서울시 범죄 현황
2. 데이터 개요
데이터 읽기
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul.csv", thousands=",", encoding="euc-kr")✨숫자값을 문자로 인식할 수 있어서 설정✨
pandas pivot table
index 설정
index 설정
✏️입력
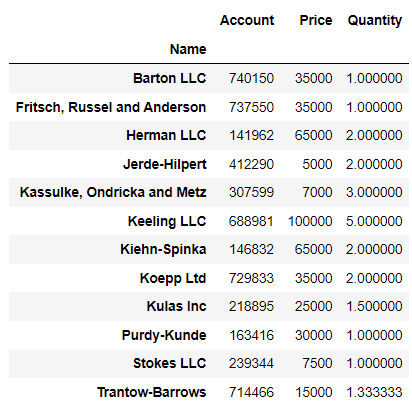
# pd.pivot_table(df, index="Name") df.pivot_table(index="Name")✨Name 컬럼을 인덱스로 설정✨
💻출력
멀티 인덱스 설정
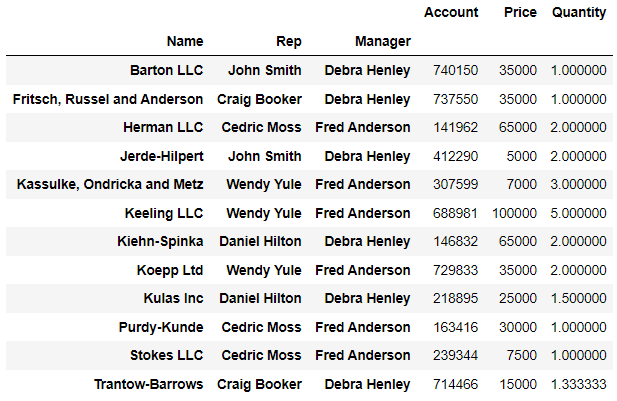
✏️입력
df.pivot_table(index=["Name", "Rep", "Manager"])💻출력
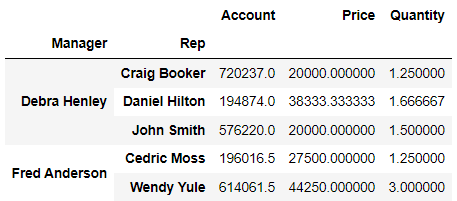
✏️입력
df.pivot_table(index=["Manager", "Rep"])💻출력
value 설정
value 설정
✏️입력
df.pivot_table(index=["Manager", "Rep"], values="Price")💻출력
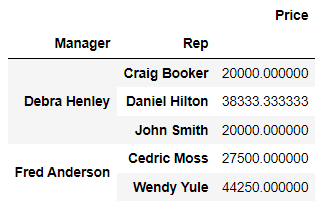
sum 연산 적용
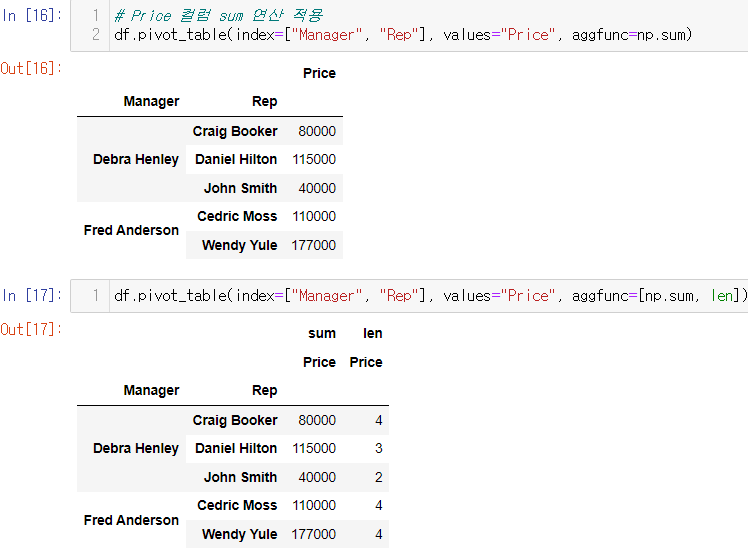
