배경
다음학기부터 조지아텍에서 Artificial Intelligence 라는 코스를 듣게 된다. 이 석사 과정 프로그램 중에서 굉장히 어려운 코스로 유명하다.. 개학하기 한달 전인 지금부터 조금이라도 들어놔야 살아 남을 수 있을 것 같다는 느낌이 들어서 급하게 코스 비디오를 틀고 듣기 시작했다.
-
Game Playing
-
Search
-
Simulated Annealing
-
Constraint Satisfaction
-
Probability
-
Bayes Nets
-
Machine Learning
-
Pattern Recognition Through Time
-
Logic And Planning
-
Planning Under Uncertainty
코스 비디오는 대충 이런 순서로 되어 있지만 나는 과제-oriented 한 사람이기 때문에 1번 과제인 Search 를 먼저 들었다. 공교롭게도 저저번 학기에 들었던 로보틱스 인공지능 수업과 겹치는 토픽이라 이해하는데에는 크게 어렵지는 않았지만 새로운 개념도 있고 복습겸 들었던 것을 정리해 보도록 하겠다.
Search란
Search를 직역하면 찾다 / 검색하다 정도의 뜻이 될 것 같다. 밑에서는 "서치"라고 부르도록 하겠지만, 이 서치라는 알고리즘은 인공지능에게 굉장히 기초적인 개념이라고 생각하면 된다. 어떤 문제 (problem space라고도 부른다) 에 대한 답을 구할때 서치라는 알고리즘이 사용이 된다. 물론 이 서치알고리즘을 사용하기 위한 전제 조건들이 있는데 이건 나중에 서술하도록 하겠다. 서치를 설명할때 거의 항상 제일 먼저 등장하는 예제가 "경로찾기" 이다.
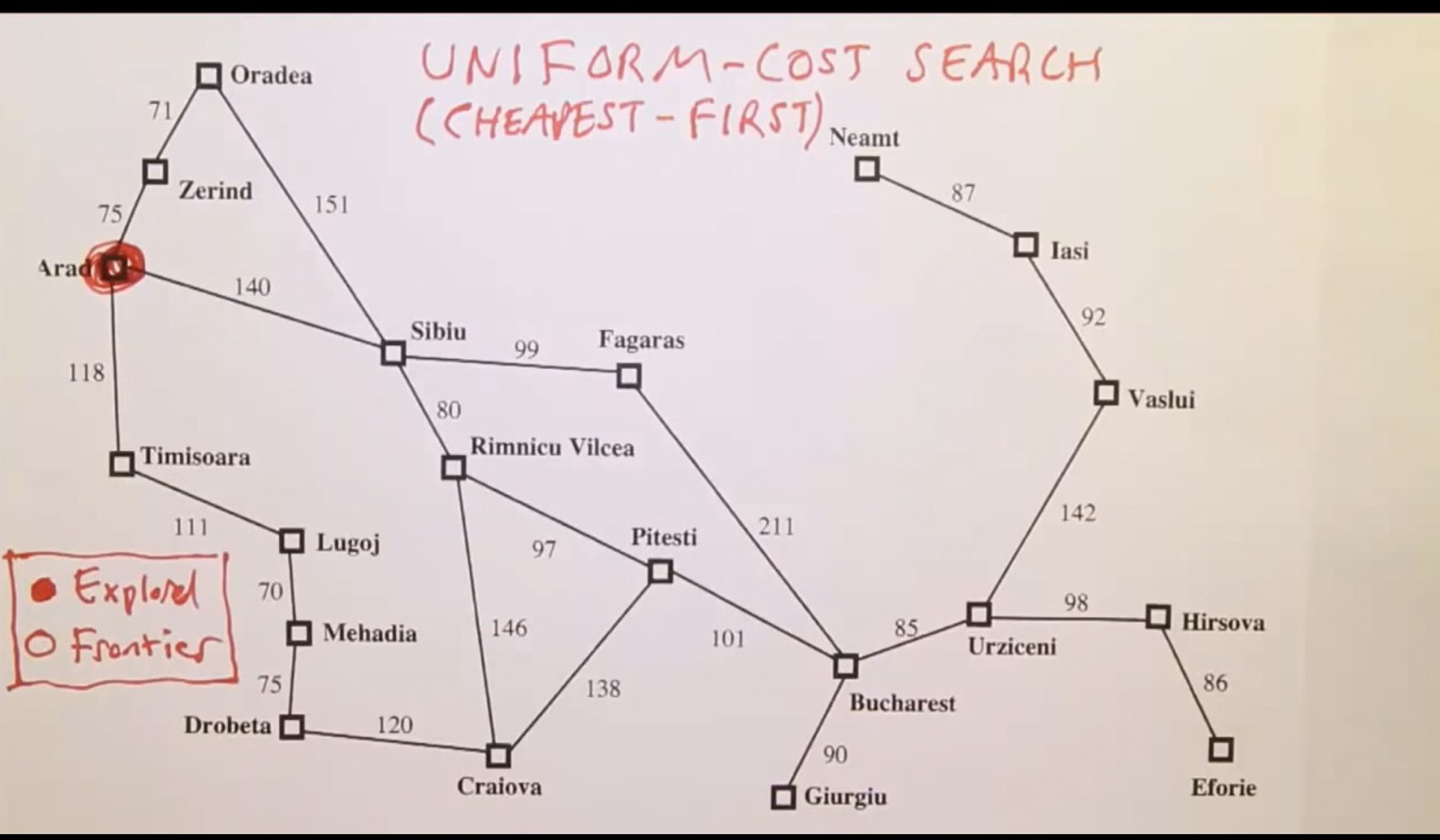
Arad 라는 도시에서 시작해서 Bucharest까지 가야한다고 생각해보자. 주어진 맵에서갈 수 있는 경로는 굉장히 많을 것이다. Sibiu로 가서 가는 경로 Tmisoara or Zerind 로 들려서 돌아가는 경로 등 경우의 수가 여러가지가 존재한다. Point A 에서 Point B로 연결되는 길은 각각의 길이 or weight or cost 가 부여가 되어 있다. Arad에서 Zerind까지는 75 Timisoara 까지는 118 등등.. 그리고 각각의 도시를 노드 or node 라고 부른다. 목적지까지 가는 경로를 최저 cost에 설정을 할 것인지, 아니면 방문하는 노드 수를 최소화 할 것인지에 따라서도 경로가 바뀔 것이다. 이런 설정을 다 해주고 인공지능에게 최적의 경로를 찾아달라고 하는 것이 서치 알고리즘이라고 생각하면 된다.
