서울시 CCTV 현황
1. 데이터 읽기
판다스 모듈 임포트
import pandas as pd
데이터 불러오기
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv")
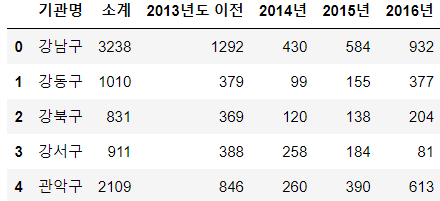
칼럼 조회
전체 칼럼 조회
✏️입력
CCTV_Seoul.columns💻출력
Index(['기관명', '소계', '2013년도 이전', '2014년', '2015년', '2016년'], dtype='object')
특정 칼럼 조회
CCTV_Seoul.columns[0]
칼럼 변경
칼럼 변경
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
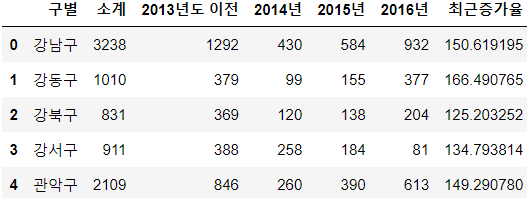
여러 칼럼 변경
pop_Seoul.rename( columns={ pop_Seoul.columns[0]: "구별", pop_Seoul.columns[1]: "인구수", pop_Seoul.columns[2]: "한국인", pop_Seoul.columns[3]: "외국인", pop_Seoul.columns[4]: "고령자", }, inplace=True )
엑셀 파일 불러오기
엑셀 파일 불러오기
