
- 데이터 규모
- 약 200억 row 처리 필요 (대략 사용자가 40만 x 아이템이 5만
- 200억 곱하기 8B / 1024 / 1024 / 1024
이거 거의 149 기가바이트 근사치다. - 시간당 5달러인 Amazon Redshift 인스턴스(메모리 244GiB)에서 5분만에 계산된다.
- memory-based니까 모든 row를 저장하고 인덱싱 필요 => DBMS가 이런거 끝내주게 잘한다.
- 200억 곱하기 8B / 1024 / 1024 / 1024
- 약 200억 row 처리 필요 (대략 사용자가 40만 x 아이템이 5만
- 데이터 규모제한
- 다양한 방법으로 200억을 유지
- 신규 사용자, 복귀 사용자에겐 인기 추천만 사용
- 최근 데이터 반, 과거 데이터 샘플링 해서 반 사용
- 사용자 40만 초과시 샘플링 해서 학습 시엔 40만으로 유지, 대신 학습을 더 자주 시행
- Redshift는 1시간에 한번, 5분간 학습 = 하루에 120분 = 2시간 = 하루 10달러 = 한달 300달러
- GPU를 사용하는 경우에 1시간 내내 학습 필요 = 하루에 24시간 = 하루 24달러 = 한달 7200달러
- 과연 이 상황에서 딥러닝 모델이 24배 비용을 추가할 가치가 있는가?
- 인건비도 고려해라
어쨌든!
딥러닝의 경량화, 최적화를 열심히 배웠지만 실제 사용하게 된다면, 그걸 정말 정말 사용해야하는지 심각하게 고민해봐라!
