
📖 Introduction
- 프로젝트 개요 : 최근 온라인 명품 시장의 성장세가 두드러지며 경쟁이 심화되고 있음. 시장에 처음 진입하는 명품 커머스의 입장에서, 대표적인 명품 커머스(머스트잇, 발란, 트렌비)의 VoC를 분석하여 시장 현황을 파악하였음. 아울러 VoC 분류 모델을 개발하여 대시보드 서비스를 제안하고자 함.
-
기간 : 2023.09.15 – 2023.10.16
-
수행 역할 :
- Selenium, BeautifulSoup으로 Google Play 스토어의 커머스 앱 리뷰 크롤링
- Pandas로 비정형 데이터 전처리
- WordCloud로 커머스별 긍정 리뷰의 주요 키워드 시각화
- Matplotlib로 커머스별 앱 사용 안정성에 대한 파이 차트 시각화
- KoBERT 전이학습이 된 카테고리, 감성 분류 모델 최적화
- Tableau로 VoC 통계 대시보드 제작
-
배운 점 :
① NLP에서 전처리 과정의 이해도를 높이고 KoBERT 모델에 대한 전이학습으로 카테고리, 감성 분류 모델을 개발.
② 최종 대시보드까지 제작하며 시각화 툴 핸들링 능력 향상.
🔧 문제 정의
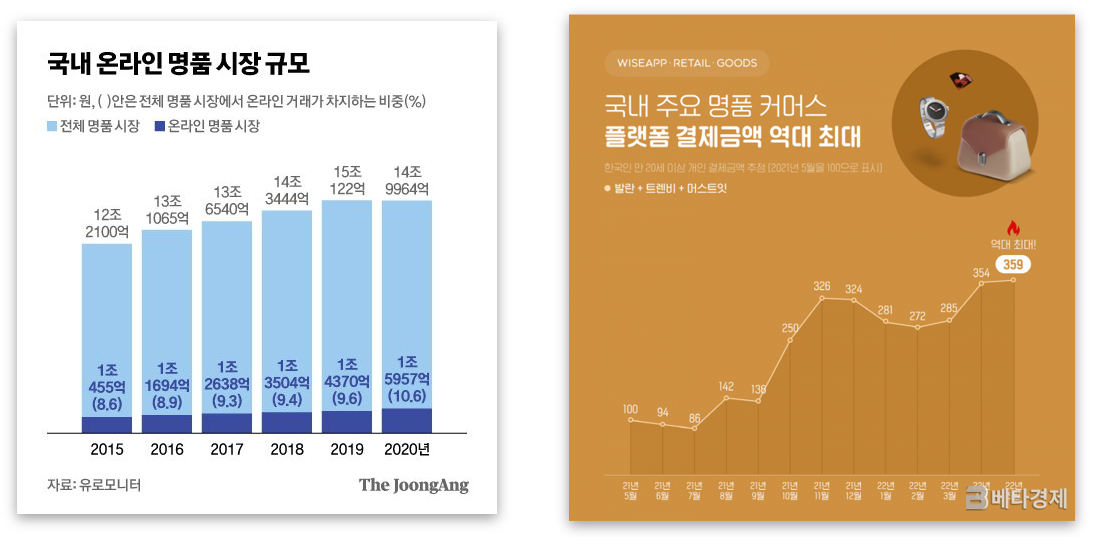
- 문제 인식 : 온라인 명품 시장의 경쟁이 심화돼 처음 진입하는 커머스의 입장에서 시장조사를 하고자 했음. 상품/서비스의 전반적인 유저 평가를 파악할 수 있는 VoC는 경영 전략의 기준이 될 수 있음.
- 목표 : 명품 커머스 3사의 VoC를 분석하여 현황을 파악하고, 분류 모델을 개발하여 VoC 분류 서비스까지 제안.
📎 데이터 수집 및 전처리
🔹 데이터 수집
➡️ 커머스 3사 앱에 대한 리뷰를 구글 플레이 스토어와 애플 앱 스토어에서 크롤링.

🔹 전처리 과정
- STEP 1 : 종결어미(~요, ~니다)와 개행문자(\n)를 기준으로 리뷰 나눔.
- STEP 2 : 이모티콘, 외국어, 문장 기호 등 리뷰에서 한글이 아닌 내용 삭제.
- STEP 3 : 키워드 딕셔너리로 리뷰를 필터링하여 카테고리 라벨링.
- STEP 4 : 한 리뷰에 카테고리가 여러 개면 수작업으로 리뷰 분류, 동시에 감성 라벨링 수작업.