pop_Seoul = pd.read_excel("../data/01. Seoul_Population.xls")
엑셀 파일 특정 인덱스부터 특정 칼럼만 불러오기
pop_Seoul = pd.read_excel( "../data/01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N")
DataFrame
- pd.Series()
- index, value
- pd.DataFrame()
- index, value, column
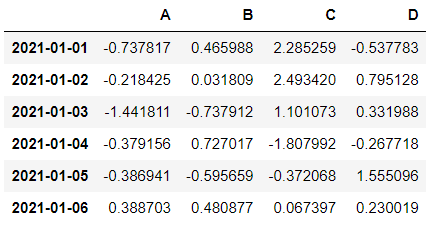
df = pd.DataFrame(data, index=dates, columns=["A", "B", "C", "D"]) df
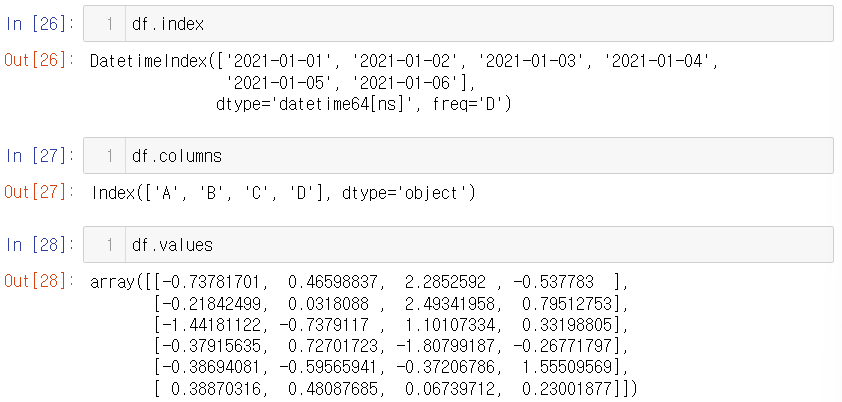
데이터 프레임의 기본 정보 확인
df.info()
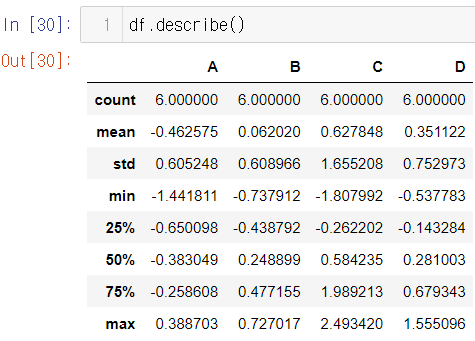
데이터 프레임의 기술통계 정보 확인
데이터 정렬
- sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬합니다
df.sort_values(by="B", ascending=False, inplace=True)
데이터 선택