Search Algorithm 필요 정보
서치 알고리즘을 돌리기 위해 다음과 같은 정보들이 필요하다. 괄호 안에 들어간 것이 parameter다.
- Initial State: 내가 어디에서 시작하는가. 출발지점이라고 생각하면 된다. 보통 이 스테이트를 s 라고 표현한다.
- Actions(s): s의 상태일때 가능한 actions (a) 가 무엇이 있는지. 예를 들면 Arad라는 state s 일 경우 가능한 actions a 들은 a1: Zerind, a2: Sibui, a3: Timisoara가 되겠다.
- Reulst(a,s): s의 상태에서 a 액션을 취했을때 나오는 새로운 상태가 되겠다. s' 이라고 많이 표현하는데, Arad state s 에서 a1 액션 (Zerind) 로 가는 action을 취하면 Zerind가 새로운 상태 s'이 되는 것이다. 쉽게말해서 Arad에서 Zerind로 갔다는 소리고 이제 내가 Zerind에 위치하게 되는 결과가 되는 것.
- Goal State(s): True or False 값을 반환 하는데, 내가 도착한 새로운 상태 s가 내가 목적지에 가고자 한 곳에 도달을 했는지 판단.
- Path (s1 (a1) -> s2 (a2) -> s3 (a3) -> s4): 어떠한 특정 s 까지 도달하기 위해 취한 actions 들. 그리고 각각 action들을 행했을때 들어가는 비용도 있으니 path cost 도 알 수가 있을 것이다. Arad 에서 Sibiu를 거쳐 Fagars 까지 갔다면 node 기준 2가 될 것 이고, weight/cost 라면 144+99 = 243이 path cost가 되겠다.
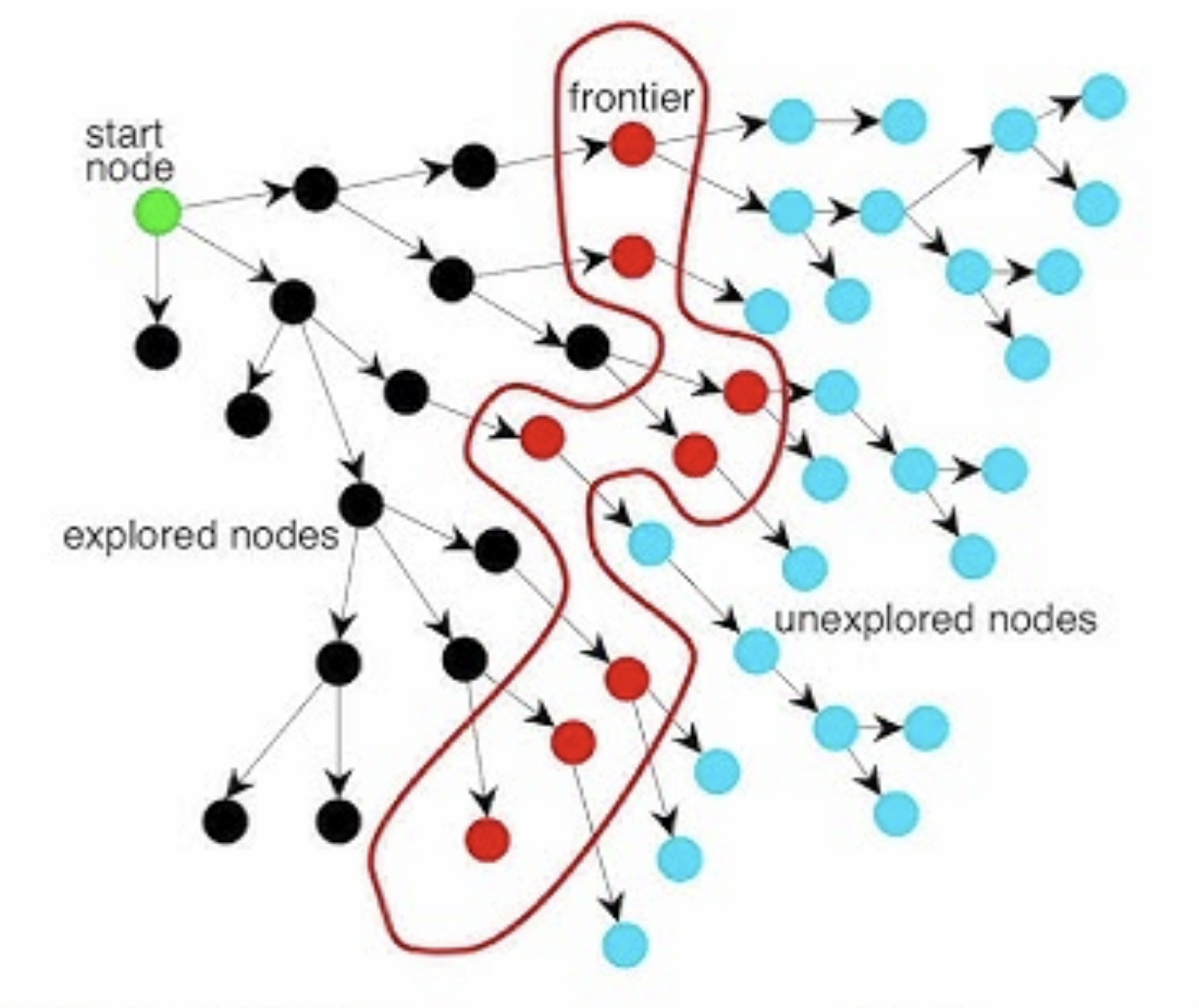
시작점에서부터 최종 목적지까지 조금씩 탐색을 시작하면 위와 같은 그림이 나오게 될 것이다. 중요하게 알아야 할 것은 Frontier 라는 개념인데, 카네기멜론 수업에서는 frontier를 이렇게 정의한다:
- 그래프 G = (V,E)와 방문한 집합 X ⊂ V의 경우, 프론티어는 방문한 정점 집합 X의 방문하지 않은 이웃 집합입니다.
예..? 난 이렇게 수학적으로 써 놓은 걸 너무 싫어함 ㅠ
간단하게 설명하면 까만 점들은 내가 이미 탐색을 한 노드들이고 파란색은 아직 확인하지 못한 노드들인데, 빨간색 노드 (프론티어) 들이 내가 탐색하고 있는 최전방의 노드들 이라고 생각하면 되겠다. 이 빨간색 노드들에서 내가 가능한 actions들이 무엇이 있고 여기가 goal state인지 아닌지 확인을 해야하는 노드들인 셈이다. 이 과정을 처리하고나면 프론티어에 있던 노드가 explored 노드로 바뀌고 프론티어 영역이 한 노드 오른쪽으로 (위 그림 기준) 확장된다.
Tree search function
서치 알고리즘은 굉장히 다양한 variation들이 존재한다. 그 중 기본/뼈대가 되는 tree search algorithm을 먼저 설명해 보겠다.
- frontier에 시작 노드/state을 집어 넣는다.
- 목적지를 찾을때 까지 밑의 루프를 돌림
- if frontier == empty: return "No Solution"
목적지까지 가는 경로가 존재하지 않다는 뜻 - else: path = take one from frontier. (frontier에서 하나 스테이트를 고른다 (pop을 사용함). 이 스테이트는 본인의 스테이트까지 도달하기 위한 모든 actions들의 정보를 가지고 있다.)
여기가 좀 중요하다. 프론티어에서 하나의 스테이트를 고르는 방식의 차이가 서치 알고리즘의 종류를 가른다고 생각하면 된다. - s = path.end (path의 가장 끝자락에 있는 노드를 설정한다)
- if s == goal: return path (목적지에 도달했다면 그 경로를 반환한다)
- else: expand path (s에서 가능한 모든 actions들 (a1,a2...)을 path에 더하고 새로운 path를 정의한다. s' 과 a' 들로 이루어진 새로운 path들이 생겨남)
- add s' to the frontier (이제 frontier에 이 s'혹은 s'들을 저장한다)
이게 tree search 알고리즘의 뼈대라고 보면 된다. 다음 주차에서는 이 서치 알고리즘의 종류들을 몇가지 설명해 보도록 하겠다.
