NLP란?🤔
인간의 언어를 컴퓨터가 이해하고 해석하여 유용한 방식으로 사용할 수 있도록 하는 인공지능(AI)과 언어학의 한 분야
NLP하는 방법
자연어를 처리하는 방법에는 여러가지가 있다.
딥러닝이 유행하기 전까지는 단어 간의 통계적인 유사성에 바탕을 둔 방법이 많이 사용되었다.
최근에는 딥러닝을 이용한 방법이 많은 인기를 얻고 있다. 특히 RNN을 많이 사용한다.
https://velog.io/@humpose/RNNRecurrent-neural-networks
RNN 참고
NLP PROCESS
자연어 처리의 첫 단계는 텍스트 전처리이다. 전처리에는
토큰화, 소문자 변환, 구두점 정제, 불용어 제거
가 있다.
토큰화
토큰화는 말뭉치에 포함된 텍스트를 꺼내서 토큰(token)이라 불리는 단위로 나누는 작업을 말한다.
ex) "This is a cat" > 토큰화 > "This", "is", "a", "cat"
소문자 변환
대문자로 된 단어를 소문자로 변경하면 단어의 개수를 줄일 수 있다.
하지만 무조건 대문자를 소문자로 만들어도 안 된다. 대문자와 소문자의 의미가 다른 단어도 있으므로 [ex)US/us]
구두점 정제
일반적으로 구두점들은 자연어 처리에 도움이 되지 않기 때문에 삭제하는 것이 좋다.
불용어 제거
불용어는 문장에 많이 등장하지만 큰 의미가 없는 단어들이다.

두 번째 단계에서는 심층 신경망이 이해할 수 있는 방식으로 단어를 변환해야 한다. 변환 방법에는
Integer encoding, One-hot encoding, Word embedding
이 있다.
Integer encoding
고유한 숫자를 사용하여 각 단어를 구분한다.
일반적으로는 빈도가 높은 단어부터 차례대로 번호를 부여한다.
예를 들어, 말뭉치(Corpus)에 단어가 1,000개가 있다면, 각 단어에 1번부터 1,000번까지의 번호(정수)를 매긴다.
One-hot encoding
각 단어를 이진 벡터 중에서 하나만 1이고 나머지는 모두 0으로 표시한다.
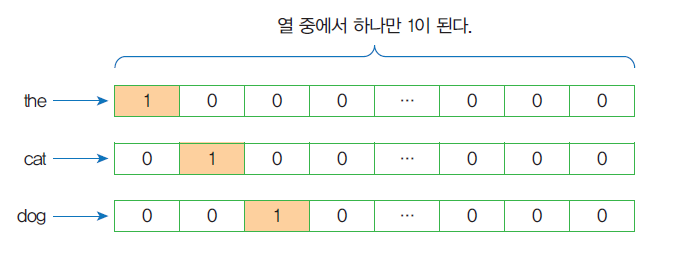
One-hot encoding의 약점
One-hot encoding의 약점은 비효율성과 유사도의 표현 불가이다.
비효율성
원-핫 인코딩된 벡터는 희소하다. 즉 벡터의 대부분이 0이다.
예를 들어서 단어 집합에 10K개의 단어가 있다고 가정하자.
각 단어를 원-핫 인코딩하면, 99.99%가 0인 벡터가 10K개가 만들어진다.
(이를 spare vector라고도 한다.)
유사도의 표현 불가
각 벡터들은 단어들 간의 유사도를 표현하지 못한다. 단어마다 1인 벡터는 전부 다르기 때문이다.
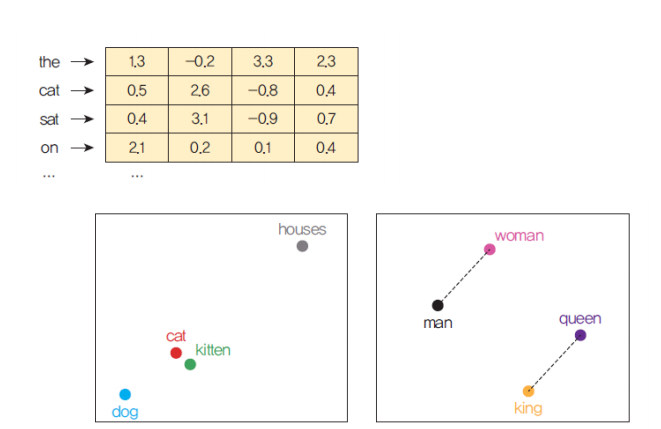
Word embedding
워드 임베딩(word embedding)은 하나의 단어를 밀집 벡터(dense vector) 로 표현하는 방법이다. 따라서, 일반적으로 단어의 개수보다 차원이 작으며 효율적이고 조밀하다.
신경망을 사용해 학습을 통하여 훈련 데이터에서 자동으로 생성하는 것이 일반적이다.
Word embedding의 종류
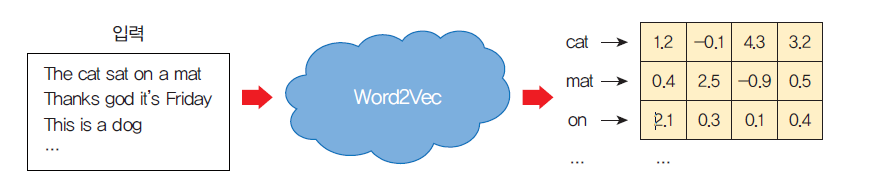
Word2vec
Word2Vec은 아래에 표시된 것처럼 텍스트 말뭉치를 입력으로 받아들이고 각 단어에 대한 벡터 표현을 출력하는 알고리즘이다.
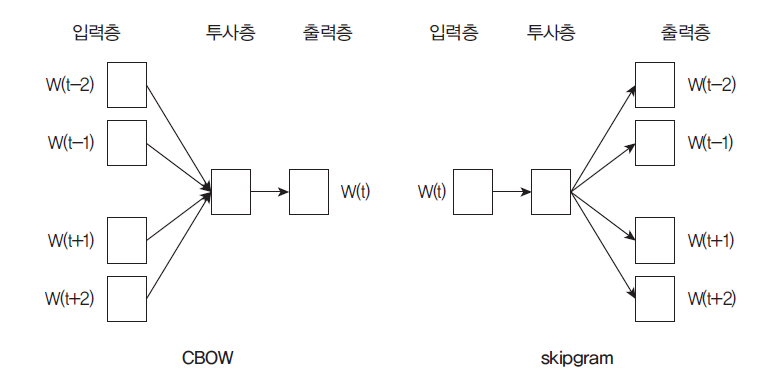
CBOW(Continuous Bag of Words)
CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법이다.
skipgram
skipgram은 중간에 있는 단어로 주변 단어들을 예측하는 방법이다.