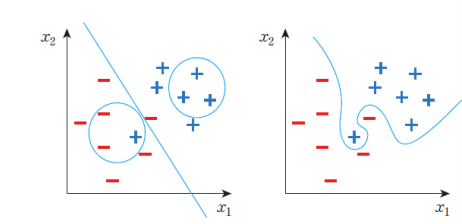
과잉적합? 과소적합?
과잉적합(Overfitting)과 과소적합(Underfitting)은 머신러닝 및 딥러닝 모델을 평가하고 최적화하는 과정에서 중요한 개념이다.
과잉적합
지나치게 훈련 데이터에 특화돼 실제 적용 시 좋지 못한 결과가 나오는 것
자세하게는 모델이 훈련 데이터에 너무 맞춰져서 훈련 데이터에 대한 예측은 잘 수행하지만, 새로운 데이터나 검증 데이터 또는 테스트 데이터에 대한 예측 능력이 떨어지는 상황을 말한다.
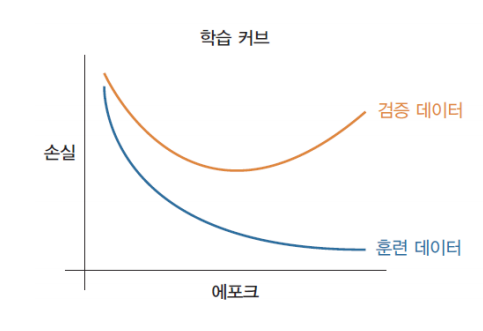
과잉 적합을 아는 방법
훈련 데이터의 손실값은 계속 감소하는데, 검증 데이터의 손실값은 증가하는 경우, 과잉 적합이다.
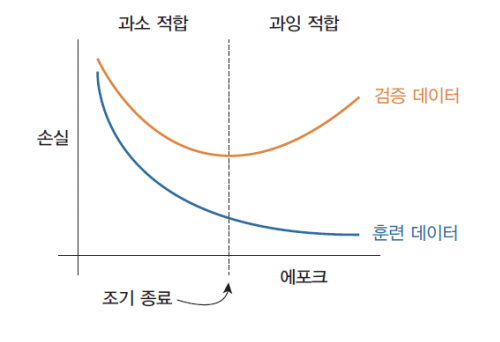
정규화
이러한 문제는 정규화를 사용해 해결 가능하다.
정규화의 종류
-
조기 종료
검증 손실이 더 이상 감소하지 않는 것처럼 보일 때마다 훈련을 중단한다.
-
가중치 규제
가중치의 값이 너무 크면, 판단 경계선이 복잡해지고 과잉 적합이 일어나므로 가중치의 절대값을 제한한다.
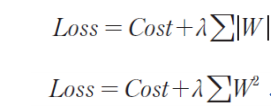
L1규제: 가중치의 절댓값 합을 비용 함수에 추가
L2규제: 가중치의 제곱 합을 비용 함수에 추가
-
데이터 증강
소량의 훈련 데이터에서 많은 훈련 데이터를 만들어낸다.
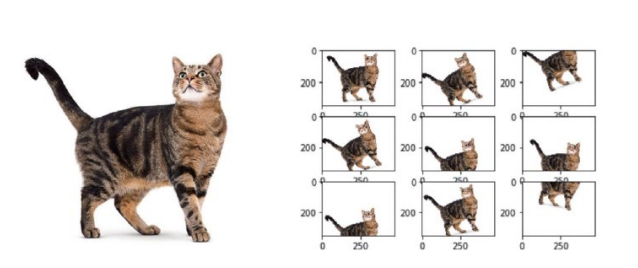
-
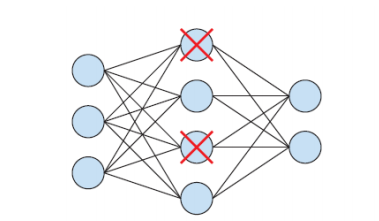
드롭아웃
몇 개의 노드들을 학습 과정에서 랜덤하게 제외한다.
과소적합
모델이 훈련 데이터에 대해서도 제대로 학습하지 못하는 상황을 의미한다. 모델이 너무 간단하거나 데이터의 복잡성을 잡아내지 못할 때 발생할 수 있다.
과소적합을 해결하는 방법
- 더 복잡한 모델 구조 사용
- 더 많은 특성(feature)을 사용
- 특성 엔지니어링을 통해 데이터를 더 잘 표현하도록 노력
- 훈련 데이터 양 증가

..