columns 설정
✏️입력
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum)✨Product를 컬럼으로 지정✨
💻출력
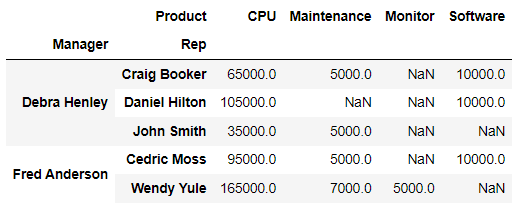
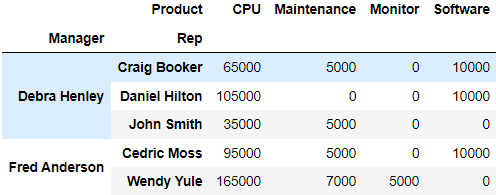
Nan 값 설정 : fill_value
✏️입력
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum, fill_value=0)💻출력
2개 이상 index, values 설정
✏️입력
df.pivot_table(index=["Manager", "Rep", "Product"], values=["Price", "Quantity"], aggfunc=np.sum, fill_value=0)💻출력
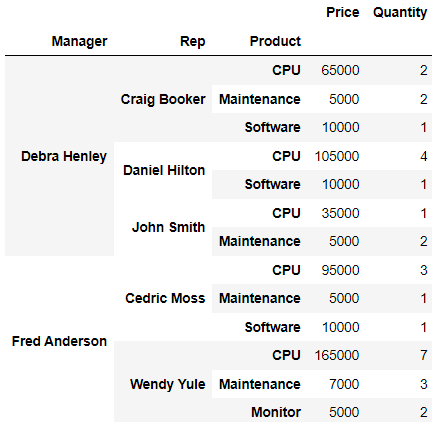
aggfunc 2개 이상 설정
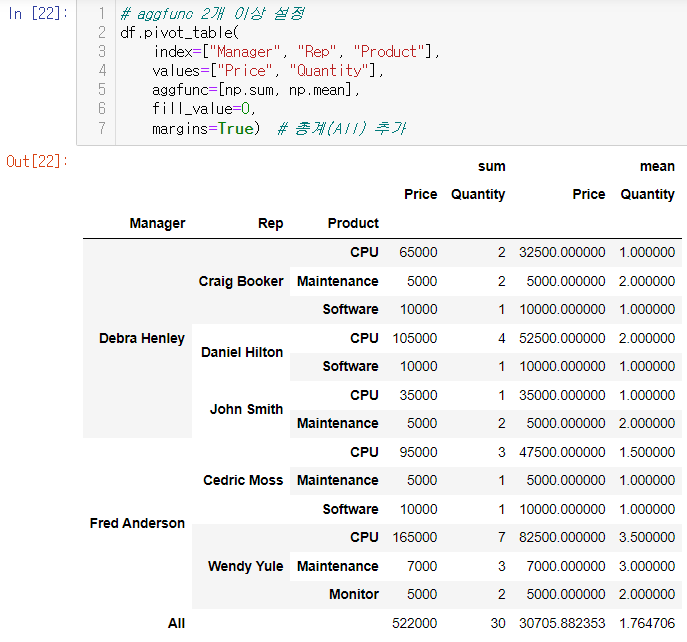
3. 서울시 범죄 현황 데이터 정리
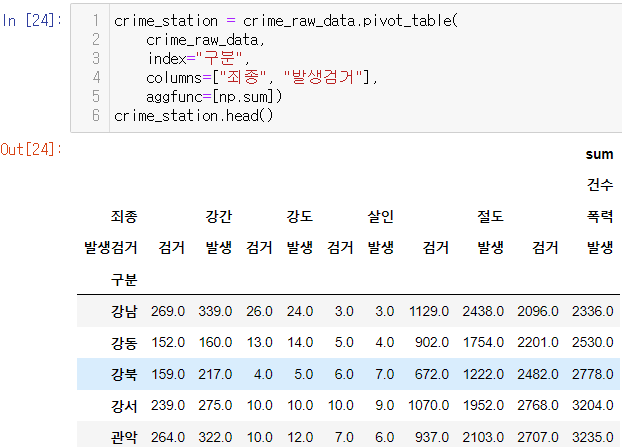
# 다중 컬럼에서 특정 컬럼 제거
✏️입력
crime_station.columns = crime_station.columns.droplevel([0,1]) crime_station.columns💻출력
