Breadth First Search (BFS)
서치 알고리즘 중 기초가 되는 BFS에 대해 얘기해보겠다. Breath를 직역하면 '폭' 이라는 뜻을 가지고 있는데 (책상 폭이 어느정도에요~ 할때 그 폭) 서치 알고리즘이 실행되는 방향이 폭으로 진행되기 때문에 이런 이름을 가지고 있는 것 같다. 저번주에 사용했던 이미지를 그래도 사용하겠다:
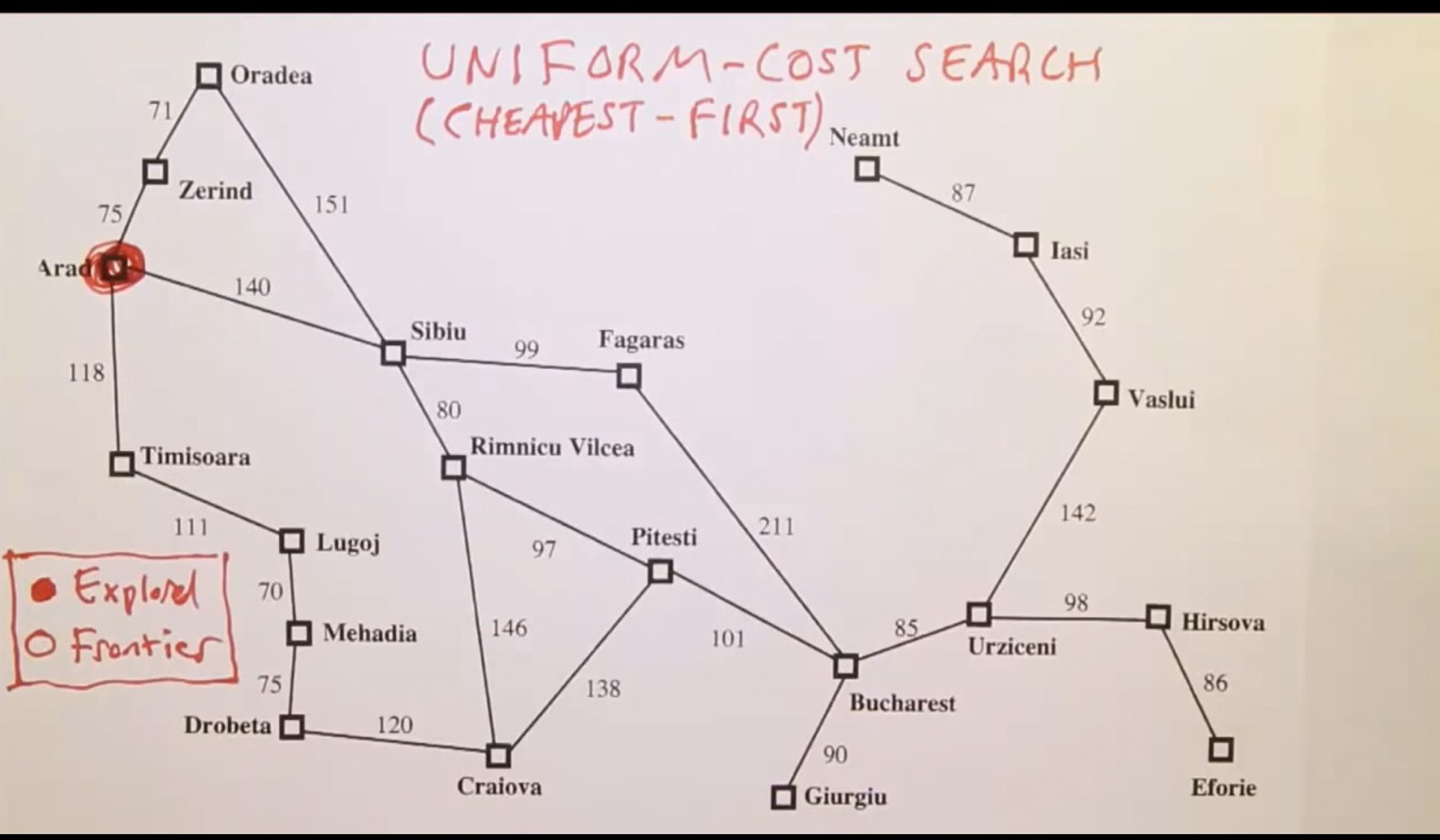
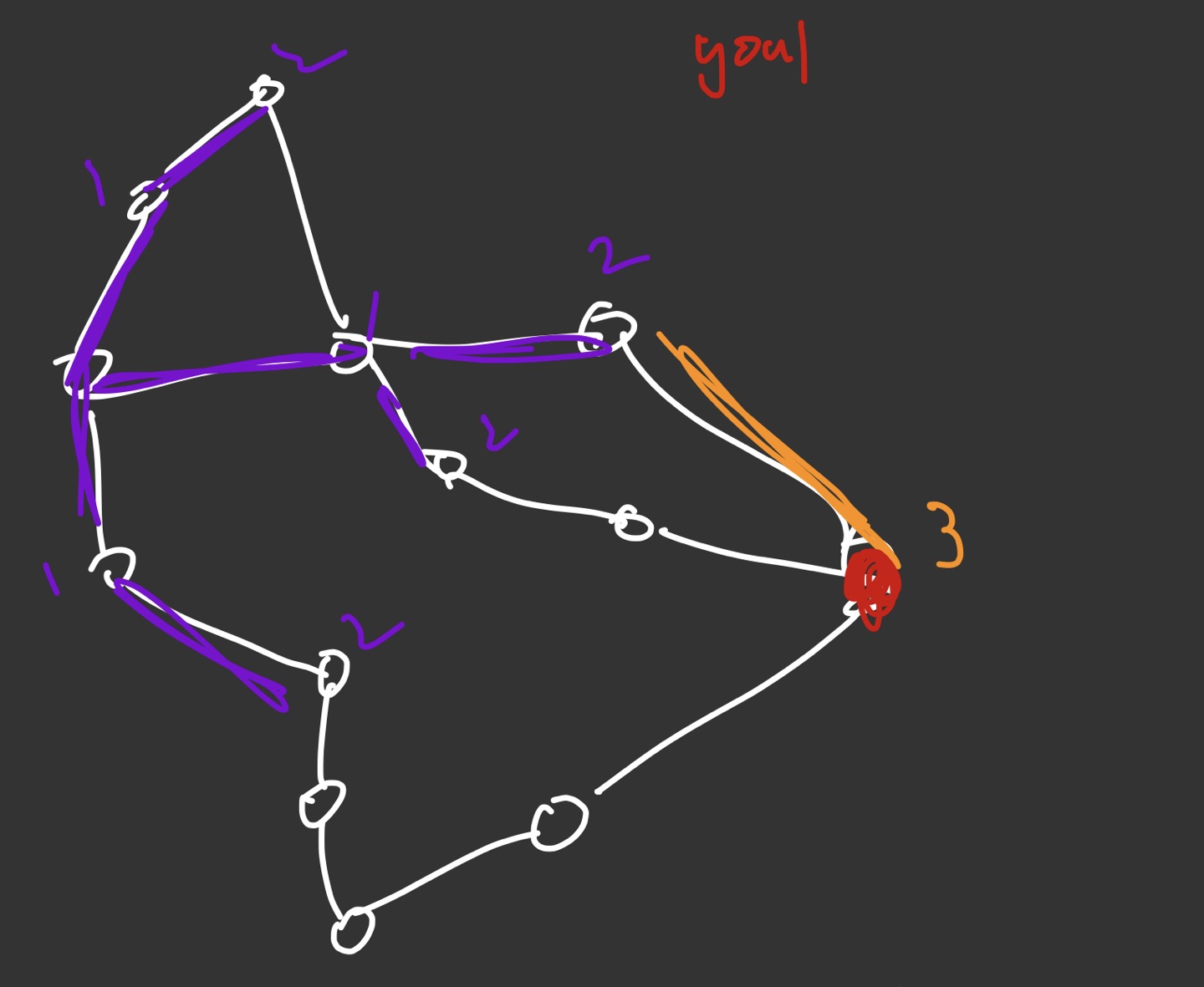
Arad 에서 시작하여 Bucharest까지 도달해야 한다고 가정했을때, 경로 탐색 순서가 노드 깊이 순으로 찾게 된다. 1의 노드 거리를 가진 Timisoara, Zerind, Sibiu를 방문하게 되고 (이 3개의 도시 중에서 어느 것이 먼저 선택이 될 지는 설정하기에 따라 다르다. Random으로 선택을 할 수도, cost 작은 순으로 고를 수도 있다. 이게 중요한 것이 아니라, Frontier가 어떤 방식으로 펼쳐지는지가 Tree function variation에서 중요하다.) 그 다음으로는 Lugoj, Oradea, Rimnicu Vilcea, Fagaras 순서로 탐색을 실시한다. 조금 장황하게 적어놓았지만 결국에는 밑의 그림과 같이 탐색을 한다는 뜻이다.