한 개 컬럼 선택
df["A"]
두 개 이상 컬럼 선택
df[["A", "B"]]
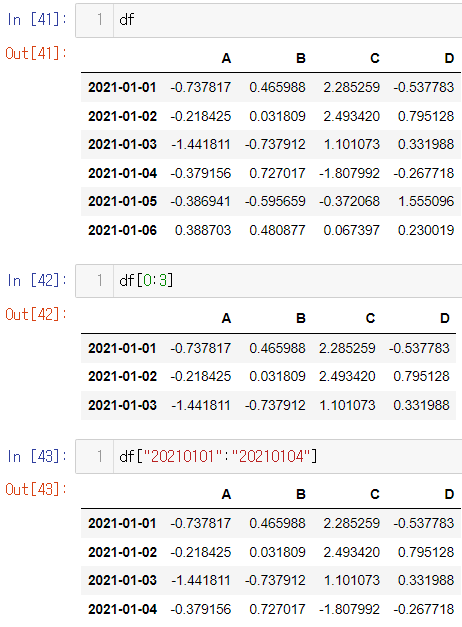
offset index
- [n:m] : n부터 m-1 까지
- 인덱스나 컬럼의 이름으로 slice 하는 경우는 끝을 포함합니다
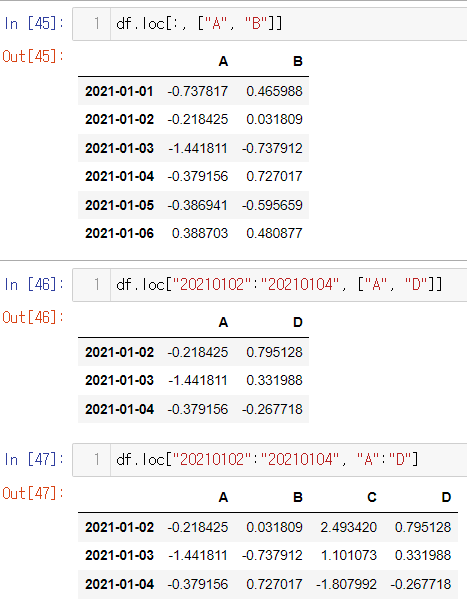
- loc : location
- index 이름으로 특정 행, 열을 선택합니다
컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
df["E"] = ["one", "one", "two", "tree", "four", "seven"]
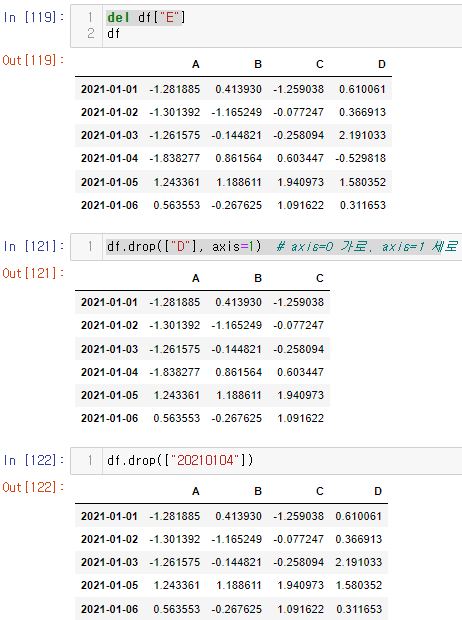
특정 컬럼 제거
- del
- drop
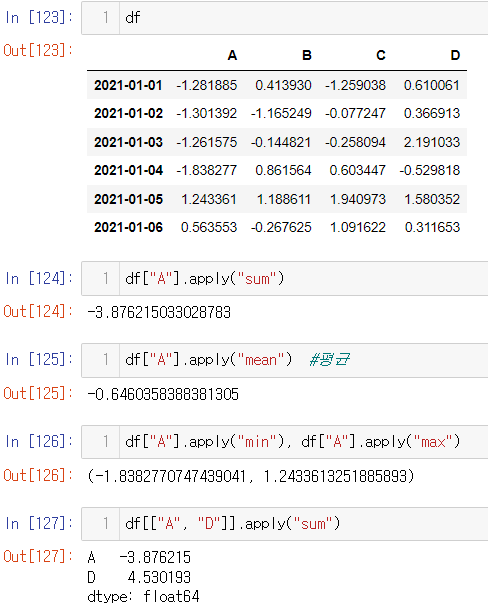
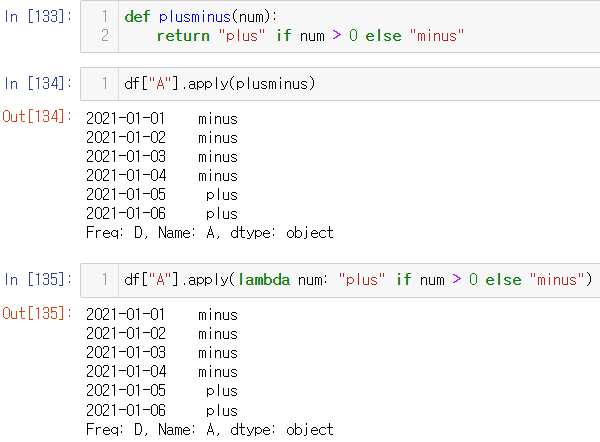
apply()
✨특정 칼럼에 대해서 연산 실행✨
2. CCTV 데이터 훑어보기
기존 컬럼이 없으면 추가, 있으면 수정
✏️입력