💡 EDA
1. 커머스 플랫폼별 긍정 리뷰의 주요 키워드 분석

➡️ 긍정 리뷰에서 빈도수가 높은 TOP 5 키워드는 커머스 플랫폼별로 거의 비슷한 양상(가격, 배송, 정품 신뢰도, 상품 구색)을 보임. 그러나 머스트잇의 경우 UX/UI 편의성(4위)이 높은 순위에 있으며, 발란, 트렌비의 경우 프로모션(각 4위, 3위)이 높은 순위에 있음.
2. 트렌비 리뷰의 특정 시기에서 부정 리뷰 증가 요인 파악

➡️ 가장 많은 데이터를 확보한 트렌비의 리뷰를 통해 커머스 플랫폼의 부정 리뷰가 급증할 때 요인이 어떻게 되는 지 알아보고자 했음. 특정 시기에 앱의 오류가 있거나 고객센터가 불만족스러울 때 부정 리뷰가 특히 증가하는 양상을 보임.
3. 정품 신뢰도를 판단하기 위한 중요 요소 분석
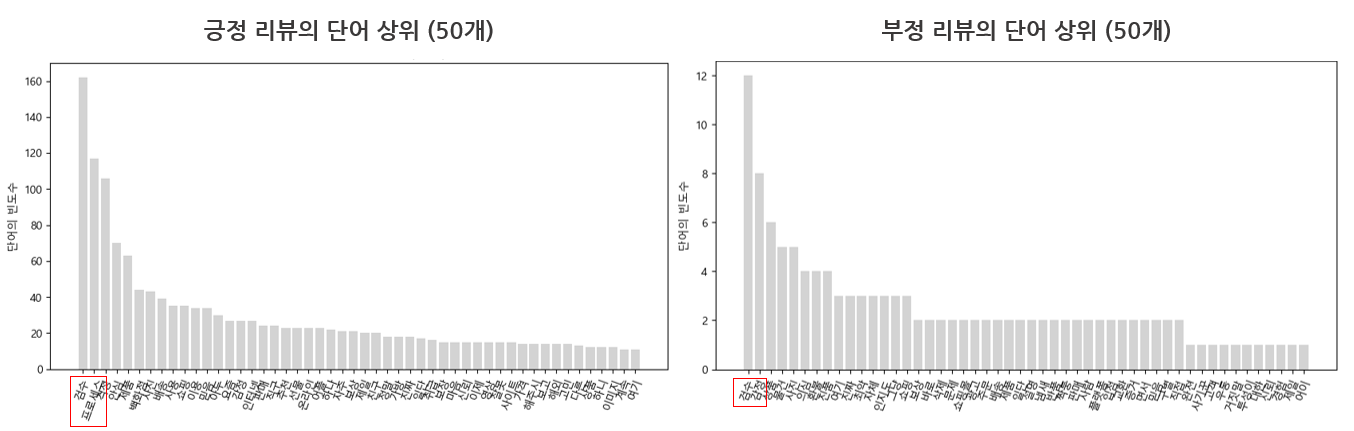
➡️ 명품 관련 여러 온라인 커머스(머스트잇, 트렌비, 캐치패션)에서 자체적으로 시행한 설문조사에 의하면 온라인 명품 구매를 이용할 때 가장 고려하는 요소는 정품 신뢰도임. 따라서 키워드 빈도 분석을 통해 정품 신뢰도 판단할 때 중요한 요소가 무엇인 지 파악함. '검수, 프로세스, 감정' 키워드가 최상위 빈도인 것으로 보아 물품 검수 과정, 정품 감정 절차가 커머스의 정품 신뢰도에 영향을 주는 중요한 요소라고 볼 수 있음.