MultiIndex([('강간', '검거'), ('강간', '발생'), ('강도', '검거'), ('강도', '발생'), ('살인', '검거'), ('살인', '발생'), ('절도', '검거'), ('절도', '발생'), ('폭력', '검거'), ('폭력', '발생')], names=['죄종', '발생검거'])
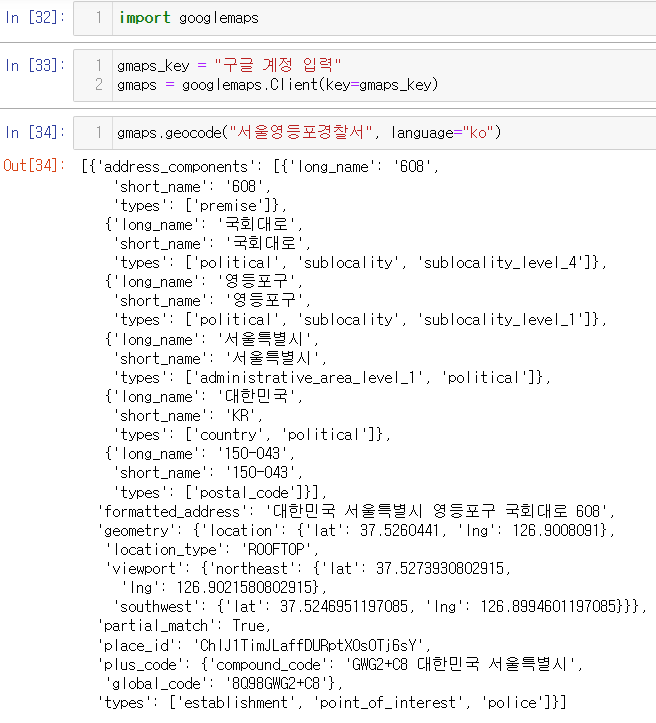
5. Google Maps API 설치
python 반복문
📌 pandas에 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴 때 for문을 사용하면, n번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들 때 itterows() 옵션을 사용하면 편함
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의
Google Maps 자료구조: 딕셔너리
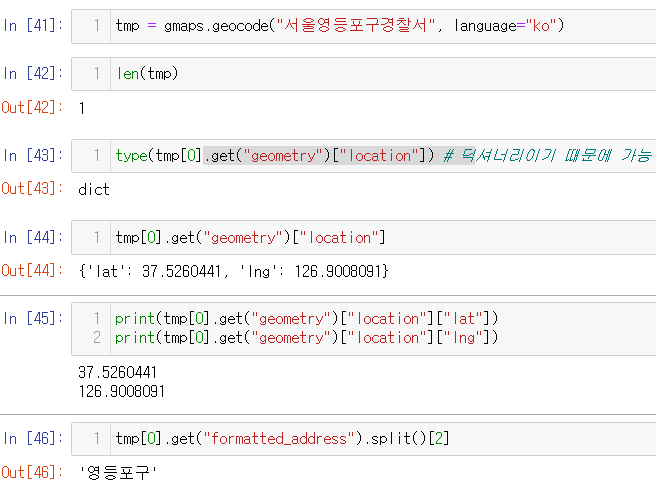
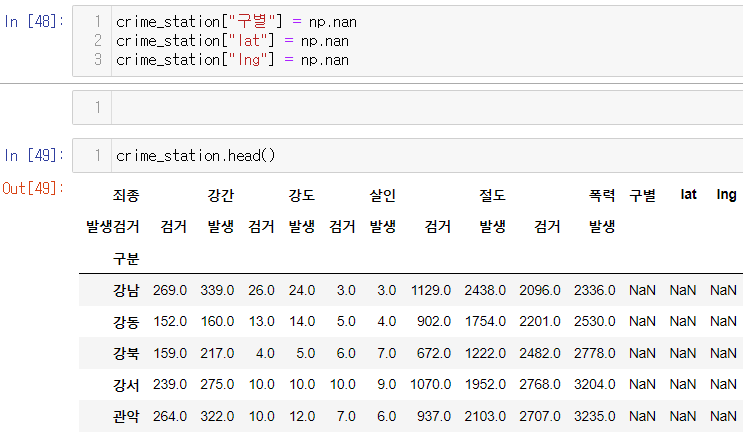
NaN 값으로 칼럼 추가
이 글은 제로베이스 데이터 취업 스쿨의 강의자료 일부를 발췌하여 작성되었습니다.

데이터 꿈나물