CCTV_Seoul["최근증가율"] = ( (CCTV_Seoul["2016년"] + CCTV_Seoul["2015년"] + CCTV_Seoul["2014년"]) / CCTV_Seoul["2013년도 이전"] * 100 ) CCTV_Seoul.sort_values(by="최근증가율", ascending=False).head(5)💻출력
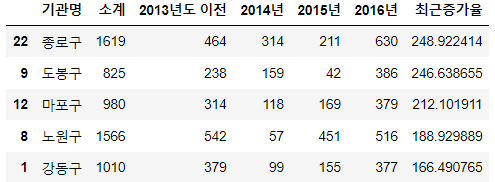
3. 인구현황 데이터 훑어보기
✏️입력
pop_Seoul = pd.read_excel( "../data/01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N") pop_Seoul.rename( columns={ pop_Seoul.columns[0]: "구별", pop_Seoul.columns[1]: "인구수", pop_Seoul.columns[2]: "한국인", pop_Seoul.columns[3]: "외국인", pop_Seoul.columns[4]: "고령자", }, inplace=True ) pop_Seoul.head()💻출력
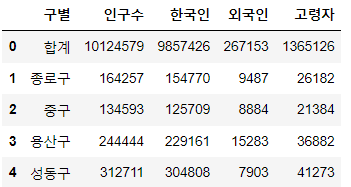
✏️입력
pop_Seoul.drop([0], axis=0, inplace=True) pop_Seoul.head()💻출력
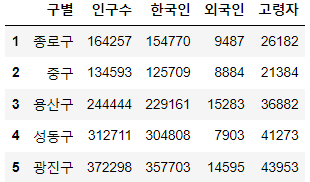