4. 커머스 플랫폼별 앱 사용 안정성에 대한 분석
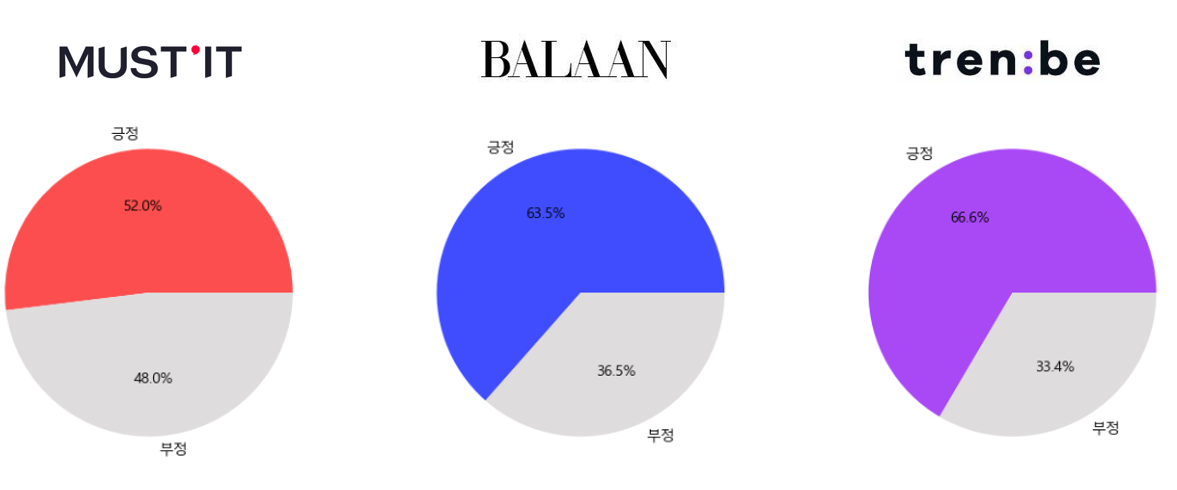
➡️ 커머스 3사 모두 긍정 리뷰의 비율이 부정 리뷰보다 높은 부분을 차지. 그러나 머스트잇의 경우 IOS 기반의 앱이 부정 비율이 높은 데 이 점이 타사에 비해 전체 부정 리뷰의 비중을 높게 만듦.
🤖 모델링
🔹 KoBERT
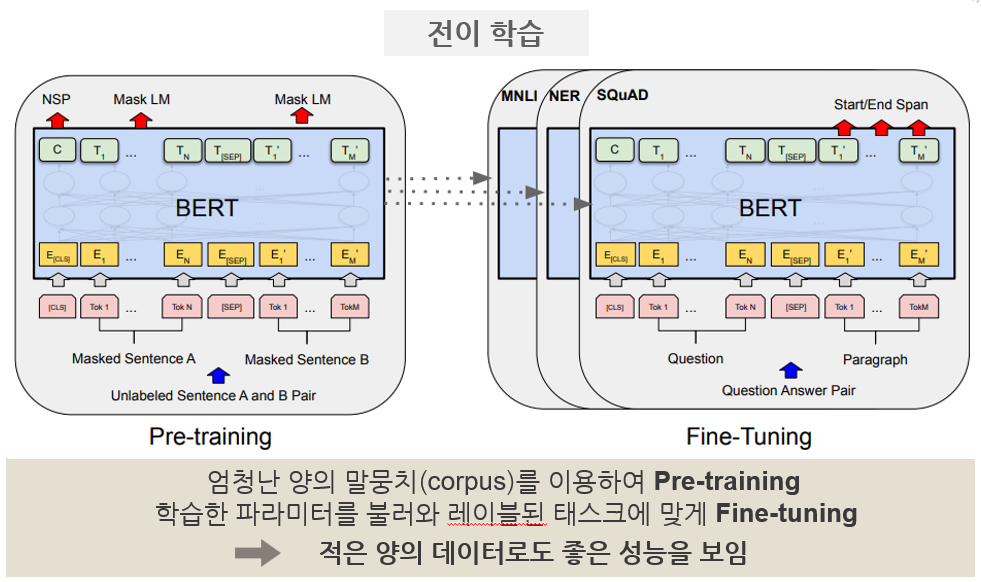
➡️ 리뷰에서 감성 클래스별 비율이 긍정 4 : 부정 1 로 클래스 불균형이 심한 편이었음. 또한 전체 확보한 리뷰 데이터가 전처리 후 약 13000개 정도로 모델을 학습 시키기에 다소 적은 양이라고 판단되었음. 따라서 적은 양의 데이터로도 좋은 성능을 낼 수 있도록, Pre-trained BERT 모델인 KoBERT 모델을 활용하여 확보한 데이터셋을 Fine-tunning 하는 전이학습을 진행하기로 결정하였음.