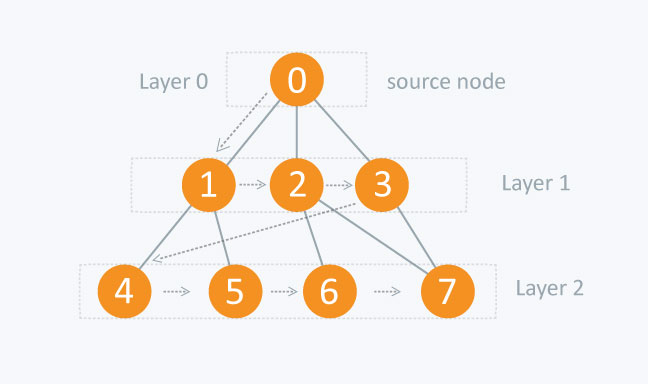
소스 노드에서 시작하여 노드 1 거리 (혹은 Layer 1)의 노드들을 다 탐색하고, 그 다음 노드 2 거리, 3거리 ... 의 식으로 탐색의 순서가 결정된다. 이렇게 쭉 펼치기 시작하면 explored nodes, frontier, unexplored nodes 들이 생길 것이다.
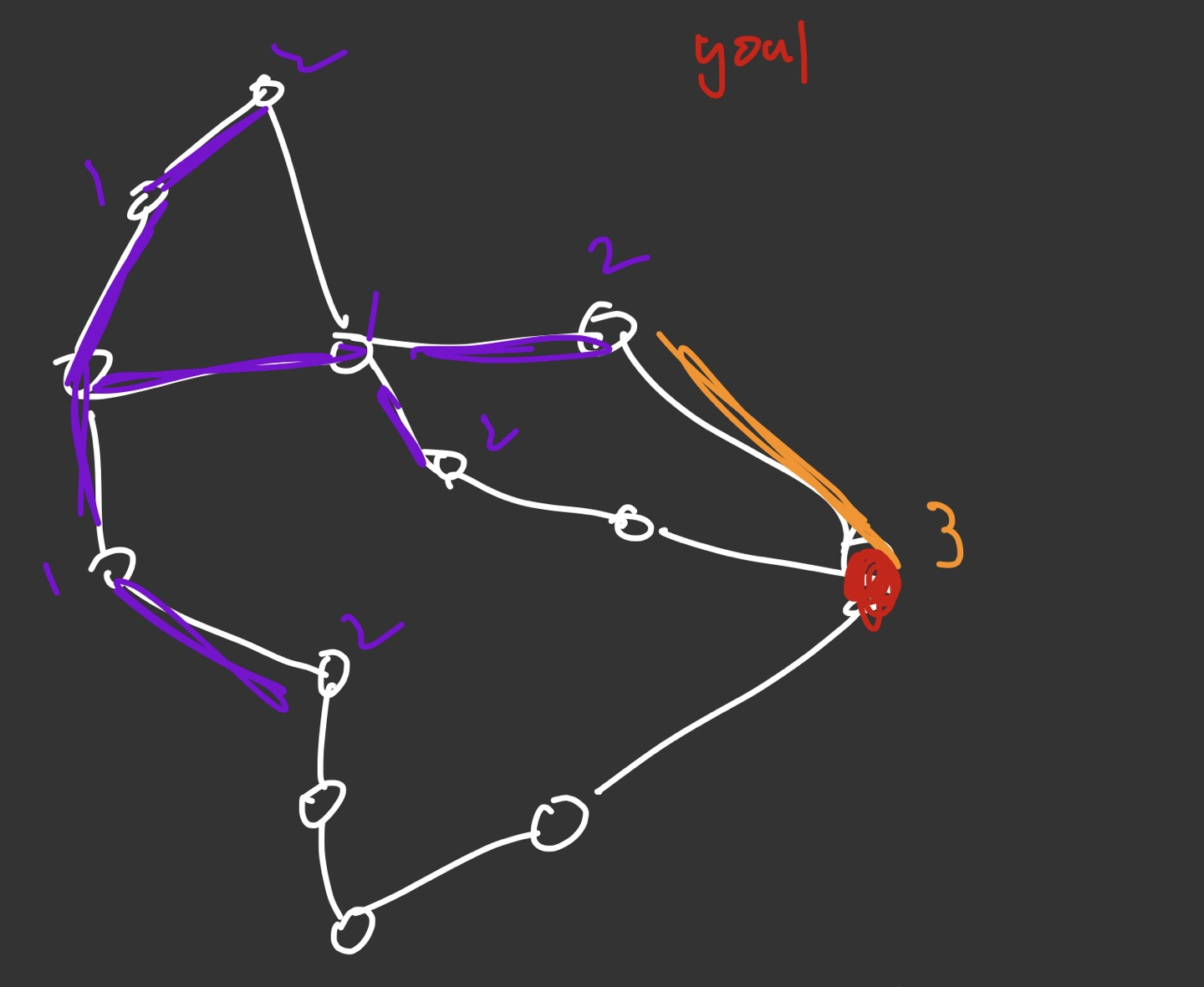
그림이 좀 발퀄이기는 한데, 결국 노드 depth에 의해서 탐색이 진행이 되고, 빨간색 goal지점에 닿게 된다. 여기서 주의해야 할 점은, 3에 바로 도달했다고 해서 알고리즘이 멈추지 않는다는 것이다. 노드 길이 2의 값을 가진 모든 프론티어에서 확장하는 단계를 거치고 나서, 그럼에도 저 주황색 path가 가장 짧은 값이 나왔을때야 비로소 알고리즘이 멈춘다. 그러니까 쉽게 말해서 2 노드 값을 가진 노드들이 맨위, 중상, 중하, 맨아래 노드들이 있는데 얘네들이 다 한번씩 expand를 해야만 알고리즘이 멈춘다는 뜻이다. 왜냐하면 더 최적화 된 루트가 있을 수 있기때문이다. 다만 여기서는 노드 길이가 무조건 자연수로밖에 나올 수 없기 때문에 (2.3짜리 노드길이는 이 문제에서는 없다), 노드 길이는 무조건 자연수라는 조건을 걸어버리고 알고리즘 탐색을 바로 terminate 하는 최적화를 할 수는 있을 것 같다.