구별에서 어떤 값들이 한 번만 나왔는 지 고유값 확인
✏️입력
pop_Seoul["구별"].unique()💻출력
array(['종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구', '도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구', '영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'], dtype=object)
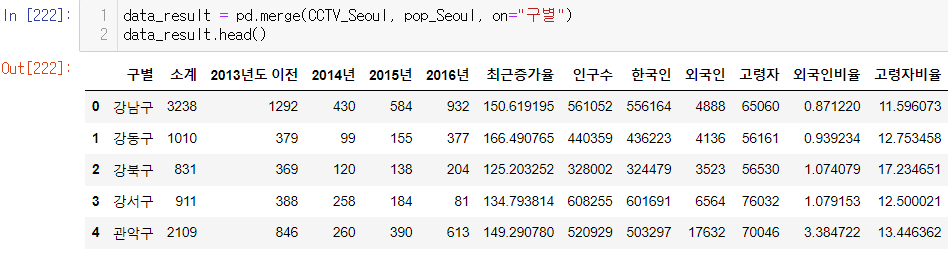
4. 두 데이터 합치기
pandas에서 데이터 프레임을 병합하는 방법
- concat()
- pd.merge()
- pd.join()
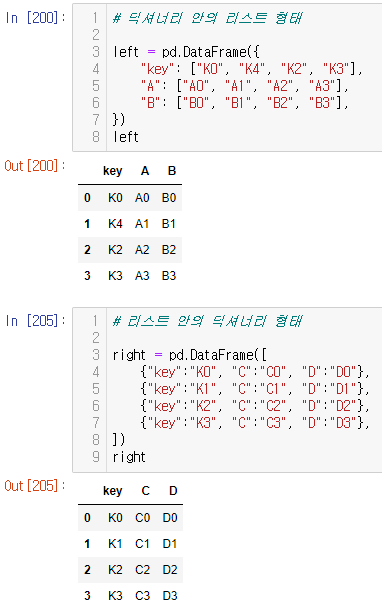
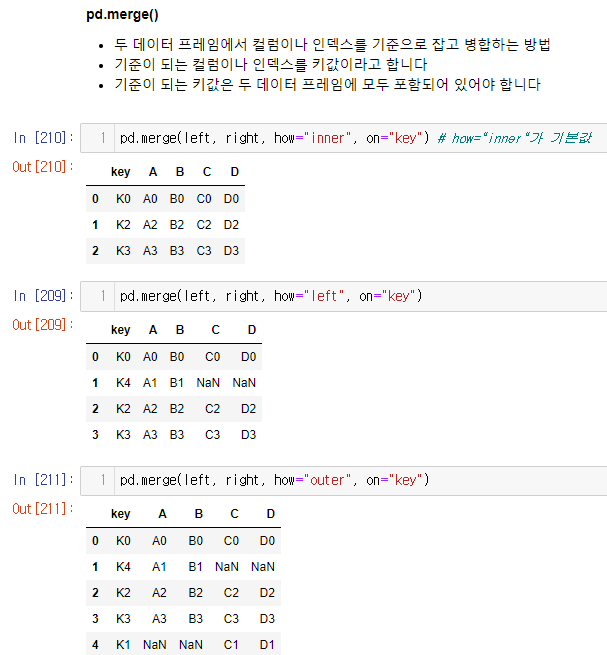
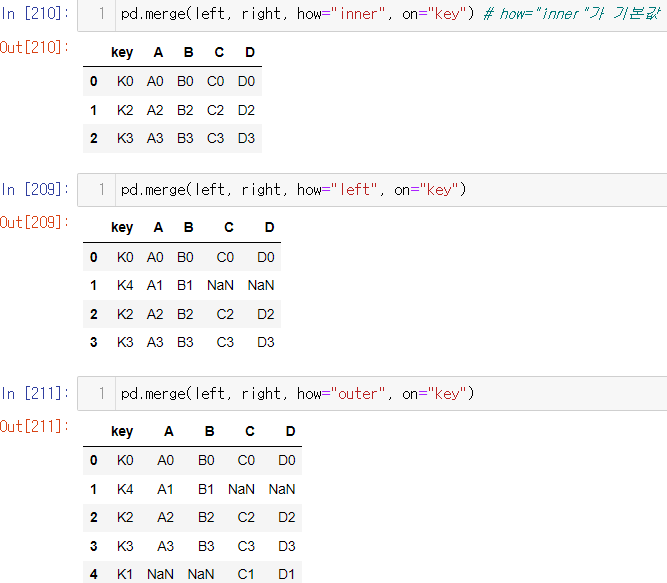
pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 합니다
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 합니다