🔹 카테고리 분류 모델

🔹 감성 분류 모델
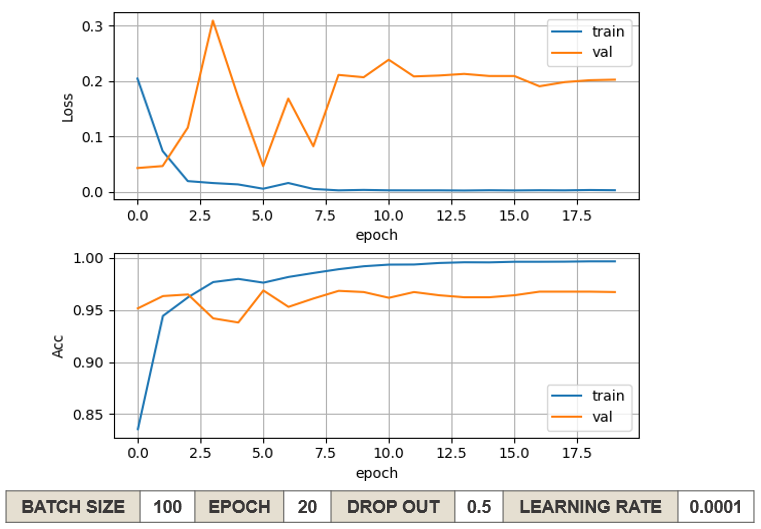
🔹 최종 모델링 결과

📊 활용 방안
🔹 VoC 분류 서비스 제안 (Tableau Public)
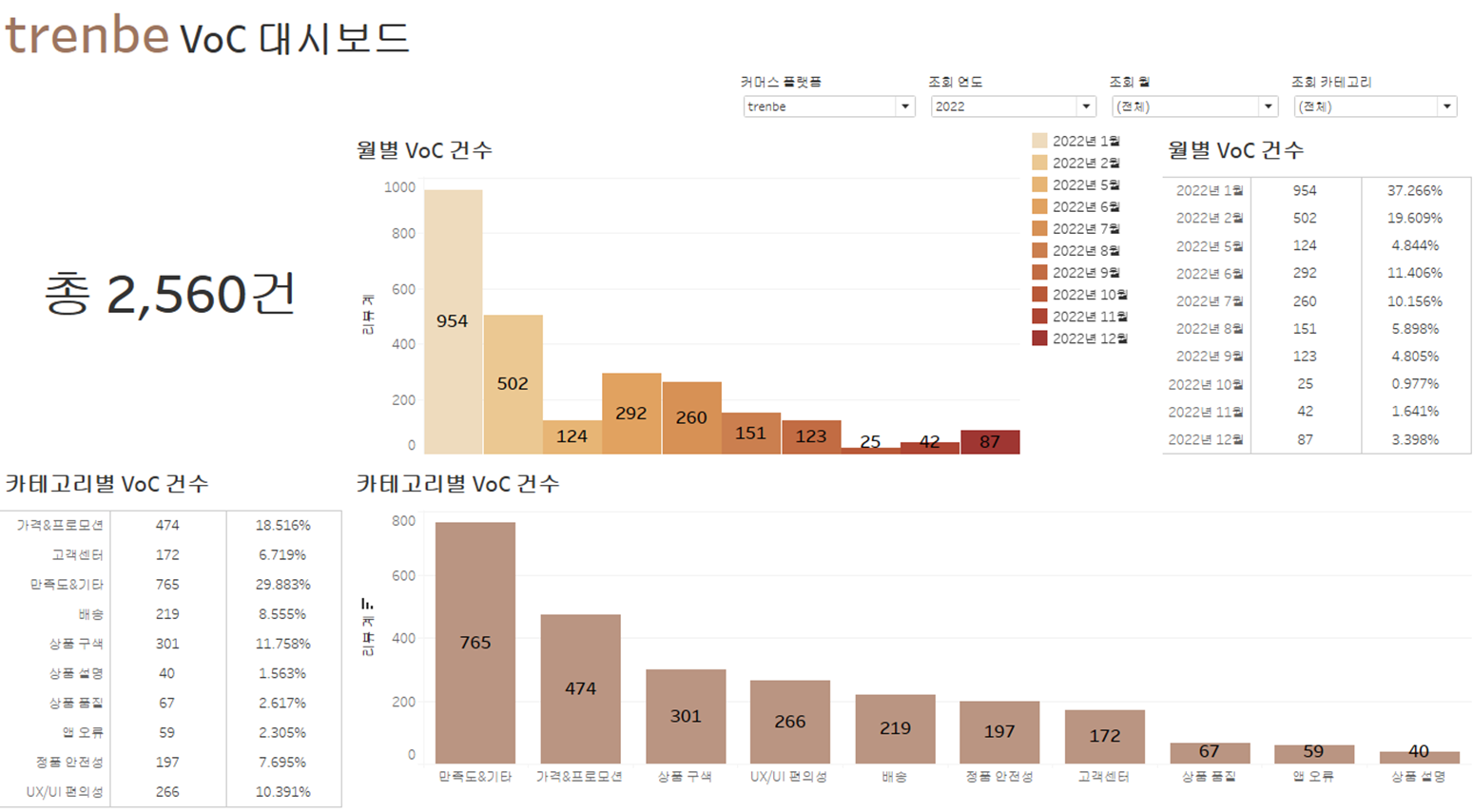
➡️ 실시간으로 VoC의 카테고리를 분류하고 대시보드화, 유저들의 상품/서비스에 대한 평가 현황을 확인