이렇게 가로로 서치를 하는 것을 (폭) breadth first search라고 한다. 이제 알아볼 것은 depth first search 이다. 알고리즘의 흐름자체는 BFS와 매우 유사하니 좀 대충 훑고 넘어가겠다.
Depth First Search (DFS)
Depth First Search는 깊이를 기준으로 탐색을 하는 알고리즘이다. 위의 그래프는 옆으로 쭉 퍼져서 한칸씩 깊게 탐색을 했지만 이 알고리즘은 말 그대로 한 브랜치를 먼저 쭉 판다는 얘기다. 밑의 그림을 참고하자
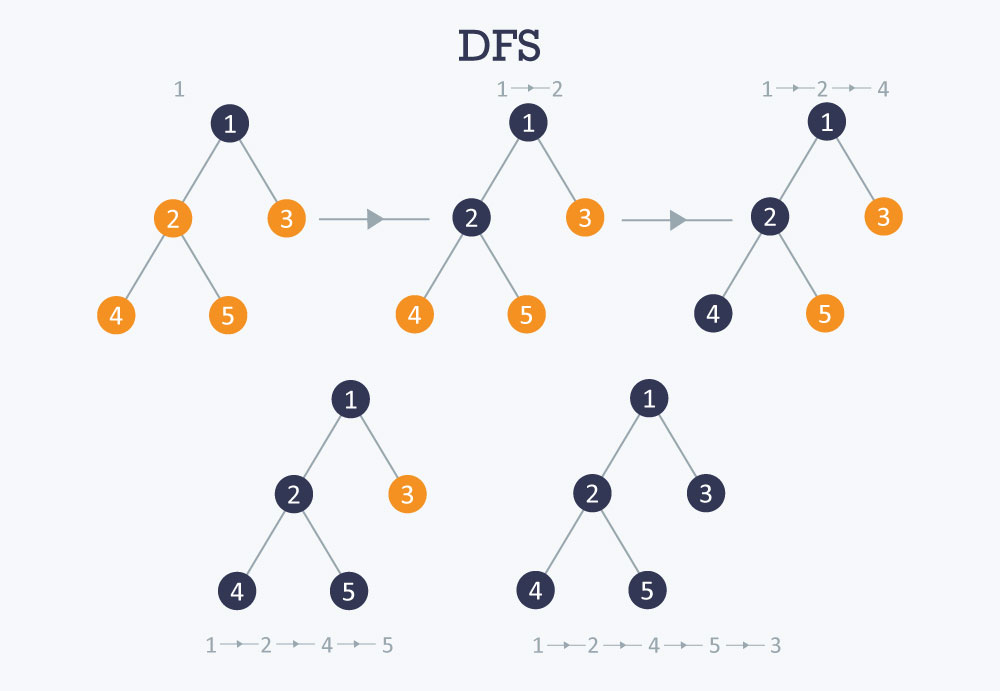
위의 그림처럼 DFS는 한쪽을 제일 깊게 파고, 더 이상 깊이 갈 곳이 없다면, 제일 가까운 위의 갈래길로 올라가 거기서부터 다시 탐색을 시작한다. 그렇기때문에 얘는 첫 단추가 잘못끼워지면 그냥 망하는 알고리즘(?) 일 수도 있다. 대신 특정경우 효율이 좋다.. 맨 위의 그림으로 예를 들면
Arad로 시작해서 Timisoara-> Lugoj -> Mehadia -> Drobeta ... 으로 이어지게 되는 것이다.
당연히 optimal한 탐색은 아니지만 이런 알고리즘도 쓰이며 존재한다는 것을 배웠다.
다음주에는 uniform cost search알고리즘과 함께 시간이 된다면 A* 알고리즘까지 다루어 보겠다...!

많은 도움이 되었습니다, 감사합니다.