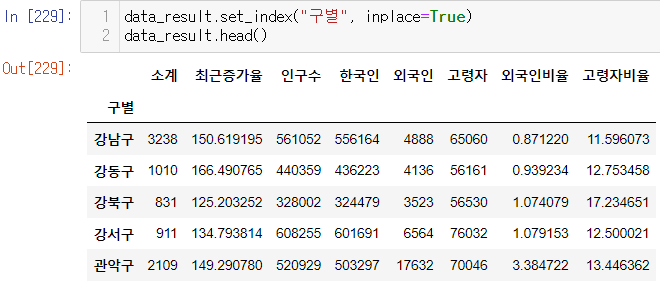
인덱스 변경
- set_index()
- 선택한 컬럼을 데이터 프레임의 인덱스로 지정
matplotlib
matplotlib 그래프 기본 형태
plt.figure(figsize=(10, 6))
plt.plot(x, y)
plt.show()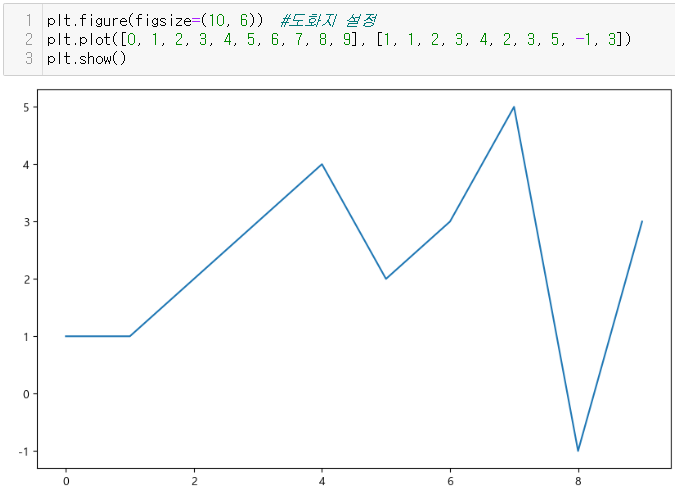
삼각함수 그리기
- np.arange(a, b, s): a부터 b까지 s의 간격
- np.sin(value)
import numpy as np t = np.arange(0, 12, 0.01) y = np.sin(t)📌 np.arange(시작점(생략 시 0), 끝점(미포함), step size(생략 시 1))
- 격자무늬 추가
- 그래프 제목 추가
- x축, y축 제목 추가
- 주황색, 파랑색 선 데이터 의미 구분
✏️입력
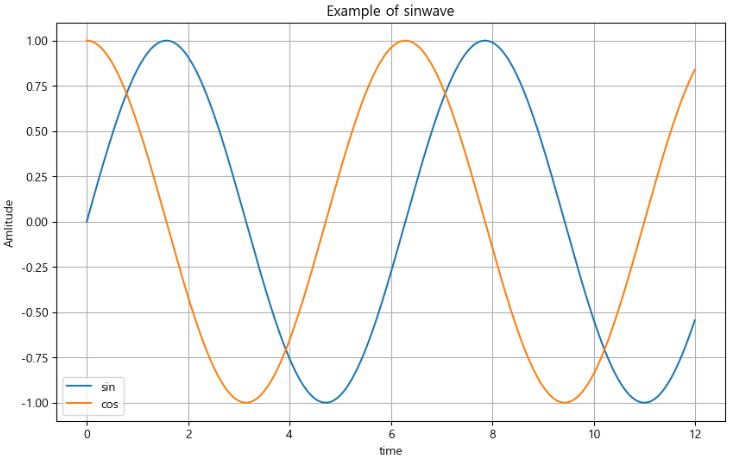
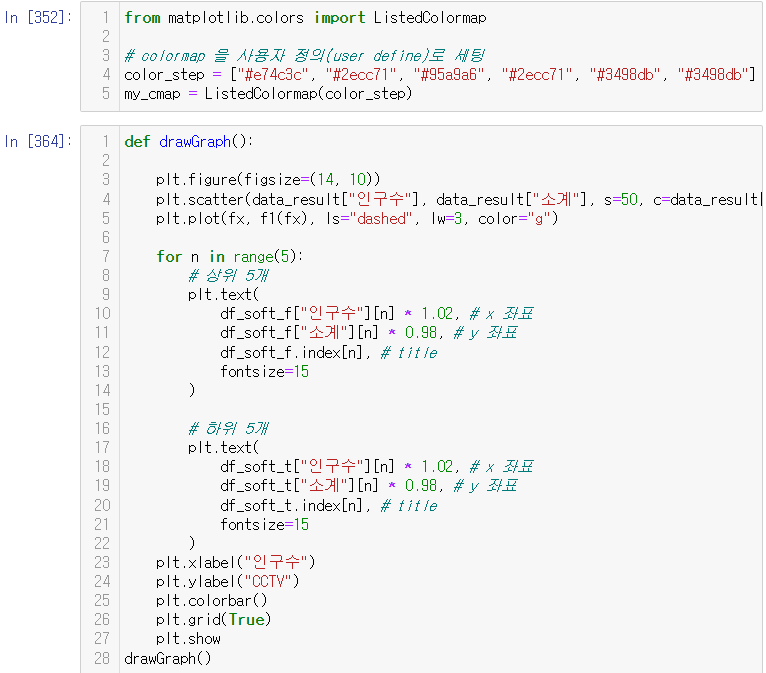
def drawGraph(): plt.figure(figsize=[10, 6]) plt.plot(t, np.sin(t), label="sin") plt.plot(t, np.cos(t), label="cos") plt.grid(True) plt.legend(loc="lower left") # 범례 # plt.legend(labels=["sin", "cos"]) # 범례 plt.title("Example of sinwave") plt.xlabel("time") plt.ylabel("Amplitude") # 진폭 plt.show💻출력
그래프 커스텀
✏️입력
💻출력

✏️입력
💻출력

scatter plot
✏️입력
💻출력

✏️입력
💻출력

5. 데이터 시각화
📌 모듈 임포트, 한글 설정
import matplotlib.pyplot as plt
#import matplotlib as mpl
from matplotlib import rc
plt.rcParams["axes.unicode_minus"] = False
# 마이너스 부호 때문에 한글 깨질 수 있어 주는 설정
rc("font", family="Malgun Gothic")
# %matplotlib inline
get_ipython().run_line_magic("matplotlib", "inline")소계 컬럼 시각화(bar, barh)
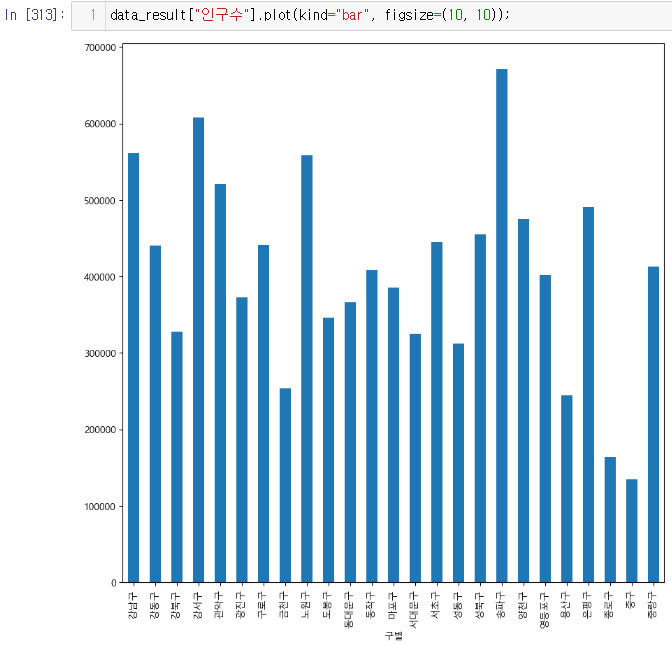
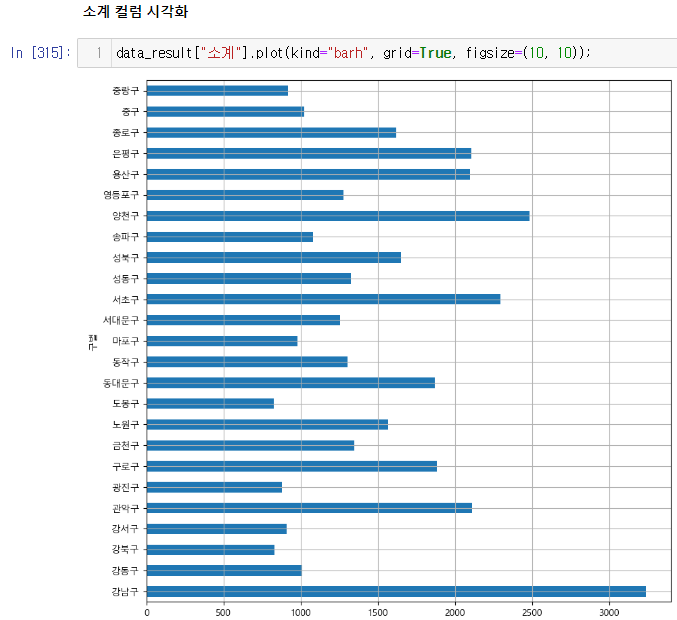
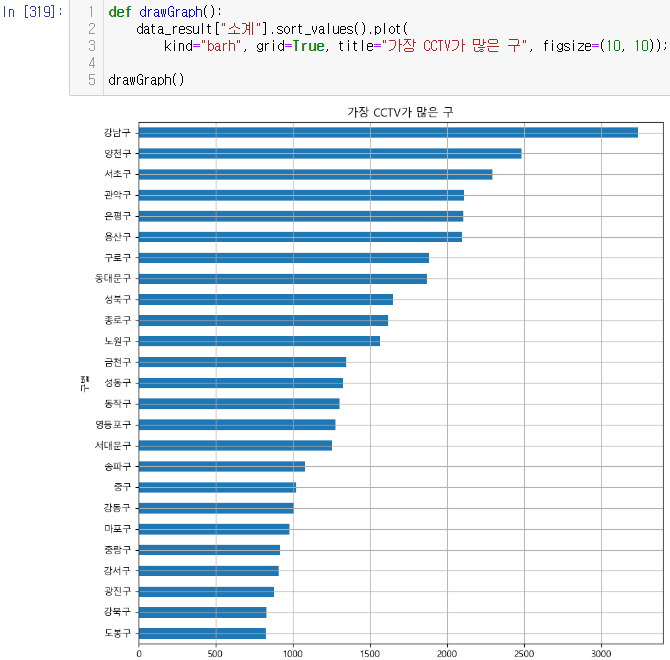
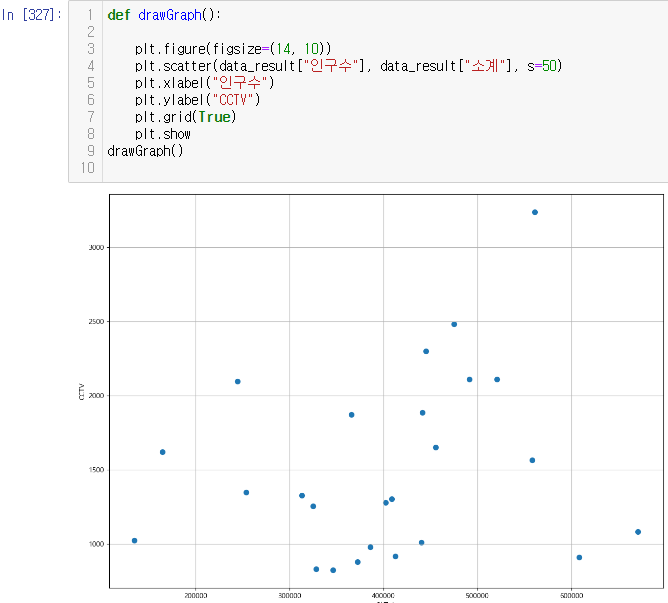
인구수와 소계 컬럼으로 scatter plot 그리기
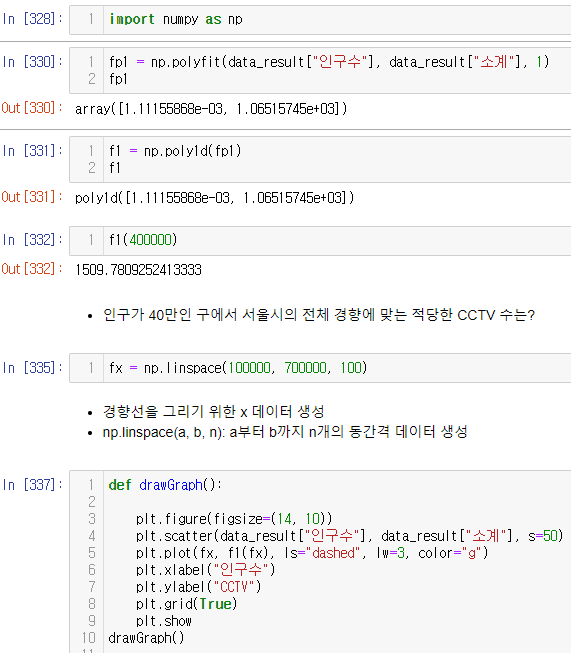
numpy를 이용한 1차 직선 만들기
- np.polyfit(): 직선을 구성하기 위한 계수를 계산
- np.poly1d(): polyfit 으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어주는 기능
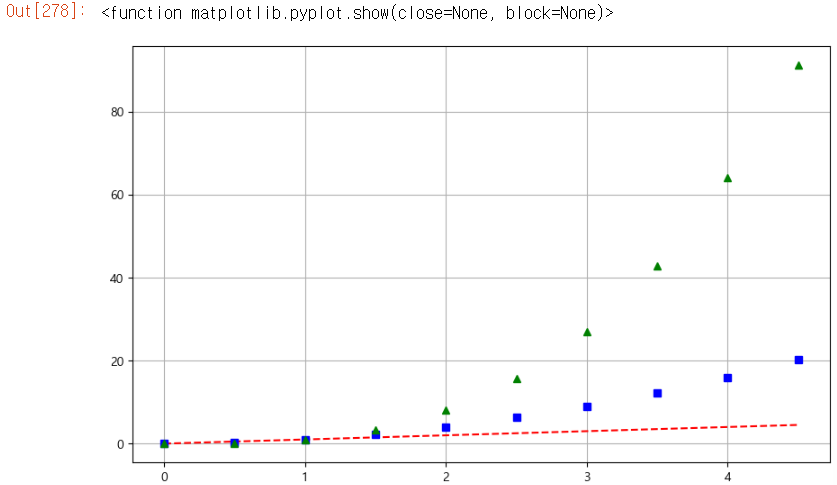
✨scatter와 plot 한 번에✨
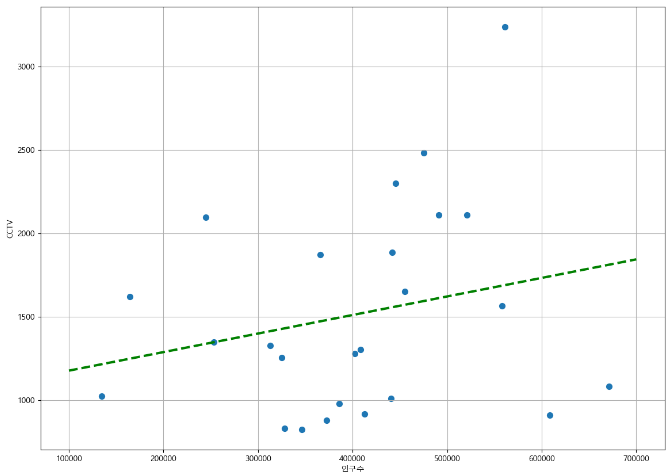
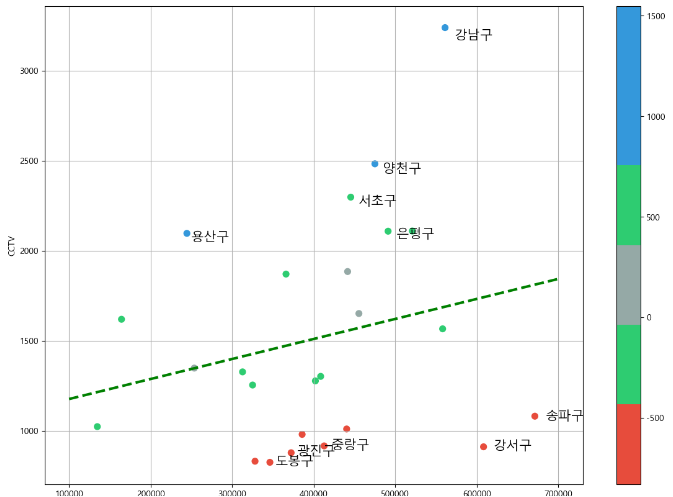
7. 강조하고 싶은 데이터를 시각화해보자
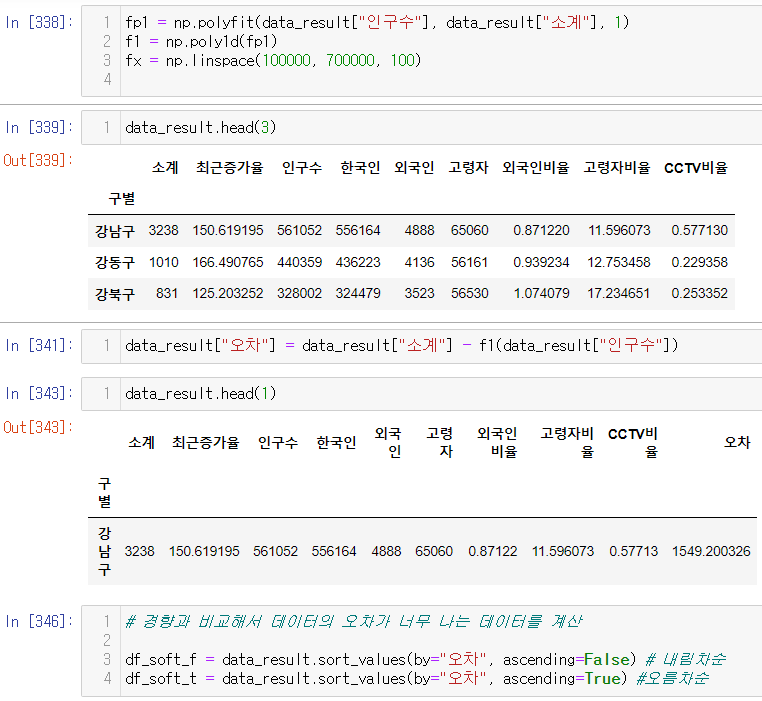
경향과의 오차 만들기
- 경향(trend)과의 오차를 만들자
- 경향은 f1 함수에 해당 인구를 입력
- f1(data_result["인구수"])
이 글은 제로베이스 데이터 취업 스쿨의 강의자료 일부를 발췌하여 작성되었습니다.

데이터 꿈나물